4.1. Case Study and Methodology for Manual Calculation of Parameters and Optimization of Waiting Systems
In carrying out these researches, we started from the assumptions and premises imposed on the waiting models adapted to the technological manufacturing systems presented, to which we added an attribute necessary to achieve an analogy in real time of the behavior of the industrial system as a waiting system, namely the one regarding the serial character of the waiting models used.
Two specifications must be made: If we analyze the behavior of a technological system as a waiting system for the realization of a single operation that can be performed at any of the TFS pending, then the analysis is made based on the presented methodology. If the behavior of the industrial system of waiting for a succession of operations corresponding to a certain technological process is analyzed, then the chosen waiting model must be imposed a specific attribute related to the serial character of the system.
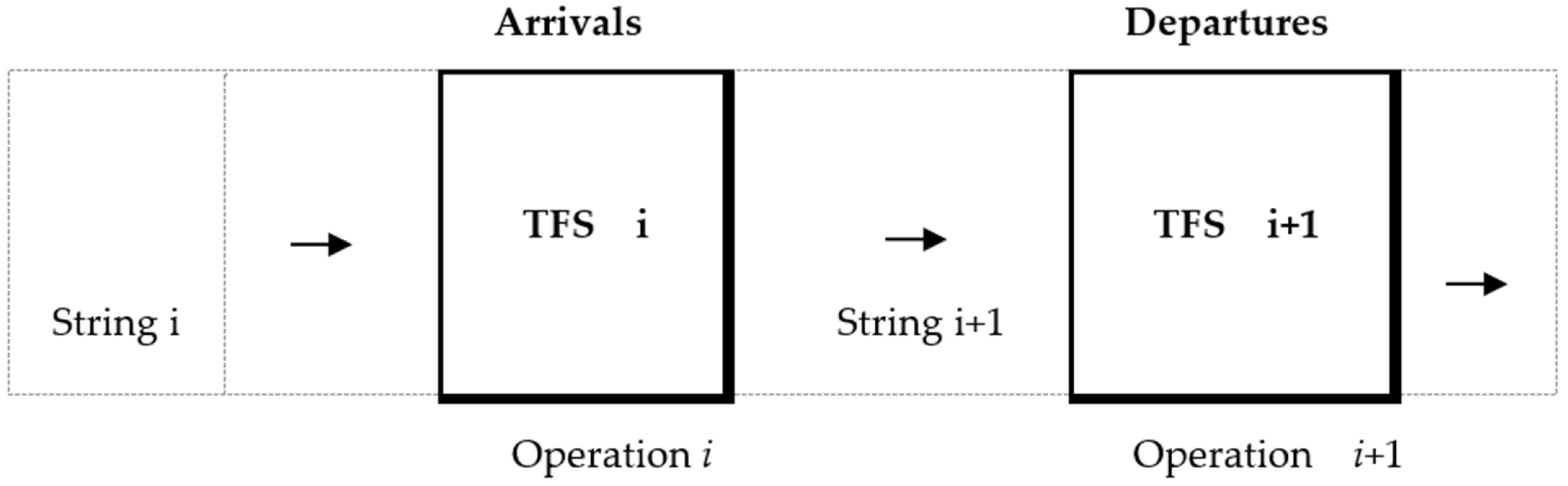
This feature takes into account the fact that, at flow-based processing, the outputs of a waiting process from a certain server (workstation TFS) are inputs for the next server (
Figure 2), and it has relevance for the study of each waiting model in terms of the interaction between workstations and their influence on the behavior in time of the system.
In the following analyses, the approach was made in both ways in order to observe the behavior in terms of technological times of the industrial systems subjected to variable production tasks in a more faithful manner.
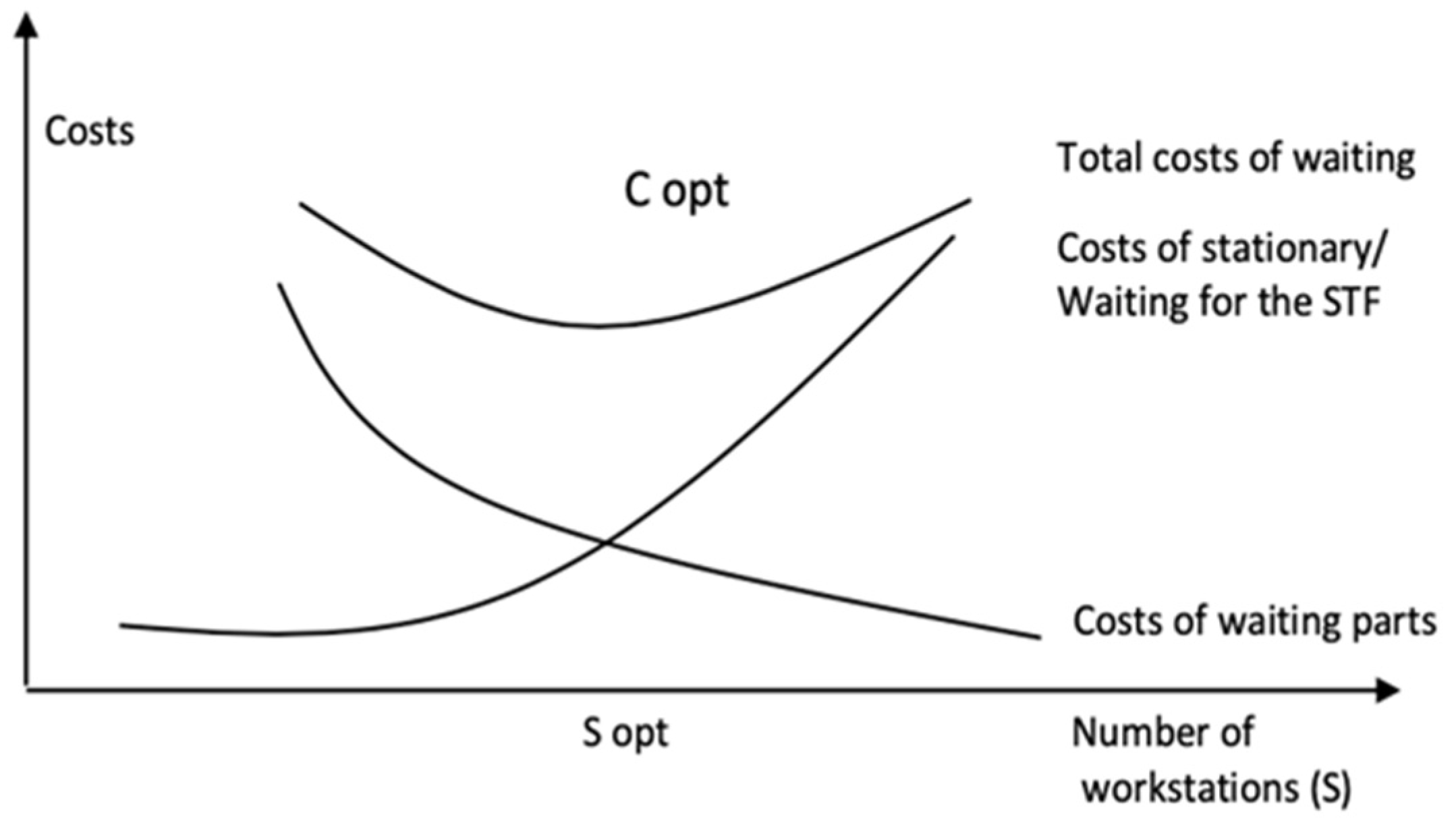
First, in the “manual” calculation, we took into account—for reasons related to space—a singular and significant example of a waiting system formed when processing a landmark in a production section, aiming that based on the parameters of the model, in the end, optimization of the system structure in terms of costs caused by waiting for parts, on the one hand, and waiting/stationing of servers, on the other hand, would be achieved. This involves determining the trade-off between the cost of waiting and serving. We proceeded through the following steps:
Determining the period of time during which the system can be considered stationary;
Timing of parameters a and u;
Verification of the consistency test ();
Calculation of waiting parametres—
r,;
Optimizing the total cost of waiting by taking into account the costs caused by waiting for the parts and servers in the system.
