Decision Model for Predicting Social Vulnerability Using Artificial Intelligence

 ,
,
Abstract
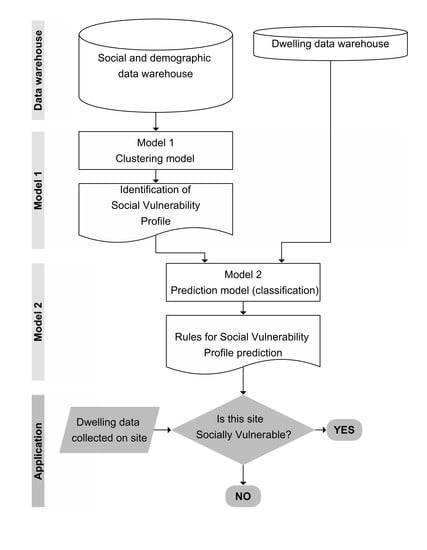
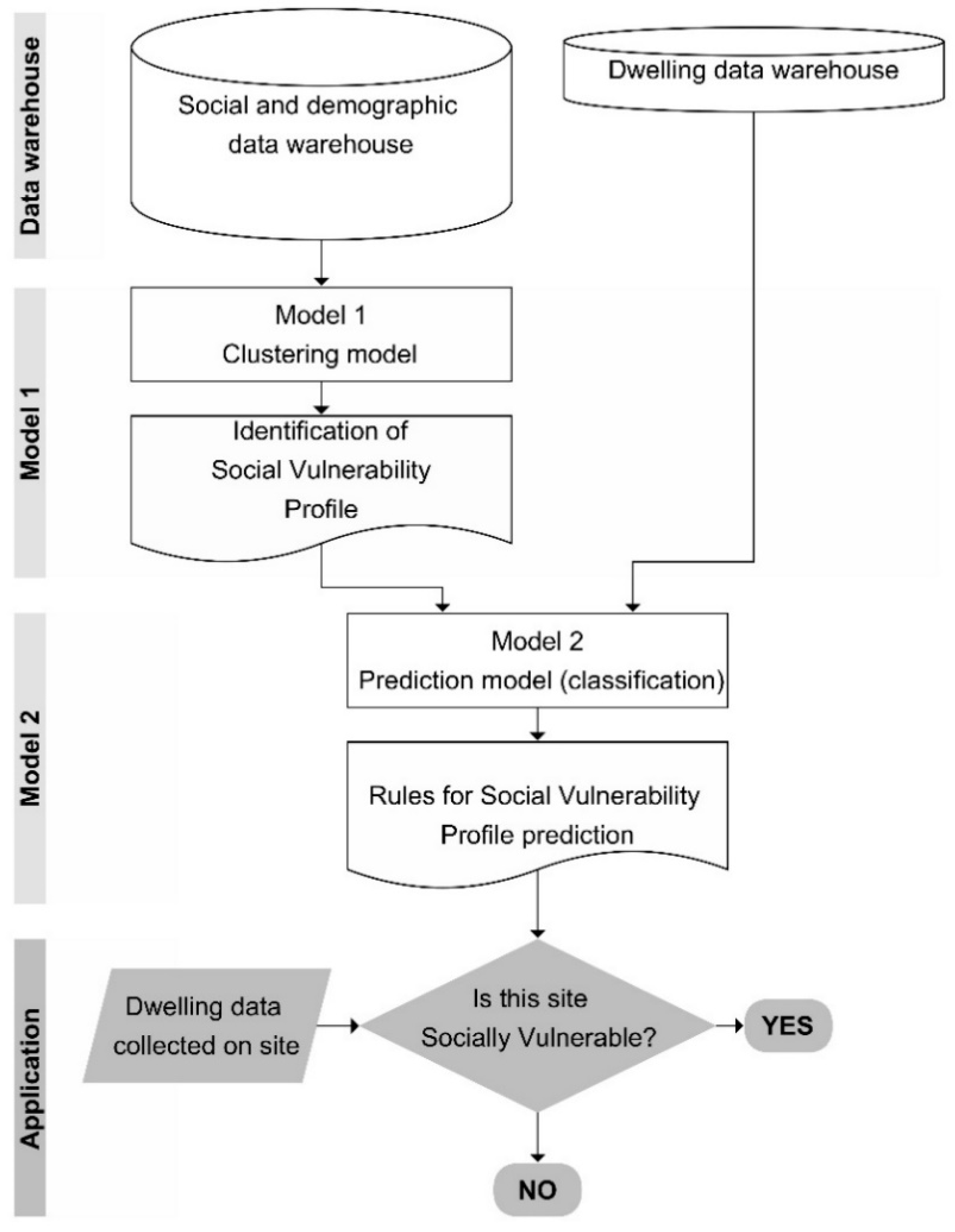
:
1. Introduction
2. Literature Review
2.1. Social Vulnerability
2.2. Decision Model and Decision Support System
2.3. Models of Knowledge Discovery and Clustering through Non-Supervised Learning—Self-Organizing Maps (SOM)
2.4. Construction of Predictive Models through Supervised Learning—Decision Trees
2.5. Hybrid Model—SOM and Decision Trees
3. Materials and Methods
3.1. Materials. Processing Information, and Functions
- Instances: The unit of territory on which the data were obtained is the Census Section, reaching the totality of the 5381 census sections of Andalusia, representing the totality of the surface and population censused in the Andalusian region, not initially carrying out any kind of sampling.
- Attributes: Table 2 lists the indicators elaborated from the Andalusian Population Census used as Modeling Phase 1, measuring instruments to identify the factors and concepts of the state-of-the-art of social vulnerability with which they are related. The attributes used in Modeling Phase 2 (Table 3) were composed of variables of the residential dimension not being used in Modeling Phase 1.
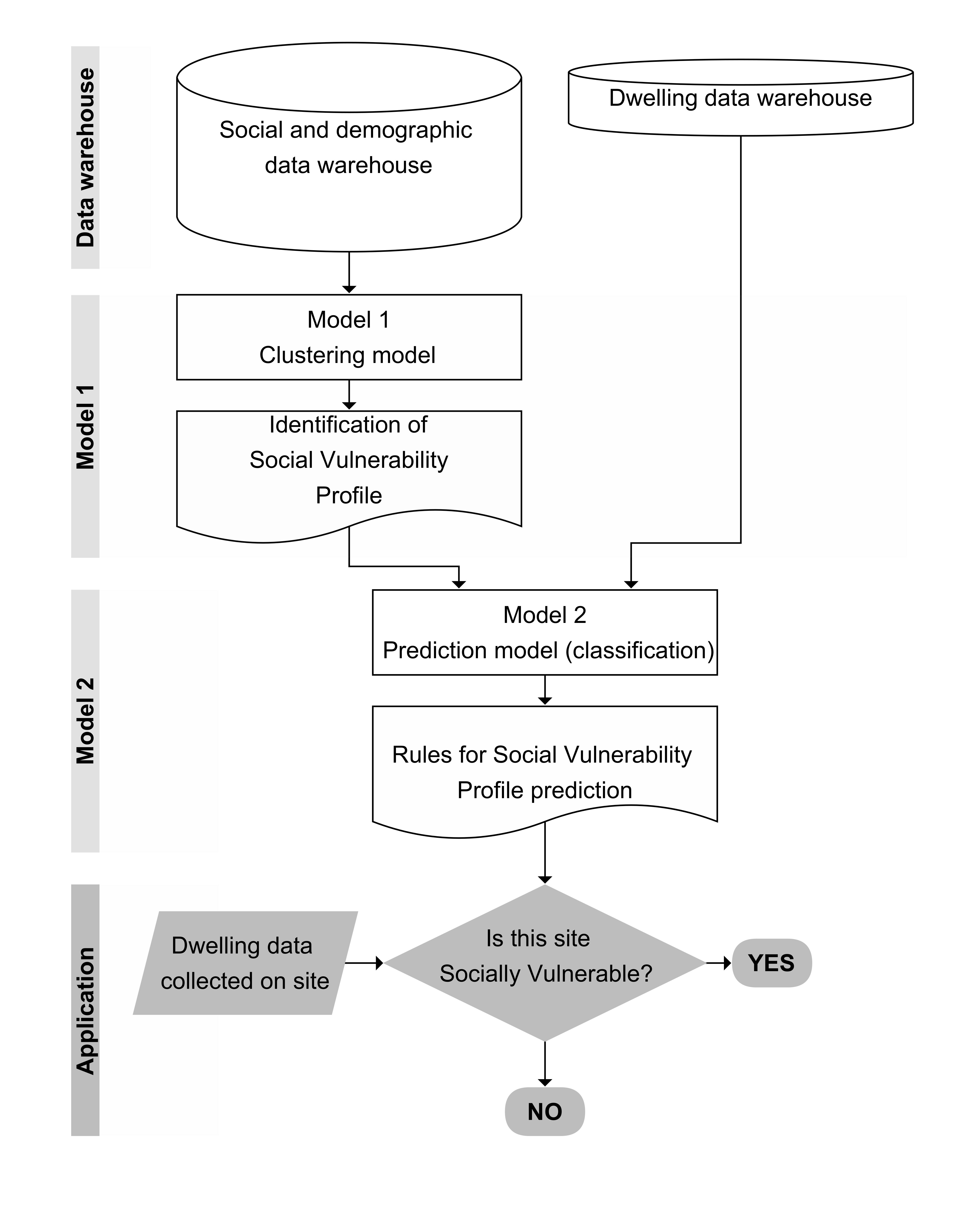
3.2. Data Warehouse
3.3. Methods-Models
3.4. Visual Representations
4. Results
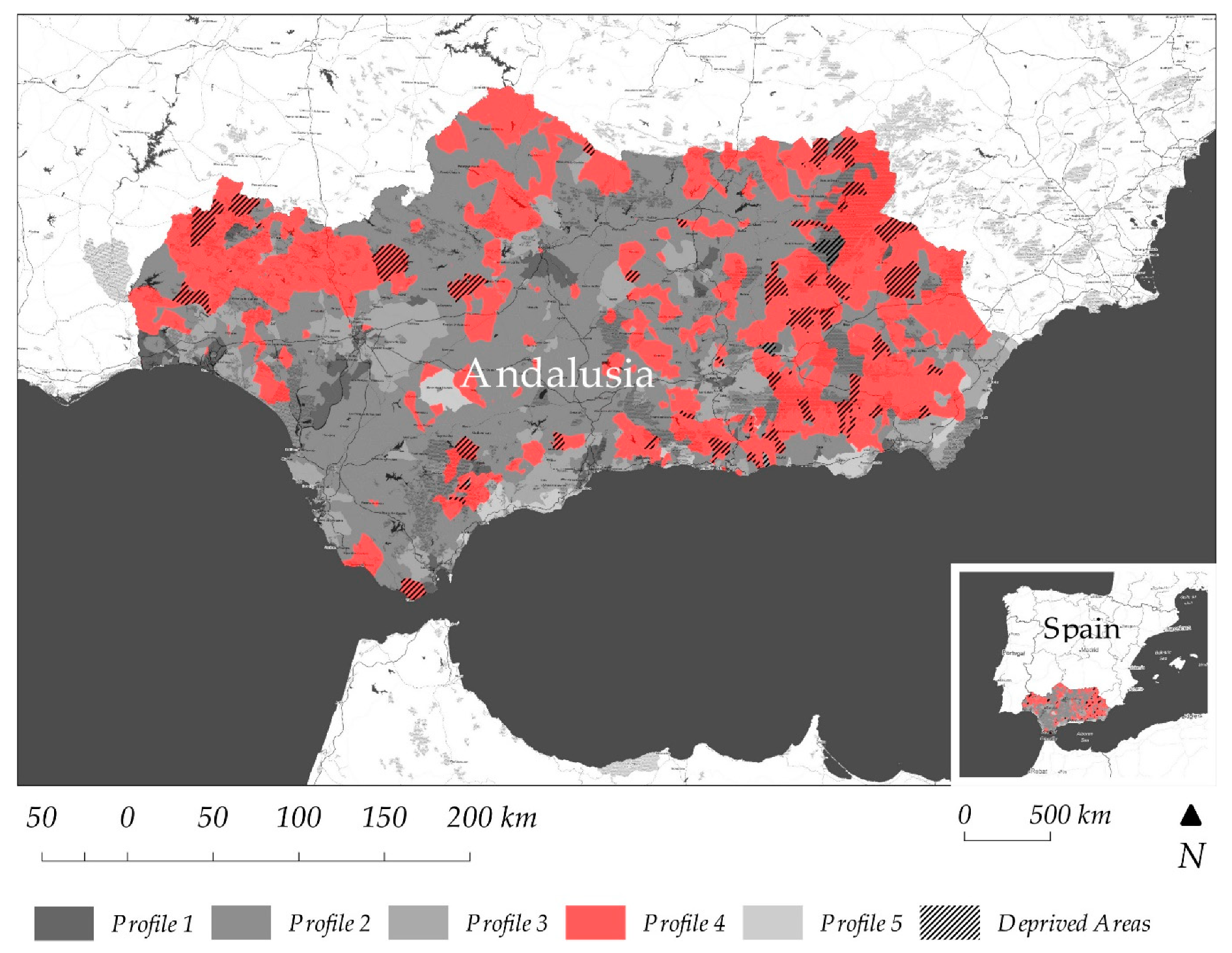
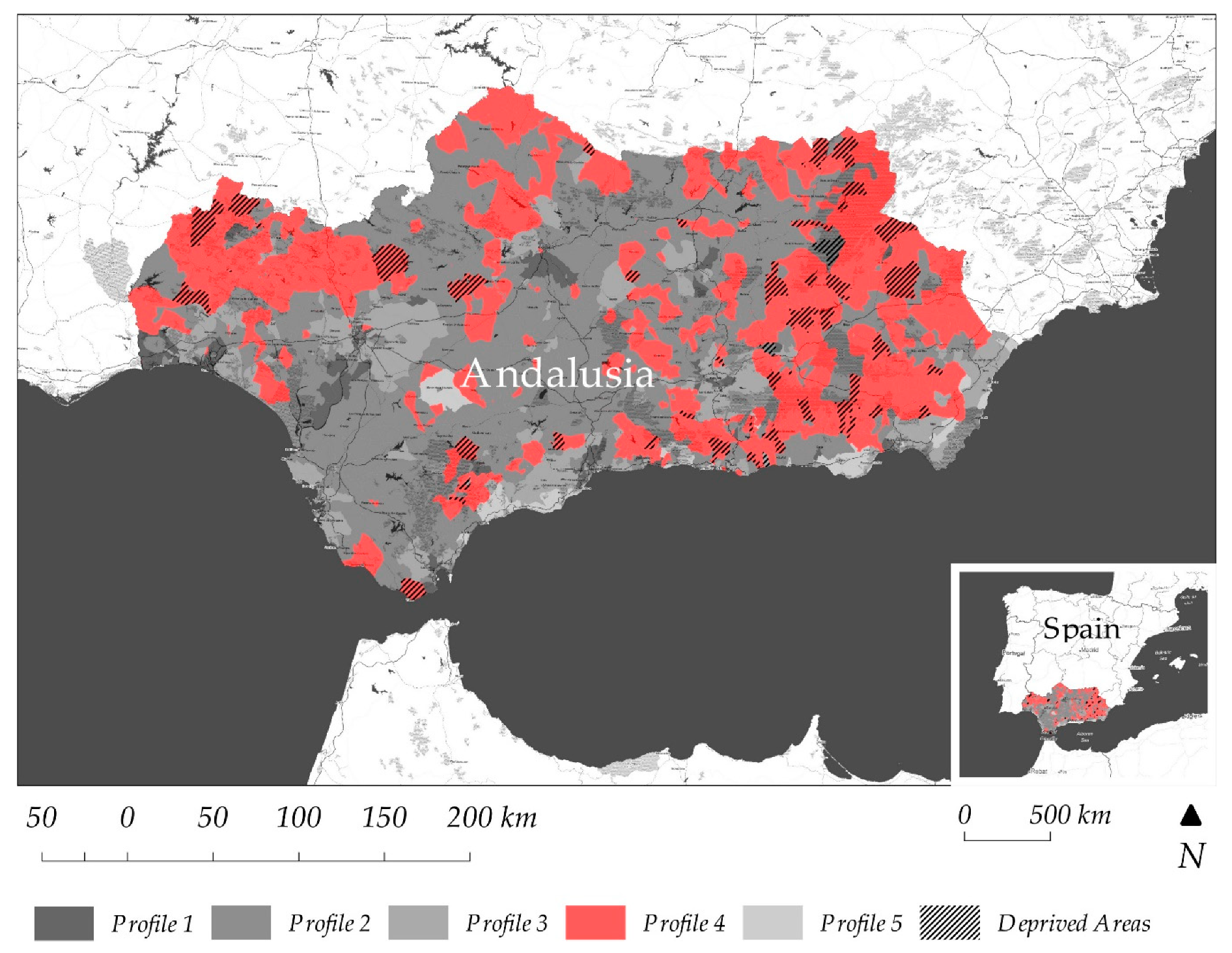
- Profile 1: Statistically, it is verified that the census sections contained in this profile present, compared with the other profiles, a greater presence of delinquency, a greater number of persons per building, a greater dedication in service employment, and a lower number of dwellings per occupied household. Through spatial representation through GIS, coincidences are observed with the main urban areas and their closest conurbations throughout the region. This profile shows the urban connotations of a well-consolidated city.
