
Data Association at the Level of Narrative Plots to Support Analysis of Spatiotemporal Evolvement of Conflict: A Case Study in Nigeria


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
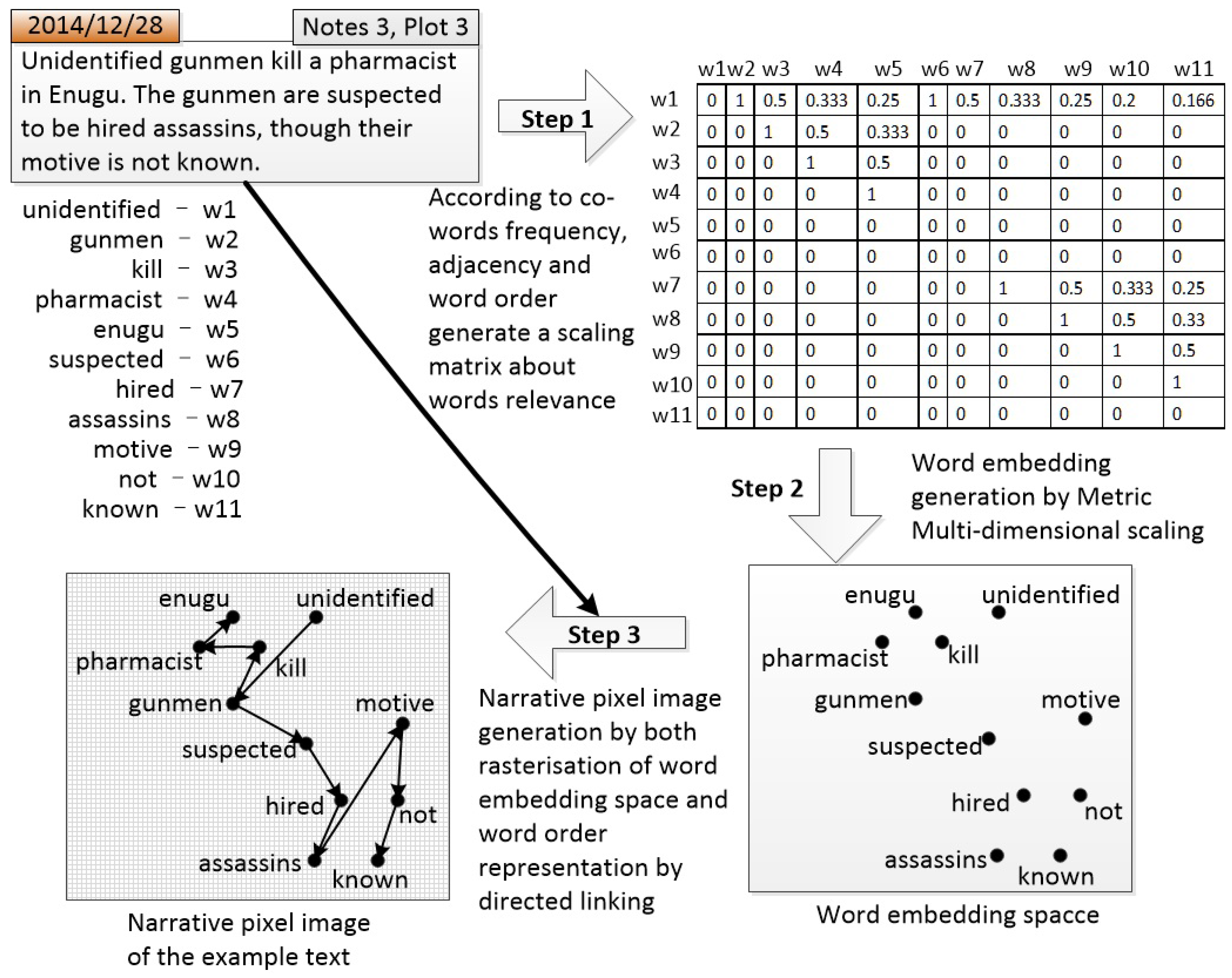
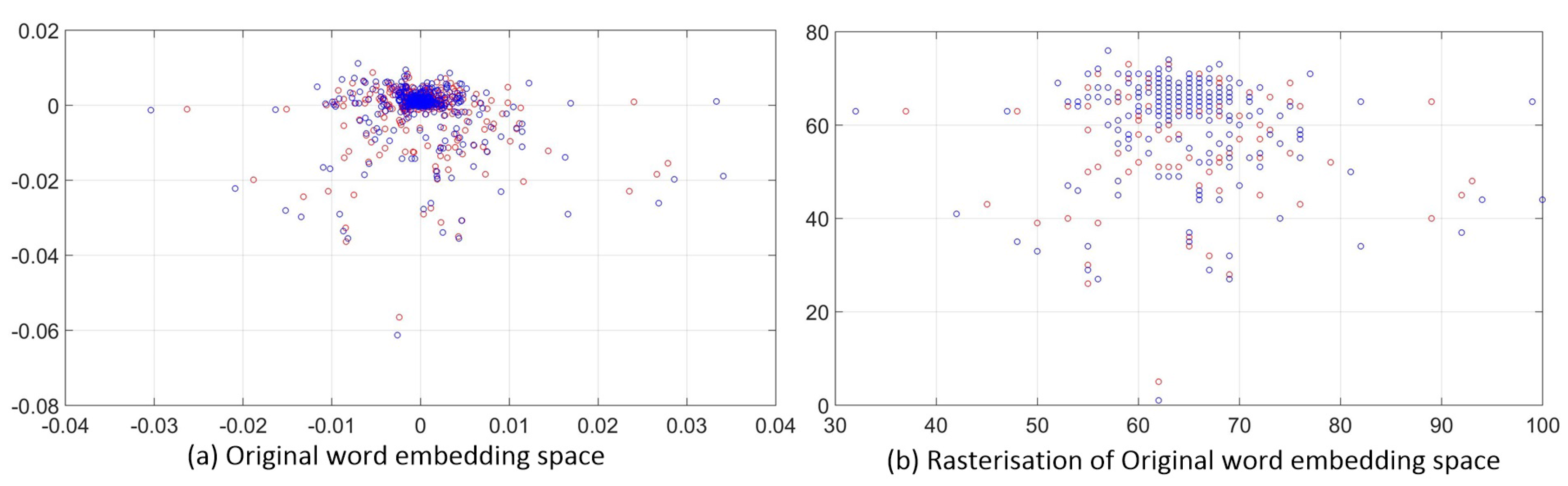
- We present an image-based textual representation that learns both the distribution of the feature words and the word orders in each event by a square pixel image.
- Based on the proposed representation, a hierarchy cluster process tool is employed to mine homologous historical events that have similar semantics as the events of interest.
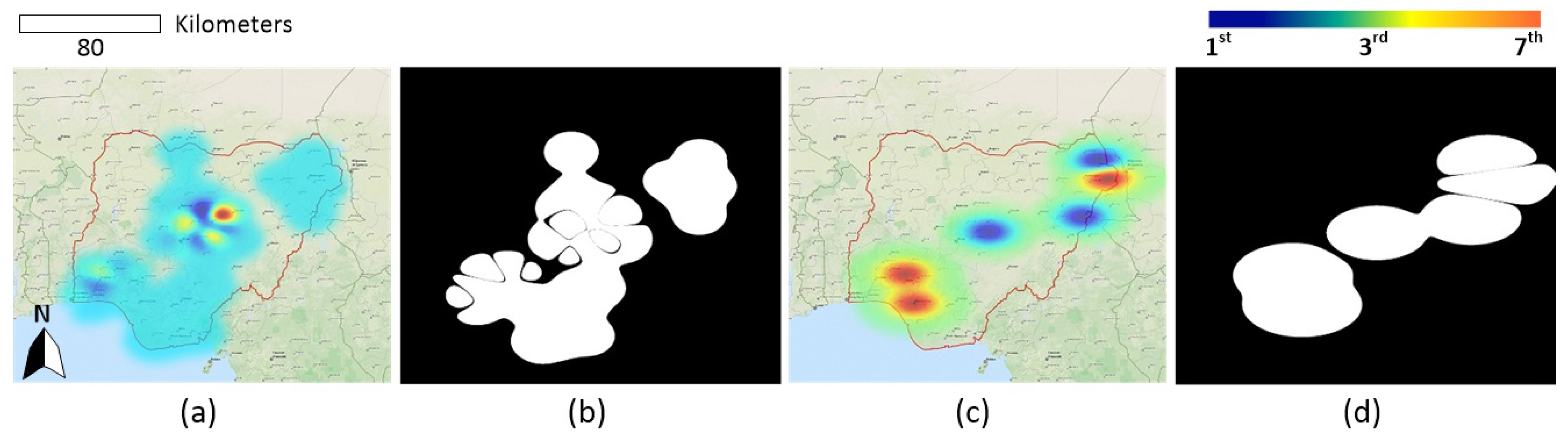
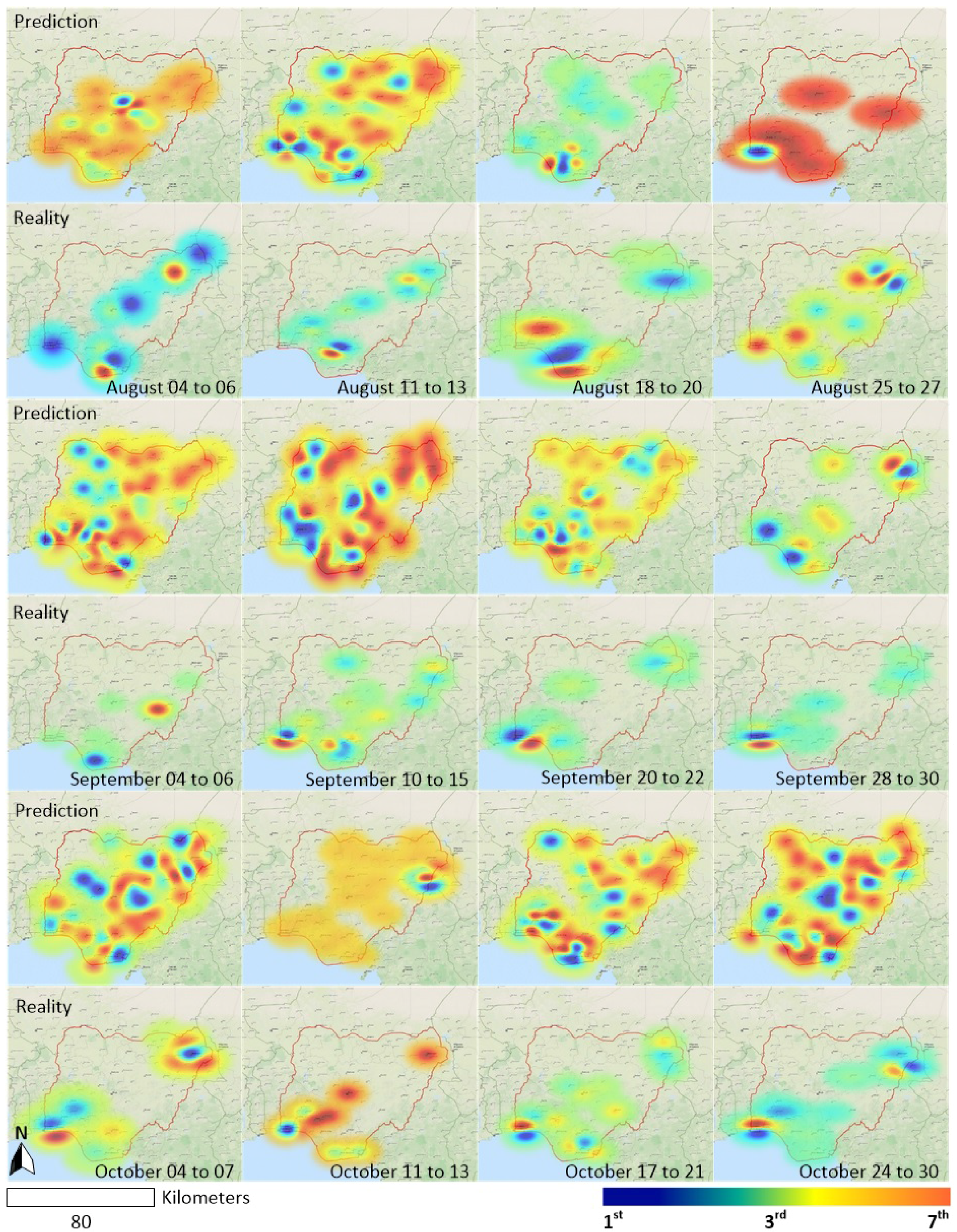
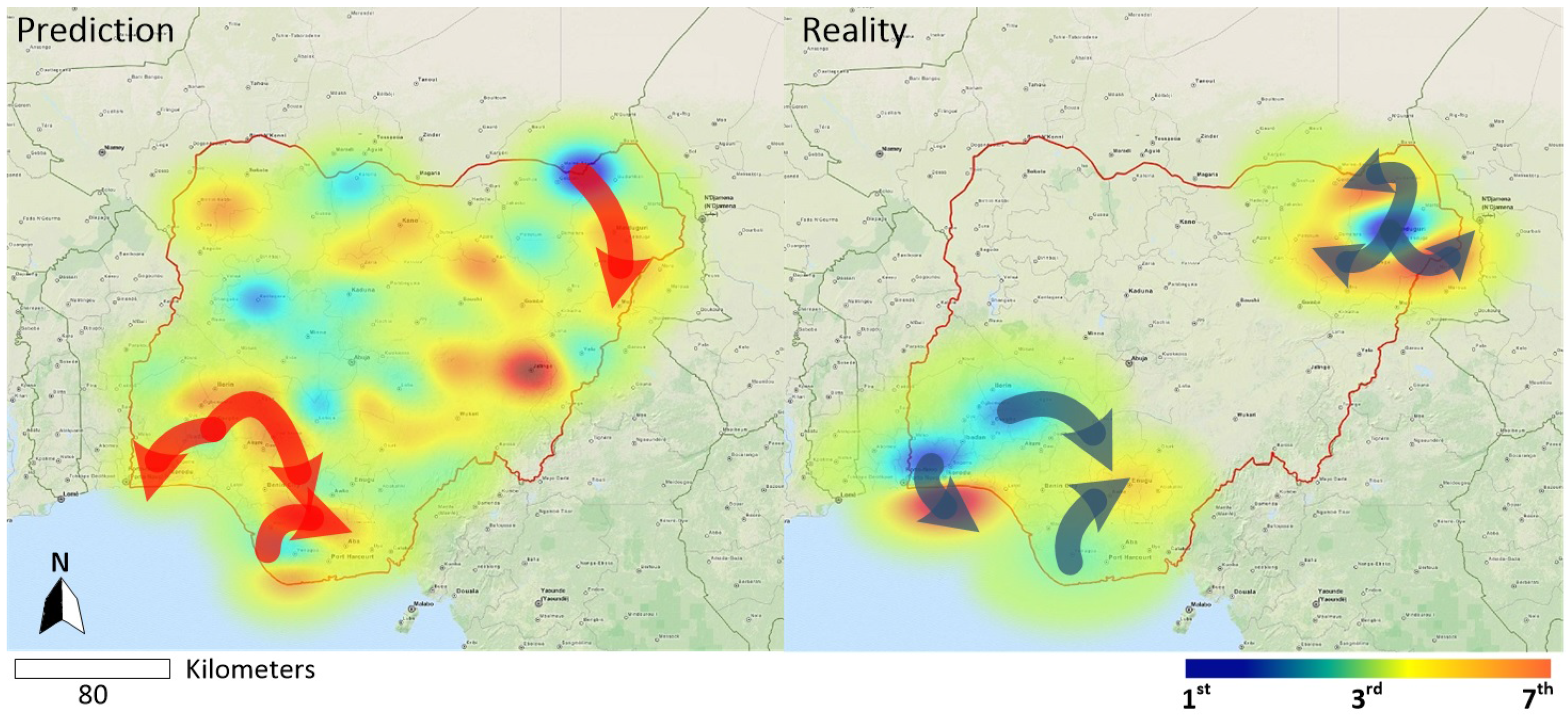
