1. Introduction
The term Artificial Neural Network (ANN) refers to generalizations of mathematical models of the biological nervous system. Over the previous two decades, researchers have enhanced the potentiality of ANNs, which added a new dimension to the study of numerous scientific subjects. Dr Hopfield advanced the dynamics of ANN by proposing a method for integrating feedback loop mechanisms, named the Hopfield Neural Network (HNN) [
1]. With a recursive structure and graded response, this HNN, one of the earliest types of neural networks, is akin to a dynamic system with two or more stable points of equilibrium [
2]. This HNN has variety and is potentially useful for health [
3], behavioral sciences [
4], and energy [
5]. However, the HNN not only always converges to an exact pattern, which results in sub-optimal solutions but also suffers highly from its storage capacity. In such a case, the introduction of logic programming can be a good counter. Following this research, we explore the connections as a single symbolic instruction and its nature into logical rule assemblies using HNN.
Satisfiability (SAT) representation is an important means of conveying logical rules with mathematical information in AI through ANNs. In this context, a general query arises—is the SAT necessary in a Discrete Hopfield Neural Network (DHNN)? To answer this, SAT is designed to be readily attached as a symbolic instruction to represent the output of DHNN. Abdullah invented the general concept of logic programming on DHNN by computing the synaptic weights [
6]. Later, a study [
7] introduced new light to the satisfiability study. This work proposed a higher-order Horn-Satisfiability (Horn-SAT) programming, which focused on embedding Horn-clauses in a Radial Basis Function Neural Network. Therefore, several researchers further extended the fundamentals of Horn-SAT by proposing different systematic
k Satisfiability (
k-SAT), such as 2SAT and 3SAT. The work by [
8] transformed the constraint satisfaction problem into the 2SAT problem, which is more effective in achieving a different number of solutions. Then, the work by [
9] introduced the systematic 3SAT logical expression with a well-known metaheuristics Genetic Algorithm (GA). This work explored previous works to direct the search into regions of better performance within the search space, thus, reducing the time and space complexity. Maximum
k Satisfiability (MAX
kSAT), inspired by an expanded version of Boolean SAT, began to gain favor in the ANN research field because it used false/negative output in comparison to other SAT presentations [
10]. Following that, [
11] developed a hybrid technique that uses an algorithm to optimize the 2SAT logical rule. This work has risen to a new type of SAT study known as Maximum 2 Satisfiability (MAX2SAT). For its nonredundant literals, the result of this MAX2SAT logical rule was also negative. The proposed approach could display MAX2SAT behavior optimally during the DHNN testing phase. However, there is no involvement of any process that can minimize the complexity of the MAX2SAT model in the training phase. Subsequently, these studies investigated only the systematic logical rule. The first attempt is to represent the symbolic output of the HNN in terms of the non-systematic logical rule made by [
12]. This research showed that Random 2 Satisfiability (RAN2SAT) can be integrated into DHNN by minimizing a cost function that corresponds to the network inconsistencies. Nonetheless, this work restricted only
k = 1, 2 in which no discussions were made on improvement strategy for
k = 1, 2, 3 or Horn Satisfiability. Another different type of non-systematic logical rule was sketched by [
13]. This study was a new variant of the 2 Satisfiability problems. This work revealed that Major 2 Satisfiability (MAJ2SAT) is able to provide a new perspective in representing some NP and probabilistic class problems. The non-systematic logic study was further extended by [
14], proposing a new dimension in the non-systematic Random
k Satisfiability (RAN
kSAT) study. This work showed the achievement of 100% accurate synaptic weights by a higher order of RAN
kSAT (
k = 3, 2) combination leads to 100% global minima solutions. Though some researchers continue to focus on the usefulness of non-systematic logical rules in DHNN, the notion has yet to be fully explored.
The effectiveness of a learning phase is a significant issue in DHNN. Ref. [
15] revealed the weakness of HNN as the number of neurons grows in terms of retrieval capacity. To address this issue, a metaheuristic method was used to determine the best neuron state that minimizes the cost function. Another significant work was proposed by [
16], in which the Hybrid Genetic Algorithm (GA) was incorporated with the training phase of HNN. This hybrid model successfully obtained the best trade-off between solution quality and computational time. Another study conducted by [
17] demonstrated the Artificial Immune System (AIS) in the training phase with the 3SAT logical rule. This investigation explained that AIS outperformed the Brute-Force algorithm in terms of the global minima ratio, hamming distance and computational time. Ref. [
18] successfully integrated the usage of GA with HNN for solving combinatorial optimization problems. In their study, the HNN was applied to GA to minimize each other’s shortcomings. The combination of both methods reduces the possible local minima in solving various NP problems. Furthermore, [
19] introduced propositional satisfiability via a hybrid metaheuristic named Hybrid Genetic Algorithm (HGA) in DHNN. This work explained that GA as a non-biased algorithm can converge to a global solution compared to conventional learning models. Finally, the authors [
20] developed a hybrid HNN and integrated it with an Imperialist Competitive Algorithm (ICA). This proposed hybrid method successfully found an optimal solution in an acceptable computation time and managed to obtain a high-quality solution with minimum cost. However, these metaheuristics focused exclusively on systematic logical rules. Additionally, these metaheuristics lack a partition solution space for which a more efficient solution is required to identify alternative neuron states to minimize the cost function. Moreover, the mentioned metaheuristics have no specific balance with the extrapolation and exploitation strategy.
Recently, social and political behaviours have also inspired the development of numerous metaheuristic solvers. An election Algorithm (EA) is a form of an iterative social-political algorithm that operates on populations of solutions via the ‘election’ procedure. Ref. [
21] addressed this Election Algorithm (EA) as a highly optimized metaheuristic for its powerful solution search space, drawing the attention of many optimization researchers. EA is a population-based iterative algorithm that works with solution groups. First, the population will be divided into several parties based on their shared beliefs and views, the best members of each party will be chosen as candidates, while the others will be voters who support the candidate. Since EA suffers from a fundamental challenge; it always becomes stuck at local optima due to the incapability of the operators. To overcome this issue, later, the author [
22] proposed the Chaotic Election Algorithm (CEA), which accelerates the convergence of the existing EA by introducing a migration operator. However, these works also have no justification for several objectives to enhance the capacity of these metaheuristics.
Research recently indicated that non-systematic logical rules can provide a flexible structure and generate various interpretations that converge to global minimum solutions. Pioneering work by [
23] created a bridge between logic programming and a metaheuristic named EA. This proposed method utilized EA with RAN2SAT logic programming that created a lower error and higher retrieval capacity with glaring computational ability. The work by [
24] utilized higher-order RAN
kSAT (
k = 1, 2, 3), which was implemented on EA in the learning phase of DHNN to enhance the correct synaptic weight with minimal error and resulted in high retrieval capacity. Notably, these works only focused on accuracy, which means achieving the maximum fitness value of the EA model. The major lacking of the previous studies is that they merely focused on a single objective function, which is the highest fitness value, and there is no strategy in terms of the logical rule, which can create a new diversity. Achieving only a fitness value or a single objective function policy cannot discover the metaheuristics performances perfectly. Nevertheless, there have not been any new metaheuristics that concentrate on multiple goals or multi-objective goals, such as accuracy and diversity, that focused not only on exploration but also on exploitation simultaneously in higher-order RAN
kSAT logical presentations. Notably, the optimal solution to a multi-objective function is a better trade-off solution for several objectives than the optimal solution to a single-objective function [
25]. Furthermore, metaheuristics with a multi-objective approach focus on two critical search processes: first, investigation of the entire feasible space (exploration) and second, the examination of a local area of the search space (exploitation) [
26]. Excessive exploration strategies frequently decrease the algorithm/metaheuristics performance [
27]. It is imperative that unbalanced exploration and exploitation assessment forwards to slow convergence that suffers from local optima [
28]. Hence, we proposed this novel Hybrid Election Algorithm (HEA) that employs a multi-objective concept where both fitness (accuracy) and diversity are put in the same pair with higher-order RAN
kSAT (
k = 3, 2) representation in DHNN. This strengthens our proposed HEA model and strongly tunes the exploration and exploitation strategy in a balanced manner.