- Profile 2: A clear diversification of employment is observed, with little presence of the service sector, an eminently Spanish population, with few immigrants and a high number of illiterates, with little presence of households with only one adult and minors. This profile is spatially identified with a population located in rural environments, differing with respect to the other rural profile (Profile 4) in that its population is younger than in the former, with a larger active population with more activities typical of that reality, such as, for example, a greater dedication to construction or industry, and with households with a greater number of inhabitants.
- Profile 3: It stands out for a greater number of births, a greater number of immigrants of provincial origin, and to a lesser extent, regional or national. They usually work in the province, with a high percentage of employed—a low unemployment rate. It is below average age, with few single-person households, and a low level of rootedness. Spatially, they are located in the main cities’ outskirts.
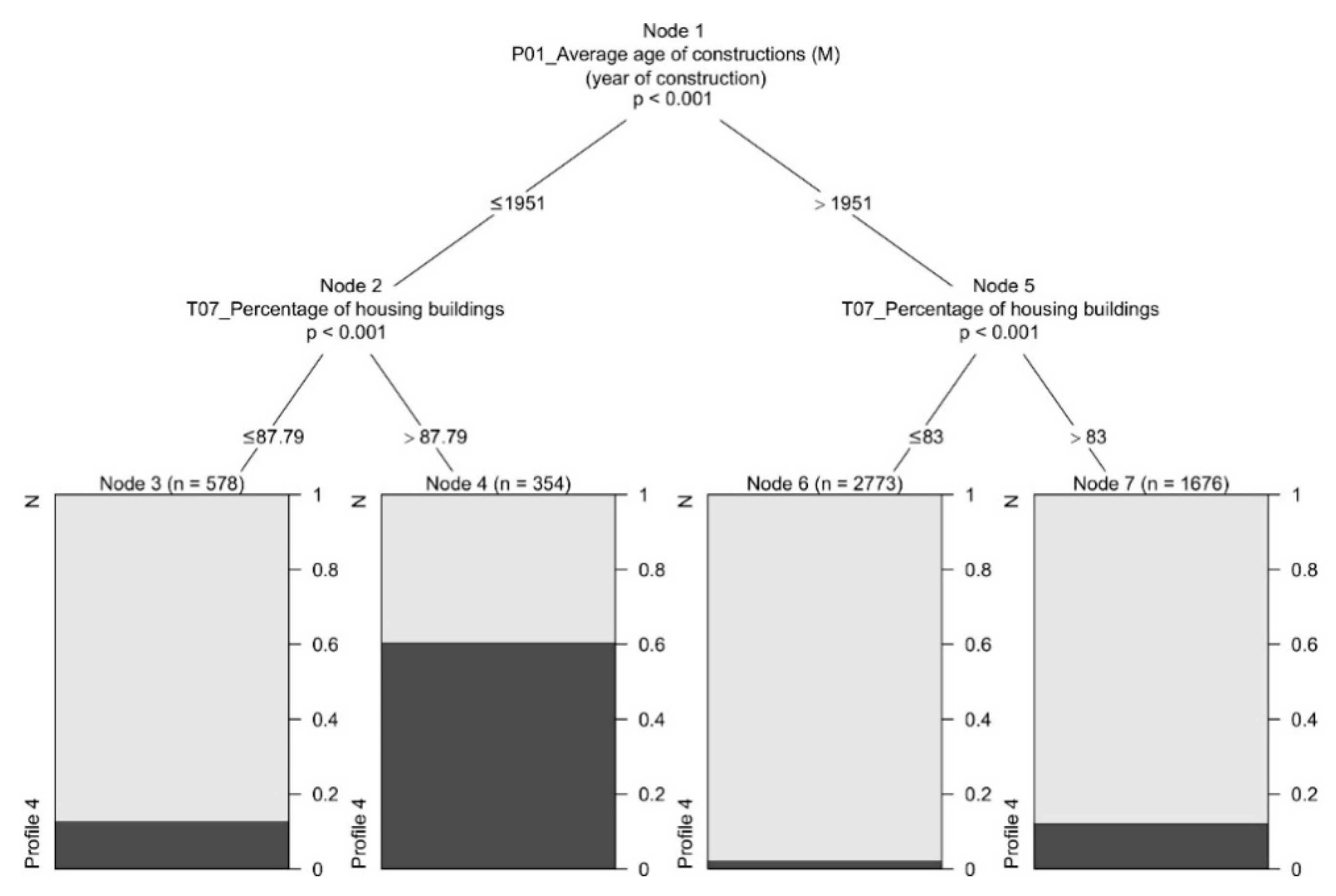
- Profile 4: The statistical analysis reveals that this population profile presents a high average age, a large number of households with a single occupant, an abundance of empty dwellings, and with issues such as a greater proportion of lack of running water than the rest. Statistical data reveal that they live in settlements with good ratios of cultural equipment and well-being per population, probably derived from the low number of inhabitants of such populations and acceptable distribution of such functions. Spatially, it is observed that they correspond to the most isolated rural sites and at a greater distance from the main cities. Comparing this profile with Profile 2, it is observed that it coincides with an older rural population, which often lives alone in urban environments with a small population, with little occupation of the dwellings and with high rates of illiteracy, unemployment, and inactivity. We can locate this profile, among other areas, prominently in Hoya de Baza (Granada), in Campos de Tabernas (Almería), in Altos de Sierra de Gádor (Almería) or in Sierra de Aracena (Huelva). As we observed in the state-of-the-art, this profile is identified with most of the factors that trigger social vulnerability.
