
Reliability and Inference for Multi State Systems: The Generalized Kumaraswamy Case


1
Laboratoire de Mathématiques Raphaël Salem, Université de Rouen-Normandie, UMR 6085, Avenue de l’Université, BP.12, F76801 Saint-Étienne-du-Rouvray, France
2
Department of Statistics and Actuarial-Financial Mathematics, University of the Aegean, GR-83200 Samos, Greece
*
Author to whom correspondence should be addressed.
Mathematics 2021, 9(16), 1834; https://0-doi-org.brum.beds.ac.uk/10.3390/math9161834
Submission received: 23 June 2021
/
Revised: 27 July 2021
/
Accepted: 30 July 2021
/
Published: 4 August 2021
(This article belongs to the Special Issue Advances in Reliability Modeling, Optimization and Applications)
Abstract
:Semi-Markov processes are typical tools for modeling multi state systems by allowing several distributions for sojourn times. In this work, we focus on a general class of distributions based on an arbitrary parent continuous distribution function G with Kumaraswamy as the baseline distribution and discuss some of its properties, including the advantageous property of being closed under minima. In addition, an estimate is provided for the so-called stress–strength reliability parameter, which measures the performance of a system in mechanical engineering. In this work, the sojourn times of the multi-state system are considered to follow a distribution with two shape parameters, which belongs to the proposed general class of distributions. Furthermore and for a multi-state system, we provide parameter estimates for the above general class, which are assumed to vary over the states of the system. The theoretical part of the work also includes the asymptotic theory for the proposed estimators with and without censoring as well as expressions for classical reliability characteristics. The performance and effectiveness of the proposed methodology is investigated via simulations, which show remarkable results with the help of statistical (for the parameter estimates) and graphical tools (for the reliability parameter estimate).
1. Introduction
The Kumaraswamy distribution is a well-known distribution, especially to those familiar with the hydrological literature [1]. Kumaraswamy’s densities are unimodal and uniantimodal and, depending on the parameter values chosen, are either increasing or decreasing or constant functions. Note that most if not all of the above characteristics are shared by both Kumarasawmy and Beta distributions (see [2,3,4]). In fact, Kumarasawmy and Beta distributions share numerous characteristics, although some of them are much more readily available, from the mathematical point of view, for the Kumaraswamy distribution. Kumaraswamy distribution is appropriate for the modeling of bounded natural and physical phenomena, such as atmospheric temperatures or hydrological measurements [5,6], record data, such as tests, games or sports [7], economic observations [8], or for empirical data with failure rate with an increasing prior [9]. It is also appropriate in situations where one considers a distribution with infinite lower and/or upper bounds to fit data, when, in fact, the bounds are finite, which makes Kumaraswamy useful in preventive maintenance. Some specific examples discussed in the literature include failure and running times of devices [10] and deterioration or fatigue failure [11]. Furthermore, due to the closed form of both its distribution as well as its quantile function (inverse cumulative distribution), Kumaraswamy appears advantageous when it comes to the quantile modeling perspective [12,13]. These characteristics make Kumaraswamy useful and easily applicable in reliability theory.
A general class of distributions with Kumaraswamy as a baseline distribution is considered in this work by using a parent continuous distribution function: . The Kumaraswamy distribution is viewed as the baseline distribution of the proposed G-class because it arises in the trivial case associated with being the identity function, which corresponds to the parent distribution. For an arbitrary continuous parent distribution, one can generate a general subclass of distributions with the support that is different from the support of the baseline distribution (i.e., the Kumaraswamy distribution), distribution that is defined like the Beta distribution, in . The general form of the G-class of distributions based on an arbitrary parent cdf with Kumaraswamy as the baseline distribution, is defined by the following (see [2,14,15,16]):
where both parameters c and a are considered shape parameters associated with the skewness and a tail weight of . Note that additional structural parameters associated with (such as the shape parameter c) and/or distributional parameters associated with the parent distribution may also be involved in (1). Due to the fact that the distribution function in (1) is written in a closed form, it can be effectively used for both uncensored and censored data in reliability theory as well as in survival analysis.
The statistical inference, including parameter estimation in the context of reliability modeling, is of vital importance. In addition to the use of a proper distribution, such as (1), for modeling purposes, one may also be interested in evaluating the performance of the reliability system involved. Indeed, for instance, the problem of performance of a system is of great importance in mechanical engineering and refers to a component of strength X, which is subject to stress Y. The system stays in operation as long as the stress is less than the strength, so the system performance is associated with the probability of exceedance, usually denoted by R. The quantity of interest in such cases is the stress–strength reliability or reliability parameter which is a measure of reliability defined by the following:
The concept of stress–strength reliability has been investigated extensively in the literature for various lifetime distributions. The reliability parameter has been obtained for several distributions that typically appear in reliability analyses, such as Exponential, Gamma, Weibull, Burr, Marshall–Olkin extended Lomax distribution and inverse Rayleigh distribution. Such distributions were considered for at least one of the two variables of interest, namely X and Y (see [17,18,19,20,21]).
In this work, we focus on the general class of distributions of the form (1), using a parent continuous distribution function, and discuss some of its properties, including the stress–strength reliability. In addition, and for a multi-state system, we provide parameter estimates for the class given in (1), which are assumed to vary over the states of the system. The theoretical part of the work also includes the asymptotics for the proposed estimators. The performance of the proposed methodology is investigated with simulated results.
The paper is organized as follows: In Section 2, we propose and discuss the G-class of distributions (1). In Section 3 and Section 4, the semi-Markov setting and the parameter estimation are provided. Reliability characteristics are discussed in Section 5, while applications are analyzed in the final section.
2. The G-Class of Distributions
Consider the family of distributions with shape parameter a and distribution function, given by the following:
which is absolutely continuous w.r.t. the Lebesgue measure, with density function and with being the standard family member when . Classical reliability distributions, such as Exponential, Rayleigh and Weibull distributions are members of (3). One of the special features of (3) is that the distribution of the minimum, i.e., of the ordered statistic of a random sample from (3), falls within this class (see [22,23]).