Moreover, a method needs to be employed to achieve the trade-off between diversity and accuracy (fitness value), which can scientifically improve the storage capacity of DHNN and the global solutions of a model. For this reason, our proposed article promotes fitness values addressed as accuracy and diversity in terms of the logical rule to develop a distinct Hybrid Election Algorithm (HEA) identity. Furthermore, our proposed HEA model introduces the notion of multi-objective functions, which adds another new light to our research. The following are the novel contributions of our study:
To construct a randomly generated second-third order Random k Satisfiability logical rule in the training phase that can optimize the correct synaptic weight and cost function of the Discrete Hopfield Neural Network.
To create multi-objective functions that maximize the fitness, and employ k-Ideal solution strings with a diversified logical rule to increase the storage capacity of the Discrete Hopfield Neural Network.
To propose a new bipolar Hybrid Election Algorithm with an effective operator that can balance the exploration and exploitation strategy in the training phase of the Discrete Hopfield Neural Network.
To compare the compatibility of our proposed model with benchmark algorithms in terms of the storage capacity, training error, testing error, the ratio of global solutions, neuron variations and similarity analysis.
Our novel model will be tested in a series of computer simulations to see how effective it is at reducing the cost function of the DHNN and arriving at useful end states. This work is initially organized into three sections: an introduction (
Section 1), an explanation of the basic RAN
kSAT formulas (
Section 2) and a discussion of DHNN (
Section 3). The Proposed Methods are explained in
Section 4 and
Section 5. Experimental setup and performance evaluation measures are further dissected in
Section 6 and
Section 7. The last parts of the report include the Results and Discussions (
Section 8) and the Conclusion (
Section 9). Here, a summary of the related studies is given in
Table 1 below.
2. Random k Satisfiability (RANkSAT)
One of the significant breakthroughs in the SAT study is Random
k Satisfiability (RAN
kSAT), which continues to be the preferred choice for ANN researchers due to its independent clause composition [
29]. RAN
kSAT is a non-systematic logical structure that comprises a set of
x literals as
with a group of
y clauses where
[
30].
Generally, a collection of random instances
over
Boolean variables forms the RAN
kSAT clause. Every logical clause normally has exactly
k variables that are linked with the OR (
) operator and are negated with a probability of
[
31]. The literal values are expressed in the bipolar form {1, −1}, which denotes either true or false. For
, the probability proportion in the negative to positive form is 1:1, 2:1, or 1:2. Note that RAN
kSAT can employ
,
and
where the formulation is shown in the Equations (1)–(3):
where
whereby
,
and
are the total numbers of the third, second and first order of logic in each clause in
, respectively. From Equation (4), the literals (positive or negative) are set at random.
Equations (5)–(7) show examples of
,
and
:
from the equations above, the outcome of each logic is known by replacing the values of {1, −1} (neuron states) with each literal. For example,
is said to be satisfiable when
that provides true values. On the other hand,
denotes unsatisfiable, which gives false values. In this paper, the RAN
kSAT complies only
since [
14] showed that
structural combination provides a more consistent interpretation. In the next section, we focus on how
logic can be represented via DHNN.
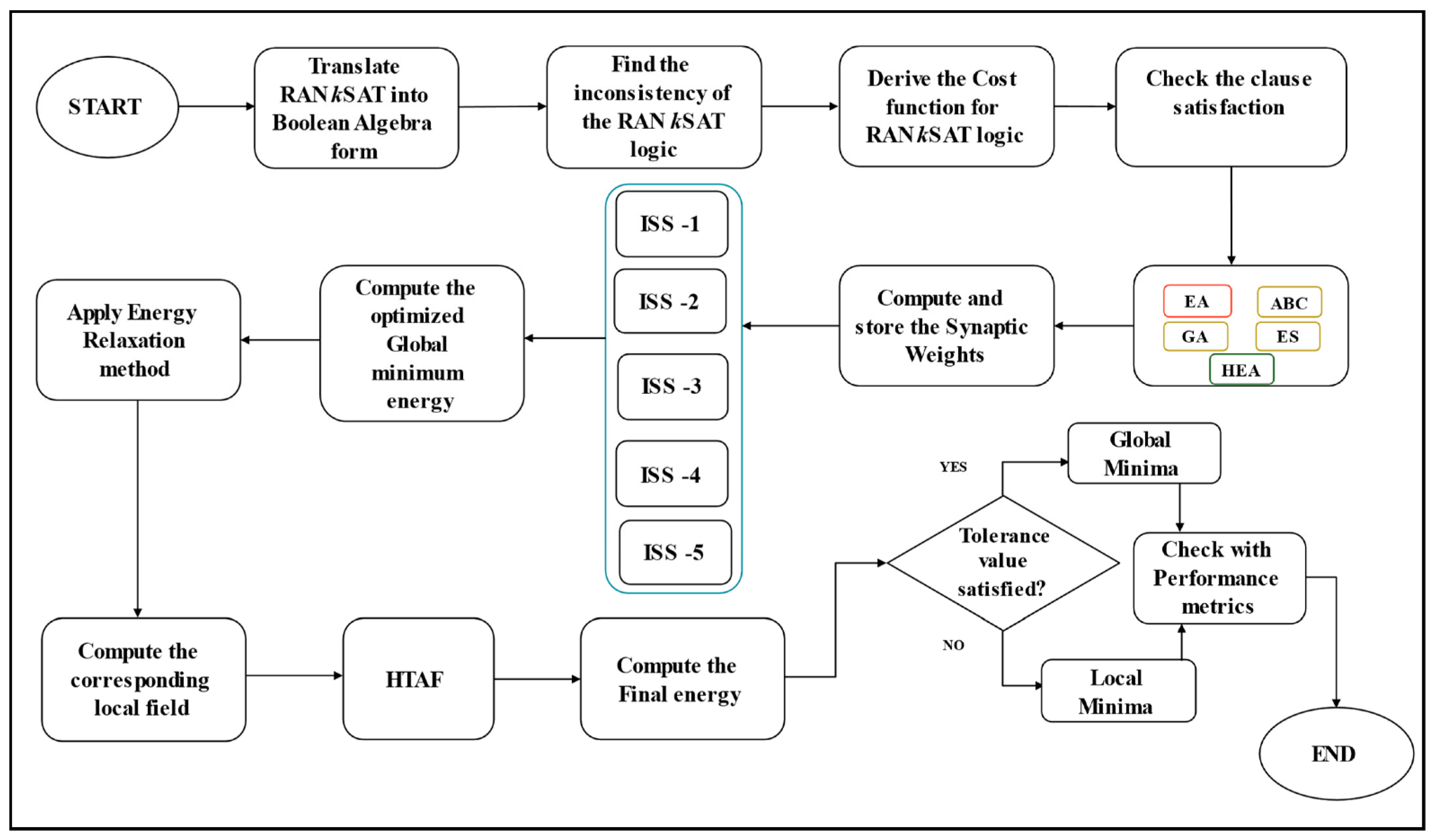
3. Random k Satisfiability in Discrete Hopfield Neural Network (DHNN)
The Discrete Hopfield Neural Network (DHNN) is a type of ANN referred to as a feedback network. In most cases, feedback refers to the output being sent back into the network. DHNN used one of the most successful storage techniques, termed content addressable memory (CAM) processes with binary/bipolar threshold units that are guaranteed local minimum convergence. DHNN is a network with no hidden layers and comprises interconnected neurons where the neurons are updated asynchronously. Here, we used the asynchronous neuron adaption of Theorem 1 to represent the DHNN units in bipolar values (1, −1). Theorem 1 shows that DHNN operated asynchronously concerning its condition.
Theorem 1. All networks described by (8) in randomized asynchronous mode will fall into a network gap with a probability of one when starting at an initial state in search space [32]. From (8),
is the synaptic weight from unit
to
.
is the current state of the unit
, and
is the pre-defined threshold. Several studies [
33,
34] defined
to verify that the DHNN always lead to a decrease in energy monotonically. The synaptic weight between neurons
and
corresponds to the intensity of connections between two neurons. Likewise, the neuron connections are approached
as
with
. The computation of the cost function
in DHNN is significant to decrease the logical inconsistency of
. The design of
Equations (9) and (10) that adapts all forms of logic combinations
is as follows.
where
is the neuron state where
. The probability for consistent interpretation is expressed in (11).
where
is the number of
clauses. The fundamental goal of using
DHNN is to successfully minimize the cost function
, which aids in finding proper synaptic weights and producing a good energy profile. Since
has a zero-cost function, it provides a satisfied interpretation (all clauses give truth value).