- Profile 5: It stands out for a high number of dwellings occupied by one person, on many occasions with some minor in charge, a high presence of immigrants from the rest of Andalusia, the rest of Spain and especially, foreigners with the consequent low rootedness of its population. They have a high employment rate, low unemployment, and low inactivity, working primarily in the service sector or in agriculture. They are spatially recognized and identified as well-known urban areas with a strong and unique presence of foreign residents. It is shown in tourist enclaves, such as the coast of Málaga and Granada, and in a very intensive agricultural production zone, such as the greenhouse area of the coast of Almería (Campo de Dalías).
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cutter, S.L. Vulnerability to environmental hazards. Prog. Hum. Geogr. 1996, 20, 529–539. [Google Scholar] [CrossRef]
- Wisner, B.; Blaikie, P.; Cannon, T.; Davis, I. At Risk: Natural Hazards, People’s Vulnerability, and Disasters; Routledge: New York, NY, USA, 2004; ISBN 0415084768. [Google Scholar]
- Ebert, A.; Kerle, N.; Stein, A. Urban social vulnerability assessment with physical proxies and spatial metrics derived from air- and spaceborne imagery and GIS data. Nat. Hazards 2009, 48, 275–294. [Google Scholar] [CrossRef]
- Prowse, M. Towards a Clearer Understanding of ‘Vulnerability’ in Relation to Chronic Poverty; Chronic Poverty Research Centre: Manchester, UK, 2003; ISBN 1904049230. [Google Scholar]
- Cutter, S.L.; Boruff, B.J.; Shirley, W.L. Social vulnerability to environmental hazards. Soc. Sci. Q. 2003, 84, 242–261. [Google Scholar] [CrossRef]
- Sánchez-González, D.; Egea-Jiménez, C. Enfoque de vulnerabilidad social para investigar las desventajas socioambientales. Su aplicación en el estudio de los adultos mayores. Papeles de población 2011, 17, 151–185. [Google Scholar]
- Blaikie, P.; Cannon, T.; Davis, I.; Wisner, B. Vulnerabilidad: El Entorno Social, Político y Económico de los Desastres; Prim. Edición Julio; LA RED: Ciudad de Panamá, República de Panamá, 1996; p. 292. [Google Scholar]
- CEPAL-ECLAC. Vulnerabilidad Sociodemográfica: Viejos y Nuevos Riesgos Para Comunidades, Hogares y Personas; CEPAL-ECLAC: Brasilia, Brazil, 2002. [Google Scholar]
- Gu, H.; Du, S.; Liao, B.; Wen, J.; Wang, C.; Chen, R.; Chen, B. A hierarchical pattern of urban social vulnerability in Shanghai, China and its implications for risk management. Sustain. Cities Soc. 2018, 41, 170–179. [Google Scholar] [CrossRef]
- Tate, E. Social vulnerability indices: A comparative assessment using uncertainty and sensitivity analysis. Nat. Hazards 2012, 63, 325–347. [Google Scholar] [CrossRef]
- Maharani, Y.N.; Lee, S.; Ki, S.J. Social vulnerability at a local level around the Merapi volcano. Int. J. Disaster Risk Reduct. 2016, 20, 63–77. [Google Scholar] [CrossRef] [Green Version]
- Maharani, Y.N.; Lee, S. Assessment of social vulnerability to natural hazards in South Korea: Case study for typhoon hazard. Spat. Inf. Res. 2017, 25, 99–116. [Google Scholar] [CrossRef]
- Kleinosky, L.R.; Yarnal, B.; Fisher, A. Vulnerability of hampton roads, Virginia to storm-surge flooding and sea-level rise. Nat. Hazards 2007, 40, 43–70. [Google Scholar] [CrossRef]
- Nelson, K.S.; Abkowitz, M.D.; Camp, J.V. A method for creating high resolution maps of social vulnerability in the context of environmental hazards. Appl. Geogr. 2015, 63, 89–100. [Google Scholar] [CrossRef]
- Lee, Y.-J. Social vulnerability indicators as a sustainable planning tool. Environ. Impact Assess. Rev. 2014, 44, 31–42. [Google Scholar] [CrossRef]
- Fatemi, F.; Ardalan, A.; Aguirre, B.; Mansouri, N.; Mohammadfam, I. Social vulnerability indicators in disasters: Findings from a systematic review. Int. J. Disaster Risk Reduct. 2017, 22, 219–227. [Google Scholar] [CrossRef]
- Khazai, B.; Merz, M.; Schulz, C.; Borst, D. An integrated indicator framework for spatial assessment of industrial and social vulnerability to indirect disaster losses. Nat. Hazards 2013, 67, 145–167. [Google Scholar] [CrossRef]
- Rufat, S.; Tate, E.; Burton, C.G.; Maroof, A.S. Social vulnerability to floods: Review of case studies and implications for measurement. Int. J. Disaster Risk Reduct. 2015, 14, 470–486. [Google Scholar] [CrossRef] [Green Version]
- Schmidtlein, M.C.; Deutsch, R.C.; Piegorsch, W.W.; Cutter, S.L. A sensitivity analysis of the social vulnerability index. Risk Anal. 2008, 28, 1099–1114. [Google Scholar] [CrossRef]
- Power, D.J.; Sharda, R.; Burstein, F. Decision Support Systems. In Wiley Encyclopedia of Management; Cooper, C.L., Ed.; John Wiley & Sons, Ltd.: Chichester, UK, 2015; pp. 1–4. ISBN 9781118785317. [Google Scholar]
- Burstein, F.; Holsapple, C. Handbook on Decision Support Systems 1: Basic Themes; Springer: Berlin, Germany, 2008; ISBN 9783540487135. [Google Scholar]
- Gorry, G.A.; Scott Morton, M.S. A Framework for Management Information System; Massachusetts Institute of Technology: Cambridge, MA, USA, 1971; pp. 458–470. [Google Scholar]
- Agarwal, P.; Skupin, A. Self-Organising Maps: Applications in Geographic Information Science; John Wiley & Sons, Ltd.: Chichester, UK, 2008; ISBN 978-0-470-02167-5. [Google Scholar]
- Kauko, T. Using the self-organising map to identify regularities across country-specific housing-market contexts. Environ. Plan. B Plan. Des. 2005, 32, 89–110. [Google Scholar] [CrossRef] [Green Version]
- Kohonen, T. Self-Organizing Maps; Springer: Berlin, Germany, 1995; ISBN 978-3-540-62017-4. [Google Scholar]
- O’Brien, P.W.; Mileti, D.S. Citizen participation in emergency response following the Loma Prieta earthquake. Int. J. Mass Emerg. Disasters 1992, 10, 71–89. [Google Scholar]
- Hewitt, K. Regions of Risk: A Geographical Introduction to Disasters; Routledge: New York, NY, USA, 1997; ISBN 9781315844206. [Google Scholar]
- Cutter, S.L.; Mitchell, J.T.; Scott, M.S. Revealing the vulnerability of people and places: A case study of georgetown county, South Carolina. Ann. Assoc. Am. Geogr. 2000, 90, 713–737. [Google Scholar] [CrossRef]
- Ngo, E.B. When Disasters and Age Collide: Reviewing Vulnerability of the Elderly. Nat. Hazards Rev. 2001, 2, 80–89. [Google Scholar] [CrossRef]
- Khan, S. Vulnerability assessments and their planning implications: A case study of the Hutt Valley, New Zealand. Nat. Hazards 2012, 64, 1587–1607. [Google Scholar] [CrossRef]
- Fekete, A. Social vulnerability change assessment: Monitoring longitudinal demographic indicators of disaster risk in Germany from 2005 to 2015. Nat. Hazards 2019, 95, 585–614. [Google Scholar] [CrossRef]
- Wu, C.C.; Jhan, H.T.; Ting, K.H.; Tsai, H.C.; Lee, M.T.; Hsu, T.W.; Liu, W.H. Application of social vulnerability indicators to climate change for the southwest coastal areas of Taiwan. Sustainability 2016, 8, 1270. [Google Scholar] [CrossRef] [Green Version]
- Fekete, A. Social Vulnerability (Re-) Assessment in Context to Natural Hazards: Review of the Usefulness of the Spatial Indicator Approach and Investigations of Validation Demands. Int. J. Disaster Risk Sci. 2019, 10, 220–232. [Google Scholar] [CrossRef] [Green Version]
- Blaikie, P.; Cannon, T.; Davis, I.; Wisner, B. At Risk: Natural Hazards, People’s Vulnerability and Disasters; Routledge: London, UK, 2014. [Google Scholar]
- Enarson, E.P.; Morrow, B.H. The Gendered Terrain of Disaster: Through Women’s Eyes; Praeger: London, UK, 1998; ISBN 0275961109. [Google Scholar]
- Enarson, E.P.; Scanlon, J. Gender Patterns in Flood Evacuation: A Case Study in Canada’s Red River Valley. Appl. Behav. Sci. Rev. 1999, 7, 103–124. [Google Scholar] [CrossRef]
- Fothergill, A. Gender, Risk, and Disaster. Int. J. Mass Emerg. Disasters 1996, 14, 33–56. [Google Scholar]
- Morrow, B.H.; Phillips, B. What’s Gender ‘Got to Do With It’? Int. J. Mass Emerg. Disasters 1999, 17, 5–11. [Google Scholar]
- Peacock, W.G.; Morrow, B.H.; Gladwin, H. Hurricane Andrew: Ethnicity, Gender, and the Sociology of Disasters; Routledge: Hoboken, NJ, USA, 1997; ISBN 0415168112. [Google Scholar]