- A spatiotemporal evolution map, which is generated by the Kriging algorithm, is presented to promote understanding of the development of a series of conflicts. The results demonstrate that our approach has the potential to provide a timely spatiotemporal predictor for the near real-time forecasting task.
2. Review
2.1. Modelling of Conflict Dynamics
2.2. Association Analysis
2.3. Computational Model of Narrative
2.4. Short Text in Narrative
- The vector space model (VSM), which represents each event text as a bag-of-words vector. The similarity computing method must be designed for comparing the representation vectors, which are sparse in high-dimensional space [45].
- The topic model is a Bayesian statistics-based algorithm that learns the topic components and mixture coefficients of each text. The conventional topic models reveal the latent topics in a corpus by capturing the word co-occurrence patterns at the document level [46].
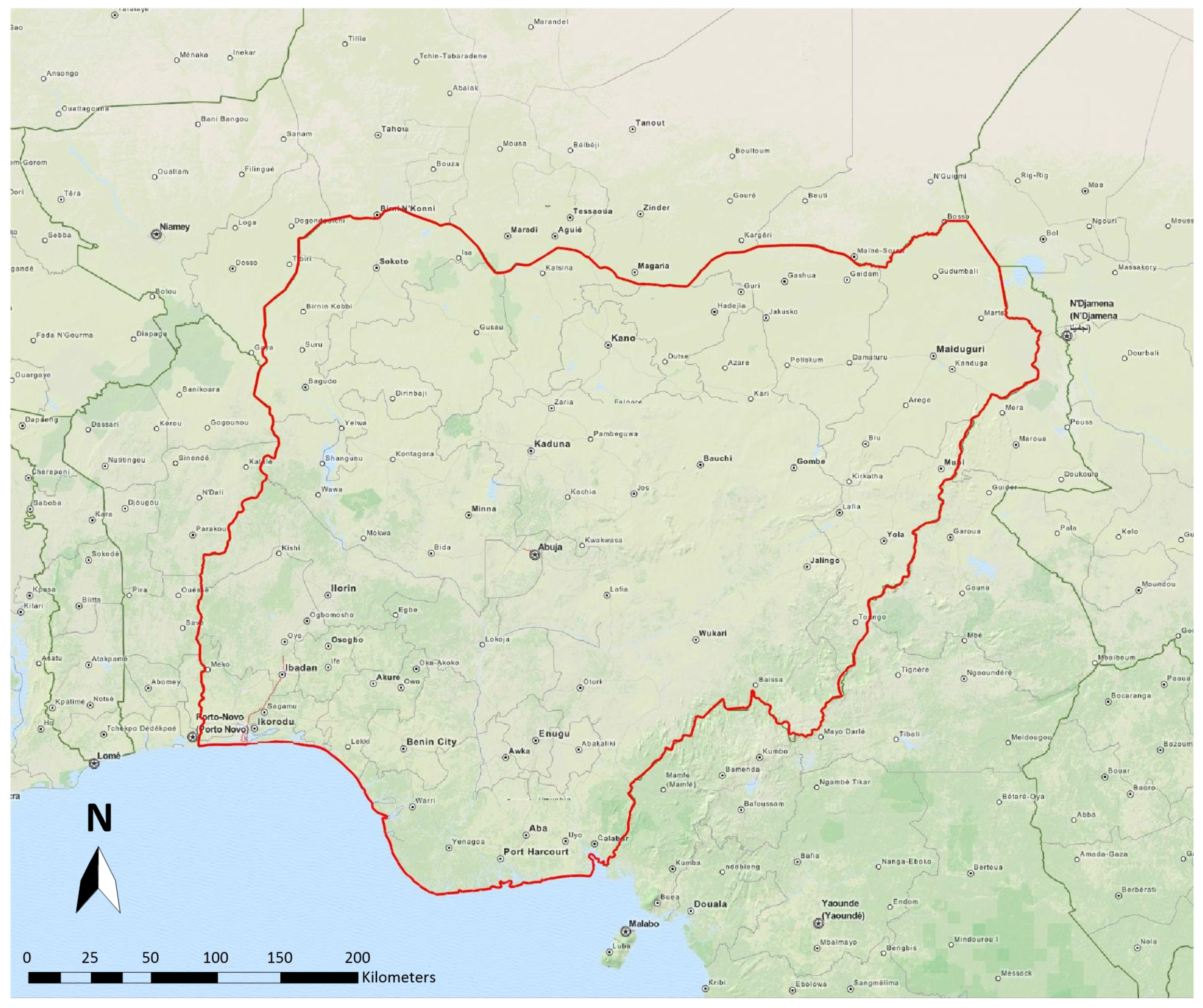
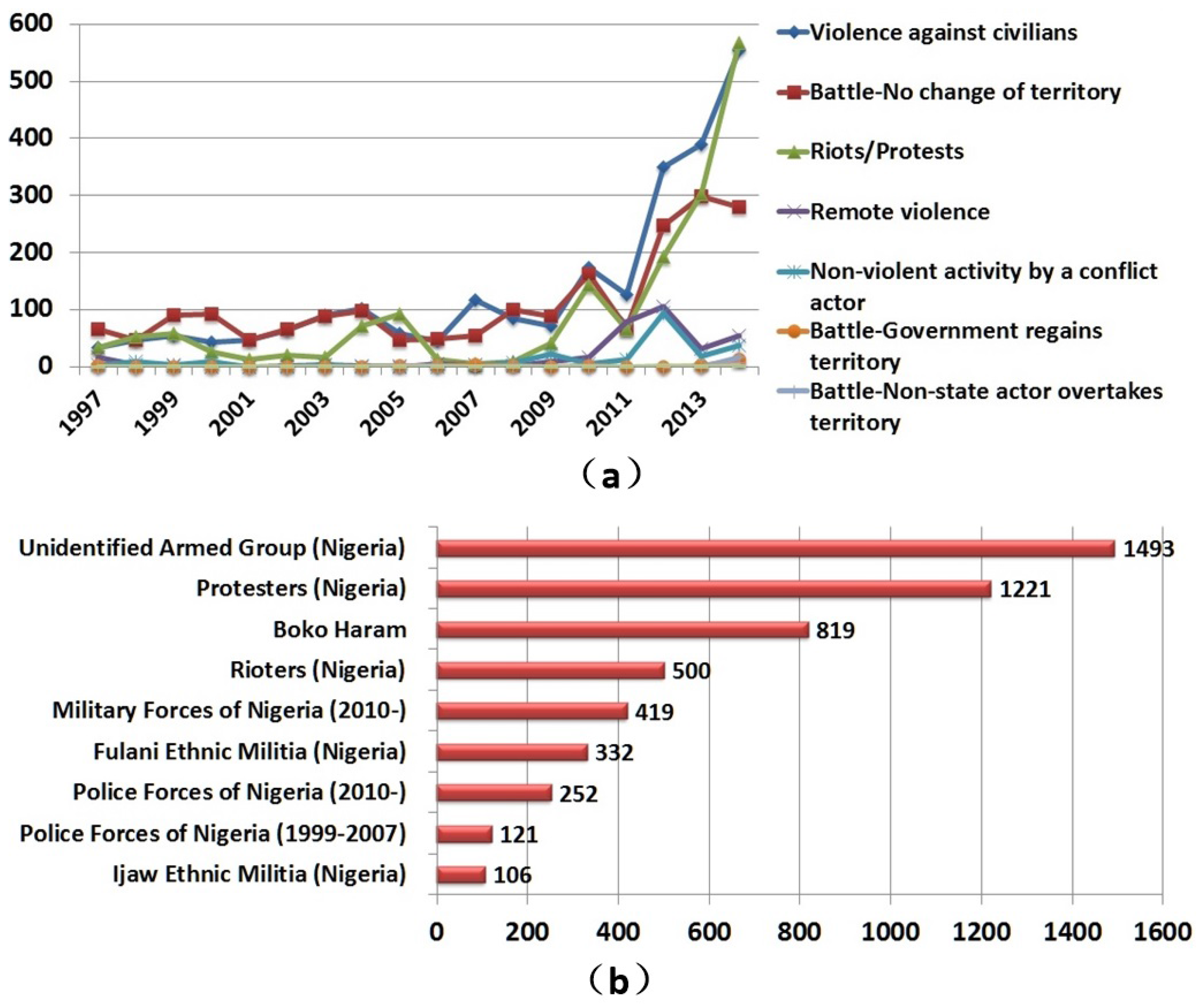
3. Data Sources
4. Methodology
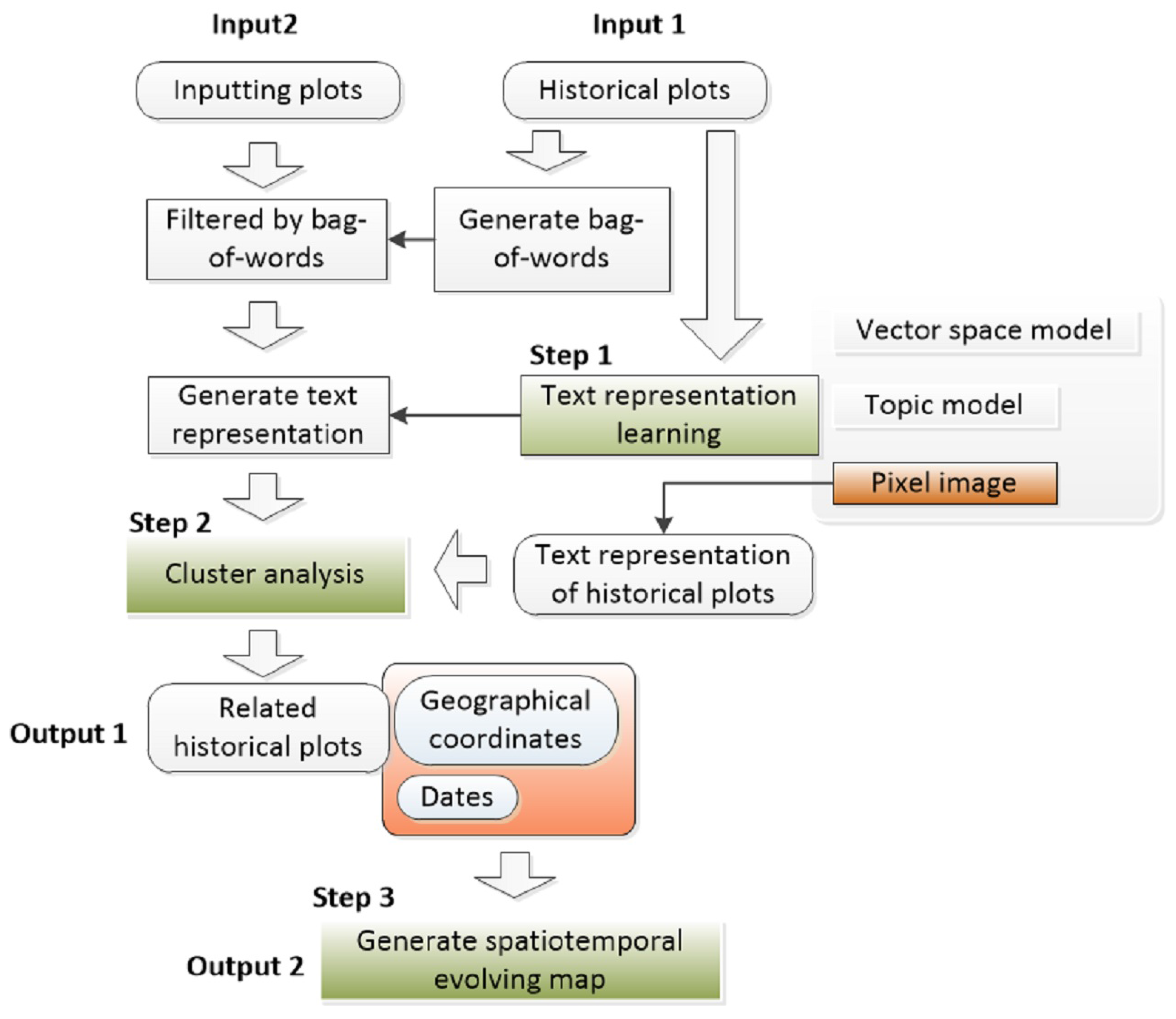
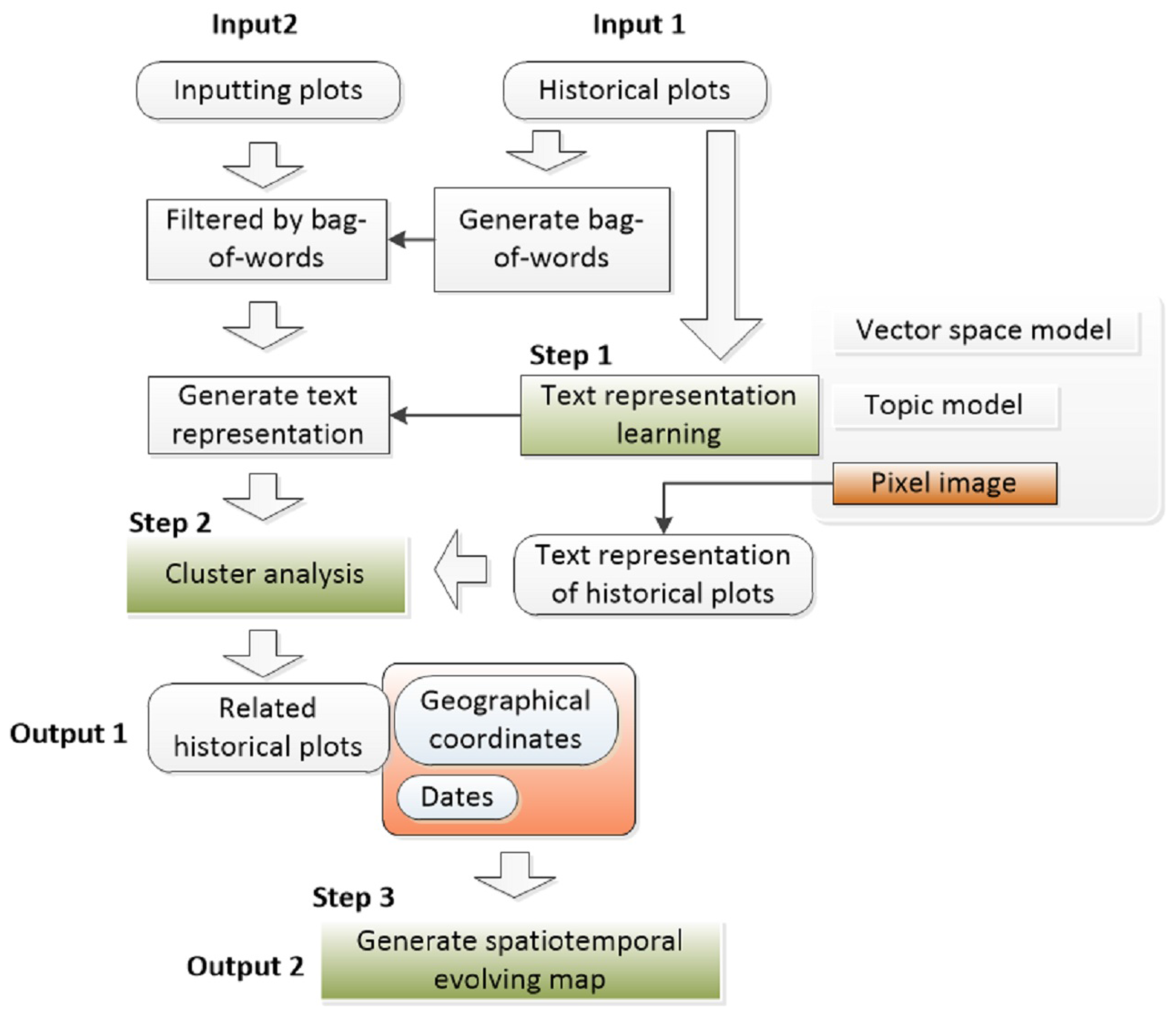
4.1. Processing Framework
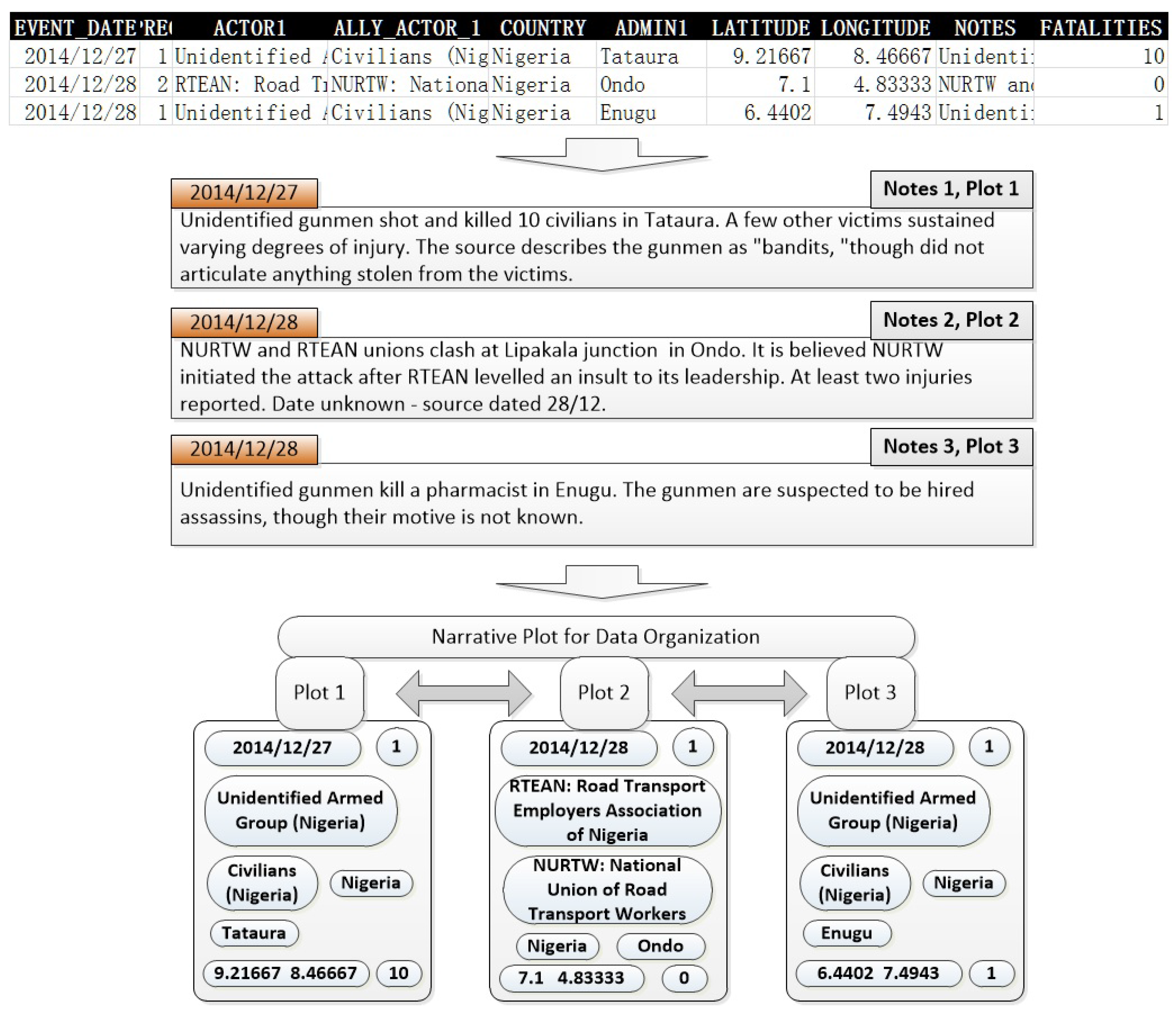
4.2. Event Text Representation
4.3. Cluster Analysis for Data Association
4.4. Evaluation Method
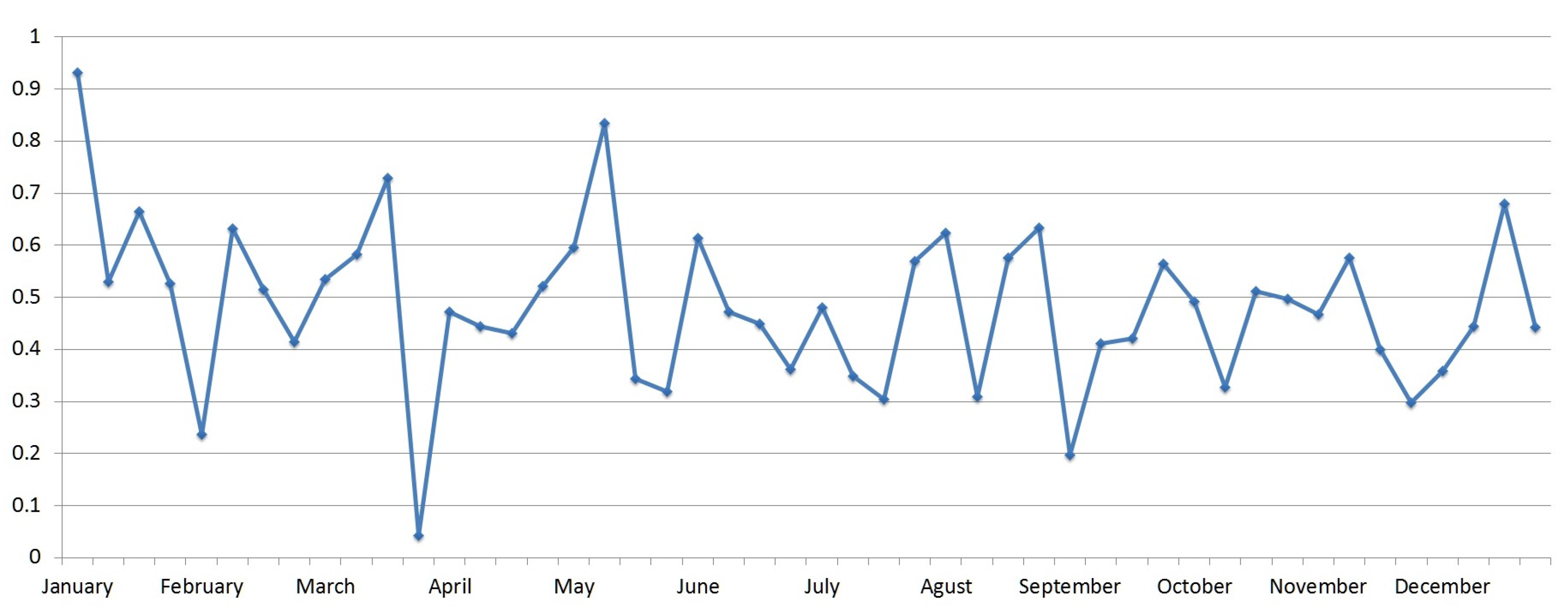
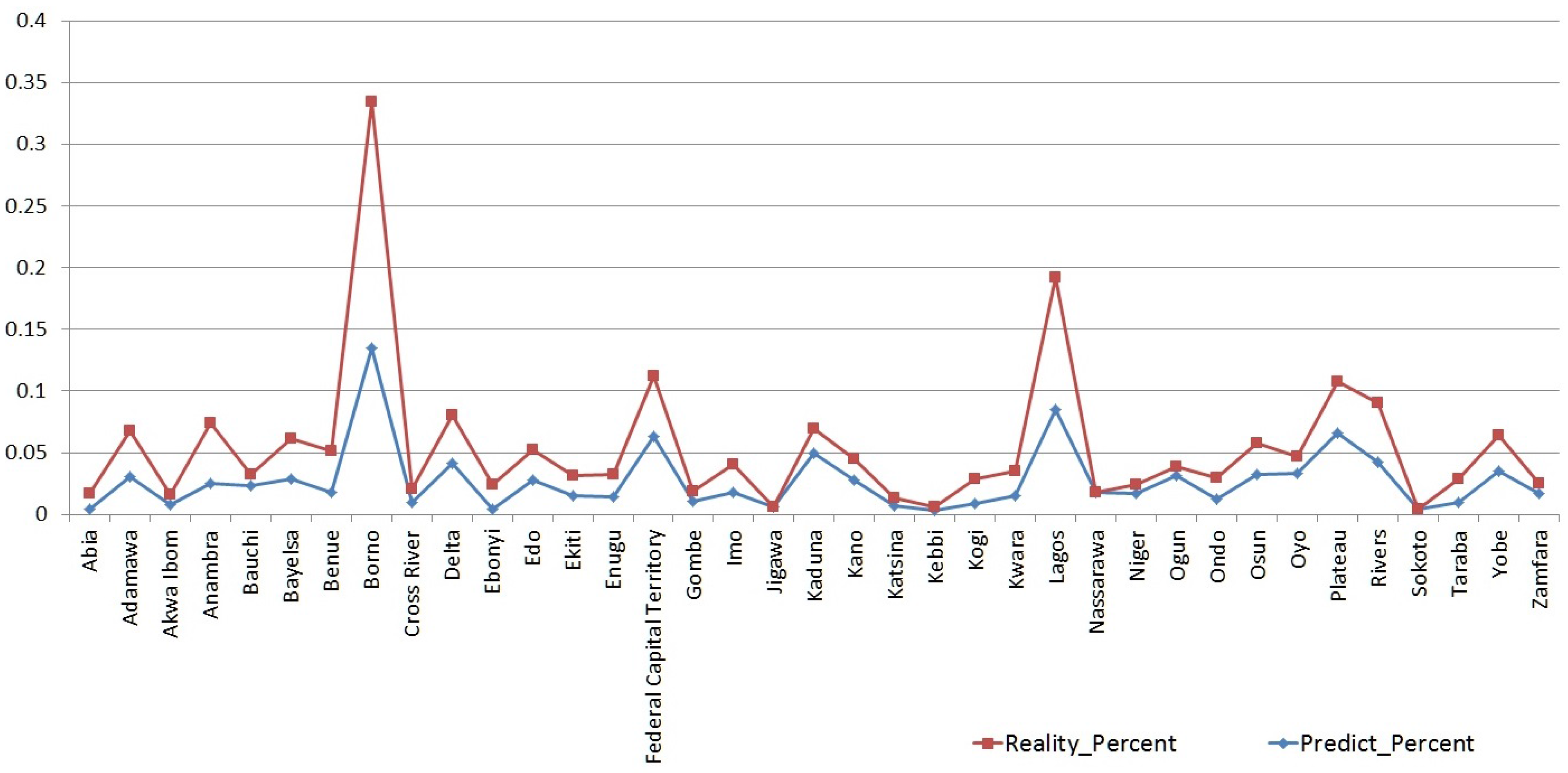
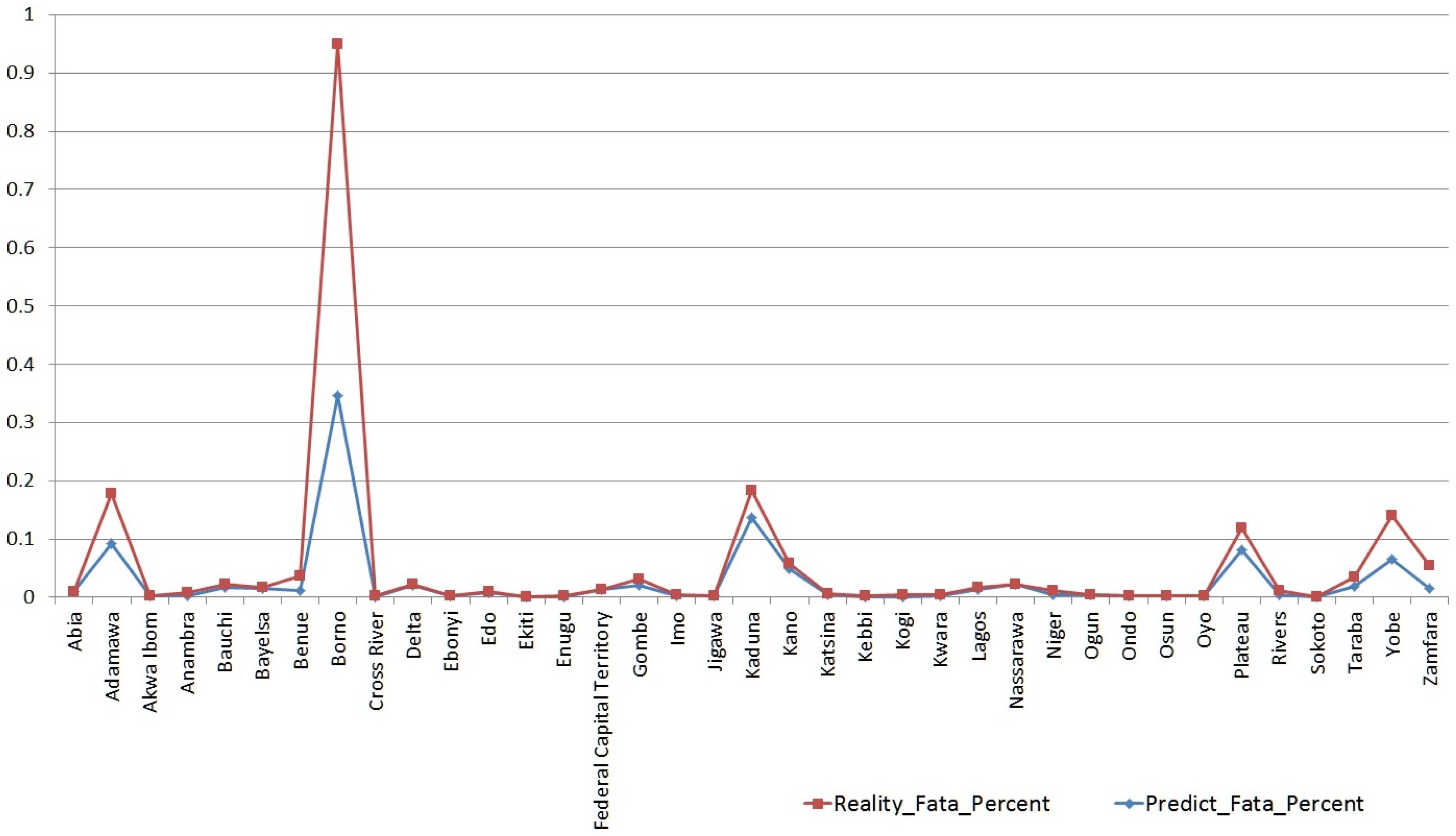
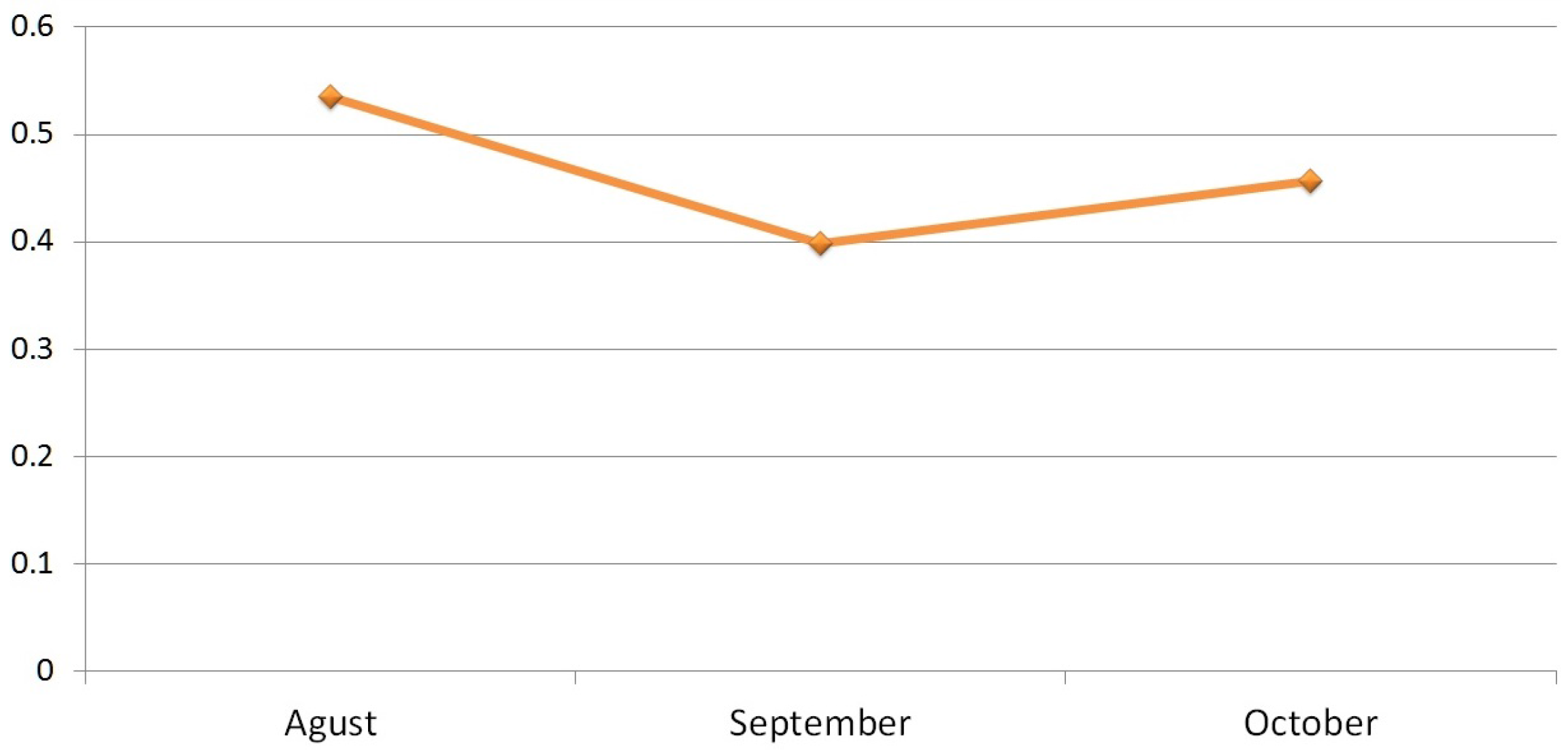
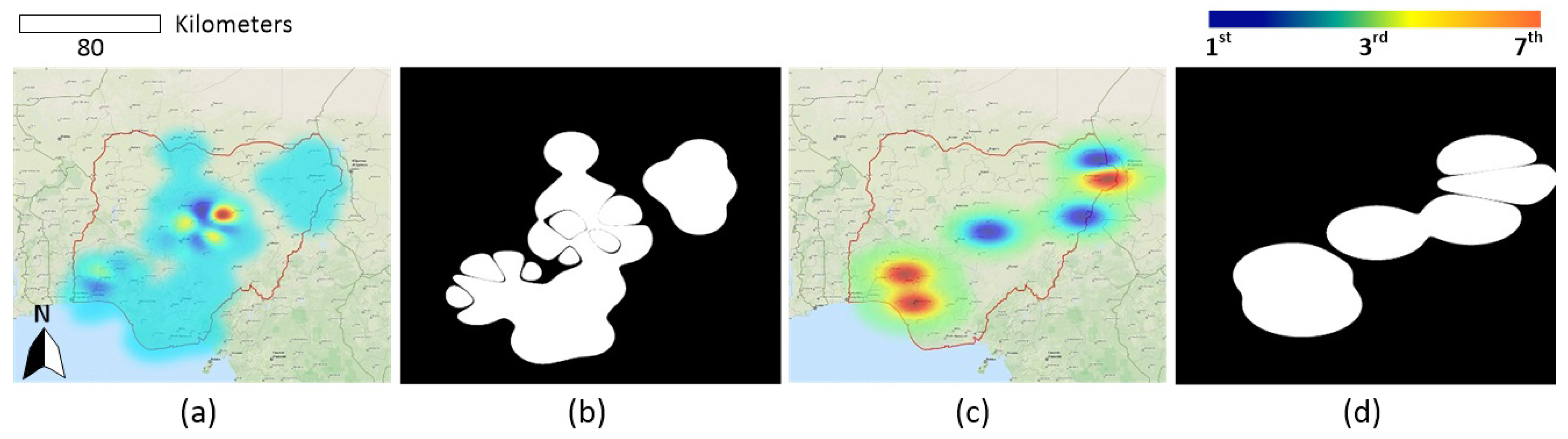
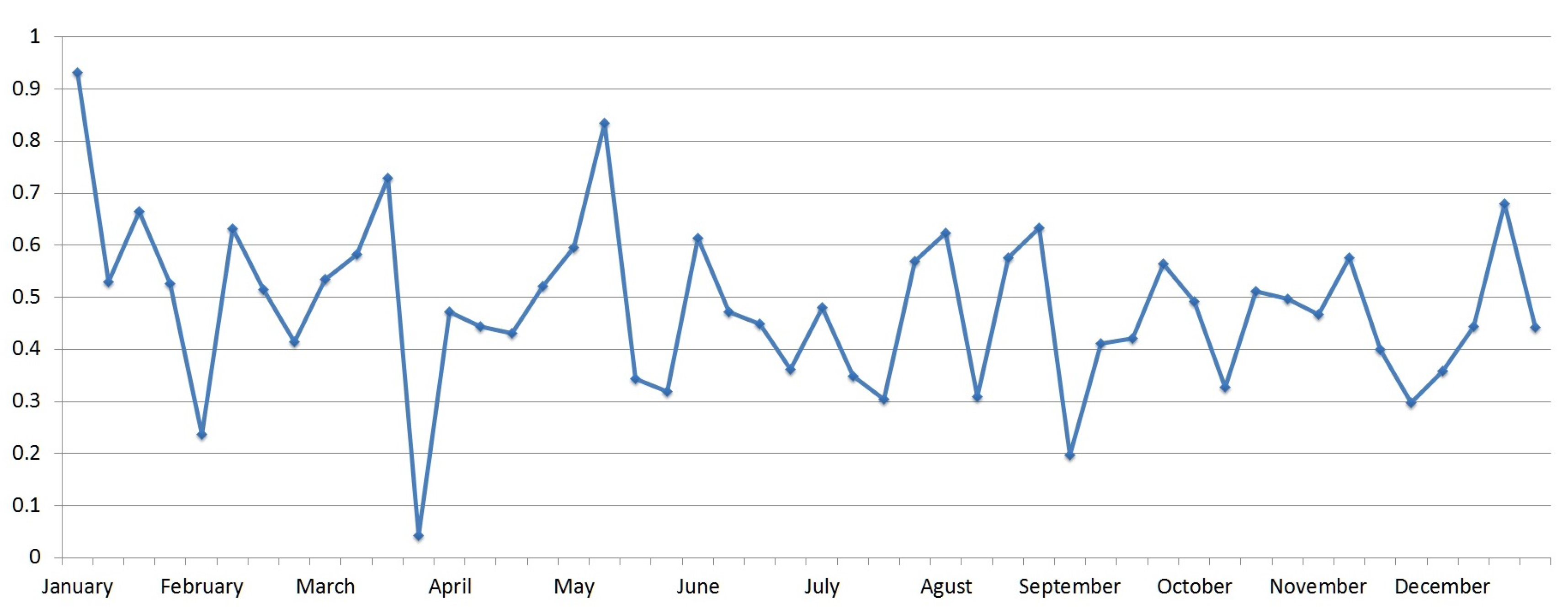
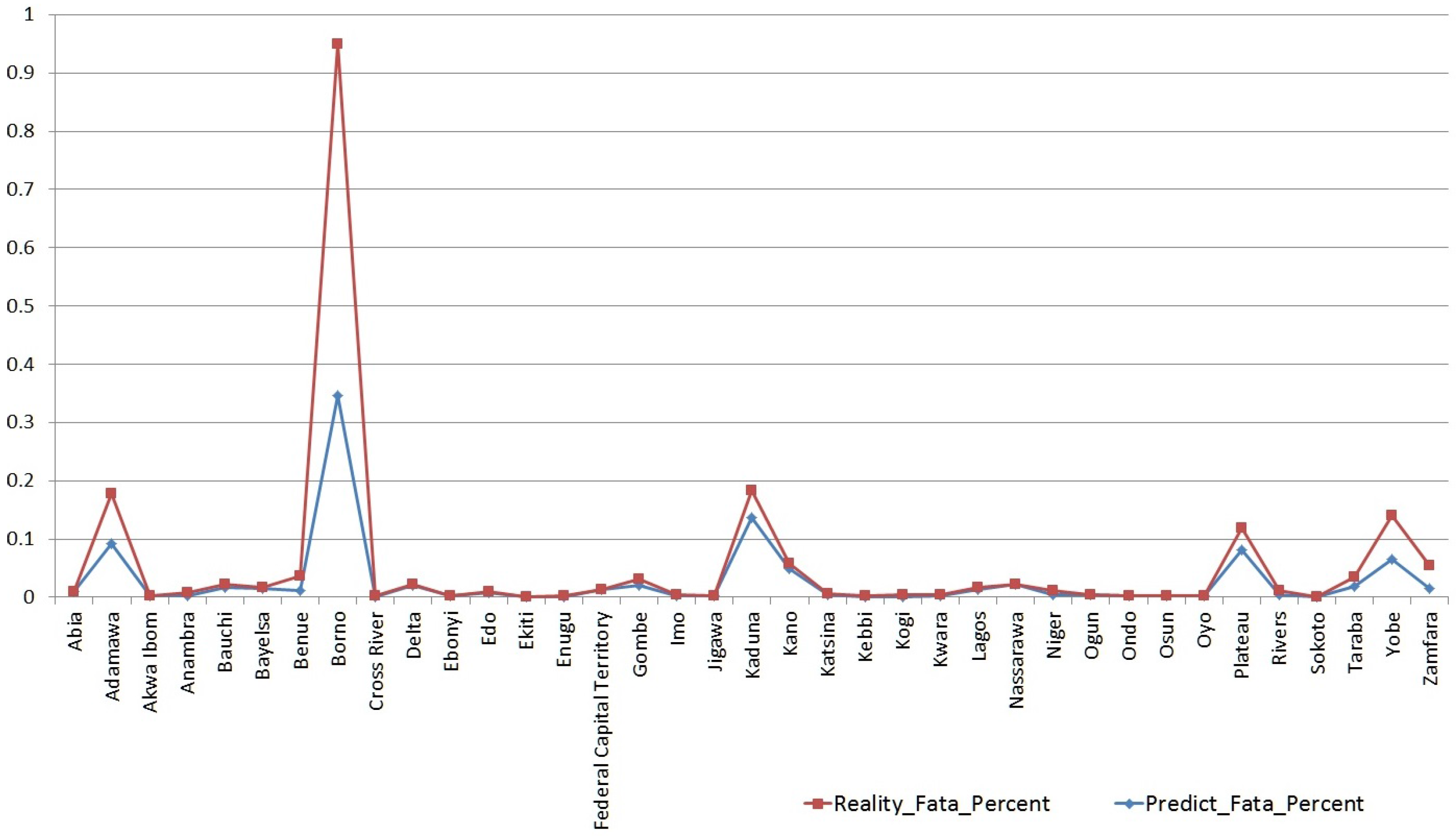
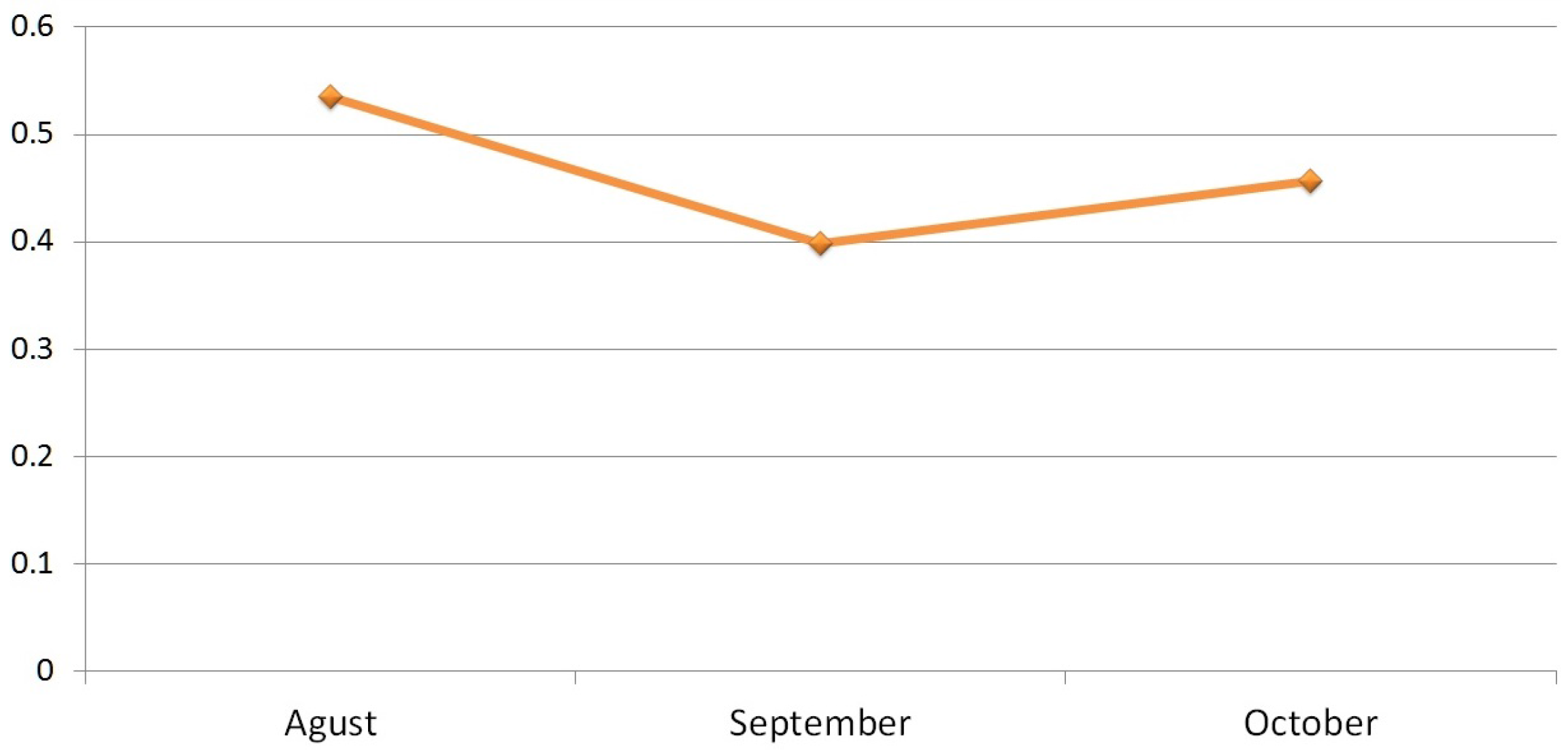
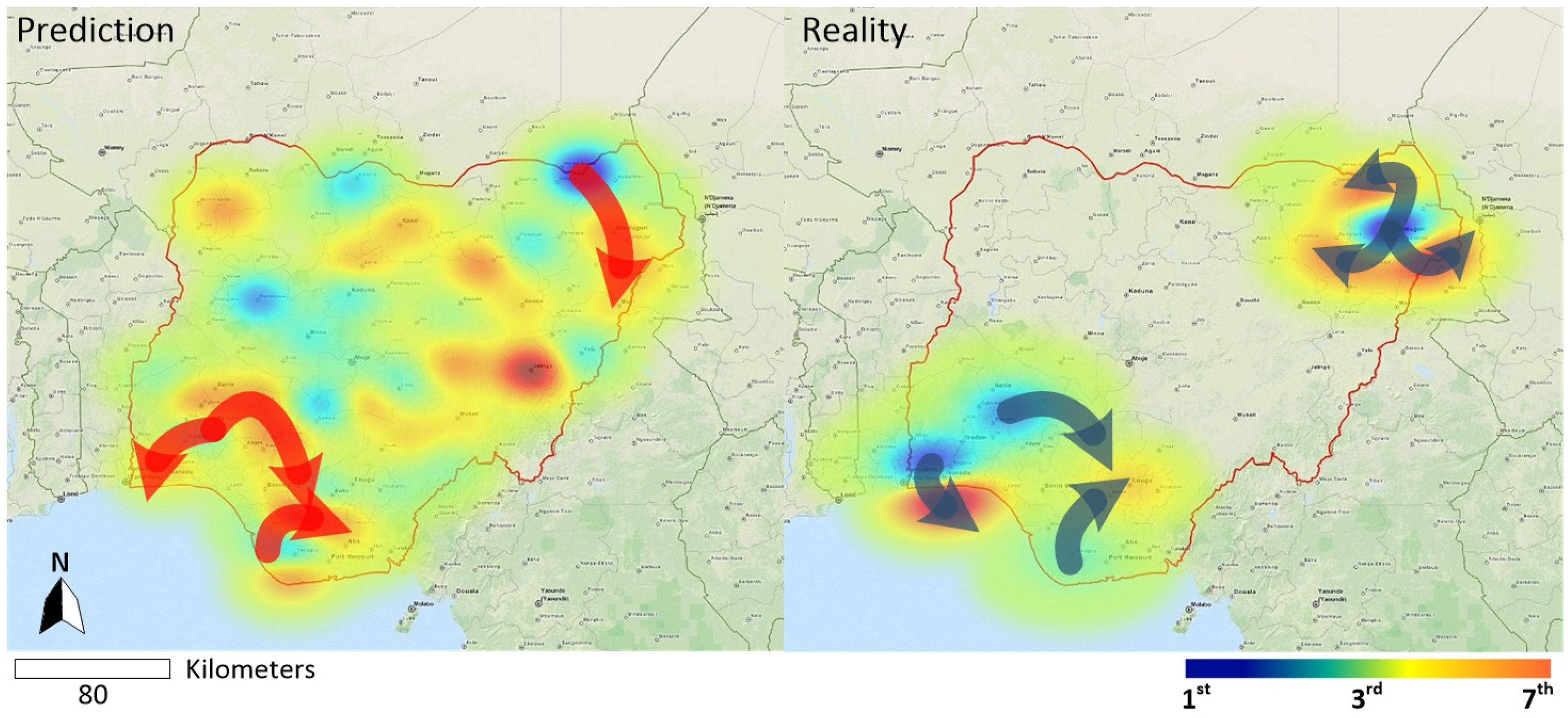
