1. Introduction
In recent years, there has been a lively interest in target location using multistatic sonars [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13]. In a multistatic sonar system, the sum of each pair of transmitter–target range and target–receiver range defines an ellipse. Then the target is at the intersection of all these ellipses [
7]. The elliptical location encountered in the multistatic sonar systems has also been considered in the MIMO radar [
14,
15,
16,
17,
18,
19,
20], multistatic radar [
21,
22,
23,
24,
25] and indoor positioning systems [
26,
27].
A considerable amount of literature has been published on the problem of estimating the coordinates of the intersection of the ellipses, which can be statistically modelled as a nonlinear estimation problem. To resolve the essential nonlinearity in the problem, linearization is a natural idea. In particular, the measurement equations were linearized by Taylor expansion, resulting in an iterative algorithm [
20]. Alternative to the Taylor expansion, introducing nuisance parameters is another approach to linearization. For example, the classic spherical-interpolation [
28] and spherical-intersection [
29] methods were ported to the elliptical location problems [
25]. However, the estimation accuracy is not optimum in [
25]. Slightly more complex than the linear models, a quadratically constrained least squares model was constructed, which is generally difficult to solve effectively [
27,
30]. More recently, as another major methodology for parameter estimation, a Bayes estimator was presented for elliptical location, involving formidable numerical integration [
4]. Intuitively, integrating other kinds of observations helps improve the positioning accuracy. For instance, the Doppler shift measurements were incorporated to improve the position estimate and identify the velocity additionally [
5].
In addition to the difficulties raised by the high nonlinearity in the statistical models, another obstacle in the multistatic sonar location is that the complex ocean environments introduce uncertainties in the positions of the transmitters and receivers. Preliminary work considering sensor location errors in elliptical location was reported in the literature [
6,
10,
13]. Recent advances have seen an efficient non-iterative estimator for the multistatic sonar location [
5,
6] inspired by the renowned work of [
31].
Perturbation analysis of least squares problems is a major topic in numerical linear algebra. Related work has focused on establishing various error bounds [
32,
33,
34]. We combine the basic techniques of perturbation analysis with multivariate statistics [
35] to quantitatively evaluate the estimators for a nonlinear estimation problem.
On the basis of the above work, our technical contributions are summarized here.
We establish a statistical model of determining both the position and velocity of a moving target in a multistatic sonar system using differential delays and Doppler shifts. The uncertainties in the sensor positions are carefully taken into account in our model. The performance limit is developed for this problem.
To tackle the proposed nonlinear hybrid parameter estimation problem, we design an efficient non-iterative solution using parameter transformation, model linearization and two-stage processing.
We further analyze the bias vector and covariance matrix of our estimator theoretically using the second/first-order perturbation analysis and multivariate statistics.
We prove that the proposed estimator has approximate statistical efficiency and linear complexity.
The rest of this paper is organized as follows.
Section 2 lists the notational conventions that will be used throughout the paper.
Section 3 provides the location scenario and formulates the problem as a nonlinear estimation problem. In
Section 4, we evaluate the performance limit for the proposed problem.
Section 5 is devoted to developing our estimator. Then,
Section 6 analyzes the bias vector and covariance matrix of our estimator up to the second/first-order random errors.
Section 7 contains comprehensive Monte Carlo simulation results, and finally
Section 8 draws the conclusion.
2. Notational Conventions
We will use bold lowercase letters to denote the
column vectors and bold uppercase ones to denote the matrices. Specifically,
is a
zeros matrix,
is a
ones matrix, and
is an identity matrix of appropriate size. The operators ⊗ and ∘ represent the Kronecker product and Hadamard product respectively. The expression
means that
is a positive semidefinite matrix.
is the square diagonal matrix with the elements of vector
on the main diagonal.
is the block diagonal matrix created by aligning the matrices
along the diagonal of
. When we want to access selected elements of a vector/matrix, we imitate the syntax of MATLAB programming language. For simplicity of presentation, we use numerous symbols and notations. They are summarized in
Table 1 for quick reference. For the sake of readability, the text also includes relevant explanations about these symbols and notations.
3. Problem Formulation and Statistical Model
We now turn to the mathematical formulation of the problem. In the multistatic sonar location scenario here, the transmitters and receivers are stationary and the target is moving. Let
M be the number of transmitters and
N be the number of receivers. We consider a two-dimensional location scenario. The unknown position vector and velocity vector of the target are denoted by
and
. For simplicity, the complete unknown parameter vector will be denoted by
To characterize the sensor location errors, the position vectors of the
i-th transmitter and
j-th receiver are modeled as random vectors
and
respectively, where
and
. We write compactly
where
and
. Generally, it can be assumed that
where the nominal positions of the sensors
and the covariance matrix
are known [
6]. Then the sensor position errors vector is
.
Physically, each transmitter radiates a sonar signal and all receivers observe the signals both from direct propagation and from indirect reflection of the target. Thus, the observation model of differential delay time between
and
is
where
c is the signal propagation speed and
is the observation noise of
[
6]. Furthermore, as the target is moving, we can also obtain the observation model of range rate (i.e., the Doppler shift measurements divided by the carrier frequency) between
and
, that is,
where
is the observation noise of
. For the notations
and
, see
Table 1.
For the transmitter at position
, all the related observations can be collected in an observation vector
where
, and
for
. Then, the observations related to all the transmitters can be denoted by
Furthermore, it is assumed that the conditional distribution (given
) of the observed vector
is of the form
where
is the ideal error-free observation vector and
is the covariance matrix of
. The corresponding observation error vector can be denoted by
.
As part of the observation model, the following small error assumptions are claimed.
,
,
,
,
,
.
The physical motivation for these assumptions is that the position uncertainty of a given transmitter is small relative to its distance to the target and its distances to all the receivers, the position uncertainty of a given receiver is small relative to its distance to the target and its distances to all the transmitters, and the relative measurement errors are small. Besides, and are assumed to be statistically independent for ease of illustration.
