1. Introduction
Protected Areas (PA) are dynamic systems that need to be studied and managed to preserve the ecosystem services they provide. Some parts of the areas are difficult to access and there is a limited budget for collecting comprehensive in-situ data for exhaustively covering the whole area. Remote sensing (RS) data offer an alternative way of obtaining a regular flow of information. Currently, many Earth Observation (EO) satellites provide a homogeneous coverage that, in some cases, is made available to everyone for free. For example, optical satellites return raw RS data that is structured in images to record the reflectance of the Earth at different wavelengths (one band for each). Reflectance cannot be directly interpreted and must be converted into a set of higher-level products estimating comparable variables or are proxies for the values measured with sensors on the ground. Some of these products are directly related to vegetation characteristics, such as leaf area index, gross primary production, vegetation wetness and height, tree cover density, vegetation composition, and classification, among others. Many of these are now considered essential biodiversity variables [
1,
2]. Potentially, the raw data is received at regular intervals and the products can be computed to obtain long time series of homogeneous variables. Provided the series is long enough, it can be used to separate seasonality and trends [
3], study the impacts of climate change on the Earth’s ecosystems, its disturbances, resilience and adaptation. Examples of products that are only possible with the availability of time series are forest disturbances, phenology, fire occurrence, hydroperiod, etc.
Currently, the RS processing facilities are automated and the data are readily available on the Internet [
4], but despite the great progress, PA managers face several problems when they try to use RS data that are related to big data issues: a huge amount of data needs to be stored and processed (volume), there is a diversity of formats (variety), and the uncertainty (veracity) is heterogeneous or unknown. In addition, the complexity results in slow processing (velocity) as a consequence of not having the right tools or technical skills for visualizing, analyzing and interpreting the data easily and thus extracting the necessary information [
5]. Geospatial web services are particularly suitable for visualizing geospatial data and the results of analytical processes [
5]. Open Geospatial Consortium (OGC) standards facilitate discovery, visualization, delivery and reuse of geospatial data [
6]. OGC Web Map Service (WMS) [
7] and Web Map Tile Service (WMTS) are common solutions applied in map clients that combine information coming from more than one server [
8]. In WMS a pictorial representation at screen resolution is sent to a client, which presents it. This strategy has the inconvenience that the client does not receive the actual values of the spatial distribution of the variables. Following the statistics provided by Lopez-Pellicer et al. in 2011 [
9], there are only 25% active downloading services as a proportion of the active WMS services. Assuming that the current situation persists, adding extra functionalities directly to WMS clients and services to support some analytical capacity could have a big impact.
The usefulness of a platform able to visualize vegetation indices, data filtering and time series analysis has been demonstrated [
10]. Ideally, a frontend element should be a web client in conjunction with OGC services. One important limitation of the first version of web client languages, such as JavaScript, was the impossibility of getting additional data without giving up the current screen content. Some developers found a solution in a library that was originally designed for requesting additional XML data that is then combined with the data already present on the web page. This technique was used to create a desktop-like geospatial sharing and visualizing portal in the GeoBrain Online Analysis System (GeOnAS) [
11]. In GeOnAS, the XMLHttpRequest() JavaScript function is used to request data asynchronously to a servlet that provides an XML answer. Once the data are received, the JavaScript code shows parts of the data in web forms, while other parts are sent to a Google maps API for graphical display. In the meantime, commonly used web map browser libraries, such as Leaflet, improved vector visualization in the client side (e.g., based on SVG) and vector analytical tools but raster manipulation is still rare. Fortunately, HTML5 incorporated the canvas API, which provides access to a comprehensive raster and vector graphics library for map browsers. Soon, developers realized the potential of this addition for displaying feature-based geospatial information as vectors [
12]. The canvas API can also be used for representing raster based information (using putImageData()), but this has not been exploited much so far [
13].
To exchange RS data, the geospatial standards define the concept of coverage. In a grid coverage, space is described by a set of dimensions that are sampled at defined intervals. Each position in the grid has a value. To be able to support coverages directly in a web browser, we need to deal with arrays of values. Arrays are an intrinsic part of the JavaScript data model and they are embedded in the code or can be delivered as lists of values in XML or JSON format [
14]. These text-based encodings are considered to be inefficient. Instead, most coverage formats use binary arrays of a specific number of bytes. HTML5 can deal with binary arrays that are stored in buffers that can be queried using functions like getInt16(), getFloat32(), etc. This approach has been used by the creators of the open source geotiff.js library at the EOX IT company [
15]. The library is capable of reading a GeoTIFF file directly in the browser and creating a dynamic visualization of it (with zoom and pan capabilities). Apart from building RGB compositions, when using plotty.js, a palette can be added to the data dynamically. The approach moves the grid transformation efforts from the server side to the client side [
16].
In this paper, we propose a solution consisting of implementing a modern web client that is able to combine AJAX, binary arrays, canvas API and the OGC WMS protocol to manage RS data structured in coverages. The proposed solution empowers the client with functionalities that were reserved for desktop GIS, such as dynamic queries, spatial filters, enhance contrast, change palettes, generate diagrams (e.g., histograms and pie charts), animations, time series profiles and complex calculations using several bands or products of the different available datasets. Today, doing calculations and analysis on the client side is really innovative. One of the few available examples on the Internet doing something similar is the JavaScript walkshed.js library, which is able to perform a cost-distance raster calculation in the client side [
17]. By using WMS, data are transferred at screen resolution. Resolutions of current screens are limited to a certain amount of pixels, and therefore, server-side generalization is necessary. Generalization is a cartographical tool that, in our case, reduces the amount of information by reducing the values in the coverage fitted in a single screen pixel to a single value by applying statistical interpolation. Some interpolation functions create a “nicer” visualization than others. The term “nice” is related to the human perception of the world, and the generalization method should obtain a visualization that resonates with our perception of reality. Human perception is good for identifying entities in images that fit with our mental model of reality. This is why we understand the classes obtained from image classification easily. Classes obtained from image classification do not always correspond to certain cartographic objects, as their spatial appearances are usually heterogeneous and their class membership may be uncertain [
18]. It is necessary to preserve elements in images by grouping things in a way that creates a visualization that preserves features that humans find “natural” in a map and that fits better with our perception of the world [
19]. Depending on the statistics that are applied to create the interpolated views, some elements will be removed, thus creating a more continuous view (e.g., mode interpolation), or some small structures will be partially saved, which might create artifacts in the pictorial representations (e.g., nearest neighbor).
In this paper, the generalized data will not only be used in visualizations, but we will also make some preliminary analyses on the simplified data. This study considers the impact that simplification has on both visualization and the statistical uncertainties induced when an analysis is made at screen resolution. In summary, the simplified map should have a low uncertainty interpolation system to ensure validity of the analysis (e.g., preserving the statistical proportions of the classes) and preserve visually satisfactory perception. While the first factor can be mathematically demonstrated and its uncertainties assessed, the second is related to subjective perception of continuity and connectivity. We will quantify the uncertainties of different interpolation methods to demonstrate that methods that are known to produce better visual perception still provide reasonably low uncertainties. The paper is structured as follows.
Section 2 introduces the datasets collected or produced in ECOPotential and the functionalities implemented in the map browser.
