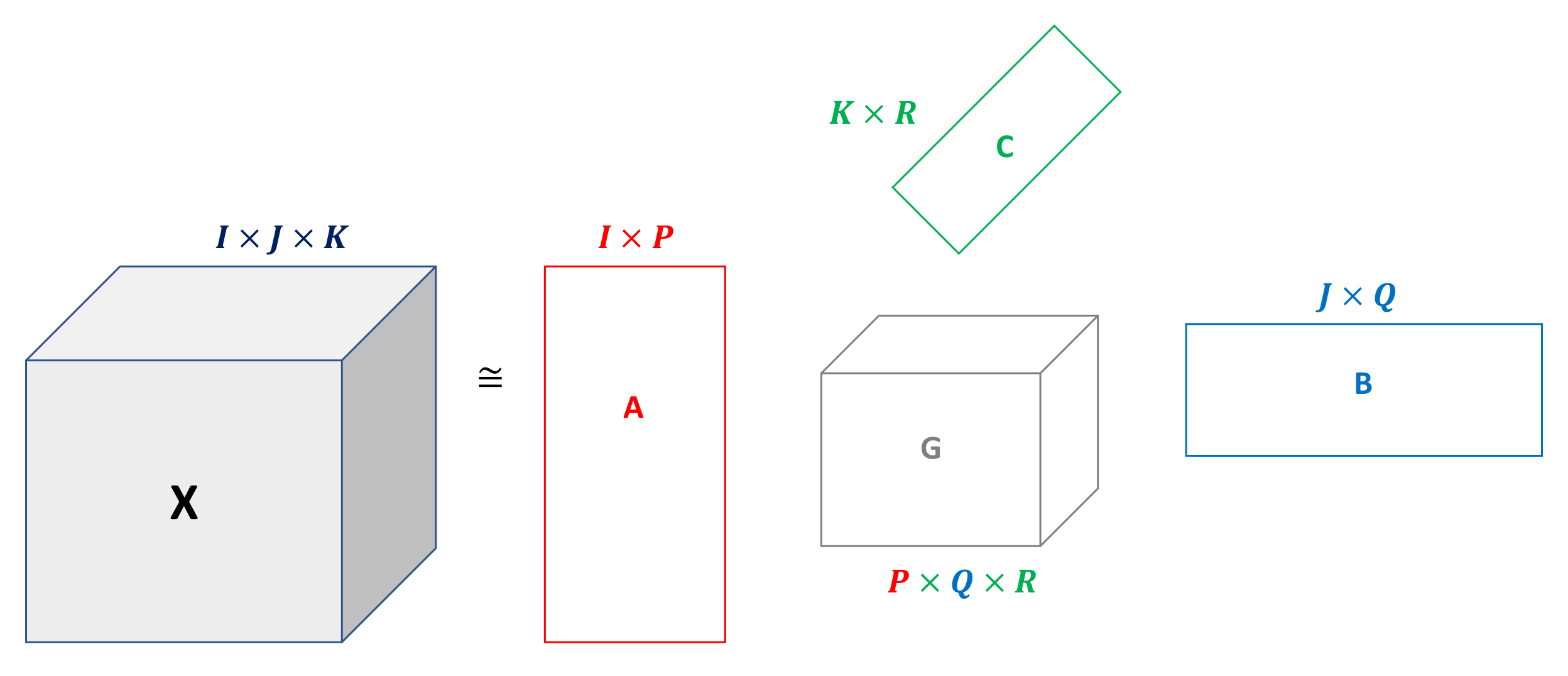
3.3. Three-Way Analysis
Data are organized in a three-way array , so that the element contains the ratio of passengers in the station i at time j on day k. It is important to notice that three-way models need the number of variables to be the same each day. For this reason, only those hours in which all stations are open every day, i.e., 5:00 to 24:00, are studied.
The model chosen for the analysis of these data was the Tucker3 model, as it was considered that the number of components for each mode could be different. The R package ThreeWay [
38] was used for data analysis.
Tucker3 analysis was performed on the dataset for all valid ranks between
and
. In order to select between the many estimated models a solution that optimally balances model fit and model complexity, the CHull model selection procedure was applied [
34,
36] with the fit percentages and the total number of fitted components (i.e.,
) as complexity value. The best solutions found were those located along the higher boundary of the convex hull. These solutions, together with the corresponding
-values, are shown in
Table 2.
