
Computational Intelligence-Based Harmony Search Algorithm for Real-Time Object Detection and Tracking in Video Surveillance Systems

 , ,
, ,
Abstract
:1. Introduction
2. Literature Review
3. The Proposed Model
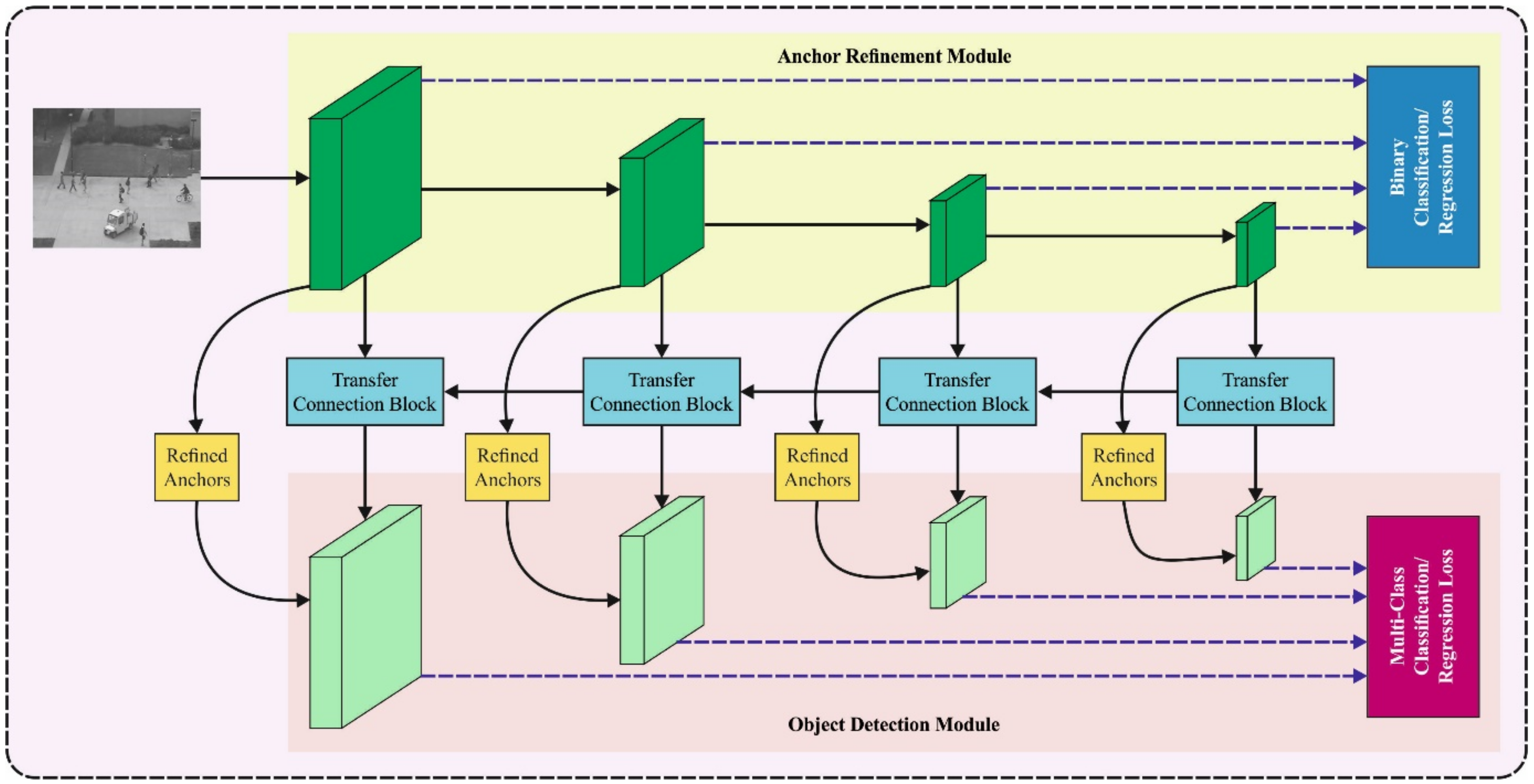
3.1. Object Detection Module: Adagrad with Improved RefineDet Model
3.1.1. ARM Module
3.1.2. TCB Module
3.1.3. ODM Module
3.1.4. Hyperparameter Optimization
3.2. Object Classification Module: HSA with TWSVM Model
- Step 1:
- Initialize Control Parameter.