Given the statistical model in Equation (
8), the problem is to estimate the target position vector
and velocity vector
, i.e.,
, in real time and at a reasonable computational cost. Another significant work is the theoretical analysis of statistical performance of the designed estimator.
We conclude this section with some comments. Generally, the small error assumptions can be satisfied by increasing the observation period in obtaining the differential delay time and range rate measurements in a nonsingular location geometry. In addition, as we will see in
Section 5, our estimator requires accurate knowledge of the positive definite covariance matrices
and
. They can usually be obtained during the calibration stage of a multistatic sonar system. Specifically, some scattering models from the environment may also help determine
.
4. Hybrid Cramér–Rao Bound
In order to set a benchmark before designing an estimator, we now evaluate the Hybrid Cramér–Rao Bound (HCRB) [
36,
37,
38,
39] for the hybrid parameter estimation problem proposed in
Section 3. The HCRB provides a lower bound on the error covariance matrix of the estimator of a hybrid unknown parameter vector.
In our statistical model, the wanted parameter vector
and the nuisance parameter vector (i.e., the actual sensor positions)
are both unknown. What makes them different is that
is deterministic, and
is a random parameter vector. Such models arise in many applications where we want to investigate model uncertainty or environmental mismatch. Here, we consider
and
together as a hybrid parameter vector
Before moving on to the estimator design, we outline the procedures for deriving the HCRB. In such a hybrid parameter case, the HCRB is calculated using the joint probability density of the observed measurement vector
and the sensor position vector
. The hybrid information matrix
can be expressed as the sum
where
represents the contribution of observations
and
represents the contribution of the prior knowledge on
. Note that the unknown parameter vector
is in the mean vector
of the multivariate normal distribution in Equation (
8) and
is a multivariate normal random vector itself as in Equation (
3).
Section 3 reveals that
depends on
,
and
c. In our model, the random parameter vector
does not depend on the deterministic parameter vector
. Thus,
and
is fairly easy to get [
40]. Consequently,
When the levels of sensor positions’ uncertainties are small, according to the approximation principle suggested by [
41], the expected value matrix in Equation (
11) can be approximated by replacing random vector
with its expected value vector
. Then, from the blockwise inversion of
and the matrix inversion lemma, we have the HCRB for the estimation of
as follows:
For numerical computation using Equation (
13),
and
are required. More information is available in
Appendix A.
5. Estimator Design
In this section, we use Taylor expansion, introduce auxiliary variables and apply multi-stage processing to deal with the nonlinear estimation problem proposed in
Section 3. In particular, our algorithm can be divided into two stages, each involving an unconstrained linear weighted least squares (WLS) computation which is computationally attractive. During the algorithm design and performance analysis of our estimator, it is necessary to use many matrix symbols to simplify the presentation. These matrices are shown in
Table 2 for easy reference. When justifying the introduction of these matrices, we find that these matrices naturally arise in a general weighted least squares problem. To prevent ourselves from obscuring the design of the estimator, the reader is referred to the
Appendix B.
Based on the Conditions 1 through 4 in
Section 3, it follows from the first-order Taylor’s formula that
If we plug Equation (
14) through Equation (16) into Equation (
4), we obtain
where
Furthermore, inserting Equation (17) and Equation (18) into Equation (
5) gives
where
5.1. First Stage
Without loss of generality, let
. Move
from the right side to the left side in Equation (
19), and square both sides. Then, we see that
Applying similar procedures to Equation (
21) gives
If we define an unknown parameter vector as
where
then a linear system of equations can be obtained from Equation (
23) and Equation (
24) as
We leave the details of
,
,
,
and
presented in
Appendix C. Note that
and
are first-order and second-order approximation error respectively.
By ignoring the second-order error term
, the WLS solution to Equation (
30) is
and has covariance matrix
where
,
and
is the zero-order approximation of
. The weighting matrix
is the inverse of the covariance matrix of the approximation error
, that is,
The computation of
is straightforward. Because of the assumed statistical independence between
and
in Equation (
A15),
where
is shown in Equation (
A16).
We get Equation (
32) by the first-order perturbation analysis.
5.2. Second Stage
With
and its covariance matrix
, the aim of the second stage is to estimate the estimation error vector introduced in the first stage. In order to use symbols similar to the first stage, we denote this estimation error vector as
, i.e.,
By substituting
and
into
, we obtain
Furthermore, plugging
,
,
and
into
gives
In matrix notation, from Equation (
37) and Equation (
38), we have
where
i.e., the estimation error in the first stage
is considered as the first-order approximation error in the second stage. This is a key point of our estimator. The details of
,
,
and the second-order approximation error
can be found in
Appendix D.
By ignoring the second-order error term
and following the first stage’s approach, the WLS solution to Equation (
39) is
and has error covariance matrix
where
,
and
is the zero-order approximation of
. The weighting matrix
is the inverse of the covariance matrix of the approximation error
, that is,
Finally, our estimator can be constructed from
in Equation (
31) and
in Equation (
41) as
Last but not least, some obstacles arise in the practical computation of our estimator. In the first stage,
and
, as shown in Equation (
A13) and Equation (
A16), involve
and
which are unavailable for the algorithm. To resolve this problem, we first assign an identity matrix to
and an all-zero matrix to
to get coarse estimates of
and
from Equation (
31), and then substitute the coarse estimates into Equation (
A13) and Equation (
A16) to update
and
. Confronted with similar problems in the second stage in Equation (
A20), we substitute
and
for computing
, resulting
and
. These approximations will be considered properly in the statistical performance analysis in
Section 6.
5.3. Summary
As a guide to implementation, the flowchart of the proposed estimator is shown in
Figure 1 and the algorithm of the first stage of our estimator is summarized in Algorithm 1.
| Algorithm 1 First stage of the estimator. |
- 1:
procedureEstimator-First-Stage() - 2:
Compute from by Equation ( 34) - 3:
Compute from by Equation ( 33) - 4:
return from by Equation ( 31) - 5:
return from by Equation ( 32) - 6:
end procedure
|
7. Results and Discussion
In the previous section, we have theoretically analyzed the performance of our estimator. Now we ascertain the performance of our estimator via computer simulations. Our simulations are divided into four subsections.