Based on the CHull plot, shown in
Figure 6, and the results presented in
Table 2, it was decided to keep the
solution, which has two components for stations, three components for hours, and two components for days.
This model explains
of the data variance. It is important to notice how, by increasing the number of components, the performance improves (see
Table 2); however, the interpretation of the model becomes more complex.
The rotational indeterminacy was used to reach the maximal simplicity for the core tensor and the component matrices in order to facilitate interpretation of the solution. The post-processed component matrices for timetable and days are given in
Table 3 and
Table 4. The post-processed core array is presented in
Table 5. Note that the core array is presented as a matrix where rows represent the stations components and columns represent the combination of hours and days components. Part of the station component matrix, which is not shown in full because of its excessive length, can be found in
Table 6. Stations with high loads in the first component appear in the first block of the table, those with high loads in the second component appear in the second block, and finally in the third block those with high loads in both components.
To evaluate the results obtained, the three component matrices were inspected so that if an element has high value (in an absolute sense) on a component it is interpreted as playing an important role in the corresponding component.
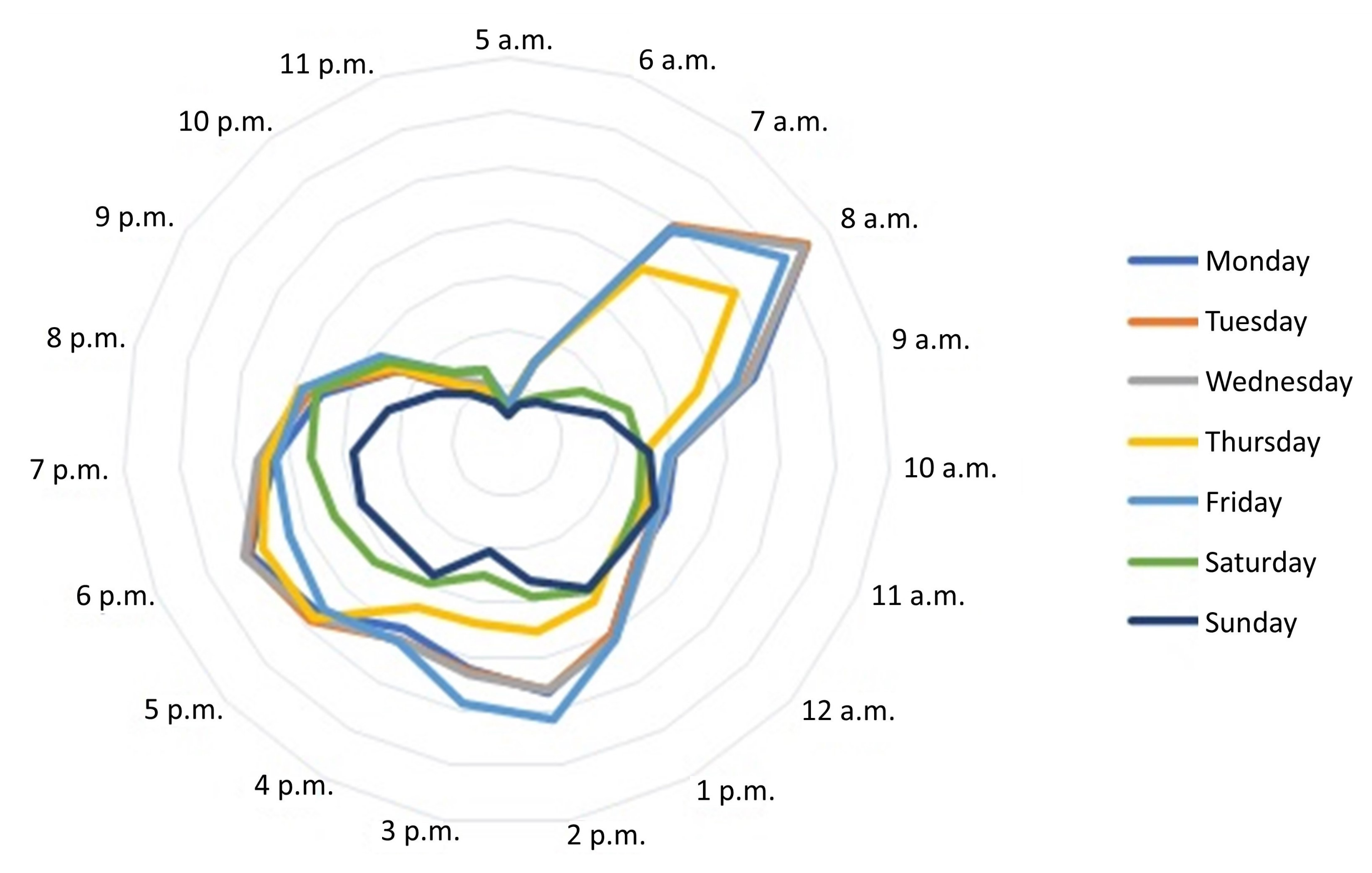
As previously noted, the time information is described in terms of the different loadings for each hour on the three components of the second mode (
Figure 7,
Figure 8 and
Figure 9). In
Table 3, it can be seen that Component 1 for the timetable mainly depends on 14:00, 15:00, 17:00, 18:00, 19:00, and 20:00. Hence, this component can be associated with afternoon and evening peak hours. Component 2 is strongly related to 10:00, 11:00, and 12:00, and so this component could be defined as off-peak hours. Finally, Component 3 has high values on 7:00 and 8:00 so it could be interpreted as morning rush hour. Some hours present high loads in more than one component, e.g., 9:00, with high loads on the second and third components.
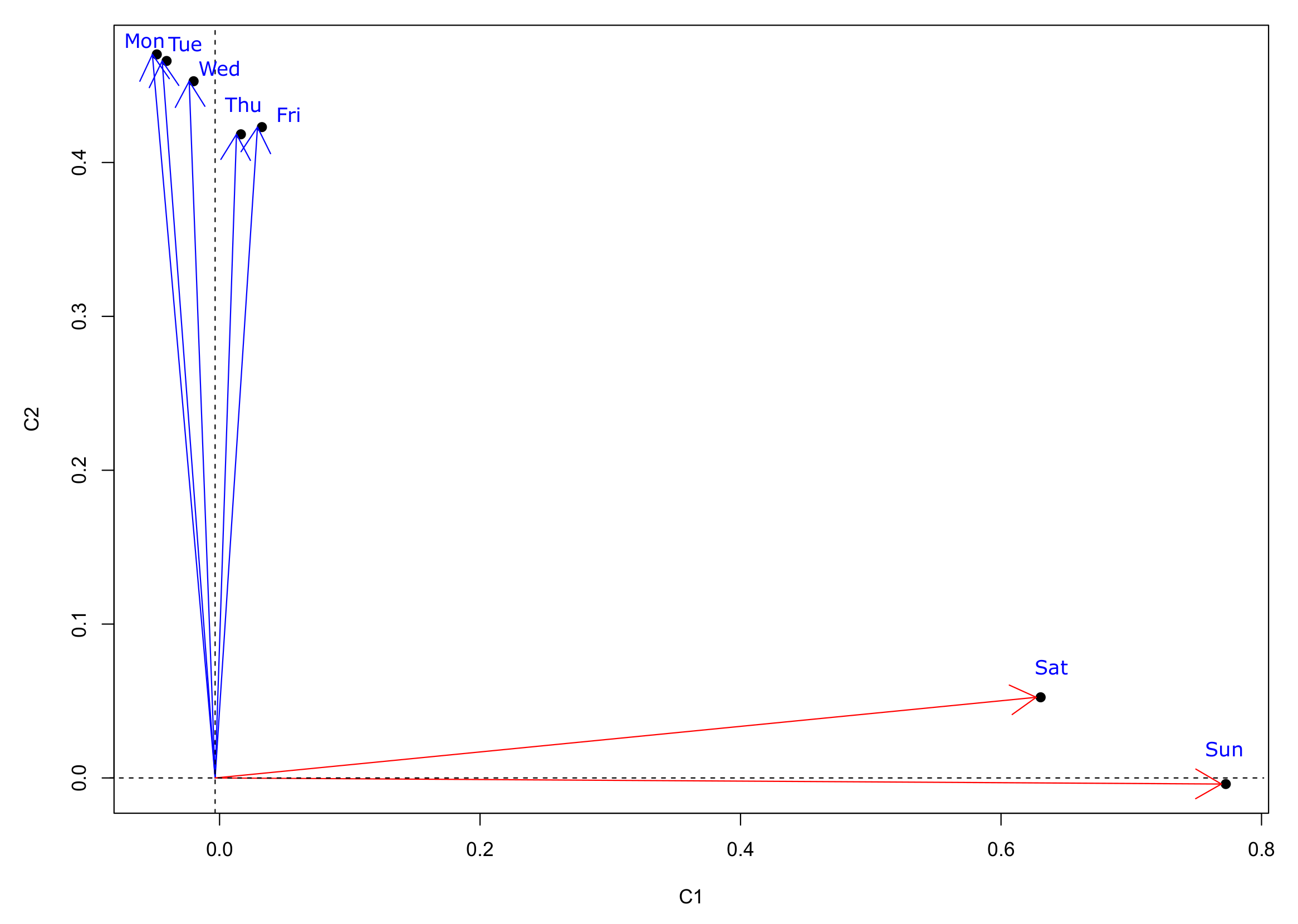
When inspecting the day component matrix (see
Table 4 and
Figure 10), it can be noted that the first component refers to weekend days and the second component clearly refers to weekdays, as Saturday and Sunday load high on the first component and the rest of the days on the second one.