The local field of DHNN is given by (12).
is symbolized as the final state of neurons, whereby
are for third, second and first-order, respectively. The Hyperbolic Tangent Activation Function (HTAF) was used in the testing phase dynamics of DHNN to enable the convergence of final neuron states while avoiding neuron oscillation [
17]. The local field of our proposed model is formulated in (12) and (13) as follows:
Here, Equation (12) is the overall formulation of the local field for
and (13) is a piecewise function of the generated final state of the neuron according to the value of (8). In this paper, Wan Abdullah (WA) method is used to compare Equation (9) with Equation (14), which is noted as an energy function
. Therefore, the WA method is an ideal method to find
in the case of
DHNN.
and then the value
attains the absolute final energy, and the minimum energy
is gained from
that reduced monotonically [
24]. Hence,
is calculated by (15).
and
and
symbolize the numbers for 1 literal, 2 literals and 3 literal clauses in
.
Finally, Equation (16) can analyze the final neuron states’ quality by distinguishing between the global and local minimum solutions. Notably, if (16) is satisfied, and the final neuron states will attain global minima solution; else, it would be trapped in a local minima solution.
where
is the pre-defined value, which is known as the tolerance value. Algorithm 1 summarizes the steps of DHNN-RAN
kSAT through the pseudo-code below.
| Algorithm 1 The pseudocode of DHNN-RANkSAT in the logic phase. |
| 1 | Start |
| 2 | Set the initial parameters, maximum combination (COMBMAX) = 1, trial number |
| 3 | Initialize the neuron to each variable consisting of |
| 4 | While |
| 5 | Forming initial states by using Equation (8) |
| | [TRAINING PHASE] |
| 6 | Define cost function by using Equation (9) |
| 7 | For do |
| 8 | Check clauses satisfaction by Equation (9) |
| 9 | If |
| 10 | Satisfied |
| 11 | Else |
| 12 | Unsatisfied |
| 13 | End For |
| 14 | Calculate synaptic weights by using the Wan Abdullah method. |
| 15 | Compute the by using Equation (14). |
| | [TESTING PHASE] |
| 16 | Local field computation to find the final state by using Equation (12) |
| 17 | For () |
| 18 | End For |
| 19 | Compute the by using Equation (15) |
| 20 | Calculate the final energy with tolerance value. |
| 21 | Check If it is Global minimum energy or local minimum energy |
| 22 | If |
| 23 | Assign Global minimum energy |
| 24 | Else |
| 25 | Assign local minimum energy |
| 26 | End |
The schematic diagram for DHNN-RAN
kSAT is shown in
Figure 1 where the RAN
kSAT represents
k = 3, 2. In this diagram, the red line represents the third-order clauses, and the purple line denotes the second-order clauses, respectively. Within each main block, the pink, orange and blue colored lines illustrate the connection of each neuron. The energy filter represents whether it aligns with the tolerance value or not. The output of the diagram depicts that either it can achieve the global minimum or a local minimum energy.
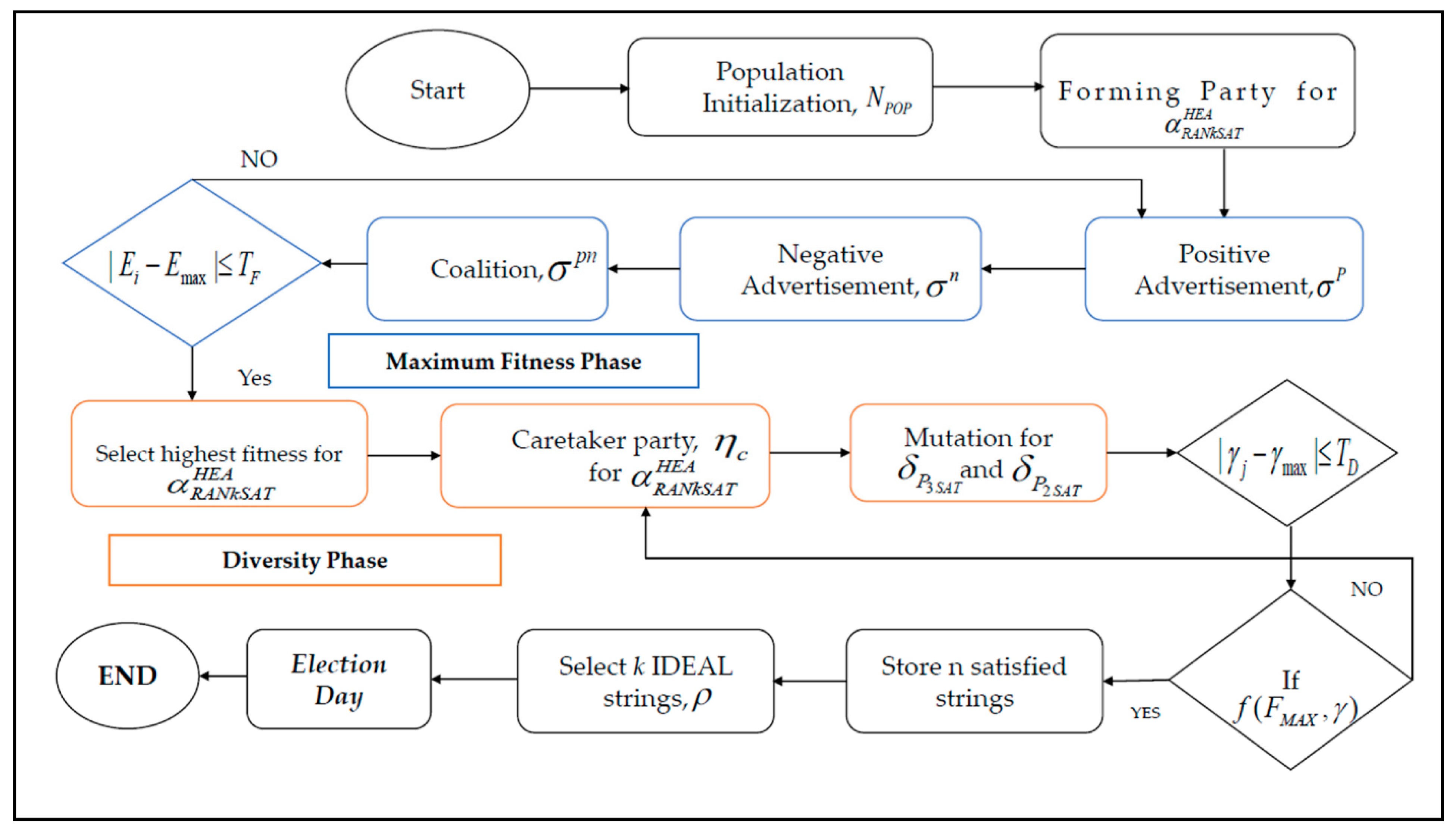
5. Proposed Hybrid Election Algorithm (HEA)
The key motivation of a hybridized algorithm is that it can cover a wide range of solutions and generate several distinct computations. Generally, metaheuristics have two segments that allow them to carry out the optimization process. These segments include the exploration of search spaces to identify potential regions of good solutions, as well as the exploitation phase, which intensifies the search for the best regions to find better solutions [
36].
Moreover, a logical representation that follows non-systematic logical expressions, such as RANkSAT, is more effective in a hybrid metaheuristic for avoiding overfitting solutions. In this context, the novel Hybrid Election Algorithm (HEA) is introduced, a type of social-political metaheuristics that combines evolutionary algorithms and swarm intelligence operations, which occupy both exploration and exploitation in a proper manner. There are no recent works that employ achieving the highest fitness value along with creating diversity in the logical rules. The core reason for addressing HEA in our paper is achieving maximum fitness value and simultaneously creating diversity in the logical rules in the same pair.
In terms of optimization, HEA introduced another efficient optimizer that can improve the local solutions. Following this, the characteristics of RAN
kSAT can rely heavily on the HEA because of its effective and robust mechanism. The HEA is utilized in this paper to find the best RAN
kSAT assignment that minimizes the cost function during the training phase of DHNN. The model is elucidated with detailed information in the next section. The procedure of the Hybrid Election Algorithm in DHNN-RAN
kSAT is explained in
Section 5.1,
Section 5.2,
Section 5.3,
Section 5.4 and
Section 5.5 5.1. Initialization
The population of individuals consisting of voters and candidates includes potential solutions of the search space of is generated randomly. Let is initialized. The state of each individual is noted as 1(TRUE) and −1(FALSE), which aligns with the possible instances . Consider the search space of being .