Notice that the general G-class of distributions in (1) with a parent continuous distribution builds a new general class of distributions with each member lying within the class given in (3), with
and Kumaraswamy as the baseline distribution of the entire class. It should be noted that the baseline (Kumaraswamy) distribution is obtained for the Uniform distribution in , i.e., for the identity function , with cdf provided by the following expression:
Note that the Kumaraswamy distribution is a member of the G-class (1) with . Kumaraswamy distribution, which, due to the form of the function G, can be viewed as a Generalized Uniform distribution, is an easy to handle distribution in the sense that it has simple explicit expressions for the distribution and quantile functions as well as the L-moments and the moments of order statistics [2]. Furthermore, it has a simple formula for the generation of random samples. The proposed general G-class though, goes beyond the Kumaraswamy since for each (any) continuous distribution chosen as the parent distribution G (i.e., Exponential, Gamma, Weibull, Gumbel, Rayleigh, and Inverse Gaussian), a new special/specific general (sub)class of densities arises (Generalized Exponential, Gamma, Weibull, Gumbel, Rayleigh or Inverse Gaussian, etc.). Observe that each of these general specific subclasses offers additional flexibility to the researcher for accommodating complex reliability phenomena. Observe further that the G-class in (1) generates a family of distributions with support that goes beyond the restrictive support of the baseline distribution in (4) and, in fact, it coincides with the support of the parent distribution . This characteristic extends even further the applicability of the G-class of distributions, covering, among others, classical reliability and survival analysis problems, where the time-to-event is the main feature to be investigated (see, for example, [24]).
2.1. Basic Characteristics of the G-Class of Distributions
The basic functions, including the pdf of the G-class of distributions (1), are given in the lemma below.
Lemma 1.
Let X be a random variable from the G-class of distributions (1) with being absolutely continuous with respect to the Lebesgue measure. Then, the density function, the hazard (failure) rate function, the reversed hazard rate function, and the cumulative hazard rate function, are the following:
where the pdf associated with .
Proof.
The results follow immediately using the following standard definitions:
where F is the cdf of the random variable involved, given in the case at hand, by (1). □
Having as the baseline distribution of (1) the Kumaraswamy distribution given in (4), it is easily seen that the associated pdf is given by the following:
Taking as a parent distribution the Exponential distribution with , we have the following:
and
while for the Weibull distribution with as a parent distribution, we have the following:
and
For the baseline Kumaraswamy distribution , observe that if the random variable then and . However, if then and . In addition, if then . In general, the parameters c and a control the skewness and the tail of the distribution so that the G-class becomes ideal for fitting skew data, which cannot be otherwise described.
As expected, irrespective of the parent distribution, the resulting distribution is a member of (1) as summarized below.
Lemma 2.
Let G be a specific distribution function with dimensional distribution parameter . Then, for the specific parent continuous distribution , the resulting is a member of the G-class of distributions (1).
Proof.
Consider a cdf and define such that . Then, the resulted F satisfies expression (1) and the result is immediate. □
Reliability Characteristics
In this section, we provide some basic reliability characteristics, including the expression for the reliability parameter in the case of two random variables with distributions in the G-class of distributions, with different shape parameters.
Theorem 1.
Let T be a random variable with cdf belonging to the G-class. Then, the reliability and hazard functions of the random variable T are given, respectively, by the following:
and
Proof.
Theorem 2.
Let be independent random variables from the G-class with shape parameters and , respectively, and common shape parameter c. Then, the reliability parameter R given in (2) is a constant that depends only on the shape parameters and .
Proof.
Let and with , the common parent distribution that may or may not depend on distributional parameters.
The reliability parameter can be written as the following:
Setting and the above integration becomes:
□
Remark 1.
Consider X and Y, two random variables having the baseline Kumaraswamy distribution of the G-class. In this case and under the setting of Theorem 2, the reliability parameter between X and Y is the following:
Setting and , we have the following:
Remark 2.
If we consider as the parent distribution the Exponential distribution , and under the setting of Theorem 2, the reliability parameter associated with X and Y is the following:
which, for and takes the following form:
Remark 3.
If , then the two distributions of the G-class (for any continuous ) share a common shape parameter, i.e., . In general, for then
so that if while if . Thus, R increases if increases as compared to ; otherwise R decreases.
2.2. Ordered Statistics and Distribution of the Minimum
In this section, we establish that the G-class is closed under minima which is a significant property with a pivotal role in inferential statistics under the multi-state setting of the following section.
Theorem 3.
If are random variables from the G-class, then the distribution function of the minimum ordered statistic is given by the following:
and belongs to the G-class.
Proof.
It is straightforward that
which belongs to the G-class with shape parameters c and . □
Lemma 3.
Let be random variables from the G-class of distributions (1), where G is the Exponential distribution. The distribution function of the first ordered statistic falls into the G-class.
Proof.
The result arises naturally from the previous theorem. In fact, by substituting the distribution of the minimum becomes the following:
□
Remark 4.
The results of this section can be generalized by dropping the assumption of identically distributed random variables. Indeed, if one considers the case of independent but not necessarily identically distributed (inid) r.v’s and assumes a random sample with the cdf of , being given by
then Theorem 3 still holds true with belonging to the G-class (1) with parameters c and , namely the following:
The next subsection concentrates on inid r.v’s under the multi-state setting with the sojourn times (the time spend on state i before moving to state j) having a distribution , belonging to (1) with shape parameter , and a common parameter c for any with N representing the finite number of system states. From a practical point of view, such a setting is quite meaningful since the transition from one state to another in multi-state systems is not necessarily described by the iid framework. Thus, for instance, the waiting time in a state i (before the system moves to state j) could be properly described by, for example, the Exponential distribution, but the distribution of the waiting time in state i or even in state j (before moving to state k) may have a heavier or lighter tail than the Exponential distribution. Such situations are tractable within our inid framework by allowing the parameter controlling the tail part of the distribution, i.e., the parameter a, to vary according to the specific current and next visited states. The case of varying both a and c parameters is a complex mathematical problem that will be left for future work.
