
Application of EM Algorithm to NHPP-Based Software Reliability Assessment with Generalized Failure Count Data


Graduate School of Advanced Science and Engineering, Hiroshima University, 1-4-1 Kagamiyama, Higashi-Hiroshima 7398527, Japan
*
Author to whom correspondence should be addressed.
Mathematics 2021, 9(9), 985; https://0-doi-org.brum.beds.ac.uk/10.3390/math9090985
Submission received: 15 March 2021
/
Revised: 23 April 2021
/
Accepted: 26 April 2021
/
Published: 27 April 2021
(This article belongs to the Special Issue Mathematics in Software Reliability and Quality Assurance)
Abstract
:Software reliability models (SRMs) are widely used for quantitative evaluation of software reliability by estimating model parameters from failure data observed in the testing phase. In particular, non-homogeneous Poisson process (NHPP)-based SRMs are the most popular because of their mathematical tractability. In this paper, we focus on the parameter estimation algorithm for NHPP-based SRMs and discuss the EM algorithm for generalized fault count data. The presented algorithm can be applied for failure time data, failure count data, and their mixture. The paper derives the EM-step formulas for basic 12 NHPP-based SRMs and demonstrate a numerical experiment to present the convergence property of our algorithms. The developed algorithms are suitable for an automatic tool for software reliability evaluation.
1. Introduction
Software reliability models (SRMs) are used to assess quantitative reliability and to control the quality of software products. Since Jelinski and Moranda [1], and Goel and Okumoto [2] presented SRMs based on stochastic processes, numerous SRMs have been proposed [3,4,5,6,7,8]. In particular, non-homogeneous Poisson process (NHPP)-based SRMs have become popular in representing the dynamics of failure occurrence processes in a variety of situations [9,10,11,12,13]. By using an NHPP-based SRM, we predict the future behavior of software failure, i.e, the number of failures experienced in future, and estimate the quantitative measure of software reliability.
The advantage of NHPP-based SRMs is simplifying the stochastic analysis. NHPPs are generally dominated by mean value functions. The mean value function indicates the expected number of failures experienced at arbitrary testing time. By choosing appropriate mean value functions, NHPP-based SRMs can fit any observed failure data. The NHPP-based SRMs and the mean value functions have a one-to-one correspondence.
The Goel–Okumoto model [2]; Goel model [2]; Musa–Okumoto model [14]; Ohba [15,16]; Yamada, Ohba, and Osaki model [17]; Zhao and Xie model [18] are early NHPP-based SRMs. They were constructed with the deterministic debugging scenarios of mean value functions. Pham [19] solved a generalized differential equation by which the mean value function in the NHPP-based SRM is governed and proposed a generalized SRM with many redundant parameters.
Apart from such a deterministic modeling framework, almost all NHPP-based SRMs can be characterized as Markov processes. Shantikumar [20] discussed a modeling framework to integrate time-homogeneous Markov processes and NHPPs by using a binomial-type stochastic point process. Langberg and Singpurwalla [21] presented a unified modeling framework for almost all NHPP-based SRMs. Chen and Singpurwalla [22] also discussed the framework with a self-exciting point process. Miller [23] introduced the concept of exponential order statistics and drastically extended Langberg and Singpurwalla’s idea. In fact, the realizations of NHPP-based SRM can be described by either the general order statistics or record value statistics of the underlying software fault data, where the fault-detection times are assumed to be independent and identically distributed (i.i.d.) random variables. Specifically, the general order statistics are based on the order of all the fault detection times, and the record value statistics focus on their maximum detection time.
In this paper, we focus on the parameter estimation problem of NHPP-based SRMs. In general, there are three steps to evaluating the software reliability with NHPP-based SRM. (i) Collect the failure data such as the number of detected bugs in the testing phase, (ii) estimate the model parameters of NHPP-based SRM to fit it to the collected data, and (iii) compute reliability measures from the NHPP-based SRM with the estimated parameters. Based on quantitative measures, we control the software development process. As a typical usage of NHPP-based SRM, we estimate the number of failures that will be experienced in the future and decide whether to continue testing the software or the software can be released. In other words, the parameter estimation of NHPP-based SRM is frequently executed in the software development phase. The computation cost of the estimation should be small in practice.
Therefore, many authors have concerns about the parameter estimation problem on NHPP-based SRMs. Nevertheless, in actual software reliability assessments, a few NHPP-based SRMs and familiar maximum likelihood (ML) estimation methods are still used conventionally. The main reason for this is that the practitioners wish to use intuitively simple statistical methods, which exclude empirically based tuning parameters for a few SRMs that have survived a long history of software reliability engineering. In fact, the Bayesian estimation methods are still minor in software engineering practice, although its theoretical benefit is recognized. On the other hand, ML estimation is based on the maximization of likelihood function with software failure data and possesses several rational properties such as asymptotic efficiency. Hossain and Dahiya [24] derived necessary and sufficient conditions that the maximum likelihood estimates (MLEs), which satisfy the non-linear likelihood equations, exist in Goel and Okumoto SRM [2]. Knafl and Morgan [25] presented a method to systematically solve the likelihood equations with two model parameters. Joe [26] also discussed the confidence interval of MLEs. Zhao and Xie [18] provided the MLEs for an extended Goel and Okumoto SRM. Jeske and Pham [27] discovered empirically that the MLEs in Goel and Okumoto SRM are not statistically consistent. It should be noted, however, that ML estimation is always possible for all NHPP-based SRMs. Even if the likelihood functions are strictly concave in model parameters, it is difficult to solve the likelihood equations analytically. For instance, in the cases where the likelihood functions are not concave and where there exists no solution for the likelihood equations inside the parameter space, the conventional methods to calculate the MLEs cannot be used. Usually, the Newton method and the Nelder–Mead method are used to solve the maximization problem in the existing literature. From the recent development of computational ability, it is becoming easier to handle a large-scale complex optimization problem.
On the other hand, it is known that the local convergence property of the Newton method is a weakness for practical application. The local convergence property means that the convergence radius of algorithm is limited, and thus, it may fail to obtain a result if we set unsuitable initial guesses. For example, when we develop the application to automatically obtain parameter estimates from given data, the local convergence property becomes troublesome when choosing the initial guesses. Therefore, the Newton method is not suitable for this purpose. Additionally, the Nelder–Mead method is one of the direct search methods. The convergence property of the Nelder–Mead method is improved from the Newton method. However, some design parameters should be provided appropriately for the Nelder–Mead method. Even if we use the Nelder–Mead algorithm, the convergence of algorithm is not always guaranteed for any given data.