- Dwyer, A.; Zoppou, C.; Nielsen, O.; Day, S.; Roberts, S. Quantifying Social Vulnerability: A Methodology for Identifying Those at Risk to Natural Hazards; Record 200; Goescience Australia: Camberra, Australia, 2014; ISBN 1-920871-09-8. [Google Scholar]
- Fischer, A.P.; Frazier, T.G. Social Vulnerability to Climate Change in Temperate Forest Areas: New Measures of Exposure, Sensitivity, and Adaptive Capacity. Ann. Am. Assoc. Geogr. 2018, 108, 658–678. [Google Scholar] [CrossRef]
- Bolin, R.C.; Stanford, L. The Northridge Earthquake: Vulnerability and Disaster; Routledge: London, UK, 1998; ISBN 9780203028070. [Google Scholar]
- Heinz Center for Science Economics and the Environment. The Hidden Costs of Coastal Hazards: Implications for Risk Assessment and Mitigation; Island Press: Washington, DC, USA, 2000; ISBN 1559637560. [Google Scholar]
- Colburn, L.L.; Jepson, M.; Weng, C.; Seara, T.; Weiss, J.; Hare, J.A. Indicators of climate change and social vulnerability in fishing dependent communities along the Eastern and Gulf Coasts of the United States. Mar. Policy 2016, 74, 323–333. [Google Scholar] [CrossRef]
- Morrow, B.H. Identifying and mapping community vulnerability. Disasters 1999, 23, 1–18. [Google Scholar] [CrossRef]
- Rubayet, K.R.; Lourenco, J.M.; Viegas, J.M. Perceptions of Pedestrians and Shopkeepers in European Medium-Sized Cities: Study of Guimaraes, Portugal. J. Urban Plan. Dev. 2012, 138, 26–34. [Google Scholar] [CrossRef]
- Burton, I.; Kates, R.W.; Robert, W.; White, G.F. The Environment as Hazard; Guilford Press: New York, NY, USA, 1993; ISBN 9780898621594. [Google Scholar]
- Combes, P.; Gaillard, M.C.; Pellet, J.; Demongeot, J. A score for measurement of the role of social vulnerability in decisions on abortion. Eur. J. Obstet. Gynecol. Reprod. Biol. 2004, 117, 93–101. [Google Scholar] [CrossRef] [PubMed]
- Mileti, D. Disasters by Design: A Reassessment of Natural Hazards in the United States; Joseph Henry Press: Washington, DC, USA, 1999; ISBN 978-0-309-26173-9. [Google Scholar]
- De Oliveira Mendes, J.M. Social vulnerability indexes as planning tools: Beyond the preparedness paradigm. J. Risk Res. 2009, 12, 43–58. [Google Scholar] [CrossRef]
- Drabek, T.E. Disaster Evacuation Behavior: Tourists and Other Transients; Institute of Behavioral Science, University of Colorado: Boulder, CO, USA, 1996; ISBN 9781877943133. [Google Scholar]
- Hewitt, K. Safe place or ‘catastrophic society’? Perspectives on hazards and disasters in Canada. Can. Geogr./Le Géographe Can. 2000, 44, 325–341. [Google Scholar] [CrossRef]
- Tobin, G.A.; Ollenburger, J.C. Natural Hazards and the Eldery; University of Colorado, Natural Hazards Research and Applications Information Center: Boulder, CO, USA, 1993. [Google Scholar]
- Cova, T.J.; Church, R.L. Modelling community evacuation vulnerability using GIS. Int. J. Geogr. Inf. Sci. 1997, 11, 763–784. [Google Scholar] [CrossRef]
- Mitchell, J.K. Crucibles of Hazard: Mega-Cities and Disasters in Transition; United Nations University Press: Tokyo, Japan, 1999; ISBN 9280809873. [Google Scholar]
- Platt, R.H. Lifelines: An Emergency Management Priority for the United States in the 1990s. Disasters 1995, 15, 172–176. [Google Scholar] [CrossRef]
- Holand, I.S. Lifeline Issue in Social Vulnerability Indexing: A Review of Indicators and Discussion of Indicator Application. Nat. Hazards Rev. 2015, 16, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Jiménez, C.E.; Calmaestra, J.A.N.; Clemente, J.D.; Rego, R.A.G. Vulnerabiliad del Tejido Social de Los Barrios Desfavorecidos de Andalucía. Análisis y potenciales; Centro de Estudios Andaluces, Consejería de la Presidencia, Junta de Andalucía: Sevilla, Spain, 2008; ISBN 9788469144060. [Google Scholar]
- Power, D.J. Decision Support Systems: Concepts and Resources for Managers; Quorum Books: London, UK, 2002; ISBN 156720497X. [Google Scholar]
- Ayeni, B. The design of spatial decision support systems in urban and regional planning. In Decision Support System in Urban Planning; Timmermans, H., Ed.; Taylor and Francis: Abingdon, UK, 1997; pp. 3–15. [Google Scholar]
- Negash, S.; Gray, P. Business Intelligence. In Handbook on Decision Support Systems 2: Variatio; Burstein, F., Holsapple, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 175–193. [Google Scholar]
- Kohli, R.; Piontek, F. DSS in Healthcare: Advances and Opportunities. In Handbook for Decision Support Systems 2; Burstein, F., Holsapple, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 483–497. [Google Scholar]
- Kek, A.G.H.; Cheu, R.L.; Meng, Q.; Fung, C.H. A decision support system for vehicle relocation operations in carsharing systems. Transp. Res. Part E Logist. Transp. Rev. 2009, 45, 149–158. [Google Scholar] [CrossRef]
- Arampatzis, G.; Kiranoudis, C.T.; Scaloubacas, P.; Assimacopoulos, D. A GIS-based decision support system for planning urban transportation policies. Eur. J. Oper. Res. 2004, 152, 465–475. [Google Scholar] [CrossRef]
- Jarupathirun, S.; Zahedi, F. GIS as Spatial Decision Support Systems. In Geographic Information Systems in Business; Pick, J.B., Ed.; Idea Group Pub: Hershey, PA, USA, 2005; ISBN 9781591404019. [Google Scholar]
- Yeh, A.G.-O. Urban planning and GIS. In Geographical information systems: principles, techniques, applications and management; Long Longley, P.A., Goodchild, M.F., Maguire, D.J., Rhind, D.W., Eds.; Wiley: New York, NY, USA, 2005. [Google Scholar]
- Goodchild, M.F. Two decades on: Critical GIScience since 1993. Can. Geogr. 2015, 59, 3–11. [Google Scholar] [CrossRef]
- Sui, D.; Goodchild, M. The convergence of GIS and social media: Challenges for GIScience. Int. J. Geogr. Inf. Sci. 2011, 25, 1737–1748. [Google Scholar] [CrossRef]
- Kwan, M.P.; Neutens, T. Space-time research in GIScience. Int. J. Geogr. Inf. Sci. 2014, 28, 851–854. [Google Scholar] [CrossRef]
- National Research Council. Learning to Think Spatially; National Academies Press: Washington, DC, USA, 2006; ISBN 978-0-309-09208-1. [Google Scholar]
- Keen, P.G.W. Decision support systems: The next decade. Decis. Support Syst. 1987, 3, 253–265. [Google Scholar] [CrossRef]
- Agarwal, P. Ontological considerations in GIScience. Int. J. Geogr. Inf. Sci. 2005, 19, 501–536. [Google Scholar] [CrossRef]
- Elwood, S. Geographic Information Science: New geovisualization technologies - Emerging questions and linkages with GIScience research. Prog. Hum. Geogr. 2009, 33, 256–263. [Google Scholar] [CrossRef]
- Leszczynski, A. Rematerializing GIScience. Environ. Plan. D Soc. Space 2009, 27, 609–615. [Google Scholar] [CrossRef]
- Yang, C.; Raskin, R.; Goodchild, M.; Gahegan, M. Geospatial Cyberinfrastructure: Past, present and future. Comput. Environ. Urban Syst. 2010, 34, 264–277. [Google Scholar] [CrossRef]
- Goodchild, M.F. Geographical Information Science. Int. J. Geogr. Inf. Sci. 1992, 6, 31–45. [Google Scholar] [CrossRef]
- Buzai, G.D.; Cacace, G.; Humacata, L.; Lanzelotti, S.L. Teoría y Métodos de la Geografía Cuantitativa: Libro 1: Por una Geografía de lo Real; MCA Libros: Buenos Aires, Argentina, 2015; ISBN 9789874598622. [Google Scholar]
- Golfarelli, M.; Rizzi, S. Datawarehouse design. Modern Principles and Methodologies; Tata McGraw Hill Education Private Limited: Bologna, Italy, 2009; ISBN 978-0-07-067752-4. [Google Scholar]
- Cao, L. Introduction to domain driven data mining. In Data Mining for Business Applications; Cao, L., Philip, S.Y., Zhang, C., Zhang, H., Eds.; Springer: Dordrecht, The Netherlands, 2009; pp. 3–10. ISBN 9780387794198. [Google Scholar]
- Abarca-Alvarez, F.J.; Campos-Sánchez, F.S.; Reinoso-Bellido, R. Methodology of Decision Support through GIS and Artificial Intelligence: Implementation for Demographic Characterization of Andalusia based on Dwelling. Estoa 2017, 6, 33–51. [Google Scholar] [CrossRef] [Green Version]
- Koskela, T.; Varsta, M.; Heikkonen, J.; Kaski, K. Temporal Sequence Processing using Recurrent SOM. Proc. Knowl.-Based Intell. Electron. Syst. 1998, 1, 1689–1699. [Google Scholar] [CrossRef]
