1. Introduction
Virtualization [
1,
2], as an effective technology for resource sharing, enables resource multiplexing of the underlying physical machines. The most common examples are hypervisor-based virtualization [
3] and container-based virtualization [
4]. In hypervisor-based virtualization, a layer called
hypervisor [
5] is added on top of the host operating system that helps allow for the running of multiple virtual machines (VMs) on a single physical machine in isolation. However, hypervisor-based virtualization encounters numerous issues, such as kernel resource duplication, portability issue, and other. On the other hand, container-based virtualization [
4] is a lightweight alternative to hypervisor-based virtualization. In this, containers use the host kernel and more than one process can run within a container in isolation from other containers. With this, the system is more resource-efficient as there is no additional layer of hypervisor and no full OS, which occupy substantial storage space for each VM in the hypervisor-based virtualization.
There is no doubt that Docker [
6] is currently the most popular open-source application container engine. Compared with VM, Docker comes with many advantages, such as better system resource management, better administrative operations, and other. With the the popularity of container-based virtualization (i.e., containerization), the use of containers grows exponentially. Therefore, developers need some management systems to manage them freely but not manipulate them one by one. As this demand continues to grow, then comes the container orchestration systems. Especially, it is difficult and tedious for developers or maintainers to manage them one by one manually. That is why we need container orchestration system to automatically manage them. Notably, various orchestration frameworks are accessible from the community, such as Kubernetes (K8s) [
7], Mesos [
8], Docker Swarm [
9], Nomad [
10], SaltStack [
11], Amazon Elastic Container Service (Amazon ECS) [
12], OpenShift [
13,
14], and many other. Among them Kubernetes is the most popular and most commonly used [
15,
16]. Importantly, Kubernetes is the most popular container orchestration framework [
7,
15,
17,
18], so in this paper we narrow down our study to Kubernetes. (A comparative analysis is presented in the
Section 3.1.) Kubernetes (Kubernetes Official Documentation
https://kubernetes.io/docs/home/, accessed on 10 January 2023) is an open-source system for automating deployment, scaling, and management of containerized applications. It is a production-grade container orchestration system; briefly, K8s is a system that can easily manage the containers.
With the development of cloud computing technology, the container management architecture led by Kubernetes [
19,
20] has been adopted and promoted by more and more enterprises. One of its functions called
Autoscaling provides an automatic solution to handle dynamic requests from clients. Although it seems that the autoscaling solution provided by K8s is powerful enough, while most of the scaling strategies such as Horizontal Pod Autoscaler (HPA) are based on
Reactive autoscaling [
21,
22,
23] that uses CPU usage or memory as a metric. The reactive autoscaling schemes are triggered by a predefined set of rules. If the user requests increase sharply in a short time, this method causes overloading and loses a large number of requests because it is too late to react and adjust the autoscaler’s parameters. Therefore, scholars are trying to apply the
Proactive scaling method [
24,
25,
26,
27,
28] or
Hybrid scaling method [
29] based on time series prediction algorithms. Recently, Long Short-term Memory (LSTM) stands out among many time series prediction algorithms by its excellent prediction time and accuracy. Therefore, we thought of using the prediction logic of the LSTM model to substitute the HPA of K8s, hoping to save more resources while ensuring that the Pod is not overloaded (in Kubernetes, applications are deployed as Pods—a Pod is a single instance of an application.). Since HPA has no way to customize the expansion logic, we need to apply the network model through the method provided by the third party and test the performance.
To find a better scaling scheme on K8s that implements proactive approaches based on traffic prediction, we summarize the prominently used time series prediction models, i.e., load prediction methodologies (in
Section 3.2) and the latest K8s autoscaling schemes (in
Section 3.3) with obvious characteristics and excellent results. Among them, the time series prediction model is mainly based on the deep learning model,
LSTM is a common method used in many studies. Therefore, it is determined that the scheme we design also applies the time series prediction model to the autoscaling logic.
