
An Enhanced Evolutionary Software Defect Prediction Method Using Island Moth Flame Optimization


 ,
,  and
and
Abstract
:1. Introduction
2. Related Works
3. Background
3.1. Classification Algorithms
3.1.1. K-Nearest Neighbor Classifier (k-NN)
3.1.2. Support Vector Machines (SVM)
3.1.3. Naive Bayes Classifier (NB)
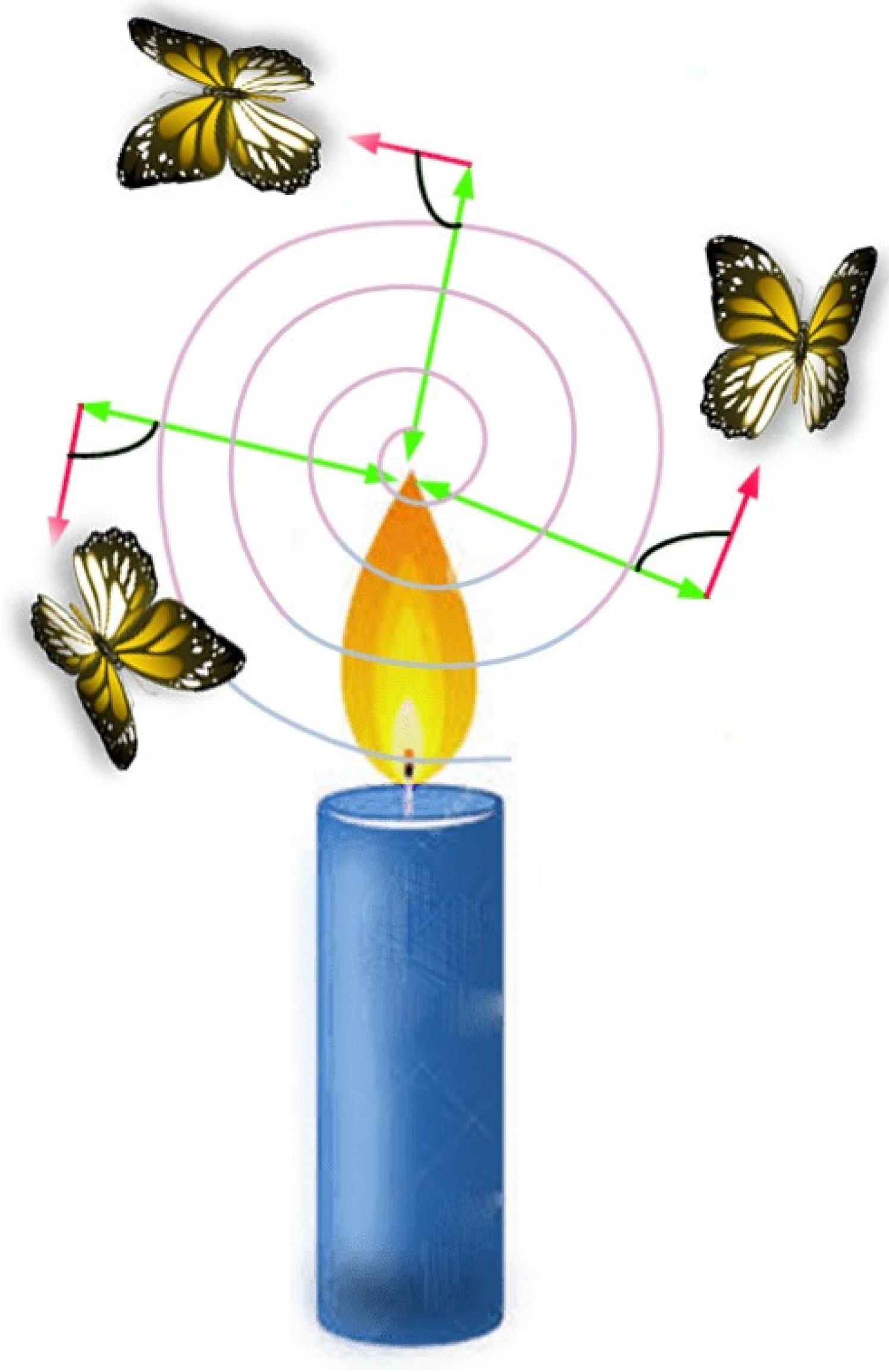
3.2. Overview of Moth Flame Optimization Algorithm
3.3. Binary Moth Flame Optimization for Feature Selection
| Algorithm 1 The pseudo-code of BMFO. |
Input: , n (# moths), d (# dimensions) Output: near optimal moth Initialization process for the moths while
do modify the number of flames using Equation (4) FMo = Fitness(Mo); if == 1 then = ; = ; else = ; = ; end if for i = 1 : n do for j = 1 : d do Modify r and t; Compute by Equation (3) based on the corresponding moth; Modify the step vector of a moth using Equation (5). Compute the probabilities by Equation (6). Modify the position of a moth by Equation (7) end for end for = + 1; end while |
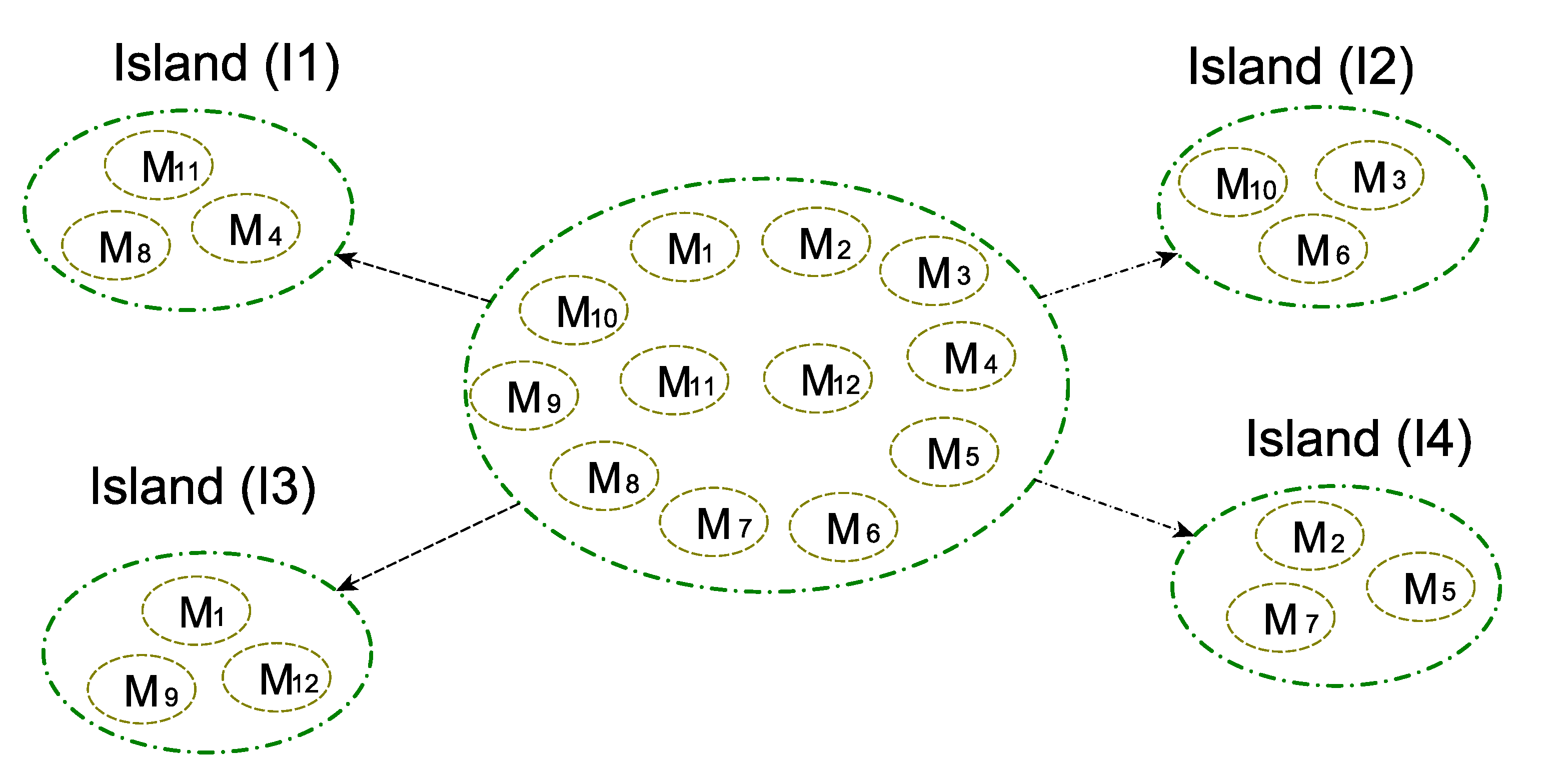
3.4. Fundamentals to Island-Based Model
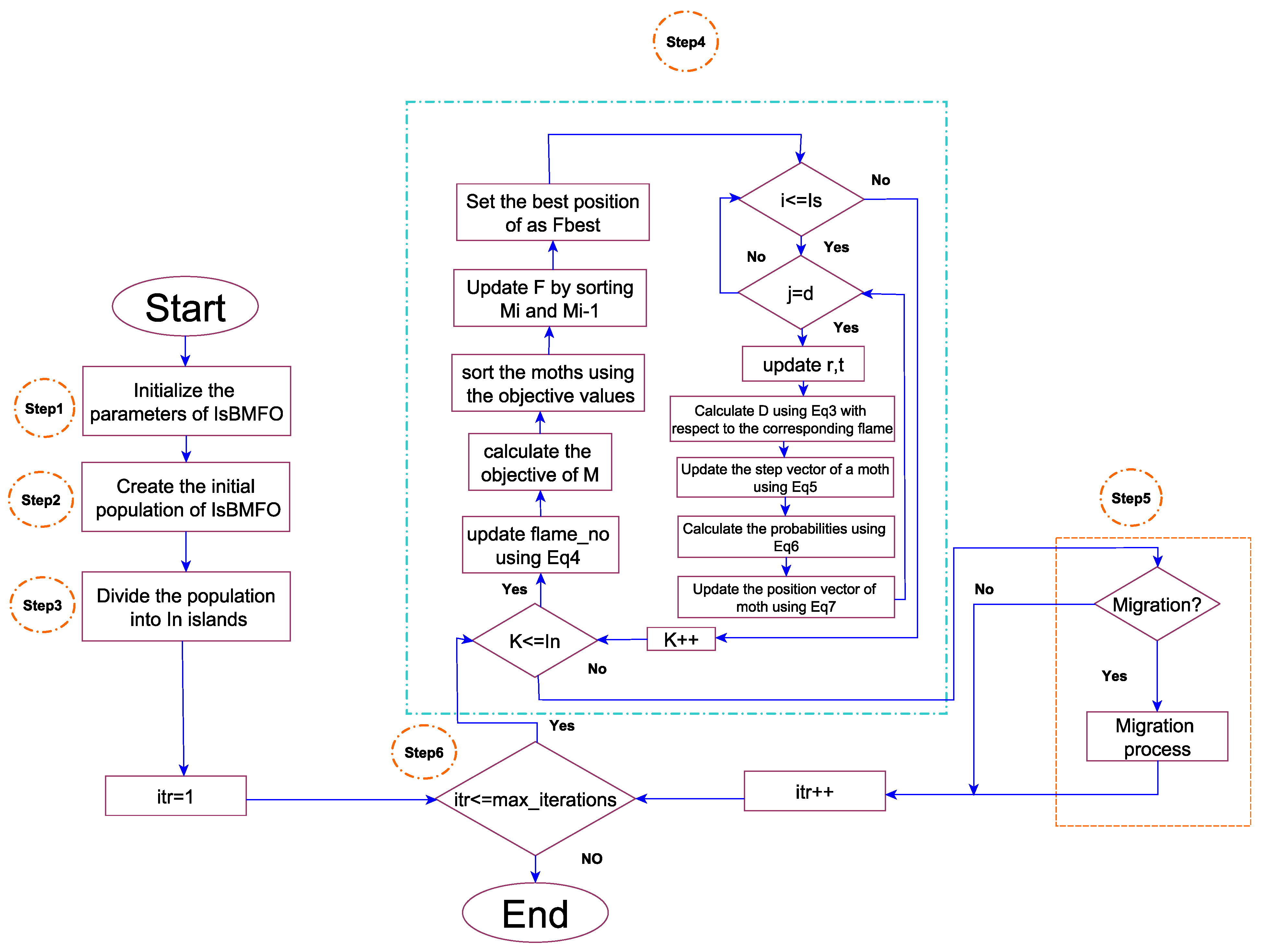
4. Island-Based MFO (IsMFO) Algorithm
| Algorithm 2: The IsBMFO pseudo-code. |
————Identification of the IsBMFO parameters——————— Set the IsBMFO parameters , n, d, , , , ————Initialize the IsBMFO positions——————— Initialize the positions of moths 0: ———Split IsBMFO into a group of islands———————— Flag(y) = False, for K = 1 : do for i = 1 : do select y, where y ∈ (1, 2, …, n) while Flage( y) is true do select y, where y ∈ 1, 2, …, end while Add to island end for end for while
do ——–Improvement step———————— for i = 1 : do Update flame no using Equation (4) FMo = Fitness(Mo); if == 1 then = ; = ; else = ; = ; end if for i = 1 : Is do for j = 1 : d do Modify r and t; Compute by Equation (3) based on the corresponding moth; Modify the step vector of a moth by Equation (5). Compute the probabilities by Equation (6). Modify the position of a moth by Equation (7) end for end for end for ————— Migration of moths———— if t mod = 0 then for , …, do whiledo end while end for end if = + 1 end while |
- Island number (): this determines the number of sub-populations that is less than or equal to n.
- The size of island (): the population size for each island can be computed using the formula since all islands are homogeneous.
- The frequency of migration (): this indicates the required iterations number to call the migration function.
- The rate of migration (): this indicates the number of moths swapped between islands based on , where .