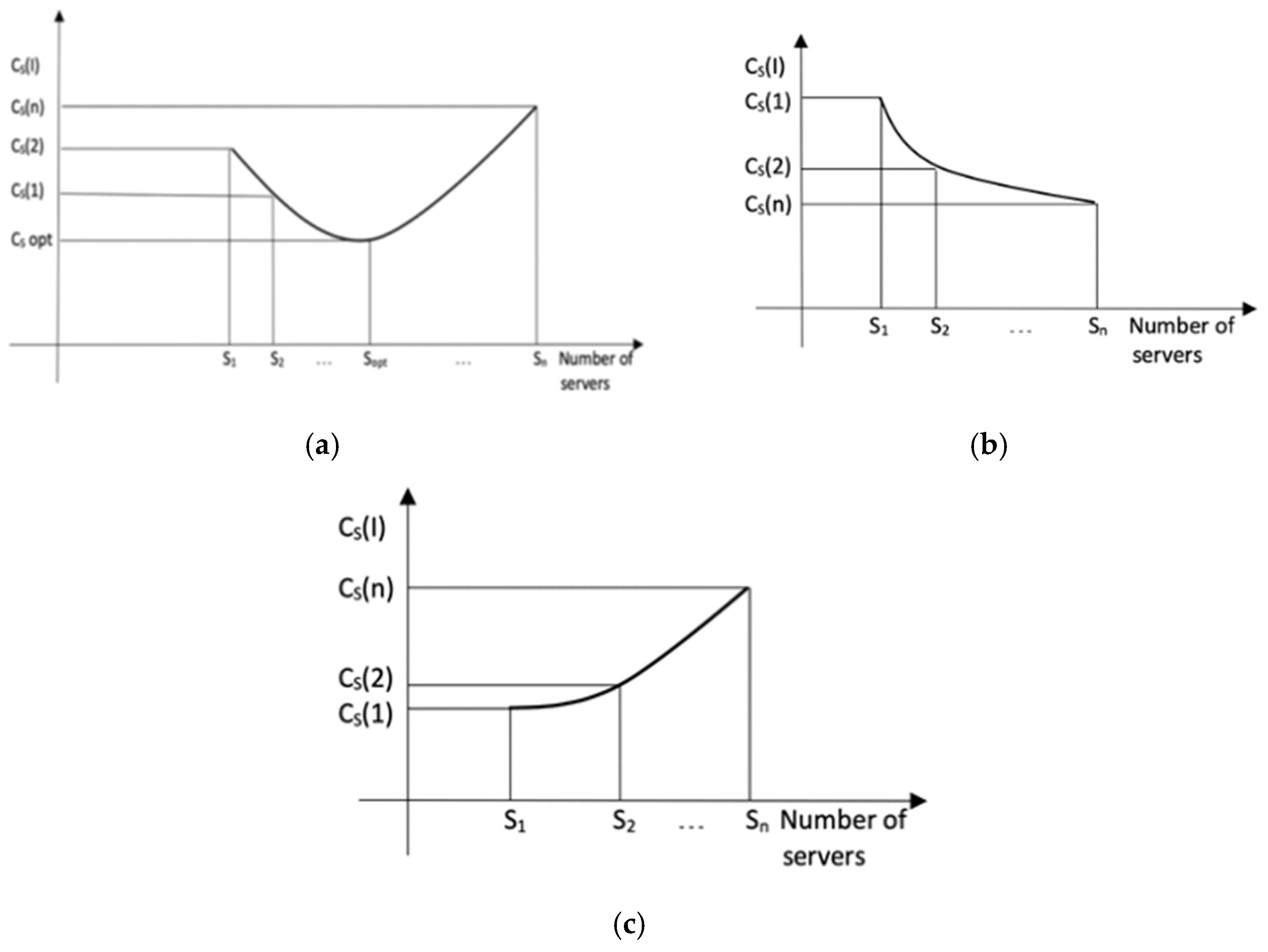
The objective was to identify the number of servers Sopt that minimizes the costs of waiting in the system Cs.
In the version of the “manual” calculation, it is necessary to individually calculate
Cs (
i) for different values
i and values of
S until the value
i = Sopt corresponding to is found:
As a characterization, the “manual” calculation method is somewhat laborious due to the modification of all the parameters of the waiting with the varying of i and the calculation based on the combinatorial analysis for i > 1, which is why, moreover, we also realized the methodology and the calculation program of assisted optimization of the parameters of the waiting system.
By returning (considered a server or serving station, such as the TFS used, whether it is a processing center or another machine tool, and the units under waiting) the semi-finished products (parts) to be processed, in order to decide if a second machine tool is needed to improve the serving or if its introduction into manufacture is uneconomic in the given situation, the waiting phenomenon and the overall costs related to it are studied.
