
Predictive Prompts with Joint Training of Large Language Models for Explainable Recommendation
 and
and
Abstract
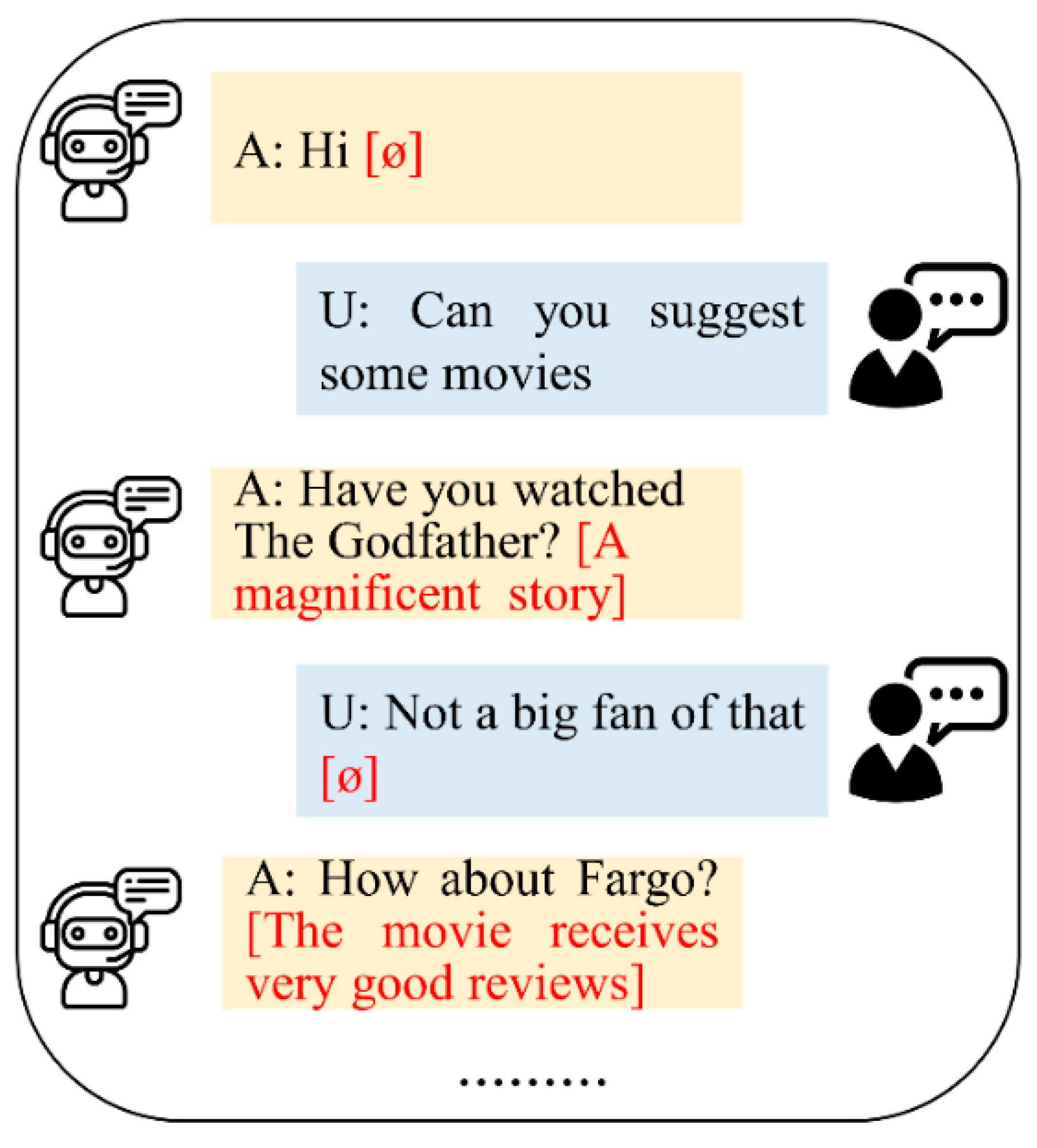
:1. Introduction
- We propose a joint training scheme to predict the recommendation rating and produce explanations of the recommendation based on the prompt learning. The predictive prompts are taken from the predictive representations learned in the rating prediction task, and fed into PLMs to generate output text.