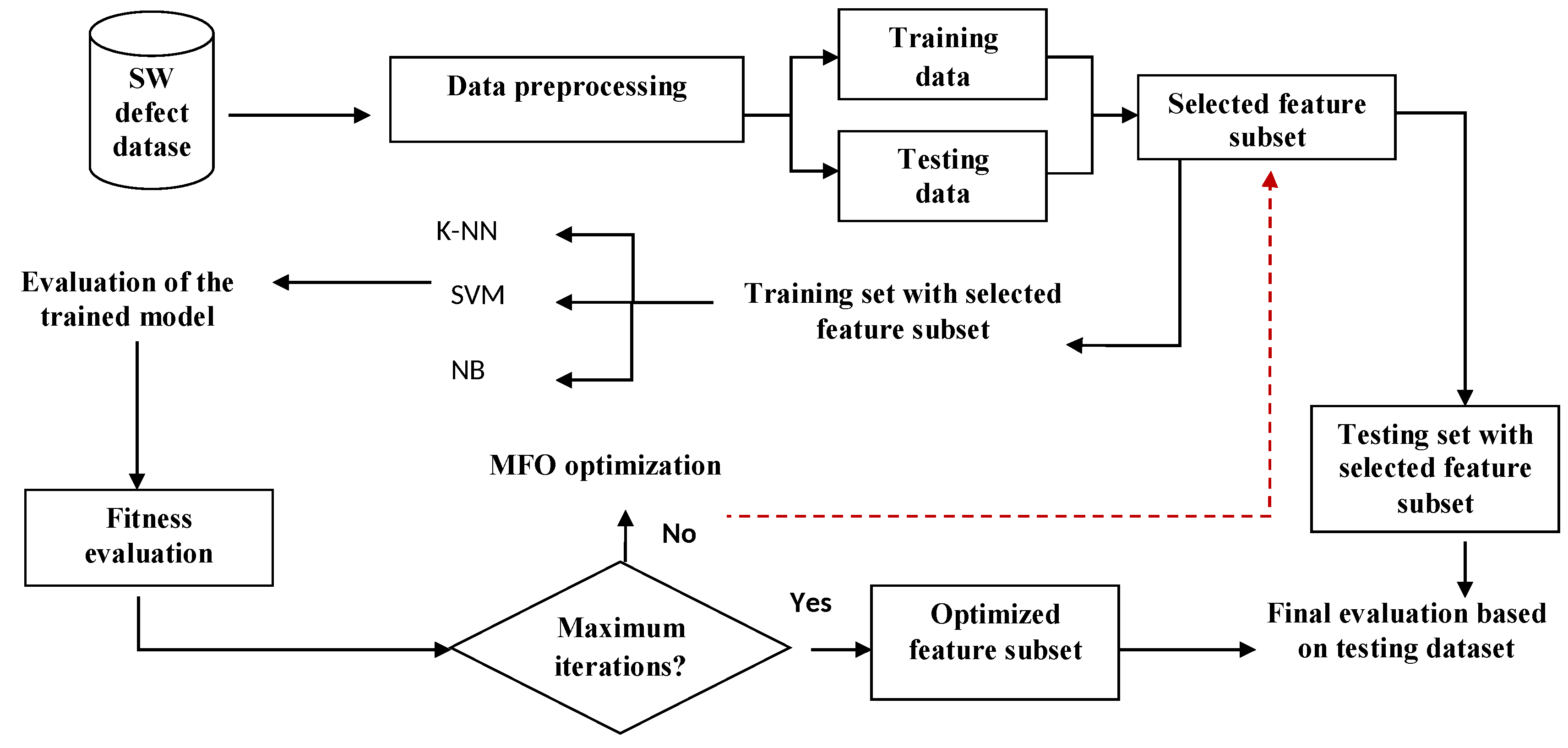
5. Experimental Results
5.1. Model Evaluation Metrics
5.2. Datasets Specifications
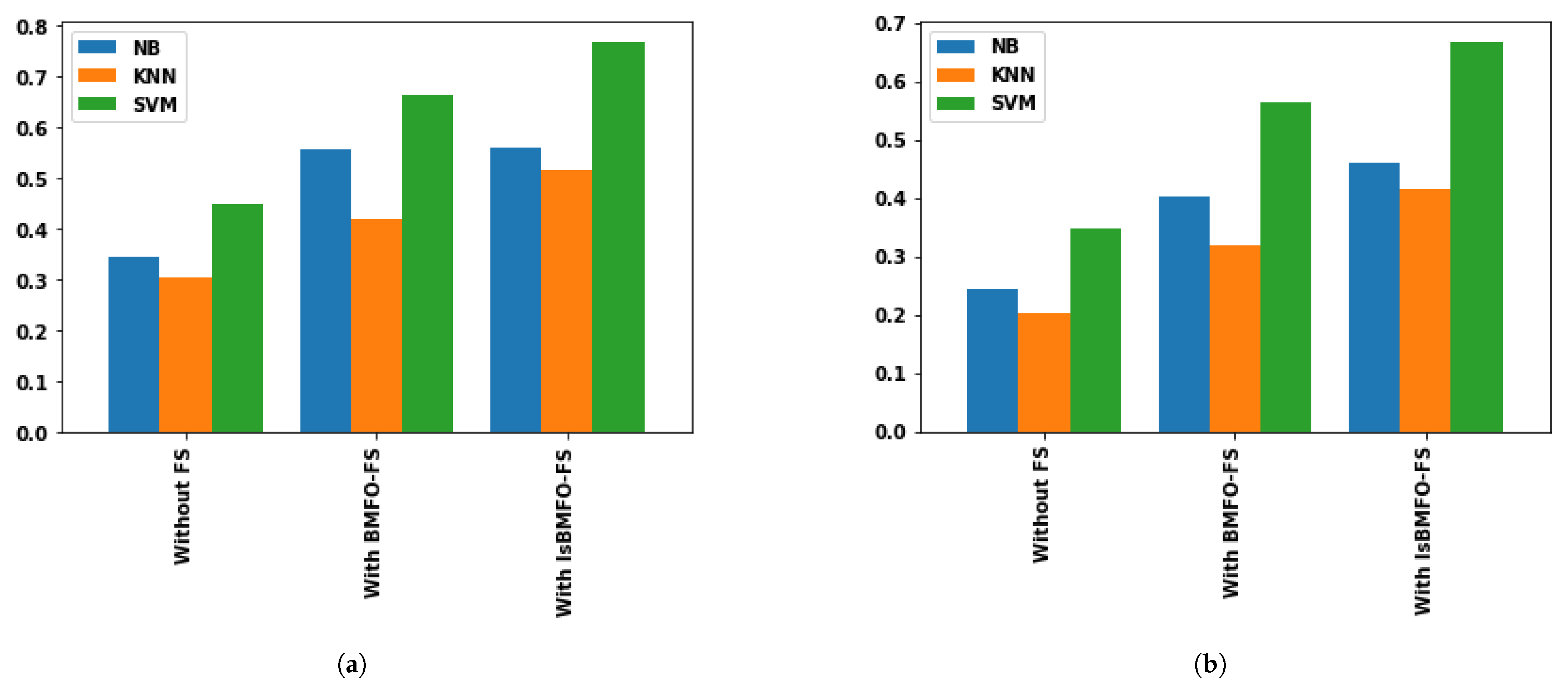
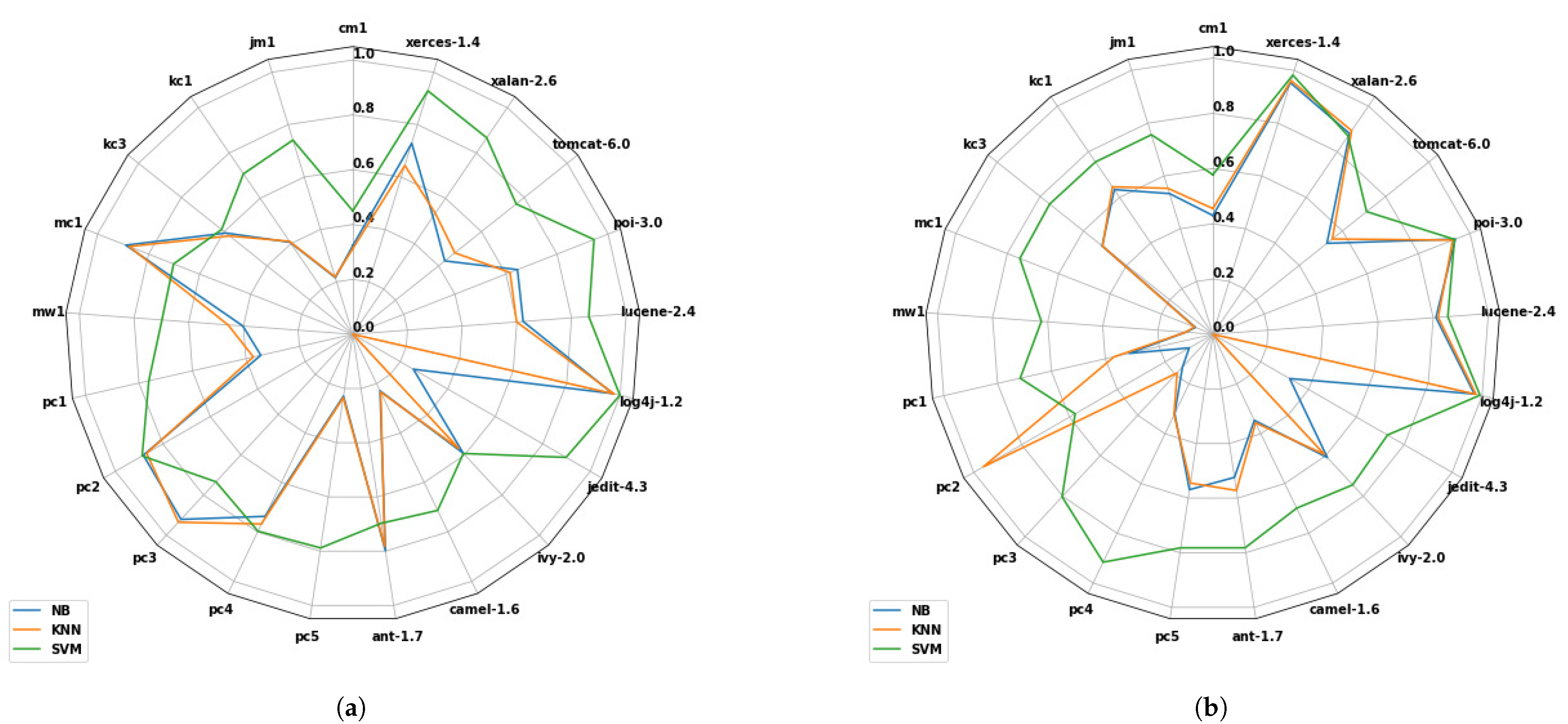
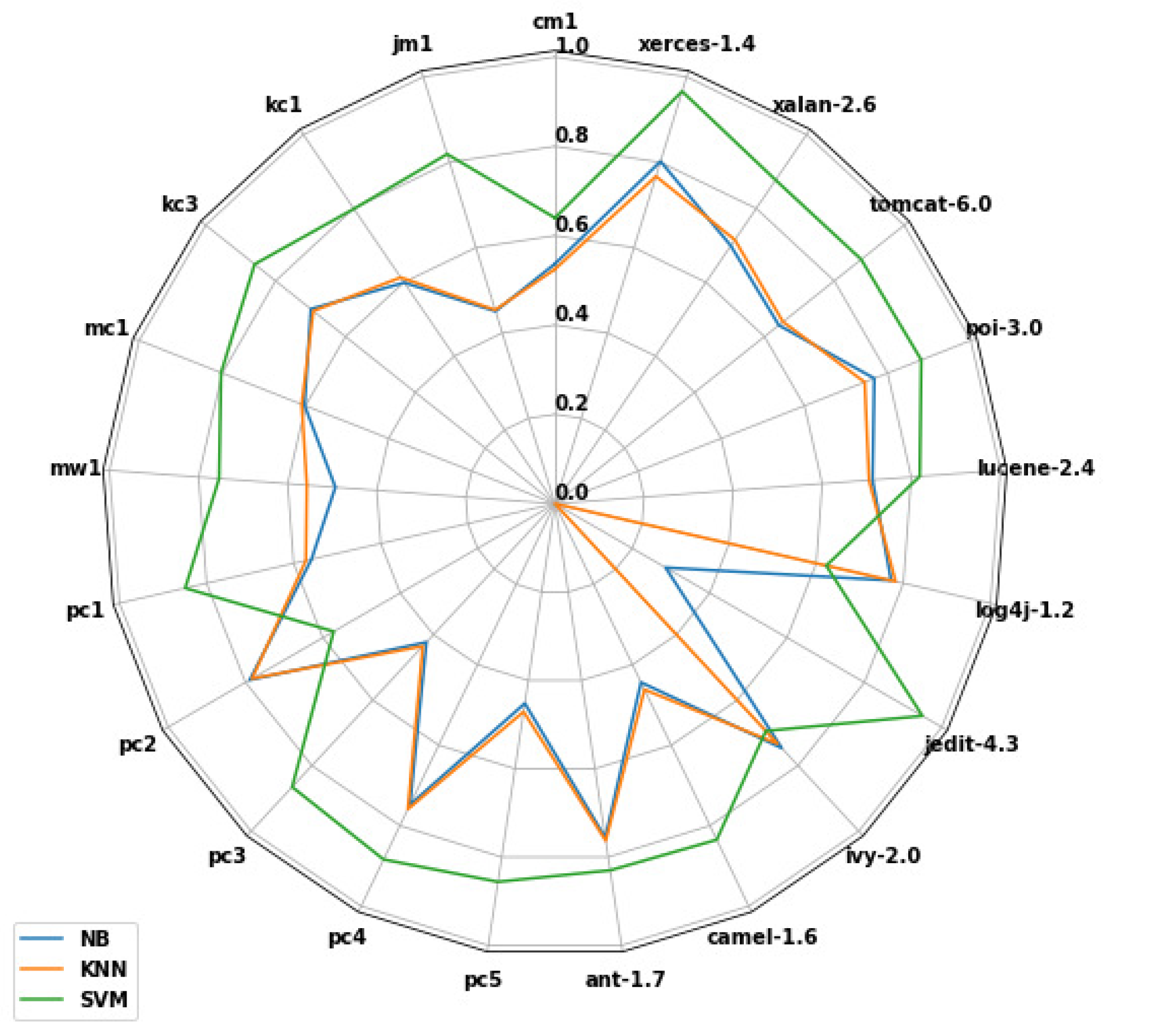
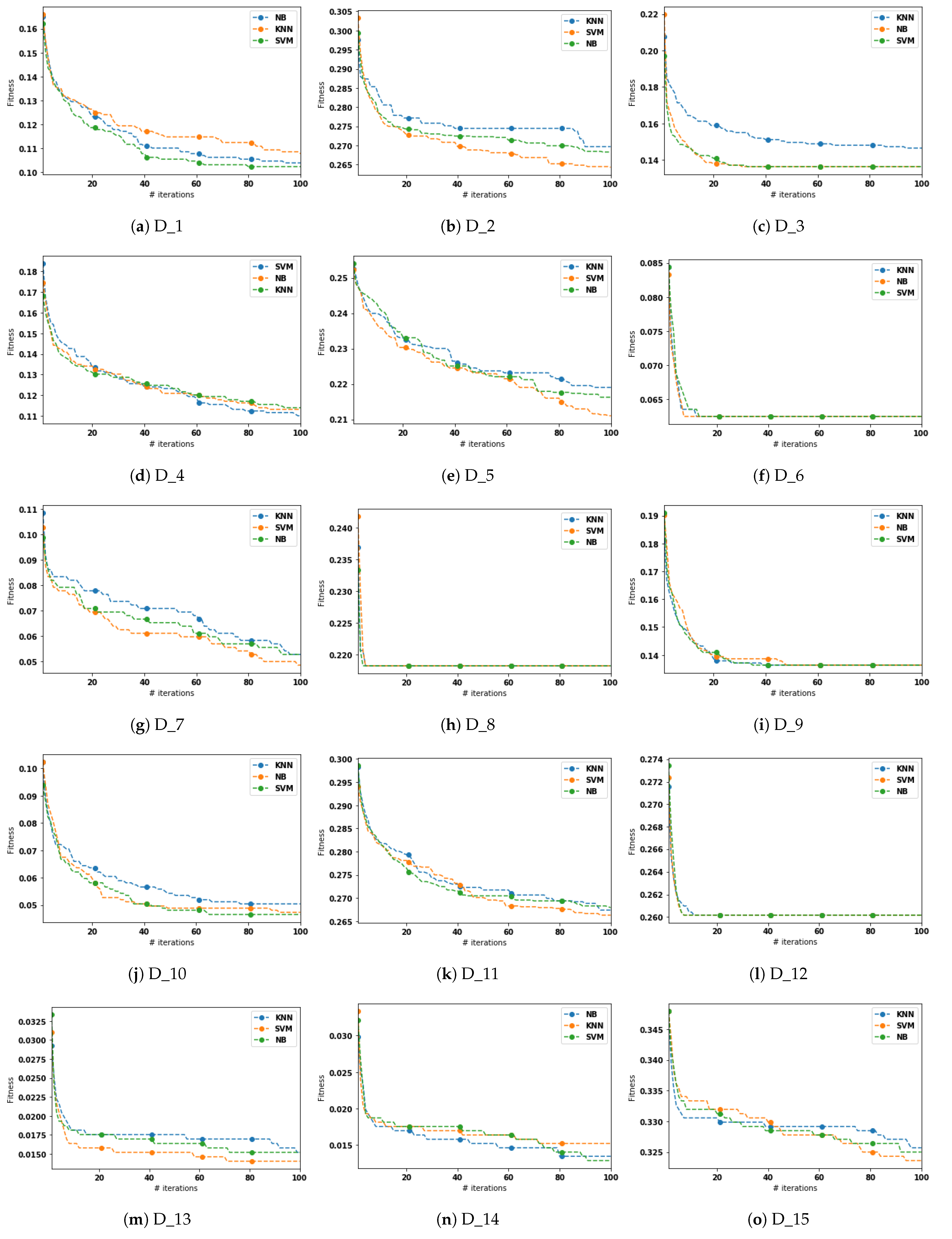
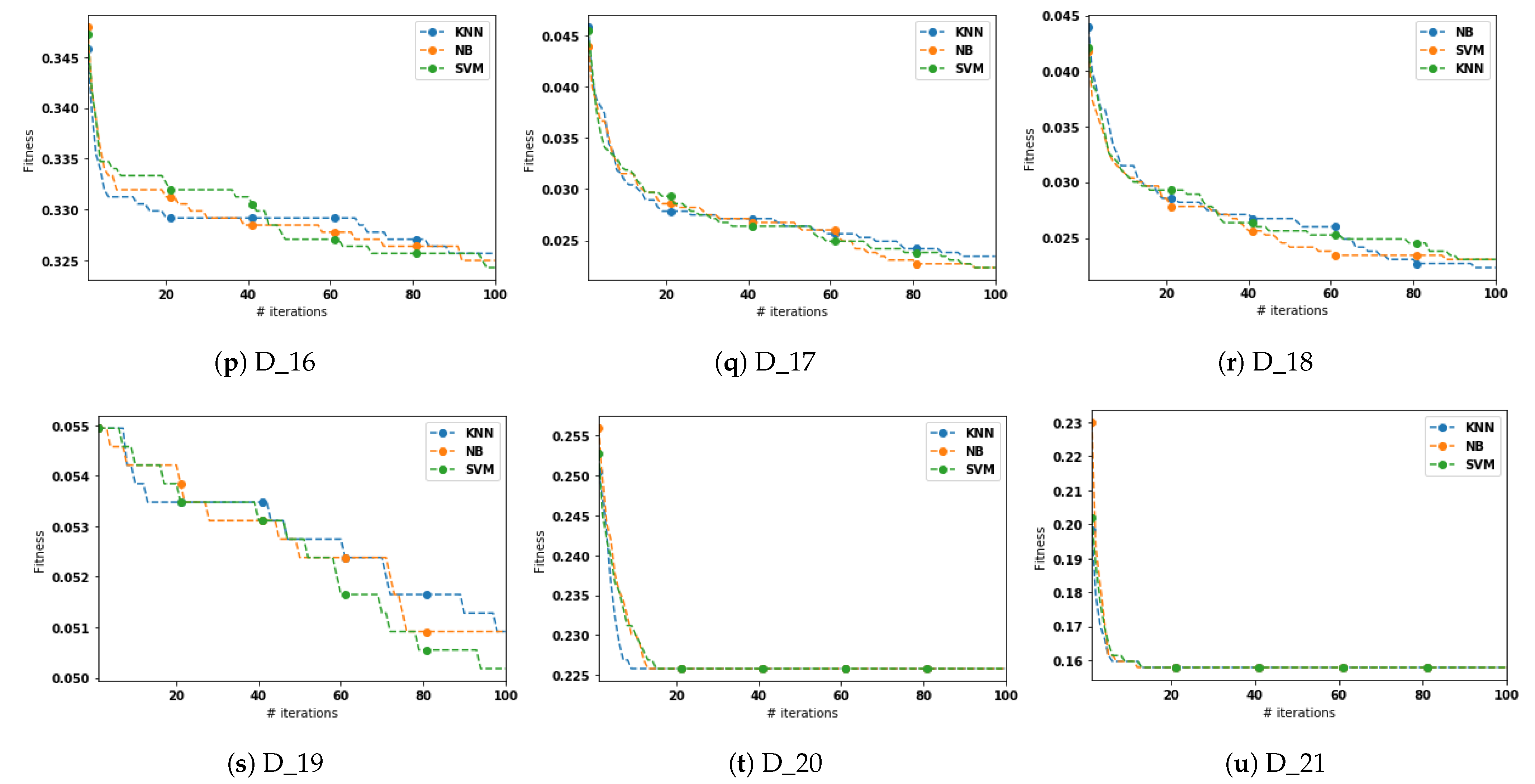
5.3. Results and Discussion
5.4. Analytical Description of the Relevant Features
6. Conclusions and Future Trends
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Levendel, Y. Reliability analysis of large software systems: Defect data modeling. IEEE Trans. Softw. Eng. 1990, 16, 141–152. [Google Scholar] [CrossRef]
- Ehrlich, W.K.; Iannino, A.; Prasanna, B.; Stampfel, J.P.; Wu, J.R. How faults cause software failures: Implications for software reliability engineering. In Proceedings of the 1991 International Symposium on Software Reliability Engineering, Austin, TX, USA, 17–18 May 1991; IEEE Computer Society: Washington, DC, USA, 1991; pp. 233–234. [Google Scholar]
- Laprie, J.C. Dependability of computer systems: Concepts, limits, improvements. In Proceedings of the IEEE Sixth International Symposium on Software Reliability Engineering (ISSRE’95), Toulouse, France, 24–27 October 1995; pp. 2–11. [Google Scholar]
- Mandeville, W.A. Software costs of quality. IEEE J. Sel. Areas Commun. 1990, 8, 315–318. [Google Scholar] [CrossRef]
- Singpurwalla, N.D. Determining an optimal time interval for testing and debugging software. IEEE Trans. Softw. Eng. 1991, 17, 313–319. [Google Scholar] [CrossRef]
- Mens, T.; Tourwé, T. A survey of software refactoring. IEEE Trans. Softw. Eng. 2004, 30, 126–139. [Google Scholar] [CrossRef] [Green Version]
- Alsawalqah, H.; Hijazi, N.; Eshtay, M.; Faris, H.; Radaideh, A.A.; Aljarah, I.; Alshamaileh, Y. Software defect prediction using heterogeneous ensemble classification based on segmented patterns. Appl. Sci. 2020, 10, 1745. [Google Scholar] [CrossRef] [Green Version]
- Wahono, R.S. A systematic literature review of software defect prediction. J. Softw. Eng. 2015, 1, 1–16. [Google Scholar]
- Li, Z.; Jing, X.; Zhu, X. Progress on approaches to software defect prediction. IET Softw. 2018, 12, 161–175. [Google Scholar] [CrossRef]
- Son, L.H.; Pritam, N.; Khari, M.; Kumar, R.; Phuong, P.T.M.; Thong, P.H. Empirical study of software defect prediction: A systematic mapping. Symmetry 2019, 11, 212. [Google Scholar] [CrossRef] [Green Version]
- Shen, Z.; Chen, S. A Survey of Automatic Software Vulnerability Detection, Program Repair, and Defect Prediction Techniques. Secur. Commun. Netw. 2020, 2020, 8858010. [Google Scholar] [CrossRef]