3. The Semi-Markov Model and Multi-State Systems
A multi-state model is a continuous time stochastic process with values in a discrete set. Diverting from the standard class of Markov processes to the semi-Markov processes, we abandon the restriction of memoryless state sojourn times but, at the same time, we retain the treatment of the data as jump processes in continuous time. In fact, for semi-Markov processes, the Markov property is assumed only for the embedded chain of distinct visited states and we also have a Markov property that acts on random time instants, i.e., on the jump time instants. Such characteristics allow for a great applicability of semi-Markov processes in fields such as economics, finance, survival analysis, reliability, health care systems, etc. [25,26,27,28,29,30,31].
Consider a stochastic jump process with state space We denote by the jump times, by the visited states at these times and by the sojourn times,
We assume that is a semi-Markov process (SMP) and that is a Markov renewal process (MRP) associated to the SMP (cf. [29]). It immediately follows that is a Markov chain, called the embedded Markov chain. Let us also denote by
the counting process of the number of jumps in the time interval .
We assume that the SMP is regular, that is for all and state
A SMP is defined by the initial law:
and the semi-Markov kernel:
We can also define the transition probabilities of as follows:
and the conditional sojourn time distribution functions as the following:
So, we have the following:
The time spent in state i before moving directly to state j is denoted by let be the corresponding cumulative distribution function and the density function with respect to the Lebesgue measure.
The model we consider assumes that the next state to be visited after i is the one for which is the minimum. Under this condition, we have the following:
where
and
We denote by the density of w.r.t. the Lebesgue measure. Note that
The following proposition holds under the G-class.
Proposition 1.
and
Remark 5.
The model considered in this work assumes that the next state to be visited after state i is the one for which is the minimum. In many cases, especially in reliability applications, the optimal choice for the next state to be visited is the one with the “lowest cost” or the “minimum distance”. This can be achieved by setting a system such that j is chosen so that the potential time spent in state i before moving directly to state j is minimal over all states in the state-space. The definition for can be adjusted accordingly if one focuses on the cost instead of the time, in which case is the potential cost for the route from state i to state j.
4. Inference with and without Censoring
We proceed now to the statistical inference with and without censoring. More specifically, for the latter case, the sojourn times are fully observed, while, for the former, right censoring is observed at the last visited state.
Let M be the total observation time. Then, the likelihood function for the case without censoring and for the sample paths
is given by the following:
where
- ,
- : the number of visits to state i up to time M of the lth trajectory, ,
- : the number of transitions from state i to state j up to time M during the lth trajectory, ,
- ,
- : the sojourn time in state i during the kth visit, of the lth trajectory, .
Using the relevant expressions associated with the G-class, Equation (22) becomes the following:
Maximizing accordingly the above function, the maximum likelihood estimators of the parameters and of the initial distribution law are obtained:
and
where
Observe that the results above hold for any number of trajectories. For the special case of a single sample path the estimator could be simplified as follows:
Turning now to the case with censoring at time M, we consider L censored sample paths denoted by . Then, the associated likelihood function is equal to the following:
where
- is the observed censored time of the lth trajectory;
- is the number of visits of state i, as last visited state, over the L trajectories; note that
- is the observed censored sojourn time in state i during the kth visit, .
It should be pointed out that, if M happens to be a jump time, then, for the associated path(s), we have and thus the corresponding likelihood term equals 1. If this happens to occur for all values of , then the censoring case described above collapses to the uncensored case discussed earlier.
For the G-class, the likelihood with censoring for the case of L trajectories given in (26) takes the following form:
The resulting estimators and of the initial distribution law are provided by the following expressions:
and
Note that, the above results hold for any number of trajectories. For the special case of the parameter estimates take the following simplified form:
where represents the last sojourn censored time.
Choosing the appropriate estimator from those obtained in this section, we can now proceed to introduce the estimators of the main components , and of the semi-Markov model:
and
Parameter Estimation for Kumaraswamy Distribution
The estimator of the parameter for the Kumaraswamy distribution with in (1) and without censoring takes the following form:
Note that the maximum likelihood estimator of the shape parameter c is obtained by solving the equation given by the following:
Finally note that, in the censored case, the estimator of becomes:
5. Transition Matrix and Reliability Approach of Semi-Markov Processes
For the purpose of this section, the Markov renewal function, , , is defined as the following [29]:
where is the nth convolution of Q by itself.
For , the semi-Markov transition matrix is defined as follows [29]:
The main idea for a reliability analysis is that the space E is divided into two subsets—U, which contains the functioning states, and D, which contains the failure states—such that and , i.e., and . We also consider the corresponding restrictions of any matrix or matrix valued-function, for example, denoted by respectively. We denote by the semi-Markov transition matrix, by and the restrictions of induced by the corresponding restrictions of the semi-Markov kernel to the set U and D, respectively (attention: and are not the restrictions of to the sets U and D) and by and the restrictions of the initial law to the sets U and D, respectively. Finally, let be the restriction of the embedded Markov chain transition matrix to the set U. Having this in mind, one can furnish several reliability indices as those derived below. Indeed, for instance, the reliability function and the failure rate are given respectively by the following:
and
Furthermore, the availability and maintainability at time t for a semi-Markov system are defined respectively by the following (for details see [29,32]):
where and .
Finally, MTTF (the mean time to failure) is given by the following:
where is the restriction to set U of the mean sojourn time in state i, , which can be estimated by the following:
or
6. Simulations
The proposed methodology is evaluated via simulations for both cases of one sample path and several sample paths. In addition, the case of censoring is also taken into account in some of the above cases. More precisely, in the first part, we consider the case of a single sample path for several values of observation time M; in the second part, we assume L sample paths where and the observation time M is set to be 1000 where the real values for the parameters and the transition probabilities of the embedded Markov chain respectively are given below Table 1.
