
3D-DCDAE: Unsupervised Music Latent Representations Learning Method Based on a Deep 3D Convolutional Denoising Autoencoder for Music Genre Classification


Abstract
:1. Introduction
- Unlike most existing research, the proposed method utilizes music data in MIDI format as input, which allows the model to consider a variety of music features. In addition, the MRN process is designed based on the musicology structure of music, which allows the model to focus on the unique structure of the music.
- Based on unsupervised learning, 3D-DCDAE can extract latent representations from large amounts of unlabeled data which can increase the generalization ability of the model. The 3D-DCDAE can be considered a powerful feature extractor. In addition, the inner structure of 3D-DCDAE is 3D-VGG so that the spatial relationships of multi-track MIDI files can be explored.
- The MLP classifier is connected after the trained 3D-DCDAE to implement music genre classification. Experimental results show that even when a small amount of labeled data is utilized and the dataset is not balanced, the model can still perform well in music genre classification.
- Experiments were conducted on the Lakh MIDI dataset to evaluate the performance of the proposed method. The results indicate that the proposed method is superior to other methods.
2. Related Works
2.1. Music Genre Classification
2.2. Comparison of Music Genre Classification Based on Deep Learning
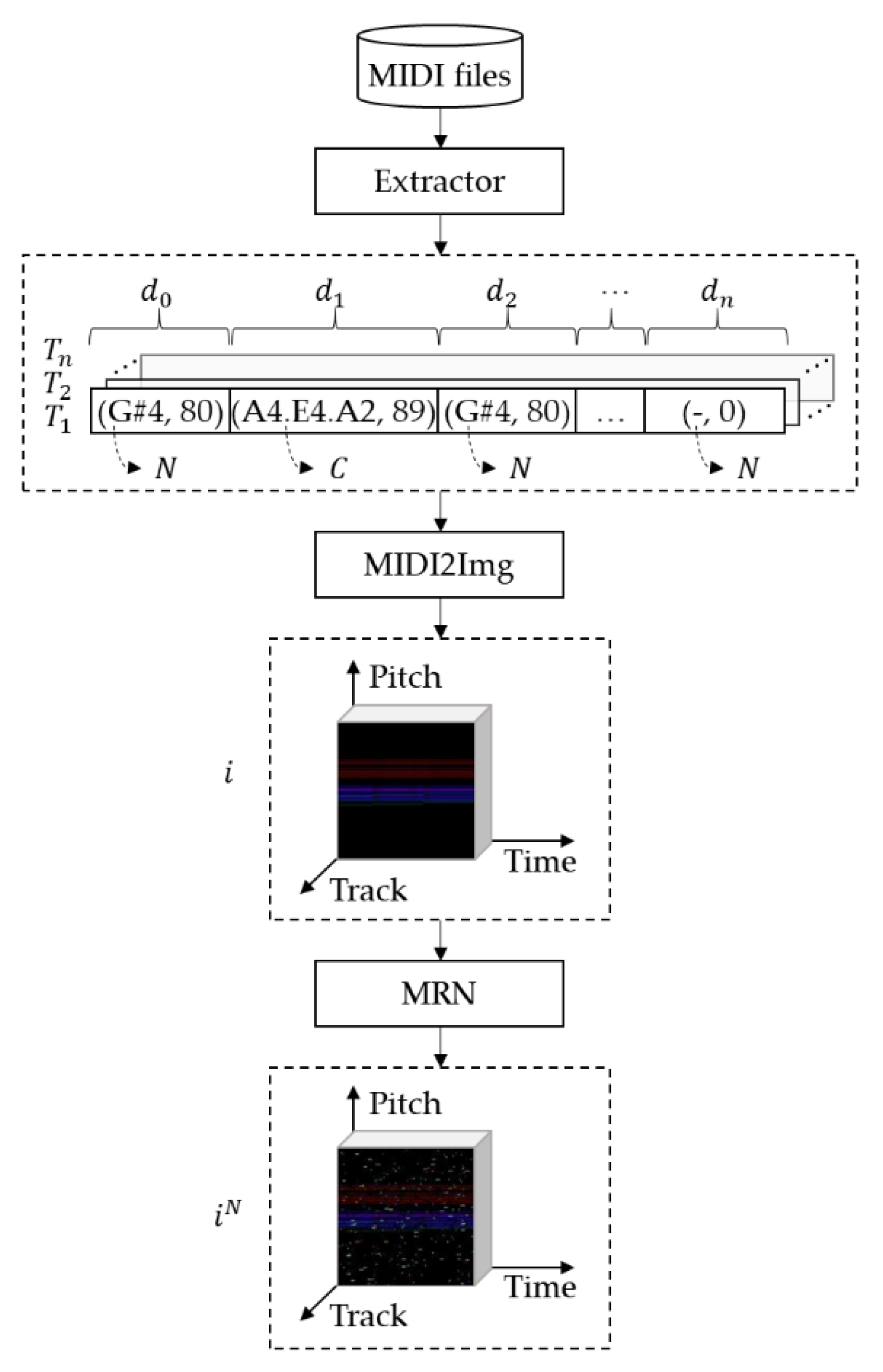
3. Music Genre Classification System Based on 3D-DCDAE
3.1. Overview
3.2. MIDI Preprocessing
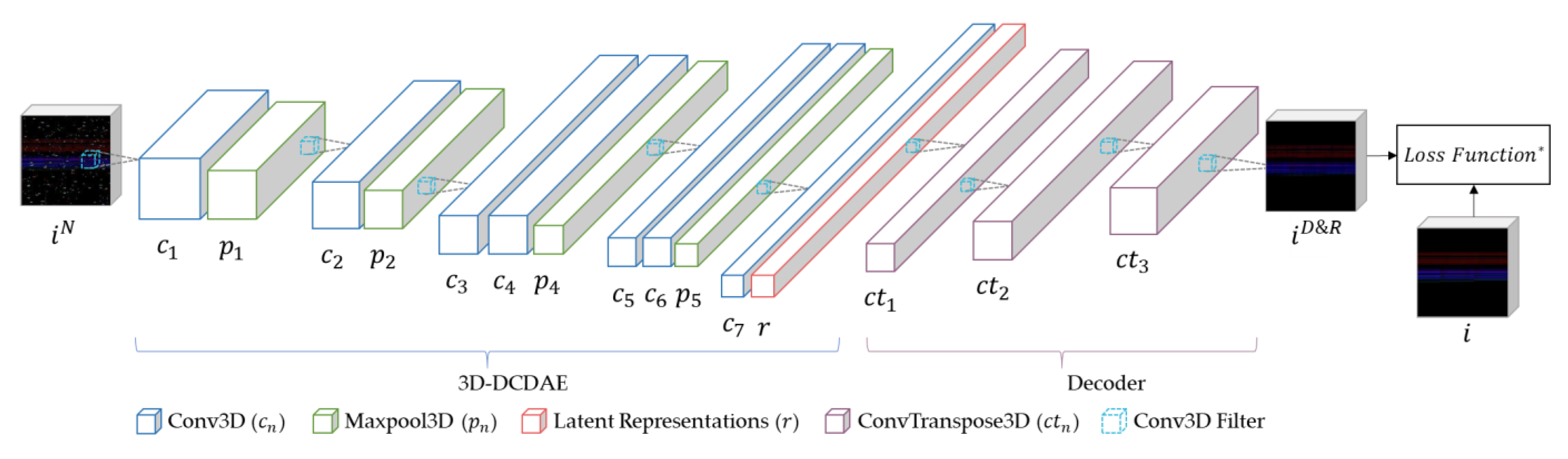
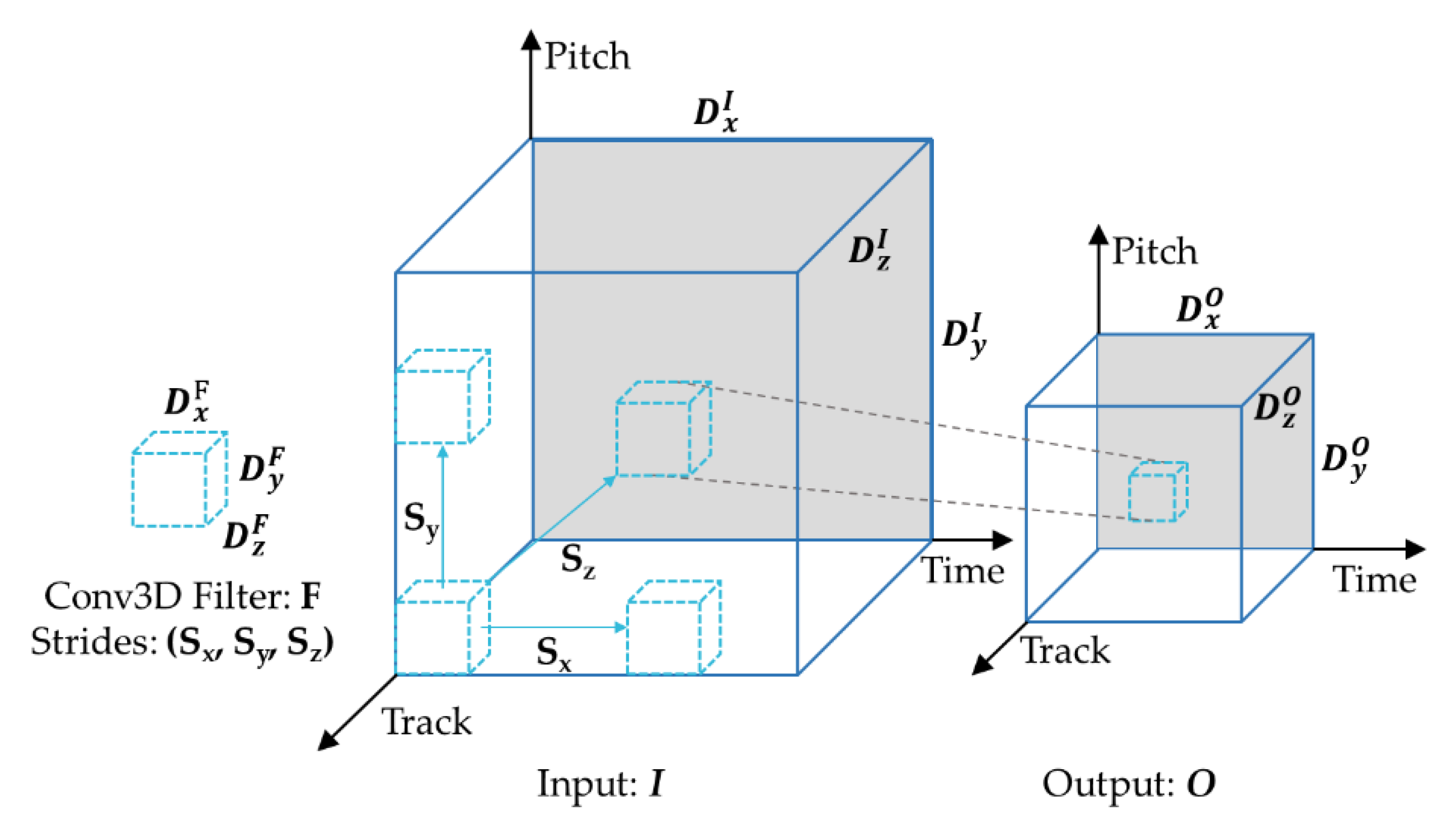
3.3. 3D-DCDAE for Latent Representations
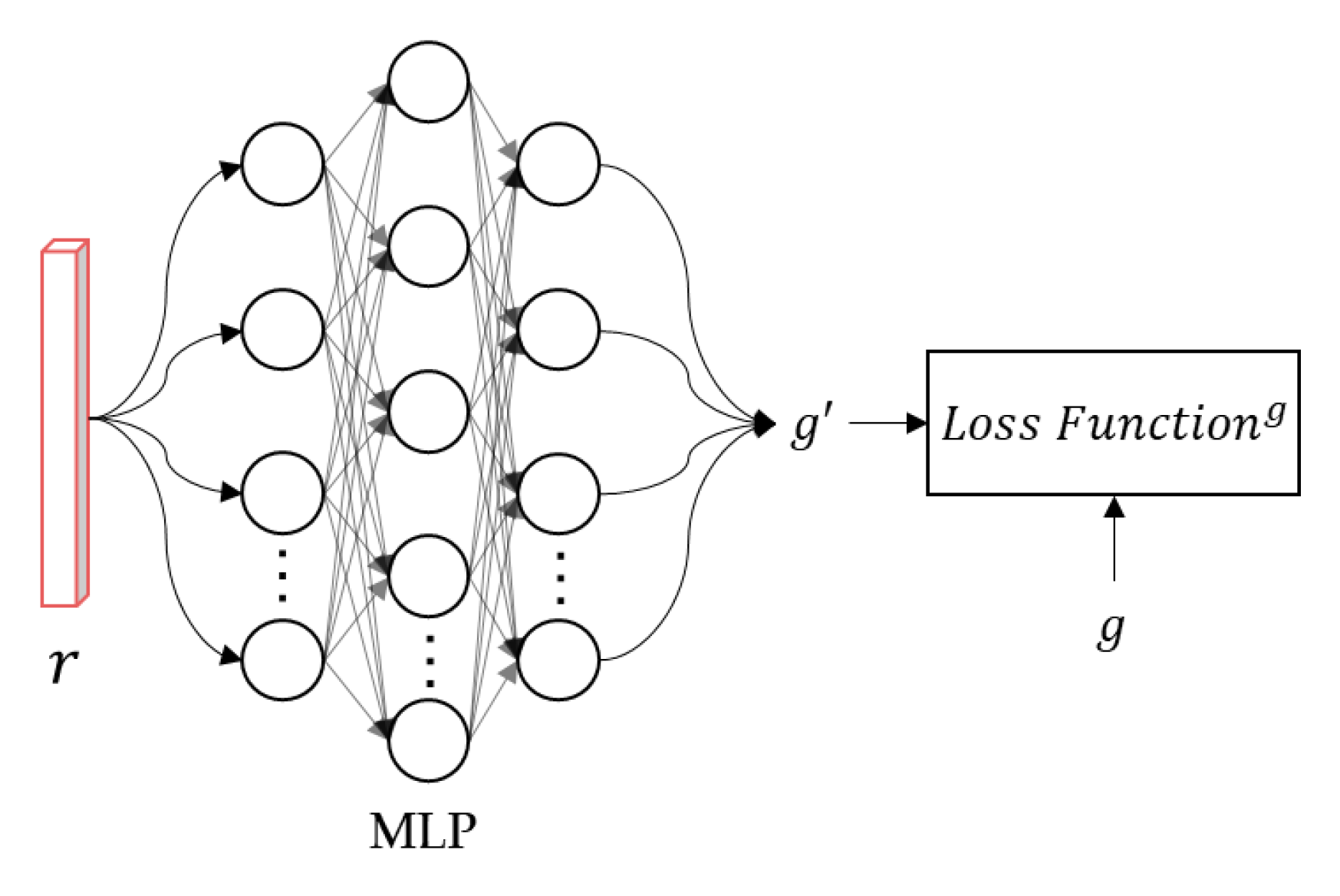
3.4. MLP Classifier
4. Experiment
4.1. Experimental Objectives
4.2. Experimental Environment
4.3. Experimental Data
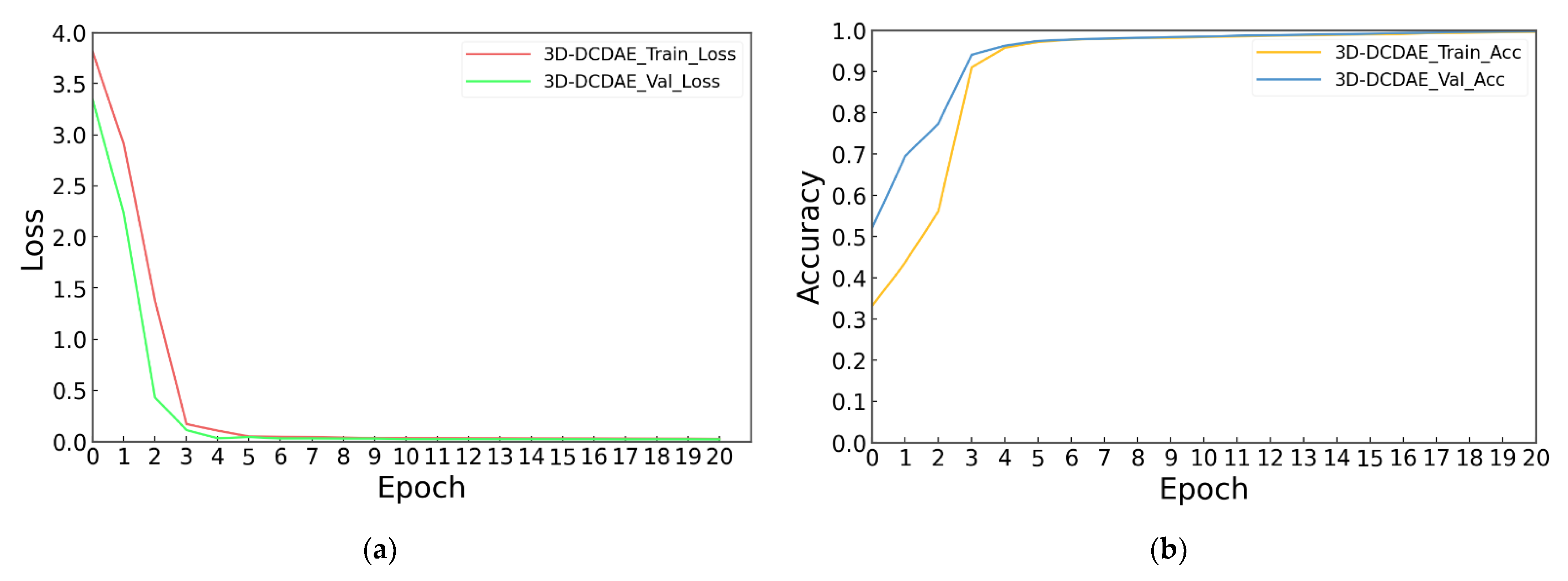
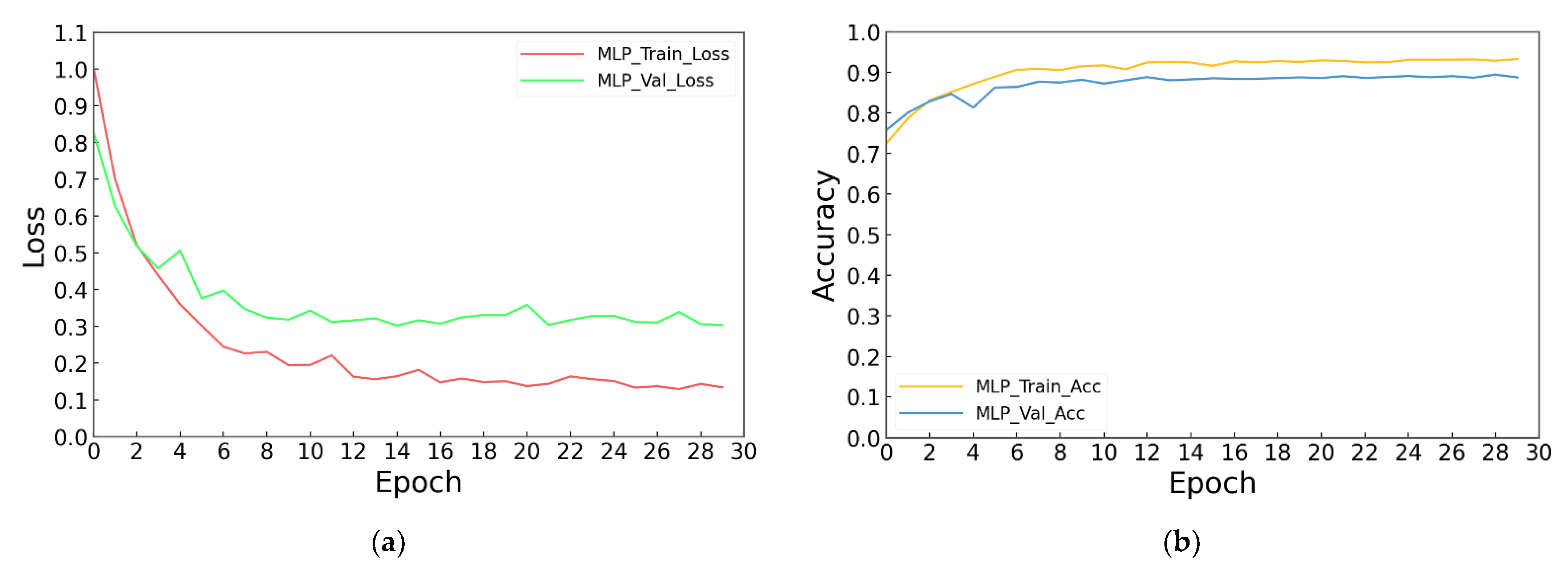
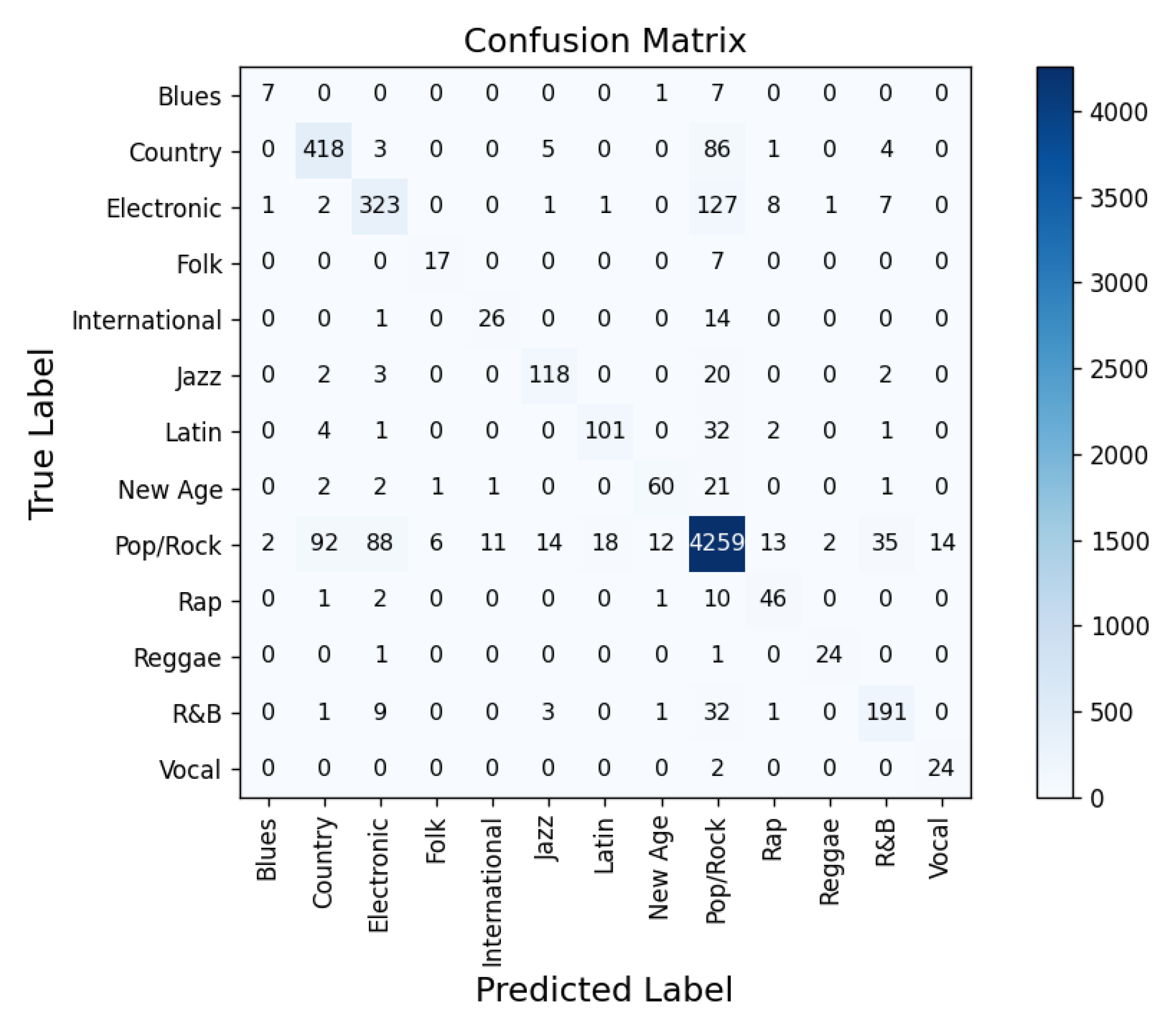
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nam, J.; Choi, K.; Lee, J.; Chou, S.Y.; Yang, Y.H. Deep learning for audio-based music classification and tagging: Teaching computers to distinguish rock from bach. IEEE Signal Process. Mag. 2018, 36, 41–51. [Google Scholar] [CrossRef]
- Jang, S.; Li, S.; Sung, Y. Fasttext-based Local Feature Visualization Algorithm for Merged Image-based Malware Classification Framework for Cyber Security and Cyber defense. Mathematics 2020, 8, 460. [Google Scholar] [CrossRef] [Green Version]