Next, we dive in analyzing the load prediction models, including the traditional forecasting models (ARIMA) and deep learning models (LSTM, BiLSTM, GRU) to derive the best one. In the processing, we use Google-cluster-data-2011-2 [
30] as a dataset. To this, we first analyze the dataset to confirm the prediction target, then train and evaluate the aforementioned models to obtain the best one and apply the model to our customized scaling scheme. After obtaining the best load prediction model, we encapsulate the model with our proposed custom pod autoscaling scheme and build a Docker image of it so that we can deploy it in a Kubernetes cluster as a component of its own. Thereby, we deploy our proposed custom pod autoscaler in our deployed Kubernetes cluster and evaluate its performance comparing with the native autoscaler HPA.
In essence, we delve into the following hypotheses in this article:
Proposing an autoscaling scheme that combines proactive and reactive method based on the latest research outcomes. In the paper, we demonstrate in detail how the scheme starts from load prediction model selection for autoscaler and the deployment of the proposed autoscaler and experimental analysis.
Exploring K8s and the third-party custom autoscaling framework, Custom Pod Autoscaler (CPA) framework [
31], integrating the CPA framework and our proposed proactive autoscaling scheme together to build our custom pod autoscaler, and deploying it to the K8s cluster for experimental analysis toward validating the effectiveness of it.
The rest of the paper is organized as follows.
Section 2 presents the architecture, features, and the components of Kubernetes.
Section 3 demonstrate the related work in the context of our study, such as commonly used container orchestration frameworks, load prediction methodologies and their respective principles related to our analysis, the latest custom autoscaler with obvious characteristics and excellent results, and analyzed their effectiveness and shortcomings.
Section 4 is about the empirical analysis of load prediction model selection for our proposed autoscaler.
Section 5 is the about the development, deployment, and evaluation of the proposed autoscaler. Conclusions and future study directions are discussed in the last section.
5. Proposed Autoscaler: Deployment and Experimental Analysis
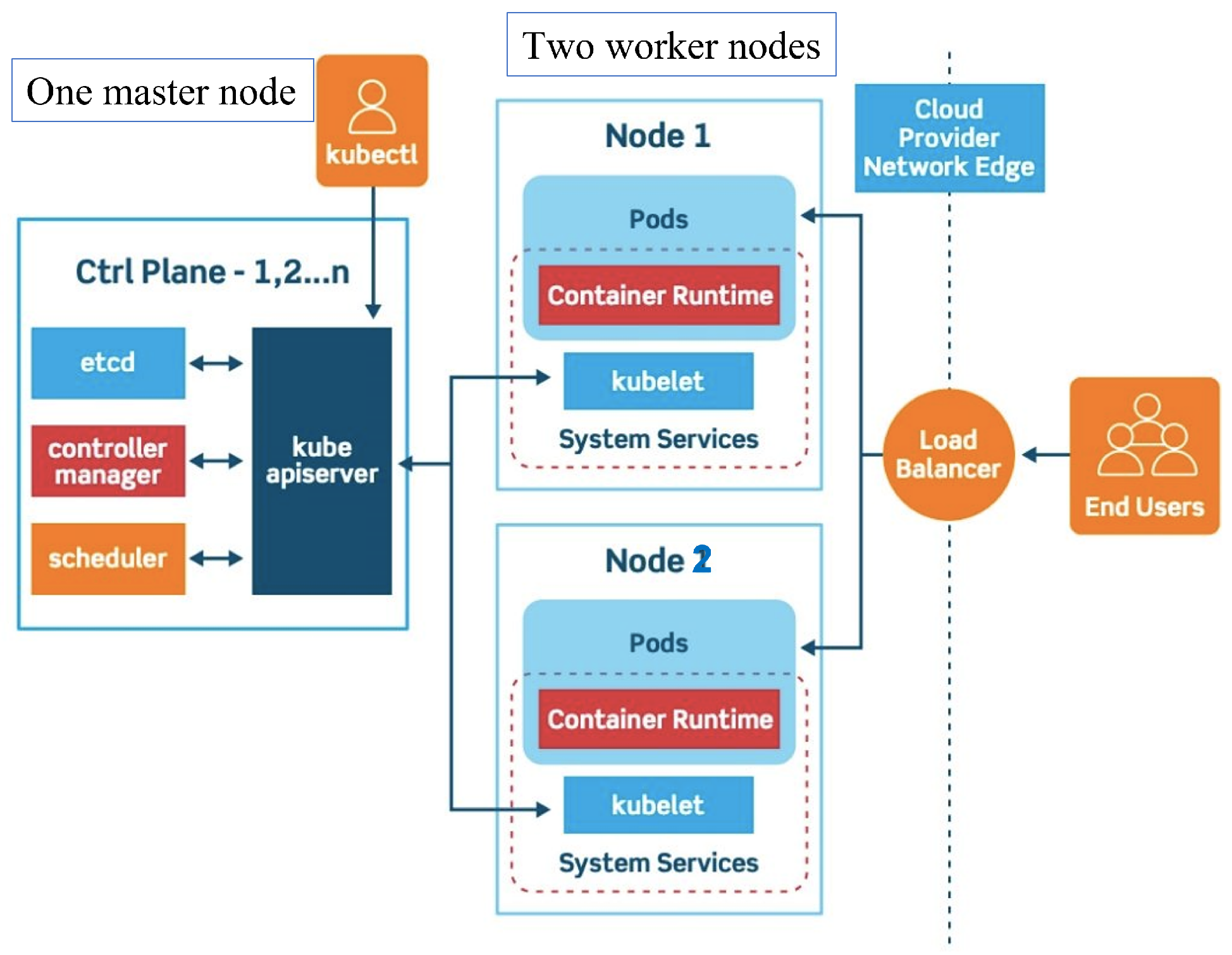
To be able to simulate the real K8s cluster for experiments under limited machines, we decide to build a cluster by creating virtual machines in local environment having one master node, and two worker nodes. Notably, we can add or remove nodes freely.
Here are the specific configurations:
