1. Introduction
A flash flood is caused by heavy rain associated with a severe thunderstorm, hurricane, etc. which are physical phenomena occurring in rapid flooding of low-lying areas such as plains, rivers, and dry lakes. The flash flood is different to the regular flood presenting a narrow scale of less than 6 h between rainfall and flooding. Since the flash flood can occur without any warning, people can be seriously injured or be killed by the flash flood with large debris such as boulders that make heavy structural damage to homes and buildings. Large debris cause the structural damage on bridges and roadways, power infrastructures, telephone infrastructures and cable lines as well. The flash flooding frequently results in loss of properties, agricultural production and other long term negative economic impacts and types of suffering, which can trigger mass migrations or population displacements. As the danger of flash flood increases, it is necessary to design effective Early Warning Systems (EWS) supporting the early detection and recognition of the flash flood [
1,
2,
3].
In order to detect the flash flood from satellite images, various Machine Learning (ML) methods were presented in the literature. Sahoo et al. [
4] proposed the application of an Artificial Neural Network (ANN) for assessing the flash floods using measured data by using backpropagation to train the network. They utilized a dataset which included 5-min-frequency water quality data and 15-min-frequency rainfall data collected during a period of 20 years from two rain gauge stations. Their experiments introduced ANN models as they are relatively simple ML methods to be applied, while simultaneously requiring expert knowledge in the form of input provided by the users. In addition, their ANN prediction model showed great ability to deal with a dataset of Low Back Pain (LBP) and established the decision-making system. Heiser et al. [
5] proposed a Naive Bayes Tree (NBT) and a Decision Tree (DT) based flash flood prediction model, using geomorphological disposition parameters. Sudhishri et al. [
6] compared the evaluation of ANN and Recurrent Neural Network (RNN) based flash flood models. Jimeno-Sáez et al. [
7] modeled the flash floods using ANN and Adaptive Neuro-Fuzzy Inference System (ANFIS) on a dataset collected from 14 different streamflow gauge stations. Root Mean Square Error (RMSE) and R Square (R2) were used as evaluation criteria. The results showed that ANFIS demonstrated a considerably superior ability to estimate real-time flash floods compared to ANN. Hong et al. [
8] proposed a hybrid forecasting technique, called RSVRCPSO, to accurately estimate heavy and extreme rainfall occurrences. RSVRCPSO is an integration of RNN, support vector regression (SVR) and a Chaotic Particle Swarm Optimization algorithm (CPSO). Khosravi et al. [
9] proposed decision tree-based algorithms for the flash flood at hazard watershed occurred in northern Iran. Hsu et al. [
10] proposed a hybrid model from the integration of the Flash-Flood Routing Model (FFRM) and ANN, called the FFRM–ANN model, to predict flash flood. Another ANN is from Sharma et al. [
11] with self-management of low back pain. The authors used the traditional ML method for involving in the flash flood problem, so that the following paragraph will revoke some of the applications of the Deep Learning methods in various fields.
In the manufacturing industry, Wang et al. [
12] presented deep learning algorithms to provide advanced tools to improve a system performance and a decision-making system. Various deep learning models were compared on handling big data of manufactures to making manufacturing “smart”. In the power industry, to detect and reduce the risk at the first stage of wind turbines, Helbing and Ritter [
13] utilized forward deep Neural Network (NN) to create an effective condition monitoring. Wang et al. [
14] reviewed several methods of deep learning for renewable energy forecasting. They divided the existing deterministic and probabilistic forecasting methods, which are intrinsic motivation of deep learning into various groups. Qiao et al. [
15] investigated handwritten digit recognition using an adaptive deep Q-learning strategy. By combining the feature maps extracted by deep learning and the capability of decision making given by reinforcement learning, they formed the adaptive Q-learning deep belief network (Q-ADBN). To optimize the algorithm, the Q-function was used to maximize the extracted features considered as the current states. The papers showed the application of deep NN in various fields such as manufacturing, power, but there were no one which applies into the flash flood fields such as the classification and segmentation problems.
In the self-driving field, Fujiyoshi et al. [
16] explained how deep learning can be applied in the field of the autonomous driving based on an image recognition problem. Further, the latest trends and methods of deep learning models applied to this field were also introduced. In another field of driving, namely speed prediction, Yan et al. [
17] focused on a vehicle speed prediction using a deep learning model. Several driving factors affecting on the accuracy of the prediction of the model are considered and analyzed. The papers are instances of the application of the Deep Learning model in the self-driving field, so that it is necessary to mention to the articles used for the flash flood classification.