6.1. Single Sample Path
Table 2 provides the squared errors of the estimators for several values of observation time M in order to study their accuracy. As was expected, the estimators improve with respect to the squared error while the value of M is increasing ( and 1000).
6.2. Several Sample Paths
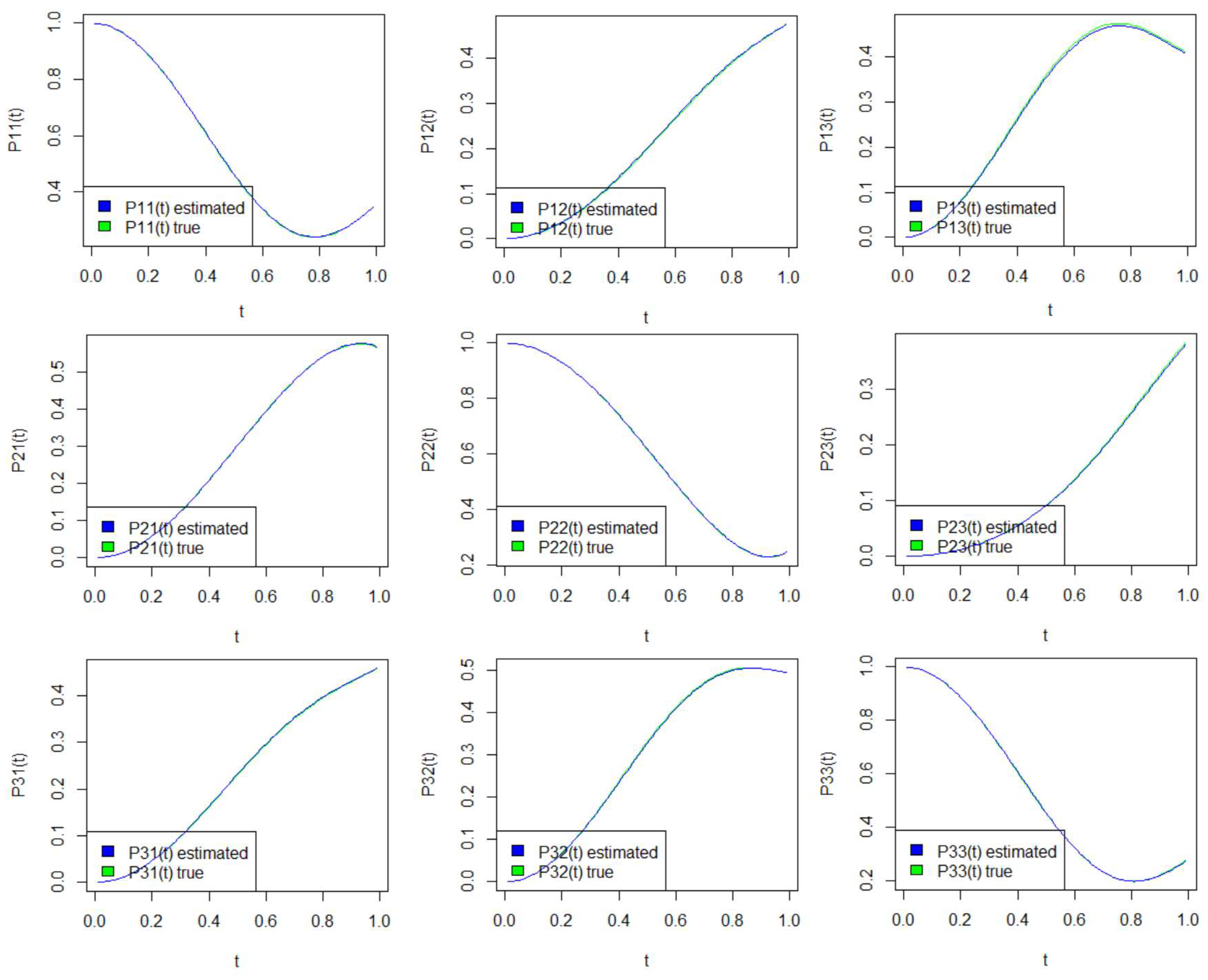
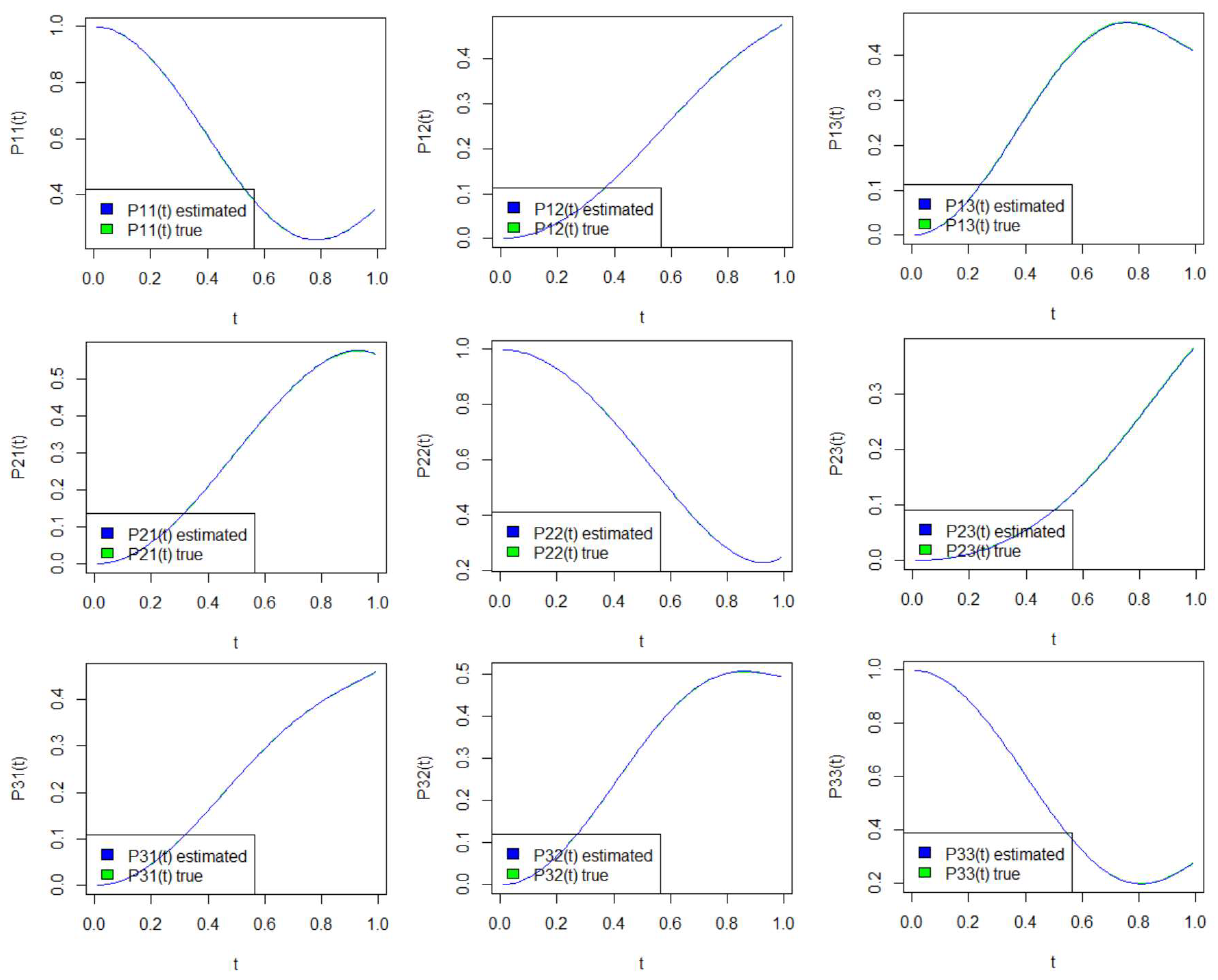
The results for the estimated transition probabilities of the semi-Markov process are provided in this subsection for various times t and for several sample paths, together with the associated standard errors. Table 3, Table 4 and Table 5 and Figure 1 refer to the uncensored case, while Table 6, Table 7 and Table 8 and Figure 2 refer to the censored case.
According to the results in Table 4 and Table 7, the estimators are more accurate as the number of trajectories is increasing. Furthermore, the estimator of the initial law (Table 3 and Table 6) seems to be very close to the target value for both the censored and the uncensored case.