Section 3 quantifies the impact of generalization statistical operations depending on the interpolation strategy.
Section 4 discusses the results, and
Section 5 provides the main conclusions.
2. Materials and Methods
2.1. Datasets
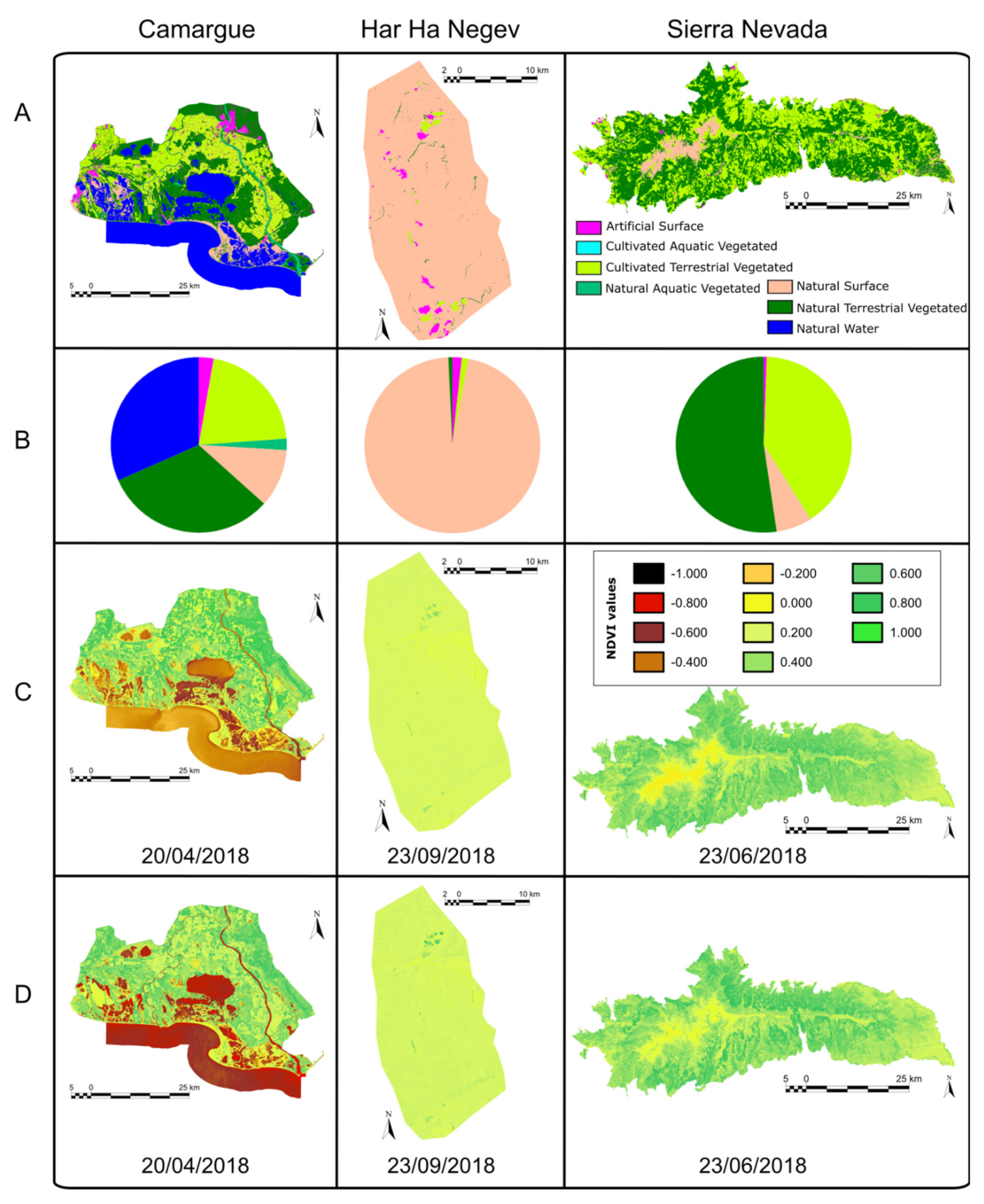
ECOPotential is a large European-funded H2020 project that focuses its activities and pilot actions on a targeted set of 23 internationally recognized PAs in Europe, European territories and beyond, blending EO from RS and field measurements, data analysis and modeling of current and future ecosystem conditions and services. These PAs include mountain (M), arid and semi-arid (A) and coastal and marine (C) ecosystem types (see
Table 1). Annual average temperatures for the arid/semi-arid ecosystems considered in ECOPotential partly surpass 20 °C (e.g., Har HaNegev, Kruger National Park). Annual precipitation can even fall below 100 mm (Har HaNegev). The variability among the PAs is strongly dependent on differences in elevation (e.g., >2400 m for Samaria in comparison with <400 m in Alta Murgia or Kruger National Park). Climatic conditions for the coastal and/or marine PAs considered in the ECOPotential range from the boreal zone (Curonian Lagoon) to the tropics (Caribbean) with a strong contribution from the Mediterranean regions [
20].
Several products have been elaborated or collected for these PAs by ECOPotential partners and presented in a map browser: leaf area index, biomass, indices such as Normalized Difference Vegetation Index (NDVI) and Enhanced Vegetation Index (EVI), fragmentation, disturbances, gross primary production, vegetation wetness, vegetation height, phenology, fire occurrence, normalized burn ratio, tree cover density, nutrients, vegetation composition, vegetation classification, habitat distribution, water turbidity, hydroperiod, snow cover, organic matter, chlorophyll-A, surface soil moisture, spectral soil quality index, surface albedo, land surface temperature, sea surface temperature, digital elevation model, bare ground, slope, etc. The browser also includes Landsat and Sentinel 2 imagery. Some of these datasets are arranged in time series of different temporal resolutions.
In the first months of the project, a questionnaire was given to 20 of the ECOPotential stakeholders to determine their level of interest in certain topics to guide the activities of the project. The results were collected in deliverable 11.1 [
21]. The conclusion was that stakeholders were equally interested in data collection, data analysis, scientific results and application in PA management. Secondly, when asked for their opinion about the best way to communicate the project results to PA staff or to the general public, in both cases maps and graphics were the preferred media over videos, policy briefs, workshops or training sessions. This convinced us that the best vehicle to communicate the project results was an interactive map browser with different levels of functionality in which basic functions do not require training.