- Kim, E.; Jang, S.; Li, S.; Sung, Y. Newspaper article-based agent control in smart city simulations. Human-Cent. Comput. Inf. Sci. 2020, 10, 1–19. [Google Scholar] [CrossRef]
- Rahardwika, D.S.; Rachmawanto, E.H.; Sari, C.A.; Irawan, C.; Kusumaningrum, D.P.; Trusthi, S.L. Comparison of SVM, KNN, and NB Classifier for Genre Music Classification based on Metadata. In Proceedings of the 2020 International Seminar on Application for Technology of Information and Communication (iSemantic), Semarang, Indonesia, 21–22 September 2020; pp. 12–16. [Google Scholar]
- Dong, M. Convolutional neural network achieves human-level accuracy in music genre classification. arXiv 2018, arXiv:1802.09697. [Google Scholar]
- Costa, Y.M.; Oliveira, L.S.; Silla, C.N., Jr. An evaluation of convolutional neural networks for music classification using spectrograms. Appl. Soft Comput. 2017, 52, 28–38. [Google Scholar] [CrossRef]
- Zhang, W.; Lei, W.; Xu, X.; Xing, X. Improved music genre classification with convolutional neural networks. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 3304–3308. [Google Scholar]
- Yu, Y.; Luo, S.; Liu, S.; Qiao, H.; Liu, Y.; Feng, L. Deep attention-based music genre classification. Neurocomputing 2020, 372, 84–91. [Google Scholar] [CrossRef]
