1. Introduction
Up to date land cover and land use (LCLU) statistics are paramount for policy and decision making and, thus, impact largely on economy and society. For example, LCLU patterns and their change influence the climate [
1,
2] and concerns on the consequences of climate change are driving high-level international policy, including the establishment of international commitments such as the Paris Climate Agreement [
3]. However, the production of LCLU statistics becomes increasingly challenging when cross-border regions, such as political or geographical units formed by autonomous states, are involved, which commonly use their own means and criteria for statistics production. Comparability and assembly of national statistics for wider scales are thus commonly compromised.
Efforts have been made to produce harmonized LCLU statistics across countries. In Europe, for example, national and international authorities have formed a partnership, the European Statistical System (ESS), for the development, production, and dissemination of comparable statistics at the European Union level. The ESS functions as a network in which the European Union authority for statistics, Eurostat, in close cooperation with national statistical authorities, leads the way in the harmonization of statistics.
International cooperation can respond to the difficulty in producing coherent statistics across states. For example, surveys for LCLU statistics are commonly used at various national levels. This is the case of the Land Use and Coverage Area frame Survey (LUCAS), promoted by Eurostat with the objective of identifying LCLU change in the European Union (EU). LUCAS takes place every three years and implements a combined approach of field observations and photo-interpretation assigned to field points. LUCAS surveys are carried out in situ in which a subset of the >1 million points defined by a 2 × 2 km
2 grid covering the European Union is visited on the ground [
4].
Point-based samples periodically visited in situ and other methods commonly applied for producing statistics, such as questionnaires, provide valuable information. However, there are some limitations, notably the non-exhaustive geographical nature of sampling and the relatively long time of revisit. Thus, the information produced has gaps in space and time, which can be small or great depending on the sampling effort and periodicity. Increasing sample size and periodicity increases the costs to possibly unaffordable levels.
An alternative means of obtaining information on LCLU is mapping. Specifically, mapping from remote sensing has been used to produce information about the Earth’s surface and can inform on the areal extent of LCLU across large areas, up to the entire globe. Dozens of LCLU maps have been produced at global and continental scales [
5]. Despite the value of these maps—some of them represent milestones in remote sensing—their use is limited mostly because they have been produced independently and for specific points in time and, thus, lack coherency and continuity [
5,
6].
Efforts have been made for harmonized LCLU mapping. For example, the CORINE Land Cover (CLC) series of maps is a harmonized representation of the LCLU of most of Europe for the reference years of 1990, 2000, 2006, and 2012 [
7]. CLC is partly produced by each individual country and, in most cases, by visual interpretation of remotely sensed data. CLC is coordinated by the European Environmental Agency and all countries follow common guidelines to ensure comparability and coherency between the national maps, which are assembled to produce pan-European products. In North America, harmonized mapping has been undertaken based on semi-automatic methods under a collaboration between Canada, Mexico, and the United States. This collaboration, called the North American Land Change Monitoring System (NALCMS), has used national land cover mapping efforts to assemble continental land cover and change maps for 2005 and 2010 [
8,
9,
10].
Harmonized cross-border mapping affords great benefits but comes with challenges. The mapping area is typically large, thus requiring vast volumes of data and resources. Research has addressed these challenges and today there is a large body of digital methods for the detection and classification of changes in LCLU from remotely sensed data [
9,
11,
12,
13,
14,
15,
16,
17,
18]. Mapping is, however, typically performed on a low-frequency basis (e.g., every five or more years [
9,
10,
15]) and for general use. In some cases, however, users have requirements that are not compatible with available LCLU maps, such as specific minimum mapping unit and time reference. Moreover, when maps are produced to estimate the area of land cover, additional methods are needed to translate the mapped areal extent of the classes to statistics, which should include estimates and uncertainty measures for a specific confidence level. Estimators have been derived for area estimation based on mapping [
19,
20] but they are underused and are little explored.