According to the above results, observe that as long as the time is close to the lower limit of the domain (i.e., close to 0), it is more likely that the process will remain in the same state (see Table 9 and Table 10 and Figure 1 and Figure 2). However, as time goes on, this changes. More specifically, for , if the semi-Markov process is in state 1 at time 0, the most probable transition is to state 3. If the semi-Markov process starts at time 0 from state 2, the most probable transition is to state 1. If starting from state 3, the most probable transition is to state 2. For , the semi-Markov process will most likely transition to state 2, given that at time 0, it has started in state 1 or 3. Finally, if it was in state 2, the process would most likely move to state 1. For the overall behavior of the estimators of the transition probabilities, see Table 5 and Table 8, where the associated standard errors are provided.
6.3. Reliability Parameter Estimation
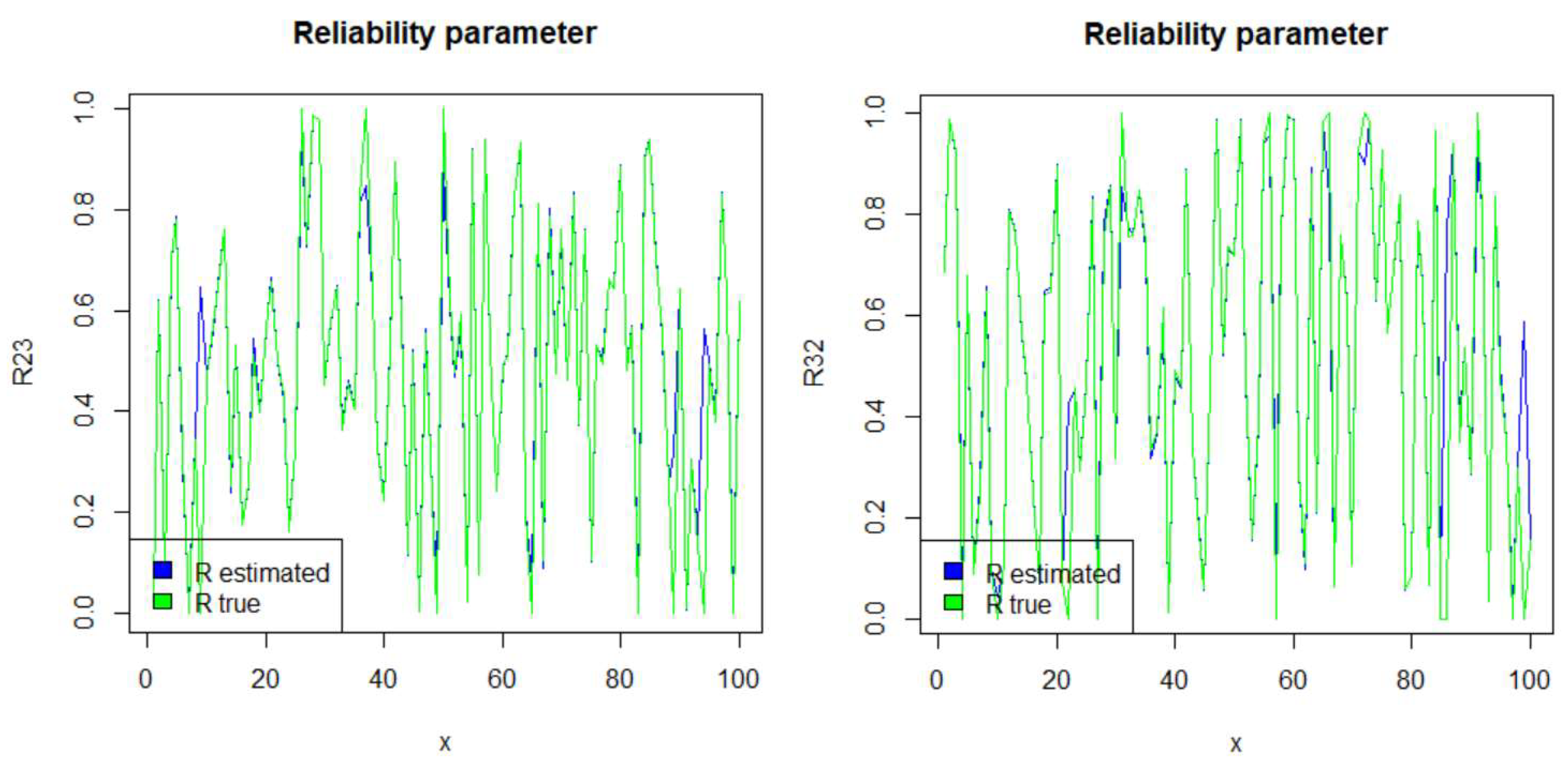
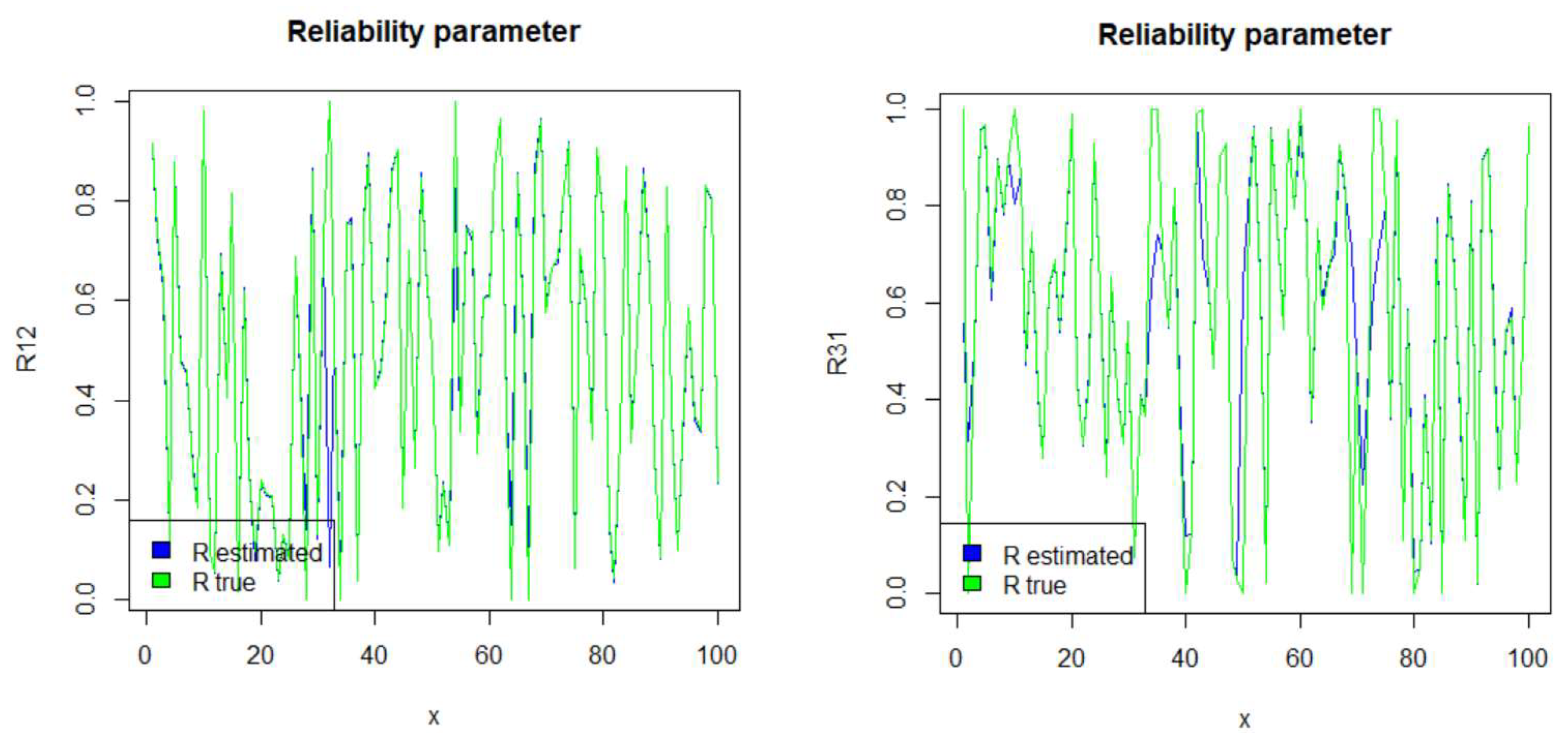
In engineering, one of the main problems of interest is the event that the system remains in a working state during the whole observation period. As mentioned in the introduction, the performance of a system in mechanical engineering is evaluated via the reliability parameter. Such a system stays in a functioning condition as long as the stress (pressure) Y is at a lower level than the strength X. In general, in a multi-state system, the transition from one state to another may be defined according to whether a component of the system fails due to the fact that the stress exceeds the strength. In this section, we provide the performance of the estimator of the reliability parameter when X and Y follow the Kumaraswamy distribution with shape parameters and , respectively. Observe that in Figure 3 and Figure 4, the estimated values (in blue) almost coincide with the true values (in green). We provide here the simulated results of the reliability parameter, using, for illustrative purposes, selected states i and j from the previous section. The notation refers to the reliability parameter for i and j.
