
Zero-Inflated Generalized Linear Mixed Models: A Better Way to Understand Data Relationships

 , ,
, ,  , and
, and 
Abstract
:1. Introduction
2. Background
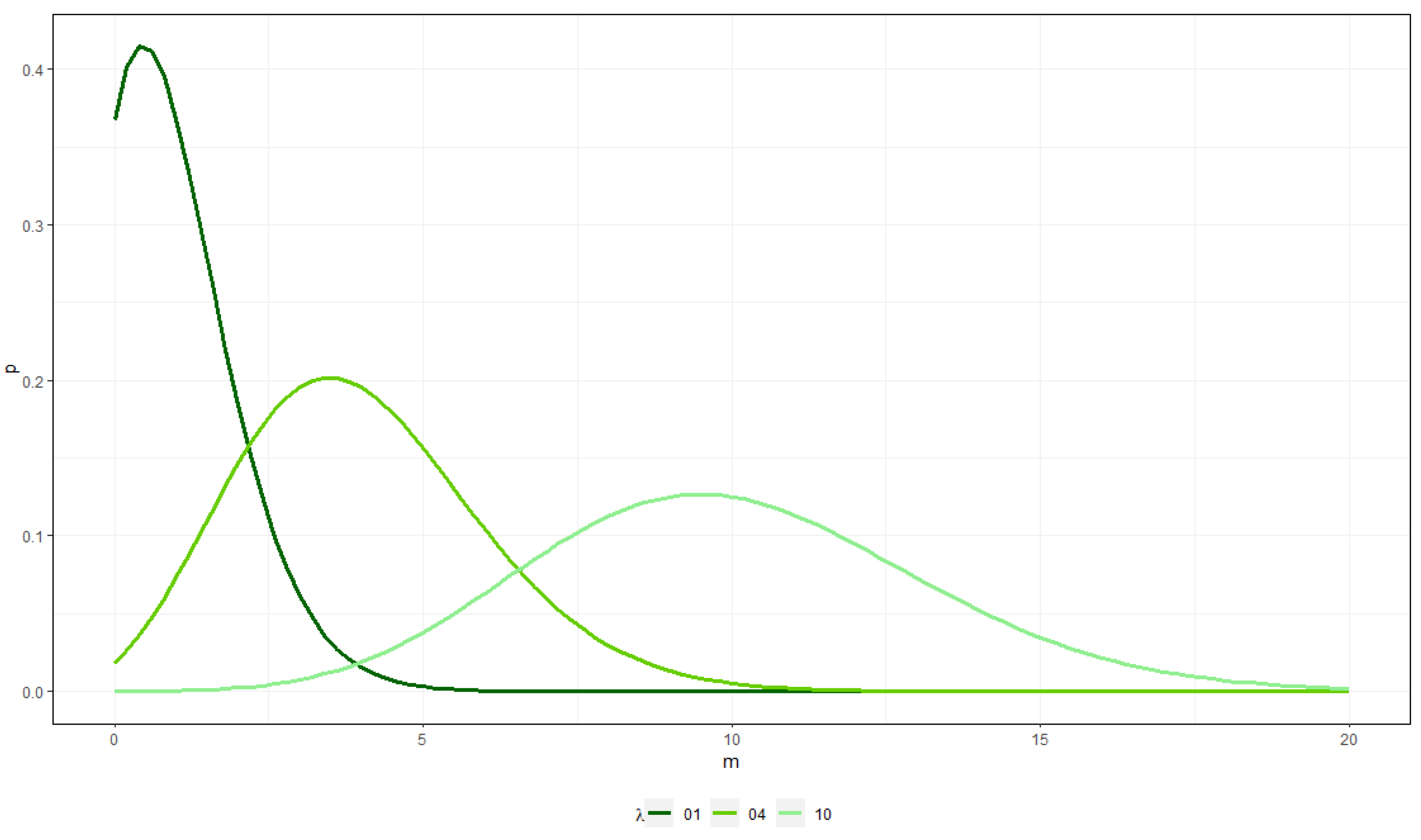
3. Count Data and Zero-Inflated Models
4. Generalized Linear Mixed Models (GLMM)
4.1. The Two-Level Model
4.2. Model Estimation and Materials
5. Culture and Corruption among United Nations’ Diplomats: An Applied Example
6. Results and Discussions
7. Final Considerations
7.1. Theoretical Aspects
7.2. Managerial Implications
7.3. Future Research in Count Data Multilevel Modeling
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
Abbreviations
| GLLM | Generalized Linear Mixed Models |
| GLM | Generalized Linear Models |
| LL | Log-Likelihood Function |
| NB | Negative Binomial |
| UN | United Nations |
| ZINB | Zero-Inflated Negative Binomial |
| ZINBM | Multilevel Zero-Inflated Negative Binomial |
| ZIP | Zero-Inflated Poisson |
Appendix A
Appendix A.1. Poisson Regression Models

Appendix A.2. Negative Binomial Regression Models and Overdispersion

Appendix A.3. Zero-Inflated Poisson Regression Models
Appendix A.4. Zero-Inflated Negative Binomial Regression Models

Appendix B
Calculated Random Effects of the Zero-Inflated Multilevel Model (ZINBM)
| African Countries | ||
| Country | Random Intercepts | Random Slopes |
| Algeria | 0.29027389 | 0.07500865 |
| Angola | 0.36813887 | 0.19668883 |
| Benin | 0.94289251 | 0.28121811 |
| Botswana | −0.04411956 | 0.02016038 |
| Burkina Faso | −0.29742728 | −0.03567919 |
| Burundi | −0.32982355 | −0.10873553 |
| Cameroon | 0.34371969 | 0.20256739 |
| Central African Republic | −0.26159519 | −0.03824944 |
| Chad | 0.01335540 | 0.00481880 |
| Comoros | 0.30241110 | 0.09969825 |
| Congo (Republic of Congo) | −0.61263303 | −0.29809801 |
| Côte d’Ivoire | 0.44484241 | 0.00888249 |
| Djibouti | −0.66107160 | −0.21794068 |
| Eritrea | −0.87335399 | 0.37184683 |
| Eswatini | −0.34670164 | 0.02799563 |
| Ethiopia | 0.61811679 | −0.02918207 |
| Gabon | −0.55575614 | −0.22744619 |
| Gambia | −0.50560832 | −0.05546880 |
| Ghana | −0.31605471 | −0.02456802 |
| Guinea | 0.14672569 | 0.05072124 |
| Guinea-Bissau | −0.01239237 | −0.00206721 |
| Kenya | −0.48414665 | −0.20664528 |
| Lesotho | −0.20847386 | 0.04272718 |
| Liberia | −0.14812793 | −0.13387362 |
| Libya | −0.42687909 | −0.17812012 |
| Madagascar | −0.19426981 | −0.06424881 |
| Malawi | −0.48238576 | −0.05618905 |
| Mali | −0.03244951 | −0.00550642 |
| Mauritania | −0.42362948 | 0.00787552 |
| Mauritius | −0.44565488 | 0.13316253 |
| Morocco | 0.59996309 | −0.08021948 |
| Mozambique | 0.22465744 | 0.06930940 |
| Namibia | −0.56727213 | 0.17922600 |
| Niger | 0.02856408 | 0.01123432 |
| Nigeria | 0.29337218 | 0.14615809 |
| Rwanda | −0.20675524 | −0.03023096 |
| Senegal | 0.47608807 | 0.03903200 |
| Sierra Leone | −0.03976362 | −0.01080527 |
| South Africa | 0.49076426 | −0.19813893 |
| Sudan | 0.41538368 | 0.12070257 |
| Tanzania | −0.14838120 | −0.06700696 |
| Togo | −0.10477449 | −0.00838254 |
| Tunisia | 0.16206770 | −0.04094673 |
| Uganda | −0.52724205 | −0.10454739 |