2.2. Map Browser with Analytical Capabilities
The ECOPotential map browser (available in
http://maps.ecopotential-project.eu/) was created in response to user requirements as an evolution of the MiraMon map browser software. The
Protected Areas from Space browser aims to provide a way to discover and explore the potential of RS data for the management of 23 PAs without requiring bulky downloads or setting up complex RS or GIS tools. About one hundred thousand individual RS items were organized in 138 layers, some of them consisting of time series, and thus there were a total of 4277 time frames (see
Table 1). This structure is represented in a hierarchical legend, structured by PA, variable and time instant. Therefore, it is not necessary to elaborate a data discovery mechanism based on a metadata catalog and metadata queries. The map browser makes it possible to discover, visualize, query, animate and download datasets. It also integrates metadata and quality descriptions associated with each layer and the capability to link to the NiMMbus system (developed in the EU H2020 NextGEOSS project) to store geospatial user feedback (GUF). A set of products (extracted from available sources or generated during the project) were organized in a visualization and analysis map browser that lowers the technological barrier to make using RS data less complex. The map browser uses the spatial-cognitive abilities that humans have developed over centuries to navigate through the geographic space. This results in a natural interface in which spatial and thematic information is interlinked [
22]. The technology described in this paper has been implemented in the MiraMon [
23] map browser open-source code (
https://github.com/joanma747/MiraMonMapBrowser). The hardware running the map services is hosted in CREAF facilities in a local installation on a 24 core Intel Xeon computer with 48Gb RAM. The server side is a CGI program maintained as part of the C language-based MiraMon developments. The client is a pure JavaScript composed of 28 modules with a total of 35000 lines of code. Both the service and the client are managed by Internet Information Services version 8.5.
The browser presents the data at predefined zoom levels of 10, 20, 60, 100 and 200 m for PA focused views and 600, 1000, 2000, 6000, 10,000, 20,000 and 60,000 m for general views. For most PAs, the entire extent of the PA fits into a 1000 pixel-wide screen at a 200 m zoom level, while for the smaller PAs, a 100 m zoom level will suffice. We selected 10, 20, 60, 100 and 200 m resolutions for this study because we consider that, at smaller resolutions, the PA looks too small on the screen. With histograms and pie charts, users can easily identify the distribution of the values for a certain layer. The produced histogram or pie chart covers the whole area visible in the map browser. This means that it can include the PA and the surroundings. To prevent the surroundings from contaminating the analysis, a selection operation can be made to exclude the area outside the PA. This is done by filtering out the pixels that are not inside the mask of the PA. This selection is made directly on the client side. The browser also incorporates other analytical functions, such as a layer calculator, confusion matrix assessment and video animations, among others, which are all carried out on the client side at screen resolution [
24].
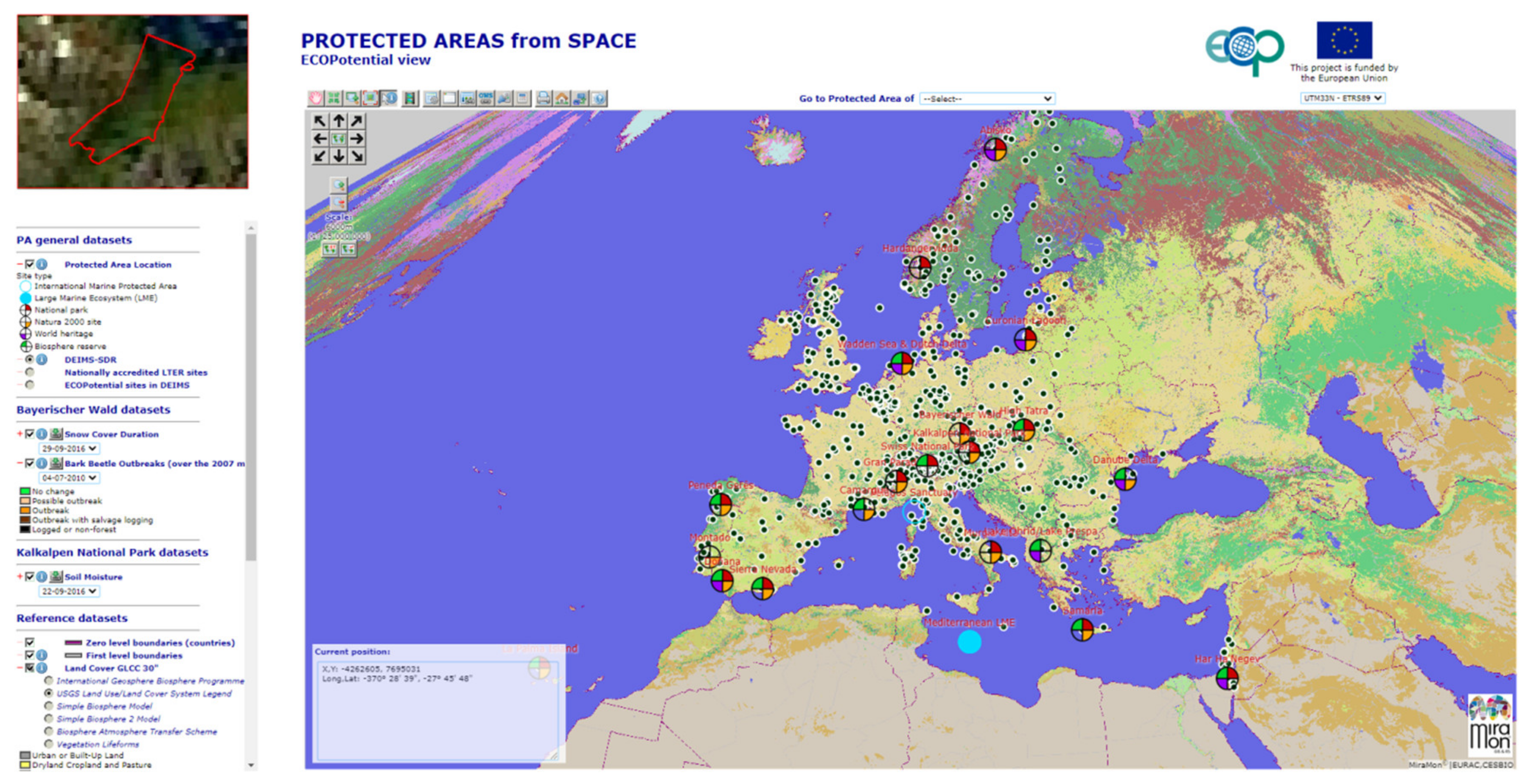
The target audience for the map browser includes PA managers, scientists and decision-makers. PA managers are concerned about their PAs, but scientists and decision-makers could be interested in comparing PAs or in conducting global studies. Therefore, while PA managers might be interested in monitoring specific aspects of their daily job, scientists and decision-makers might need a more general overview. For this reason, we concluded that the map browser should cover all PAs but be able to switch from one PA to another easily. Technically, each PA has its own bounding box and cartographic projection; however, it is possible to switch from one PA to another automatically by simply selecting the PA name in a dropdown list (see
Figure 1).
RS data and derived higher-level products (by analysis or modeling) can be represented as coverages. In the OGC Coverage Implementation Schema (CIS) [
25], a coverage dataset is represented as a range set, a range type and a domain. If the domain can be expressed as a grid, then the range set can be an array of values of a predefined data type (range type). In the presented map browser, data is structured in a set of layers. Each layer is mapped to a specialization of a coverage considered as a regular grid with at least 2 dimensions representing 2 coordinates over the Earth in one or more cartographic projections. Each layer can be represented by a set of range sets (the actual values of the grid), each of which is associated with a value for each extra dimension that the coverage may present. If we follow the GIS and RS tradition, a 2D range set should be transported in raster binary encoding. In this implementation of a map browser we have selected the simplest possible binary encoding, sometimes referred to as the “raw” format. In this format, the values of the grid are represented as an array of binary encoded numbers all of the same binary type. Using the new JavaScript array buffer object, this type of data can be stored in a JavaScript variable. A modified WMS server is used to generate the binary arrays as a return of a common WMS GetMap request with the desired bounding box and the format parameter set to “application/x-img”. In the client, a WMS request is made in an asynchronous mode using the XMLHttpRequest() function configured in a way that allows binary responses. The WMS request is tailored so that the received values correspond one-to-one to the pixels of a map area on the screen. When received, the binary data are stored in an array buffer for later use.