5.1. Reactive (Default) Autoscaling in K8s (HPA in K8s)
After deploying the K8s cluster according to the above configuration, we created a simple yaml file and named it
nginx-hpa.yaml for testing. This
yaml file contains the configuration of two components, one is
Deployment that is responsible for managing a Pod with a Docker image, e.g., an nginx [
66] image. To ensure HPA works normally the CPU resource is also configured for the containers in the cluster that running the application, limit, and request are 500 m and 50 m, respectively. The other component is the
Service that exposes the service for external access. Next, we run the following command to apply the
yaml configuration, as shown in the Listing 8.
| Listing 8. Creation of a HPA having the Deployment for an nginx server. |
| kubectl apply -f nginx-hpa.yaml |
Then waiting for the Deployment and Service to be created and become “Running” status, we can successfully access the deployed nginx network service by accessing the IP address of any worker node and corresponding port number. Now, we apply HPA by entering the command, as shown in the Listing 9.
| Listing 9. Autoscaling of nginx HPA limiting the CPU usage to having the replica Pods between 1 and 10. |
| kubectl autoscale deployment nginx-hpa --cpu-percent=10 --min=1 --max=10 |
We set the upper limit of CPU usage to 10% to quickly trigger scaling and set the minimum and maximum number of Pods for each replica to 1 and 10, respectively, to represent the scale of scaling. Finally, we create a load generator image by executing the command, as shown in the Listing 10 to continuously generate requests for worker nodes to access the nginx page we just created to stress test the cluster.
| Listing 10. Load generator for accessing the ngnix server deployed by the nginx HPA. |
| kubectl run -i --tty load-generator --rm --image=busybox |
| --restart=Never -- /bin/sh -c ⸌⸌while true; |
| do wget -q -O- http://192.168.56.110:30003; |
| wget -q -O- http://192.168.56.111:30003; done" |
We run the command, as shown in the Listing 11 to observe the actual running state of HPA.
| Listing 11. Getting/Fetching data about the HPA. |
| kubectl get hpa |
Notably, we trace the running state of HPA, when the stress test starts at “8m” (at the 8th minute). We observe that HPA did not detect the surge of requests and did not scale the replicas respectfully until about 50s have passed. One more important point to note is that when the stress test ends at “9m” (at 9th minute), HPA takes more than 1 min to perform scale down. The log shown in
Figure 16 illustrates that for a sudden increase in requests, there is still a considerable delay in HPA response.