| Zambia | 0.22360128 | 0.03534670 |
| Zayre | 0.27668468 | 0.29463712 |
| Zimbabwe | 0.62168926 | −0.07141636 |
| Asian Countries | ||
| Country | Random Intercepts | Random Slopes |
| Armenia | −0.35352111 | −0.09339492 |
| Azerbaijan | 0.19415641 | 0.09802380 |
| Bangladesh | 0.44949158 | 0.02262673 |
| Bhutan | 0.23931487 | −0.10189279 |
| Cambodia | −0.34036202 | −0.25131552 |
| China | −0.34968305 | 0.03957045 |
| Georgia | 0.00376565 | 0.00081100 |
| India | 0.49470753 | −0.04487317 |
| Indonesia | 0.55611730 | 0.25351292 |
| Japan | −0.47067235 | 0.33723226 |
| Kazakhstan | 0.06968353 | 0.02646168 |
| Kyrgyzstan | 0.16421008 | 0.04128285 |
| Laos | −0.36615737 | −0.09463578 |
| Malaysia | −0.05021094 | 0.02749636 |
| Mongolia | −0.30501764 | 0.00854783 |
| Nepal | −0.12802811 | −0.02303344 |
| Philippines | 0.06464324 | −0.00243171 |
| Singapore | 0.05540805 | −0.06245646 |
| South Korea | −0.27408919 | 0.06821146 |
| Sri Lanka | −0.11471574 | 0.00593398 |
| Tajikistan | −0.42844117 | −0.25478445 |
| Thailand | 0.80785575 | −0.02971311 |
| Turkmenistan | −0.50514492 | −0.30576730 |
| Uzbekistan | −0.35409601 | −0.16818937 |
| Vietnam | −0.12923459 | −0.02394848 |
| Middle East Countries | ||
| Country | Random Intercepts | Random Slopes |
| Bahrain | 0.12970880 | −0.05181181 |
| Cyprus | −0.48447181 | 0.38519245 |
| Egypt | 0.91216283 | −0.04196600 |
| Iran | −0.39907911 | −0.08266890 |
| Israel | −0.23540525 | 0.18956769 |
| Jordan | −0.69146088 | 0.20780363 |
| Kuwait | 0.91731159 | −0.62780406 |
| Lebanon | −0.79813114 | 0.00007300 |
| Oman | −0.21215604 | 0.13006397 |
| Pakistan | 0.44354709 | 0.13218649 |
| Saudi Arabia | 0.22240830 | −0.08234248 |
| Syria | 0.41615624 | 0.07051341 |
| Turkey | −0.11882707 | 0.02221109 |
| United Arab Emirates | −0.24431332 | 0.13840813 |
| Yemen | −0.57927546 | −0.09647853 |
| European Countries | ||
| Country | Random Intercepts | Random Slopes |
| Albania | 0.44277582 | 0.18957083 |
| Austria | 0.45259684 | −0.45199415 |
| Belarus | −0.57872150 | −0.10517272 |
| Belgium | 0.00566068 | −0.00420827 |
| Bosnia & Herzegovina | 0.27446995 | 0.00448070 |
| Bulgaria | 1.12489858 | 0.12753296 |
| Croatia | −0.18674269 | −0.00045776 |
| Czechia | 0.18708253 | −0.07003003 |
| Denmark | −0.12906556 | 0.14799282 |
| Estonia | −0.05015729 | 0.02194181 |
| Finland | −0.50544598 | 0.57713222 |
| France | 0.24695152 | −0.22664305 |
| Germany | −0.03254498 | 0.03421383 |
| Greece | 0.04097844 | −0.02443984 |
| Hungary | −0.27064047 | 0.14312356 |
| Ireland | −0.00913212 | 0.00946188 |
| Italy | 0.76640023 | −0.50200084 |
| Latvia | −0.30630650 | 0.04069200 |
| Lithuania | −0.61513082 | 0.14220830 |
| Moldova | −0.75627015 | −0.09149125 |
| Netherlands | −0.03288228 | 0.03697565 |
| North Macedonia | −0.51077076 | 0.00863490 |
| Norway | −0.23699016 | 0.25795913 |
| Poland | −0.45472045 | 0.19941508 |
| Portugal | 0.67046682 | −0.57361285 |
| Romania | −0.04864107 | −0.00168571 |
| Russia | −0.84761028 | −0.21218648 |
| Slovakia | −0.06970213 | 0.01001509 |
| Slovenia | 0.26469128 | −0.15521686 |
| Spain | 0.58641231 | −0.50766076 |