5. Results and Analysis
6. Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Owutu, I.U. Globalization and management of regional conflicts and security in Africa: The case of ECOWAS. Net J. Soc. Sci. 2014, 2, 37–43. [Google Scholar]
- Raleigh, C.; Dublin, T.C. Violence against civilians: A disaggregated analysis. Int. Interact. 2012, 38, 462–481. [Google Scholar] [CrossRef]
- Mundell, J. Africa Conflict Monthly Monitor; A Consultancy Africa Intelligence (CAI) Publication: Gauteng, South Africa, 2014. [Google Scholar]
- West Africa Monitor Quarterly Issue 3. Available online: http://www.afdb.org/fileadmin/uploads/afdb/Documents/Publications/Quarterly_West_Africa_Monitor_-_Issue_3.pdf (accessed on 13 February 2016).
- West Africa Monitor Quarterly Issue 4. Available online: http://www.afdb.org/fileadmin/uploads/afdb/Documents/Publications/Quarterly_West_Africa_Monitor_-_Issue_4.pdf (accessed on 13 February 2016).
- MacEachren, A. Spatio-Temporal Event Detection, Automated Event Detection Based on Document Content, Spatial, and Temporal Attributes. Available online: http://www.geovista.psu.edu/resources/flyers/NEVAC_Event_Detection.pdf (accessed on 13 February 2016).
- Sun, Y.; Han, J. Meta-path-based relationship prediction. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012.
- Raleigh, C. ACLED (Armed Conflict Location & Event Data Project). Available online: http://www.acleddata.com/data/ (accessed on 13 February 2016).
- Raleigh, C.; Dowd, C. ACLED Working Paper No. 9 Peacekeeping and Civilian Protection. ACLED (Armed Conflict Location & Event Data Project). Available online: http://www.acleddata.com/wp-content/uploads/2015/10/ACLED-Working-Paper-No.