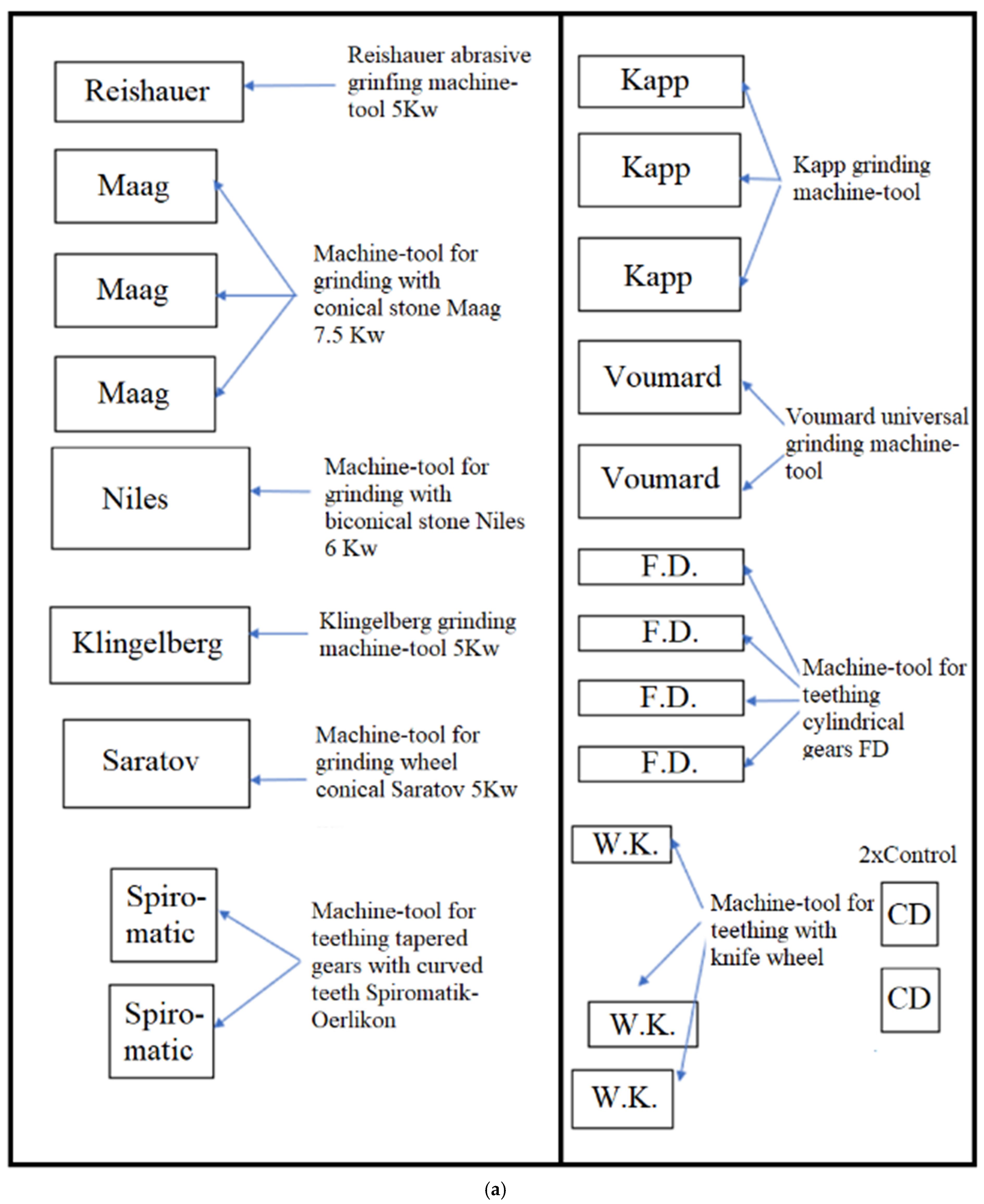
It analyzes the waiting phenomena that occur in a concrete processing case, such as the gears from the component of a horizontal machine for milling and boring, which are small series manufactured at a real factory along automatic lines (
Figure 3a,b).
The fluctuation of orders, depending on the market requirements and implicitly the production load, from one period to another justifies the application of the waiting analysis. Observations are made on the process, and the stages I–V presented, necessary for optimization, were taken.
Stage I. involves establishing the assumed stationary periods in terms of waiting in the system. Then, it is assumed stationary the periods when the presence of the blank(s) pending is relatively high, and the waiting system relatively balanced. From observations made in time on the technological process of processing the analyzed group of gears, it was experimentally found that, except for a “weemble” interval of about 30 min, from the beginning of each exchange in which the number of pending parts is insignificant and varies according to indeterminate laws, in the rest of the working interval, the waiting process can be considered stationary. Generally, in most of the analyzed intervals, there is a super unit number of pending parts, another number of parts under processing, the volume of both categories influenced by the rate of entries, the service capacity of the industrial system, etc. We, therefore, considered that the period T for which the process becomes stationary is about 7.5 h or 450 min, and we then used the same unit of measurement in the analysis of waiting on the parameters.
Stage II. involves the determination based on the timing of the parameters
a and
u (where
a is the average rate of inputs and
u = the average rate of servings in the unit of time). It should be mentioned that, in order to respect the statistical character of the study v. [
2], it is necessary that when the signification test is performed
χ2,the number of elements of the crowd is greater than or equal to 50.
In our case, in order to cover the reference period, we formed the set of analysis from 75 intervals of 6 minutes for the study of arrivals, whether the intervals are consecutive or not.
With these experimental data, it is possible to calculate the average of the distribution of the arrival M(x), which is 1.17. Of the seven intervals, the last three of them had less than five values; thus, we only considered four intervals. The statistics is 0.508, while the . Therefore we accepted the hypothesis of Poisson distribution of 1.17 for 6 minutes, hence 0.19/min.
In parallel with this, for the study of the services, observations and timings were made on the actual duration of the services. Respecting the condition of choosing a large number of observed cases, at least 50, we choose a number of 75 serving cases—machined parts.
Because the servings were made in several intervals of the form , we considered each range concentrated in its average value .
We obtained the expected service time of 7.847, and the estimated parameter was u = 0.127. Because all the last five intervals out of nine had less than five values, we grouped them, obtaining five intervals. The statistic was 4.42818, while the quantile was . Therefore we accepted that the service are exponential with u = 0.127.
Stage IV. Calculation of parameters of the waiting system: we obtained, as above, a = 0.19 and u = 0.127.