| Sweden | −0.23326544 | 0.26606757 |
| Switzerland | −0.59286471 | 0.68130772 |
| Ukraine | 0.36722275 | 0.14899188 |
| United Kingdom | −0.54808365 | 0.59353453 |
| Yugoslavia | 0.08347056 | 0.03895000 |
| North American and Caribbean Countries | ||
| Country | Random Intercepts | Random Slopes |
| Canada | −0.17267838 | 0.19520823 |
| Dominican Republic | −0.58287177 | −0.07829544 |
| Haiti | 0.20322620 | 0.07527424 |
| Jamaica | −0.24794002 | 0.00938118 |
| Trinidad & Tobago | 0.37387195 | −0.09694391 |
| Oceania Countries | ||
| Country | Random Intercepts | Random Slopes |
| Australia | −0.10445492 | 0.10975066 |
| Fiji | 0.02271001 | −0.00678572 |
| New Zealand | −0.57624262 | 0.65679904 |
| Papua New Guinea | 0.27204064 | 0.07077443 |
| South American Countries | ||
| Country | Random Intercepts | Random Slopes |
| Argentina | 0.31771912 | −0.01948855 |
| Bolivia | −0.44415219 | −0.02577823 |
| Brazil | 0.96602883 | −0.23480633 |
| Chile | 0.66125855 | −0.48323508 |
| Colombia | −0.29419744 | −0.05614823 |
| Costa Rica | 0.40459963 | −0.21728966 |
| Ecuador | −0.30005928 | −0.08591258 |
| El Salvador | −0.02803395 | 0.00091081 |
| Guatemala | −0.58738992 | −0.12267548 |
| Guyana | −0.39814087 | 0.01490841 |
| Honduras | −0.38180429 | −0.11161159 |
| Mexico | −0.35404205 | −0.01542422 |
| Nicaragua | 0.16002692 | 0.04744322 |
| Panama | −0.30726926 | 0.00814645 |
| Paraguay | 0.13283151 | 0.06199097 |
| Peru | 0.16886576 | −0.01576054 |
| Uruguay | −0.04140083 | 0.01679624 |
| Venezuela | −0.02358928 | −0.00732867 |
References
- Blevins, D.P.; Tsang, E.W.K.; Spain, S.M. Count-Based Research in Management: Suggestions for improvement. Organ. Res. Methods 2015, 18, 47–69. [Google Scholar] [CrossRef]
- Almeida, B.P.; Gonçalves, E.; da Silva, A.S.; Reis, R. Internalization of Knowledge Spillovers by Regions: A measure based on self-citation patents. Ann. Reg. Sci. 2020, 66, 309–330. [Google Scholar] [CrossRef]
- O’Hara, R.; Kotze, J. Do Not Log-Transform Count Data. Nat. Preced. 2010, 1, 1. [Google Scholar]
- Lambert, D. Zero-Inflated Poisson Regression, with an Application to Defects in Manufacturing. Technometrics 1992, 34, 1–14. [Google Scholar] [CrossRef]
- Spriensma, A.S.; Hajos, T.R.S.; de Boer, M.R.; Heymans, M.W.; Twisk, J.W.R. A New Approach to Analyse Longitudinal Epidemiological Data with an Excess of Zeros. BMC Med. Res. Methodol. 2013, 1, 13–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heck, R.; Thomas, S.L. An Introduction to Multilevel Modeling Techniques: MLM and SEM Approaches Using Mplus, 3rd ed.; Routledge: New York, NY, USA, 2015; p. 461. [Google Scholar]
- Mathieu, J.E.; Chen, G. The Etiology of the Multilevel Paradigm in Management Research. J. Manag. 2011, 37, 610–641. [Google Scholar] [CrossRef]
- Courgeau, D. Methodology and Epistemology of Multilevel Analysis: Approaches from different Social Sciences; Springer: Paris, France, 2012; p. 240. [Google Scholar]
- Arceneaux, K.; Nickerson, D.W. Modeling Certainty with Clustered Data: A comparison of methods. Political Anal. 2009, 17, 177–190. [Google Scholar] [CrossRef] [Green Version]