Under the scope of the European Statistical System’s (ESS’s) objectives and mission, a project funded by Eurostat, LUCAS Grant 2015, has been developed to produce harmonized, quality-assured LCLU information according to a predefined classification and with a given precision (the third level of the EU Nomenclature of Territorial Units for Statistics—NUTS). LUCAS Grant 2015 accommodates the feasibility of future updates based on a national integrated approach to produce LCLU information to comply with the ESS medium-term strategy for LCLU statistics. Another main goal of LUCAS Grant 2015 is to accomplish a general framework for LCLU mapping and statistics production across Europe based on spatial databases that can provide exhaustive spatial coverage and frequent updating.
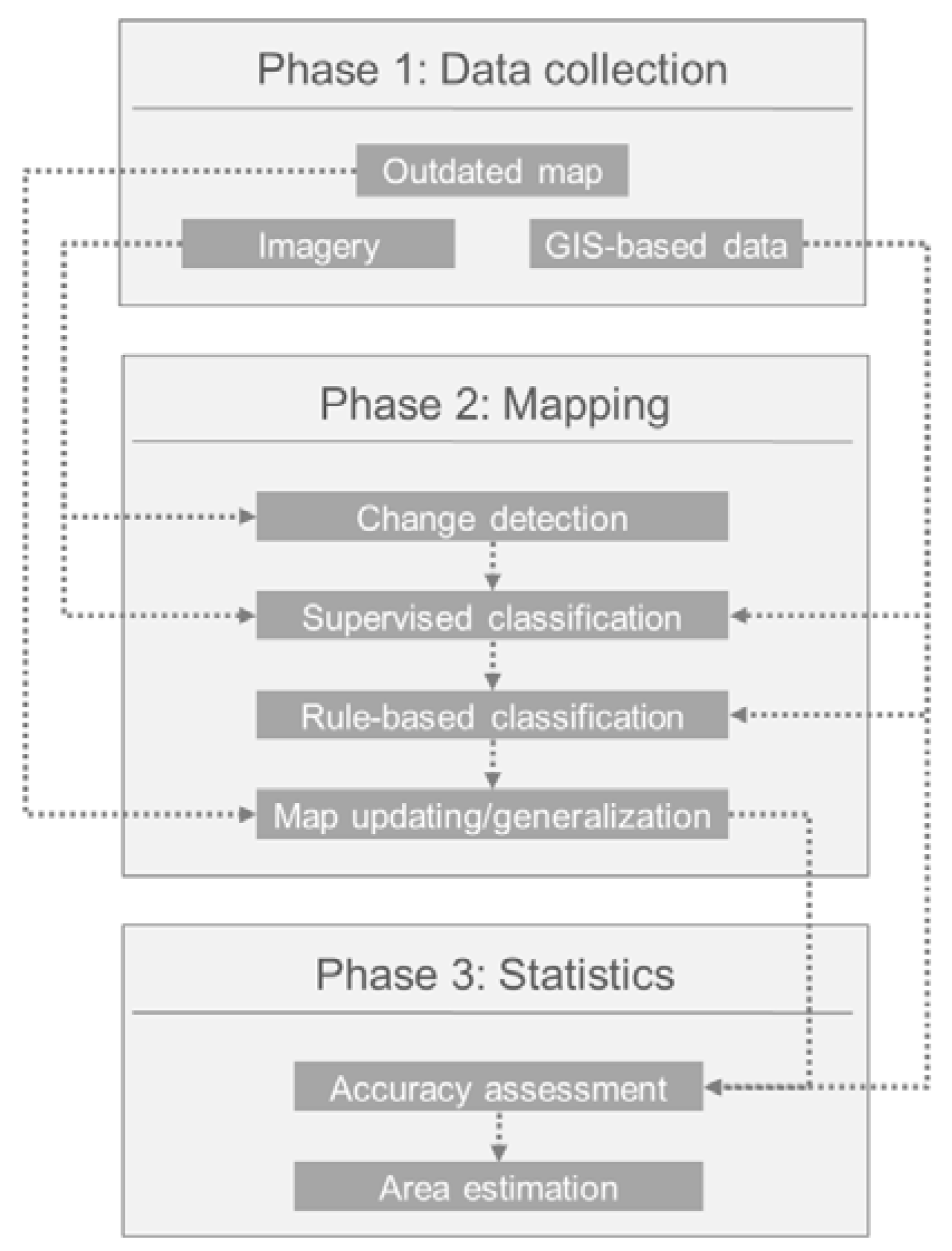
This paper presents and discusses the framework designed under the scope of LUCAS Grant 2015, centered on the production of land cover statistics for continental Portugal for a period of six years (2010–2015). The framework was designed to combine digital classification of remotely sensed data and available national geographical data sets and official statistics to estimate total areas of land cover classes. The methodology proposed in this paper can be applied elsewhere since it is grounded on the use of data under free access policy, following the EU Directive Infrastructure for Spatial Information in Europe (INSPIRE), at the same time that it is harmonized with data acquisition and dissemination procedures of the ESS. The results stress the potential of the general framework for continuous land cover statistics production, but difficulties and bottlenecks were found spanning mapping, accuracy assessment, and area estimation.