The station scores (shown for prototypical stations in
Table 6) indicate the position of each station on these dimensions. When discarding small station scores, most stations have high loadings on one dimension and a few on both dimensions. It is important to note that the stations that score high in one component score negatively in the other one. For example, Roquetes and Santa Rosa are the stations with the highest loading on the first dimension, Fira and Mas Blau the stations with the highest loading on the second dimension, and Poblenou and Hospital de Sant Pau load high on both dimensions. Therefore, three clusters of stations can be considered. The stations belonging to each cluster are shown in
Table 7. Cluster 1 is formed by stations that have a high score on the second dimension, cluster 2 by those with high scores on the first dimension, and, finally, cluster 3 by the stations that have high scores in both dimensions. To ease the interpretation of the results, spatial location of the clusters within the Barcelona metro network is shown in
Figure 11, where Voronoi diagrams (based on Euclidean distance) are used, so that each cell represents a station that is coloured according to the cluster it belongs to.
Cluster 1 includes, amongst others, stations located in the industrial and logistics zones of the city (Fira, Mas Blau, MercaBarna, and Parc Logístic), hospitals ( Hospital Clínic, Hospital de Bellvitge, and Vall D’Hebron), and those belonging to the University campus (Zona Univesitá, Marina, Universitat, Ciutadella, and Diagonal). In addtion, stations close to hotels and landmarks are included, such as Sagrada Família, El Born, Barceloneta, Plaza Catalunya, Passeig de Gràcia, Jardines de Pedralbes, Barrio de Gràcia, Les Rambles, and Palau de la Música, among others. The two stations in Barcelona’s airport also belong to this group. Stations in cluster 2 are mainly located in the municipalities of Badalona, San Adriá de Besós, Hospitalet de LLobregat, Esplugas de LLobregat, El Prat de LLobregat, Cornellá de LLobregat, Moncada y Reixach, Santa Coloma de Gramanet, and some surrounding neighbourhoods such as Nou Barris and Sant Andreu. Finally, stations in cluster 3 are locate around the city center of Barcelona, mainly in Sant Andreu y Horta Guinardó.
Once the component matrices have been analyzed individually for each mode, a detailed analysis of the core array is necessary. The core array summarizes the main interactions in the data. Therefore, the largest (in absolute value) core values are examined to find the main interactions.