- Hall, D.B. Zero-Inflated Poisson and Binomial Regression with Random Effects: A case study. Biometrics 2000, 56, 1030–1039. [Google Scholar] [CrossRef] [PubMed]
- Fisman, R.; Miguel, E. Corruption, Norms, and Legal Enforcement: Evidence from diplomatic parking tickets. J. Polit. Econ. 2007, 115, 1020–1048. [Google Scholar] [CrossRef] [Green Version]
- Shook, C.L.; Ketchen, D.J.; Cycyota, C.S.; Crockett, D. Data Analytic Trends and Training in Strategic Management. Strat. Mgmt. J. 2003, 24, 1231–1237. [Google Scholar] [CrossRef]
- Perumean-Chaney, S.; Morgan, C.J.; McDowall, D.; Aban, A.B. Zero-Inflated and Overdispersed: What’s one to do? J. Stat. Comput. Simul. 2013, 83, 1671–1683. [Google Scholar] [CrossRef]
- Pew, T.; Warr, R.L.; McDSchultz, G.G.; Heaton, M. Justification for Considering Zero-Inflated Models in Crash Frequency Analysis. Transp. Res. Interdiscip. Perspect. 2020, 8, 1671–1683. [Google Scholar] [CrossRef]
- Lee, S. Addressing Imbalanced Insurance Data Through Zero-Inflated Poisson Regression with Boosting. ASTIN Bull. 2021, 51, 27–55. [Google Scholar] [CrossRef]
- Diaz, M.; Huff-Corzine, L.; Corzine, J. Demanding Reduction: A County-level analysis examining structural determinants of human trafficking arrests in Florida. Crime Delinq. 2020, 1–24. [Google Scholar] [CrossRef]
- Koning, I.; de Looze, M.; Harakeh, Z. Parental Alcohol-Specific Rules Effectively Reduce Adolescents’ Tobacco and Cannabis Use: A longitudinal study. Drug Alcohol Depend. 2020, 216, 1–6. [Google Scholar] [CrossRef]
- Chinaeke, E.; Melanie, G.; Yuan, H.; Jiajia, Z.; Bankole, O. Parental The Positive Association Between Employment and Self-Reported Mental Health in the USA: A robust application of marginalized zero-inflated negative binomial regression (MZINB). J. Public Health 2020, 42, 340–352. [Google Scholar]
- Clouston, S.A.P.; Natale, G.; Link, B.J. Socioeconomic Inequalities in the Spread of Coronavirus-19 in the United States: A examination of the emergence of social inequalities. Soc. Sci. Med. 2021, 268, 113554. [Google Scholar] [CrossRef]
- Karmakar, M.; Lantz, P.M.; Tipirneni, R. Association of Social and Demographic Factors with COVID-19 Incidence and Death Rates in the US. JAMA 2021, 4, e2036462. [Google Scholar]
- Bolker, B.M. Linear and Generalized Linear Mixed Models. In Ecological Statistics: Contemporary Theory and Application; Fox, G.A., Negrete-Yankelevich, S., Sosa, V.J., Eds.; Oxford University Press: Oxford, UK, 2015; p. 406. [Google Scholar]
- Brooks, M.E.; Kristensen, K.; van Benthem, K.J.; Magnusson, A.; Berg, C.W.; Nielsen, A.; Skaug, H.J.; Mächler, M.; Bolker, B.M. glmmTMB Balances Speed and Flexibility Among Packages for Zero-inflated Generalized Linear Mixed Modeling. R J. 2017, 9, 378–400. [Google Scholar] [CrossRef] [Green Version]
- Woltman, H.; Feldstain, A.; MacKay, J.C.; Rocchi, M. An Introduction to Hierarchical Linear Modeling. TQMP 2012, 8, 52–69. [Google Scholar] [CrossRef] [Green Version]
- DeBruine, L.M.; Barr, D.J. Understanding Mixed-Effects Models Through Data Simulation. AMPPS 2021, 4, 1–15. [Google Scholar]