5.2. Eligibility Assessment
All randomized instances must undergo eligibility/fitness function assessment. There will be a reward for each of the correct instances that results in a satisfying RAN
kSAT clause. During the eligibility/fitness assessment process, the number of achieved clauses is used to determine the eligibility of the individuals. The eligibility or fitness value can be determined from Equation (21).
where
means the order of RAN
kSAT clauses. The aim is to increase the value of the eligibility/fitness function or decrease the value of the cost function.
5.3. Initial Formation of the Parties
In this stage, the solution space is divided into
parties. Then, the process of calculation of voters for each party can be written in Equation (23).
where
is the size of the population. Equation (23) is used to determine the eligibility of each instance (voters or candidates). In each party
, the prospective solution with the highest eligibility value is elected as a candidate
. The remaining the instances are attached as the voter
of the candidate. Then, the correlation distance function (
CorD) between the candidate
and the voter
was expressed in Equation (24).
5.4. Advertisement Campaign
After organizing the initial parties, we select the initial candidate with the highest fitness solution in each party. The main distinction between standard EA and the proposed HEA is largely due to the progress made in this advertising campaign. Next, each candidate will launch its advertising campaign, which will consist of four steps: positive advertisement, negative advertisement, coalition, and newly affiliated- another effective step is the caretaker party. Hence, these sub-steps of the advertisement campaign are explained below.
5.4.1. Positive Advertisement
The candidate will reveal their plans during this stage and attempt to sway voters voting selections. Hence, the number of voters who the candidate will influence is given as follows:
where
is a positive advertisement rate
. The reasonable effect between the candidate and the voter is expressed as the eligibility correlation distance coefficient by (26).
Each influenced voter
will determine the number of neuron states that can update based on the following Equation (27).
where
is the sum of the first, second and third-order of
. First, the influenced voter will update the neuron state randomly according to the predetermined number. Then, the eligibility/fitness value of each of the influenced voters
will be evaluated based on (21). In each party, there is the possibility that the influenced voter
will replace the current candidate due to higher eligibility/fitness value.
As a result, the candidate will be replaced by the solution with the highest fitness value in order to improve the quality of the solutions in the parties (more qualified supporters). If a voter and a candidate have the same eligibility, the candidate position shall be maintained (no replacement will be made). Suppose the best solution is identified in the positive advertisement. In that case, it will continue to be a candidate in the following steps until the first iteration is completed, at which point it will be announced as the best solution in the election stage.
5.4.2. Negative Advertisement
At this point, candidates use negative advertising to try to entice supporters from other parties to their side to expand the search space. This negative campaign generally benefits popular parties because it leads to an increase in popularity. Equation (28) depicts the number of voters (
) candidates can attract from other parties voters (
) with the highest fitness value.
where
are the voters from other parties, and
is a negative advertisement rate
. The correlation or similarity belief between the voters and the candidates is similar to Equation (29).
The reasonable effect from the candidate to the voter from another party is defined based on the eligibility distance correlation coefficient
.
Each influenced voter
will determine the number of neuron states, which can be updated based on the following Equation (31).
By using Equation (26), we can calculate the eligibility of the new supporters. Again, if a voter has a fitness value greater than the candidate, the candidate will be replaced by this voter.
5.4.3. Coalition
During this stage, parties collaborate and establish a coalition in order to explore additional areas in the search space . The processes and formulations used in the coalition stage were the same as in the previous strategy. First, the two parties will be randomly combined to determine the new candidate after this merger. To begin, use Equation (22) to determine the eligibility distance function and distance coefficient. Then, using Equation (23), specify the number of variables that need to be updated in each voter from this united party. The fitness values of all voters have now been updated. Finally, a comparison is made between the voters’ fitness and previous candidates’ fitness. This will be elected if the old candidate still has the highest fitness value in the next stage. However, if other circumstances arise, such as a voter having a higher fitness rating than the previous candidate. This fittest voter will be a new candidate who will face off against another political party.
5.4.4. Caretaker Party
After completing the traditional coalition stage, the accuracy of the proposed model is tested. If this proposed model satisfies its accuracy (by finding
k strings that achieve the highest fitness value), we can proceed to the next phase, known as the diversity phase. This diversity phase generates the ability to create the ‘best pool’ of instances where voters can only stay with the maximum fitness value. This ‘best pool’ is named the Caretaker party. In this stage, those who achieved the highest fitness value were selected for this pool. Mainly Caretaker party takes care of all of its best strings. Therefore, the dynamic stairs enhance the diversity of the proposed HEA mechanism model. The selection process for choosing the highest fitness value can be calculated by Equation (28).
where
is the ratio of the achieved maximum fitness value.
The mutation insertion concept is also utilized in this Caretaker party to improve its diversity, which creates a new dimension in the study of the proposed HEA model. Notably, the Caretaker party emphasizes the exploitation mechanism. Thus, it is better to choose such a type of mutation insertion, which can choose randomly with a more localized search. Moreover, the general mutation is muted randomly while there is no mechanism to detect unsatisfied clauses and inclusion of positive/negative states. In this context, we exploit shift mutation that works by shifting a randomly chosen frontier between two adjacent clauses by one/ single step, either to the right to the left or vice versa [
37]. Shift mutation not only focuses on non-satisfied clauses but also focuses on the inclusion of positive-negative states combination in each clause. In retrospect, the Shift mutation operator essentially provides HEA with local search capability; a phenomenon called intensification. However, shift mutation is a more localized search operation than swap mutation.
Hence, the condition of Equation (32) is satisfied; the fittest voters are moved to the next stage for the participating final round—‘Election Day’.
5.5. The Election Day
The best solution (the candidate) in each party will be tested at this stage. Then, this solution will be announced as the optimal solution if it has attained the maximum fitness value with desired logical states (at least one negative state in the solution string). Otherwise, a second iteration will be carried out. After that, the procedures will be repeated until all conditions (from Equations (23)–(32)) have been met.
Meanwhile, we provide a real example in
Appendix A that may guide how voters and candidates represent the value of a Party. Now, we present the pseudocode in the Algorithm 2 and sketch the total flowchart in
Figure 2, of our proposed Hybrid Election Algorithm (HEA) below:
| Algorithm 2 Pseudocode for proposed Hybrid Election Algorithm. |
| 1 | Start |
| 2 | Initialize the population consisting of |
| 3 | While |
| 4 | Forming initial parties by using Equation (23) |
| 5 | For do |
| 6 | Calculate the similarity between the voters and the candidates by using Equation (24) |
| 7 | End For |
| 8 | [Positive Advertisement] |
| 9 | For do |
| 10 | Evaluate the number of voters by using Equation (25) |
| 11 | Evaluate the reasonable effect from the candidate by using Equation (26) |
| 12 | Update the neuron state according to Equation (27) |
| 13 | If |
| 14 | Assign as new |
| 15 | Else |
| 16 | Remain |
| 17 | End For |
| | Negative Advertisement] |
| 18 | For do |
| 19 | Evaluate the similarity between the voters from the other party and the candidate from Equation (28) |
| 20 | Evaluate the reasonable effect from the candidate and update the neuron state by using Equation (30) |
| 21 | If |
| 22 | Assign as new |
| 23 | Else |
| 24 | Remain |
| 25 | End For |
| 26 | [Coalition] |
| 27 | For do |
| 28 | Evaluate the similarity between the voters from the other party and the candidate from Equation (29) |
| 29 | Evaluate the reasonable effect from the candidate and update the neuron state by using Equation (30) |
| 30 | If |
| 31 | Assign as new |
| 32 | Else |
| 33 | Remain |
| 34 | End For |
| 35 | End While |
| | [Caretaker Party] |
| 36 | For do |
| 37 | //Input Mutation operator// |
| 38 | If |
| 39 | //Choose Five Highest fitness candidates// |
| 40 | Assign as new (Select five voters as five new candidates) |
| 41 | Else |
| 42 | Remain (Five new candidates) |
| 43 | End For |
| 44 | Return Output the Five final neuron states |
| 45 | End |
| 46 | End While |
| 47 | Return Output the final neuron state |
5.6. Model Reproducibility
The same experiments need to be conducted to reproduce a framework with the model DHNNRANkSAT-HEA repeatedly on certain data sets or obtain the same results. Specific factors should be considered as below:
- i.
The logical presentation must be RANkSAT for k = 3, 2 structure where the threshold iteration is set at 100 to distinguish the maximum capacity of the presented algorithms.
- ii.
To achieve the optimal synaptic weight in the training phase, the WA method is utilized. According to [
24], the WA method is more stable than Hebbian learning. It is worth mentioning that different logic operators have different capabilities in producing negative literal.