Section 7.1 compares the error covariance matrix of our estimator with HCRB and the ones of two typical estimators, i.e., the spherical-interpolation initialized Taylor series method (SI-TS) [
28,
45] and TS-WLS [
5]. Then, surface plots of the biases are shown in
Section 7.2. In
Section 7.3, we empirically explore the time complexity of our estimator for locating multiple disjoint targets. Finally, we use 80 randomly generated large-scale localization scenarios to further test the proposed estimator in
Section 7.4.
The first three subsections base on the simulation settings of [
6]. Specifically, the simulations use
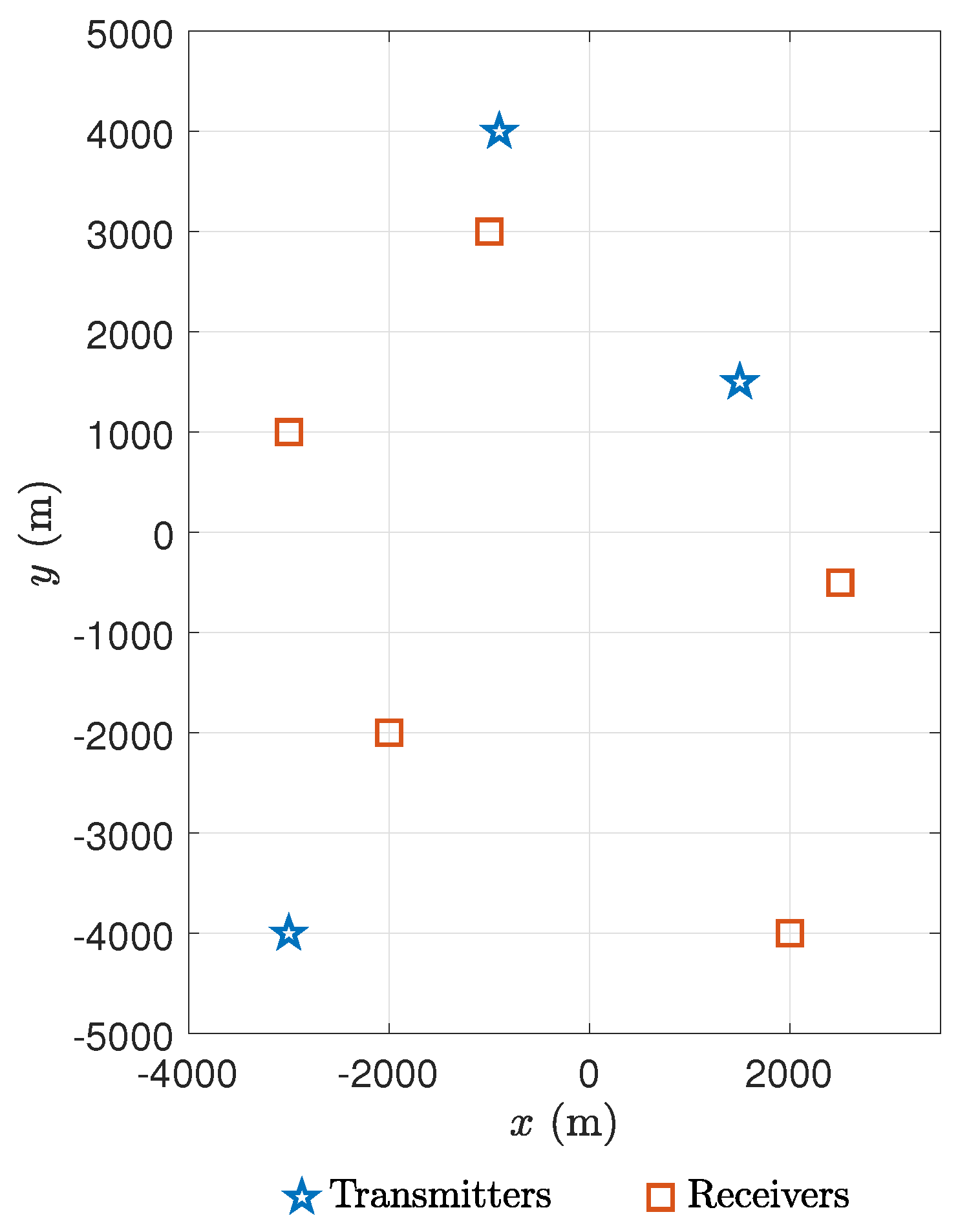
transmitters and
receivers to determine the unknown position
and velocity
of a moving target. As in [
6], the nominal positions of the sensors are known and given as follows.
m,
m,
m,
m,
m,
m,
m, and
m. Graphically, the nominal location geometry is shown in
Figure 2.
The additional common settings for
Section 7.1 and
Section 7.2 are as follows. The target is at
m with velocity
m/s and the signal propagation speed is
m/s. The observation error covariance matrix related to the transmitter at
is
for
, where
is a given positive constant,
, and
[
31]. The sensors’ position error covariance matrix is
, where
is a given positive constant.
We list the settings of the Monte Carlo simulations in
Table 4 to illustrate our experiments more clearly. Using Equation (
8) based on
Table 4, we generate data for simulations.
7.1. Performance Comparison
We now turn to the performance comparison of several estimators. For a specific estimator
of the unknown parameter vector
, its performance can be measured by the root-mean-square error (RMSE), which is defined as follows.
where
L is the number of Monte Carlo simulations and
is the
ℓ-th random realization of
.