- Hair, J.F., Jr.; Fávero, L.P. Multilevel Modeling for Longitudinal Data: Concepts and applications. Rausp Manag. J. 2010, 54, 459–489. [Google Scholar] [CrossRef]
- Meteyard, L.; Davies, R.A.I. Best Practice Guidance for Linear Mixed-Effects Models in Psychological Science. J. Mem. Lang. 2020, 112, 104092. [Google Scholar] [CrossRef] [Green Version]
- Parker, R.A.; Scott, C.; Inácio, V.; Stevens, N.T. Using Multiple Agreement Methods for Continuous Repeated Measures Data: A tutorial for practitioners. BMC Med. Res. Methodol. 2020, 20, 154. [Google Scholar] [CrossRef]
- Hox, J. Multilevel Analysis: Techniques and Applications, 3rd ed.; Routledge: New York, NY, USA, 2017; p. 364. [Google Scholar]
- Fávero, L.P.; Belfiore, P. Data Science for Business and Decision Making; Academic Press Elsevier: Cambridge, MA, USA, 2019; p. 1244. [Google Scholar]
- Finch, W.H.; Bolin, J.E.; Kelley, K. Multilevel Modeling Using R, 2nd ed.; Chapman and Hall: New York, NY, USA, 2019; p. 254. [Google Scholar]
- Garson, G. Multilevel Modeling: Applications in STATA®, IBM® SPSS®, SAS®, R, & HLM™; Sage Publications: Thousand Oaks, CA, USA, 2019; p. 552. [Google Scholar]
- Nelder, J.A.; Wedderburn, W.M. Generalized Linear Models. J. R. Stat. Soc. 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Cameron, A.C.; Trivedi, P.K. Regression Analysis of Count Data, 2nd ed.; Cambridge University Press: Cambridge, MA, USA, 2013; p. 597. [Google Scholar]
- Hilbe, J.M. Negative Binomial Regression, 2nd ed.; Cambridge University Press: Cambridge, MA, USA, 2011; p. 576. [Google Scholar]
- Hilbe, J.M. Modeling Count Data; Cambridge University Press: Cambridge, MA, USA, 2014; p. 300. [Google Scholar]
- Wooldridge, J.M. Econometric Analysis of Cross Section and Panel Data, 2nd ed.; MIT Press: Cambridge, MA, USA, 2010; p. 1095. [Google Scholar]
- Cameron, A.C.; Trivedi, P.K. Regression-Based Tests for Overdispersion in the Poisson Model. J. Econ. 1990, 46, 347–364. [Google Scholar] [CrossRef]
- Fávero, L.P.; Belfiore, P.; Santos, M.A.; Freitas Souza, R. A Stata (and Mata) Package for Direct Detection of Overdispersion in Poisson and Negative Binomial Regression Models. Stat. Optim. Inf. Comput. 2020, 8, 773–789. [Google Scholar] [CrossRef]
- Payne, E.H.; Hardin, J.W.; Egede, L.E.; Ramakrishnan, V.; Selassie, A.; Gebregziabher, M. Approaches for Dealing with Various Sources of Overdispersion in Modeling Count Data: Scale adjustment versus modeling. Stat. Methods Med. Res. 2017, 26, 1802–1823. [Google Scholar] [CrossRef]
- Fávero, L.P.; Serra, R.G.; Santos, M.A.; Brunaldi, E. Cross-Classified Multilevel Determinants of Firm’s Sales Growth in Latin America. IJOEM 2018, 13, 902–924. [Google Scholar] [CrossRef]
- Ngatchou-Wandji, J.; Paris, C. On the Zero-Inflated Count Models with Application to Modelling Annual Trends in Incidences of Some Occupational Allergic Diseases in France. J. Data Sci. 2011, 69, 639–659. [Google Scholar]
- Vuong, Q.H. Likelihood Ratio Tests for Model Selection and Non-Nested Hypotheses. Econometrica 1989, 57, 307–333. [Google Scholar] [CrossRef] [Green Version]