From the early 2000s, our research group has developed an alternative parameter estimation algorithm based on the EM (expectation maximization) principle [28,29] and applied it to the software reliability assessment based on NHPP-based SRMs [30,31,32,33,34,35,36,37,38,39,40]. As another examples of EM algorithms in SRMs, Kimura and Yamada [41], Leadoux [42], and Okamura and Dohi [43] attempted to use EM algorithms to estimate the imperfect debugging model [44] and architecture-based SRMs [45,46]. Their models were based on the continuous-time Markov chain and are closely related to Markov-modulated Poisson processes and/or Markovian arrival processes. Additionally, Zeephongsekul et al. [47] and Nagaraju et al. [48] proposed ECM (expectaton conditional maximization) algorithms for NHPP-based SRMs to handle several specific models.
The EM algorithm is an algorithm that finds maximum likelihood estimates for a statistical model with incomplete data. The idea behind our EM algorithms is to find the incomplete data structure of NHPP-based SRMs. Concretely, in NHPP-based SRMs, we assume that the number of failures is finite due to a finite number of software bugs, but all of them cannot be observed, i.e., the number of reaming software failures can be regarded as missing data. From this insight, the EM algorithm for an individual NHPP-based SRM is developed. Although the convergence speed of EM algorithm is generally slower than other general-purpose numerical methods such as the Newton method, it has a global convergence property. This property allows us to reduce efforts in choosing good initial guesses for the model parameters and is suitable for automating the estimation procedure. In our past work [49], we summarized EM algorithms for 12 NHPP-based SRMs when the failure data were time data. The failure time data consisted of a set of exact failure times experienced. In practice, it is difficult to obtain exact failure times. Generally, we record failure count data consisting of the number of failures experienced for time intervals. For example, it is reasonable to record the number of failures per working day. From this reason, this paper presents the EM algorithms for 12 basic NHPP-based SRMs when the failure count data are given. In particular, we consider the generalized failure count data that involve both failure time and count data formats, and thus, the developed EM algorithms can be applied to either failure time data, failure count data, or their mixture.
We highlight our contributions here: (i) we derive the EM-step formula for NHPP-based SRMs with a finite number of failures under generalized fault count data, (ii) we derive concrete EM-step formulas for 12 basic NHPP-based SRMs, and (iii) we demonstrate the performance on the convergence property of the presented algorithms with real software failure data. To our best knowledge, this is the first paper that presents the EM algorithm for the generalized fault count data in 12 basic NHPP-based SRMs.
This paper is organized as follows. In Section 2, we introduce NHPP-based SRMs that are considered in this paper. In particular, NHPP-based SRMs are classified by failure time distribution and present the relationship between basic 12 NHPP-based SRMs and their failure time distributions. In Section 3, we derive the EM-step formulas for 12 basic NHPP-based SRMs. Section 4 is devoted to a numerical example to compare the convergence properties of EM algorithm, the Nelder–Mead method, and the quasi-Newton method. Finally, we conclude the paper with remarks in Section 5.
2. NHPP-Based SRMs
2.1. Model Description
Let denote the number of software failures experienced before time t. We make the following model assumptions [21]:
- Assumption A: A software failure occurs at a random time. The probability distribution of all failure times are identical and mutually independent.
- Assumption B: The number of inherent software faults causing failures is finite.
Here, and N are the cumulative distribution function of the failure time and the number of inherent faults. Then, the probability mass function of the cumulative number of failures experienced by time t is
where . This is often called the framework of generalized order statistics [21]. For instance, when the failure distribution is an exponential distribution, the corresponding SRM, the so-called exponential order statistics model, is the same as the Jelinski–Moranda SRM [1].
Most NHPP-based SRMs are advanced models of the generalized order statistics models. We make an additional model assumption [21]:
- Assumption C: The number of inherent faults is unknown, but prior information is given by a Poisson distribution.
When the expected number of inherent faults is , the cumulative number of software failures at time t has the following probability mass function:
Equation (2) is equivalent to the probability mass function of NHPP with mean value function . In this modeling framework, the failure time distribution specifies an NHPP-based SRM.
Since the NHPP-based SRM is characterized by the failure time distribution, there have been a number of NHPP-based SRMs that change the failure time distribution. In this paper, we propose basic NHPP-based SRMs using well-known statistical distributions as the failure time distribution. Table 1 shows 11 basic NHPP-based SRMs and their failure time distributions. In the table, most of the basic NHPP-based SRMs correspond to the existing traditional NHPP-based SRMs. ‘exp’ is the so-called Goel and Okumoto model [2], ‘gamma’ is a generalized delayed S-shaped model [17,18], ‘pareto‘ is a modified Duane model [50], ‘tlogis‘ is an inflection S-shaped model [15], and ‘lxvmin‘ is the Goel (Weibull) model [51].
2.2. Parameter Estimation
As mentioned before, the model parameters of NHPP-based SRMs should be estimated from software failure data to predict the future tendency of a software failure. The most commonly used technique for parameter estimation is maximum likelihood (ML) estimation. In the context of ML estimation, we found model parameters that maximize the log-likelihood function (LLF). Since the LLF depends on the failure data experienced, the ML estimation of NHPP-based SRMs has been discussed for two types of data: failure time data and count data. The failure time data is a set of exact times in which a software failure occurs in the testing phase. The count data, equivalently called grouped data, consists of the number of failures experienced for time intervals. The estimation problems for these two data structures have been discussed separately.
This paper deals with a generalized data structure to express both failure time and count data. Our data structure is , where failures that occur at the ith time interval, . In addition, if , an additional failure occurs at the end of the ith time interval, i.e, at time . Otherwise, if , no failure occurs at the instant. If for all time intervals, the data turns out the failure count data. If and for all i, is the failure time data.
Based on the generalized data, the LLF for NHPP-based SRMs is written in the following form:
Then, the problem is to find the optimal , so-called maximum likelihood estimates (MLEs), maximizing . However, it is noted that we cannot derive the closed form solution of MLEs. That is, we need to utilize numerical optimization techniques such as the Newton method, quasi-Newton method, and Nelder–Mead method.
Although conventional methods such as the Newton method and the Nelder–Mead method may be occasionally useful in computing MLEs of the NHPP-based SRMs, it is worth noting that these aim to solve unconstrained optimization problems in ML estimation. However, in many cases, we have to cope with constrained optimization problems because almost all of the model parameters of NHPP-based SRMs are implicitly constrained, such as positive constraint.
3. EM Algorithms for NHPP-Based SRMs
This paper develops numerical procedures to compute MLEs for NHPP-based SRMs with generalized data. The proposed estimation algorithms are based on the EM principle. The EM algorithm is one of the statistical approaches to compute the MLEs for incomplete data and is numerically stable because of its global convergence property. Moreover, the proposed EM algorithms for NHPP-based SRMs are based on the closed forms of MLEs for an arbitrary fault-detection time distribution and are capable of solving constrained optimization problems. Although we have already developed EM algorithms for failure time data and failure count data for several basic NHPP-based SRMs, this paper revisits their EM algorithm when generalized data are given.