- Step 2:
- Initialize Harmony memory.
- Step 3:
- Estimate the efficiency of present harmony.
- Step 4:
- Estimate the efficiency of recently created harmony and improvise harmony.
- Step 5:
- Check ending condition.
| Algorithm 1 Pseudocode of the harmony search algorithm (HSA). |
| Begin; |
| Determine objective function |
| Determine Harmony Memory Considering rate (HMCR) |
| Determine Pitch adjusting rate (PAR) and other parameters |
| Create Harmony Memory with arbitrary harmonies |
| while (t < max number of iterations) |
| while (I <= number of variables) |
| if (rand < HMCR), |
| Select the value in HM for the variable i |
| if (rand < PAR), |
| Modify the value by adding a particular amount |
| end if |
| else |
| Select an arbitrary value |
| end if |
| end while |
| Take the New Harmony (solution) if better |
| end while |
| Define the present optimum solution |
| End |
4. Performance Validation
4.1. Dataset Details
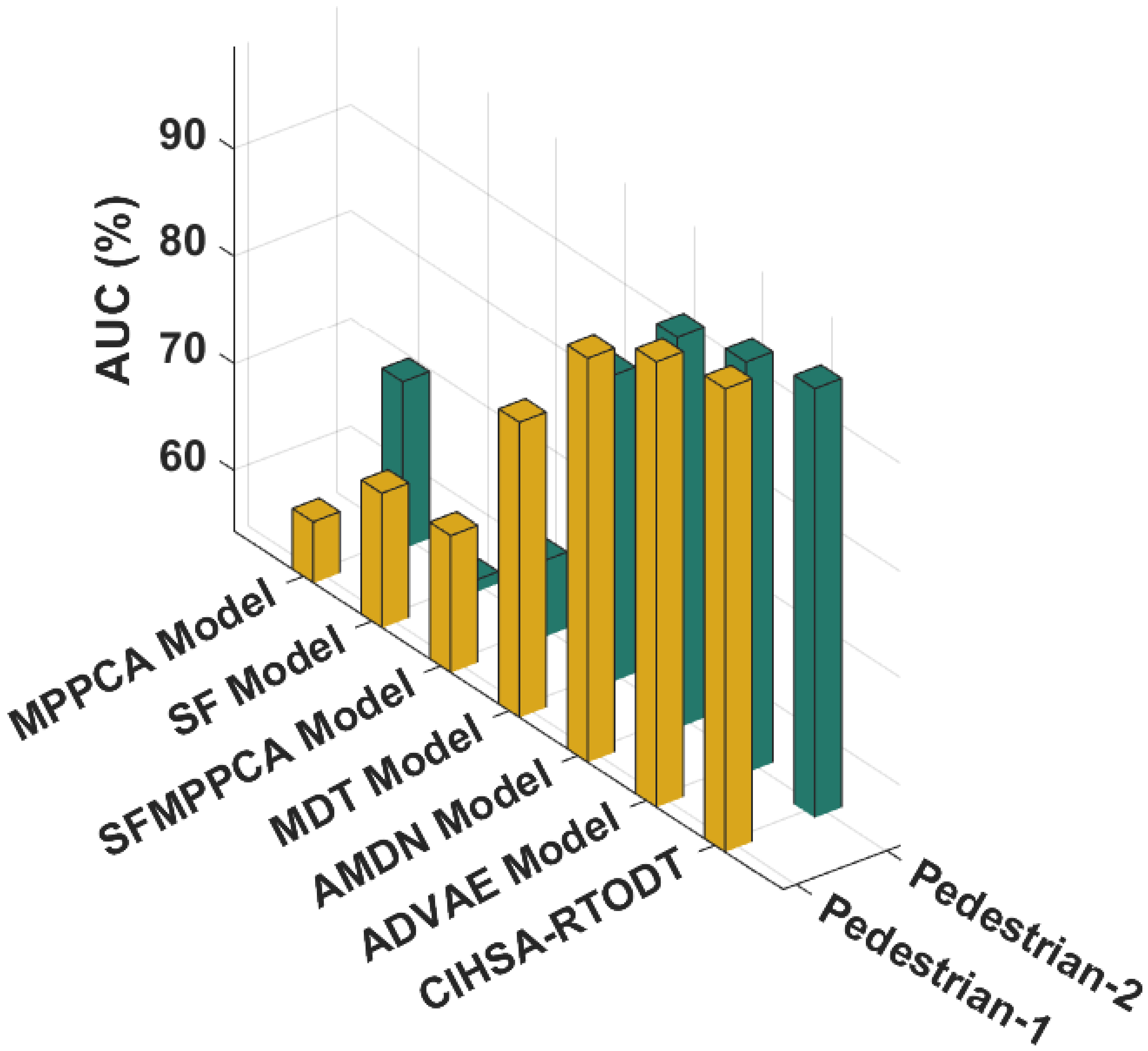