- Goldstein, H. Multilevel Statistical Models, 4th ed.; Wiley Series in Probability and Statistics; Wiley: Chichester, UK, 2010; p. 384. [Google Scholar]
- Santos, M.A.; Fávero, L.P.; Distadio, L.F. Adoption of the International Financial Reporting Standards (IFRS) on Companies’ Financing Structure in Emerging Economies. Financ. Res. Lett. 2016, 16, 179–189. [Google Scholar] [CrossRef]
- Serra, R.G.; Fávero, L.P. Multiples’ Valuation: The Selection of Cross-Border Comparable Firms. Emerg. Mark. Financ. Trade 2018, 54, 1973–1992. [Google Scholar] [CrossRef]
- Fávero, L.P. The Zero-Inflated Negative Binomial Multilevel Model: Demonstrated by a Brazilian dataset. IJMOR 2018, 11, 90–107. [Google Scholar] [CrossRef]
- Lee, A.H.; Wang, K.; Scott, J.A.; Yau, K.K.W.; McLachlan, G.J. Multilevel Zero-Inflated Poisson Regression Modelling of Correlated Count Data with Excess Zeros. Stat. Methods Med. Res. 2006, 15, 47–61. [Google Scholar] [CrossRef]
- Rabe-Hesketh, S.; Skrondal, A.; Pickels, A. Maximum Likelihood Estimation of Limited and Discrete Dependent Variable Models with Nested Random Effects. J. Econ. 2005, 128, 301–323. [Google Scholar] [CrossRef] [Green Version]
- Mauro, P. Corruption and Growth. Q. J. Econ. 1995, 110, 681–712. [Google Scholar] [CrossRef]
- Duggan, M.; Levitt, S.D. Winning Isn’t Everything: Corruption in Sumo Wrestling. Am. Econ. Rev. 2002, 92, 1594–1605. [Google Scholar] [CrossRef] [Green Version]
- Glaeser, E.L.; Goldin, C. Corruption and Reform: Lessons from America’s Economic History; University of Chicago Press: Chigago, IL, USA, 2006; p. 384. [Google Scholar]
- Levitt, S.D. White-Collar Crime Writ Small: A case study of bagels, donuts, and the honor system. Am. Econ. Rev. 2006, 96, 290–294. [Google Scholar] [CrossRef]
- Svensson, J. Eight Questions about Corruption. J. Econ. Perspect. 2005, 19, 19–42. [Google Scholar] [CrossRef] [Green Version]
- Desmarais, B.A.; Harden, J.J. Testing for Zero Inflation in Count Models: Bias Correction for the Vuong Test. Stata J. 2013, 13, 810–835. [Google Scholar] [CrossRef] [Green Version]
- Okhuysen, G.; Bonardi, J.-P. The Challenges of Building Theory by Combining Lenses. AMR 2011, 36, 6–11. [Google Scholar] [CrossRef]
- Bettis, R.; Gambardella, A.; Helfat, C.; Mitchell, W. Quantitative empirical analysis in strategic management: Editorial. Strateg. Manag. J. 2014, 35, 949–953. [Google Scholar] [CrossRef]
- Dale, D.; Sirchenko, A. Estimation of Nested and Zero-Inflated Ordered Probit Models. Stata J. 2021, 21, 3–38. [Google Scholar] [CrossRef]
- Antonakis, J.; Bastardoz, N.; Rönkkö, M. On Ignoring the Random Effects Assumption in Multilevel Models: Review, critique, and recommendations. Organ. Res. Methods 2021, 24, 443–483. [Google Scholar] [CrossRef] [Green Version]
- Klakattawi, H.; Vinciotti, V.; Yu, K. A Simple and Adaptive Dispersion Regression Model for Count Data. Entropy 2018, 20, 142. [Google Scholar] [CrossRef] [Green Version]
- Favero, L.P.; Santos, M.A.; Serra, R.G. Cross-Border Branching in the Latin American Banking Sector. IJBM 2018, 4, 496–528. [Google Scholar] [CrossRef]