- Ritter, H.; Kohonen, T. Self-organizing semantic maps. Biol. Cybern. 1989, 61, 241–254. [Google Scholar] [CrossRef]
- Kaski, S.; Kohonen, T. Exploratory Data Analysis By The Self-Organizing Map: Structures Of Welfare And Poverty In The World. In Proceedings of the Third International Conference on Neural Networks in the Capital Markets, London, UK, 11–13 October 1995; pp. 498–507. [Google Scholar]
- Villmann, T.; Merényi, E.; Hammer, B. Neural maps in remote sensing image analysis. Neural Netw. 2003, 16, 389–403. [Google Scholar] [CrossRef]
- Tayebi, M.H.; Hashemi Tangestani, M.; Vincent, R.K. Alteration mineral mapping with ASTER data by integration of coded spectral ratio imaging and SOM neural network model. Turk. J. Earth Sci. 2014, 23, 627–644. [Google Scholar] [CrossRef]
- Yan, J.; Thill, J.-C. Visual data mining in spatial interaction analysis with self-organizing maps. Environ. Plan. B Plan. Des. 2009, 36, 466–486. [Google Scholar] [CrossRef]
- Campos-Sánchez, F.S.; Abarca-Álvarez, F.J.; Serra-Coch, G.; Chastel, C. Evaluación comparativa del nivel de Desarrollo Orientado al Transporte (DOT) en torno a nodos de transporte de grandes ciudades: Métodos complementarios de ayuda a la decisión. EURE. Rev. Latinoam. Estud. Urbanos Reg. 2019, 45, 5–30. [Google Scholar] [CrossRef]
- Faggiano, L.; de Zwart, D.; García-Berthou, E.; Lek, S.; Gevrey, M. Patterning ecological risk of pesticide contamination at the river basin scale. Sci. Total Environ. 2010, 408, 2319–2326. [Google Scholar] [CrossRef]
- Gomes, H.; Ribeiro, A.B.; Lobo, V. Location model for CCA-treated wood waste remediation units using GIS and clustering methods. Environ. Model. Softw. 2007, 22, 1788–1795. [Google Scholar] [CrossRef]
- Yang, C.; Guo, R.; Wu, Z.; Zhou, K.; Yue, Q. Spatial extraction model for soil environmental quality of anomalous areas in a geographic scale. Environ. Sci. Pollut. Res. 2014, 21, 2697–2705. [Google Scholar] [CrossRef]
- Basara, H.G.; Yuan, M. Community health assessment using self-organizing maps and geographic information systems. Int. J. Health Geogr. 2008, 7, 67. [Google Scholar] [CrossRef] [Green Version]
- Delmelle, E.C.; Thill, J.C.; Furuseth, O.; Ludden, T. Trajectories of Multidimensional Neighbourhood Quality of Life Change. Urban Stud. 2012, 50, 923–941. [Google Scholar] [CrossRef]
- Skupin, A.; Hagelman, R. Visualizing Demographic Trajectories with Self Organizing Maps. Geoinformatica 2005, 9, 159–179. [Google Scholar] [CrossRef]
- Guo, D.; Chen, J.; MacEachren, A.M.; Liao, K. A Visualization System for Space-Time and Multivariate Patterns (VIS-STAMP). IEEE Trans. Vis. Comput. Graph. 2006, 12, 1461–1474. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Skupin, A.; Esperbé, A. An alternative map of the United States based on an n-dimensional model of geographic space. J. Vis. Lang. Comput. 2011, 22, 290–304. [Google Scholar] [CrossRef]
- Hatzichristos, T. Delineation of demographic regions with GIS and computational intelligence. Environ. Plan. B Plan. Des. 2004, 31, 39–49. [Google Scholar] [CrossRef]
- Abarca-Alvarez, F.J.; Navarro-Ligero, M.L.; Valenzuela-Montes, L.M.; Campos-Sánchez, F.S. European Strategies for Adaptation to Climate Change With the Mayors Adapt Initiative by Self-Organizing Maps. Appl. Sci. 2019, 9, 3859. [Google Scholar] [CrossRef] [Green Version]
- Spielmans, S.E.; Thill, J.-C. Social area analysisss, data mining, and GIS. Comput. Environ. Urban Syst. 2008, 32, 110–122. [Google Scholar] [CrossRef]
- Behnisch, M.; Ultsch, A. Urban data-mining: Spatiotemporal exploration of multidimensional data. Build. Res. Inf. 2009, 37, 520–532. [Google Scholar] [CrossRef]
- Abarca-Alvarez, F.J.; Osuna-Pérez, F. Cartografías semánticas mediante redes neuronales: Los mapas auto-organizados (SOM) como representación de patrones y campos. EGA. Rev. Expresión Gráfica Arquit. 2013, 18, 154–163. [Google Scholar] [CrossRef] [Green Version]
- Diappi, L.; Bolchim, P.; Buscema, M. Improved Understanding of Urban Sprawl Using Neural Networks. In Recent Advances in Design and Decision Support Systems in Architecture and Urban Planning; Van-Leeuwen, J.P., Timmermans, H.J.P., Eds.; Politecn Milan, Dept Architecture and Planning: Milan, Italy, 2004; pp. 33–49. ISBN 1-4020-2408-8. [Google Scholar]
- Hamaina, R.; Leduc, T.; Moreau, G. Towards Urban Fabrics Characterization based on Buildings Footprints. In Bridging the Geographic Information Sciences; Gensel, J., Josselin, D., Vandenbroucke, D., Eds.; Springer: Berlin, Germany, 2012; pp. 231–248. ISBN 978-3-642-29063-3. [Google Scholar]
- Salah, M.; Trinder, J.; Shaker, A. Evaluation of the self-organizing map classifier for building detection from lidar data and multispectral aerial images. J. Spat. Sci. 2009, 54, 15–34. [Google Scholar] [CrossRef]
- Skupin, A.; Agarwal, P. Introduction: What is a Self-Organizing Map? In Self-Organising Maps: Applications in Geographic Information Science; Agarwal, P., Skupin, A., Eds.; Wiley: Chichester, UK, 2008; pp. 1–20. ISBN 0470021675. [Google Scholar]
- Bação, F.; Lobo, V.; Painho, M. Self-organizing maps as substitutes for k-means clustering. Comput. Sci. 2005, 3516, 476–483. [Google Scholar] [CrossRef] [Green Version]
- Witten, I.H.; Frank, E.; Hall, M. A Data Mining: Practical Machine Learning Tools and Techniques; Elsevier Science & Technology Books: San Diego, CA, USA, 2011; ISBN 0080890369. [Google Scholar]
- Hernández Orallo, J.; Ramírez Quintana, M.J.; Ferri Ramírez, C. Introducción a la Minería de Datos; Pearson Prentice Hall: Madrid, Spain, 2004; ISBN 8420540919. [Google Scholar]
- Kass, G.V. An Exploratory Technique for Investigating Large Quantities of Categorical Data. Appl. Stat. 1980, 29, 119–127. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman & Hall: London, UK, 1984; ISBN 0-412-04841-8. [Google Scholar]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Strobl, C.; Malley, J.; Tutz, G. An Introduction to Recursive Partitioning: Rationale, Application and Characteristics of Classification and Regression Trees, Bagging and Random Forests. Psychol. Methods 2010, 14, 323–348. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Strasser, H.; Weber, C. On the Asymptotic Theory of Permutation Statistics. Math. Methods Stat. 1999, 8, 220–250. [Google Scholar] [CrossRef] [Green Version]
- Astudillo, C.A.; John Oommen, B. Imposing tree-based topologies onto self organizing maps. Inf. Sci. (Ny). 2011, 181, 3798–3815. [Google Scholar] [CrossRef] [Green Version]
- Astudillo, C.A.; Oommen, B.J. On achieving semi-supervised pattern recognition by utilizing tree-based SOMs. Pattern Recognit. 2013, 46, 293–304. [Google Scholar] [CrossRef]
- Yang, Z.R.; Chou, K.-C. Mining biological data using self-organizing map. J. Chem. Inf. Comput. Sci. 2003, 43, 1748–1753. [Google Scholar] [CrossRef]
- Gómez-Carracedo, M.P.; Andrade, J.M.; Carrera, G.V.S.M.; Aires-de-Sousa, J.; Carlosena, A.; Prada, D. Combining Kohonen neural networks and variable selection by classification trees to cluster road soil samples. Chemom. Intell. Lab. Syst. 2010, 102, 20–34. [Google Scholar] [CrossRef]
- Di Maio, F.; Rossetti, R.; Zio, E. Postprocessing of Accidental Scenarios by Semi-Supervised Self-Organizing Maps. Sci. Technol. Nucl. Install. 2017. [Google Scholar] [CrossRef] [Green Version]
- Tsai, C.-F.; Lin, Y.-C.; Wang, Y.-T. Discovering Stock Trading Preferences By Self-Organizing Maps and Decision Trees. Int. J. Artif. Intell. Tools 2009, 18, 603–611. [Google Scholar] [CrossRef]
- Shanmuganathan, S.; Li, Y. An AI based approach to multiple census data analysis for feature selection. J. Intell. Fuzzy Syst. 2016, 31, 859–872. [Google Scholar] [CrossRef] [Green Version]
- Silver, M.S. On the Design Features of Decision Support Systems: The Role of System Restrictiveness and Decisional Guidance. In Handbook on Decision Support Systems 2: Variations; Burstein, F., Holsapple, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 261–291. [Google Scholar]