- Li, N.; Shepperd, M.; Guo, Y. A systematic review of unsupervised learning techniques for software defect prediction. Inf. Softw. Technol. 2020, 122, 106287. [Google Scholar] [CrossRef] [Green Version]
- Aljarah, I.; Mafarja, M.; Heidari, A.A.; Faris, H.; Mirjalili, S. Multi-verse optimizer: Theory, literature review, and application in data clustering. In Nature-Inspired Optimizers; Springer: Cham, Switzerland, 2020; pp. 123–141. [Google Scholar]
- Mafarja, M.; Heidari, A.A.; Faris, H.; Mirjalili, S.; Aljarah, I. Dragonfly algorithm: Theory, literature review, and application in feature selection. In Nature-Inspired Optimizers; Springer: Cham, Switzerland, 2020; pp. 47–67. [Google Scholar]
- Singh, P.D.; Chug, A. Software defect prediction analysis using machine learning algorithms. In Proceedings of the 2017 IEEE 7th International Conference on Cloud Computing, Data Science & Engineering-Confluence, Noida, India, 12–13 January 2017; pp. 775–781. [Google Scholar]
- Khurma, R.A.; Aljarah, I.; Sharieh, A. Rank based moth flame optimisation for feature selection in the medical application. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Khurma, R.A.; Aljarah, I.; Sharieh, A. An Efficient Moth Flame Optimization Algorithm using Chaotic Maps for Feature Selection in the Medical Applications. In Proceedings of the 9th International Conference on Pattern Recognition Applications and Methods (ICPRAM), Valletta, Malta, 22–24 February 2020; pp. 175–182. [Google Scholar]
- Faris, H.; Aljarah, I.; Alqatawna, J. Optimizing feedforward neural networks using krill herd algorithm for e-mail spam detection. In Proceedings of the 2015 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Amman, Jordan, 3–5 November 2015; pp. 1–5. [Google Scholar]
- Khurma, R.A.; Aljarah, I.; Sharieh, A. A Simultaneous Moth Flame Optimizer Feature Selection Approach Based on Levy Flight and Selection Operators for Medical Diagnosis. Arab. J. Sci. Eng. 2021, 1–26. [Google Scholar] [CrossRef]
- Agarwal, V.; Bhanot, S. Firefly inspired feature selection for face recognition. In Proceedings of the 2015 IEEE Eighth International Conference on Contemporary Computing (IC3), Noida, India, 20–22 August 2015; pp. 257–262. [Google Scholar]
- Jouhari, H.; Lei, D.; Al-qaness, M.A.A.; Abd Elaziz, M.; Damaševičius, R.; Korytkowski, M.; Ewees, A.A. Modified Harris Hawks optimizer for solving machine scheduling problems. Symmetry 2020, 12, 1460. [Google Scholar] [CrossRef]
- Sahlol, A.T.; Elaziz, M.A.; Jamal, A.T.; Damaševičius, R.; Hassan, O.F. A novel method for detection of tuberculosis in chest radiographs using artificial ecosystem-based optimisation of deep neural network features. Symmetry 2020, 12, 1146. [Google Scholar] [CrossRef]