- Experiments are conducted on the TripAdvisor dataset to verify the effectiveness of our approach on both rating prediction task and explanation generation task. The results show that our method is not only capable of generating suitable explanations but also achieves promising performance comparable with other state-of-the-art algorithms in terms of Root Mean Square Error (RMSE) and Mean Absolute Error (MAE) for the rating prediction task.
2. Related Work
2.1. Recommendation Systems
2.2. Pre-Trained Language Models
2.3. Prompt Learning
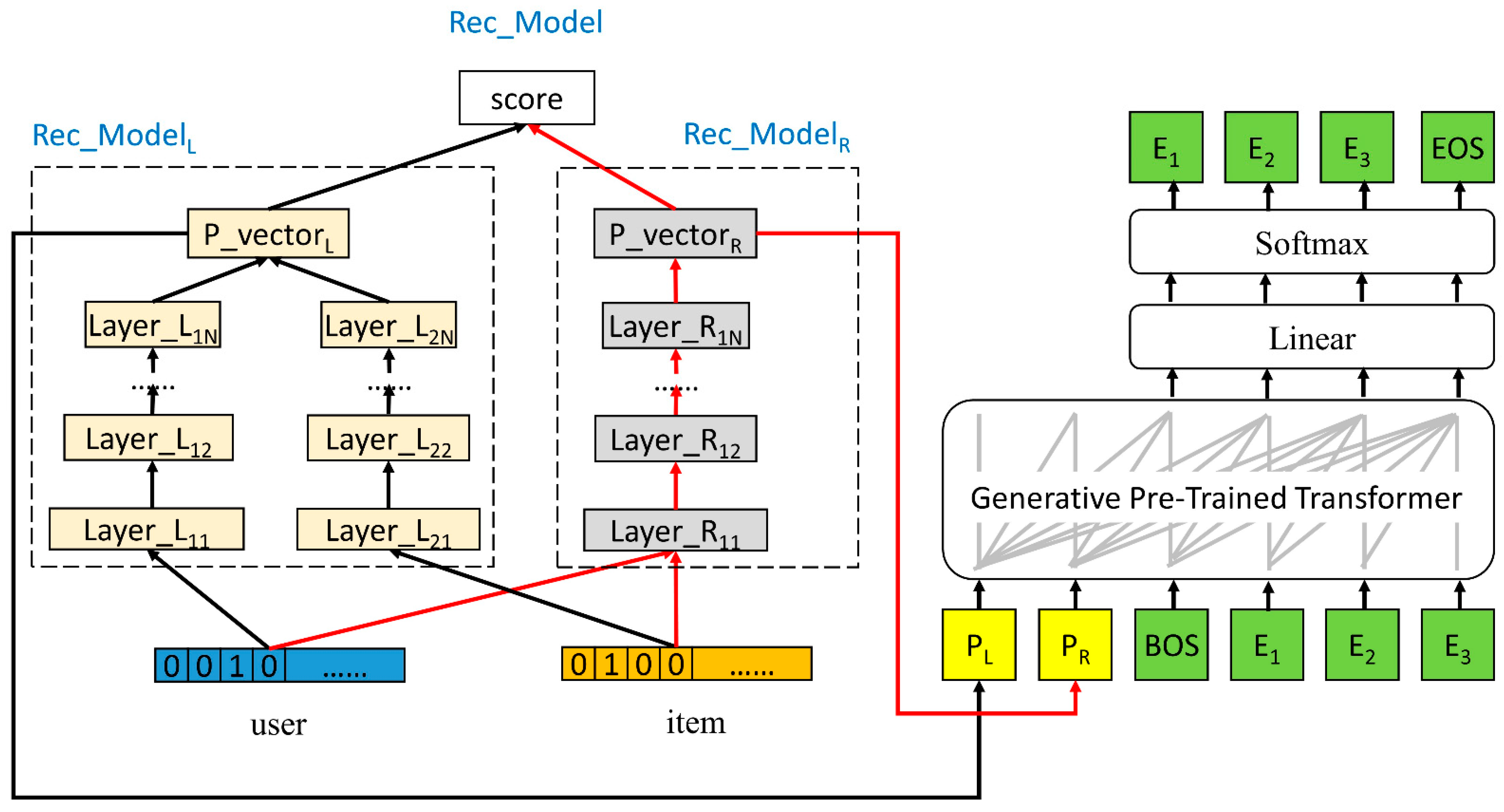
3. Proposed Method
3.1. Prompt-Based Explainable Recommendation Architecture
3.2. Learning Process
| Algorithm 1: Prompt-Based Explainable Recommendation Model. |
| Input: The training dataset D {User (U), Item (I), Explanation (E)} Output: for all the trainable weights in the model |
|
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Criterion
4.3. Experimental Performances
- Att2Seq [35]: This method is an attention-enhanced attribute-to-sequence network and is initially proposed to create product reviews. The model uses the user ID, product ID, and rating as attributes.
- NRT [36]: Unlike reviews which are lengthy and time consuming, tips are very succinct insights to capture user experience with only a few words in E-commerce sites. This paper uses multi-task learning framework to predict product ratings and generate tips where the rating prediction is based on a multi-layer perceptron network and tip generation is a sequence decoder model. The input of this model consists of user id and item id.
- PEPLER-MF [32]: PEPLER is a personalized prompt-based learning for explainable recommendation using pre-trained language models based on user and item IDs. PEPLER-MF uses Matrix Factorization (MF) for the recommendation rating score prediction by the user and item embeddings. The explanations are produced with the aid of pre-trained language models.
- PEPLER-MLP [32]: This method is another variant of PEPLER. The major difference is that this model trains a Multi-Layer Perceptron (MLP) to estimate the rating scores.
4.4. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kumar, P.; Thakur, R.S. Recommendation system techniques and related issues: A survey. Int. J. Inf. Technol. 2018, 10, 495–501. [Google Scholar] [CrossRef]