5.2. Proactive Autoscaling in K8s (CPA in K8s)
In this section, we demonstrate the CPA framework, our CPA, and the specific packaging and deployment process of our CPA.
5.2.1. Introduction to CPA Framework
Custom Pod Autoscaler (CPA) framework [
31] is a customizable K8s autoscaler developed by the DigitalOcean team (DigitalOcean
https://www.digitalocean.com/, accessed on 10 January 2023). It runs in a set of CPA frameworks written in the Go programming language. This framework abstracts the complex interaction process between CPA and K8s, allowing developers to use any language to write scaling logic, which has better scalability and easier management than K8s native HPA.
CPA frameworks provides developers with two stages for customizing the scaling logic: metrics gathering and evaluation. The job of the first stage metrics gathering is mainly used to collect metrics in K8s, and pass the user-defined metrics to be collected to the next stage in json format. It also works as an API that can be called to check the metrics usage of the target container or application at the current moment. The job of the evaluation stage is to pass the collected metrics as input to the scaling logic defined by the developer to decide whether to scale up or scale down to the target number of replicas.
The custom pod autoscaler operator (Custom Pod Autoscaler Operator
https://github.com/jthomperoo/custom-pod-autoscaler-operator, accessed on 10 January 2023) [
67] is a framework of CPA. It is an operator that takes the responsibility of creating a developer-defined CPA in the cluster as shown in
Figure 17. Especially, deploying CPA operator in the cluster is also a prerequisite for deploying CPA.
5.2.2. Workflow of Our Custom Pod Autoscaler
In this section, we show step by step how to write custom autoscaling logic, encapsulate the logic into a CPA image, and finally deploy proactive autoscaler to the cluster to achieve custom autoscaling.
The workflow of the two stages in CPA is shown in
Figure 18, such as
Metric Gatherer and
Evaluator. Herein, we define
metric.py as a
Metric Gatherer and define
evaluate.py as an
Evaluator that predicts load and computes replicas:
- 1.
Read target metric and information from the K8s Metrics Server.
- 2(a).
Convert the current number of replicas and CPU usage to JSON format and pass it to the Evaluator.
- 2(b).
Collect and update the historical time sequence locally into the database.
- 3.
Load the deep learning model and read historical time sequence to Evaluator for predicting and calculating the replicas.
- 4.
Assign the target number of replicas calculated by Evaluator.
Next, we introduce the internal implementation logic of the Metric Gatherer and Evaluator in detail through two flowcharts as shown in
Figure 19 and
Figure 20.
The main job of the Metric Gatherer (
Figure 19) is to collect information about the target application. In particular, it collects the Pod information running by the target application from the K8s metrics server, then extracts the current number of copies
and the CPU usage of each Pod. Next, the total CPU usage
is obtained by summing the CPU usage of each target Pod, and then the average CPU usage
is obtained through
. After that, it saves the current
to the database and updates the historical time series
, and finally converts
and
into JSON format and passes it to the Evaluator.
The Evaluator (
Figure 20) is primarily responsible for executing the scaling logic. First, it receives the
and
passed from the Metrics Gatherer and reads the corresponding values from the JSON file, and then reads the historical time series
and the pre-trained model
from the database. Initialize the target CPU usage threshold
and the target number of replicas
to 50 and 0, respectively. Then judge whether the historical sequence length
is greater than the input size
required by the model. If so,
is passed into
as input to predict the average CPU usage
for the next step (next period of time), and then execute the HPA algorithm to calculate the corresponding
. If the time sequence does not meet the model input length, it then simply executes the original HPA logic that calculates the corresponding
through
and
. Finally, it converts
into JSON format and sends it to Deployment to execute the autoscaling strategy to the specified number of replicas.