The core matrix
indicates that the combination of components that extracts the largest variability is the combination of the first component of the first mode, the third component of the second mode, and the second component of the third mode,
(
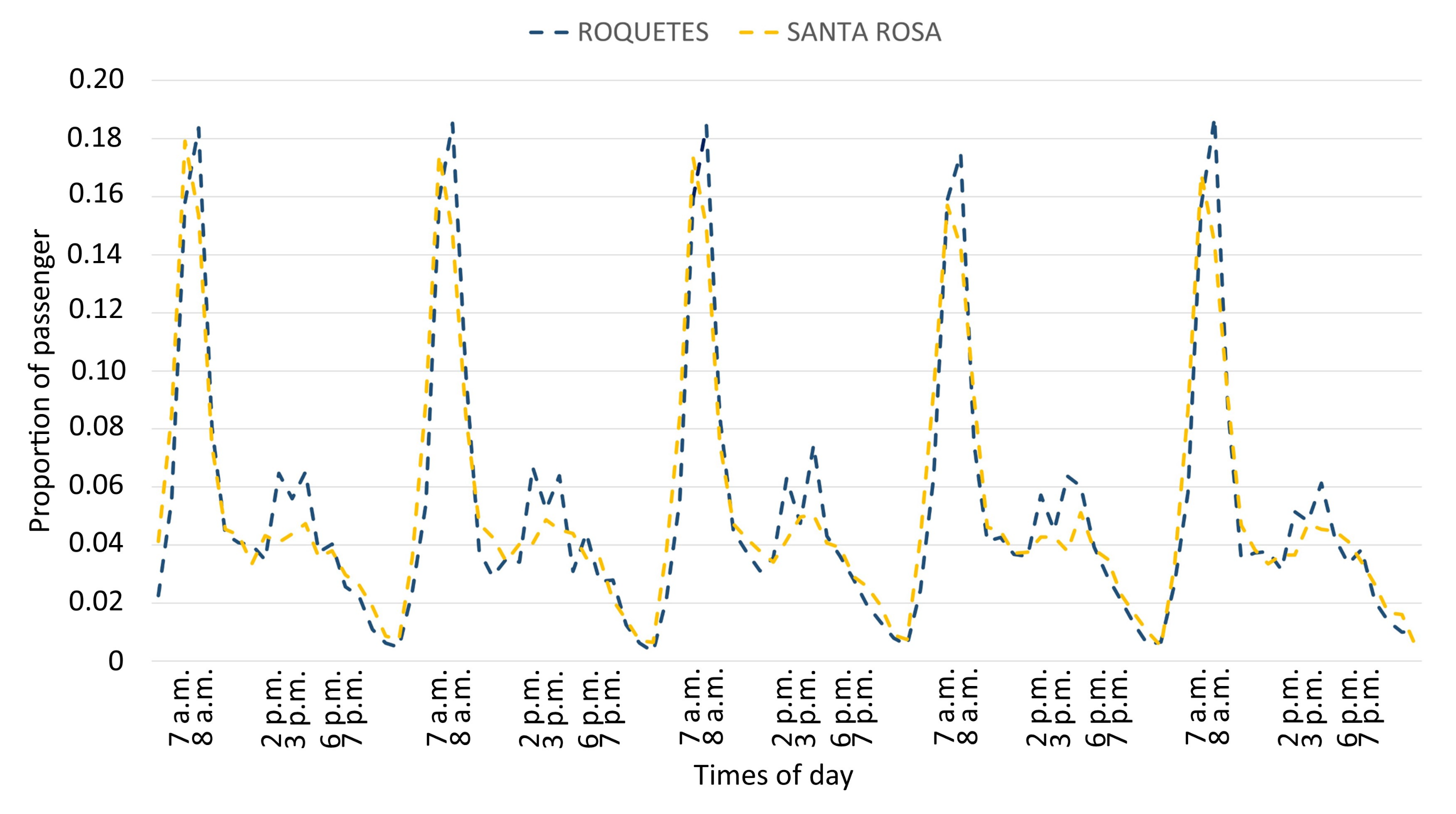
Table 5). It indicates positive interaction among components P1, Q3, and R2. This reveals that stations with high loadings on the first component have an increase in the proportion of passengers when associated with the morning peak hours (7 a.m., 8 a.m.) on weekdays. This is the case of stations belonging to the Cluster 2 like Roquetes or Santa Rosa, amongst others. The passenger’s pattern of proportion per hour for Roquetes and Santa Rosa stations, both belonging to Cluster 2, is shown in
Figure 12. In that figure, the highest passenger flow taking place between 7 and 8 in the morning is shown. In contrast, stations with negative values on the first component have a decrease in the proportion of passengers in the rush hours in the morning (
Figure 13).