Author Contributions
All authors contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors wish to express their appreciation for the anonymous reviewers and the academic editor for their valuable and constructive comments that greatly improved the quality of the manuscript. This work was completed while the third author was a postodoctoral researcher at the Laboratory of Statistics and Data Analysis of the University of the Aegean.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| K | Kumaraswamy distribution |
| U | Uniform distribution |
| Exp | Exponential distribution |
| SMP | Semi-Markov process |
| MRP | Markov renewal process |
| MTTF | Mean time to failure |
| S.E. | Squared errors |
References
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Jones, M.C. Kumaraswamy’s distribution: A beta-type distribution with some tractability advantages. Stat. Methodol. 2008, 6, 70–81. [Google Scholar] [CrossRef]
- Kohansal, A. On estimation of reliability in a multicomponent stress-strength model for a Kumaraswamy distribution based on progressively censored sample. Stat. Pap. 2019, 60, 2185–2224. [Google Scholar] [CrossRef]
- Mitnik, P.A. New Properties of the Kumaraswamy Distribution. Comm. Stat. Theory Methods 2013, 42, 741–755. [Google Scholar] [CrossRef]
- Fletcher, S.G.; Ponnambalam, K. Estimation of reservoir yield and storage distribution using moments analysis. J. Hydrol. 1996, 182, 259–275. [Google Scholar] [CrossRef]
- Ganji, A.; Ponnambalam, K.; Khalili, D.; Karamouz, M. Grain yield reliability analysis with crop water demand uncertainty. Stoch. Environ. Res. Risk Assess. 2006, 2, 259–277. [Google Scholar] [CrossRef]
- Nadar, M.; Papadopoulos, A.; Kizilaslan, F. Statistical analysis for Kumaraswamy’s distribution based on record data. Stat. Pap. 2013, 54, 355–369. [Google Scholar] [CrossRef]
- Courard-Hauri, D. Using Monte Carlo analysis to investigate the relationship between overconsumption and uncertain access to one’s personal utility function. Ecol. Econ. 2007, 64, 152–162. [Google Scholar] [CrossRef]
- Seifi, A.; Ponnambalam, K.; Vlach, J. Maximization of manufacturing yield of systems with arbitrary distributions of component values. Ann. Oper. Res. 2000, 99, 373–383. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Edwin, M.M.; Ortega, S.N. The Kumaraswamy Weibull distribution with application to failure data. J. Franklin Inst. 2010, 347, 1399–1429. [Google Scholar] [CrossRef]
- Ghosh, I. On the reliability for some bivariate dependent Beta and Kumaraswamy distributions: A brief survey. Stoch. Qual. Control 2019, 34, 115–121. [Google Scholar] [CrossRef]
- Gilchrist, W.G. Statistical Modelling with Quantile Functions; Chapman & Hall/CRC: Boca Raton, FL, USA, 2001. [Google Scholar]
- Mitnik, P.A.; Baek, S. The Kumaraswamy distribution: Median-dispersion re-parameterizations for regression modeling and simulation-based estimation. Stat. Pap. 2013, 54, 177–192. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Castro, M. A new family of generalized distributions. J. Stat. Comput. Simul. 2011, 81, 883–898. [Google Scholar] [CrossRef]
- Eugene, N.; Lee, C.; Famoye, F. Beta-normal distribution and its applications. Comm. Stat. Theory Methods 2002, 31, 497–512. [Google Scholar] [CrossRef]
- Jones, M.C. Families of distributions arising from distributions of order statistics (with discussion). Test 2004, 13, 1–43. [Google Scholar] [CrossRef]
- Awad, A.M.; Azzam, M.M.; Hamdan, M.A. Some inference results on Pr(X < Y) in the bivariate exponential model. Comm. Stat. Theory Methods 1981, 10, 2515–2524. [Google Scholar]
- Church, J.D.; Harris, B. The estimation of reliability from stress strength relationships. Technometrics 1970, 12, 49–54. [Google Scholar] [CrossRef]
- Constantine, K.; Karson, M. Estimation of P(Y < X) in gamma case. Comm. Stat. Simul. Comput. 1986, 15, 365–388. [Google Scholar]
- Kotz, S.; Lumelskii, Y.; Pensky, M. The Stress-Strength Model and Its Generalizations. Theory and Applications; World Scientific: Singapore, 2003. [Google Scholar]
- Weerahandi, S.; Johnson, R.A. Testing reliability in a stress-strength model when X and Y are normally distributed. Technometrics 1992, 34, 83–91. [Google Scholar] [CrossRef]
- Balasubramanian, K.; Beg, M.I.; Bapat, R.B. On families of distributions closed under extrema. Sankhya A 1991, 53, 375–388. [Google Scholar]
- Barbu, V.S.; Karagrigoriou, A.; Makrides, A. Semi-Markov Modelling for Multi-State Systems. Methodol. Comput. Appl. Probab. 2017, 19, 1011–1028. [Google Scholar] [CrossRef]
- Slud, E.V.; Vonta, F. Efficient semiparametric estimators via modified profile likelihood. J. Stat. Plan. Inference 2005, 129, 339–367. [Google Scholar] [CrossRef]
- Asanjarani, A.; Liquet, B.; Nazarathy, Y. Estimation of semi-Markov multi-state models: A comparison of the sojourn times and transition intensities approaches. Int. J. Biostat. 2020. [Google Scholar] [CrossRef]
- Barbu, V.; Boussemart, M.; Limnios, N. Discrete-time semi-Markov model for reliability and survival analysis. Comm. Stat. Theory Methods 2004, 33, 2833–2868. [Google Scholar] [CrossRef]
- D’Amico, G.; Manca, R.; Petroni, F.; Selvamuthu, D. On the Computation of Some Interval Reliability Indicators for Semi-Markov Systems. Mathematics 2021, 9, 575. [Google Scholar] [CrossRef]
- Janssen, J.; Manca, R. Semi-Markov Risk Models for Finance, Insurance and Reliability; Springer: New York, NY, USA, 2007. [Google Scholar]
- Limnios, N.; Oprişan, G. Semi-Markov Processes and Reliability; Birkhäuser: Boston, MA, USA, 2001. [Google Scholar]
- Lisnianski, A.; Frenkel, I.; Karagrigoriou, A. Recent Advances in Multi-State Reliability, Theory and Applications; Springer Series in Reliability Engineering; Springer: Berlin, Germany, 2018. [Google Scholar]
- Lisnianski, A.; Levitin, G. Multi-State System Reliability: Assessment, Optimization and Applications; World Scientific: Singapore, 2003. [Google Scholar]
- Ouhbi, B.; Limnios, N. Non-parametric estimation for semi-Markov kernels with application to reliability analysis. Appl. Stoch. Models Data Anal. 1996, 12, 209–220. [Google Scholar] [CrossRef]
Figure 1.