- Barkan, O.; Koenigstein, N.; Yogev, E.; Katz, O. CB2CF: A neural multiview content-to-collaborative filtering model for completely cold item recommendations. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen Denmark, 16–20 September 2019; pp. 228–236. [Google Scholar]
- Liu, Z.; Wang, H.; Niu, Z.; Wu, H.; Che, W.; Liu, T. Towards Conversational Recommendation over Multi-Type Dialogs. In Proceedings of the 58th Annual Meeting of the Association-for-Computational-Linguistics (ACL), Online, 5–10 July 2020; pp. 1036–1049. [Google Scholar]
- Van Dis, E.A.; Bollen, J.; Zuidema, W.; van Rooij, R.; Bockting, C.L. ChatGPT: Five priorities for research. Nature 2023, 614, 224–226. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Wang, X.; Wang, Y.; Xie, X. Explainable recommendation through attentive multi-view learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3622–3629. [Google Scholar]
- Chen, Z.; Wang, X.; Xie, X.; Parsana, M.; Soni, A.; Ao, X.; Chen, E. Towards explainable conversational recommendation. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 2994–3000. [Google Scholar]
- Alshammari, M.; Nasraoui, O.; Sanders, S. Mining semantic knowledge graphs to add explainability to black box recommender systems. IEEE Access 2019, 7, 110563–110579. [Google Scholar] [CrossRef]
- Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Zettlemoyer, L.; et al. Opt: Open pre-trained transformer language models. arXiv 2022, arXiv:2205.01068. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; Volume 1, pp. 4582–4597. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Ko, H.; Lee, S.; Park, Y.; Choi, A. A survey of recommendation systems: Recommendation models, techniques, and application fields. Electronics 2022, 11, 141. [Google Scholar] [CrossRef]
- Chen, K.; Liang, B.; Ma, X.; Gu, M. Learning audio embeddings with user listening data for content-based music recommendation. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, Canada, 6–11 June 2021; pp. 3015–3019. [Google Scholar]
- Su, Y.; Zhang, R.; MErfani, S.; Gan, J. Neural graph matching based collaborative filtering. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Online, 11–15 July 2021; pp. 849–858. [Google Scholar]
- Liu, N.; Zhao, J. Recommendation system based on deep sentiment analysis and matrix factorization. IEEE Access 2023, 11, 16994–17001. [Google Scholar] [CrossRef]