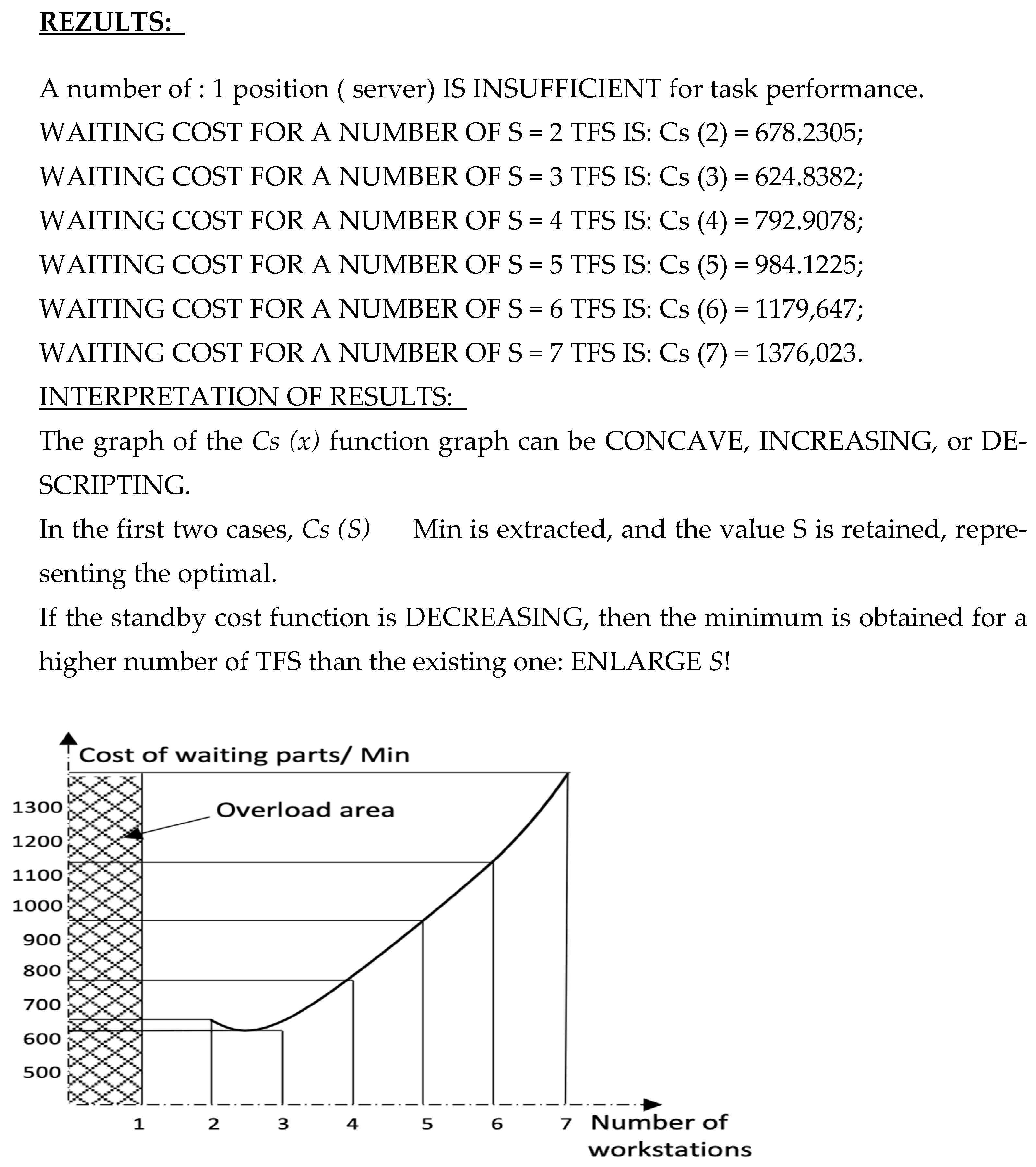
Because u < a to immediately shows that the use of a single serving station would be insufficient for the full realization of the production task, it automatically leads to the realization of an assimilated narrow point, at which the parts would accumulate constantly, and the length of the waiting string would increase indefinitely, a situation that is unacceptable from a technical point of view. This makes it mandatory in the analysis and optimization process to resort for this case to a supra unit number of processing stations.
From the values
a and
u, it was noticed that
Smin, for
u >
a is:
Smin = 2. Therefore, we calculated, in turn, the parameters of the calling system for
S = 2 using the specific relationships of multiserver systems.
Stage V. Optimize the total cost of waiting according to the costs caused by waiting for parts and servers in the system.
In the current version of the “manual” calculation, complications occur in the optimization process due to the specific way of searching for the optimal. This involves the varying of
S = i in the ascending direction, starting with the
Smin value, known, and the calculation for each
S of the parameters of the calling system and of the expression, with the known notations, of the cost of waiting:
The optimal cost, as well as the identification of the optimal number of
Sopt servers that minimizes the waiting costs in the system, is found through a process of comparing the
Cs values:
In these conditions, two significant disadvantages appeared, which also led to the imposition in order to effectively solve the second method of optimization, the assisted method.
The calculation was generally laborious because, for each modification of S, the parameters of the calling system must be recalculated with the complex relationships presented.
In the initial phase of optimization, the number of attempts—replays—of the comparison calculation necessary to find the optimal is not known, which increases the degree of uncertainty in assessing the opportunity of effective application of the method and difficulties in assessing the duration of the optimization process.
However, for queueing networks, the manual computation was easier because we had to solve a linear system. We used the Gauss–Seidel method because the system (1) did not have to be modified: it gave the iteration formulae directly.
Example: consider the Jackson queueing network. The results are presented in
Appendix C.
4.2. Case Study on Computer-Assisted Simulation and Optimization of TFS Operation Based on Standby Models
The study was performed using the same experimental data taken in 1.2.1 in order to finalize the analysis and achieve the proper optimization in terms of expectation theory, as well as other values collected experimentally in different procedures to illustrate the use of the algorithm and of the corresponding program for different concrete processing situations.
This finally allowed interpretations of the results and drew conclusions on the appropriateness of implementing such optimization methods in the industrial field, highlighting the facilities offered in the process of supervision and preparation of manufacturing, but also any malfunctions observed during application in concrete cases.
We, therefore, resumed the analysis of the expectation for processing in small series conditions and with variable production loads within the gear workshop of
Figure 3 with the group of wheels (including the percentage of spare parts) from the composition of a machine (tools for real drilling and milling A.F 85).