- Makhadmeh, S.N.; Al-Betar, M.A.; Alyasseri, Z.A.A.; Abasi, A.K.; Khader, A.T.; Damaševičius, R.; Mohammed, M.A.; Abdulkareem, K.H. Smart home battery for the multi-objective power scheduling problem in a smart home using grey wolf optimizer. Electronics 2021, 10, 447. [Google Scholar] [CrossRef]
- Anbu, M.; Mala, G.A. Feature selection using firefly algorithm in software defect prediction. Clust. Comput. 2019, 22, 10925–10934. [Google Scholar] [CrossRef]
- Khurma, R.; Castillo, P.; Sharieh, A.; Aljarah, I. Feature Selection using Binary Moth Flame Optimization with Time Varying Flames Strategies. In Volume 1: ECTA, INSTICC, Proceedings of the 12th International Joint Conference on Computational Intelligence, Budapest, Hungary, 2–4 November 2020; SciTePress: Setúbal, Portugal, 2020; pp. 17–27. [Google Scholar] [CrossRef]
- Hussien, A.G.; Amin, M.; Abd El Aziz, M. A comprehensive review of moth-flame optimisation: Variants, hybrids, and applications. J. Exp. Theor. Artif. Intell. 2020, 32, 705–725. [Google Scholar] [CrossRef]
- Shehab, M.; Abualigah, L.; Al Hamad, H.; Alabool, H.; Alshinwan, M.; Khasawneh, A.M. Moth–flame optimization algorithm: Variants and applications. Neural Comput. Appl. 2020, 32, 9859–9884. [Google Scholar] [CrossRef]
- Kaur, K.; Singh, U.; Salgotra, R. An enhanced moth flame optimization. Neural Comput. Appl. 2020, 32, 2315–2349. [Google Scholar] [CrossRef]
- Khurmaa, R.A.; Aljarah, I.; Sharieh, A. An intelligent feature selection approach based on moth flame optimization for medical diagnosis. Neural Comput. Appl. 2021, 33, 7165–7204. [Google Scholar] [CrossRef]
- Xu, Y.; Chen, H.; Luo, J.; Zhang, Q.; Jiao, S.; Zhang, X. Enhanced Moth-flame optimizer with mutation strategy for global optimization. Inf. Sci. 2019, 492, 181–203. [Google Scholar] [CrossRef]
- Khan, M.A.; Sharif, M.; Akram, T.; Damaševičius, R.; Maskeliūnas, R. Skin lesion segmentation and multiclass classification using deep learning features and improved moth flame optimization. Diagnostics 2021, 11, 811. [Google Scholar] [CrossRef]
- Al-Betar, M.A.; Awadallah, M.A. Island bat algorithm for optimization. Expert Syst. Appl. 2018, 107, 126–145. [Google Scholar] [CrossRef]
- Al-Betar, M.A.; Awadallah, M.A.; Doush, I.A.; Hammouri, A.I.; Mafarja, M.; Alyasseri, Z.A.A. Island flower pollination algorithm for global optimization. J. Supercomput. 2019, 75, 5280–5323. [Google Scholar] [CrossRef]
- Al-Betar, M.A.; Awadallah, M.A.; Khader, A.T.; Abdalkareem, Z.A. Island-based harmony search for optimization problems. Expert Syst. Appl. 2015, 42, 2026–2035. [Google Scholar] [CrossRef]
- Awadallah, M.A.; Al-Betar, M.A.; Bolaji, A.L.; Doush, I.A.; Hammouri, A.I.; Mafarja, M. Island artificial bee colony for global optimization. Soft Comput. 2020, 24, 13461–13487. [Google Scholar] [CrossRef]