The next step is to represent the data in the map area of the screen. A canvas area is associated with the map area to create the view. By requesting an image to the canvas with the function createImageData(), an array of RGB values covering a predefined set of pixels in the screen is returned ready to be filled. The binary arrays returned by the WMS service are not directly applicable here but can be easily adapted. To allow maximum flexibility, each layer defines a set of styles that are a set of rules for transforming the binary arrays into the proper RGB values that form the colors of an image representing the data. In ECOPotential map browser, a style can have one of the following three modes: color palette, RGB or a more elaborated calculation among bands [
24].
Besides visualization, having the actual array of values directly on the client side opens a new set of possible applications that were not available with a classical WMS approach. If the binary arrays are stored for later use, with a bit of programming, statistical summaries can be easily calculated by the JavaScript code, and one of the available open-source diagram libraries can be used to plot the graphical representations, such as histograms or a pie charts. In our case, we opted for chart.js because it easily allows each bar of a bar chart to have a different color. This characteristic makes it possible to assign a bar representing a range of values the same color, which represents the central value of the range in the map when the styling rules are applied. Another immediate operation that can be improved is the point query, as it does not have to rely on a WMS server-side request (GetFeatureInfo) to get the response. The response can be extracted directly from the store binary array used for creating the view and is fast enough to show the value of all visible layers when hovering over the map with the mouse. This technology also makes it possible to filter out some values of the image that do not meet a condition set by another layer (e.g., represent NDVI values only if the elevation is lower than a certain value or only for a certain land cover category). The style of the generated selection layer can also be edited to adjust the visualization among the values better.
Layers visualized in a single viewport in the overlaying stack are co-registered because they are requested in the same number of columns and rows and the same bounding box, and therefore, all cells have the same pixel size. This means that the JavaScript code can perform pixel by pixel layer calculations using the actual values of the binary arrays and immediately present the result at screen resolution to the user. Calculations can be relatively simple spectral indices, such as EVI or SAVI [
26], or a complex model involving several layers. Internally, the JavaScript code benefits from the eval() function to evaluate any calculation that can be expressed as a pixel by pixel mathematical expression using generic names of layer bands. To visualize the results, a loop for all pixels is made in the viewport. For each pixel, the generic name of the layer bands are replaced by the actual values of that pixel before sending the expression to the JavaScript eval() function to obtain the resulting value of the pixel.
The described methodology executes complex operations at screen resolution on the client side. This has the advantage of giving the user virtual products that were not precalculated on the server side but rather are presented to the user on the fly each time they zoom or pan. This gives the user plenty of options to actually create new band combinations or request new calculations that go far beyond the ones initially foreseen by the map browser creator. Moreover, all the presented results (map visualizations, graphics and statistical summaries) are calculated at screen resolution. How well the calculated results represent the real values that should result from performing the same operations at full resolution on the server side depends on the interpolation method (performed by the server that provides the binary arrays in the first place), on how these uncertainties are propagated in the client’s calculations and on which generalization method is applied.
2.3. Interpolation on the Server Side
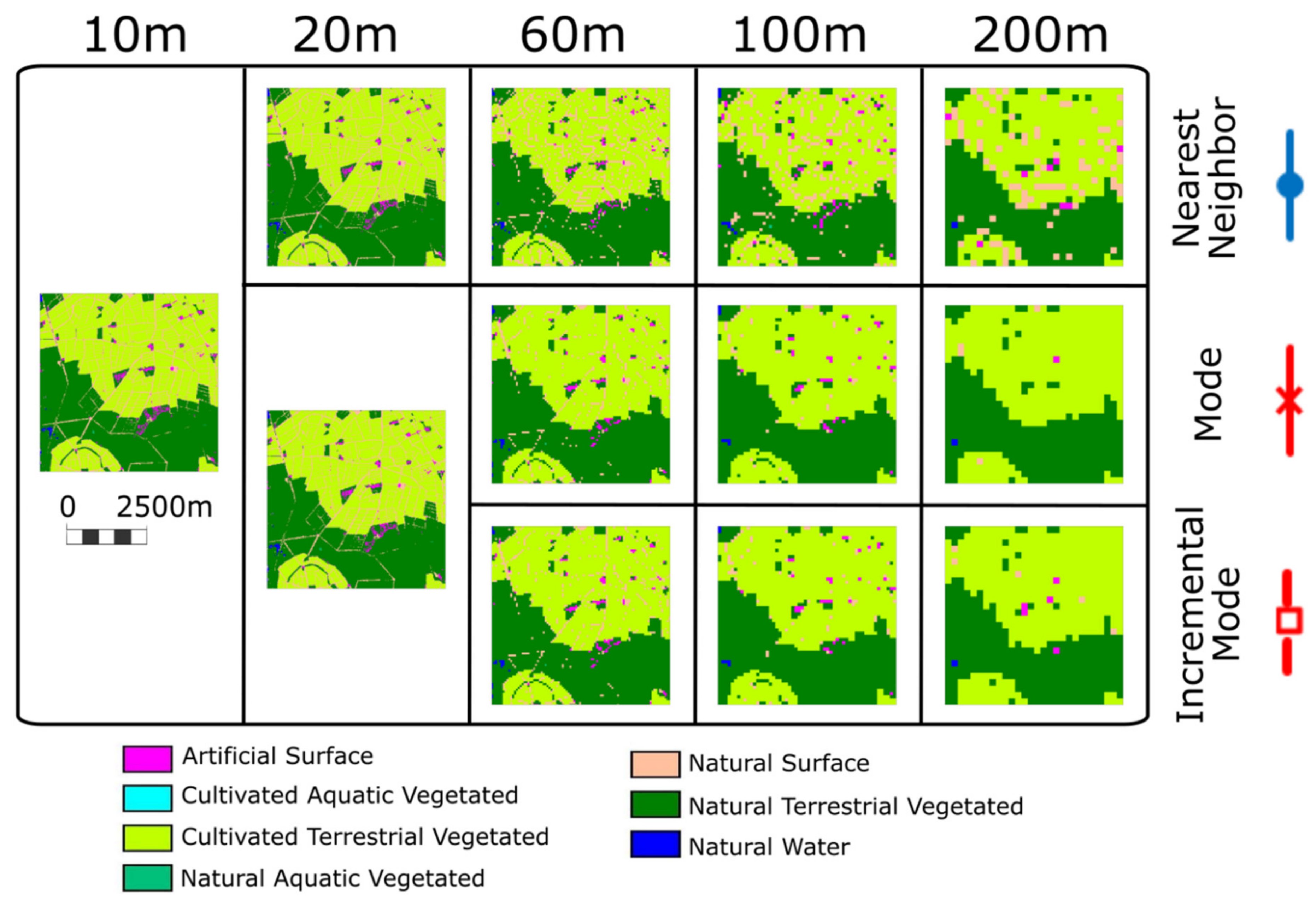
On the server side, each layer is associated with a coverage dataset that has a predefined resolution conditioned by the sensor limitations and the modeling algorithms. For example, a Sentinel 2 satellite image has a minimum pixel size of 10 m. Normally, a computer screen will present the map in an area no bigger than 1000 pixels so that the extent of the data presented is limited at full resolution to a 10 km wide area. However, the areas selected for the ECOPotential project are bigger than that. Therefore, to present the whole PA on the screen, a generalization needs to be made. Thus, in some extreme cases (i.e., Montado, Kruger and the Wadden Sea) a single pixel value is an average of 50 × 50 original cells. In order to respond to a WMS request covering the complete PA, the server needs to interpolate the values of the original coverage. In the second part of the paper we discuss in depth how well the interpolated values represent the real values and the uncertainties that this interpolation introduces.