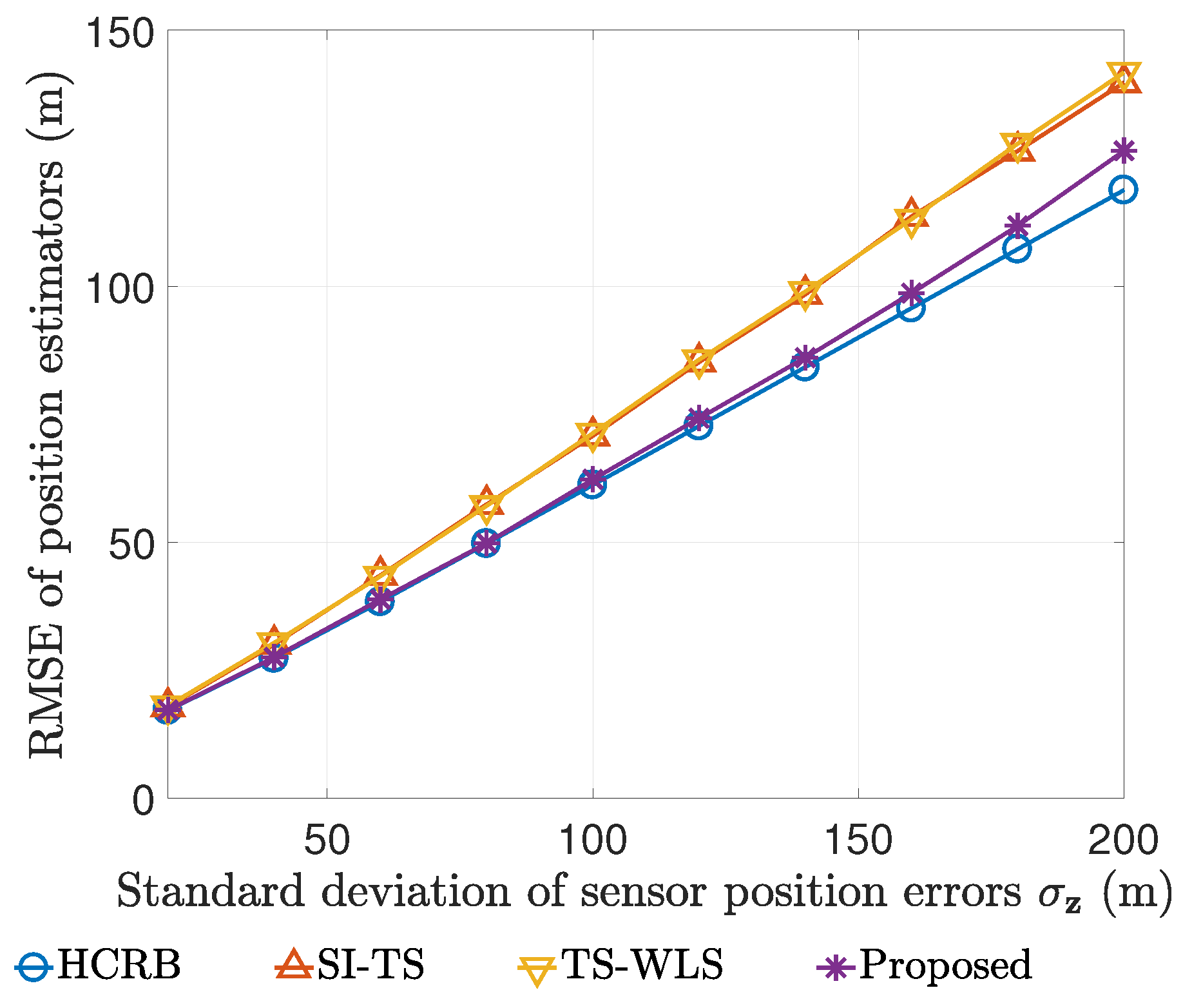
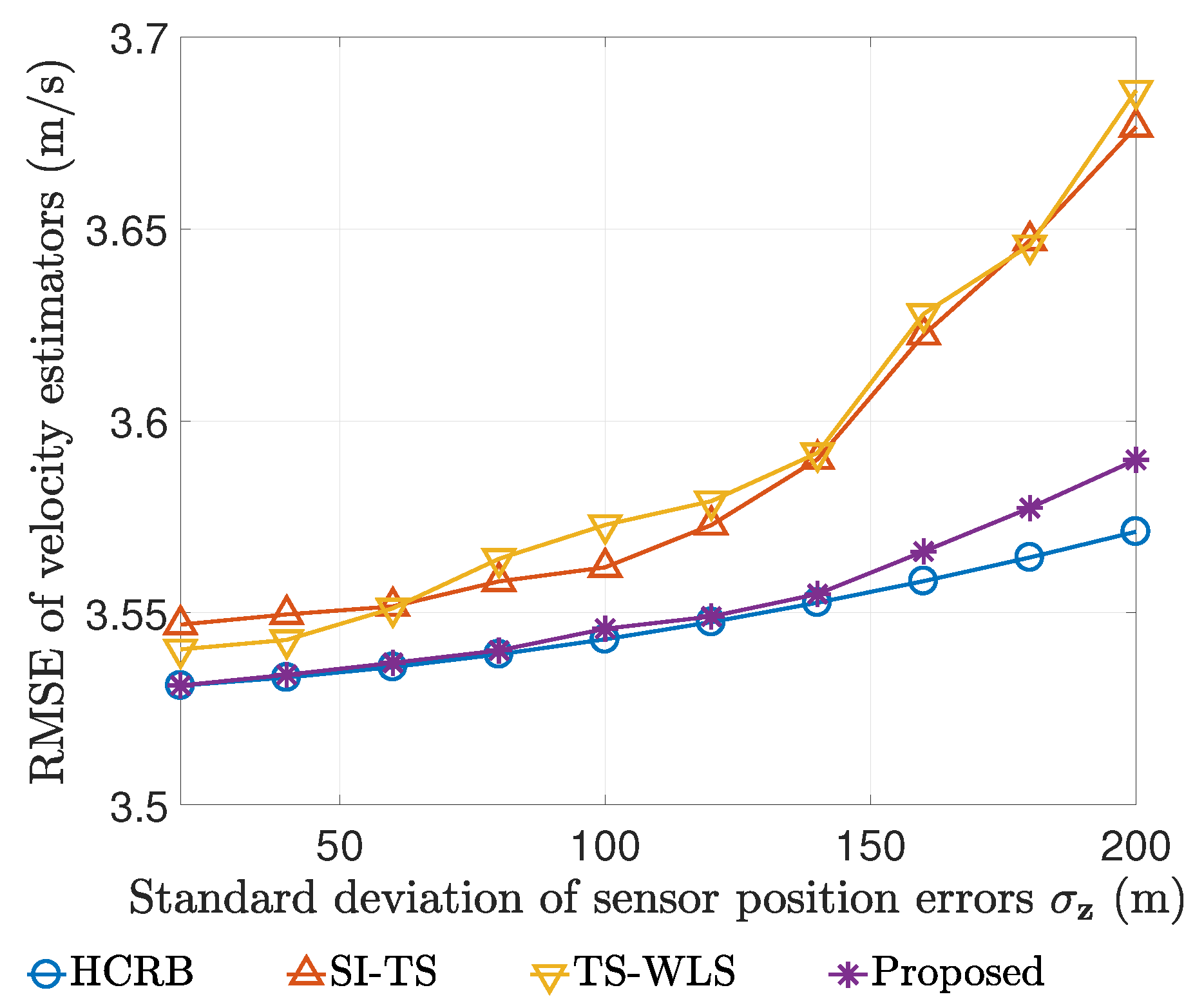
The RMSEs of our estimator, SI-TS and TS-WLS are compared with HCRB here. The simulation settings are as follows.