- Song, G.; Wang, Z.; Han, F.; Ding, S.; Iqbal, M.A. Music auto-tagging using deep recurrent neural networks. Neurocomputing 2018, 292, 104–110. [Google Scholar] [CrossRef]
- Qiu, L.; Li, S.; Sung, Y. DBTMPE: Deep bidirectional transformers-based masked predictive encoder approach for music genre classification. Mathematics 2021, 9, 530. [Google Scholar] [CrossRef]
- Zhou, J.; Peng, L.; Chen, X.; Yang, D. Robust sound event classification by using denoising autoencoder. In Proceedings of the 2016 IEEE 18th International Workshop on Multimedia Signal Processing (MMSP), Montreal, QC, Canada, 21–23 September 2016; pp. 1–6. [Google Scholar]
- Sarkar, R.; Biswas, N.; Chakraborty, S. Music genre classification using frequency domain features. In Proceedings of the 2018 Fifth International Conference on Emerging Applications of Information Technology (EAIT), IIEST, Howrah, India, 12–13 January 2018; pp. 1–4. [Google Scholar]
- Lee, J.; Lee, M.; Jang, D.; Yoon, K. Korean Traditional Music Genre Classification Using Sample and MIDI Phrases. KSII Trans. Internet Inf. Syst. 2018, 12, 1869–1886. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- The Lakh MIDI Dataset. Available online: https://colinraffel.com/projects/lmd/ (accessed on 1 October 2020).