4.2. Detection Results of CIHSA-RTODT Technique
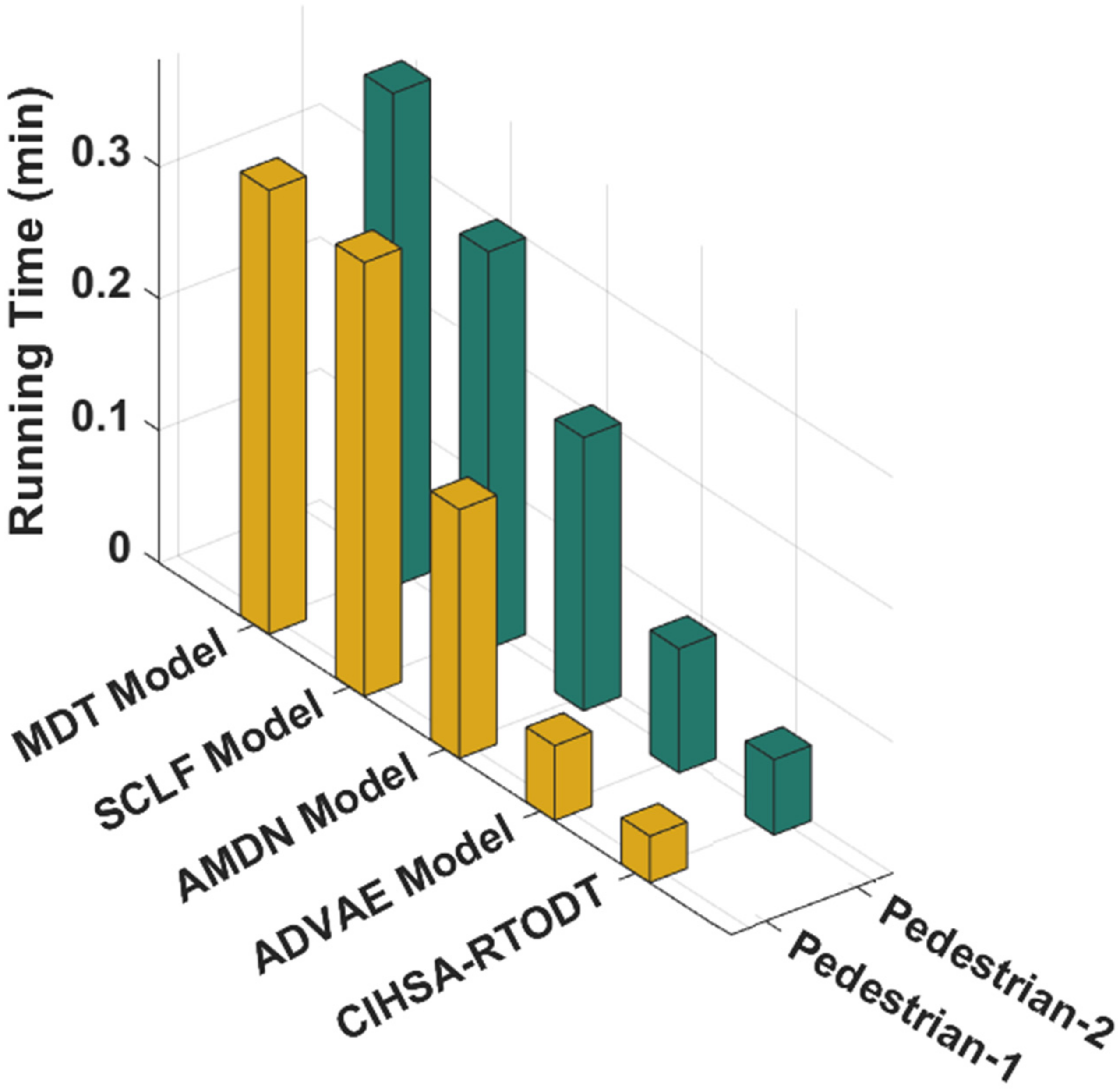
4.3. Running Time Analysis of CIHSA-RTODT Technique
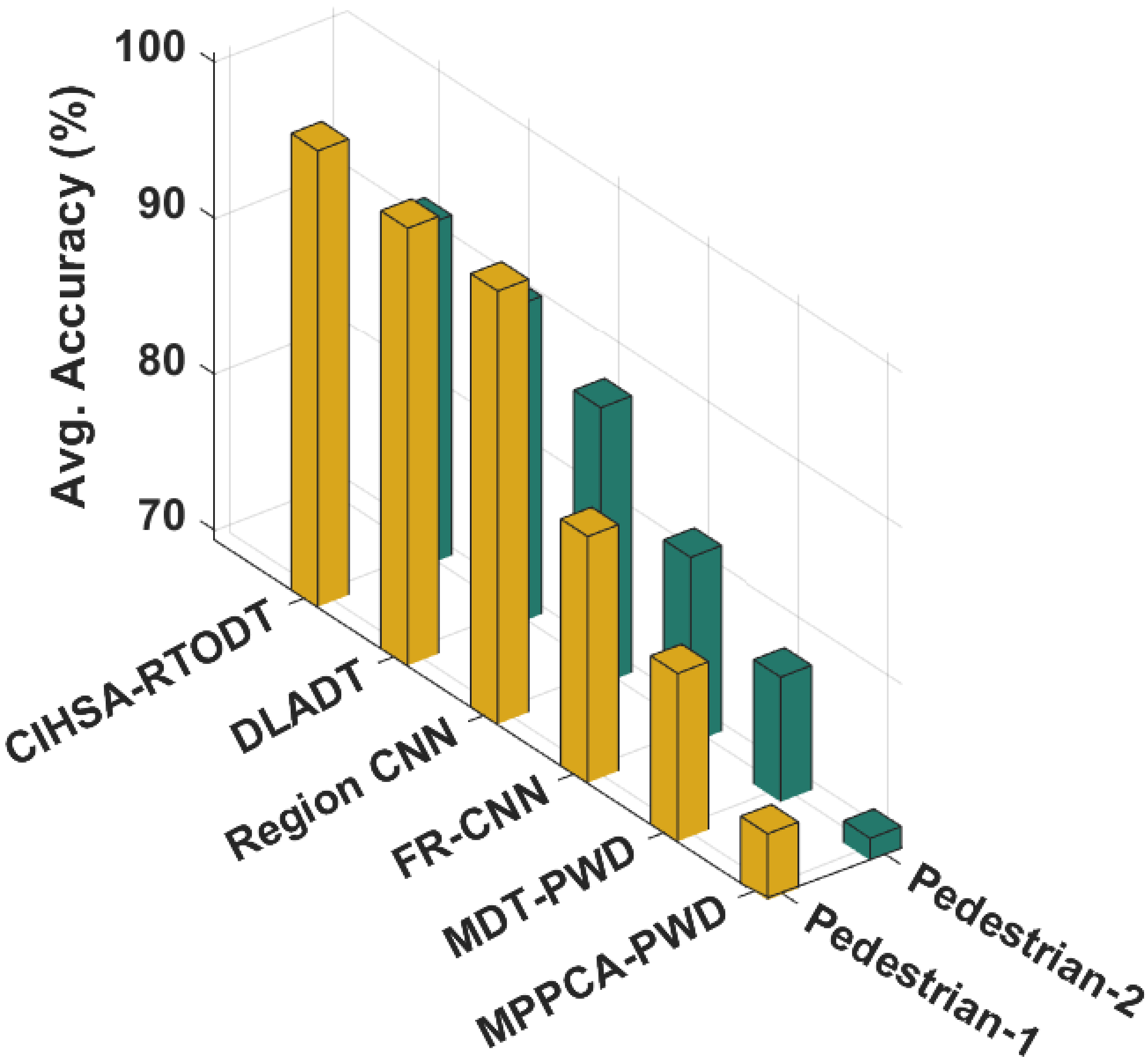
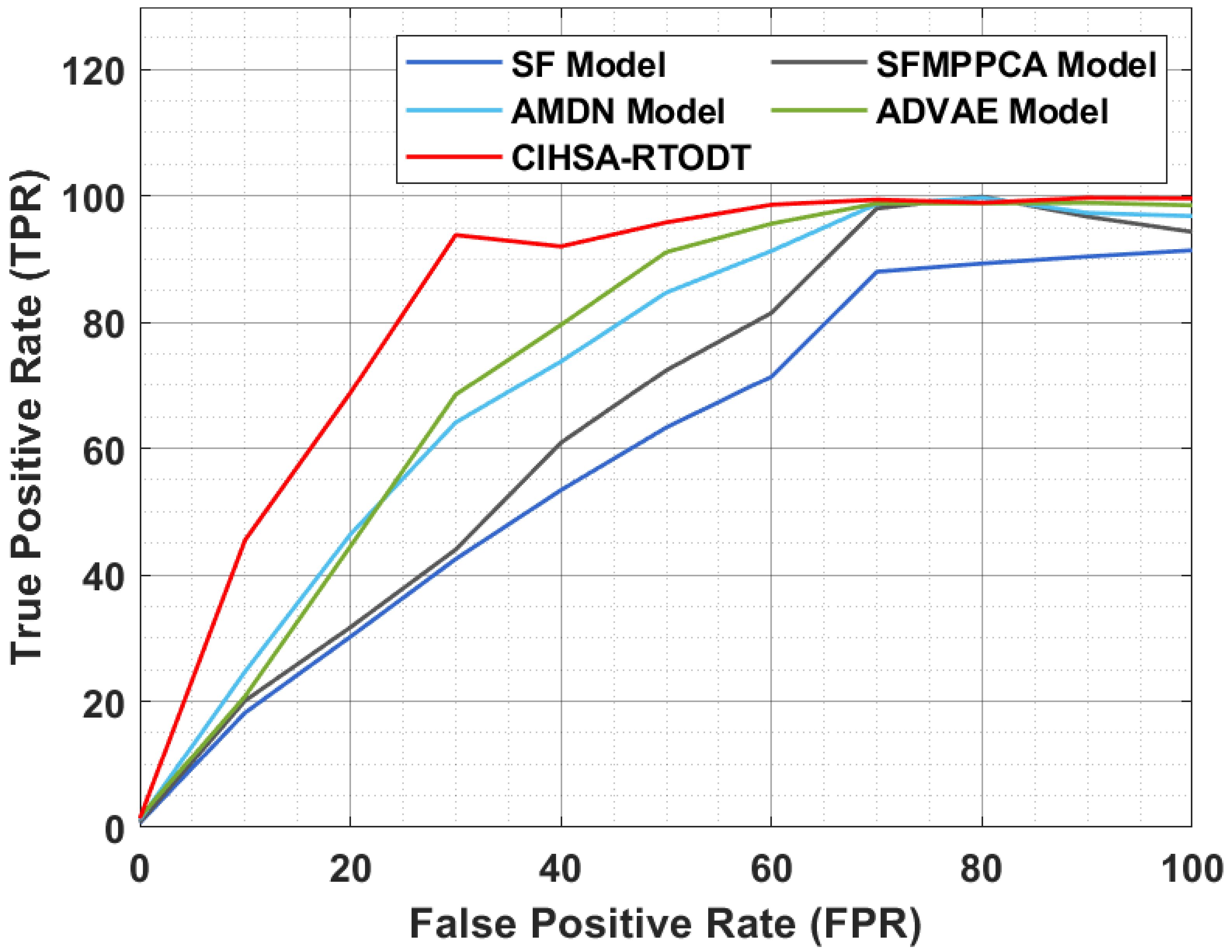
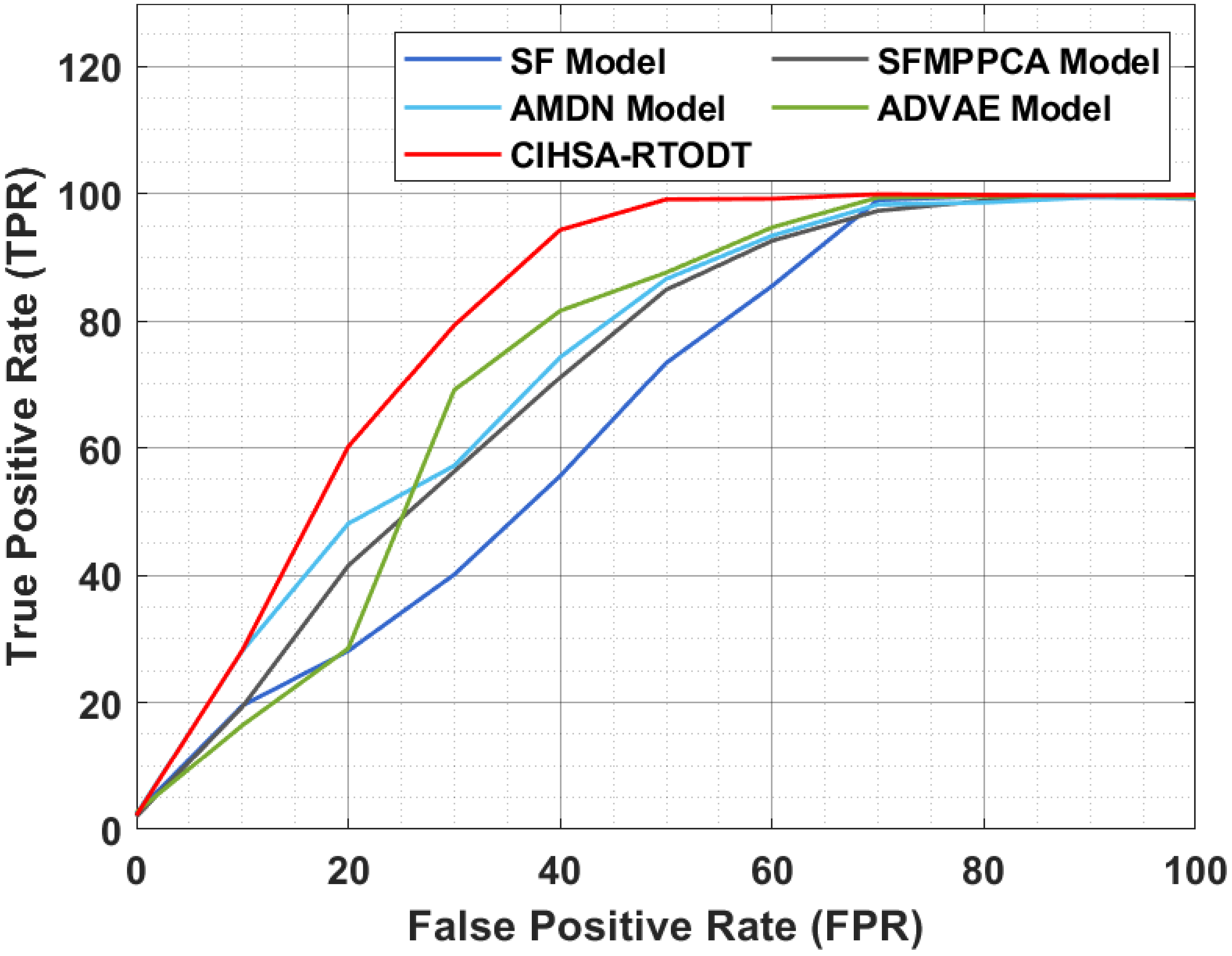
4.4. Comparative Result Analysis of CIHSA-RTODT Technique
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Pal, S.K.; Pramanik, A.; Maiti, J.; Mitra, P. Deep learning in multi-object detection and tracking: State of the art. Appl. Intell. 2021, 51, 6400–6429. [Google Scholar] [CrossRef]
- Połap, D.; Woźniak, M. Meta-heuristic as manager in federated learning approaches for image processing purposes. Appl. Soft Comput. 2021, 113, 107872. [Google Scholar] [CrossRef]
- Hatwar, R.B.; Kamble, S.D.; Thakur, N.V.; Kakde, S. A review on moving object detection and tracking methods in video. Int. J. Pure Appl. Math. 2018, 118, 511–526. [Google Scholar]