-9_Peacekeeping-and-Civilian-Protection_2015.pdf (accessed on 13 February 2016).
- Raleigh, C.; Kniveton, D. Come rain or shine: An analysis of conflict and climate variability in East Africa. J. Peace Res. 2012, 49, 51–64. [Google Scholar] [CrossRef]
- ACLED (Armed Conflict Location & Event Data Project). Unidentified Armed Groups. Available online: http://www.acleddata.com/wp-content/uploads/2012/07/ACLED_Unidentified-Armed-Groups-Working-Paper_July-2012.pdf (accessed on 11 February 2016).
- Raleigh, C.; Dowd, C.; Moody, J. ACLED Conflict Trends Report No. 40 August 2015. ACLED (Armed Conflict Location & Event Data Project). Available online: http://www.acleddata.com/wp-content/uploads/2015/08/ACLED_Conflict-Trends-Report-No.40-August-2015_pdf.pdf (accessed on 13 February 2016).
- Raleigh, C.; Dowd, C.; Moody, J. ACLED Conflict Trends Report No. 41 September 2015. ACLED (Armed Conflict Location & Event Data Project). Available online: http://www.acleddata.com/wp-content/uploads/2015/09/ACLED_Conflict-Trends-Report-No.41-September-2015_pdf.pdf (accessed on 13 February 2016).
- Raleigh, C.; Dowd, C.; Moody, J. ACLED Conflict Trends Report No. 42 October 2015. ACLED (Armed Conflict Location & Event Data Project). Available online: http://www.acleddata.com/wp-content/uploads/2015/10/ACLED_Conflict-Trends-Report-No.42-October-2015_pdf.pdf (accessed on 13 February 2016).
- ACLED (Armed Conflict Location & Event Data Project). Available online: http://www.acleddata.com/visuals/trends/ (accessed on 13 February 2016).