In order to have fast delivery, our web map browser implementation needs a sequence of fixed interpolated zoom levels to be pre-computed. To minimize the interpolation effects, each less dense interpolated grid is created in a way that completely overlaps with the original grid. This is only possible if an exact multiple of the original resolution is selected for the interpolated grid [
27]. As a consequence, each cell of the interpolated grid exactly overlays a predefined number of cells in the original grid. A common practice in map browsers (e.g., OSM tiles
https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames) is to recursively multiply the cell size by a factor of two [
28,
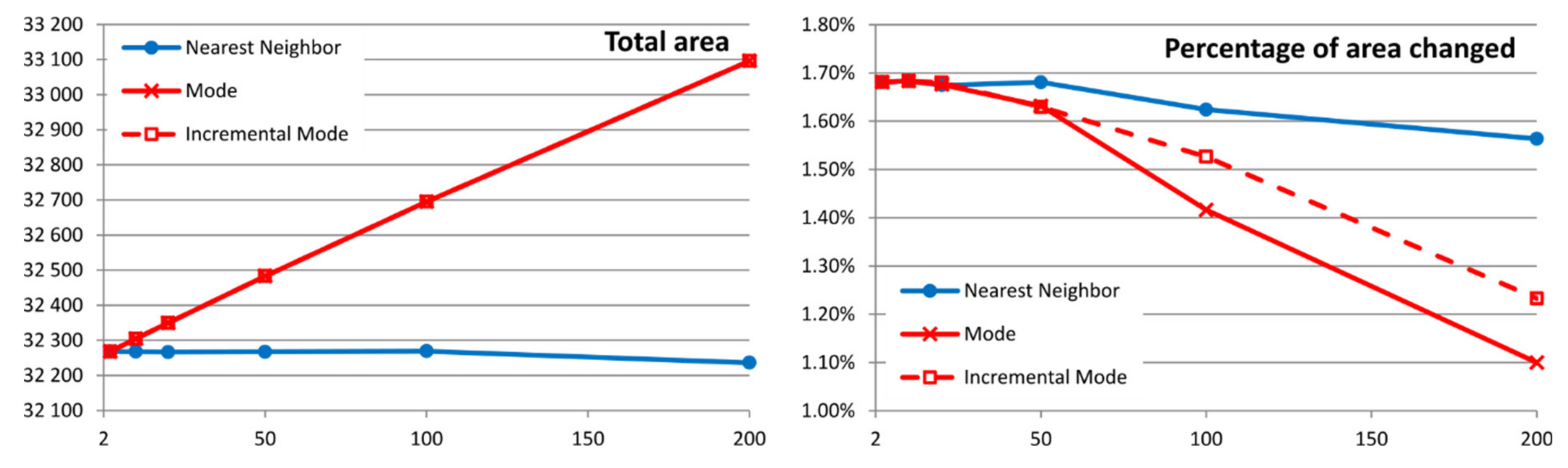
29]. Starting at 10 m, this results in a 20, 40, 80, 160, 320 and 640 m cell size. However, these cell sizes are not appropriate when trying to combine a diverse set of RS products, because most higher zoom levels do not correspond to the common medium resolution satellite product specifications. To mitigate this, starting with a 10 m resolution (used in Sentinel 2 data), we get the first interpolated zoom level by applying a factor of 2 (combining 4 original cells into one) and the next 2 levels by applying a factor of 3 (combining 9 original cells into one) and 5 (combining 25 original cells into one) to the first interpolated zoom level. Then, from the last resulting zoom level, we repeat the process resulting in 20, 60, 100, 200, 600 and 1000 m resolutions. An alternative could be to generate all zoom levels by direct interpolation of the original cells (e.g., generate the 100 m resolution by interpolating 100 cells of the original resolution instead of incrementally by interpolating 25 cells of the 20 m resolution). We call the first process “incremental”, being preferable because it is much faster as it involves less data. However, depending on the interpolation method, results are not identical to the “non-incremental” approach.
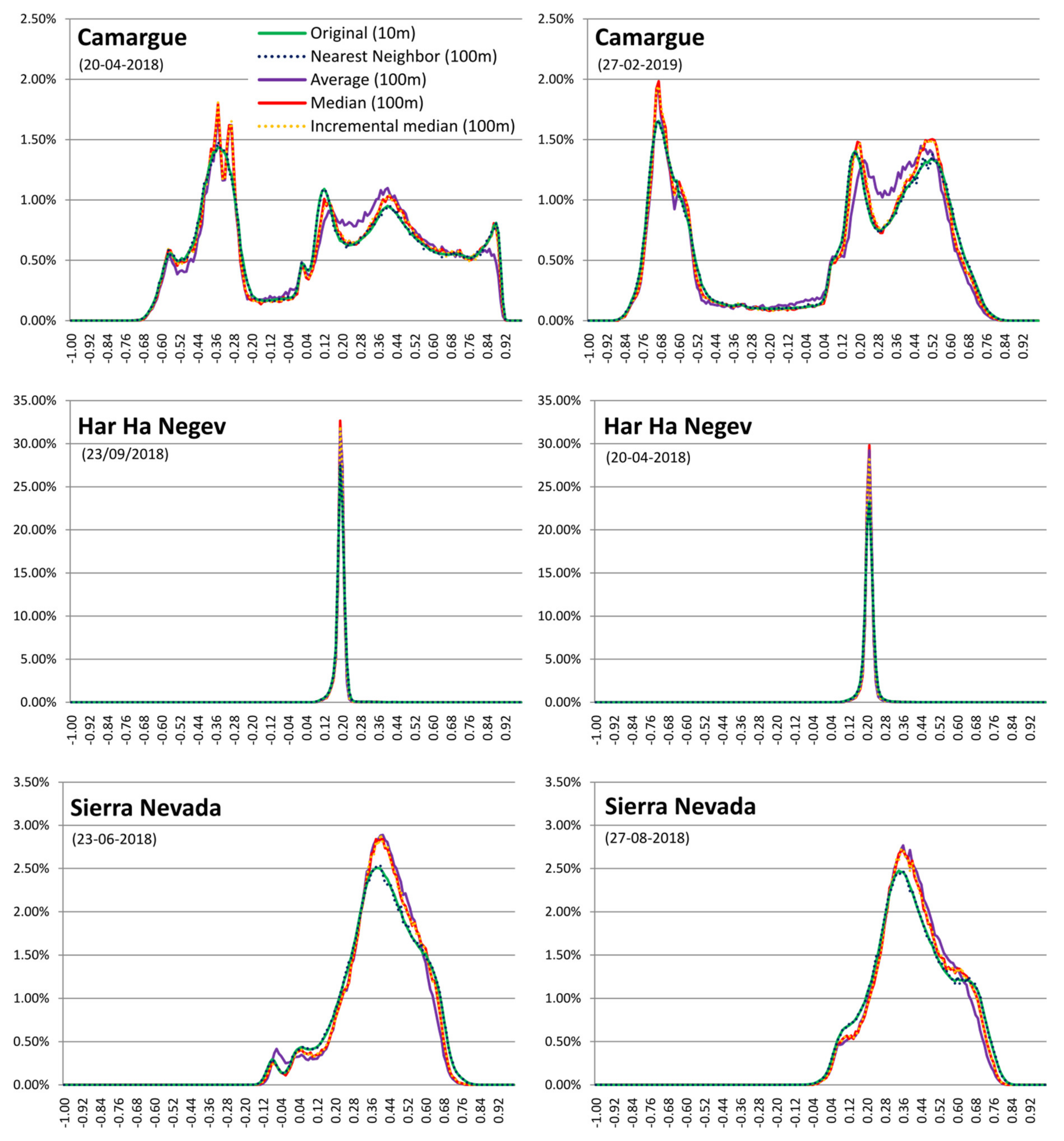