At the launch of the program, the initial choice must be made regarding the type of waiting model and whether or not only the analysis of the model is desired, as it results from the first communication screen shown in
Figure 4.
Considering that for the process of processing cylindrical teeth in the endowment of the workshop, there are, and can be used, a maximum of seven machine tools (four gear milling machines with snail milling module and three gear milling machines with a wheel knife, the rest of the machines have other destinations), we chose from block options 4 and 5. These led to the data entry stage with the options in
Figure 5 and following the results in
Figure 6.
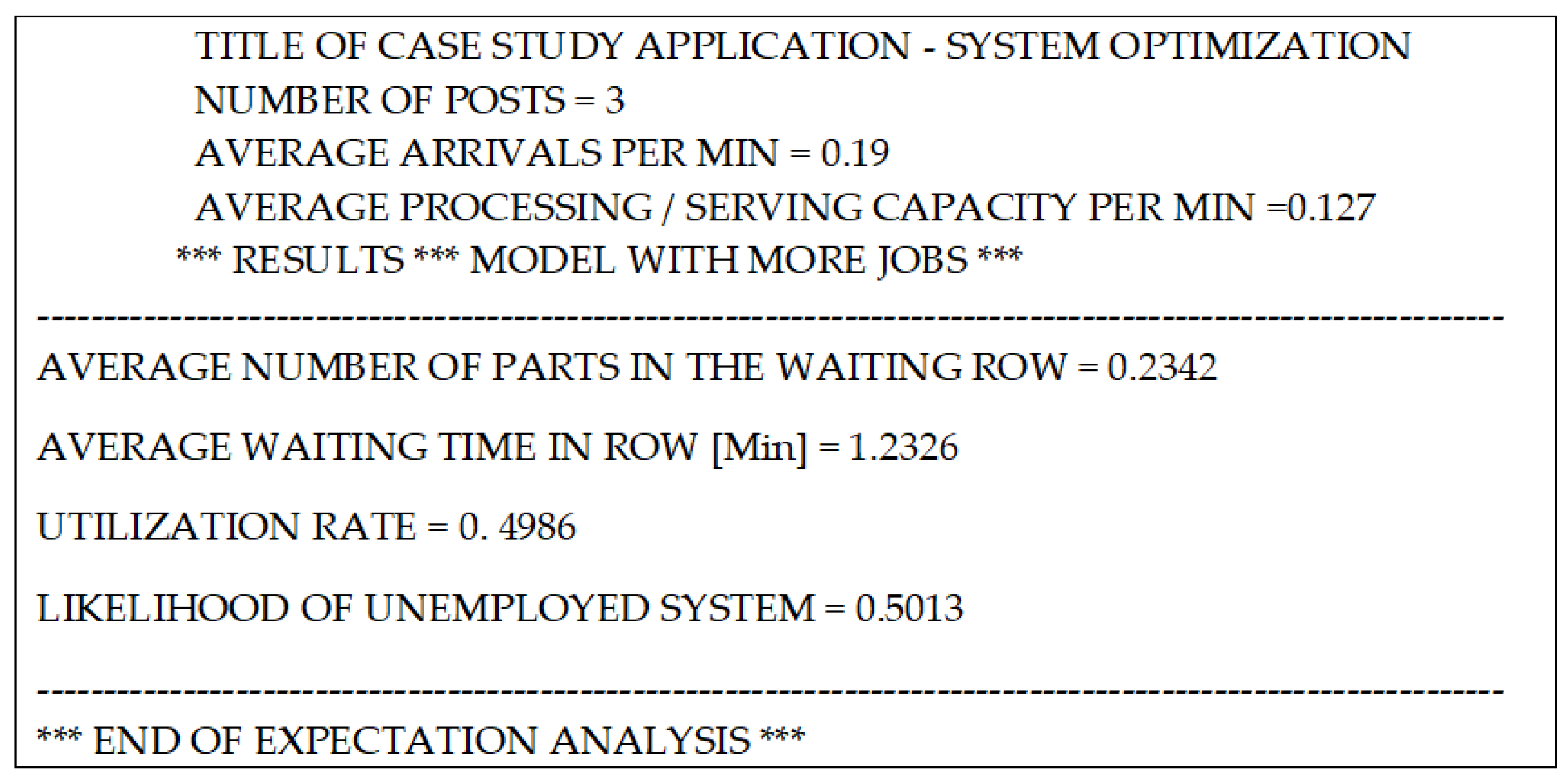
In the initial option, it was specified that in addition to the analysis of the expectations, it is desired to achieve the optimization of the waiting system in order to determine the optimal number of servers si that the expenses caused by waiting/parking machines—tools, on the one hand, and parts to be worked on, on the other hand—to be minimal, then the input data must be completed with the additional elements according to
Figure 7 this resulting in the completion of the output data with the elements related to optimization,
Figure 8.
In the C++ program, we simulated, during a maximum simulation period, the arrivals and services. Therefore we used the variable simulation clock.
We first estimated the average number of units in the system and the average number of units in the queue as:
The other elements were computed as follows. First, we took into account that the number of units in the queue conditioned by the existence of the queue (Kleinrock, 1975) geometric distributed with parameter
r. We then obtain the formula
The time spent in a queue conditioned by the existence of a queue is exponential of parameter
S∗
u∗(1 −
r). Therefore:
With the C++ simulation program with the same costs,
C1 = 150 and
C2 = 250, we first run for a maximum of seven servers in a system with one station. The first application was with
a = 0.6 and
u = 1. The next application was, in fact, with what we considered from the industry:
a = 0.19 and
u = 0.127. However, by changing the unit time, we can consider
u = 1 and by proportion
a = 1.5. The results are presented in
Appendix B.