- Fulzele, P.; Singh, R.; Kaushik, N.; Pandey, K. A hybrid model for music genre classification using LSTM and SVM. In Proceedings of the 2018 Eleventh International Conference on Contemporary Computing (IC3), Noida, India, 2–4 August 2018; pp. 1–3. [Google Scholar]
- Choi, K.; Fazekas, G.; Sandler, M.; Cho, K. Convolutional recurrent neural networks for music classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2392–2396. [Google Scholar]
- Dieleman, S.; Schrauwen, B. End-to-end learning for music audio. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 6964–6968. [Google Scholar]
- Lee, J.; Park, J.; Kim, K.L.; Nam, J. Samplecnn: End-to-end deep convolutional neural networks using very small filters for music classification. Appl. Sci. 2018, 8, 150. [Google Scholar] [CrossRef] [Green Version]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked convolutional auto-encoders for hierarchical feature extraction. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 52–59. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Chorowski, J.; Weiss, R.J.; Bengio, S.; Van den Oord, A. Unsupervised speech representation learning using wavenet autoencoders. IEEE ACM Trans. Audio Speech Lang. Process. 2019, 27, 2041–2053. [Google Scholar] [CrossRef] [Green Version]
- Naranjo-Alcazar, J.; Perez-Castanos, S.; Zuccarello, P.; Antonacci, F.; Cobos, M. Open set audio classification using autoencoders trained on few data. Sensors 2020, 20, 3741. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C. Mean squared error: Love it or leave it? A new look at signal fidelity measures. IEEE Signal Process. Mag. 2009, 26, 98–117. [Google Scholar] [CrossRef]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Cuthbert, M.S.; Ariza, C.; Friedland, L. Feature Extraction and Machine Learning on Symbolic Music using the music21 Toolkit. In Proceedings of the 12th International Society for Music Information Retrieval Conference (ISMIR), Miami, FL, USA, 24–28 October 2011; pp. 387–392. [Google Scholar]
- McFee, B.; Bertin-Mahieux, T.; Ellis, D.P.; Lanckriet, G.R. The million song dataset challenge. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 909–916. [Google Scholar]
- McKay, C.; Cumming, J.; Fujinaga, I. JSYMBOLIC 2.2: Extracting features from symbolic music for use in musicological and MIR research. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), Paris, France, 23–27 September 2018; pp. 348–354. [Google Scholar]