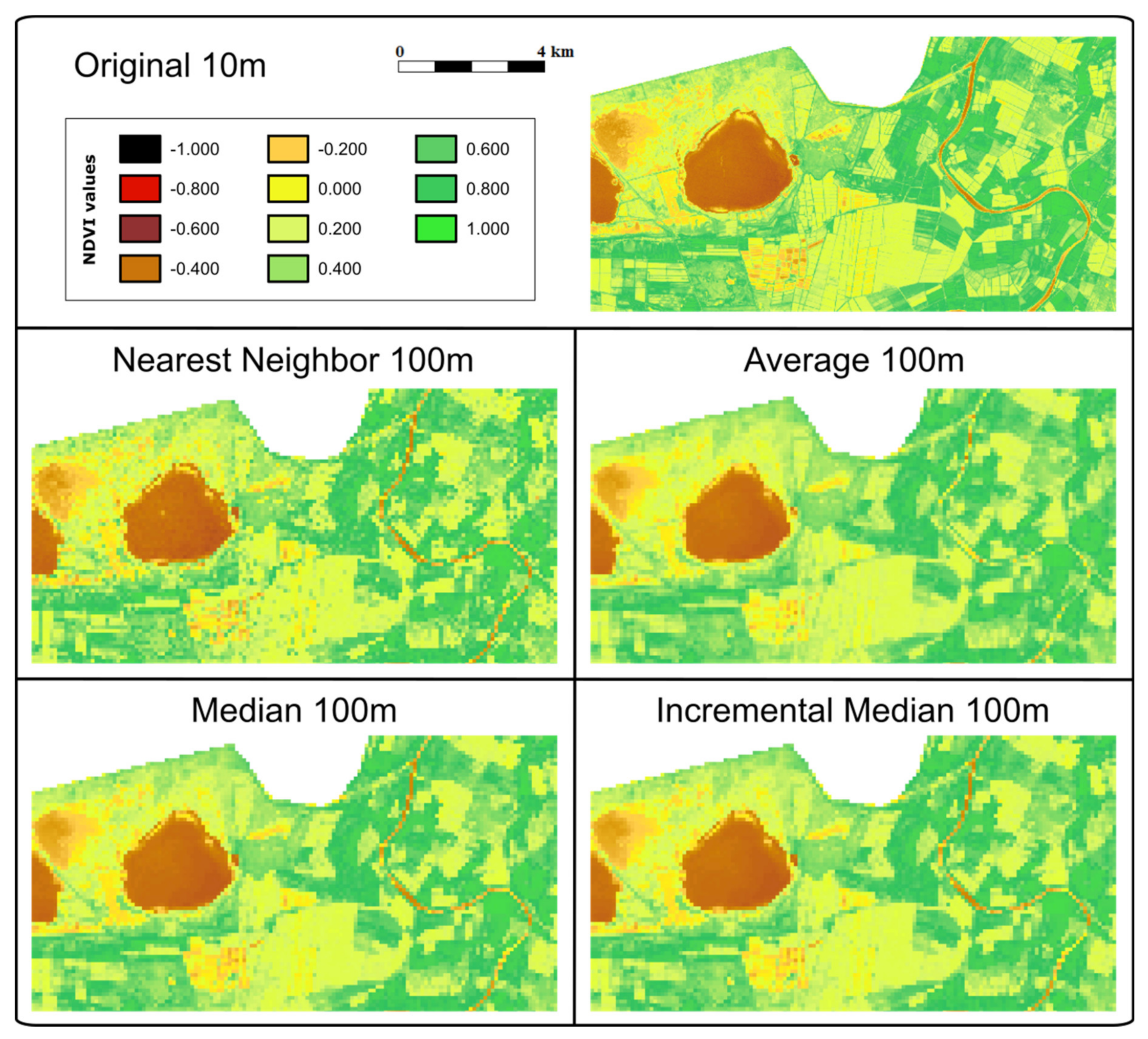
How the interpolated cells are derived from the original cells depends on the type of data. For categorical data, where numbers are actually representing concepts, only interpolations that preserve the individual values are possible, such as the nearest neighbor (NN) and the modal value (mode) generated from the original data (MD) or by increments from previous resolutions (MDi). For continuous values, the nearest neighbor (NN), the mean value (AV) and the median value generated from the original data (ME) or by increments from previous resolutions (MEi) can be used. For the AV and NN methods, results are not affected by using the original values or generating them by increments, and therefore, in practice, there is only one solution. Except for the trivial situation of an area with constant values, each method gives a different result, some methods being more visually appealing for human perception (AV, MD and MDi) but also introducing more statistical biases. Since the interpolations are pre-computed on the server side, our objective is to select a compromise between human perception and lower statistical uncertainties.
Computing the mean value and the median value is straightforward; however, the modal value needs additional consideration. Determining the mode in small samples is particularly tricky. The mode is the most present value, but when the sample is small there are several combinations of values that produce more than one modal value (e.g., with 4 values, 2 different values repeated twice). A normal procedure for calculating the mode consists of sorting the values and counting them. When two or more modal values are found, returning the first one introduces an unwanted bias towards categories represented by lower numbers. In the case of more than one modal value, it is important to select a good method for tie-breaking [
30]. The routine used in this paper deals with this situation by selecting the mode randomly from among the tied modal values.