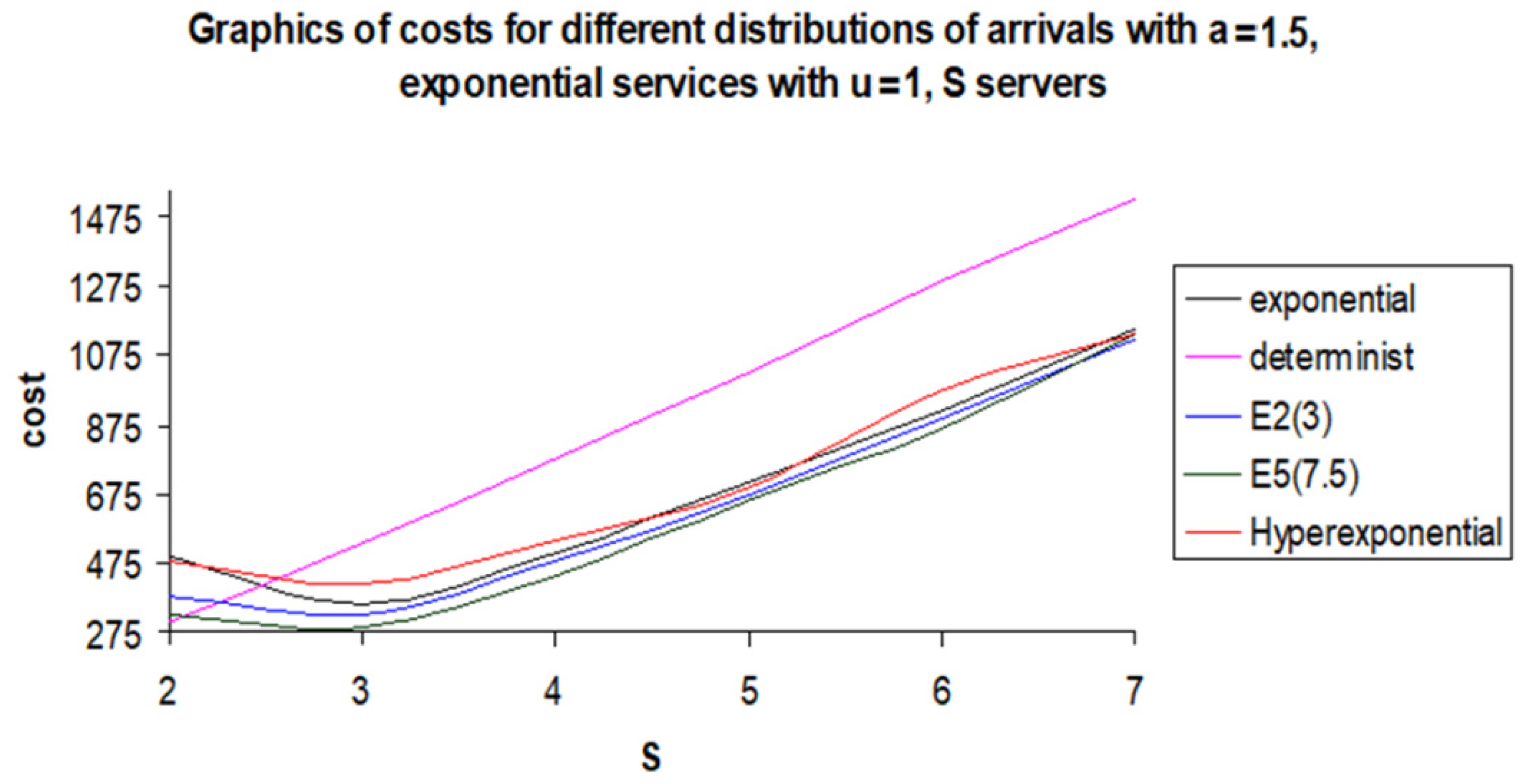
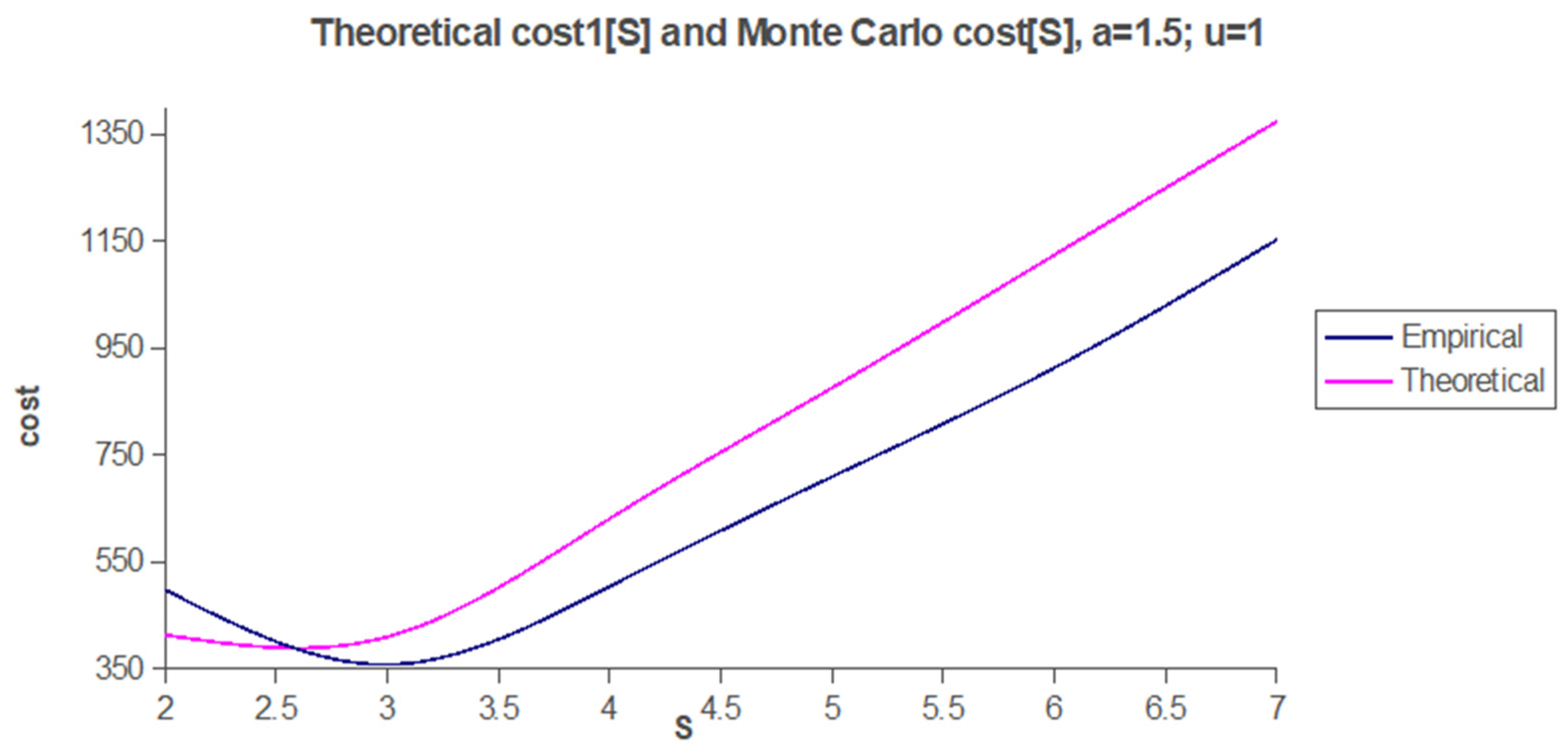
We finalized the analysis with comparative graphics of the costs with the comparative graphics of costs (
Figure 9).