- Demartines, P.; Blayo, F. Kohonen Self-Organizing Maps: Is the Normalization Necessary? Complex Syst. 1992, 6, 105–123. [Google Scholar]
- Weiss, S.M.; Indurkhya, N. Predictive Data Mining: A Practical Guide; Morgan Kaufmann: San Francisco, CA, USA, 1998; ISBN 1558604030. [Google Scholar]
- Ketchen, D.J.; Shook, C.L. The Application Of Cluster Analysis In Strategic Management Reseach: An Anlysis and Critique. Strateg. Manag. J. 1996, 17, 441–458. [Google Scholar] [CrossRef]
- Ball, G.H.; Hall, D.J. A Novel Method of Data Analysis Andpattern Classification; SRI International: Menlo Park, CA, USA, 1965. [Google Scholar]
- Calinski, T.; Harabasz, J. A Dendrite Method for Cluster Analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Lletí, R.; Ortiz, M.C.; Sarabia, L.A.; Sánchez, M.S. Selecting variables for k-means cluster analysis by using a genetic algorithm that optimises the silhouettes. Anal. Chim. Acta 2004, 515, 87–100. [Google Scholar] [CrossRef]
- Hair, J.F., Jr.; Black, W.C.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis, 7th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2009; ISBN 9780138132637. [Google Scholar]
- Wu, P.K.; Hsiao, T.C. Factor Knowledge Mining Using the Techniques of AI Neural Networks and Self-Organizing Map. Int. J. Distrib. Sens. Netw. 2015, 11, 412418. [Google Scholar] [CrossRef]
- Wasserstein, R.L.; Lazar, N.A. The ASA’s statement on p-values: Context, process, and purpose. Am. Stat. 2016, 70, 129–133. [Google Scholar] [CrossRef] [Green Version]
- Coe, R.; Merino, C. Magnitud del efecto: Una guía para investigadores y usuarios. Rev. Psicol. 2003, 21, 147–177. [Google Scholar]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1998; ISBN 0-8058-0283-5. [Google Scholar]
- Sarlin, P. Exploiting the self-organizing financial stability map. Front. Artif. Intell. Appl. 2012, 243, 248–257. [Google Scholar] [CrossRef]
- Hothorn, T.; Hornik, K.; Zeileis, A. Unbiased recursive partitioning: A conditional inference framework. J. Comput. Graph. Stat. 2006, 15, 651–674. [Google Scholar] [CrossRef] [Green Version]
- Bação, F.; Lobo, V.; Painho, M. The Self-Organizing Map and it’s variants as tools for geodemographical data analysis: The case of Lisbon’s Metropolitan Area. Comput. Geosci. 1995, 31, 155–163. [Google Scholar] [CrossRef]
- Skupin, A.; Hagelman, R. Attribute space visualization of demographic change. In Proceedings of the 11th ACM International Symposium on Advances in Geographic Information Systems, New Orleans, LA, USA, 7–8 November 2003; pp. 56–62. [Google Scholar] [CrossRef] [Green Version]
- Streich, B. Stadtplanung in der Wissensgesellschaft Ein Handbuch; Verlag für Sozialwissenschaften: Wiesbaden, Germany, 2005; ISBN 9783663114802. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Capital 1 | Description of Factors 1 | Concept 2 | Resources of References |
|---|---|---|---|
| Human capital | Demographic characteristics | Age | [15,16,18,26,27,28,29,30,31,32,33] |
| Gender | [1,15,16,27,30,32,34,35,36,37,38,39,40,41] | ||
| Race and ethnicity | [16,18,39,41,42] | ||
| Occupation | [15,27,31,43,44] | ||
| Population growth and mortality | [18,28,31,32,43,45,46] | ||
| Social and economics characteristics | Socioeconomic status (income, political power, prestige) | [15,16,17,18,27,28,33,34,39,41,45,46,47,48] | |
| Employment | [15,17,31,33,40,41,44,49,50] | ||
| Education | [16,17,31,32,33,41,43,44,48,50] | ||
| Social dependence | [16,17,30,32,40,41,43,44,45,51,52] | ||
| Special needs populations | [16,41,44,45,53] | ||
| Social capital | Community development | Commercial and industrial development | [16,43,44] |
| Rural/urban | [16,28,54,55] | ||
| Residential property | [15,18,28,31,42,43,44,50] | ||
| Renters | [15,18,31,33,41,43,45,50] | ||
| Family and social structure | [16,18,34,43,45,46] | ||
| Public resource provision and public security | Public infrastructure and resources that belong to inhabitants and its safety | Infrastructure and lifelines | [16,18,32,41,43,50,56,57] |
| Medical services | [17,18,27,31,32,43,45,57] |
| Measurements (Indicators) | Concept [5,15] | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Relation to Social Vulnerability | Age | Gender | Race and Ethnicity | Occupation | Population Growth | Socioeconomic Status | Employment | Education | Social Dependence | Spetial Needs Populations | Commercial & ind. Dev. | Rural/Urban | Residential Property | Renters | Family and Social Structure | Infrastructure & Lifelines | Medical Services | |
| A01_Health facilities/1 k inhabitants | − | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● |
| A02_Education facilities/1 k inhabitants | − | ○ | ○ | ○ | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| A03_Well-being facilities/1 k inhabitants | − | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| A04_Cultural or sport facilities/1 k inhabitants | − | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● |
| A05_Facilities/1 k inhabitants | − | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ |
| B01_Percentage of dwellings no running water | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ |
| B02_Percentage of dwellings with gas | − | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ |
| B03_Percentage of dwellings with telephone | − | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ |
| C01_Percentage of street cleaning complaints | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ |
| C02_Percentage of crime complaints | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ |
| D01_Population | +/− | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| D02_Average age population | + | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| D03_Percentage of births | − | ● | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| D04_Percentage of men | − | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| D05_Percentage of women | + | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| E01_People per building | +/− | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ |
| E02_Percentage of households 1 adult | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ |
| E03_Porcent. of households 1 adult and minor | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ |
| E04_Percentage of households with 2 adults | − | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ |
| E05_Percentage of households with 3 adults | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ |
| E06_Percentage of households with 4 adults | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ |
| E07_Homes | − | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| E08_Inhabitants per household | +/− | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ |
| E09_Ratio of residential buildings/household | + | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F01_Percentage of rooted population | − | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F02_Percent. of provincial immigrant populat. | + | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F03_Percent. of regional immigrant population | + | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F04_Percent. of national immigrant population | + | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F05_Percent. of foreign immigrant population | + | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F06_Percentage from Spain | − | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F07_Percentage from EU | − | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F08_Percentage from non-EU Europe | − | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F09_Percentage from North America | − | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F10_Percentage from Central America | + | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F11_Percentage from South America | + | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F12_Percentage from Asia | + | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F13_Percentage from Africa | + | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F15_Percentage from Oceania | +/− | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| F16_Percentage Statelessness | + | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| G01_Percentage working in the province | − | ○ | ○ | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| G02_Percentage working in region | + | ○ | ○ | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| G03_Percentage working in Spain | + | ○ | ○ | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| G04_Percentage working in another country | + | ○ | ○ | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| H01_Percentage of employed population | − | ○ | ○ | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| H02_Percentage of population unemployed | + | ○ | ○ | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| H03_Percentage of inactive population | + | ○ | ○ | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| I01_Commercial establishment/1 k inhabitants | +/− | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| I02_Office and services/1 k inhabitants | − | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| I03_Industrial/1 k inhabitants | + | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| I04_Premises dedicated to farming/1 k inhab. | +/− | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| I05_Inactive premises/1 k inhabitants | + | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| J01_Combined HDI - | + | ○ | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| J02_Combined HDI + | − | ○ | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| J03_Combined HDI | +/− | ○ | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| K01_Percent. active pop. employed in farming | +/− | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ● | ○ | ○ | ○ | ○ | ○ |
| K02_Percent. active pop. employed in fisheries | +/− | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| K03_Percent. active pop. employed in industry | +/− | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| K04_P. active p. employed in construction | +/− | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| K05_P. active p. employed in the service sector | − | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| K06_Percent. active population unemployed | + | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ |
| L01_Percentage of dwelling owned | − | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ● | ○ | ○ | ○ |
| L02_Percentage of dwellings for rent | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ● | ○ | ○ | ○ |
| L03_P. of housing not rented and not owned | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ● | ○ | ○ | ○ |
| M01_Construction status (M) | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ |
| M02_Construction status (SD) | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ |
| N01_Percentage of illiteracy | + | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| Measurements |
|---|
| O01_Percentage of dwellings with garage |
| O02_Percentage of non-accessible dwellings |
| P01_Average age of constructions (year) (M) |
| P02_Average age of Constructions (year) (SD) |
| Q01_Percentage of complaints outside noise |
| Q02_Percentage of pollution complaints |
| R01_Average height of constructions (M) |
| R02 Average building height (SD) |
| S01_Housing buildings |
| T01_Percentage of single-family dwellings |
| T02_Percent. grouped single-family dwelling |
| T03_P. single-family dwellings with commercials |
| T04_Percentage of multi-family dwellings |
| T05_Percentage commercial b. with dwellings |
| T06_Percentage of commercial buildings |
| T07_Percentage of housing buildings |
| U01_ P. complaints poor communications |
| U02_P. of complaints about scarce green areas |
| V01_Percentage of dwellings with no toilets |
| Measurements | Population | Profile 4 | ||||||
|---|---|---|---|---|---|---|---|---|
| 5381cs (100%) | 550cs (10.22%) | |||||||
| M | SD | M | SD | C | T | ES | ES | |
| A01_Health facilities/1 k inhabitants | 1.39 | 6.16 | 1.56 | 2.45 | ns | 1.62 | 0.027 | |
| A02_Education facilities/1 k inhabitants | 1.14 | 2.36 | 2.16 | 3.2 | *** | 7.51 | 0.433 | + |
| A03_Well-being facilities/1 k inhabitants | 0.831 | 1.682 | 1.845 | 3.774 | *** | 6.30 | 0.602 | ++ |
| A04_Cultural or sport facilities/1 k inhabitants | 0.715 | 1.468 | 1.941 | 3.067 | *** | 9.37 | 0.835 | +++ |
| A05_Facilities/1 k inhabitants | 4.08 | 8.31 | 7.51 | 7.25 | *** | 11.1 | 0.412 | + |
| B01_Percentage of dwellings no running water | 0.906 | 2.836 | 3.156 | 6.471 | *** | 8.15 | 0.793 | ++ |
| B02_Percentage of dwellings with gas | 22.77 | 33.76 | 12.31 | 28.29 | *** | 8.67 | −0.30 | − |
| B03_Percentage of dwellings with telephone | 86.96 | 17.48 | 63.45 | 23.69 | *** | 23.2 | −1.34 | − − − |
| C01_Percentage of street cleaning complaints | 35.09 | 19.82 | 21.22 | 22 | *** | 14.7 | −0.69 | − − |
| C02_Percentage of crime complaints | 25.32 | 23.66 | 4.942 | 10.61 | *** | 45.0 | −0.86 | − − − |
| D01_Population | 1367 | 518 | 900.2 | 410.5 | *** | 26.6 | −0.90 | − − − |
| D02_Average age population | 38.00 | 4.407 | 42.73 | 4.015 | *** | 27.6 | 1.073 | +++ |
| D03_Percentage of births | 11.31 | 3.209 | 9.541 | 2.78 | *** | 14.9 | −0.55 | − − |
| D04_Percentage of men | 0.491 | 0.023 | 0.519 | 0.019 | *** | 9.85 | 0.432 | + |
| D05_Percentage of women | 0.509 | 0.023 | 0.481 | 0.019 | *** | 9.85 | −0.43 | − |
| E01_People per building | 14.46 | 22.91 | 2.43 | 3.79 | *** | 74.5 | −0.52 | − − |
| E02_Percentage of households 1 adult | 18.80 | 7.548 | 27.86 | 7.369 | *** | 28.8 | 1.200 | +++ |
| E03_Porcent. of households 1 adult and minor | 1.832 | 1.115 | 1.278 | 0.923 | *** | 14.0 | −0.49 | − |
| E04_Percentage of households with 2 adults | 41.24 | 6.749 | 41.00 | 5.11 | ns | 1.07 | −0.03 | |
| E05_Percentage of households with 3 adults | 18.40 | 3.363 | 16.53 | 3.129 | *** | 14.0 | −0.55 | − − |
| E06_Percentage of households with 4 adults | 19.71 | 6.639 | 13.31 | 4.701 | *** | 31.9 | −0.96 | − − − |
| E07_Homes | 449.2 | 167.5 | 340.2 | 145.7 | *** | 17.5 | −0.65 | − − |
| E08_Inhabitants per household | 3.035 | 0.359 | 2.618 | 0.305 | *** | 32.0 | −1.15 | − − − |
| E09_Ratio of residential buildings/household | 0.742 | 0.564 | 1.417 | 0.476 | *** | 33.1 | 1.195 | +++ |
| F01_Percentage of rooted population | 80.10 | 9.491 | 82.19 | 4.996 | *** | 9.78 | 0.219 | + |
| F02_Percent. of provincial immigrant populat. | 3.871 | 5.813 | 3.833 | 3.524 | ns | 0.25 | −0.01 | |
| F03_Percent. of regional immigrant population | 1.349 | 1.278 | 0.966 | 1.088 | *** | 8.24 | −0.29 | − |
| F04_Percent. of national immigrant population | 1.582 | 1.326 | 1.886 | 1.586 | *** | 4.50 | 0.229 | + |
| F05_Percent. of foreign immigrant population | 1.317 | 2.794 | 1.131 | 1.946 | * | 2.23 | −0.06 | |
| F06_Percentage from Spain | 97.92 | 4.58 | 98.58 | 2.68 | *** | 5.79 | 0.144 | |
| F07_Percentage from EU | 0.77 | 2.967 | 0.819 | 2.205 | ns | 0.52 | 0.016 | |
| F08_Percentage from non-EU Europe | 0.181 | 0.56 | 0.119 | 0.376 | *** | 3.85 | −0.11 | |
| F09_Percentage from North America | 0.049 | 0.181 | 0.016 | 0.076 | *** | 10.2 | −0.18 | |
| F10_Percentage from Central America | 0.036 | 0.088 | 0.014 | 0.048 | *** | 10.8 | −0.25 | − |
| F11_Percentage from South America | 0.412 | 0.827 | 0.202 | 0.473 | *** | 10.3 | −0.25 | − |
| F12_Percentage from Asia | 0.083 | 0.337 | 0.019 | 0.118 | *** | 12.6 | −0.18 | |
| F13_Percentage from Africa | 0.543 | 2.011 | 0.226 | 1.052 | *** | 7.08 | −0.15 | |
| F15_Percentage from Oceania | 0.003 | 0.022 | 0.001 | 0.011 | *** | 3.53 | −0.08 | |
| F16_Percentage Statelessness | 0.000 | 0.006 | 0 | 0 | *** | − | −0.04 | |
| G01_Percentage working in the province | 6.428 | 5.484 | 6.808 | 4.43 | * | 2.00 | 0.069 | |
| G02_Percentage working in region | 0.867 | 0.999 | 0.975 | 0.948 | ** | 2.65 | 0.107 | |
| G03_Percentage working in Spain | 0.472 | 0.568 | 1.001 | 1.256 | *** | 9.87 | 0.929 | +++ |