- Cameron, A.C.; Trivedi, P.K. Microeconomics using Stata; Stata Press: College Station, TX, USA, 2010; p. 706. [Google Scholar]
- Mouatassim, Y.; Ezzahid, E.H.; Belasri, Y. Operational Value-at-Risk in Case of Zero-Inflated Frequency. IJEF 2012, 4, 70–77. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Journal Name (1) | Google Scholar’s Ranking (2) | “Zero -Inflated” (3) | “Poisson” (4) | “Negative Binomial” (5) | “Overdispersion” (6) | Count Models (7) = (4) + (5) − (6) | ZIM Relative Participation (8) = (3)/(7) |
|---|---|---|---|---|---|---|---|
| Journal of Business Ethics | 1 | 4 | 36 | 22 | 6 | 52 | 7.69% |
| Computers Education | 2 | 2 | 22 | 2 | 0 | 24 | 8.33% |
| American Journal of Public Health | 3 | 32 | 549 | 151 | 85 | 615 | 5.20% |
| Research Policy | 4 | 48 | 236 | 248 | 80 | 404 | 11.88% |
| Global Environmental Change | 5 | 8 | 36 | 19 | 6 | 49 | 16.33% |
| Health Affairs | 6 | 9 | 76 | 57 | 13 | 120 | 7.50% |
| Social Science Medicine | 7 | 36 | 422 | 153 | 60 | 515 | 6.99% |
| New Media Society | 8 | 0 | 13 | 15 | 4 | 24 | 0.00% |
| American Journal of Political Science | 9 | 14 | 53 | 54 | 32 | 75 | 18.67% |
| Procedia-Social and Behavioral Sciences | 10 | 9 | 100 | 27 | 6 | 121 | 7.44% |
| Journal Name (1) | Google Scholar Ranking (2) | “Multilevel Model” (3) | “Hierarchical Model” (4) | “Random Coefficients Model” (5) | GLMM (6) = (3) + (4) + (5) |
|---|---|---|---|---|---|
| Journal of Business Ethics | 1 | 60 | 47 | 13 | 120 |
| Computers & Education | 2 | 62 | 27 | 0 | 88 |
| American Journal of Public Health | 3 | 59 | 20 | 2 | 81 |
| Research Policy | 4 | 35 | 22 | 6 | 63 |
| Global Environmental Change | 5 | 25 | 13 | 1 | 39 |
| Health Affairs | 6 | 2 | 7 | 0 | 9 |
| Social Science Medicine | 7 | 727 | 149 | 36 | 912 |
| New Media Society | 8 | 2 | 7 | 0 | 9 |
| American Journal of Political Science | 9 | 38 | 17 | 1 | 56 |
| Procedia-Social and Behavioral Sciences | 10 | 72 | 144 | 6 | 22 |
| Verification | Count Data Regression Model | |||
|---|---|---|---|---|
| Poisson | Negative Binomial (NB) | Zero-Inflated Poisson (ZIP) | Zero-Inflated Negative Binomial (ZINB) | |
| Overdispersion in Outcome Variable | No | Yes | No | Yes |
| Inflation of Zeros in Outcome Variable | No | No | Yes | Yes |
| Variable | Description |
|---|---|
| wbcode | Polychotomic categorical variable that indicates the acronyms of the countries in the dataset. |
| region | Polychotomic variable that points to a region of the globe to which each country in the dataset belongs: Africa, Asia, Europe, Middle East, North America, Oceania, and South America. |
| violations_all | Discrete variable that measures the amount of unpaid parking violations by diplomats in a givencountry. It is the outcome variable of the models. |
| corruption | Continuous variable that indicates the level of corruption in each country. The greater the polarity, the greater the country’s corruption. |
| post | Dichotomous variable that indicates the moments that consider the inexistence and existence of legal consequences to unpaid parking violations by diplomats-’no’ and ’yes’ indicators, respectively. |