2. Study Area
Analyses focused on the continental territory of Portugal, which is located in the western extreme of the Iberian Peninsula, Europe (
Figure 1). The area of continental Portugal is approximately 89,100 km
2 and includes a diversity of natural conditions spanning generally a north–south gradient but also west–east due to the presence of the Atlantic Ocean in the west. Mediterranean and temperate climatic influences are found in the country and relatively hot and dry summers follow cold and wet winters. Mild weather conditions are typically found near the seaside, while rainy and dry weather characterize the north and south, respectively. Main settlements are located along the coastline, interwoven with low-density developed land. The Mediterranean bio-geographic region favors a great variety of landscapes displayed as a mosaic of forest, intensive agriculture, and wetlands associated with the major river mouths. Forests of eucalyptus targeted for production can be broadly found with native species of pines, scrublands, and fine-grained complex agricultural practices dominating large areas of the northern and hilly countryside; the typical Mediterranean silvopastoral system of oak stands concentrate in the southern peneplain. Both cases are punctuated by other land cover types, such as sprawling population centers and water reservoirs.
Land cover was defined based on the classification system of LUCAS, which has eight main categories: artificial land, cropland, woodland, shrubland, grassland, bareland, water, and wetland. These main categories are divided into 15 classes (
Table 1) according to the hierarchical disaggregation of the classes of LUCAS and additional definitions of the Eurostat Annual Crop Statistics (ACS), Food and Agriculture Organization (FAO) of the United Nations, and INSPIRE Directive.
4. Results
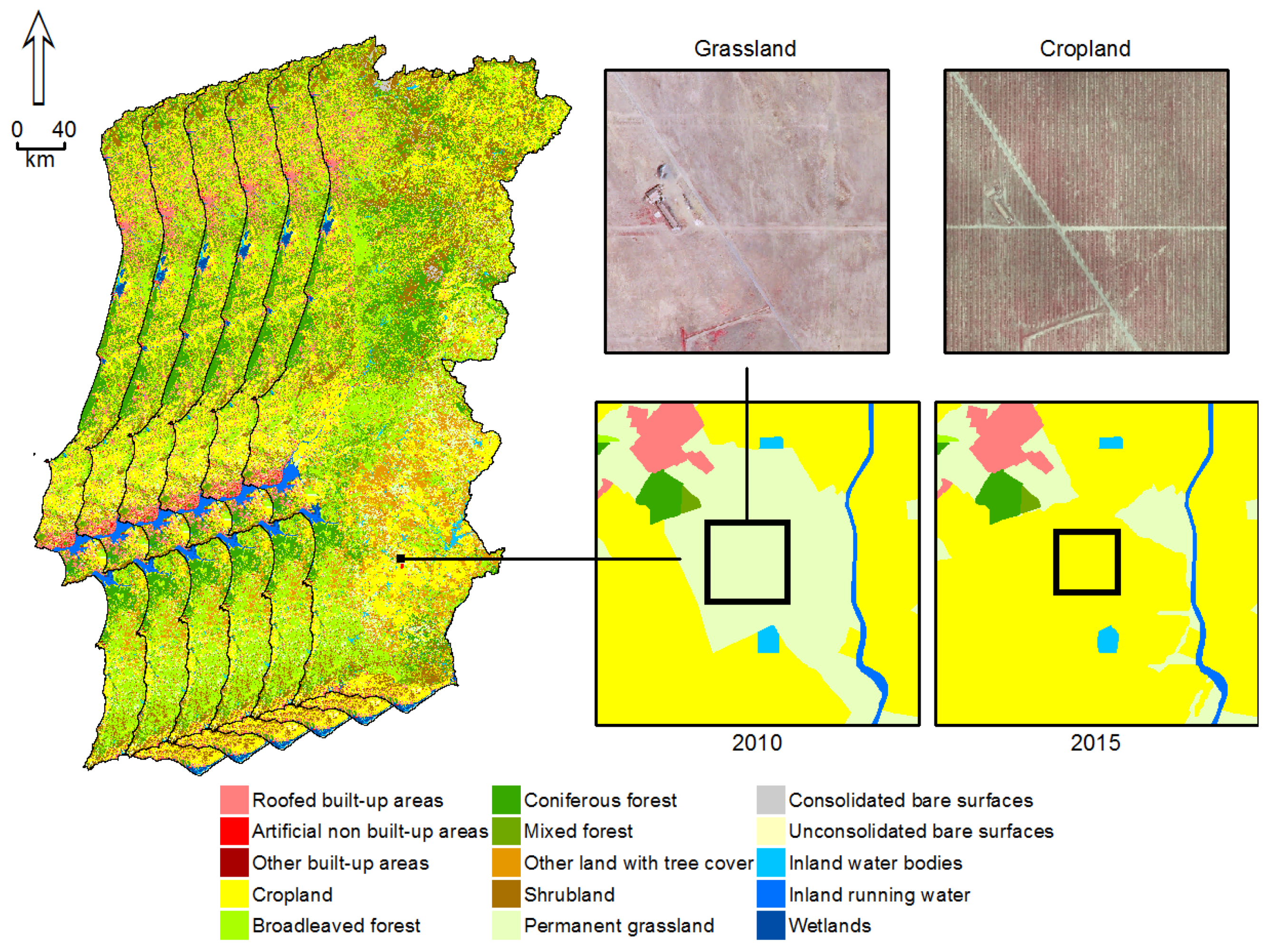
A land cover map was produced for 2010 (
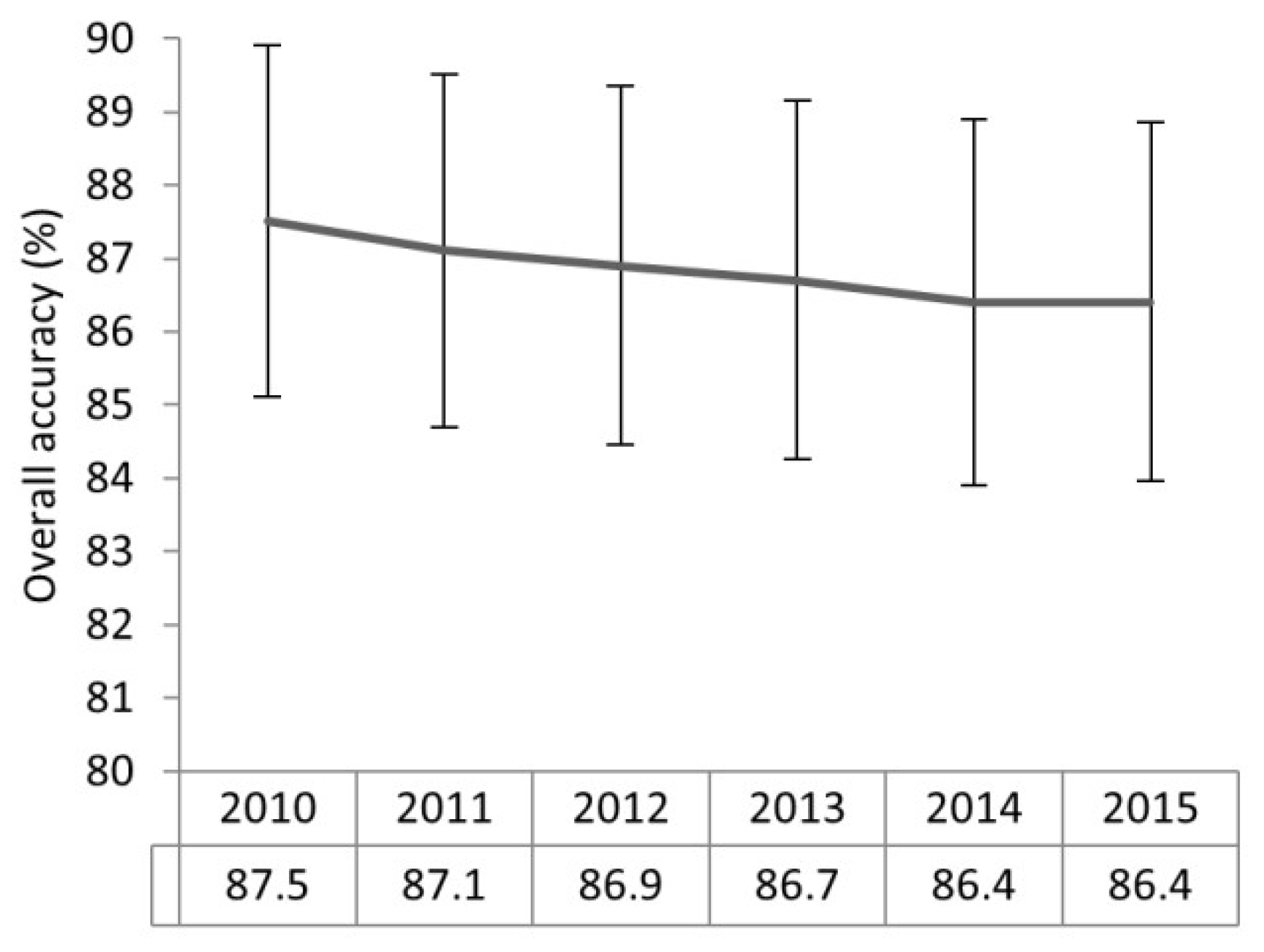