- Ferraro, A.; Lemström, K. On large-scale genre classification in symbolically encoded music by automatic identification of repeating patterns. In Proceedings of the 5th International Conference on Digital Libraries for Musicology, Paris, France, 28 September 2018; pp. 34–37. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Contents | Deep RNN [9] | Machine Learning [13] | CRNN [17] | Sample-CNN [19] | The Proposed Method |
|---|---|---|---|---|---|
| Input Feature | Scattering Transformed | MIDI to String | Mel-spectrogram | Raw Waveform | MIDI2Img |
| Neural Network | Deep GRU | Normalized Compression Distance | CRNN | Very Deep CNN | 3D-DCDAE |
| Hyper Parameter | Value |
|---|---|
| 15% | |
| 80% | |
| 10% | |
| 10% |
| Hyper Parameter | Value |
|---|---|
| Batch size | 32 |
| Width/Height | 128 |
| Tracks | 3 |
| Input size | (32, 128, 128, 3) |
| Learning rate | 0.01 |
| Warm-up steps | 1000 |
| Epochs | 20 |
| Optimizer | Adam |
| Output size | (32, 128, 128, 3) |
| Hyper Parameter | Value |
|---|---|
| Input size | (32, 128, 128, 3) |
| Learning rate of 3D-DCDAE | 5 × 10−5 |
| Learning rate of MLP classifier | 5 × 10−4 |
| Batch size | 32 |
| Optimizer | Adam |
| Output size | (32, 13) |
| Genre | Number of MIDI | Number of MIDI Images |
|---|---|---|
| Pop/Rock | 8603 | 45,259 |
| Country | 962 | 5381 |
| Electronic | 694 | 4713 |