The core element
among components P2, Q1, and R1 highlights that stations with high loading in the second component have a larger proportion of passengers in the afternoon and evening rush hours on weekdays. This is the case of stations in Cluster 1. In
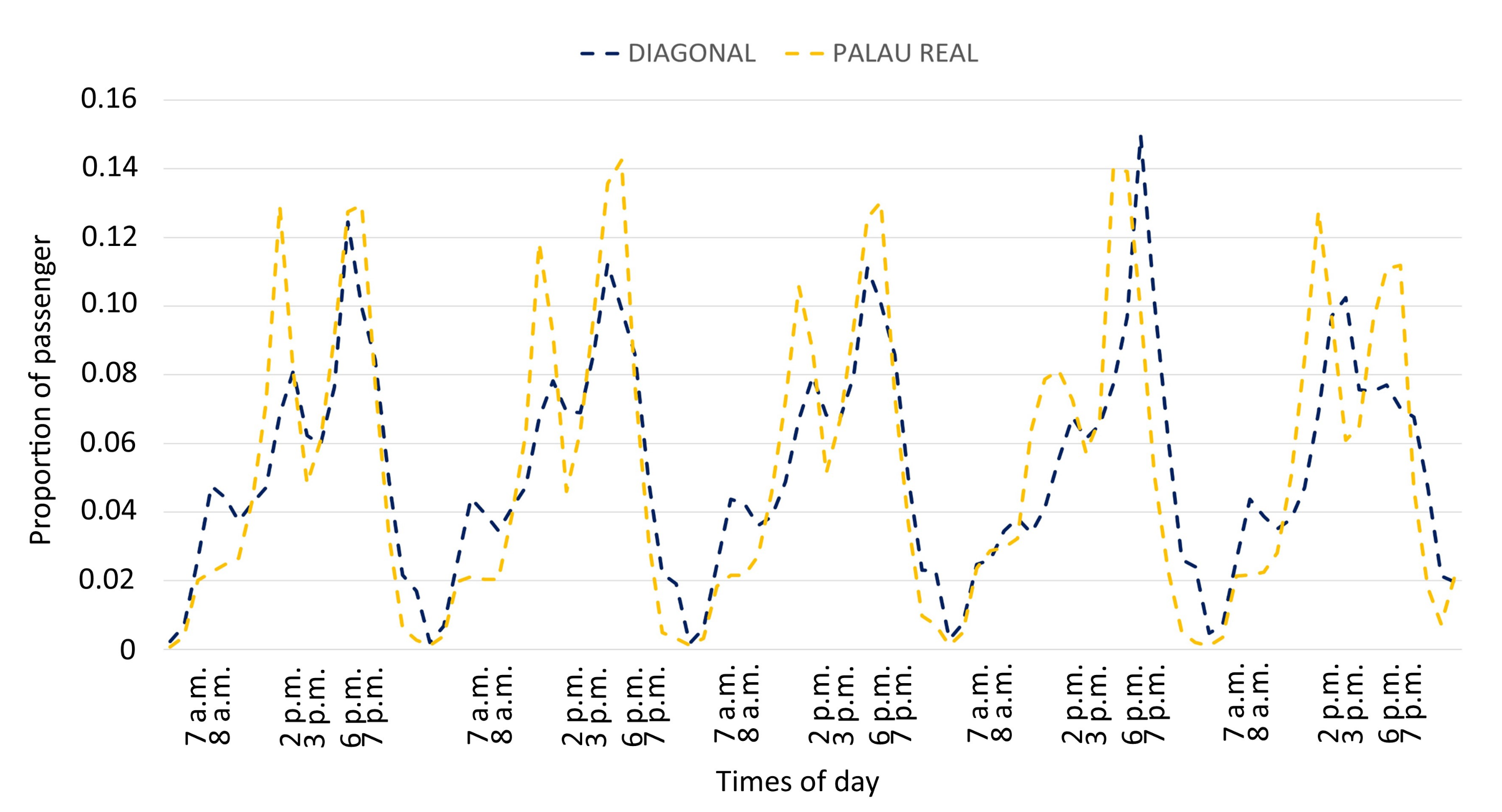
Figure 13, the pattern of proportion of passengers per hour is shown for Diagonal and Palau Real stations. According to the figure, the highest passenger flow takes place between 2 and 3 in the afternoon and 5 and 8 in the evening. It can also be seen how the stations in cluster 2 (with negative scores on the second component) have a lower proportion of passenger at peak hours in the afternoon and evening on weekdays (
Figure 12).