Figure 3) where cropland, woodland, shrubland, and grassland form approximately 92% of the mapped area. Artificial land, bareland, water, and wetlands are minority classes. The estimated overall accuracy of the 2010 map is 87.5%. This result is closely related to COS2010, as this official map was the basis for the map production.
Land cover is generally stable over time and, thus, similar maps were produced for the following years (
Figure 3).
Table 7 shows the area of each map that changed as compared to the precedent year’s map while
Figure 3 shows an example of grassland converted to cropland. The estimated thematic accuracy of these maps is similar to that of 2010 but slightly smaller and follows a decreasing trend (
Figure 4). The differences between the accuracy of the maps are not statistically significant.
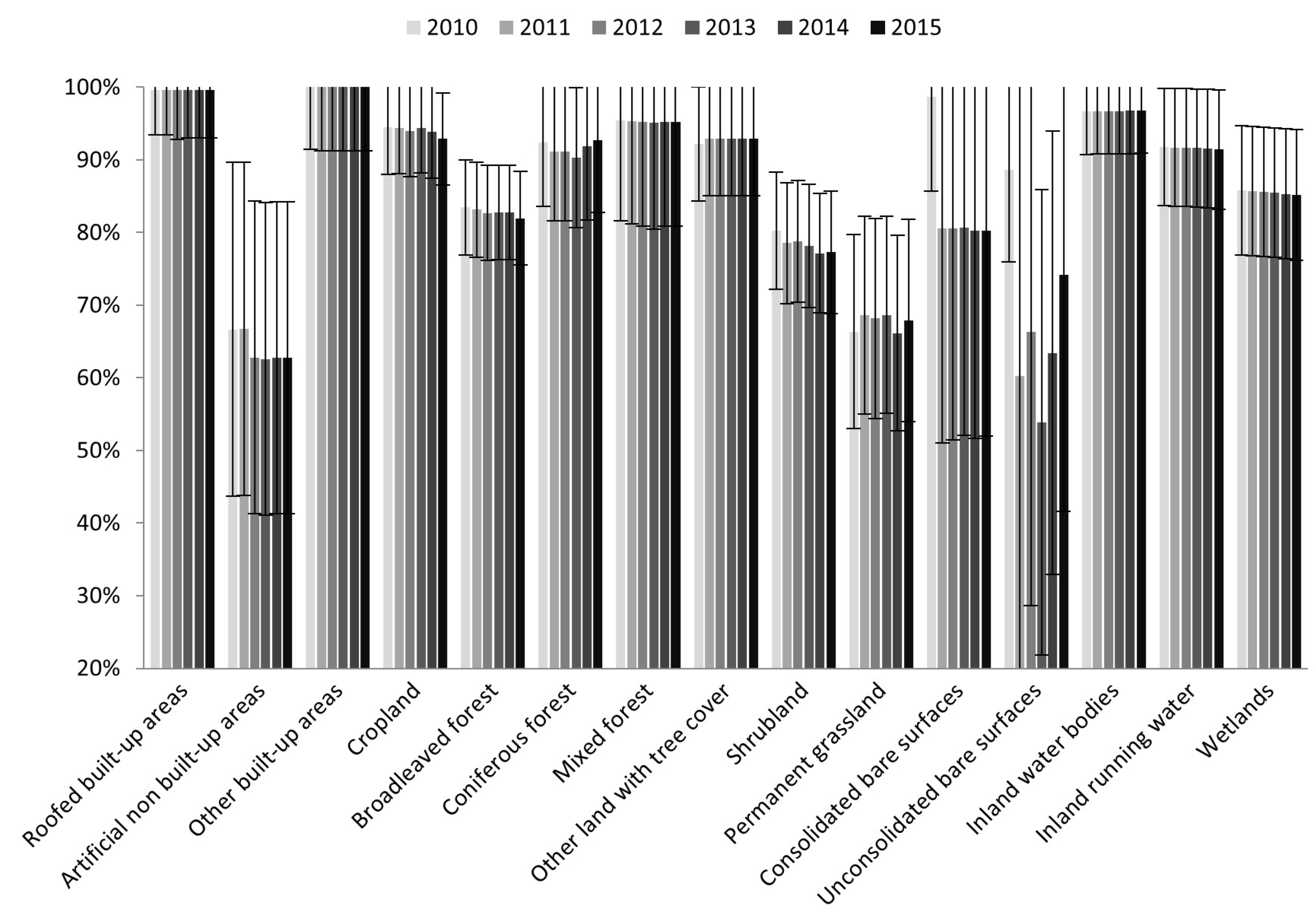
The overall accuracy of the maps depends on the accuracy of the classes mapped. Relatively more challenging classes present smaller user’s (
Figure 5) or producer’s (
Figure 6) accuracy, which expresses commission and omission errors, respectively. With regard to the former error type, mixed forest, consolidated bare surfaces, and permanent grassland are especially over-represented on the maps (relatively small user’s accuracy), and this error tended to increase over time, except for consolidated bare surfaces (
Figure 5). On the other hand, artificial non-built-up areas, unconsolidated bare surfaces, and permanent grassland are under-represented (relatively small producer’s accuracy), with an unclear increasing or decreasing trend over time (
Figure 6). Permanent grassland is particularly problematic as it accumulates considerable commission and omission map errors. In some cases, the difference between the accuracy of the classes is statistically significant, such as the user’s accuracy of artificial built-up areas and mixed forest (
Figure 5). However, the differences between the maps for the accuracies of the same class over time are always statistically insignificant.