| R&B | 475 | 7557 |
| Latin | 293 | 1410 |
| Jazz | 280 | 1538 |
| New Age | 230 | 878 |
| Rap | 117 | 565 |
| International | 86 | 491 |
| Reggae | 69 | 344 |
| Folk | 64 | 281 |
| Vocal | 41 | 230 |
| Blues | 32 | 164 |
| Total | 11,946 | 68,811 |
| Evaluation Indicators | Results |
|---|---|
| Accuracy | 0.8830 |
| Precision | 0.8823 |
| Recall | 0.8830 |
| F1-score | 0.8821 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, L.; Li, S.; Sung, Y. 3D-DCDAE: Unsupervised Music Latent Representations Learning Method Based on a Deep 3D Convolutional Denoising Autoencoder for Music Genre Classification. Mathematics 2021, 9, 2274. https://0-doi-org.brum.beds.ac.uk/10.3390/math9182274
Qiu L, Li S, Sung Y. 3D-DCDAE: Unsupervised Music Latent Representations Learning Method Based on a Deep 3D Convolutional Denoising Autoencoder for Music Genre Classification. Mathematics. 2021; 9(18):2274. https://0-doi-org.brum.beds.ac.uk/10.3390/math9182274
Chicago/Turabian StyleQiu, Lvyang, Shuyu Li, and Yunsick Sung. 2021. "3D-DCDAE: Unsupervised Music Latent Representations Learning Method Based on a Deep 3D Convolutional Denoising Autoencoder for Music Genre Classification" Mathematics 9, no. 18: 2274. https://0-doi-org.brum.beds.ac.uk/10.3390/math9182274