8. Result and Discussions
Estimating the performance of any metaheuristics requires metrics for accuracy in terms of fitness, bias and variability. To check the prediction of our algorithm, we simulated the model and studied the dynamics of the various number of neurons. This study aims to see how effective our proposed model is by limiting the number of neurons . In addition, we experimented with solution strings (storage capacity), training error, testing error, energy analysis and similarity index in the interval . Moreover, to assess the performances via statistical metric, we consider ‘MAE’ as a performance indicator in training, testing and energy analysis. The error value is calculated in MAE. Notably, a lower MAE value will be considered as a higher tendency in achieving optimal solutions. Finally, Friedman test analysis is conducted for each part where the analysis is attached in each table by mentioning average (AVG), minimum (MIN), maximum (MAX) value with average rank (AVG.RANK) of each model.
8.1. Training Phase
8.1.1. Ideal Solution Strings
Figure 4 depicts the relative performances of
and
models in terms of Ideal Solution Strings, which are represented as CAM. Here, we see that for the small number of neurons,
only can generate five (05) Ideal solution strings. From the interval
, these models’ performances go down rapidly. For
, the generating number of ideal solution strings is almost zero at
. This happened due to lower management of synaptic weight calculation, for which this model cannot gather correct stored patterns in the testing phase. Additionally,
has no filtering process, which satisfies our objective functions for subtle desired ideal solution strings. Similarly, for higher
,
is also inefficient in achieving ideal solution strings. This is because
has no additional operator except a positive advertisement/ mutation/scout bee operator, respectively, that can improve the local solution, which impacts finding ideal solution strings. These models failed to utilize the Pareto optimality concept to generate ideal solution strings for higher
. If we look into the
model, the arranging capacity of ideal solution strings is very impressive. From the initial point to
, this model continuously produces five ideal solution strings. This gives clear evidence that the
model has fully utilized both diversity and fitness phase concepts by which more local solution improving optimizers are involved to achieve optimal synaptic weight that leads to our target ideal solution strings.
According to Deb and Deb [
46], introducing a mutation operator in any algorithm can improve the exploration and exploitation strategy. The Shift mutation in the caretaker party of the advertisement campaign concept develops the population to introduce a higher ability to find more satisfied solution strings that leads to global solutions too. Hence, we can conclude by mentioning that the
model created desired ideal solution strings, expressed herein CAM and outperformed the other models.
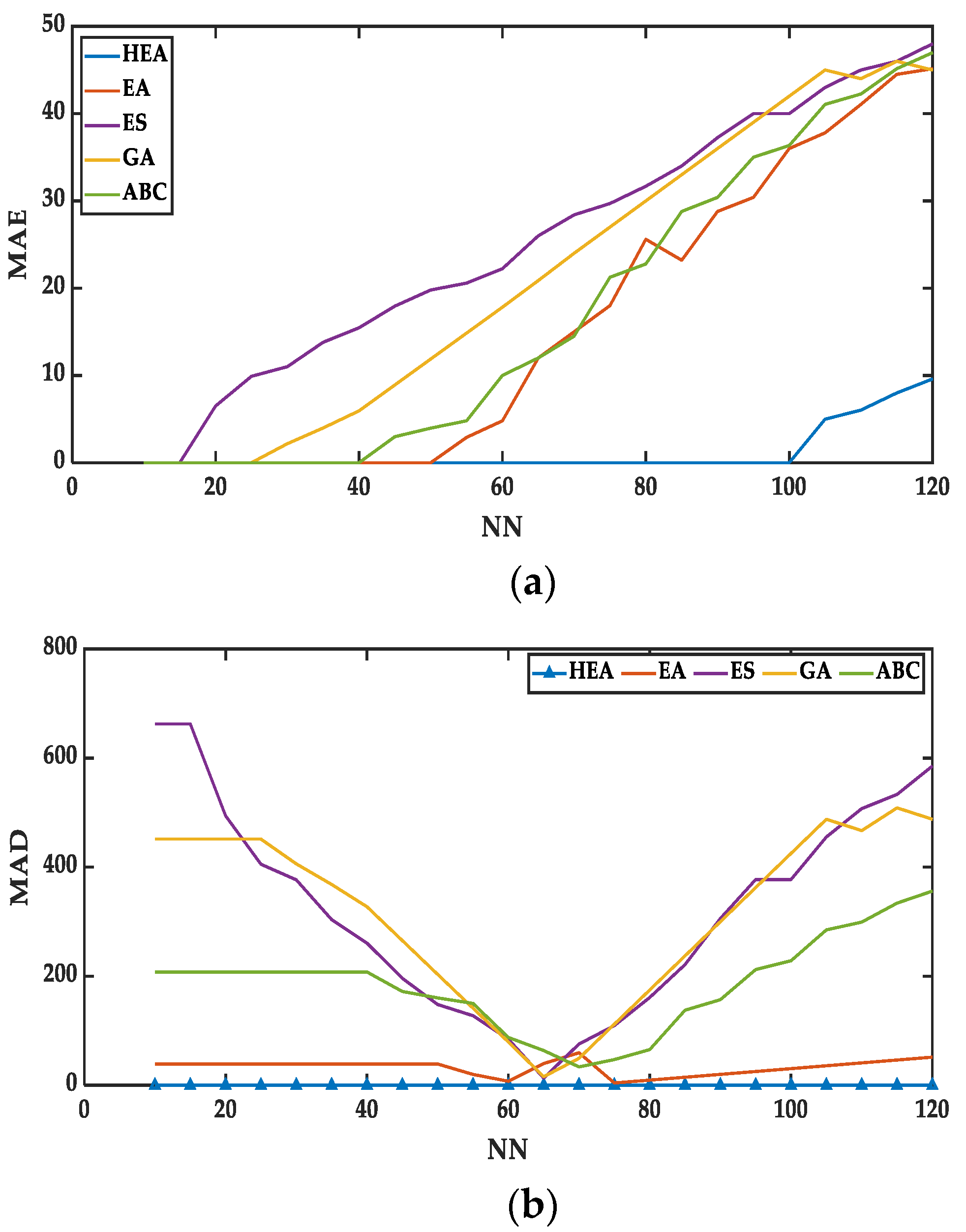
8.1.2. Fitness
Figure 5a and
Table 5 show that the results of training errors (the fitness value) in
MAE and
Figure 5b present the
MAD-Fitness value for the models
and
. Having a lower value of
MAE and
MAD indicates a higher degree of accuracy (fitness). In general, it is noticeable that the
MAE value for
models rise after a certain number of neurons.
This means that the higher
MAE of a model cannot optimize desired fitness value in the training phase. After
, the
MAE values for
model start continuously rising without any intervention. This has happened because
has trial and error nature that causing the sub-optimal training phase. It was stated by [
17] that
exploiting ’trial and error’ nature for the higher number of neurons.
If we check the conditions, the error proportionally increases as the number of neurons rises. This elucidates that these models have no additional optimization phase to achieve the multi-objectives, which is not defined, and there is a high chance to gain non-improving solutions. On the other hand, fitness for MAE value is up to the level. From the interval , the MAE value of is zero. This means that the combination of 3SAT and 2SAT clauses can gain more satisfied interpretations, which helps to achieve maximum fitness value.
However, the proposed
model has a strong influencer, such as the caretaker party in the advertisement campaign, which mainly reduces the fluctuation of
MAE. After the negative and coalition campaign strategy, the voter increases the chances to enhance the eligibility where the selected voters with the highest eligibility value have formed a stronger party. Thus, individual eligibility for all the voters and candidates increases and the absolute error is reduced vividly. This finding has a good agreement with the study of [
14] where clause arrangement is the key issue in Random Satisfiability. Notably, 3SAT clauses
create more satisfied state options that show the potential
MAE value is almost zero in DHNN. Moreover, in the whole simulation, the
generates a poor
MAE value in terms of fitness, which shows that
consists of effective optimizers that can achieve the optimal training phase.
A similar concept applies to
Figure 5b, which represents the
MAD-Fitness value for the different RAN
kSAT models. In this Figure, it is also clearly visible that the
MAD value for
is straight zero. This means that the
model achieved 100% of the desired fitness value.
Additionally, the Friedman test has also been conducted and is shown in
Table 5 for the
and
models. The degree of freedom is
, considering
, and the Chi-Square value for
MAE-fitness is
. The null hypothesis of equal performance for all the models is rejected. Furthermore, the lower value of an average rank represents the better position of a model. Here, we have also checked the rank analysis of the models through
Table 5 and identified that the lowest number rank for fitness occurred for
model, which is 1.87.