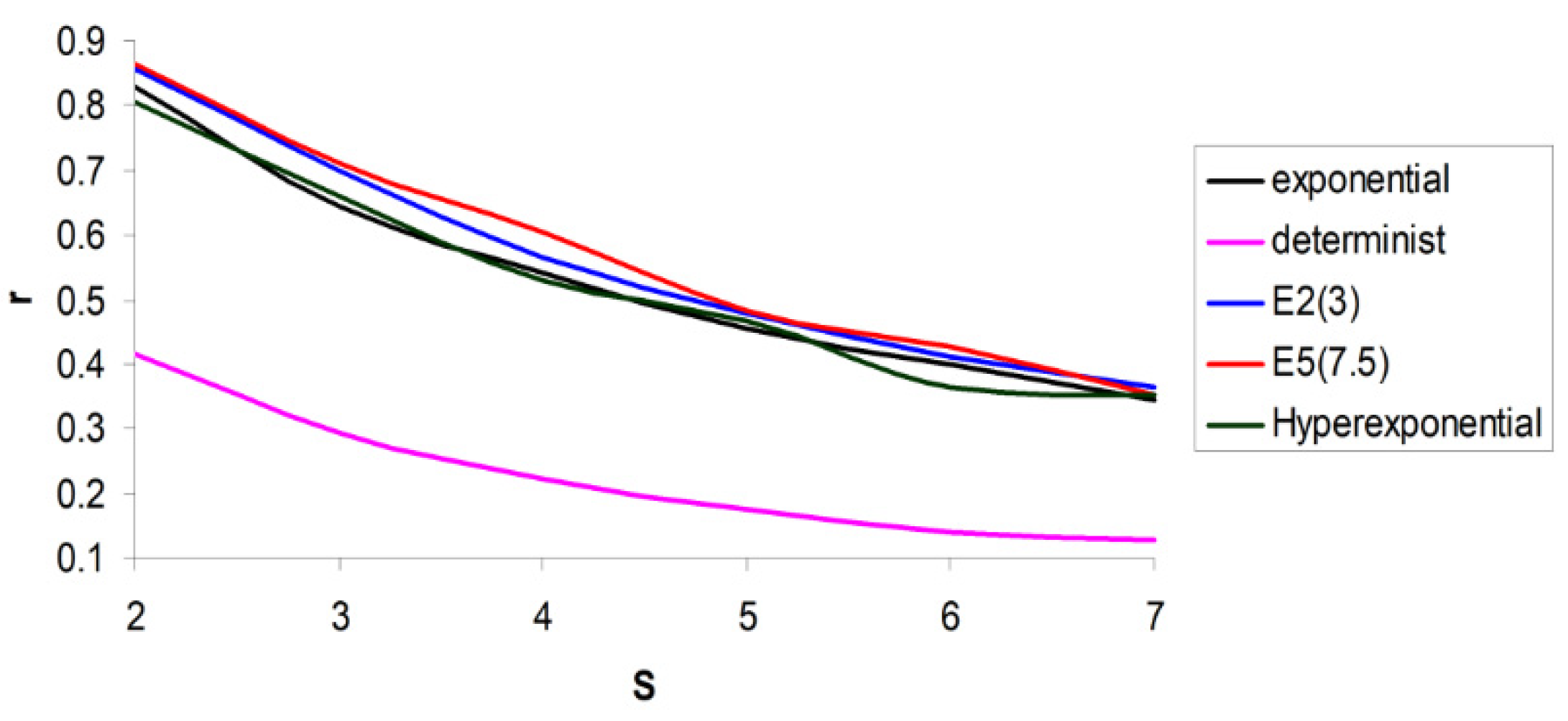
We noticed that the deterministic case is isolated. This can be explained by the fact that in this case, optimal
S is 2, while in the other cases, optimal
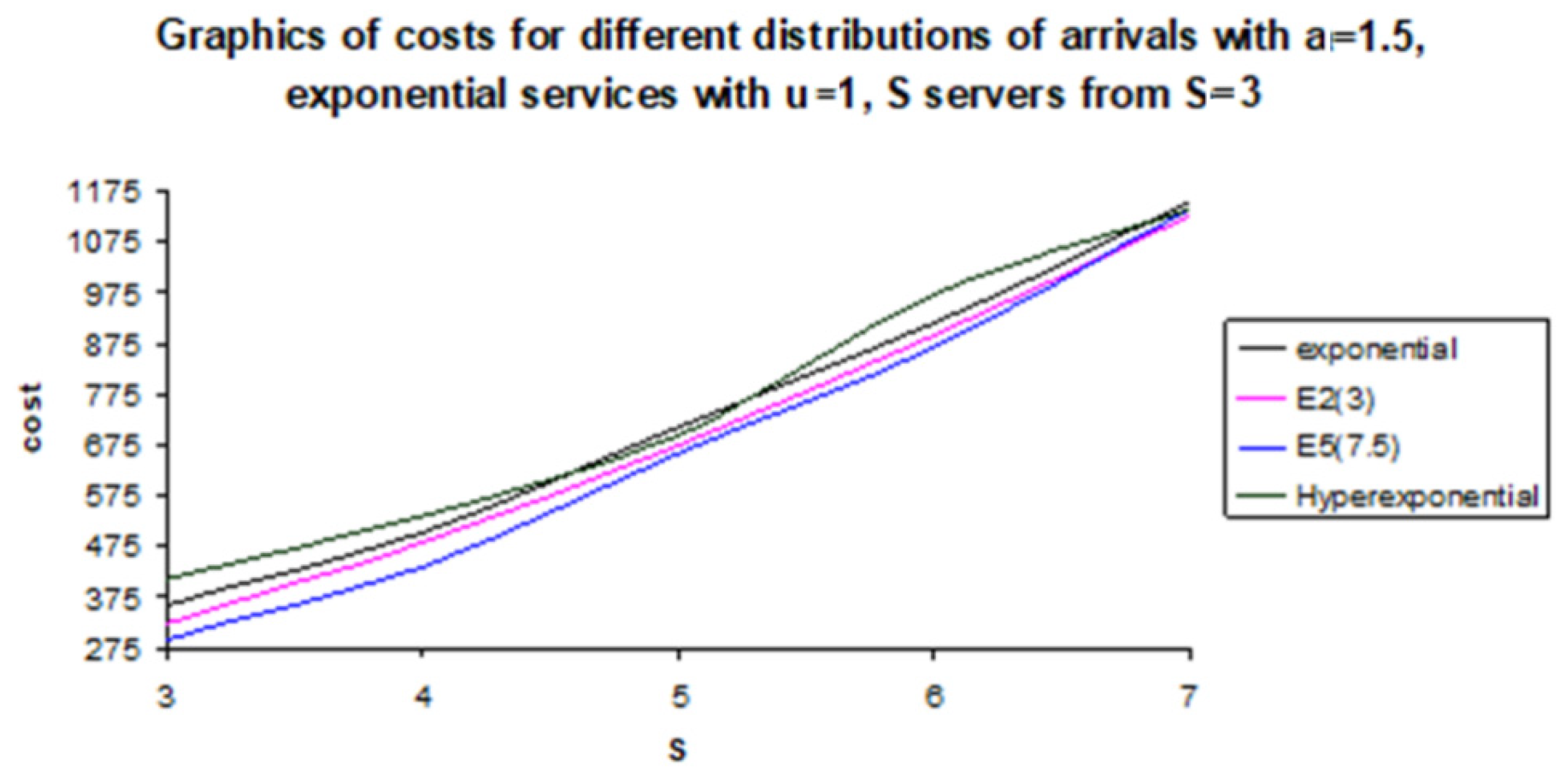
S is 3. In the following graphics (
Figure 10), we represented only the non-deterministic cases.