| staff | Discrete variable that measures the number of diplomats from a given country. |
| lgdppcus | Continuous variable that indicates the natural logarithm of GDP per capita of each country. |
| Violation_all | Corruption | Post | Staff | Lgdppcus | Region |
|---|---|---|---|---|---|
| Min.: 0.0 1st Q.: 2.0 Median: 18.5 3rd Q.: 253.8 Max: 16,751.0 Mean: 494.6 | Min.: −2.583 1st Q.: −0.415 Median: 0.327 3rd Q.: 0.720 Max: 1.583 Mean: 0.014 | Freq. of ‘no’: 149 Freq. of ‘yes’: 149 | Min.: 2.000 1st Q.: 6.000 Median: 9.000 3rd Q.: 14.000 Max: 86.000 Mean: 11.810 | Min.: 4.559 1st Q.: 6.036 Median: 7.266 3rd Q.: 8.543 Max: 10.505 Mean: 7.394 | Africa: 92 Asia: 50 Europe: 70 Middle East: 30 North America: 12 Oceania: 8 South America: 36 |
| NB–Model 3 Fisman and Miguel [11] | ZINB | ZINBM | |
|---|---|---|---|
| Fixed Effects | |||
| intercept | 2.871 *** | 3.115 *** | 2.732 ** |
| (0.987) | (0.909) | −1,150 | |
| corruption | 0.575 *** | 0.475 *** | 0.561 *** |
| (0.162) | (0.159) | (0.215) | |
| post | −4.215 *** | −4.284 *** | −4.265 *** |
| (0.175) | 0.153 | (0.136) | |
| staff | 0.051 *** | 0.048 *** | 0.040 *** |
| (0.008) | (0.011) | (0.011) | |
| lgdppcus | 0.091 | 0.110 | 0.105 |
| (0.116) | (0.112) | (0.129) | |
| Africa | 2.865 *** | 2.657 *** | 2.885 *** |
| (0.504) | (0.466) | (0.642) | |
| Asia | 1.985 *** | 1.771 *** | 2.133 *** |
| (0.518) | (0.484) | (0.668) | |
| Europe | 2.237 *** | 1.991 *** | 2.020 *** |
| (0.510) | (0.500) | (0.656) | |
| Middle East | 3.229 *** | 3.084 *** | 3.045 *** |
| (0.544) | (0.533) | (0.707) | |
| Oceania | 1.508 ** | 1.399 ** | 1.832 ** |
| (0.739) | (0.679) | (0.922) | |
| South America | 1.667 *** | 1.453 *** | 1.671 ** |
| (0.533) | (0.515) | (0.684) | |
| Logistic Component | |||
| intercept | - | −2.432 *** | −2.331 *** |
| (0.298) | (0.260) | ||
| corruption | - | −0.695 *** | −0.564 *** |
| (0.204) | (0.212) | ||
| Random Effects | |||
| -intercept | - | - | 0.502 |
| -slope (corruption) | - | - | 0.296 |
| Observations | 298 | 298 | 298 |
| Log-likelihood () | −1547.691 (df = 12) | −1526.838 (df = 14) | −1515.049 (df = 17) |
| Vuong z-Statistic | p-Value | |
|---|---|---|
| Raw | 2.953160 | 0.0015727 |
| AIC-corrected | 2.669934 | 0.0037933 |
| BIC-corrected | 2.146377 | 0.0159215 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fávero, L.P.; Hair, J.F., Jr.; Souza, R.d.F.; Albergaria, M.; Brugni, T.V. Zero-Inflated Generalized Linear Mixed Models: A Better Way to Understand Data Relationships. Mathematics 2021, 9, 1100. https://0-doi-org.brum.beds.ac.uk/10.3390/math9101100
Fávero LP, Hair JF Jr., Souza RdF, Albergaria M, Brugni TV. Zero-Inflated Generalized Linear Mixed Models: A Better Way to Understand Data Relationships. Mathematics. 2021; 9(10):1100. https://0-doi-org.brum.beds.ac.uk/10.3390/math9101100
Chicago/Turabian StyleFávero, Luiz Paulo, Joseph F. Hair, Jr., Rafael de Freitas Souza, Matheus Albergaria, and Talles V. Brugni. 2021. "Zero-Inflated Generalized Linear Mixed Models: A Better Way to Understand Data Relationships" Mathematics 9, no. 10: 1100. https://0-doi-org.brum.beds.ac.uk/10.3390/math9101100