3.1. EM Algorithm
The EM algorithm is an iterative method for computing ML estimates with incomplete data [28,29]. Let and be observable and unobservable data vectors, respectively, and be a model parameter vector to be estimated from only the observable data. In the ML estimation, we find a parameter vector by maximizing the following log-likelihood function (LLF) :
where is any probability density or mass function and thus denotes the likelihood function for complete data .
Let denote the conditional expected LLF with respect to the complete data vector using the posterior distribution for unobservable data vector with a given parameter vector :
Then, the EM algorithm consists of an E-step and an M-step. The E-step computes the conditional expected LLF with respect to the complete data vector using the posterior distribution for unobservable data vector with provisional parameter vector , i.e., . In the M-step, we find a new parameter vector that maximizes the expected LLF:
and becomes a provisional parameter vector at the next E- and M-steps. These steps surely increase the marginal LLF. The E- and M-steps are repeatedly executed until the parameters converge.
3.2. EM Algorithm for NHPP-Based SRMs
Consider the complete data in NHPP-based SRMs, , where is the ith failure time and N is the number of all the failures. It is worth noting that the number of all the failures in software is unobserved. Since N is the Poisson-distributed random variable and obeys , the complete LLF is given by
From the standard argument of MLEs, the MLEs of and can be derived as
and
respectively. These imply that the estimation problem of NHPP-based SRMs under complete data can be decomposed into separate problems for two distribution functions: Poisson distribution and the failure time distribution.
Since the number of failures and the exact failure time in intervals are unobserved, the generalized data are incomplete data. By applying the EM algorithm, we have the following EM-step formulas for NHPP-based SRMs with the generalized data:
and
Additionally, we obtain the following formula to compute the expected values. For any measurable function , the expected value with the generalized data is expressed as
where is a probability density function (p.d.f.) of failure time provided that the parameter vector is . The derivation of this formula is given in Appendix A.
exp: ‘exp’ is the model where the failure time distribution is an exponential distribution. This model is exactly the same as the Goel–Okumoto model [2]. Define the c.d.f. of failure time as
Since the MLE of an ordinary exponential distribution is given by a closed from, the EM-step formulas for exp are directly derived from Equations (10) and (11);
By applying the formula for the expected value, we have
where
gamma: The failure time distribution becomes the following gamma distribution:
where and are shape and scale parameters, respectively. When is fixed, the model reduces the delayed S-shaped SRM [17].
Similar to exp, the EM-step formulas are given using Equations (10) and (11):
where is the digamma function, i.e., . Additionally, we use the updated to compute . Note that Equation (21) can easily be solved with the nonlinear equation solver such as a bisection method. In addition, and are obtained as follows:
where is the complementary c.d.f. of gamma distribution with parameters and . On the other hand, we need the numerical integration to obtain . It should be noted that, if the shape parameter is fixed, then the computation algorithm becomes simple because we ignore solving the nonlinear equation and computing the expected value .
pareto: ‘pareto’ is the SRM where the failure time distribution is the Pareto distribution of the second kind. The Pareto distribution of the second kind is called Lomax distribution:
This model was proposed as the modified Duane model [50].
Since the Pareto distribution of the second kind is a mixture of exponential distribution, the EM algorithm for ‘pareto’ is constructed using this property. In general, the mixture distribution is defined as a superposition of original statistical distributions with mixture ratio. Let be the c.d.f. of mixture ratio distribution for the parameter . Then, the mixture distribution is given by
The Pareto distribution of the second kind is a mixture of exponential distribution when the mixture ratio distribution is a gamma distribution. That is, the failure time distribution is written in the following form:
For the EM algorithm of mixture-type SRMs, we also define the fault detection rate for each fault as a hidden variable.
Let be a set of failure time and its associated fault detection rate for all the failures. The complete LLF is given by
Similar to gamma, we have the following EM-step formula from the MLEs of gamma distributions:
On the other hand, the formula for the expected value is given by
where is an arbitrary measurable function and
tnorm, lnorm: ‘tnorm’ and ‘lnorm’ are SRMs whose failure time distributions are truncated and log normal distributions, respectively. The failure time distributions for tnorm and lnorm are
where is the c.d.f. of the standard normal distribution. Since the EM algorithms for both models with failure time and count data were introduced in detail in the literature [34], this paper provides the EM-step formulas with the generalized data.
- EM-step formula for tnorm:where
- EM-step formula for lnorm:where
In the above formulas, is the complementary c.d.f. of the standard normal distribution, and and are expressed with the p.d.f. of the standard normal distribution :
In addition, after the convergence, we take to obtain the ML estimate for in the case of tnorm.
tlogis, llogis tlogis and llogis are the SRMs with truncated and log logistic distributions, respectively. In particular, ‘tlogis‘ is equivalent to the inflection S-shaped model [15]. The failure time distribution of tlogis is given by
where is the c.d.f. of standard logistic distribution
By taking into account the exponential of logistic distribution, we have the following failure time distribution of llogis:
Since logistic distribution does not belongs to the exponential family of distributions, neither expectation nor maximization can be expressed as simple formulas. To construct the algorithm, we consider only one assumption; the number of all failures is not observed. Then, the EM-step formulas become
- The EM-step formula for tnorm
- The EM-step formula for lnorm
The second equations in both formulas indicate that is updated by the MLEs when the number of all the failures is given by and . These algorithm are also stable if there exists a unique solution maximizing the right-hand side of the second term. Note that, after the convergence, the model parameter in tlogis can be obtained as .
txvmax, lxvmax, txvmin, lxvmin Suppose that the failure time caused by each failure follows an extreme value type I distribution. The extreme value type I distribution is called Gumbel distribution, and its definition is based on the limitation of the maximum value of random variables. Here, the c.d.f. of a standard Gumbel distribution is defined as
Similar to tnorm, lnorm, tlogis, and llogis, we consider the truncation and logarithm of the extreme value distribution. In addition, since the extreme value distribution is not symmetric, we also consider the case of negative samples, i.e., the minimum value of random variables.
The failure time distributions of txvmax and lxvmax are, respectively,
Similarly, the failure time distributions of txvmin and lxvmin are given by
where corresponds to the c.d.f. of a standard extreme value type I distribution of the minimum. From Equation (63), we find that lxvmin is equivalent to the Weibull distribution.