- Wieczorek, M.; Sika, J.; Wozniak, M.; Garg, S.; Hassan, M. Lightweight CNN model for human face detection in risk situations. IEEE Trans. Ind. Inform. 2021. early access. [Google Scholar] [CrossRef]
- Kaushal, M.; Khehra, B.S.; Sharma, A. Soft Computing based object detection and tracking approaches: State-of-the-Art survey. Appl. Soft Comput. 2018, 70, 423–464. [Google Scholar] [CrossRef]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.C.; Qi, H.; Lim, J.; Yang, M.H.; Lyu, S. UA-DETRAC: A new benchmark and protocol for multi-object detection and tracking. Comput. Vis. Image Underst. 2020, 193, 102907. [Google Scholar] [CrossRef] [Green Version]
- Połap, D.; Woźniak, M. Image features extractor based on hybridization of fuzzy controller and meta-heuristic. In Proceedings of the 2021 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Luxembourg, 11–14 July 2021; pp. 1–6. [Google Scholar]
- Chouhan, S.S.; Kaul, A.; Singh, U.P. Image segmentation using computational intelligence techniques. Arch. Comput. Methods Eng. 2019, 26, 533–596. [Google Scholar] [CrossRef]
- Połap, D.; Woźniak, M.; Mańdziuk, J. Meta-heuristic Algorithm as Feature Selector For Convolutional Neural Networks. In Proceedings of the 2021 IEEE Congress on Evolutionary Computation (CEC), Krakow, Poland, 28 June–1 July 2021; pp. 666–672. [Google Scholar]
- Elhoseny, M. Multi-object detection and tracking (MODT) machine learning model for real-time video surveillance systems. Circuits Syst. Signal Processing 2020, 39, 611–630. [Google Scholar] [CrossRef]
- Supreeth, H.S.G.; Patil, C.M. Efficient multiple moving object detection and tracking using combined background subtraction and clustering. Signal Image Video Processing 2018, 12, 1097–1105. [Google Scholar] [CrossRef]
- Lyu, Y.; Yang, M.Y.; Vosselman, G.; Xia, G.S. Video object detection with a convolutional regression tracker. ISPRS J. Photogramm. Remote Sens. 2021, 176, 139–150. [Google Scholar] [CrossRef]