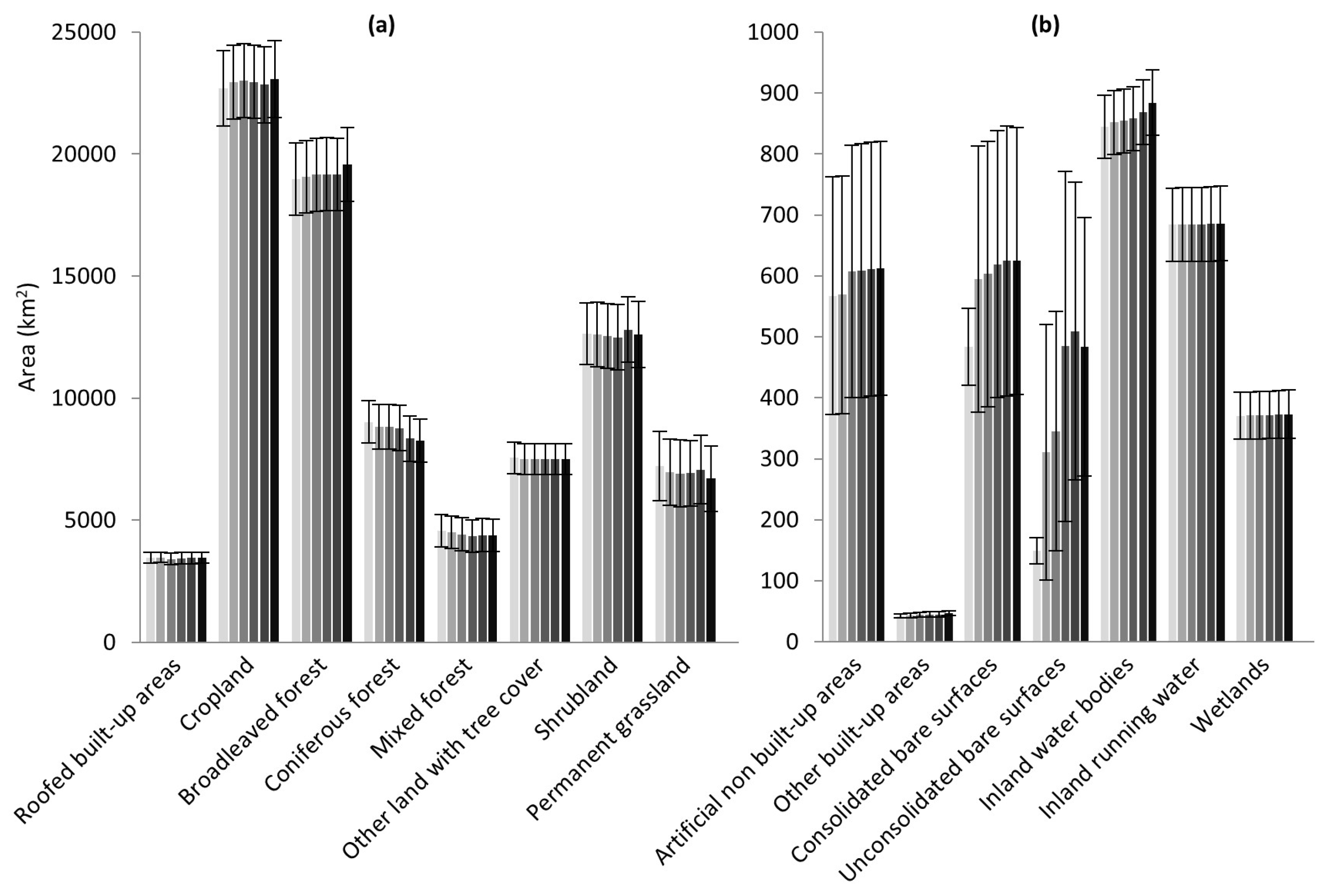
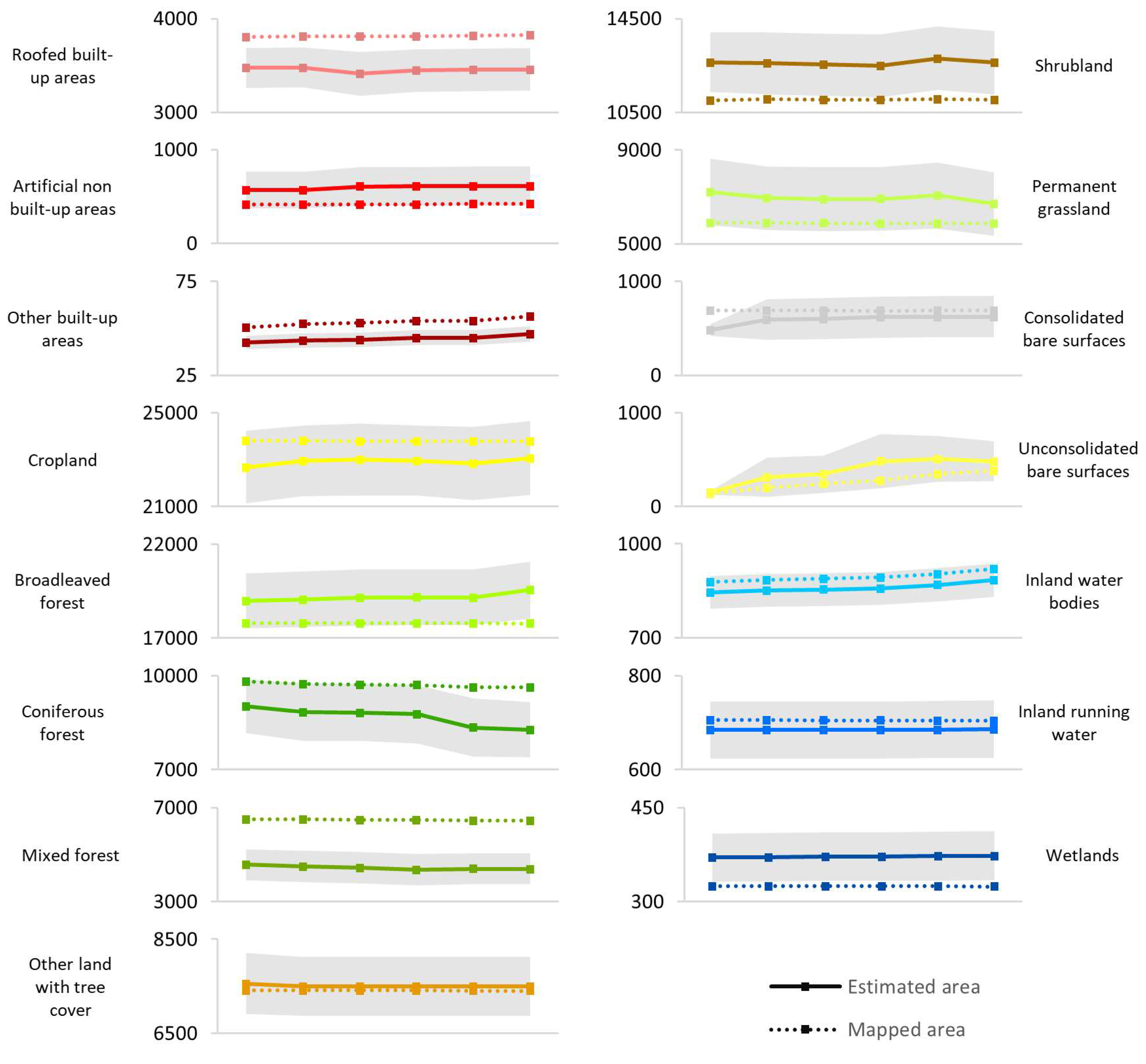
The mapped area of the land cover classes and the estimated error of the maps were used to estimate the actual area of each class in each year. The two most abundant classes (
Figure 7a) are cropland (~23,000 km
2) and broadleaved forest (~19,000 km
2) and their abundance tended to increase during the period analyzed. Next, a group of six classes cover a relevant fraction of the territory: shrubland (~12,500 km
2), coniferous forest (~9000 km
2), other land with tree (~7500 km
2), permanent grassland (~7200 km
2), mixed forest (~4500 km
2), and roofed built-up areas (~3500 km
2). Differences between classes are statistically significant, except for coniferous forest, other land with trees, and permanent grassland, so the true order of their abundance may be swapped. The estimates suggest that the area of coniferous forests, mixed forests, and permanent grassland is in decline, while roofed built-up areas are expanding, although slightly. Then, a group of seven minority classes (
Figure 7b) cover a total of ~2600 km
2. Inland running water and other built-up areas are the most and least abundant minority classes (~850 km
2 and ~42 km
2), respectively. These classes are predominantly stable over time but unconsolidated bare surfaces increased substantially from 149 km
2 in 2010 to 484 km
2 in 2015. To note in most cases, the evolution of the classes’ areas over time indicates differences in estimations, which are not statistically significant. Despite the interest that drivers for landscape change may be raised by these results, they are out of the scope of this paper.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}