- Radlinski, F.; Boutilier, C.; Ramachandran, D.; Vendrov, I. Subjective attributes in conversational recommendation systems: Challenges and opportunities. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 12287–12293. [Google Scholar]
- Li, S.; Lei, W.; Wu, Q.; He, X.; Jiang, P.; Chua, T.S. Seamlessly unifying attributes and items: Conversational recommendation for cold-start users. ACM Trans. Inf. Syst. 2021, 39, 1–29. [Google Scholar] [CrossRef]
- Lei, W.; He, X.; Miao, Y.; Wu, Q.; Hong, R.; Kan, M.Y.; Chua, T.S. Estimation-action-reflection: Towards deep interaction between conversational and recommender systems. In Proceedings of the 13th International Conference on Web Search and Data Mining, Online, 10–13 July 2020; pp. 304–312. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Wang, H.; Li, J.; Wu, H.; Hovy, E.; Sun, Y. Pre-Trained Language Models and Their Applications. Engineering 2022, 25, 51–65. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Zhiyuli, A.; Chen, Y.; Zhang, X.; Liang, X. BookGPT: A General Framework for Book Recommendation Empowered by Large Language Model. arXiv 2023, arXiv:2305.15673. [Google Scholar]
- Ji, J.; Li, Z.; Xu, S.; Hua, W.; Ge, Y.; Tan, J.; Zhang, Y. Genrec: Large language model for generative recommendation. arXiv 2023, arXiv:2307. [Google Scholar]
- Cai, X.; Xu, H.; Xu, S.; Zhang, Y. BadPrompt: Backdoor Attacks on Continuous Prompts. Adv. Neural Inf. Process. Syst. 2022, 35, 37068–37080. [Google Scholar]
- Jiang, Z.; Xu, F.F.; Araki, J.; Neubig, G. How can we know what language models know? Trans. Assoc. Comput. Linguist. 2020, 8, 423–438. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Malthouse, E.C. PBNR: Prompt-based News Recommender System. arXiv 2023, arXiv:2304.07862. [Google Scholar]
- Zhang, Z.; Wang, B. Prompt learning for news recommendation. arXiv 2023, arXiv:2304.05263. [Google Scholar]
- Deng, Z.H.; Huang, L.; Wang, C.D.; Lai, J.H.; Philip, S.Y. Deepcf: A unified framework of representation learning and matching function learning in recommender system. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 61–68. [Google Scholar]
- He, T.; Tan, X.; Xia, Y.; He, D.; Qin, T.; Chen, Z.; Liu, T.Y. Layer-wise coordination between encoder and decoder for neural machine translation. Adv. Neural Inf. Process. Syst. 2018, 31. Available online: https://api.semanticscholar.org/CorpusID:54088698 (accessed on 9 October 2023).