is
s,
is from 0 m to 200 m with a step size of 20 m, and the number of Monte Carlo simulations is
for each value of
. The comparison curves for both the position estimator and the velocity estimator are plotted respectively in
Figure 3 and
Figure 4. It is evident that our estimator has the least RMSE and can attain the HCRB accuracy at lower noise levels for determining both the position and the velocity.
7.2. Bias Calculation
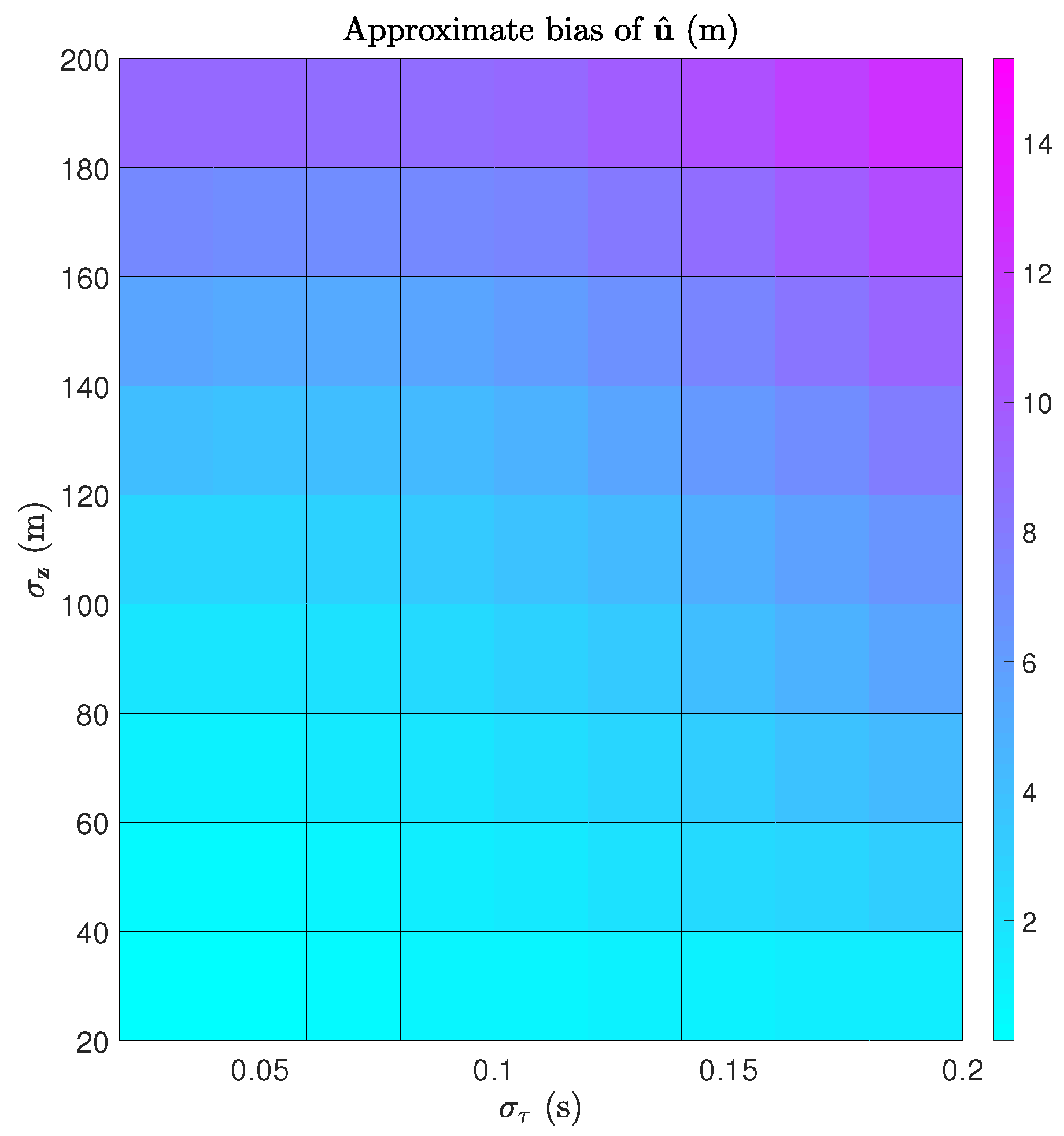
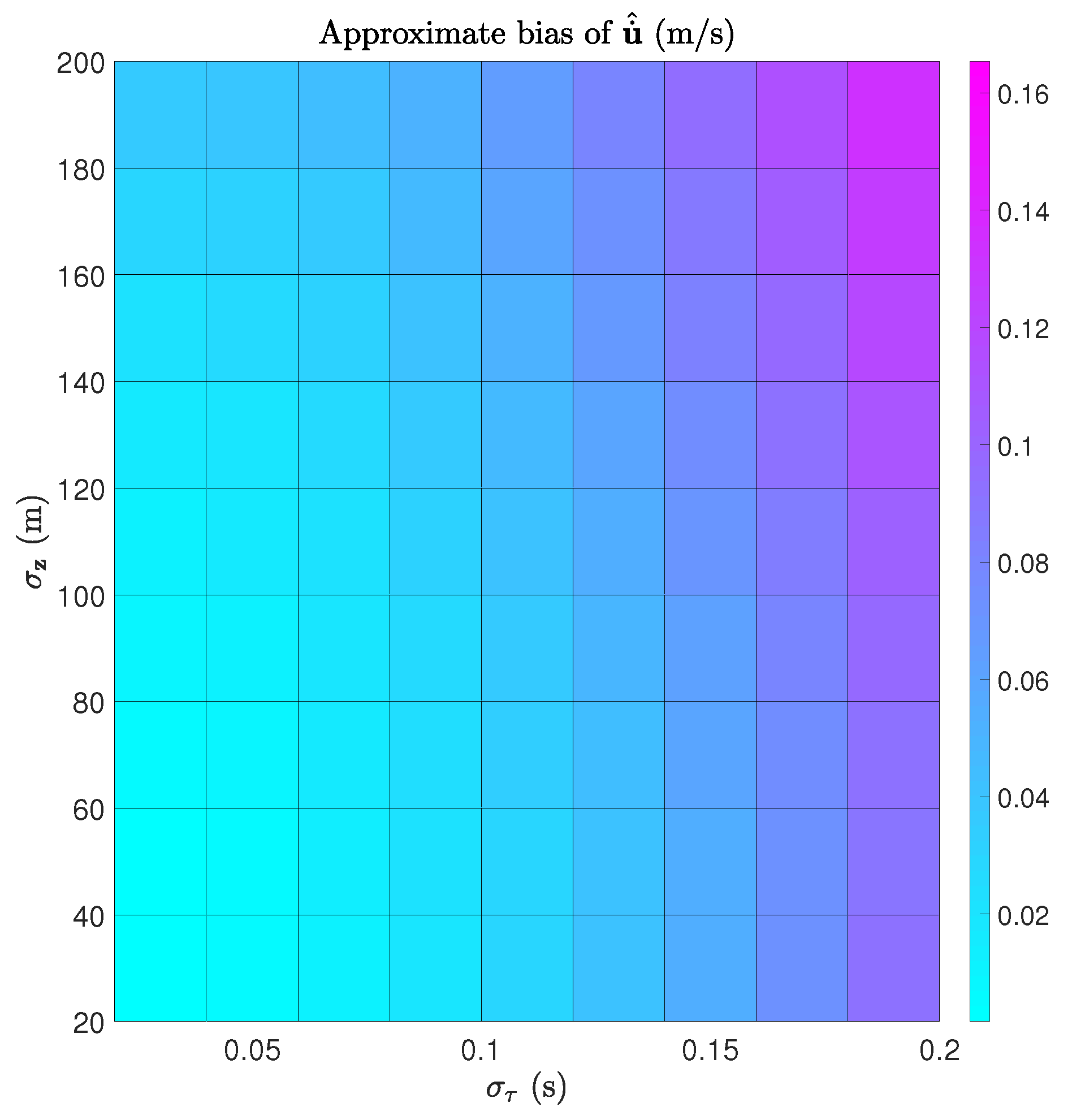
In this subsection, we evaluate the bias of our estimator. The simulation settings are as follows.
is from
s to
s with a step size of
s, and
is from 20 m to 200 m with a step size of 20 m. The norms of the theoretical bias vectors of
and
are calculated using results from
Section 6 and further visualized as surface plots in
Figure 5 and
Figure 6. It is consistent with intuition that the biases of both
and
increase with both
and
. It should be noted that the biases are relatively small compared with the norms of
m and
m/s, even if the noise levels are high, e.g.,
s and
m.
7.3. Localizing Multiple Disjoint Targets
The aim of this section is to evaluate the computational complexity of the algorithm in the sense of scalability, since the WLS algorithm involved in our estimator is computationally efficient. One advantage of our estimator is that it is ready to be extended to location of multiple disjoint targets by concatenating the data matrices in
Section 5. Let the number of the disjoint targets be
K, and
Monte Carlo experiments of joint location are performed for each value of
. Then, the running time of the
experiments are recorded. For convenience of comparison, we normalize the running time for each
K with the one for
. The normalized running times are plotted in
Figure 7 using log-log scale. It can be seen that the running time grows almost exponentially with respected to the number of targets. This observation indicates that localizing multiple targets sequentially is more time-efficient than localizing them simultaneously using our estimator. Such defects may root in the fact that our joint estimator does not share the nuisance parameters across the multiple targets.