- Gupta, A.; Suri, B.; Kumar, V.; Misra, S.; Blažauskas, T.; Damaševičius, R. Software code smell prediction model using Shannon, Rényi and Tsallis entropies. Entropy 2018, 20, 372. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumari, M.; Misra, A.; Misra, S.; Sanz, L.F.; Damasevicius, R.; Singh, V.B. Quantitative quality evaluation of software products by considering summary and comments entropy of a reported bug. Entropy 2019, 21, 91. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naidu, M.S.; Geethanjali, N. Classification of defects in software using decision tree algorithm. Int. J. Eng. Sci. Technol. 2013, 5, 1332–1340. [Google Scholar]
- Can, H.; Xing, J.; Zhu, R.; Li, J.; Yang, Q.; Xie, L. A new model for software defect prediction using particle swarm optimization and support vector machine. In Proceedings of the 2013 IEEE 25th Chinese Control and Decision Conference (CCDC), Guiyang, China, 25–27 May 2013; pp. 4106–4110. [Google Scholar]
- Shuai, B.; Li, H.; Li, M.; Zhang, Q.; Tang, C. Software defect prediction using dynamic support vector machine. In Proceedings of the 2013 IEEE Ninth International Conference on Computational Intelligence and Security, Emeishan, China, 14–15 December 2013; pp. 260–263. [Google Scholar]
- Agarwal, S.; Tomar, D. A feature selection based model for software defect prediction. Int. J. Adv. Sci. Technol. 2014, 65, 39–58. [Google Scholar] [CrossRef]
- Abaei, G.; Selamat, A. A survey on software fault detection based on different prediction approaches. Viet. J. Comput. Sci. 2014, 1, 79–95. [Google Scholar] [CrossRef]
- Malhotra, R.; Nishant, N.; Gurha, S.; Rathi, V. Application of Particle Swarm Optimization for Software Defect Prediction Using Object Oriented Metrics. In Proceedings of the 2021 IEEE 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 88–93. [Google Scholar]
- Balogun, A.O.; Basri, S.; Mahamad, S.; Abdulkadir, S.J.; Capretz, L.F.; Imam, A.A.; Almomani, M.A.; Adeyemo, V.E.; Kumar, G. Empirical Analysis of Rank Aggregation-Based Multi-Filter Feature Selection Methods in Software Defect Prediction. Electronics 2021, 10, 179. [Google Scholar] [CrossRef]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar]
- Kushida, J.i.; Hara, A.; Takahama, T.; Kido, A. Island-based differential evolution with varying subpopulation size. In Proceedings of the 2013 IEEE 6th International Workshop on Computational Intelligence and Applications (IWCIA), Hiroshima, Japan, 13 July 2013; pp. 119–124. [Google Scholar]
- Michel, R.; Middendorf, M. An island model based ant system with lookahead for the shortest supersequence problem. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Amsterdam, The Netherlands, 27–30 September 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 692–701. [Google Scholar]