Since the extreme value distribution is not an exponential family, we consider only one assumption; the number of all the failures is not observed. Then, the EM-step formulas are given by
- The EM-step formula for txvmax and txvmin
- The EM-step formula for lxvmax and lxvmin
4. Numerical Example
We investigated the numerical characteristics of the presented EM algorithms. Here, we compare the convergence property with the Nelder–Mead method and the quasi-Newton method (BFGS method). First, we check the trace of model parameters until they converge to MLE for the proposed method (EM algorithm), the Nelder–Mead method, and the BFGS method. In this experiment, we used the fault count data, which were collected from real software projects [53]. The statistics of fault count data are given as follow.
- Data label: SS1A
- Working days: 151
- The number of failures: 112
- LOC: Hundreds of thousands
- Software type: Operations
For the above failure count data, we estimated the parameters of ‘exp’. The MLEs of exp are and , and the maximum LLF is .
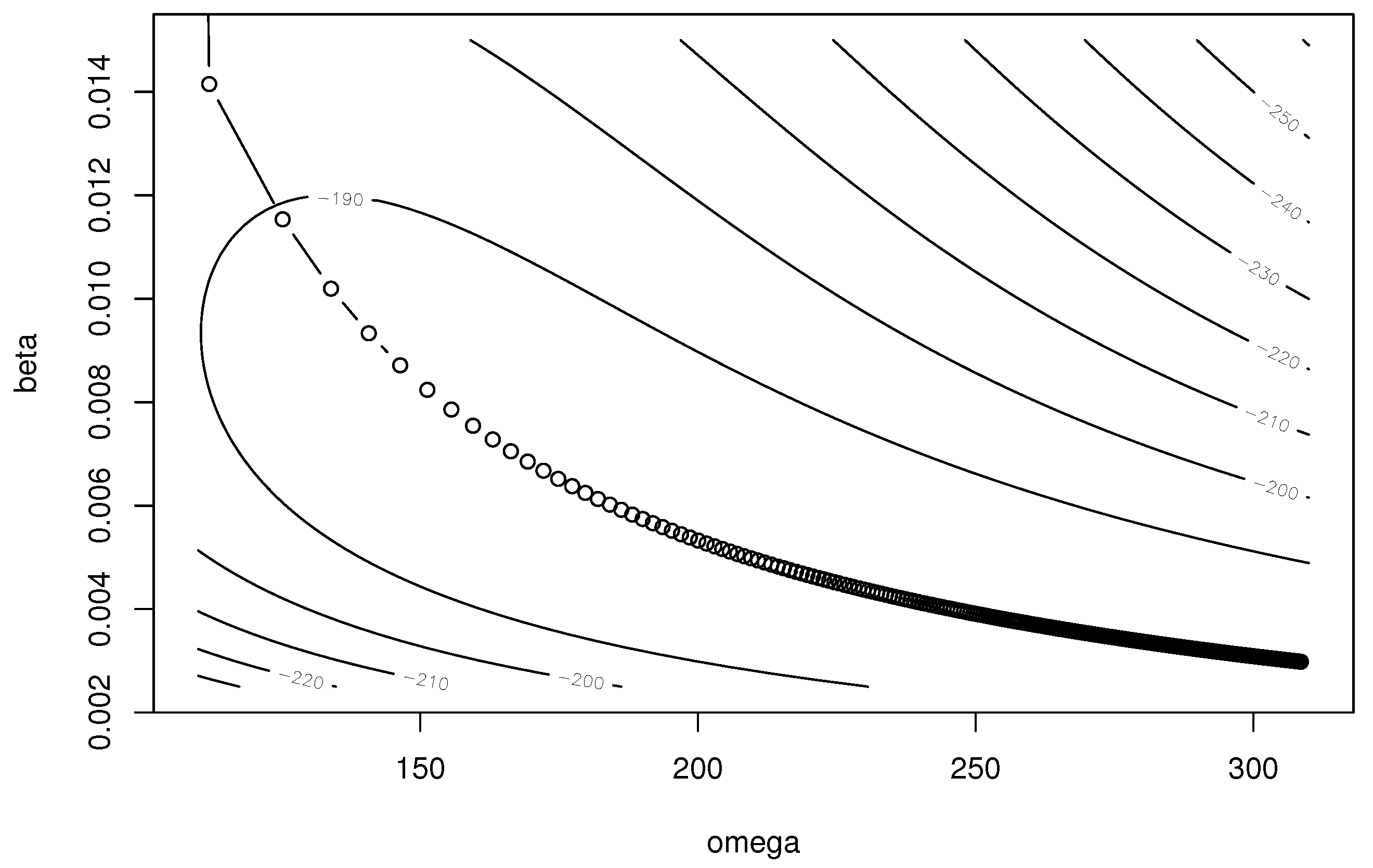
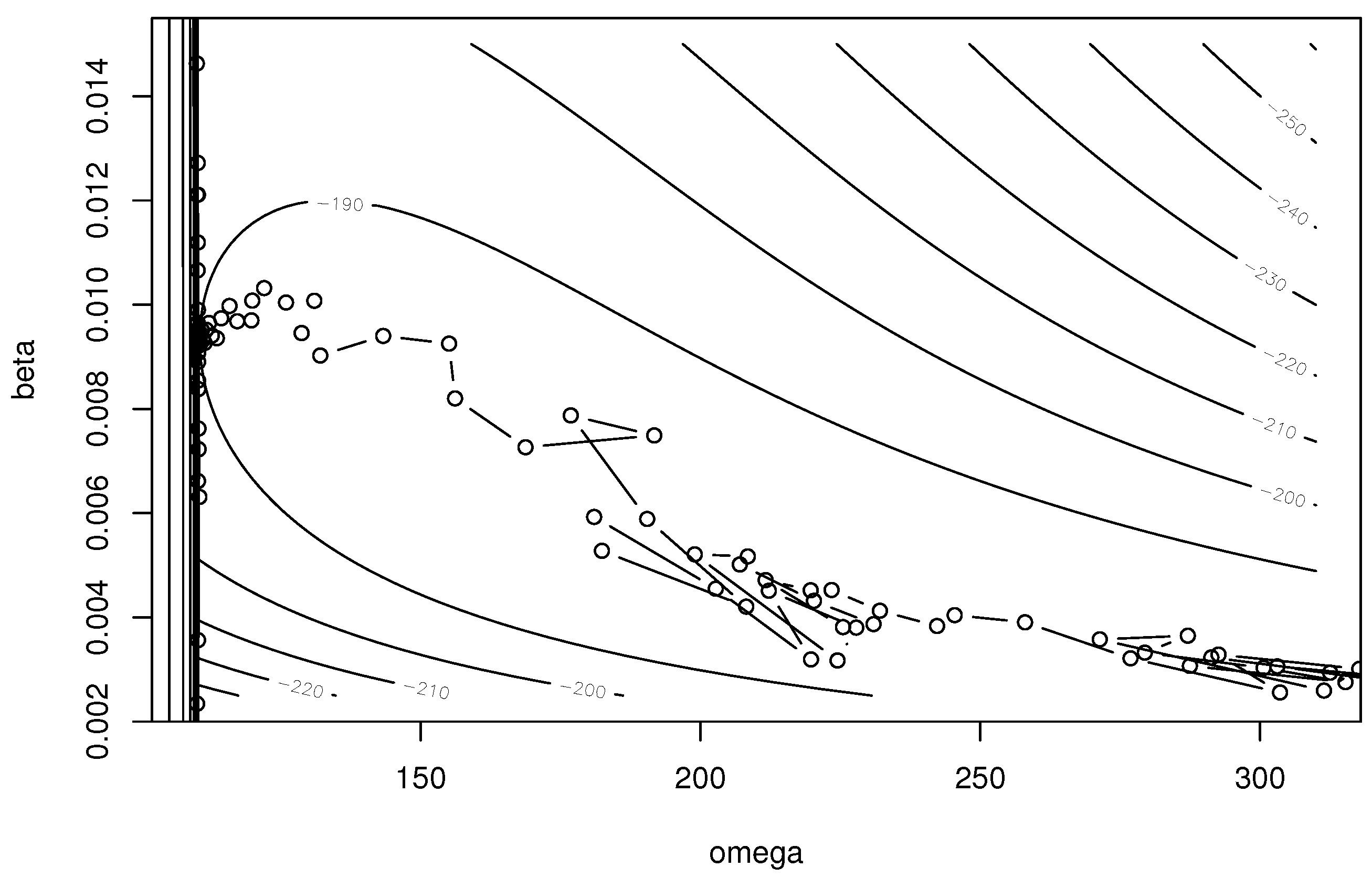
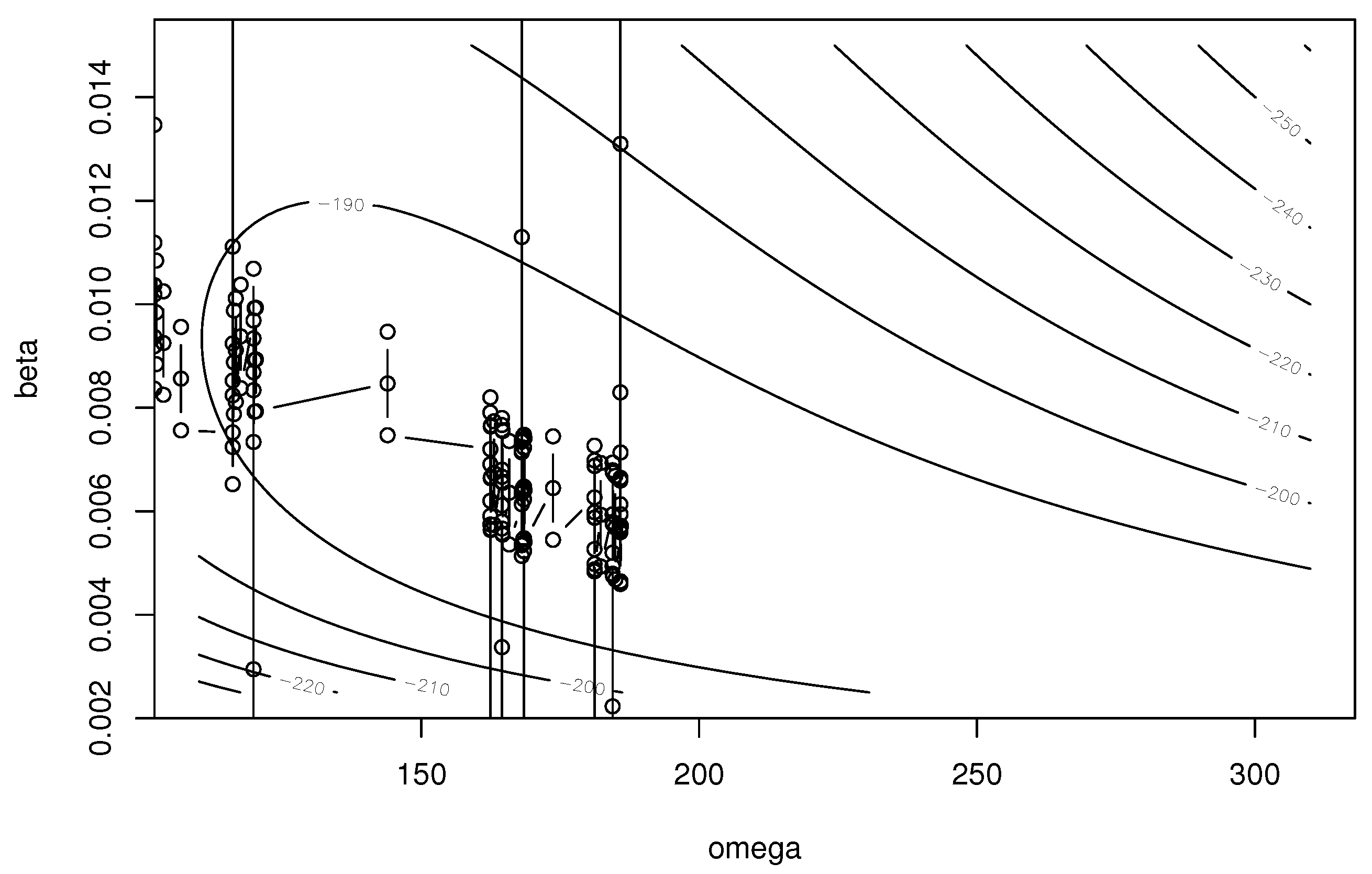
Figure 1, Figure 2 and Figure 3 show the trace of model parameters for EM algorithm, the Nelder–Mead method, and the BFGS method when the initial guesses are and . We use the ‘optim’ function in R for the Nelder–Mead and BFGS methods. From these figures, we find that the EM algorithm stably updates the model parameters and converges to close parameters to the MLEs. However, the convergence speed is not fast, since the update becomes smaller as the parameters are close to the MLEs. The Nelder–Mead method provides the MLEs, but the trace of the algorithm is not stable. In particular, this algorithm sometimes takes invalid values that violate the parameter constraints, i.e., or , while searching for the parameters. Figure 3 depicts the trace of parameters for the BFGS method. The convergence property is the worst among the three methods. Additionally, the algorithm fails to obtain the MLE.
Next, we present the convergence properties for the proposed EM algorithm, the Nelder–Mead method, and the BFGS method quantitatively. Here, we use two additional fault count data that were collected from real software projects [53] as well as SS1A.