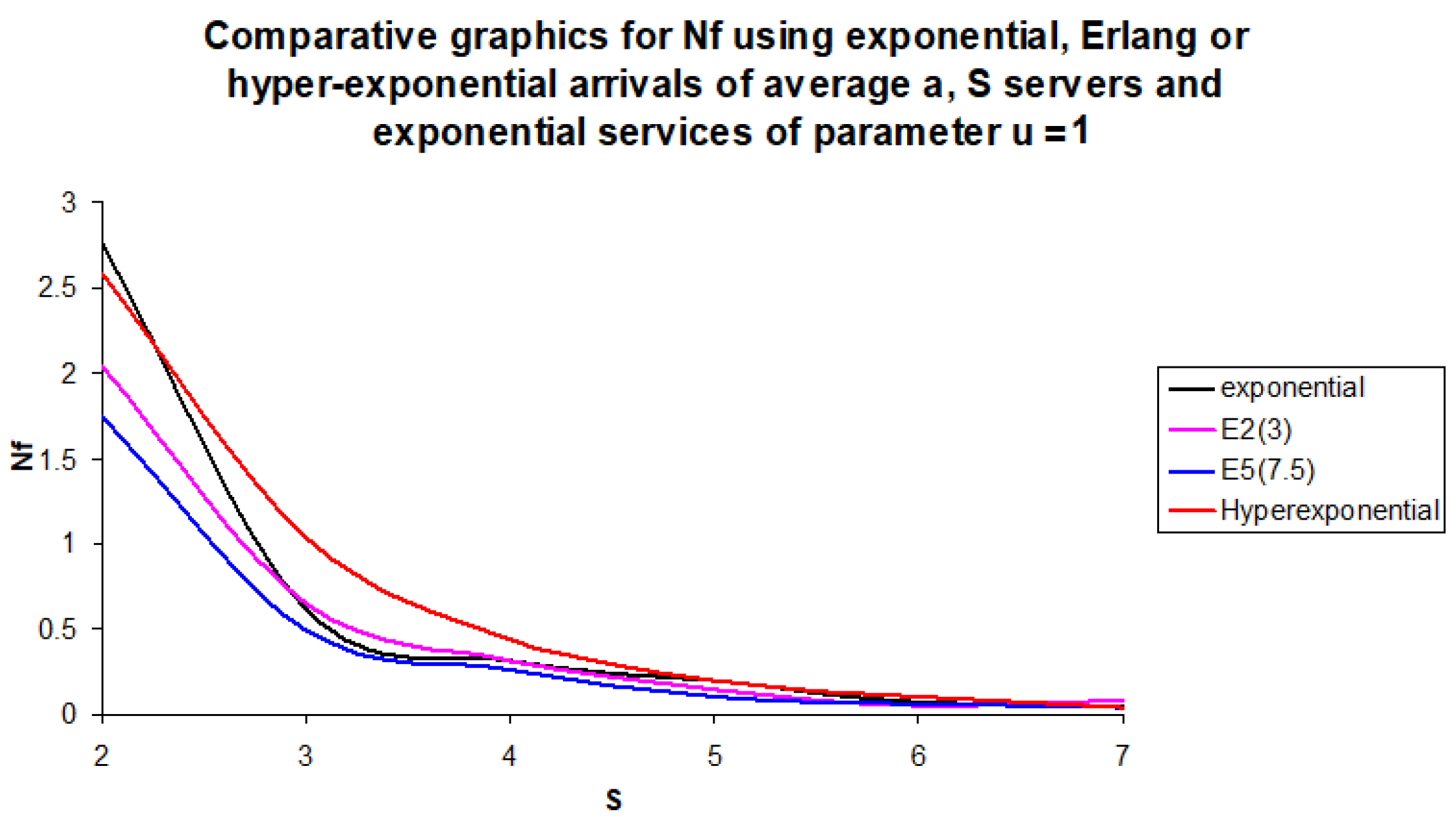
For the costs in non-deterministic cases, the increasing order is Erlang of order 5, Erlang of order 3, and exponential. The costs in the hyper-exponential case are greater than the two Erlang cases for all S between 2 and 7. Compared with exponential, the costs are greater for S = 3, 4 or 6 and are smaller in the other cases. In the deterministic case, the cost is minimal (comparing the other distribution) only for S = 2. For S > 2, the corresponding costs are greater than the exponential case, even if we add one server in the last case. They are also greater than that of the hyper-exponential case. The same property can be noticed in the exponential case, starting from S = 4.
From S = 6, the cost is greater than all the other costs from other distributions.



 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