- Xiong, Y.; Ge, Y.; From, P.J. An improved obstacle separation method using deep learning for object detection and tracking in a hybrid visual control loop for fruit picking in clusters. Comput. Electron. Agric. 2021, 191, 106508. [Google Scholar] [CrossRef]
- Lin, X.; Li, C.T.; Sanchez, V.; Maple, C. On the detection-to-track association for online multi-object tracking. Pattern Recognit. Lett. 2021, 146, 200–207. [Google Scholar] [CrossRef]
- Chen, H.; Cai, W.; Wu, F.; Liu, Q. Vehicle-mounted far-infrared pedestrian detection using multi-object tracking. Infrared Phys. Technol. 2021, 115, 103697. [Google Scholar] [CrossRef]
- Schöller, F.E.T.; Blanke, M.; Plenge-Feidenhans, M.K.; Nalpantidis, L. Vision-based object tracking in marine environments using features from neural network detections. IFAC-Pap. 2020, 53, 14517–14523. [Google Scholar] [CrossRef]
- Shi, J.; Wang, X.; Xiao, H. Real-Time Pedestrian Tracking and Counting with TLD. J. Adv. Transp. 2018, 2018, 8486906. [Google Scholar] [CrossRef] [Green Version]
- Xie, H.; Wu, Z. A robust fabric defect detection method based on improved RefineDet. Sensors 2020, 20, 4260. [Google Scholar] [CrossRef]
- Lydia, A.; Francis, S. Adagrad—An optimizer for stochastic gradient descent. Int. J. Inf. Comput. Sci. 2019, 6, 566–568. [Google Scholar]
- Sadewo, W.; Rustam, Z.; Hamidah, H.; Chusmarsyah, A.R. Pancreatic Cancer Early Detection Using Twin Support Vector Machine Based on Kernel. Symmetry 2020, 12, 667. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Nalepa, J.; Kawulok, M. Selecting training sets for support vector machines: A review. Artif. Intell. Rev. 2019, 52, 857–900. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.Z.; Govindasamy, V.; Xu, H.; Wang, X.; Zenger, K. Harmony search method: Theory and applications. Comput. Intell. Neurosci. 2015, 2015, 39. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Available online: http://www.Svcl.Ucsd.Edu/Projects/Anomaly/Dataset.Htm (accessed on 20 January 2022).