- Data label: SS1B
- Working days: 663
- The number of failures: 375
- LOC: Hundreds of thousands
- Software type: Operations
- Data label: SS1C
- Working days: 472
- The number of failures: 277
- LOC: Hundreds of thousands
- Software type: Operations
For three data sets—SS1A, SS1B, and SS1C—we applied the proposed EM algorithm, the Nelder–Mead method, and the BFGS method for 12 basic NHPP-based SRMs with 100 different initial parameters. In the experiment, the initial parameters were selected by random numbers. Table 2, Table 3 and Table 4 present the number of converged estimations, i.e., the number of times that the model parameters are successfully estimated for each NHPP-based SRMs and methods. If this value is 100, the method succeeded in obtaining the MLE for all of the initial parameters. On the other hand, if this value is 0, the estimation method fails to obtain the MLE for all of the initial parameters due to numerical computation errors such as overflow and underflow.
From these results, we find that the convergence rates of the proposed EM algorithms are 100% in the cases of exp, gamma, pareto, tnorm, and tlogis. Since the number of converged estimations of the Nelder–Mead is almost the same as that of BFGS for all cases, the convergence properties of their methods are the same if we use the ‘optim’ function in R. Additionally, since lxvmax did not fit SS1B and SS1C, all of the estimation methods failed to obtain the MLE. Furthermore, it was found that the numbers of converged estimates in the Nelder–Mead and BFGS methods are worse than that of the EM algorithm, specifically in the cases of exp, gamma, and pareto. Additionally, in the cases of tnorm and lnorm, the convergence property of EM is slightly superior to the other two methods. In exp, gamma, pareto, tnorm, and lnorm, the failure time distributions belong to the exponential family, and thus, their EM-step formulas do not include the numerical optimization step. That is, these EM-step formulas are ‘pure’ EM-step formulas. Therefore, the convergence properties outperform those of the Nelder–Mead and BFGS methods. On the other hand, in the cases of tlogis, llogis, txvmax, lxvmax, txvmin, and lvxmin, the failure time distributions are not in the exponential family, and we should use the numerical optimization step in their EM-step formulas. This is the reason why the convergence property of the presented EM algorithm is same as that in the Nelder–Mead and BFGS methods.
5. Conclusions
This paper derived EM-step formulas for 12 basic NHPP-based SRMs when the generalized failure count data are given. Since the generalized fault count data involve both time and count data formats, the presented EM algorithms can be applied to failure data experienced in practice. In addition, the convergence property of EM algorithm is better than or equivalent to other ordinary methods such as the Nelder–Mead and BFGS methods for practical software fault data. Thus, the presented algorithms are suitable for implementation in the automatic tool for software reliability evaluation. In fact, our research group has developed an AddIn of Microsoft Excel to estimate software reliability [54].
In the future, we will develop a reliability assessment tool by integrating a software repository such as GitHub, a bug tracking system, and a continuous integration system, and the tool will continuously monitor the reliability of software.
Author Contributions
Conceptualization, H.O. and T.D.; methodology, H.O.; software, H.O.; supervision, T.D.; validation, T.D.; writing—original draft, H.O. and T.D.; writing—review and editing, H.O. and T.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Derivation of Equation (12)
For convenient, and are written as and , respectively, and is simplified as . Here we have
where .
According to the order statistics of failure times, the first term of the right-hand side of the above can be rewritten as follows.
Since are i.i.d. random variables, the multiple integrals of denominator in Equation (A2) is given by
Similarly, the numerator becomes
Henceforth we have
The second term of the right-hand side of Equation (A1) is straightforwardly given by . The third term can be derived by a similar way to the first term. Taking account of the condition , we have
where .
References
- Jelinski, Z.; Moranda, P.B. Software Reliability Research. In Statistical Computer Performance Evaluation; Freiberger, W., Ed.; Academic Press: New York, NY, USA, 1972; pp. 465–484. [Google Scholar]
- Goel, A.L.; Okumoto, K. Time-Dependent Error-Detection Rate Model for Software Reliability and Other Performance Measures. IEEE Trans. Reliab. 1979, R-28, 206–211. [Google Scholar] [CrossRef]
- Lyu, M.R. (Ed.) Handbook of Software Reliability Engineering; McGraw-Hill: New York, NY, USA, 1996. [Google Scholar]
- Musa, J.D.; Iannino, A.; Okumoto, K. Software Reliability, Measurement, Prediction, Application; McGraw-Hill: New York, NY, USA, 1987. [Google Scholar]
- Pham, H. Software Reliability; Springer: Singapore, 2000. [Google Scholar]
- Xie, M. Software Reliability Modelling; World Scientific: Singapore, 1991. [Google Scholar]
- Rook, P. (Ed.) Software Reliability Handbook; Elsevier Science: London, UK, 1990. [Google Scholar]
- Singpurwalla, N.D.; Wilson, S.P. Statistical Methods in Software Engineering; Springer: New York, NY, USA, 1997. [Google Scholar]
- Li, Q.; Pham, H. A Generalized Software Reliability Growth Model With Consideration of the Uncertainty of Operating Environments. IEEE Access 2019, 7, 84253–84267. [Google Scholar] [CrossRef]
- Li, Q.; Pham, H. NHPP software reliability model considering the uncertainty of operating environments with imperfect debugging and testing coverage. Appl. Math. Model. 2017, 51, 68–85. [Google Scholar] [CrossRef]
- He, Y. NHPP software reliability growth model incorporating fault detection and debugging. In Proceedings of the 2013 IEEE 4th International Conference on Software Engineering and Service Science, Beijing, China, 23–25 May 2013; pp. 225–228. [Google Scholar]