4. Discussion
The potential of JavaScript clients for map applications was been demonstrated by common JavaScript map libraries, such as Leaflet and Google maps, as well as by JavaScript web applications that enable the user to create, manipulate and study cartography, such as Carto (formerly CartoBD) [
32] and Instamaps [
33]. Most of these solutions can manipulate vector data directly in the browser. However, when dealing with raster data, they rely on server side rendering and transferring pictorial representations (e.g., using WMS and WMTS standards). One example of these current state-of-the-art solutions is MapML: a newly formulated proposal to extend HTML language to declaratively describe maps [
34]. Perhaps, one of the reasons for this situation is that vector data can be encoded in text formats (such as GML or GeoJSON) that can be easily managed by the old and new versions of JavaScript. On the other hand, raster data is commonly encoded in binary format. One exception is the tile raster format designed by Mapbox for an interactive web presentation called UTFGrid. UTFGrid files use JSON to encode the rows of the grid as strings, each one containing a list of UTF-8 encoded codes. Each code is associated to a feature that has a list of numeric and alphanumerical properties that can be shown to the user when hovering over the image with the mouse pointer [
35]. The encoding is only efficient for categorical raster data (or rendered vector data), but it is not appropriate for RS data. In the RS area the Sinergise
Sentinel Playground (
http://apps.sentinel-hub.com/sentinel-playground/) offers the possibility to do some raster operations such as to create band combinations and band indices in a similar way that we do in the map browser [
36]. However, in the
Sentinel Playground these operations are generated in the server side and sent to the client using an extension of WMS.
The potential of the web browser to deal with raster data remains underexploited. This paper has presented the MiraMon Web Map Browser, which takes advantage of some characteristics introduced in HTML5 (binary arrays and canvas) to transfer raster data to the client that is later transformed into visual 2D representations on the client side. This enables the client to provide alternative representations of the data as well as to do statistical analyses, time profiles, filters, layer combinations, pixel-based calculations, etc. without any further interaction with the server. Web map clients can provide a platform that is closer to a traditional GIS that also works with raster data. The main difference between a traditional GIS and this approach is that each time the user pans or zooms on the map, new binary arrays at screen resolution are requested, dividing the loading effort between the client and server. All operations are done in real time at pixel level, so the validity of the results of these operations are conditioned by the uncertainties generated during the server side interpolation to the screen resolution and the propagation of the uncertainty in the operations. This paper quantifies these uncertainties and assesses the validity of the results that can be extracted from the analysis of RS in the Protected Areas from Space application of the MiraMon Web Map Browser.
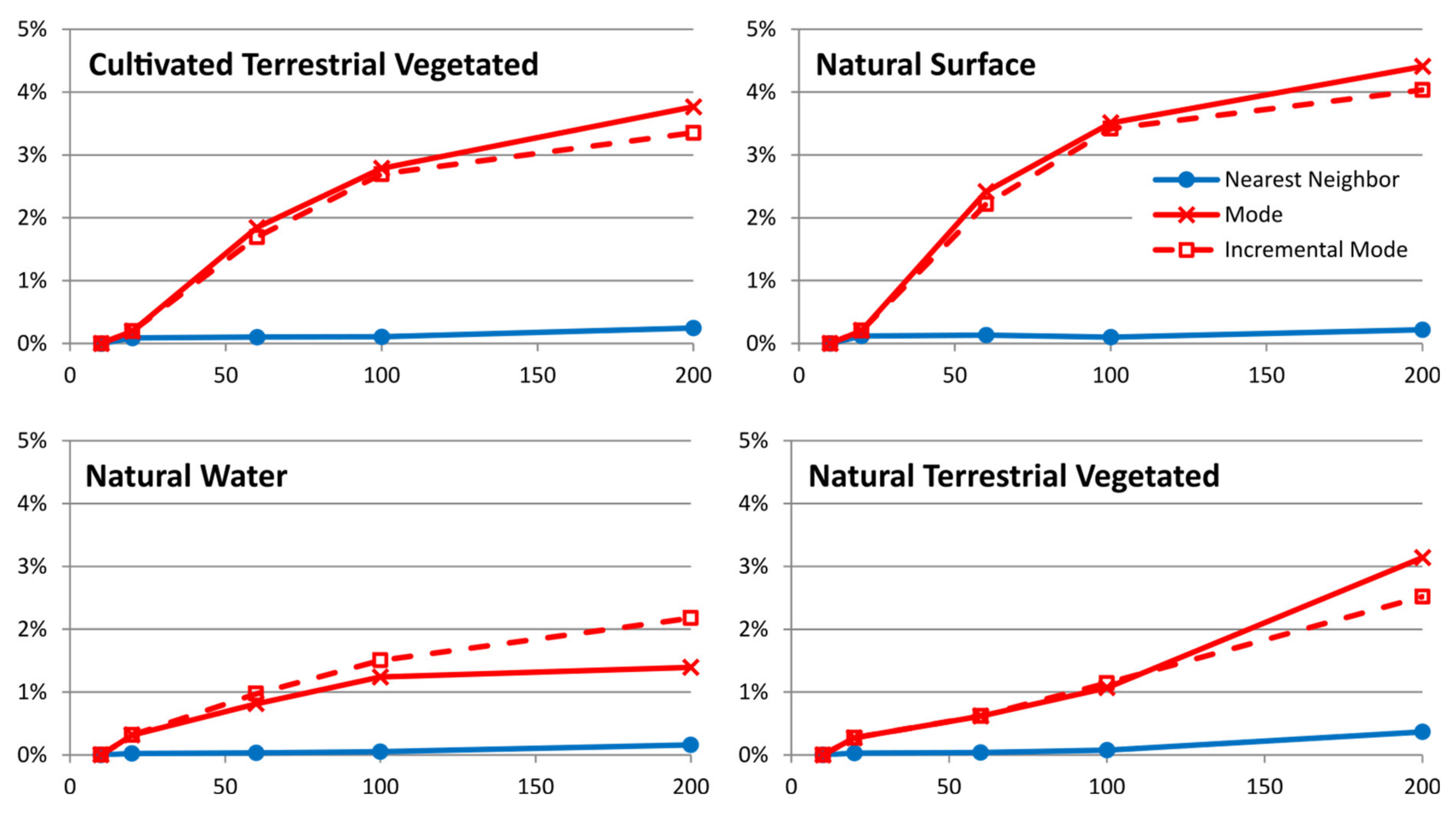
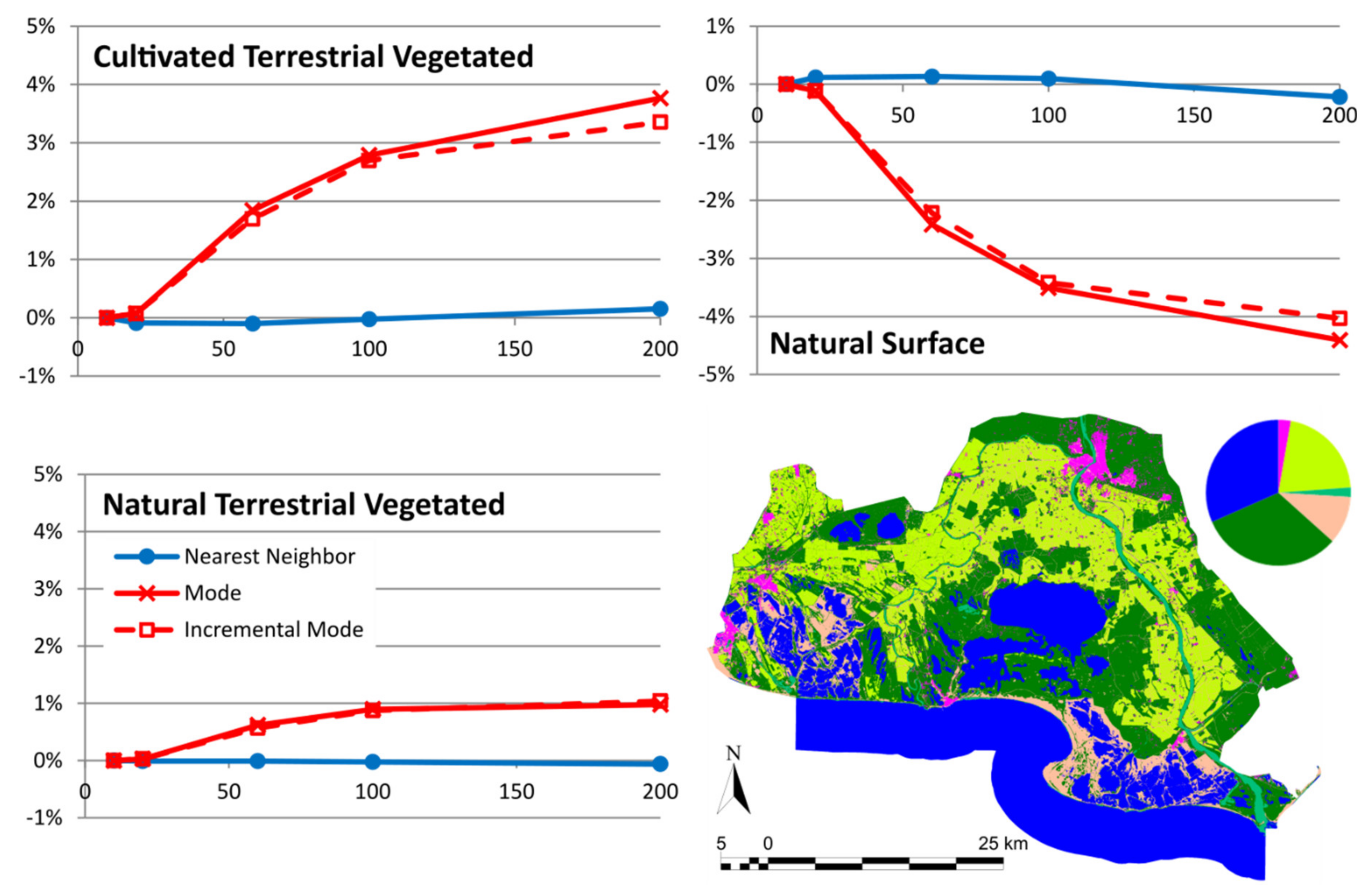
In a regular sized PA of about 100–200 km wide (10,000–40,000 km2), products derived from RS high-resolution data (e.g., Sentinel 2, 10 m cell size) require a factor 10–20 zoom level to fit in a regular screen of a map browser. At this zoom level (100–200 m pixel size), we have seen that common statistical analyses at screen resolution are still representative of the original data at full resolution. As a categorical data example (i.e., land cover data), uncertainties in the area covered by a class are normally below 1% and are never higher than 5% of the total PA area. Modal interpolation is preferable because it produces more homogeneous patches that are better perceived as objects and it does not create unreasonable uncertainties. As for a continuous data example (i.e., NDVI), common statistics, such as mean and standard deviation, do not vary by more than 1% of the NDVI range, although, not surprisingly, the maximum and minimum values are too sensitive to mean interpolation. Median interpolation is preferable because it produced more homogeneous patches than nearest neighbor, borders are better perceived as objects and it does not create unreasonable uncertainties.