8.1.3. Diversity
Figure 6a and
Table 6 depict the training error in
MAE concerning the diversity and
Figure 6b represents the error in
MAD for
and
models. Here, the lower
MAE and
MAD values present the higher diversity of the model. In all models, it has been found that as the number of neurons increases the
MAE value is getting higher, and the diversity is projecting lower. This means that as
increases, the population diversity diminishes.
During the interval , has a very negligible error in terms of diversity. After the mentioned interval, the MAE values increase rapidly. This happens because this model has no partition and that cannot create more negative literal in searching satisfied interpretations. Moreover, we know that is always able to run for a lower number of neurons for its weak mechanism. Following this, the models performance ability is better than model because these models have partition solution space, that can adopt more negative literal for finding satisfied interpretations. Although perform better, the lack of exploration and exploitation balance strategy in the operators creates lower diversity when increases.
Alternatively, the proposed
makes the combination of the state with the non-benchmark logical state, which achieved a maximum diversity rate that creates a dynamic shed until
(the accumulated error is practically zero).
has more partition solution spaces rather than other models, which keeps the advertisement campaign strategy of this algorithm in a balanced manner and retains the lower status of
MAE value. This lines up that the different number of negative literals
shows additional compatibility as a symbolic instruction in DHNN. Involving mutation strategy in the diversity phase ensures the algorithm’s exploitation and global search abilities [
47]. However, the effect of the interaction of the mutation machinist in the advertisement campaigns caretaker party improves the final states of the neurons as well as leads the global search abilities.
Similarly, we can write for
Figure 6b that represents the
MAD value for the diversity in different RAN
kSAT models. In this Figure, it is also clearly visible that the
MAD value for
is absolutely zero. This means that the
model has fulfilled with a 100% diversity strategy.
Here, the Friedman test was also conducted in
Table 6 for
and
models. The degree of freedom is
, considering
, and the Chi-Square value for the
MAE-fitness is
. The null hypothesis of equal performance for all the models is rejected. Furthermore, the lower value of an average rank represents the better position of a model. Here, we have also checked the rank analysis of the models through
Table 6, that identifies the lowest rank for fitness occurred for
model, which is 1.48.
8.2. Testing Phase
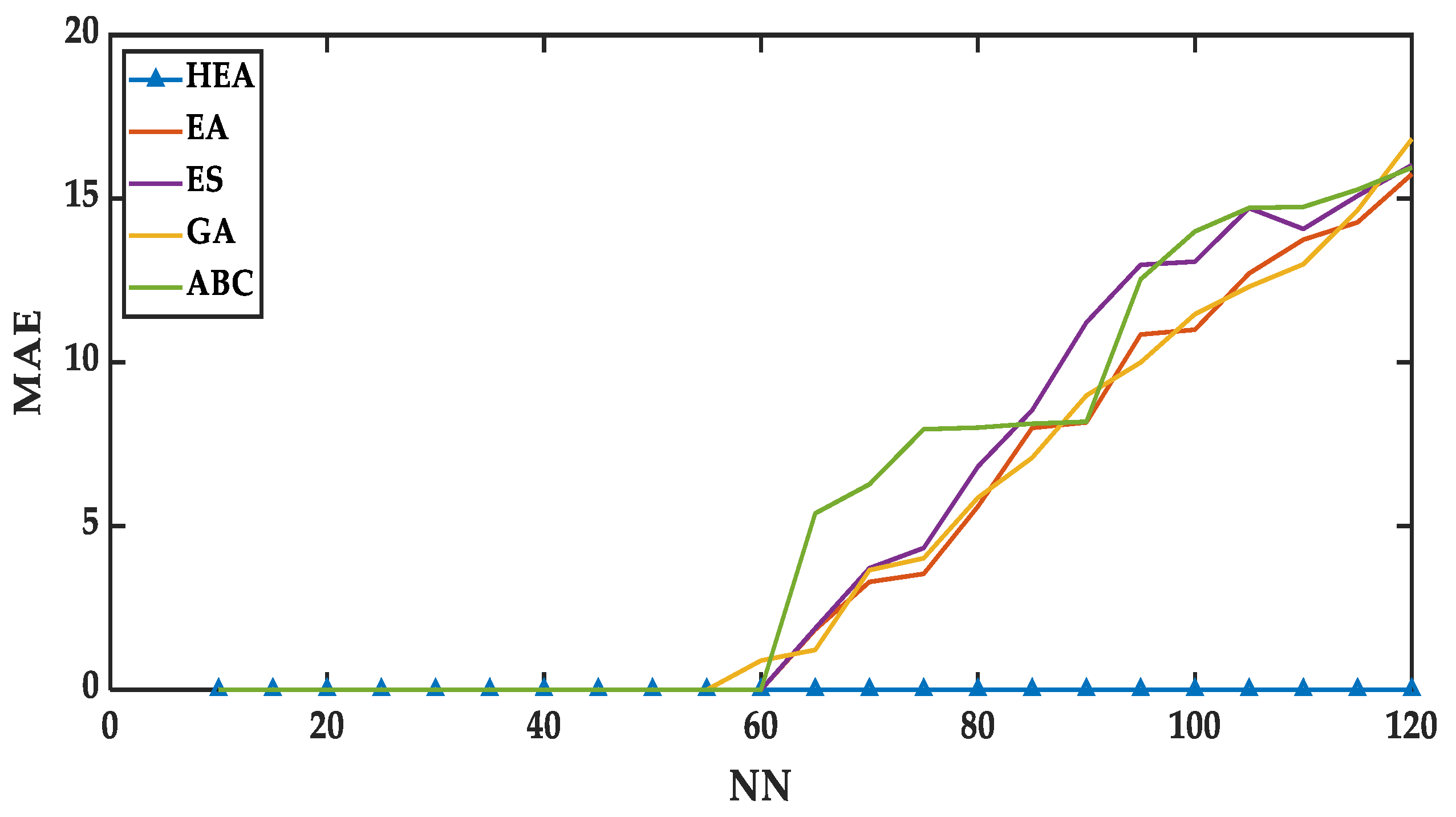
The error analysis in the testing phase is sketched in
Figure 7 and
Table 7. In this section, the behavior of various models in terms of synaptic weight management that retrieve the final states of neurons and produce global minima solutions are discussed. The competence of the testing phase in DHNN will be the indicator of
model which can successfully achieve optimal synaptic weights to retrieve the final states that produce global minima solutions.
Referring to
Figure 7,
generates zero
MAE value with lower
whereas the testing-
MAE value sharply rises and reaches maximum error that is
when
is higher. This has happened due to
generating the wrong synaptic weight for higher
, which complies with the sub-optimal training phase. However, the models
also failed to achieve its desired correct synaptic weight for higher
, and this creates a higher testing-
MAE value. This happened due to more
,
, which cannot explore the search space properly, which affects minimizing the cost function. To avoid this issue in the future, these models can adopt a greedy selection operator that can avoid sub-optimal solutions [
48].
On the other hand, we can investigate the scenario of , which depicts the best performance in the testing phase. From the initial stage to , the proposed creates the finest result achieving almost zero MAE values in the testing phase. This has happened since has two filtering phases (fitness and diversity) are mentioned in the multi-objective concepts, which have several layers. These layers have a strategy for improving global search space, which is an exploration and local search space, which is known as exploitation. This strategy generates a zero-value cost function for that leads to 100% global minimum solutions. Importantly, if the mechanism of failed to retrieve optimal synaptic weight, the testing phase will be affected. Hence, it can be validated that is a better model for finding global minima solutions compared to the other mentioned models.
Here, the Friedman test is conducted in
Table 7 for
and
models. The degree of freedom is
, considering
, and the Chi-Square value for the
MAE-fitness is
. The null hypothesis of equal performance for all the models is rejected. Furthermore, the lowest value of an average rank represents the better position of a model. Here, we also check the rank analysis of the models through
Table 7 and identify that the lowest rank occurred for
model, which is 2.00.
Energy Analysis
In this section, the types of energy analysis for different DHNN models are explained. Here,
Figure 8 and
Table 8 elucidate the ratio of global solutions
reached by
and
models.
Figure 9 and
Table 9 represent the difference in energy examined by measuring the
MAE value with different
.