- Song, K.Y.; Chang, I.H.; Pham, H. NHPP Software Reliability Model with Inflection Factor of the Fault Detection Rate Considering the Uncertainty of Software Operating Environments and Predictive Analysis. Symmetry 2019, 11, 521. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Zhang, L.; Wu, J.; Wu, J.; Yang, H. A New Method of Model Combination Based on the NHPP Software Reliability Models. In ICMSS 2018: Proceedings of the 2018 2nd International Conference on Management Engineering, Software Engineering and Service Sciences; ACM: New York, NY, USA, 2018; pp. 153–158. [Google Scholar] [CrossRef]
- Musa, J.D.; Okumoto, K. A Logarithmic Poisson Execution Time Model for Software Reliability Measurement. In Proceedings of the 7th International Conference Software Engineering (ICSE-1084); IEEE CS Press: Los Alamitos, CA, USA; ACM: New York, NY, USA, 1984; pp. 230–238. [Google Scholar]
- Ohba, M. Software Reliability Analysis. IBM J. Res. Dev. 1984, 28, 428–443. [Google Scholar] [CrossRef]
- Ohba, M. Inflection S-Shaped Software Reliability Growth Model. In Stochastic Models in Reliability Theory; Osaki, S., Hatoyama, Y., Eds.; Springer: Berlin, Gremany, 1984; pp. 144–165. [Google Scholar]
- Yamada, S.; Ohba, M.; Osaki, S. S-Shaped Reliability Growth Modeling for Software Error Detection. IEEE Trans. Reliab. 1983, R-32, 475–478. [Google Scholar] [CrossRef]
- Zhao, M.; Xie, M. On Maximum Likelihood Estimation for a General non-Homogeneous Poisson Process. Scand. J. Stat. 1996, 23, 597–607. [Google Scholar]
- Pham, H.; Zhang, X. An NHPP Software Reliability Models and its Comparison. Int. J. Reliab. Qual. Safe. Eng. 1997, 4, 269–282. [Google Scholar] [CrossRef]
- Shanthikumar, J.G. A General Software Reliability Model for Performance Prediction. Microelectron. Reliab. 1981, 21, 671–682. [Google Scholar] [CrossRef]
- Langberg, N.; Singpurwalla, N.D. Unification of Some Software Reliability Models. SIAM J. Sci. Comput. 1985, 6, 781–790. [Google Scholar] [CrossRef]
- Chen, Y.; Singpurwalla, N.D. Unification of Software Reliability Models by Self-Exciting Point Processes. Adv. Appl. Probab. 1997, 29, 337–352. [Google Scholar] [CrossRef]
- Miller, D.R. Exponential Order Statistic Models of Software Reliability Growth. IEEE Trans. Softw. Eng. 1986, SE-12, 12–24. [Google Scholar] [CrossRef]
- Hossain, S.A.; Dahiya, R.C. Estimating the Parameters of a non-Homogeneous Poisson-Process Model for Software Reliability. IEEE Trans. Reliab. 1993, 42, 604–612. [Google Scholar] [CrossRef]
- Knafl, G.; Morgan, J. Solving ML Equations for 2-parameter Poisson-Process Model for Ungrouped Software Failure Data. IEEE Trans. Reliab. 1996, 45, 42–53. [Google Scholar] [CrossRef]
- Joe, H. Statistical Inference for General-Order-Statistics and Nonhomogeneous-Poisson-Process Software Reliability Models. IEEE Trans. Softw. Eng. 1989, 15, 1485–1490. [Google Scholar] [CrossRef]
- Jeske, D.R.; Pham, H. On the maximum likelihood estimates for the Goel-Okumoto software reliability model. Am. Stat. 2001, 55, 219–222. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. B 1977, R-39, 1–38. [Google Scholar]
- Wu, C.F.J. On the convergence properties of the EM algorithm. Ann. Stat. 1983, 11, 95–103. [Google Scholar] [CrossRef]
- Okamura, H.; Dohi, T.; Osaki, S. EM algorithms for logistic software reliability models. In Proceedings of the 22nd IASTED International Conference on Software Engineering, Innsbruck, Austria, 17–19 February 2004; ACTA Press: Crete, Greece, 2004; pp. 263–268. [Google Scholar]
- Okamura, H.; Murayama, A.; Dohi, T. EM Algorithm for Discrete Software Reliability Models: A Unified Parameter Estimation Method. In Proceedings of the 8th IEEE International Symposium High Assurance Systems Engineering, Tampa, FL, USA, 25–26 March 2004; pp. 219–228. [Google Scholar]
- Okamura, H.; Watanabe, Y.; Dohi, T. Estimating a mixed software reliability models based on the EM algorithm. In Proceedings of the International Symposium on Empirical Software Engineering (ISESE2002), Nara, Japan, 3–4 October 2002; IEEE Computer Society Press: Los Alamitos, CA, USA, 2002; pp. 69–78. [Google Scholar]
- Okamura, H.; Watanabe, Y.; Dohi, T. An iterative scheme for maximum likelihood estimation in software reliability modeling. In Proceedings of the 14th International Symposium on Software Reliability Engineering, Denver, CO, USA, 17–20 November 2003; pp. 246–256. [Google Scholar]
- Okamura, H.; Dohi, T.; Osaki, S. Software reliability growth models with normal failure time distributions. Reliab. Eng. Syst. Saf. 2013, 116, 135–141. [Google Scholar] [CrossRef]
- Ohishi, K.; Okamura, H.; Dohi, T. Gompertz software reliability model: Estimation algorithm and empirical validation. J. Syst. Softw. 2009, 82, 535–543. [Google Scholar] [CrossRef] [Green Version]
- Okamura, H.; Dohi, T. Phase-type software reliability model: Parameter estimation algorithms with grouped data. Ann. Oper. Res. 2016, 244, 177–208. [Google Scholar] [CrossRef]
- Okamura, H.; Dohi, T. Hyper-Erlang software reliability model. In Proceedings of the 2008 14th IEEE Pacific Rim International Symposium on Dependable Computing, Taipei, Taiwan, 15–17 December 2008. [Google Scholar]
- Okamura, H.; Dohi, T. Building Phase-Type Software Reliability Model. In Proceedings of the 2006 17th International Symposium on Software Reliability Engineering, Raleigh, NC, USA, 7–10 November 2006; pp. 289–298. [Google Scholar]
- Xiao, X.; Okamura, H.; Dohi, T. NHPP-based software reliability models using equilibrium distribution. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. (A) 2012, E95-A, 894–902. [Google Scholar] [CrossRef] [Green Version]
- Kawasaki, M.; Okamura, H.; Dohi, T. A Comprehensive Evaluation of Software Reliability Modeling Based on Marshall-Olkin Type Fault-Detection Time Distribution. In Proceedings of the 2017 24th Asia-Pacific Software Engineering Conference (APSEC), Nanjing, China, 4–8 December 2017; pp. 486–494. [Google Scholar] [CrossRef]