| G04_Percentage working in another country | 0.12 | 0.289 | 0.162 | 0.534 | ns | 1.85 | 0.146 | |
| H01_Percentage of employed population | 33.19 | 6.505 | 27.37 | 7.108 | *** | 19.1 | −0.89 | − − − |
| H02_Percentage of population unemployed | 10.47 | 5.106 | 12.94 | 7.532 | *** | 7.68 | 0.483 | + |
| H03_Percentage of inactive population | 38.02 | 7.242 | 43.94 | 7.253 | *** | 19.1 | 0.817 | +++ |
| I01_Commercial establishment/1 k inhabitants | 26.9 | 98.9 | 19.4 | 20.9 | *** | 8.40 | −0.07 | |
| I02_Office and services/1 k inhabitants | 10.7 | 44.6 | 8.1 | 12.2 | *** | 5.08 | −0.05 | |
| I03_Industrial/1 k inhabitants | 3.07 | 12.11 | 3.63 | 7.94 | ns | 1.66 | 0.046 | |
| I04_Premises dedicated to farming/1 k inhab. | 0.65 | 6.71 | 3.14 | 19.84 | ** | 2.95 | 0.371 | + |
| I05_Inactive premises/1 k inhabitants | 13.37 | 20.22 | 19.63 | 29.47 | *** | 4.98 | 0.309 | + |
| J01_Combined HDI - | −0.002 | 0.004 | 0.001 | 0.002 | *** | 8.98 | 0.222 | + |
| J02_Combined HDI + | 0.000 | 0.000 | 0.000 | 0.000 | ns | 1.29 | −0.03 | |
| J03_Combined HDI | −0.002 | 0.004 | 0.000 | 0.003 | *** | 8.79 | 0.220 | + |
| K01_Percent. active pop. employed in farming | 4.161 | 6.062 | 7.275 | 5.736 | *** | 12.7 | 0.513 | ++ |
| K02_Percent. active pop. employed in fisheries | 0.139 | 0.593 | 0.026 | 0.123 | *** | 21.6 | −0.19 | |
| K03_Percent. active pop. employed in industry | 3.809 | 2.46 | 2.814 | 2.178 | *** | 10.7 | −0.40 | − |
| K04_P. active p. employed in construction | 4.471 | 2.442 | 4.352 | 2.081 | ns | 1.34 | −0.04 | |
| K05_P. active p. employed in the service sector | 20.60 | 8.115 | 12.90 | 4.829 | *** | 37.3 | −0.95 | − − − |
| K06_Percent. active population unemployed | 24.09 | 11.26 | 31.61 | 16.40 | *** | 10.7 | 0.668 | ++ |
| L01_Percentage of dwelling owned | 82.28 | 13.3 | 82.73 | 10.1 | ns | 1.02 | 0.033 | |
| L02_Percentage of dwellings for rent | 9.393 | 11.28 | 5.046 | 5.163 | *** | 19.7 | −0.38 | − |
| L03_P. of housing not rented and not owned | 8.324 | 8.686 | 12.22 | 9.616 | *** | 9.52 | 0.449 | + |
| M01_Construction status (M) | 1.165 | 0.206 | 1.230 | 0.197 | *** | 7.77 | 0.316 | + |
| M02_Construction status (SD) | 0.395 | 0.233 | 0.501 | 0.208 | *** | 11.9 | 0.451 | + |
| N01_Percentage of illiteracy | 4.631 | 3.766 | 6.811 | 3.825 | *** | 13.3 | 0.579 | ++ |
| Measurements | Population | Profile 4 | ||||||
|---|---|---|---|---|---|---|---|---|
| 5381cs (100%) | 550cs (10.22%) | |||||||
| M | SD | M | SD | C | T | ES | ES | |
| O01_Percentage of dwellings with garage | 19.03 | 18.79 | 16.7 | 14.07 | *** | 3.88 | −0.12 | |
| O02_Percentage of non-accessible dwellings | 72.81 | 30.4 | 87.94 | 22.67 | *** | 15.6 | 0.497 | + |
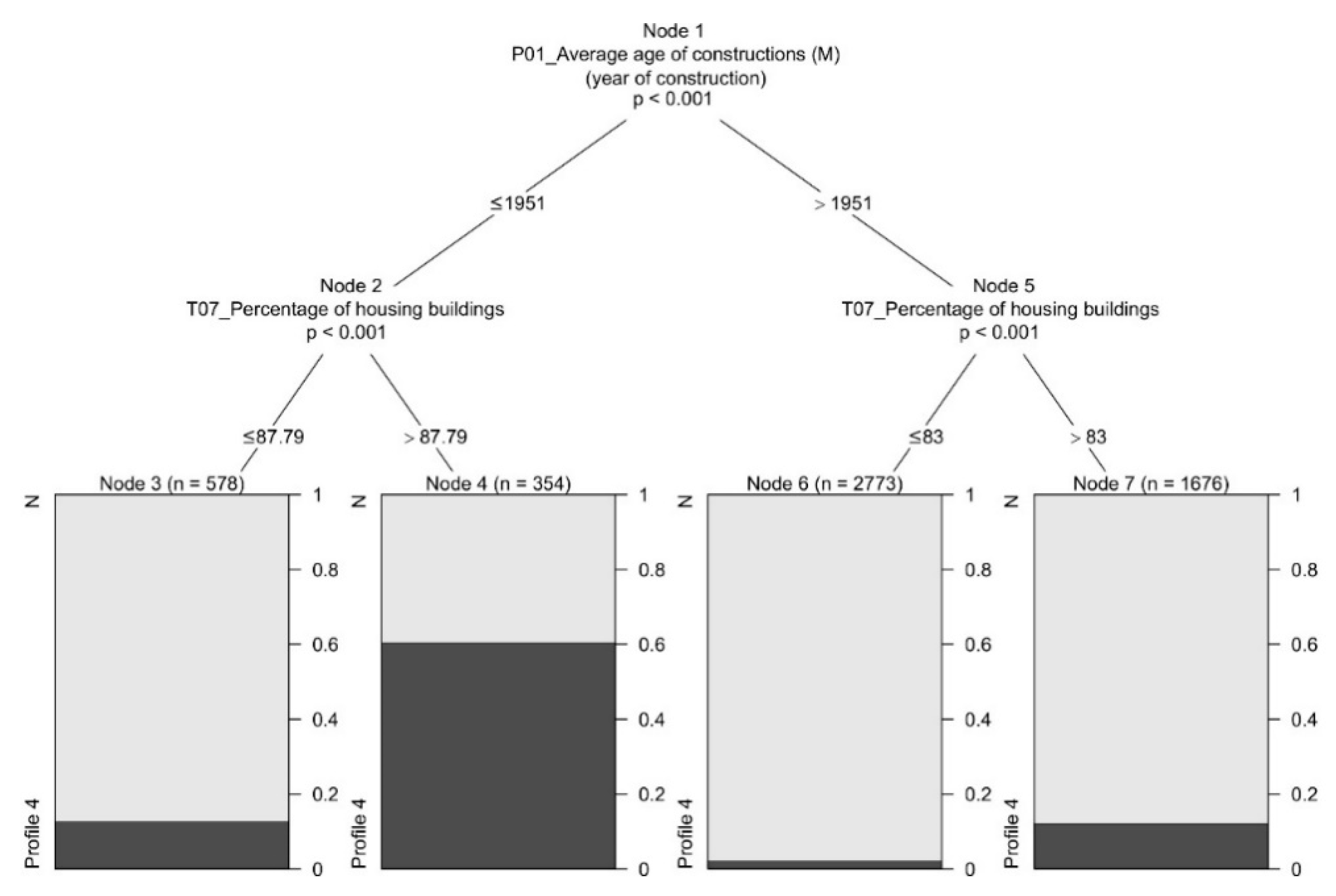
| P01_Average age of constructions (year) (M) | 1963 | 20 | 1942 | 28.1 | *** | 17.1 | −1.01 | − − − |
| P02_Average age of Constructions (year) (SD) | 23.38 | 14.79 | 37.00 | 14.78 | *** | 21.6 | 0.920 | +++ |
| Q01_Percentage of complaints outside noise | 32.52 | 18.35 | 13.15 | 15.82 | *** | 28.7 | −1.06 | − − − |
| Q02_Percentage of pollution complaints | 19.46 | 14.82 | 8.114 | 11.65 | *** | 22.8 | −0.77 | − − |
| R01_Average height of constructions (M) | 2.678 | 1.603 | 1.701 | 0.507 | *** | 45.2 | −0.61 | − − |
| R02 Average building height (SD) | 5.463 | 5.272 | 1.943 | 1.338 | *** | 61.7 | −0.67 | − − |
| S01_Housing buildings | 327.5 | 292.7 | 460.1 | 225.3 | *** | 13.8 | 0.453 | + |
| T01_Percentage of single-family dwellings | 61.1 | 33.88 | 87.48 | 13.05 | *** | 47.4 | 0.779 | ++ |
| T02_Percent. grouped single-family dwelling | 21.66 | 21.86 | 8.52 | 8.7 | *** | 35.4 | −0.60 | − − |
| T03_P. single-family dwell. with commercials | 17.04 | 24.09 | 3.94 | 6.38 | *** | 48.1 | −0.54 | − − |
| T04_Percentage of multi-family dwellings | 0.196 | 0.795 | 0.057 | 0.2 | *** | 16.3 | −0.17 | |
| T05_Percentage commercial b. with dwellings | 0.8 | 2.585 | 0.239 | 0.742 | *** | 17.7 | −0.22 | − |
| T06_Percentage of commercial buildings | 8.93 | 19.87 | 6.95 | 7.79 | *** | 5.95 | −0.10 | |
| T07_Percentage of housing buildings | 0.08 | 1.047 | 0.22 | 1.79 | ns | 1.84 | 0.134 | |
| U01_ P. complaints poor communications | 13.94 | 15.95 | 15.06 | 20.53 | ns | 1.27 | 0.069 | |
| U02_P. of complaints about scarce green areas | 48.84 | 25.97 | 37.59 | 31.06 | *** | 8.49 | −0.43 | − |
| V01_Percentage of dwellings with no toilets | 1.319 | 2.947 | 2.197 | 5.114 | *** | 4.03 | 0.298 | + |
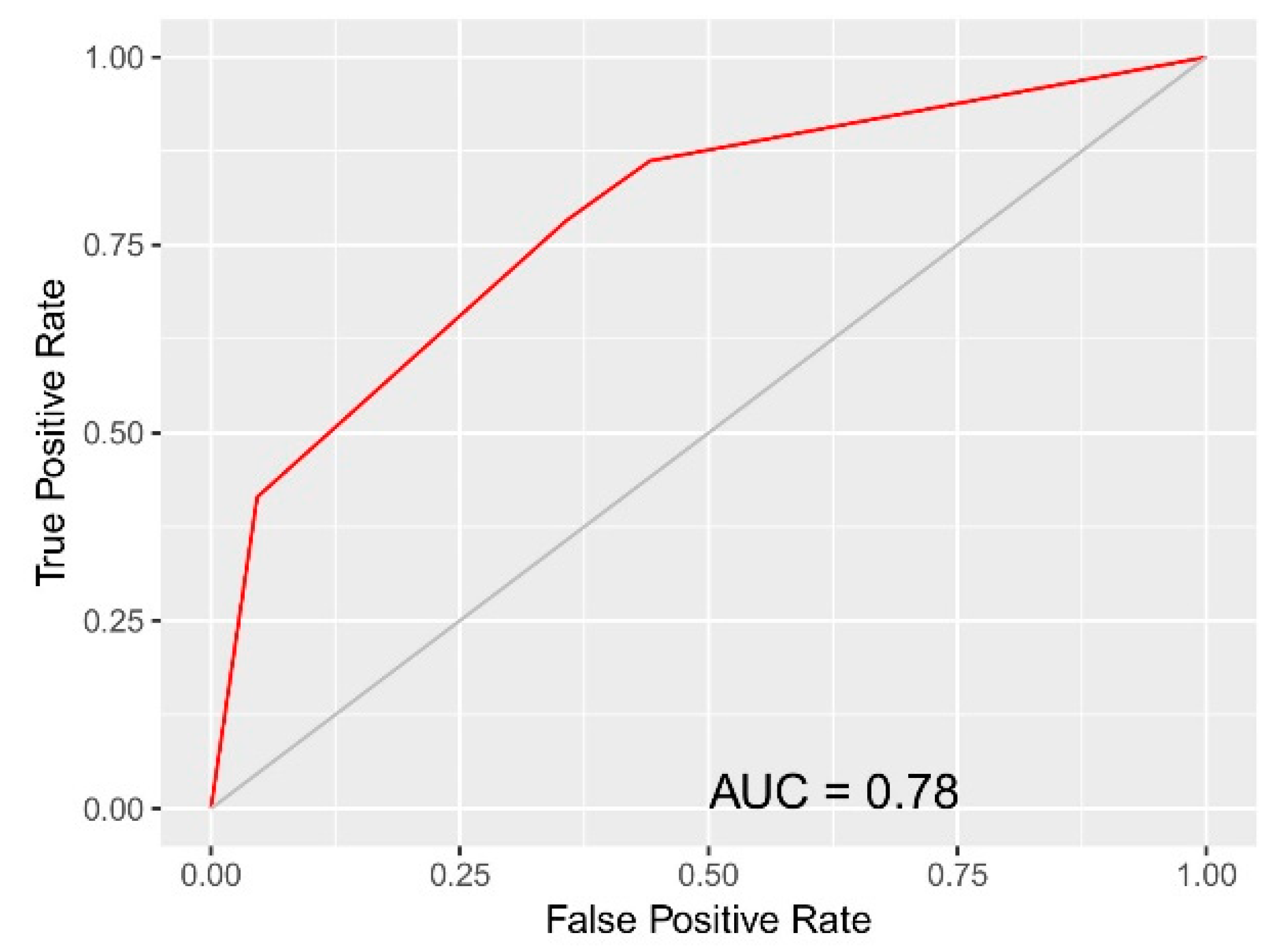
| True Condition (Population in Deprived Areas) 1 | Total Cumulative | |||
|---|---|---|---|---|
| Condition Positive | Condition Negative | |||
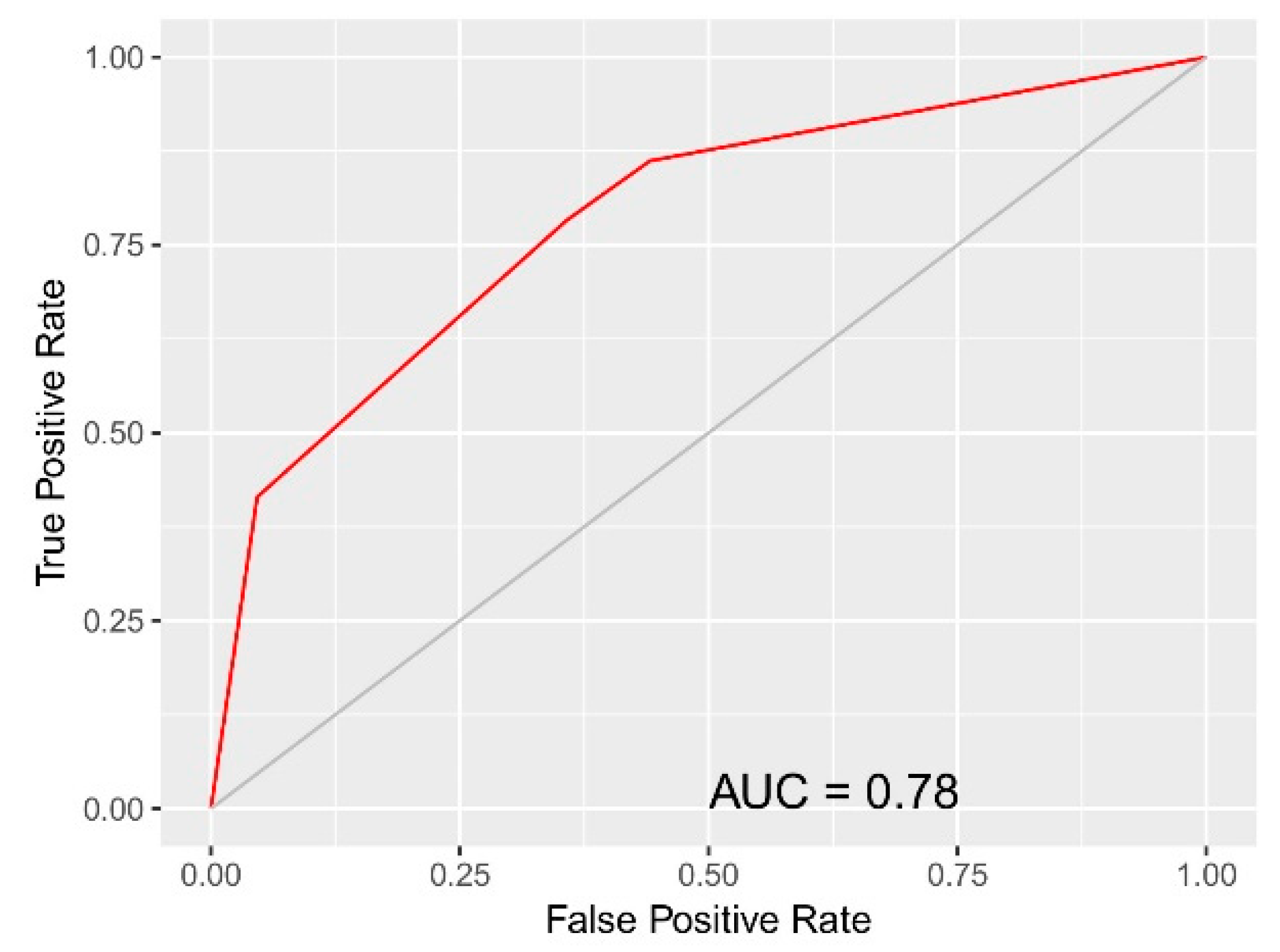
| Predicted condition (Predicted as Profile 4) | Predicted positive | 60 (TP) | 412 (FP) | 472 |
| Predicted negative | 4 (FN) | 1499 (TN) | 1503 | |
| Total cumulative | 64 | 1911 | 1975 | |
| Province | Municipality | Population 2006 1 | Population in Deprived Areas (%) 1 | Model 1: Population in Profile 4 (%) | Model 2: Predicted Probability of Profile 4 (%) |
|---|---|---|---|---|---|
| Almería | Almócita | 156 | 100 | 100 | 60 (max.) |
| Alsodux | 131 | 100 | 100 | 60 (max.) | |
| Beires | 128 | 100 | 100 | 13.50 | |
| Benitagla | 66 | 100 | 100 | 60 (max.) | |
| Canjáyar | 1561 | 58.62 | 100 | 60 (max.) | |
| Cóbdar | 192 | 100 | 100 | 60 (max.) | |
| Ohanes | 765 | 100 | 100 | 60 (max.) | |
| Sta. Cruz de Marchena | 245 | 100 | 100 | 60 (max.) | |
| Turrillas | 249 | 100 | 100 | 60 (max.) | |
| Tres Villas (Las) | 581 | 100 | 100 | 60 (max.) | |
| Cádiz | San José del Valle | 4244 | 67.95 | 0 | 3 to 13.5 2 |
| Córdoba | Conquista | 486 | 100 | 100 | 60 (max.) |
| Granada | Agrón | 283 | 100 | 100 | 60 (max.) |
| Albondón | 914 | 100 | 100 | 12.5 | |
| Albuñán | 448 | 100 | 100 | 13.5 | |
| Almegíjar | 421 | 100 | 100 | 60 (max.) | |
| Cástaras | 259 | 100 | 100 | 60 (max.) | |
| Cortes de Baza | 2206 | 55.03 | 100 | 13.5 to 602 | |
| Darro | 1438 | 100 | 0 | 13.5 | |
| Freila | 1074 | 100 | 100 | 12.5 | |
| Gorafe | 526 | 100 | 100 | 60 (max.) | |
| Itrabo | 1117 | 100 | 100 | 12.5 | |
| Lobras | 121 | 100 | 100 | 60 (max.) | |
| Lugros | 367 | 100 | 100 | 60 (max.) | |
| Lújar | 491 | 100 | 100 | 13.5 | |
| Orce | 1387 | 100 | 100 | 60 (max.) | |
| Polopos | 1557 | 100 | 0 | 12.5 | |
| Soportújar | 265 | 100 | 100 | 13.5 | |
| Villanueva Torres | 778 | 100 | 100 | 3 | |
| Nevada | 1179 | 100 | 100 | 60 (max.) | |
| Guajares (Los) | 1337 | 100 | 100 | 13.5 | |
| Huelva | Cumbres Enmedio | 44 | 100 | 100 | 60 (max.) |
| Cumbres S. Bartolomé | 490 | 100 | 100 | 60 (max.) | |
| Valdelarco | 237 | 100 | 100 | 60 (max.) | |
| Jaén | Chiclana de Segura | 1191 | 60.20 | 100 | 60 (max.) |
| Espelúy | 750 | 100 | 100 | 60 (max.) | |
| Génave | 565 | 100 | 100 | 60 (max.) | |
| Hinojares | 446 | 100 | 100 | 60 (max.) | |
| Hornos | 663 | 100 | 100 | 60 (max.) | |
| Santiago Calatrava | 883 | 100 | 100 | 13.5 | |
| Málaga | Atajate | 142 | 100 | 0 | 13.5 |
| Benadalid | 258 | 100 | 100 | 13.5 | |
| Benarrabá | 538 | 100 | 100 | 13.5 | |
| Sedella | 646 | 100 | 100 | 60 (max.) | |
| Sevilla | Villanueva Río-M | 5217 | 83.21 | 0 | 3 to 12.5 2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abarca-Alvarez, F.J.; Reinoso-Bellido, R.; Campos-Sánchez, F.S. Decision Model for Predicting Social Vulnerability Using Artificial Intelligence. ISPRS Int. J. Geo-Inf. 2019, 8, 575. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8120575
Abarca-Alvarez FJ, Reinoso-Bellido R, Campos-Sánchez FS. Decision Model for Predicting Social Vulnerability Using Artificial Intelligence. ISPRS International Journal of Geo-Information. 2019; 8(12):575. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8120575
Chicago/Turabian StyleAbarca-Alvarez, Francisco Javier, Rafael Reinoso-Bellido, and Francisco Sergio Campos-Sánchez. 2019. "Decision Model for Predicting Social Vulnerability Using Artificial Intelligence" ISPRS International Journal of Geo-Information 8, no. 12: 575. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi8120575