In
Figure 8 and
Table 8, we can check whether the number of negative literals of 3SAT and 2SAT clauses influences the
. The capability of a model in achieving
, indicates the effectiveness of a proposed model to produce a consistent final neuron state. In this figure, we see that
approaches
for a certain interval
. Conversely, this consistency is degraded when
increases. At
the
for
has rapidly drops, and for
, it approaches zero. This is happened due to the presence of more 2SAT clauses, which creates more non-satisfied interpretations as well as no logical variety involved to overcome the final neuron states effectively. Though
have a good optimizer, there are no specific objectives that can improve the logical rule and the operators cannot explore and exploit it properly.
Interestingly, our proposed consistently produces the highest ratio of global solutions in the interval . The abovementioned optimal range consistently produces for . This is caused since employs the multi-objective function concept, which brings a different number of solutions by introducing negative states in the diversity phase of 3SAT and 2SAT clauses. More importantly, the appropriate placement of the local and global search operators tends . This logical variety includes the ideal neuron state where the HTAF update the final neuron state successfully.
In the
mechanism, both exploration (negative and coalition campaign) and exploitation (positive and caretaker party) function equally for which this
executes only a single iteration in comparison to other models. Hence, the
obtained by the
model has a good agreement of the work by [
15] where
approaching 1 can achieve 100% global minimum energy.
Here, the Friedman test results for
and
models have been demonstrated in the
Table 8. The degree of freedom is
, considering
, and the Chi-Square value for
is
. The null hypothesis of equal performance for all the models is rejected. Furthermore, the higher
value of an average rank represents the better position of a model. Here, we also check the rank analysis of the models through
Table 8 and identify that the highest value for
occurred for
model, which is 4.00.
In terms of energy analysis,
Figure 9 and
Table 9 illustrate how the
MAE value between the minimum energy (
) and final energy (
) is used to examine the difference in energy. From the mentioned Figure and Table, we also observe a similar trend for
models in which the
MAE value in the energy analysis is sharply increasing in the interval of
. This takes place since
cannot generate more satisfied solution strings for which it requires higher iterations that are trapped to local optima. On the other hand, our proposed
model has no error that is zero
MAE value from the initial point until the end of the simulation. This has happened due to the generating satisfied solution strings following Equations (18) and (19). After the mutation the caretaker party
has a large capacity in achieving more satisfied solution strings, which arises zero
MAE value for energy analysis and satisfied Equation (16) with tolerance value accurately. Despite creating intelligence effort throughout the learning phase, this network has been presented with an excellent error reduction mechanism to prevent non-improving solutions. As a result, the neuron state for
has minimum state oscillation and has been updated properly during the testing phase.
In
Table 9, the Friedman test directed for
and
models. The degree of freedom is
, considering
, and the Chi-Square value for Energy-
MAE is
. The null hypothesis of equal performance for all the models is rejected. Furthermore, the lower value of an average rank represents the better position of a model. Here, we also check the rank analysis of the models through
Table 9 and recognize that the lowest rank value for
MAE-Energy occurred for the
model, which is 1.93.
8.3. Similarity Index
In
Figure 10 and
Figure 11 as well as
Table 10 and
Table 11, we have examined the similarity and dissimilarity of the obtained final neuron states using the similarity index (SI). This indexing is specific for binary variables and use for divergency studies [
49]. In the similarity index analysis, we have looked for the study of Total Neuron Variation (TNV) and the Gower–Legendre Index (
GLI) according to the Equations (40) and (39).
8.3.1. Total Neuron Variation ()
Figure 10 and
Table 10 show the evaluation of total neuron variation (
) for various DHNN-RAN
kSAT models. The performance of
and
with DHNN in terms of variation of final neuron states in the training phase will be examined in this section. According to the finding, the neuron variations generate for
are slowly growing up, and these models have achieved maximum peak with
and
, respectively in
. The model
reached the highest peak at
and achieved
.
After and , the number of solution variations for the models continuously drops down, and after , the neuron variation is very low for and almost zero for . This is due to having no optimization layer that cannot explore the search space. A higher number of neurons (), becomes stuck at local optima due to the inability of the key operators, such as advertising campaigns for EA in searching for solution space.
To the contrary, our proposed model has gradually reached the peak and remained until the end of the simulation. This is owing to the efficient synaptic weight management and training provided by . Furthermore, has two phases with four-layer optimization, which allows for the intensification and diversification of a large search space with the use of optimization operators. This model has manifested that the proposed logical structure is very effective in creating more variation of solutions as the number of neurons increases. Moreover, the variation analysis by shows the diversified negative literals impact of DHNN on the production of global solutions. Consequently, we can say that lower energy analysis (ratio global) affects the low performance (for ) and higher energy analysis (ratio global) depicts the increased performance of for .
In
Table 10, the Friedman test directed for
and
models. The degree of freedom is
, considering
, and the Chi-Square value for
is
. The null hypothesis of equal performance for all the models is rejected. Furthermore, the highest value of an average rank represents the best position of a model. Here, we have also checked the rank analysis of the models through
Table 10 and identified that the highest rank for
has occurred for
model, which is 4.91.
8.3.2. Gower–Legendre Index (GLI)
Figure 11 and
Table 11 portrayed the
GLI value attained by different DHNN-RAN
kSAT models.
GLI measures the similarity of negative states concerning the benchmark state. For this case, the higher
GLI value is better for investigating the similarity index. In our analysis, the
models have recorded poor values 0.2, 0.198 and 0.126, respectively, for higher
. This states that for higher
, different number of negative states in the logical rule results valleys, which decrease to a lower value. Even at
,
cannot generate any value, which means that these models are trapped into 100% local minima solutions. Correspondingly, for higher
, the
GLI value is staked at 0.15, which is also very low. This
model can generate a minimum
GLI value at the end of the simulation because it can produce a few global solutions for higher
and the variables of each state for
obtained are not all equal to the ideal neuron states.
Nevertheless, the proposed generates a designated value until the end of the simulation, which shows a higher GLI value rather than other presented models. This demonstrates that the proposed showcased with the different do not affect the variation of final neuron states. Moreover, the composition of multi-objective concept effect for higher GLI value since this proposed model makes a good alignment with RANkSAT representation. In addition, the higher GLI value admits the mechanism that is capable of finding ideal solution strings, which enhances the storage capacity of DHNN. This model successfully explored more diverse states that result in global minimum energy.
In
Table 11, the Friedman test directed for
and
models. The degree of freedom is
, considering
, and the Chi-Square value for
GLI is
. The null hypothesis of equal performance for all the models is rejected. Furthermore, the highest value of an average rank represents the best position of a model. Here, we also check the rank analysis of the models through
Table 11 and identify that the highest rank for
GLI occurred for
model, which is 1.87.
From
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11 and
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11, the scenario of the overall performances of the models is demonstrated. The final neuron states attained by the proposed
model is found very nominal in the over-fitting issue and obtain the highest neuron variation achieved at the end of the simulation. More importantly, the storage capability in terms of ideal solution strings, error calculations and energy analysis exposed that the
model achieved the highest global minima solutions, which correspond to global minimum energy. If we observe the compatibility of the mentioned models in terms of storage capacity, training analysis, testing analysis, energy analysis and similarity analysis our proposed DHNNRAN
kSAT-HEA model outperformed the traditional EA, ES, GA and ABC models.
8.4. Impact Analysis
The pioneer observation from the above discussions and analysis, it is clearly visible that is superior to other presented models. The balanced exploration–exploitation mechanist, proper placement of the local–global search operators and the perfect intelligent mutation mechanism piled as an unbeatable strength compared to other mentioned models with the optimal solutions. As shown in the pseudo-code of , the diversity phase was observed to explore more negative states that correspond to the projected solution string. For the exploration part, the trajectory of the fitness value is obtained by the ‘maximum fitness phase’ in the advertisement campaign (Negative advertisement and Coalition part).
This is contrary to other models (), which increase the gap between the desired outcome and the current fitness value of the population. In terms of exploitation, the Positive advertisement and Caretaker party of the advertisement campaign keep fasting to acquire the highest fitness value. The exploration and exploitation strategy assemble to achieve our objectives in a single iteration. On the other hand, other models do not acquire similar benefit because of unbalancing position of exploration–exploitation mechanisms that creates lower fitness value. Thus, is reported to provide a positive impact although the initial population was initialized in random nature.