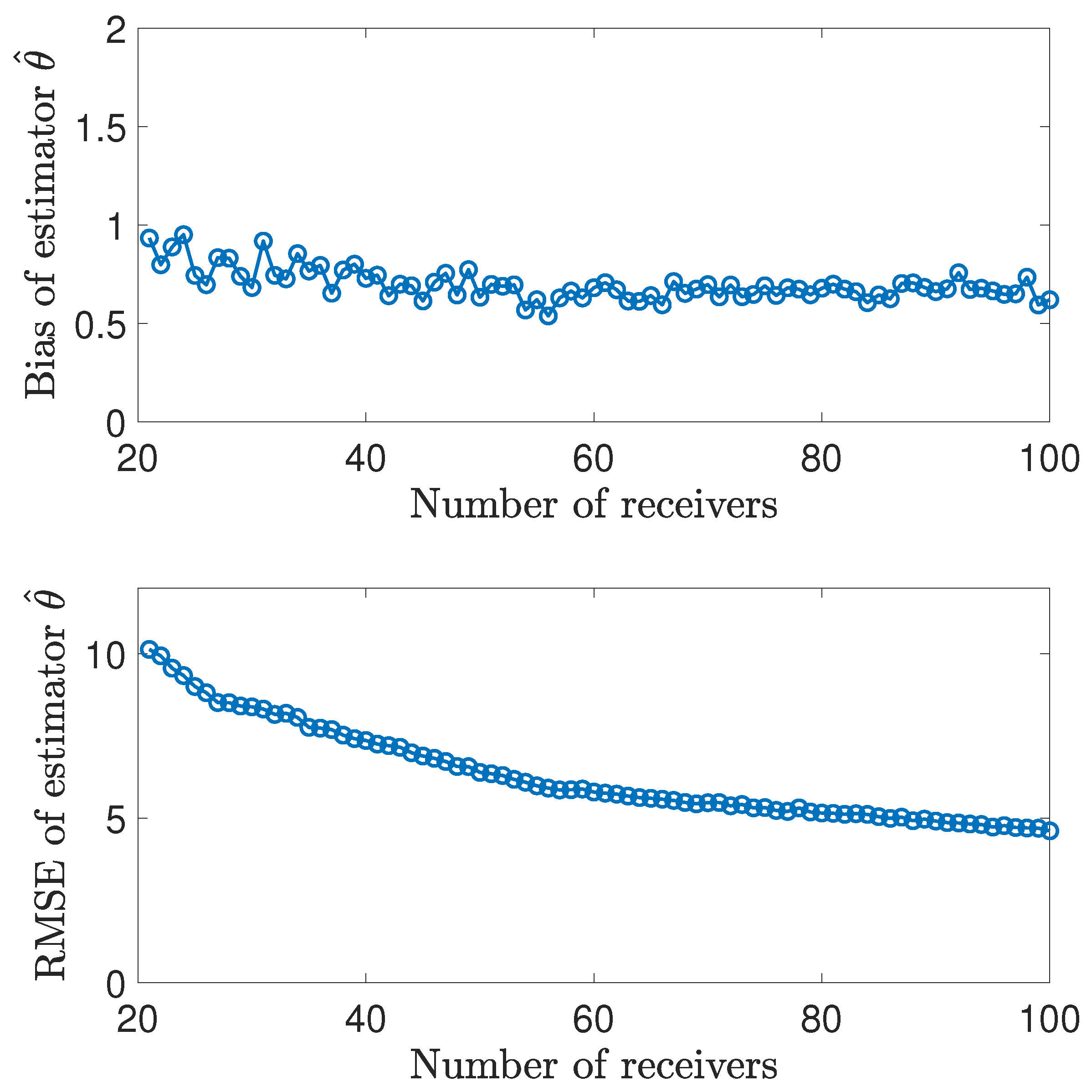
7.4. Large-Scale Simulation Experiments
The location scenario in
Section 7.1 through
Section 7.3 is the one examined in [
6]. In order to evaluate the performance of the proposed estimator more comprehensively, we design the following lareg-scale random experiments. In view of the symmetry of the transmitter
and receiver
in the observation model, we fix the number of transmitters to 1, and increase the number of receivers from 21 to 100. The transmitter’s position is fixed at
m. Both the
x-ordinate and
y-ordinate of the individual receiver’s position have the uniform probability distribution within the interval
m.
m, and
s. Other unspecified settings in these experiments are referred in
Table 4. In each location scenario, we conduct