5.2.3. Development and Shipment of CPA Image
In this section, we show the file structure and configuration required to build a CPA image. Notably, we have uploaded the CPA image building workflow to Github (CPA Image
https://github.com/vikinglion/Autoscaler/tree/main/k8s-metrics-cpu, accessed on 20 January 2023), which also includes the configuration files for HPA and other files to carry out the experimental analysis as discussed in the later part of this paper. The file structure for the CPA image is, as shown in the Listing 12.
| Listing 12. File structure for the CPA image. |
| k8s-metrics-cpu |
| -- GRU_Model_24 |
| -- config.yaml |
| -- cpa.yaml |
| -- Dockerfile |
| -- metric.py |
| -- evaluate.py |
| -- requirements.txt |
The workflow of metric.py and evaluate.py has been explained in detail in the previous subsection. We set the CPA configuration through config.yaml (shown in the Listing 13) for the autoscaler, which defines which scripts to run, how to call them, and a timeout for the script. We define the shell command method to drive the CPA to call the custom script and judge whether the user-defined logic is successfully called by the return value of the script. Next, we set K8s metrics server configuration to allow CPA automatically gather designated metrics such as CPU and memory. In the experiment, we set the CPU as the collection metric.
| Listing 13. Configuration for the CPA image (config.yaml). |
| evaluate: |
| type: "shell" |
| timeout: 12500 |
| shell: |
| entrypoint: "python" |
| command: |
| - "/evaluate.py" |
| metric: |
| type: "shell" |
| timeout: 12500 |
| shell: |
| entrypoint: "python" |
| command: |
| - "/metric.py" |
| kubernetesMetricSpecs: |
| - type: Resource |
| resource: |
| name: cpu |
| target: |
| type: Utilization |
| requireKubernetesMetrics: true |
After the configuration file is set, start to package the
Dockerfile to build the CPA image. We pull in
python:3.8-slim version and put the environment required by the custom script into the
requirement.txt file. Finally, add the CPA configuration file
config.yaml, custom scaling scripts
metric.py and
evaluate.py, trained model
GRU_Model_24 to the environment. After that, we run the command, as shown in the Listing 14 to build a Docker image for the CPA image (Notably, the image is created in to the local repository). Due to network problems, the image cannot be directly uploaded to Docker Hub (Docker Hub
https://hub.docker.com/, accessed on 10 January 2023), we push it to the public repository of Alibaba Cloud (Alibaba Cloud
https://www.aliyun.com/, accessed on 10 January 2023).
| Listing 14. Building a Docker image for the our custom CPA and uploading it to public repository. |
| docker build -t vikinglion/k8s-metrics-cpu:latest . |
| docker push registry.cn-hangzhou.aliyuncs.com/ vikinglion/k8s-metrics-cpu:latest |
5.2.4. Deployment of CPA Image and Testing on K8s
As mentioned in the previous subsection, the prerequisite for the operation of our CPA is the successful installation of the CPA operator, so the first step is to determine the version corresponding to K8s and the operator, and then enter the command to install, as shown in the Listing 15.
| Listing 15. Installation of Custom Pod Autoscaler Operator. |
| VERSION=v1.2.1 |
| HELM_CHART=custom-pod-autoscaler-operator |
| helm install ${HELM_CHART} https://github.com/ jthomperoo/custom-pod-autoscaler-operator/ |
| releases/download/${VERSION}/ custom-pod-autoscaler-operator-${VERSION}.tgz |
Next, we focus on configuring cpa.yaml to deploy CPA, as shown in the Listing 16. First, we pull the created CPA image from the public repository of Alibaba Cloud, and then set the target application and metric in the cluster as same as the experiment in HPA. In addition, the CPA framework has also encapsulated the stabilization window mechanism; here we set it to 60 s.