- Pustokhina, I.V.; Pustokhin, D.A.; Vaiyapuri, T.; Gupta, D.; Kumar, S.; Shankar, K. An automated deep learning based anomaly detection in pedestrian walkways for vulnerable road users safety. Saf. Sci. 2021, 142, 105356. [Google Scholar] [CrossRef]
- Xu, M.; Yu, X.; Chen, D.; Wu, C.; Jiang, Y. An efficient anomaly detection system for crowded scenes using variational autoencoders. Appl. Sci. 2019, 9, 3337. [Google Scholar] [CrossRef] [Green Version]
- Murugan, B.S.; Elhoseny, M.; Shankar, K.; Uthayakumar, J. Region-based scalable smart system for anomaly detection in pedestrian walkways. Comput. Electr. Eng. 2019, 75, 146–160. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Testbed | Frames No. | Time (s) |
|---|---|---|---|
| UCSDped2 | Pedestrian-1 Dataset | 360 | 12 |
| Pedestrian-2 Dataset |
| Models | Running Time (min) | |
|---|---|---|
| Pedestrian-1 | Pedestrian-2 | |
| MDT Model | 0.336 | 0.373 |
| SCLF Model | 0.328 | 0.300 |
| AMDN Model | 0.188 | 0.207 |
| ADVAE Model | 0.057 | 0.094 |
| CIHSA-RTODT | 0.035 | 0.057 |
| Models | AUC (%) | |
|---|---|---|
| Pedestrian-1 | Pedestrian-2 | |
| MPPCA Model | 60.00 | 69.87 |
| SF Model | 66.85 | 55.42 |
| SFMPPCA Model | 67.11 | 61.43 |
| MDT Model | 81.84 | 82.85 |
| AMDN Model | 92.00 | 90.75 |
| ADVAE Model | 95.85 | 92.63 |
| CIHSA-RTODT | 97.51 | 94.32 |
| FPR | Methods | ||||
|---|---|---|---|---|---|
| SF Model | SFMPPCA Model | AMDN Model | ADVAE Model | CIHSA-RTODT | |
| 10 | 18.20 | 20.10 | 24.70 | 20.80 | 45.50 |
| 20 | 30.20 | 31.70 | 46.40 | 44.50 | 68.80 |
| 30 | 42.50 | 44.00 | 64.10 | 68.50 | 93.80 |
| 40 | 53.40 | 60.90 | 73.80 | 79.60 | 92.00 |
| 50 | 63.30 | 72.40 | 84.70 | 91.10 | 95.80 |
| 60 | 71.40 | 81.50 | 91.30 | 95.60 | 98.60 |
| 70 | 88.00 | 98.00 | 98.70 | 98.80 | 99.40 |
| 80 | 89.30 | 99.90 | 99.70 | 98.80 | 98.90 |
| 90 | 90.40 | 96.70 | 97.30 | 98.90 | 99.70 |
| 100 | 91.39 | 94.30 | 96.80 | 98.50 | 99.60 |
| FPR | Methods | ||||
|---|---|---|---|---|---|
| SF Model | SFMPPCA Model | AMDN Model | ADVAE Model | CIHSA-RTODT | |
| 10 | 19.50 | 19.30 | 28.10 | 16.40 | 28.20 |
| 20 | 28.10 | 41.50 | 48.10 | 28.50 | 60.20 |
| 30 | 40.10 | 56.30 | 57.20 | 69.10 | 79.30 |
| 40 | 55.60 | 71.10 | 74.30 | 81.60 | 94.30 |
| 50 | 73.40 | 84.90 | 86.60 | 87.60 | 99.10 |
| 60 | 85.50 | 92.60 | 93.40 | 94.70 | 99.20 |
| 70 | 99.00 | 97.30 | 98.30 | 99.40 | 99.90 |
| 80 | 99.60 | 98.90 | 98.60 | 99.60 | 99.80 |
| 90 | 99.60 | 99.50 | 99.40 | 99.70 | 99.70 |
| 100 | 99.70 | 99.20 | 99.30 | 99.50 | 99.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, M.F.; Omri, M.; Abdel-Khalek, S.; Khalil, E.; Mansour, R.F. Computational Intelligence-Based Harmony Search Algorithm for Real-Time Object Detection and Tracking in Video Surveillance Systems. Mathematics 2022, 10, 733. https://0-doi-org.brum.beds.ac.uk/10.3390/math10050733
Alotaibi MF, Omri M, Abdel-Khalek S, Khalil E, Mansour RF. Computational Intelligence-Based Harmony Search Algorithm for Real-Time Object Detection and Tracking in Video Surveillance Systems. Mathematics. 2022; 10(5):733. https://0-doi-org.brum.beds.ac.uk/10.3390/math10050733
Chicago/Turabian StyleAlotaibi, Maged Faihan, Mohamed Omri, Sayed Abdel-Khalek, Eied Khalil, and Romany F. Mansour. 2022. "Computational Intelligence-Based Harmony Search Algorithm for Real-Time Object Detection and Tracking in Video Surveillance Systems" Mathematics 10, no. 5: 733. https://0-doi-org.brum.beds.ac.uk/10.3390/math10050733