- Clionadh, R.; Choi, H.J.; Kniveton, D. The devil is in the details: An investigation of the relationships between conflict, food price and climate across Africa. Global Environmental Change. Glob. Environ. Chang. 2015, 32, 187–199. [Google Scholar]
- Bhatt, M.; Wallgrun, J.O. Geospatial Narratives and Their Spatio-Temporal Dynamics: Commonsense Reasoning for High-Level Analyses in Geographic Information Systems. ISPRS Int. J. Geo-Inf. 2014, 3, 166–205. [Google Scholar] [CrossRef]
- Damiano, R.; Lieto, A. Ontological representations of narratives: A case study on stories and actions. In Proceedings of the Workshop on Computational Models of Narrative 2013, Hamburg, Germany, 4–6 August 2013.
- Elson, D.K. Detecting story analogies from annotations of time, action and agency. In Proceedings of the Third Workshop on Computational Models of Narrative, Istanbul, Turkey, 26–27 May 2012.
- Vlek, C.S.; Prakken, H.; Renooij, S.; Verheij, B. Representing and evaluating legal narratives with subscenarios in a Bayesian network. In Proceedings of the Workshop on Computational Models of Narrative 2013, Hamburg, Germany, 4–6 August 2013.
- ACLED (Armed Conflict Location & Event Data Project). Annex 2—Separating AFRC/RUF Violence in the NPWJ Conflict Mapping Report. Available online: http://www.acleddata.com/wp-content/uploads/2015/01/SLL-Appendix_Specific-Notes-on-seperation-AFRC-RUF-Violence.pdf (accessed on 11 February 2016).
- ACLED (Armed Conflict Location & Event Data Project). Annex 1—Codebook for NPWJ Conflict Mapping Report. Available online: http://www.acleddata.com/wp-content/uploads/2015/02/Annex-1_Codebook_Main.pdf (accessed on 11 February 2016).
- Ralph, S.; Lindgren, M.; Padskocimaite, A. UCDP Georeferenced Event Dataset(GED) Codebook Version 1.5. Available online: http://www.ucdp.uu.se/ged/data/ucdp-ged-points-v-1-5-codebook.pdf (accessed on 13 February 2016).
- Zammit Mangion, A.; Sanguinetti, G.; Kadirkamanathan, V. Variational estimation in spatiotemporal systems from continuous and point-process observations. IEEE Signal. Process. 2012, 60, 3449–3459. [Google Scholar] [CrossRef]
- Schutte, S.; Weidmann, N.B. Diffusion patterns of violence in civil wars. Polit. Geogr. 2011, 30, 143–152. [Google Scholar] [CrossRef]
- Zhukov, Y.M. Roads and the diffusion of insurgent violence: The logistics of conflict in Russia’s North Caucasus. Polit. Geogr. 2012, 31, 144–156. [Google Scholar] [CrossRef]
- Zammit-Mangion, A.; Dewar, M.; Kadirkamanathan, V.; Sanguinetti, G. Point process modelling of the Afghan War Diary. Proc. Natl. Acad. Sci. USA 2012, 109, 12414–12419. [Google Scholar] [CrossRef] [PubMed]
- Tran, C.C.; Yost, R.S.; Yanagida, J.F.; Saksena, S.; Fox, J.; Sultana, N. Spatio-temporal occurrence modeling of highly pathogenic avian influenza subtype H5N1: A case study in the Red River Delta, Vietnam. ISPRS Int. J. Geo-Inf. 2013, 2, 1106–1121. [Google Scholar] [CrossRef]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Li, L.; Goodchild, M.F. The role of social networks in emergency management: A research agenda. Int. J. Inf. Syst. Crisis Response Manag. 2010, 2, 49–59. [Google Scholar] [CrossRef]
- Perumal, M.; Velumani, B.; Sadhasivam, A.; Ramaswamy, K. Spatial data mining approaches for GIS—A brief review. Adv. Intell. Syst. Comput. 2015, 2, 579–592. [Google Scholar]
- Shi, X.; Ayotte, J.D.; Onda, A.; Miller, S.; Rees, J.; Gilbert-Diamond, D.; Onega, T.; Gui, J.; Karagas, M.; Moeschler, J. Geospatial association between adverse birth outcomes and arsenic in groundwater in New Hampshire, USA. Environ. Geochem. Health 2015, 37, 333–351. [Google Scholar] [CrossRef] [PubMed]
- Carlson, J.A.; Saelens, B.E.; Kerr, J.; Schipperijn, J.; Conway, T.L.; Frank, L.D.; Chapman, J.E.; Glanz, K.; Cain, K.L.; Sallis, J.F. Association between neighborhood walkability and GPS-measured walking, bicycling and vehicle time in adolescents. Health Place 2015, 32, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Luong, N.V.; Tateishi, R.; Hoan, N.T. Analysis of an Impact of Successionin Mangrove Forest Association Using Remote Sensing and GIS Technology. J. Geogr. Geol. 2015, 7, 106–116. [Google Scholar]
- Mei, Z.; Xu, S.; Ouyang, J. Spatio-temporal association analysis of county potential in the Pearl River Delta during 1990 C2009. J. Geogr. Sci. 2015, 25, 319–336. [Google Scholar] [CrossRef]
- Li, D.; Deogun, J.; Harms, S. Interpolation techniques for geo-spatial association rule mining. In Proceedings of the 9th International Conference, RSFDGrC 2003, Chongqing, China, 26–29 May 2003; pp. 573–580.
- Qin, S.; Liu, F.; Wang, C.; Song, Y.; Qu, J. Spatial-temporal analysis and projection of extreme particulate matter (PM10 and PM2.5) levels using association rules: A case study of the Jing-Jin-Ji region, China. Atmos. Environ. 2015, 120, 339–350. [Google Scholar] [CrossRef]
- Chen, A.T.; Yoon, A.; Shaw, R. People, Places and Emotions: Visually Representing Historical Context in Oral Testimonies. In Proceedings of the Third Workshop on Computational Models of Narrative, Istanbul, Turkey, 26–27 May 2012.
- Broadwell, P.M.; Tangherlini, T.R. TrollFinder: Geo-semantic exploration of a very large corpus of Danish folklore. In Proceedings of the Third Workshop on Computational Models of Narrative, Istanbul, Turkey, 26–27 May 2012.
- Batal, I.; Fradkin, D.; Harrison, J.; Moerchen, F.; Hauskrecht, M. Mining recent temporal patterns for event detection in multivariate time series data. In Proceedings of the 18th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012.
- Matsubara, Y.; Sakurai, Y.; Faloutsos, C.; Iwata, T.; Yoshikawa, M. Fast mining and forecasting of complex time-stamped events. In Proceedings of the 18th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012.
- Han, B.; Baldwin, T. Lexical normalisation of short text messages: Makn sens a twitter. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, USA, 19–24 June 2011.
- Hua, W.; Wang, Z.; Wang, H.; Zheng, K.; Zhou, X. Short text understanding through lexical-semantic analysis. In Proceedings of the 2015 IEEE 31st International, Seoul, Korea, 13–17 April 2015; pp. 495–506.
- Yin, J.; Wang, J. A dirichlet multinomial mixture model-based approach for short text clustering. In Proceedings of the 20th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014.
- Song, Y.; Roth, D. Unsupervised Sparse Vector Densification for Short Text Similarity. NAACL 2015. Available online: http://aclweb.org/anthology/N/N15/N15-1138.pdf (accessed on 13 February 2016).
- Yan, X.; Guo, J.; Lan, Y.; Cheng, X. A biterm topic model for short texts. In Proceedings of the International World Wide Web Conference, Rio de Janeiro, Brazil, 13–17 May 2013.
- OpenStreetMap. Available online: http://www.openstreetmap.org/#map=5/44.277/10.942 (accessed on 13 February 2016).
- Steyvers, M.; Shiffrin, R.M.; Nelson, D.L. Semantic Spaces based on Free Association that Predict Memory Performance. Available online: http://lsa.colorado.edu/LexicalSemantics/SteyversShiffrinNelson.pdf (accessed on 14 February 2016).
- Borg, I.; Groenen, P.J.F. Modern Multidimensional Scaling, Theory and Applications; Springer: Berlin, Germany, 2005. [Google Scholar]
- Christian, B.; Fiedler, F.; Oswald, A.; Plant, C.; Bianca, W.; Peter, W. ITCH: Information-theoretic cluster hierarchies. In Proceedings of the Conference: Machine Learning and Knowledge Discovery in Databases, Barcelona, Spain, 20–24 September 2010.
- Taha, Y.; Robert, S.; Rung, A.; Kornai, A. Dynamics of conflicts in wikipedia. PLoS ONE 2012, 7. [Google Scholar] [CrossRef] [Green Version]
- Lophaven, S.N.; Nielsen, H.B. A MATLAB Kriging Toolbox Version 2.0, August 1, 2002. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.73.5824 (accessed on 14 February 2016).
- Quinonerocandela, J.; Edwardrasmussen, C. A unifying view of sparse approximate Gaussian process regression. J. Mach. Learn. Res. 2005, 6, 1935–1959. [Google Scholar]







© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bi, S.; Han, X.; Tian, J.; Liang, X.; Wang, Y.; Huang, T. Data Association at the Level of Narrative Plots to Support Analysis of Spatiotemporal Evolvement of Conflict: A Case Study in Nigeria. ISPRS Int. J. Geo-Inf. 2016, 5, 188. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5100188
Bi S, Han X, Tian J, Liang X, Wang Y, Huang T. Data Association at the Level of Narrative Plots to Support Analysis of Spatiotemporal Evolvement of Conflict: A Case Study in Nigeria. ISPRS International Journal of Geo-Information. 2016; 5(10):188. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5100188
Chicago/Turabian StyleBi, Size, Xiaoyu Han, Jing Tian, Xiao Liang, Yang Wang, and Tinglei Huang. 2016. "Data Association at the Level of Narrative Plots to Support Analysis of Spatiotemporal Evolvement of Conflict: A Case Study in Nigeria" ISPRS International Journal of Geo-Information 5, no. 10: 188. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi5100188