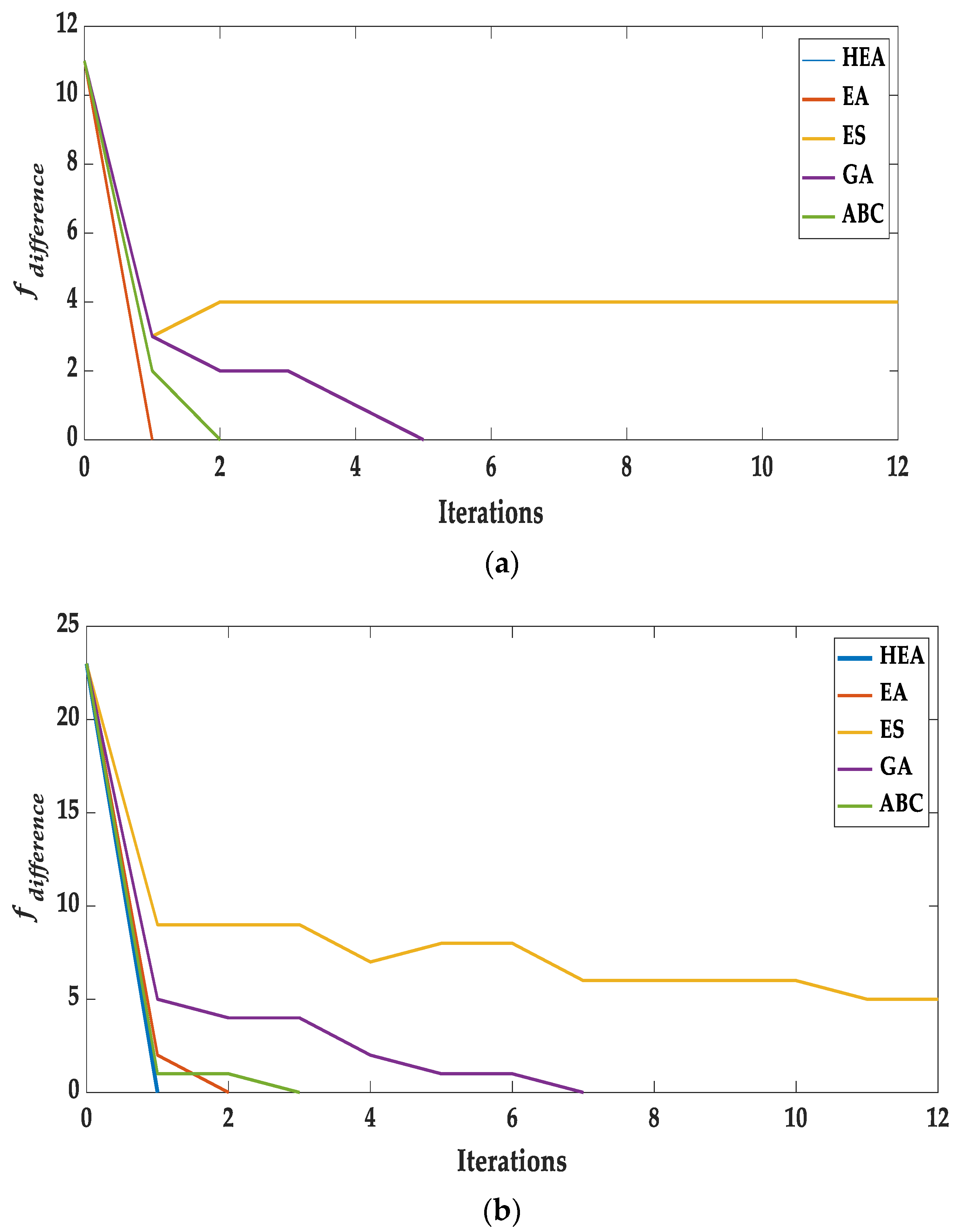
8.5. Convergence Analysis
In this experiment,
Figure 12a–d shows the convergence behavior of the proposed
was compared with other state-of-the-art algorithms. The combined existence of the exploration and exploitation strategy of the proposed
is more balanced in comparison to other algorithms. As shown in
Figure 12a–d, the convergence curve for different RAN
kSAT models illustrated that
requires only single iterations to obtain optimal solutions compared to other state-of-the-art algorithms. Having more exploitation mechanisms, the
model manages to avoid being trapped in the local solutions.
Although, showed competitive performances, the number of iterations requires more than the proposed model. Another obvious issue is that needs higher iterations since the operator is not quite effective. The models and have the primary weakness in terms of exploration and exploitation in deploying and utilizing the operators. This convergence analysis shows that failed to present the influence since it has no exploration and exploitations mechanisms.
8.6. Overall Comparative Overview of the Proposed Method with Existing Methods
In this section, we consider a different number of neurons
to verify the effectiveness of the proposed model with some other standard models.
Table 12 illustrates an overall comparison of
with existing methods with different metrics.
Based on
Table 12, for different numbers of neurons
generated the superior result in terms of fitness accuracy, diversity accuracy, testing error, energy error, total neuron variations and similarity index analysis compared to other mentioned models. It means that
satisfies our desired objectives: maximum fitness value and diversified logical structure with desired ideal solution string that enhances the storage capacity of DHNN. It is worthwhile to discuss the intriguing fact revealed by the retrieval capability of DHNN in ensuring the final states of the neurons that lead to global convergence. The robust operators of the proposed
enhanced the capability of achieving the highest number of global solutions. In a nutshell, we can express that our proposed
model outperformed all the mentioned models.
8.7. Pareto Optimality Analysis
The performance of
in doing multi-objective function can be examined through Pareto front solutions [
50]. Here,
Figure 13 explains the Pareto frontier of a multi-objective function with two criteria where most points belong to the Pareto frontier area. This figure delineates several important features—dominated states, non-dominated states, Pareto front and Ideal objective state of Pareto optimality for a multi-objective function.
Generally, the Pareto front consists of the set of best trade-off points, which are noted as the non-dominated points. While the Ideal states define the upper bounds (optimal points) for the objective function values, respectively. According to the study of [
51], the neuron state produced by the
model as shown in
Figure 14 that follows the non-dominated states as well as upper bound states which achieves Ideal states.
However, our proposed model does not entirely incorporate the concept of Pareto dominance in the selection of Ideal strings. Our proposed relies greatly in the competency of both objective functions. In this context, an Ideal string must comply with maximum fitness with logical diversity that are stored in CAM (DHNN). When the string achieves maximum fitness then it proceeds to the diversity phase. The mechanism continues unless any one of the phases failed to satisfy the objective functions. Moreover, the Pareto optimality can be considered when five (5) ideal solution strings fail to generate in a simulation. In our total simulation , the proposed model successfully achieved five ideal solution strings. Hence, the sub optimal neuron state for cannot be found and analyzed.
9. Conclusions
This paper reveals a novel multi-objective DHNNRANkSAT-HEA model, and a new insight into the non-systematic logical rule for a high dimensional decision system. A higher order logical structure addressed as RANkSAT (for ) is formed to optimize the cost function of DHNN. This paper proposed a novel multi-objective function that capitalize maximum fitness and diversified ratio of negative literals in each clause with five ideal solution strings that increase the storage capacity of DHNN.
A new hybrid metaheuristic, named Hybrid Election Algorithm (HEA), is also proposed by introducing a dynamic ‘Caretaker party’ operator in the mechanism of an advertisement campaign that improves the quality of local solutions. More importantly, our proposed model is capable of maintaining balance between the exploration–exploitation strategy for which it can avoid sub optimal solutions. Importantly, our proposed DHNNRANkSAT-HEA model successfully interprets to minimize the cost function within a single iteration during the training phase. Finally, we observed from the experimental evaluations and statistical and impact analysis that our proposed DHNNRANkSAT-HEA model achieved superior results in comparison with other models.
According to the famous no-free-lunch theorem [
52], no metaheuristic/algorithm can perform equally well in all types of conditions. In this regard, our model might not guarantee that it can be successfully implemented on other ANNs, such as the Radial Basis Function Neural Network, since each ANN model has individual architecture analysis. On the other hand, this DHNNRAN
kSAT-HEA model has several shortcomings that could be addressed in future research. We emphasize that our proposed model limits the number of maximum combinations (COMBMAX), which also limits the simulation ability to generate satisfiable neuron states. Furthermore, this study stops at 120 neurons, in contrast to [
23], which takes up to 300 neurons. This discussion also verified that the compatibility of
with the proposed
model in DHNN logic programming can be applied in the logic/data mining field [
53,
54] in the next exploration.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