Comparing two dates to determine changes could be more sensitive to uncertainty propagation. Nevertheless, the total number of changes in the land cover category in an example of a PA in Catalonia had a value of 1.7 ± 0.3% in a 50 zoom level factor. This demonstrates that operating at screen resolution is still useful. As a result of this study, our MiraMon map browser will include a warning message which informs users about possibly unacceptable uncertainties when they make an analytical operation at screen resolutions with ratios above 1:25 of the original resolution of the data.
Full resolution is needed only if precise values are required. Thus, making a preliminary exploration of data at a smaller resolution gives acceptable results and saves time and computing power. A hypothesis can be rapidly explored in the map browser and can be carefully quantified at full resolution later when necessary. This could be achieved by combining the current approach with a server-side analytical package implemented with a R library or using the OGC Web Coverage Processing Service (WCPS), which provides a standard language for analytical requests on the server side. Other similar languages for RS cloud processing facilities are currently emerging, such as OpenEO [
37]. In the future, the presented approach could be combined with one of these server-side alternatives to obtain precise results once the client-side coarse analysis has shown the soundness of the analytical approach.
The study presented here demonstrated that the results extracted from the Protected Areas from Space map browser are of a reasonable uncertainty. Thanks to these results, it is fully justified that the map browser is transferred to the H2020 e-shape project for its continuation in selected PS. This ensures a continuation of the operations of the map browser for at least four more years. After this period, the technology can be transferred to the directors of PAs for their own management and sustainability. The software powering the map browser is part of the MiraMon GIS family of products that is maintained as an open source project and is also powering other data visualizations in other European projects such as the H2020 Ground Truth 2.0 citizen science datasets, the Catalan Data Cube map viewer as well as the Spanish project NEWFORLAND.
5. Conclusions
The approach of providing EO data and analytical capabilities at screen resolution was demonstrated as useful and practical for protected area managers. However, the validity and uncertainties of the results in the client side generated by the different interpolation methods need to be evaluated in comparison to the same analysis performed at full resolution on the server side and balanced with visual satisfaction of the maps.
The study presented in this paper validates the approach by concluding that in all categorical studied cases, uncertainties in the area covered by a class are normally below 1% and 5% in the worst scenario. For continuous values, uncertainties are always lower than 1% of the value range. When more sensitive situations to uncertainties are applied, such as comparing two dates, results extracted at screen resolution are valid and never fully eclipsed by uncertainties. The study also shows that the nearest neighbor interpolation is the least sensitive method regarding uncertainties, while it gives the least satisfactory visual perception. For categorical values, the incremental mode is the method that has the best balance between visual perception and less statistical uncertainty. For continuous values, the incremental median method is the one with a better balance.
These interpolation methods will be recommended in future map services data preparation phases. With the methodology presented here, a hypothesis can be rapidly explored in the map browser, saving time and money. Future work will be focused on automatically connecting the map browser with a processing facility that can be used to carefully quantify the conclusion of exploratory results obtained in the map browser. Moreover, we will extend the capabilities of the connection with the NiMMbus geospatial user feedback system, in order to allow the user to share the analytical operations created in the map browser.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 Nearest Neighbor
Nearest Neighbor Mode
Mode Incremental Mode
Incremental Mode Mode
Mode Incremental Mode
Incremental Mode Mode
Mode Incremental Mode
Incremental Mode