Monte Carlo simulations. Then we explore the effect of the number of reveivers on the bias/RMSE and computational complexity of the proposed estimator in
Figure 8 and
Figure 9.
Figure 8 shows that increasing the number of receivers helps to reduce the RMSE of the estimator. It should be noted that increasing the number of receivers does not lead to a decrease of bias. This fact may imply that designing unbiased estimators is an inherently difficult problem in nonlinear estimation.
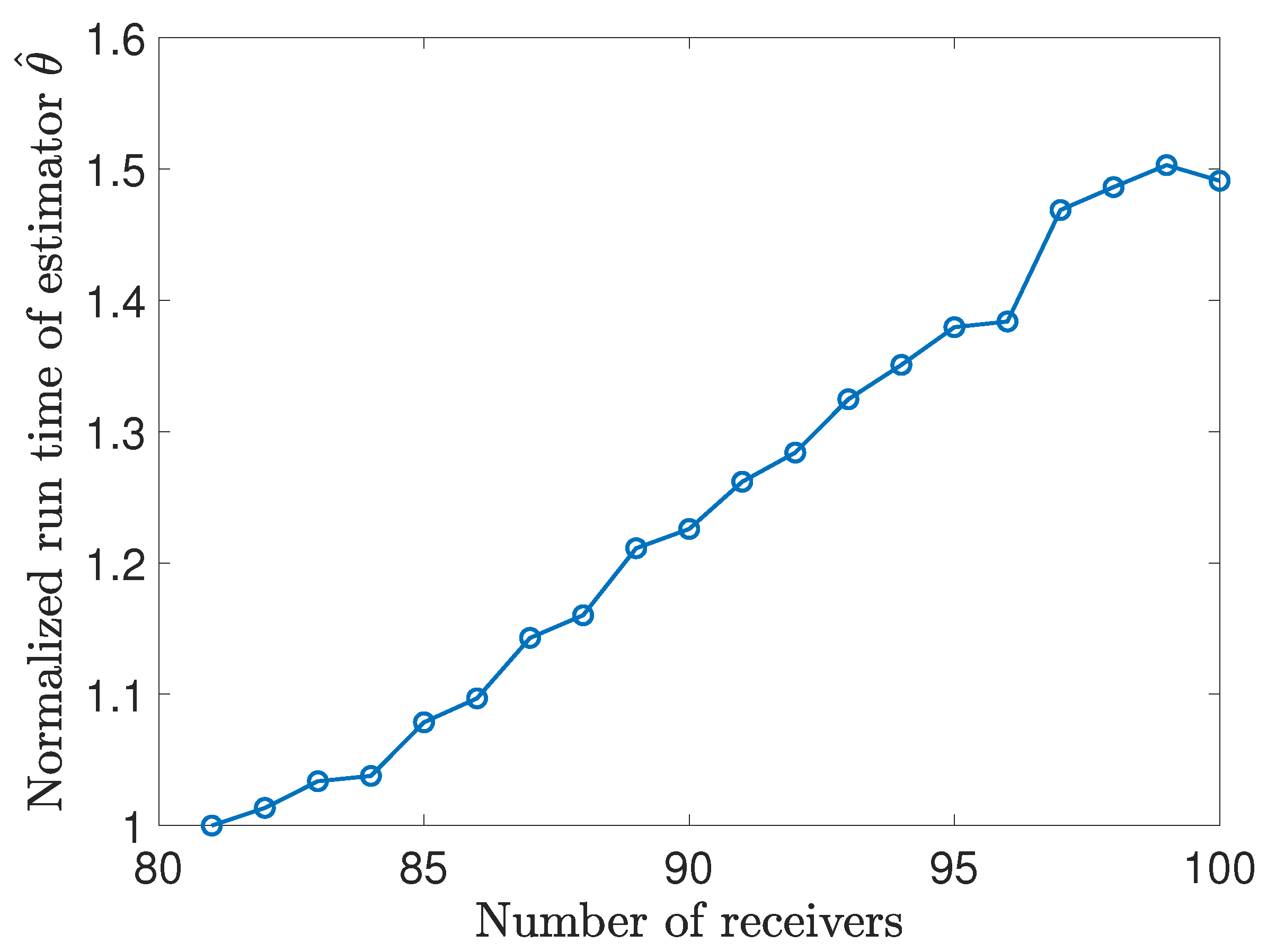
In addition, as can be seen in
Figure 9, the estimator’s relative running time scales linearly as more receivers are used when the number of the receivers is large enough (e.g.,
here). This trend coincides with the theoretical linear complexity obtained in
Section 6.3.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
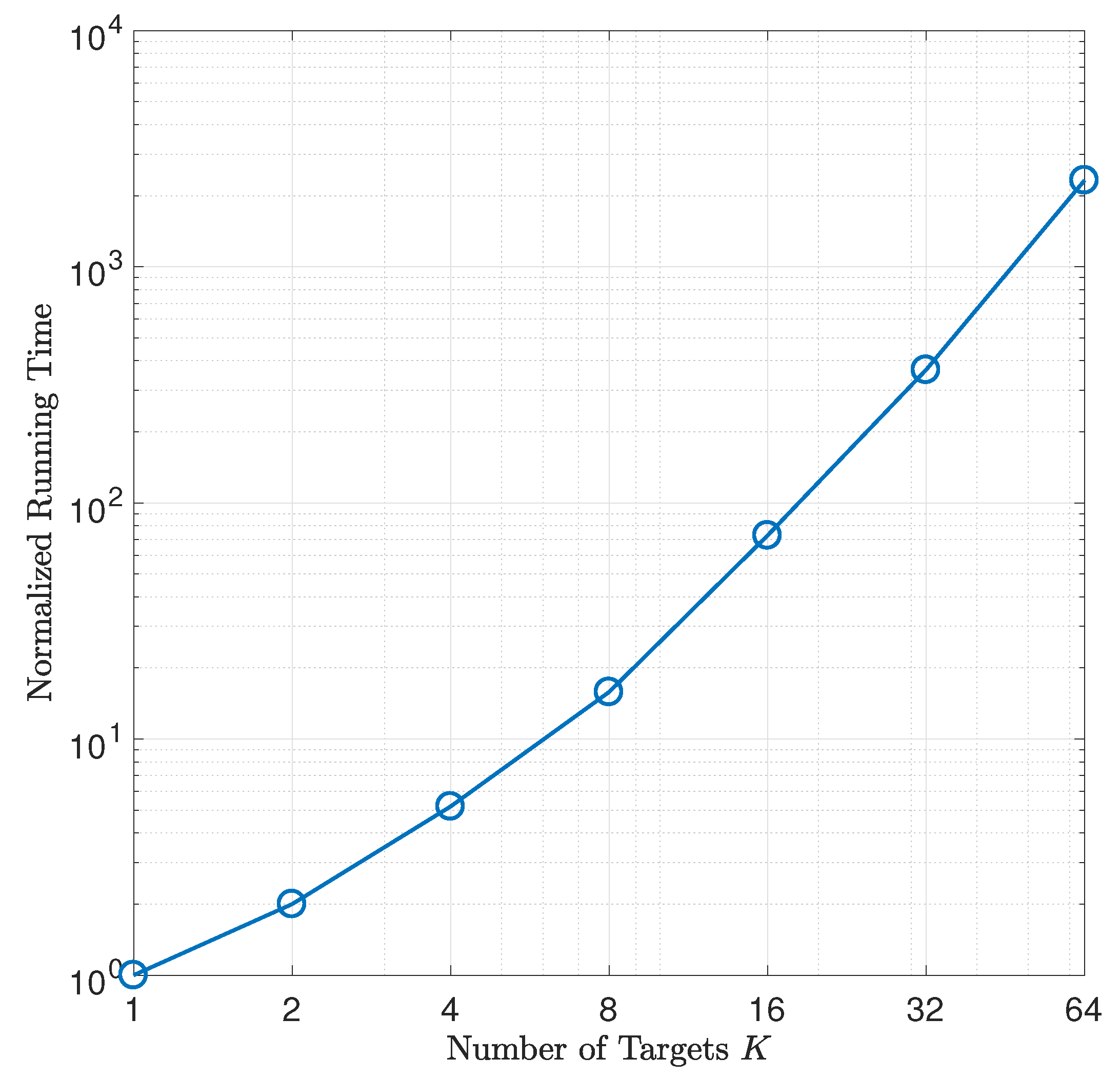{kind=link}
{kind=link}
{kind=link}