- Araujo, L.; Merelo, J.J. Diversity through multiculturality: Assessing migrant choice policies in an island model. IEEE Trans. Evol. Comput. 2010, 15, 456–469. [Google Scholar] [CrossRef]
- Khurma, R.A.; Aljarah, I.; Sharieh, A.; Mirjalili, S. Evolopy-fs: An open-source nature-inspired optimization framework in python for feature selection. In Evolutionary Machine Learning Techniques; Springer: Singapore, 2020; pp. 131–173. [Google Scholar]
- Khurma, R.A.; Sabri, K.E.; Castillo, P.A.; Aljarah, I. Salp Swarm Optimization Search Based Feature Selection for Enhanced Phishing Websites Detection. In Proceedings of the Applications of Evolutionary Computation: 24th International Conference, EvoApplications 2021, Held as Part of EvoStar 2021, Virtual Event, 7–9 April 2021; Springer Nature: Basingstoke, UK, 2021; Volume 12694, pp. 146–161. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual Labels | |||
|---|---|---|---|
| Predicted labels | Defect | Non-Defect | |
| Defect | TruePos | FalsePos | |
| Non-defect | FalseNeg | TrueNeg | |
| No. | Name | Features | Instances | Defects | Non-Defects | Defect Ratio | Non-Defect Ratio |
|---|---|---|---|---|---|---|---|
| D_1 | cm1 | 38 | 327 | 42 | 285 | 12.8 | 87.2 |
| D_2 | jm1 | 22 | 7782 | 1672 | 6110 | 21.5 | 78.5 |
| D_3 | kc1 | 22 | 1183 | 314 | 869 | 26.5 | 73.5 |
| D_4 | kc3 | 40 | 194 | 36 | 158 | 18.6 | 81.4 |
| D_5 | mc1 | 39 | 1988 | 46 | 1942 | 2.3 | 97.7 |
| D_6 | mw1 | 38 | 253 | 27 | 226 | 10.7 | 89.3 |
| D_7 | pc1 | 38 | 705 | 61 | 644 | 8.7 | 91.3 |
| D_8 | pc2 | 37 | 745 | 16 | 729 | 2.1 | 97.9 |
| D_9 | pc3 | 38 | 1077 | 134 | 943 | 12.4 | 87.6 |
| D_10 | pc4 | 38 | 1287 | 177 | 1110 | 13.8 | 86.2 |
| D_11 | pc5 | 39 | 1711 | 471 | 1240 | 27.5 | 72.5 |
| D_12 | ant-1.7 | 21 | 745 | 166 | 579 | 22.3 | 77.7 |
| D_13 | camel-1.6 | 21 | 965 | 188 | 777 | 19.5 | 80.5 |
| D_14 | ivy-2.0 | 21 | 352 | 40 | 312 | 11.4 | 88.6 |
| D_15 | jedit-4.3 | 21 | 492 | 11 | 481 | 2.2 | 97.8 |
| D_16 | log4j-1.2 | 21 | 205 | 189 | 16 | 92.2 | 7.8 |
| D_17 | lucene-2.4 | 21 | 340 | 203 | 137 | 59.7 | 40.3 |
| D_18 | poi-3.0 | 21 | 442 | 281 | 161 | 63.6 | 36.4 |
| D_19 | tomcat-6 | 20 | 858 | 77 | 781 | 9 | 91 |
| D_20 | xalan-2.6 | 21 | 885 | 411 | 474 | 46.4 | 53.6 |
| D_21 | xerces-1.4 | 21 | 588 | 437 | 151 | 74.3 | 25.7 |
| Datasets | IsBMFO-KNN | IsBMFO-NB |
|---|---|---|
| D_1 | 2.44 | 1.56 |
| D_2 | 4.31 | 2.24 |
| D_3 | 1.21 | 1.37 |
| D_4 | 1.28 | 1.61 |
| D_5 | 1.31 | 1.81 |
| D_6 | 1.23 | 1.62 |
| D_7 | 2.38 | 1.30 |
| D_8 | 2.46 | 2.23 |
| D_9 | 4.52 | 5.14 |
| D_10 | 4.95 | 2.25 |
| D_11 | 3.14 | 3.56 |
| D_12 | 6.63 | 9.22 |