Real and estimated semi-Markov transition probabilities in the case of uncensored trajectories.
Figure 1.
Real and estimated semi-Markov transition probabilities in the case of uncensored trajectories.

Figure 2.
Real and estimated semi-Markov transition probabilities in the case of censored trajectories.
Figure 2.
Real and estimated semi-Markov transition probabilities in the case of censored trajectories.

Figure 3.
Reliability parameters for the case of uncensored trajectories.

Figure 4.
Reliability parameters for the case of censoring at the beginning and/or at the end.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Real values for the parameters and transition probabilities .
| 1 | 2 | 3 | 1 | 2 | 3 | ||
|---|---|---|---|---|---|---|---|
| 1 | 0 | 0.9 | 2.1 | 1 | 0 | 0.3 | 0.7 |
| 2 | 1.5 | 0 | 0.3 | 2 | 0.833 | 0 | 0.167 |
| 3 | 1.2 | 1.8 | 0 | 3 | 0.4 | 0.6 | 0 |
Table 2.
Squared errors (S.E.) for the estimators of and in the case of no censoring, for various values of M.
Table 2.
Squared errors (S.E.) for the estimators of and in the case of no censoring, for various values of M.
| M | 10 | 50 | 100 | 1000 |
|---|---|---|---|---|
| S.E. | ||||
| S.E. |
Table 3.
The estimated values of the initial law in the case of trajectories without censoring.
| i | 1 | 2 | 3 |
|---|---|---|---|
| 0.319 | 0.355 | 0.326 |
Table 4.
Squared errors (S.E.) for the estimators of and in the case of no censoring, for various values of L.
Table 4.
Squared errors (S.E.) for the estimators of and in the case of no censoring, for various values of L.
| L | 5 | 10 | 100 | 1000 |
|---|---|---|---|---|
| S.E. | ||||
| S.E. |
Table 5.
Squared errors (S.E.) for the estimators of the semi-Markov transition probabilities in the case of no censoring.
Table 5.
Squared errors (S.E.) for the estimators of the semi-Markov transition probabilities in the case of no censoring.
| t | 0.1 | 0.2 | 0.5 | 0.9 |
|---|---|---|---|---|
| S.E. |
Table 6.
The estimated values of the initial law in the case of trajectories with censoring at the beginning and/or at the end.
Table 6.
The estimated values of the initial law in the case of trajectories with censoring at the beginning and/or at the end.
| i | 1 | 2 | 3 |
|---|---|---|---|
| 0.328 | 0.328 | 0.344 |
Table 7.
Squared errors (S.E.) for the estimators of and in the case of censoring at the beginning and/or at the end, for various values of L.
Table 7.
Squared errors (S.E.) for the estimators of and in the case of censoring at the beginning and/or at the end, for various values of L.
| L | 5 | 10 | 100 | 1000 |
|---|---|---|---|---|
| S.E. | ||||
| S.E. |
Table 8.
Squared errors for the estimators of the semi-Markov transition probabilities in the case of censoring at the beginning and/or at the end.
Table 8.
Squared errors for the estimators of the semi-Markov transition probabilities in the case of censoring at the beginning and/or at the end.
| t | 0.1 | 0.2 | 0.5 | 0.9 |
|---|---|---|---|---|
| S.E. |
Table 9.
Estimators for the transition probabilities of the semi-Markov process for and .
| 1 | 2 | 3 | 1 | 2 | 3 | ||
|---|---|---|---|---|---|---|---|
| 1 | 0.970 | 0.009 | 0.021 | 1 | 0.456 | 0.200 | 0.358 |
| 2 | 0.014 | 0.983 | 0.003 | 2 | 0.288 | 0.625 | 0.096 |
| 3 | 0.012 | 0.017 | 0.971 | 3 | 0.226 | 0.326 | 0.460 |
Table 10.
Estimators for the transition probabilities of the semi-Markov process for and .
| 1 | 2 | 3 | 1 | 2 | 3 | ||
|---|---|---|---|---|---|---|---|
| 1 | 0.254 | 0.334 | 0.470 | 1 | 0.276 | 0.387 | 0.337 |
| 2 | 0.459 | 0.383 | 0.202 | 2 | 0.466 | 0.207 | 0.327 |
| 3 | 0.345 | 0.470 | 0.239 | 3 | 0.365 | 0.408 | 0.227 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Barbu, V.S.; Karagrigoriou, A.; Makrides, A. Reliability and Inference for Multi State Systems: The Generalized Kumaraswamy Case. Mathematics 2021, 9, 1834. https://0-doi-org.brum.beds.ac.uk/10.3390/math9161834
AMA Style
Barbu VS, Karagrigoriou A, Makrides A. Reliability and Inference for Multi State Systems: The Generalized Kumaraswamy Case. Mathematics. 2021; 9(16):1834. https://0-doi-org.brum.beds.ac.uk/10.3390/math9161834
Chicago/Turabian StyleBarbu, Vlad Stefan, Alex Karagrigoriou, and Andreas Makrides. 2021. "Reliability and Inference for Multi State Systems: The Generalized Kumaraswamy Case" Mathematics 9, no. 16: 1834. https://0-doi-org.brum.beds.ac.uk/10.3390/math9161834
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.