| Listing 16. Configuration file for deploying the CPA image while monitoring an application called php-cpa (cpa.yaml). |
| apiVersion: custompodautoscaler.com/v1 |
| kind: CustomPodAutoscaler |
| metadata: |
| name: k8s-metrics-cpu |
| spec: |
| template: |
| spec: |
| containers: |
| - name: k8s-metrics-cpu |
| image: registry.cn-hangzhou.aliyuncs.com/vikinglion/k8s-metrics-cpu:latest |
| imagePullPolicy: IfNotPresent |
| scaleTargetRef: |
| apiVersion: apps/v1 |
| kind: Deployment |
| name: php-cpa |
| roleRequiresMetricsServer: true |
| config: |
| - name: interval |
| value: "10000" |
| - name: downscaleStabilization |
| value: "60" |
To generate a more stable load from the tested application, we chose the test image php-apache.yaml on the K8s official website, the application of this image defines an index.php page, and executes a for loop statement to generate CPU usage to simulate the load in the cluster. In this experiment, we copied and renamed php-apache.yaml to php-hpa.yaml and php-cpa.yaml, and deployed two identical content (two Deployments) with different names, respectively, which is used to compare the scaling effect of CPA and native HPA.
It is convenient to quickly deploy HPA through the command line; however, it is inconvenient to modify the configuration information, so we also configured hpa.yaml and the target CPU usage threshold is set to 50%, the maximum and minimum number of replicas are 20 and 1, respectively, and the stabilization window time is to 60s as in CPA. The next step is to deploy the aforementioned YAML files in the cluster. Consequently, we go in the following way, as shown in the Listing 17.
| Listing 17. Deployment of HPA and CPA, and Performance analysis. |
| kubectl apply -f php-cpa.yaml |
| kubectl apply -f php-hpa.yaml |
| kubectl apply -f cpa.yaml |
| kubectl apply -f hpa.yaml |
As in the previous HPA experiments, we trigger the target application to execute business logic by configuring load-generator.yaml. The working principle is to access php-cpa and php-hpa applications separately every 0.01 s through ClusterIP.
After deploying the load-generator, we captured 20 min of data to show the results. The process of scaling the number of replicas of
php-cpa and
php-hpa was displayed from the control interface of Prometheus (
Figure 21). The blue and red lines represent the number of replicas of
php-cpa and
php-hpa, respectively. It can be observed from the figure that the load trend generated by the test application is relatively stable, so the autoscaling process of HPA and CPA is roughly the same with a small amount of error, which also proves that our proposed autoscaling scheme is feasible after deployed on the real K8s cluster.
6. Conclusions and Future Work
Deploying applications through cloud computing services has become the choice of most users. One of the important functions is autoscaling, which is still implemented through reactive methods to trigger scaling logic and cannot meet the needs of all users respectfully. Therefore, it is necessary to analyze specific applications and customize the corresponding scaling strategy. To this, we begin with proposing a proactive scaling scheme that is based on the GRU deep learning model to address the shortcomings of the default autoscaler, HPA. In particular, we develop a load prediction model based on GRU for the autoscaler, then based on the predicted load, our custom autoscaler scales the replicas of a deployed application to meet the user demands. Respectively, we implement our custom autoscaling scheme, deploy it to the real K8s cluster, and empirically evaluate the effectiveness of it.
The paramount advantage of our scaling scheme is that it can train the model for each metric respectfully and replace the scaling logic at any time, which has better scalability. However, there are still aspects that need to be improved in our scheme. We develop our load prediction model in terms of CPU utilization in a node. In load prediction, it would be good if we could develop the model for individual tasks; however, this would increase the training complexity. In other aspect, while testing our custom pod autoscaler, we use a load generator to trigger and drive the test application to generate CPU load in K8s. This form of test method cannot generate custom target values duly, so this is our primary problem that needs to be solved in the future. In addition, all of the prediction models are based on the supervised learning method, which relies on models that are fully trained on target metrics, so we will consider other viable strategies such as reinforcement learning or other state-of-the-art methods as alternatives.

 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}