- Kimura, M.; Yamada, S. Software reliability management: Techniques and applications. In Handbook of Reliability Engineering; Pham, H., Ed.; Springer: London, UK, 2003; pp. 265–284. [Google Scholar]
- Ledoux, J.; Rubino, G. A counting model for software reliability analysis. Int. J. Model. Simul. 1997, 17, 289–297. [Google Scholar] [CrossRef] [Green Version]
- Okamura, H.; Dohi, T. Unification of software reliability models using Markovian arrival processes. In Proceedings of the 17th IEEE Pacific Rim International Symposium on Dependable Computing (PRDC-2011), Pasadena, CA, USA, 12–14 December 2011; IEEE CS Press: Los Alamitos, CA, USA, 2011; pp. 20–27. [Google Scholar]
- Goel, A.L.; Okumoto, K. An Imperfect Debugging Model for Reliability and Other Quantitative Measures of Software Systems; Technical Report 78-1; Department of IE & OR, Syracuse University: Syracuse, NY, USA, 1978. [Google Scholar]
- Littlewood, B. A Reliability Model for Systems with Markov Structure. Appl. Stat. 1975, 24, 172–177. [Google Scholar] [CrossRef]
- Ledoux, J. Availability modeling of modular software. IEEE Trans. Reliab. 1999, 48, 159–168. [Google Scholar] [CrossRef] [Green Version]
- Zeephongsekul, P.; Jayasinghe, C.L.; Fiondella, L.; Nagaraju, V. Maximum-Likelihood Estimation of Parameters of NHPP Software Reliability Models Using Expectation Conditional Maximization Algorithm. IEEE Trans. Reliab. 2016, 65, 1571–1583. [Google Scholar] [CrossRef]
- Nagaraju, V.; Fiondella, L.; Zeephongsekul, P.; Jayasinghe, C.L.; Wandji, T. Performance Optimized Expectation Conditional Maximization Algorithms for Nonhomogeneous Poisson Process Software Reliability Models. IEEE Trans. Reliab. 2017, 66, 722–734. [Google Scholar] [CrossRef]
- Okamura, H.; Dohi, T. Application of EM Algorithm to NHPP-Based Software Reliability Assessment with Ungrouped Failure Time Data. In Stochastic Reliability and Maintenance Modeling: Essays in Honor of Professor Shunji Osaki on his 70th Birthday; Dohi, T., Nakagawa, T., Eds.; Springer: London, UK, 2013; pp. 285–313. [Google Scholar] [CrossRef]
- Littlewood, B. Rationale for a Modified Duane Model. IEEE Trans. Reliab. 1984, R-33, 157–159. [Google Scholar] [CrossRef]
- Goel, A.L. Software Reliability Models: Assumptions, Limitations and Applicability. IEEE Trans. Softw. Eng. 1985, SE-11, 1411–1423. [Google Scholar] [CrossRef]
- Gokhale, S.S.; Trivedi, K.S. Log-Logistic Software Reliability Growth Model. In Proceedings of the Third IEEE International High-Assurance Systems Engineering Symposium (HASE-1998), Washington, DC, USA, 13–14 November 1998; IEEE CS Press: Turku, Finland, 1998; pp. 34–41. [Google Scholar]
- Musa, J. Software Reliability Data; Technical Report; Rome Air Development Center, Griffiss AFB: Rome, NY, USA, 1979. [Google Scholar]
- Okamura, H.; Dohi, T. SRATS: Software reliability assessment tool on spreadsheet (Experience report). In Proceedings of the 24th International Symposium on Software Reliability Engineering (ISSRE 2013), Pasadena, CA, USA, 4–7 November 2013; IEEE CS Press: Los Alamitos, CA, USA, 2013; pp. 100–117. [Google Scholar]
Figure 1.
Trace of parameters in the EM algorithm.

Figure 2.
Trace of parameters in the Nelder–Mead method.

Figure 3.
Trace of parameters in the BFGS method.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Basic NHPP-based SRMs.
| Model | Failure Time Distribution |
|---|---|
| exp | Exponential distribution [2] |
| gamma | Gamma distribution [17,18] |
| pareto | Pareto type-II distribution [50] |
| tnorm | Truncated normal distribution [34] |
| lnorm | Log-normal distribution [34] |
| tlogis | Truncated logistic distribution [15] |
| llogis | Log-logistic distribution [52] |
| txvmax | Truncated extreme-value distribution (max) [35] |
| lxvmax | Log-extreme-value distribution (max) [35] |
| txvmin | Truncated extreme-value distribution (min) [35] |
| lxvmin | Log-extreme-value distribution (min) [35,51] |
Table 2.
The number of converged estimations (SS1A).
| Model | EM | Nelder-Mead | BFGS |
|---|---|---|---|
| exp | 100 | 19 | 19 |
| gamma | 100 | 34 | 34 |
| pareto | 100 | 57 | 57 |
| tnorm | 100 | 88 | 88 |
| lnorm | 100 | 98 | 98 |
| tlogis | 100 | 100 | 100 |
| llogis | 100 | 100 | 100 |
| txvmax | 100 | 100 | 100 |
| lxvmax | 99 | 99 | 99 |
| txvmin | 64 | 65 | 65 |
| lxvmin | 92 | 92 | 92 |
Table 3.
The number of converged estimations (SS1B).
| Model | EM | Nelder-Mead | BFGS |
|---|---|---|---|
| exp | 100 | 7 | 7 |
| gamma | 100 | 7 | 6 |
| pareto | 100 | 18 | 18 |
| tnorm | 100 | 98 | 98 |
| lnorm | 87 | 87 | 87 |
| tlogis | 100 | 100 | 100 |
| llogis | 87 | 87 | 87 |
| txvmax | 99 | 99 | 99 |
| lxvmax | 0 | 0 | 0 |
| txvmin | 89 | 89 | 89 |
| lxvmin | 100 | 41 | 41 |
Table 4.
The number of converged estimations (SS1C).
| Model | EM | Nelder-Mead | BFGS |
|---|---|---|---|
| exp | 100 | 9 | 8 |
| gamma | 100 | 13 | 12 |
| pareto | 100 | 47 | 47 |
| tnorm | 100 | 98 | 98 |
| lnorm | 96 | 97 | 97 |
| tlogis | 100 | 100 | 100 |
| llogis | 96 | 96 | 96 |
| txvmax | 99 | 99 | 99 |
| lxvmax | 0 | 0 | 0 |
| txvmin | 89 | 89 | 89 |
| lxvmin | 100 | 43 | 43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Okamura, H.; Dohi, T. Application of EM Algorithm to NHPP-Based Software Reliability Assessment with Generalized Failure Count Data. Mathematics 2021, 9, 985. https://0-doi-org.brum.beds.ac.uk/10.3390/math9090985
AMA Style
Okamura H, Dohi T. Application of EM Algorithm to NHPP-Based Software Reliability Assessment with Generalized Failure Count Data. Mathematics. 2021; 9(9):985. https://0-doi-org.brum.beds.ac.uk/10.3390/math9090985
Chicago/Turabian StyleOkamura, Hiroyuki, and Tadashi Dohi. 2021. "Application of EM Algorithm to NHPP-Based Software Reliability Assessment with Generalized Failure Count Data" Mathematics 9, no. 9: 985. https://0-doi-org.brum.beds.ac.uk/10.3390/math9090985
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.