| D_13 | 9.41 | 5.56 |
| D_14 | 1.78 | 1.12 |
| D_15 | 2.32 | 2.35 |
| D_16 | 2.23 | 3.25 |
| D_17 | 5.18 | 2.12 |
| D_18 | 4.13 | 3.82 |
| D_19 | 3.66 | 8.4 |
| D_20 | 2.61 | 3.13 |
| D_21 | 2.65 | 2.14 |
| Datasets | AF | SF | FFR% | RF |
|---|---|---|---|---|
| cm1 | 38 | 15 | 61% | F2, F3, F7, F9, F11, F14, F17, F19, F23, F25, F26, F32, F33, F36, F38 |
| jm1 | 22 | 9 | 59% | F1, F2, F4, F6, F7, F11, F13, F16, F19 |
| kc1 | 22 | 8 | 64% | F3, F7, F9, F10, F14, F15, F18, F21 |
| kc3 | 40 | 16 | 60% | F2, F4, F7, F8, F9, F11, F17, F19, F23, F26, F28, F31, F33, F35, F39, F40 |
| mc1 | 39 | 12 | 69% | F3, F7, F8, F12, F13, F15, F20, F24, F28, F29, F32, F38 |
| mw1 | 38 | 13 | 66% | F1, F5, F9, F11, F14, F16, F19, F20, F22, F25, F27, F30, F31 |
| pc1 | 38 | 10 | 74% | F1, F6, F13, F15, F17, F21, F24, F27, F29, F35 |
| pc2 | 37 | 14 | 62% | F1, F3, F4, F8, F13, F14, F17, F25, F27, F29, F30, F34, F36, F37 |
| pc3 | 38 | 11 | 71% | F2, F3, F6, F9, F17, F20, F22, F26, F31, F34, F37 |
| pc4 | 38 | 11 | 71% | F1, F5, F8, F9, F14, F22, F23, F26, F31, F35, F38 |
| pc5 | 39 | 12 | 69% | F2, F4, F8, F10, F12, F15, F19, F25, F29, F30, F32, F37 |
| ant-1.7 | 21 | 7 | 67% | F1, F5, F7, F10, F16, F19, F21 |
| camel-1.6 | 21 | 9 | 57% | F2, F5, F6, F9, F11, F12, F14, F17, F20 |
| ivy-2.0 | 21 | 10 | 52% | F3, F7, F10, F11, F13, F15, F16, F19, F20, F21 |
| jedit-4.3 | 21 | 11 | 48% | F1, F4, F5, F7, F9, F13, F14, F15, F18, F20, F21 |
| log4j-1.2 | 21 | 8 | 62% | F6, F9, F10, F13, F15, F17, F20, F21 |
| lucene-2.4 | 21 | 9 | 57% | F2, F4, F7, F10, F11, F15, F18, F19, F21 |
| poi-3.0 | 21 | 11 | 48% | F2, F5, F7, F8, F9, F10, F11, F14, F17, F19, F21 |
| tomcat-6 | 20 | 7 | 65% | F4, F5, F8, F11, F13, F19, F20 |
| xalan-2.6 | 21 | 8 | 62% | F1, F3, F6, F10, F11, F12, F19, F20 |
| xerces-1.4 | 21 | 10 | 52% | F1, F4, F6, F7, F8, F11, F14, F16, F20, F21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khurma, R.A.; Alsawalqah, H.; Aljarah, I.; Elaziz, M.A.; Damaševičius, R. An Enhanced Evolutionary Software Defect Prediction Method Using Island Moth Flame Optimization. Mathematics 2021, 9, 1722. https://0-doi-org.brum.beds.ac.uk/10.3390/math9151722
Khurma RA, Alsawalqah H, Aljarah I, Elaziz MA, Damaševičius R. An Enhanced Evolutionary Software Defect Prediction Method Using Island Moth Flame Optimization. Mathematics. 2021; 9(15):1722. https://0-doi-org.brum.beds.ac.uk/10.3390/math9151722
Chicago/Turabian StyleKhurma, Ruba Abu, Hamad Alsawalqah, Ibrahim Aljarah, Mohamed Abd Elaziz, and Robertas Damaševičius. 2021. "An Enhanced Evolutionary Software Defect Prediction Method Using Island Moth Flame Optimization" Mathematics 9, no. 15: 1722. https://0-doi-org.brum.beds.ac.uk/10.3390/math9151722