- Geng, S.; Fu, Z.; Ge, Y.; Li, L.; De Melo, G.; Zhang, Y. Improving personalized explanation generation through visualization. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 1, pp. 244–255. [Google Scholar]
- Li, L.; Zhang, Y.; Chen, L. Personalized prompt learning for explainable recommendation. ACM Trans. Inf. Syst. 2023, 41, 1–26. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Dong, L.; Huang, S.; Wei, F.; Lapata, M.; Zhou, M.; Xu, K. Learning to generate product reviews from attributes. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 1, pp. 623–632. [Google Scholar]
- Li, P.; Wang, Z.; Ren, Z.; Bing, L.; Lam, W. Neural rating regression with abstractive tips generation for recommendation. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 345–354. [Google Scholar]
- Li, L.; Zhang, Y.; Chen, L. Personalized Transformer for Explainable Recommendation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; Volume 1. [Google Scholar]
- Gao, C.; Zheng, Y.; Li, N.; Li, Y.; Qin, Y.; Piao, J.; Quan, Y.; Chang, J.; Jin, D.; He, X.; et al. A survey of graph neural networks for recommender systems: Challenges, methods, and directions. ACM Trans. Recomm. Syst. 2023, 1, 1–51. [Google Scholar] [CrossRef]
- Hu, L.; Liu, Z.; Zhao, Z.; Hou, L.; Nie, L.; Li, J. A Survey of Knowledge Enhanced Pre-Trained Language Models. IEEE Trans. Knowl. Data Eng. 2023, 1–19. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| batch size | 128 |
| epoch | 10 |
| size | 768 |
| size | 768 |
| layers N in Rec_Model | 2 |
| learning rate | 0.00075 |
| BLEU-1 | BLEU-4 | ROUGE1-F | ROUGE2-F | RMSE | MAE | |
|---|---|---|---|---|---|---|
| Att2Seq | 15.20% | 0.96% | 16.38% | 2.19% | - | - |
| NRT | 13.76% | 0.80% | 15.58% | 1.68% | 0.790 | 0.610 |
| PEPLER-MF | 15.94% | 1.14% | 16.38% | 2.14% | 1.574 | 1.341 |
| PEPLER-MLP | 15.91% | 1.03% | 16.39% | 2.13% | 0.799 | 0.612 |
| Our Model | 16.45% | 1.10% | 16.71% | 2.24% | 0.795 | 0.607 |
| Ground truth_1: location was good and was close to many restaurants |
| Generation_1: the hotel is located in a great location |
| Ground truth_2: pool area is good though |
| Generation_2 the pool is great and the staff are very helpful |
| Ground truth_3: the bed is very comfortable and the bath room is great |
| Generation_3 the bed was very comfortable and the bathroom was clean and modern |
| Ground truth_4: i enjoyed the front desk staff |
| Generation_4 the front desk staff was very helpful |
| Ground truth_5: gym also very small and with an odd smell |
| Generation_5 the room was very small and the bathroom was very small |
| BLEU-1 | BLEU-4 | ROUGE1-F | ROUGE2-F | RMSE | MAE | |
|---|---|---|---|---|---|---|
| Our Model | 16.45% | 1.10% | 16.71% | 2.24% | 0.795 | 0.607 |
| - | 15.89% | 1.03% | 16.43% | 2.14% | 0.796 | 0.611 |
| - | 15.81% | 1.03% | 16.41% | 2.17% | 0.798 | 0.612 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-S.; Tsai, C.-N.; Su, S.-T.; Jwo, J.-S.; Lee, C.-H.; Wang, X. Predictive Prompts with Joint Training of Large Language Models for Explainable Recommendation. Mathematics 2023, 11, 4230. https://0-doi-org.brum.beds.ac.uk/10.3390/math11204230
Lin C-S, Tsai C-N, Su S-T, Jwo J-S, Lee C-H, Wang X. Predictive Prompts with Joint Training of Large Language Models for Explainable Recommendation. Mathematics. 2023; 11(20):4230. https://0-doi-org.brum.beds.ac.uk/10.3390/math11204230
Chicago/Turabian StyleLin, Ching-Sheng, Chung-Nan Tsai, Shao-Tang Su, Jung-Sing Jwo, Cheng-Hsiung Lee, and Xin Wang. 2023. "Predictive Prompts with Joint Training of Large Language Models for Explainable Recommendation" Mathematics 11, no. 20: 4230. https://0-doi-org.brum.beds.ac.uk/10.3390/math11204230