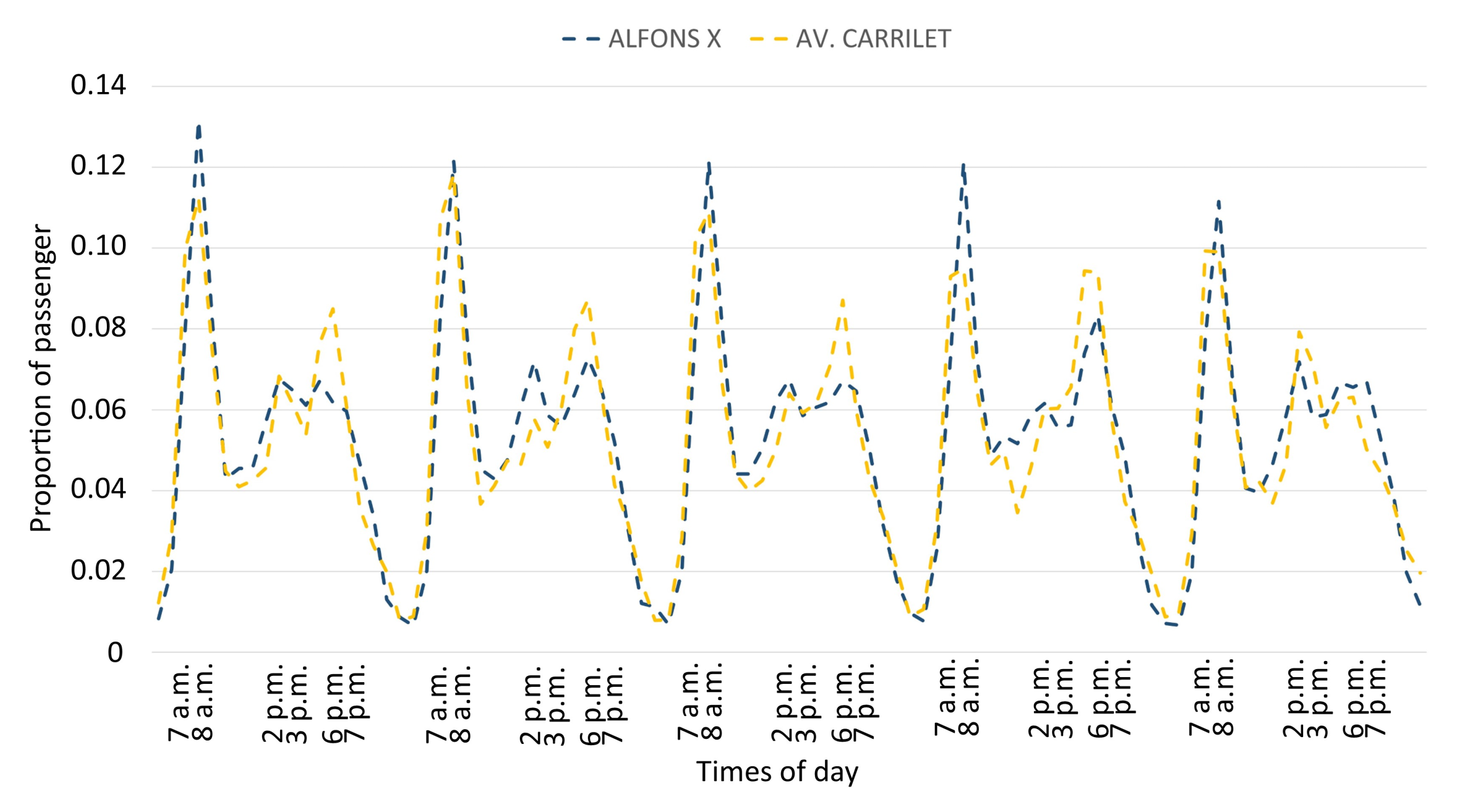
In contrast, as previously seen, there are stations with high loadings on both dimensions. Thus, in these stations there are peak hours both in the morning and in the afternoon on weekdays. Some stations in this group are Alfons X, Av.Carrilet, Clot, Bellvitge, Collblanc, Encants, Fabra i Puig, Hospital de Sant Pau, Joanic, and Poblenou.
Figure 14 shows the pattern of proportion of passengers per hour for some stations in this group.
It is important to notice that the core elements related to the first component of the third mode (weekend days) take values below one on the third component of timetable (morning rush hour) ( and ). This means there is no rush hour in the morning on weekends. Furthermore, the highest value in the core elements related to weekend days is , therefore the greatest interaction occurs between the stations with high values on the first component during off-peak hours. Interaction with the first component of timetable (afternoon and evening rush hour) is quite similar in all stations ( and ).


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}