Recently, Deep Learning has been also effectively used to detect floods with high accuracy. In general, there are several Deep Learning based decision making and forecasting techniques proposed in the literature. For example, Wason [
18] proposed a new deep learning method with hidden abilities of deep Neural Network (NN) that are close to human performance in many tasks. Anbarasan [
19] combined IoT, big data and convolutional neural networks for the flood detection. The data collected by IoT sensors are considered as big data. After that, normalization and imputation algorithm are applied to pre-process, which is then used as inputs of convolutional deep neural network to classify whether these inputs are the occurrence of flood or not. For the satellite image classification, Singh and Singh [
20] presented a Radial Basic Function Neural Network (RBFNN) using a Genetic Algorithm (GA) for detecting flood in a particular area. The RBFNN was used because it accepts noise and unseen satellite images as inputs. Then, the proposed model is trained by the GA algorithm in order to output the high classification performance. The flood Detection and Service (FD&S) has also a crucial role in the decision-making problem and the flood detection through Sensor Web, which has the ability for various kinds of sensor accesses [
21]. Since the model is used in the classification problem, proposing the model for the segmentation is make more sense in the field of the flash flood detection. Other models could be found in [
22,
23].
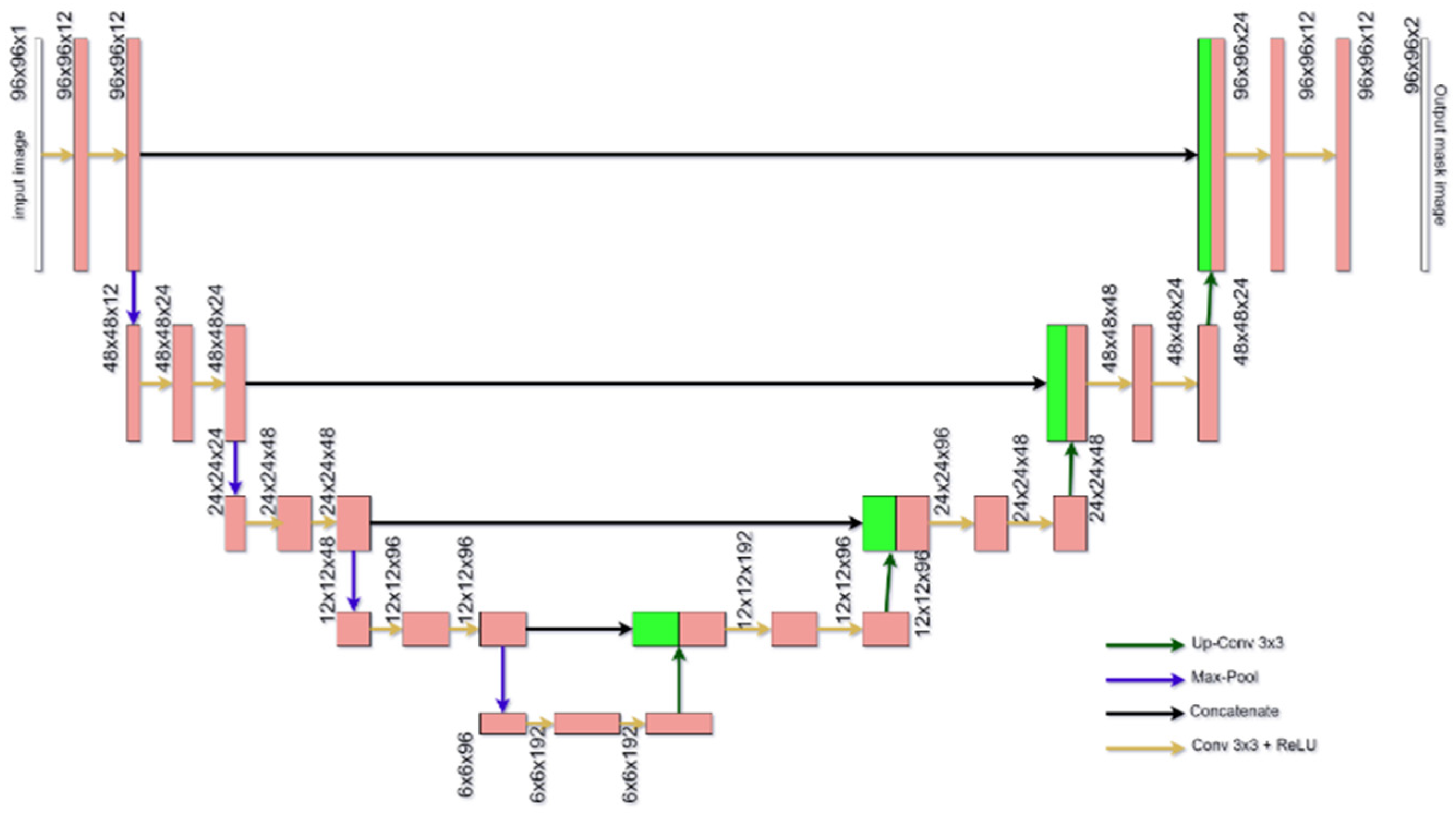
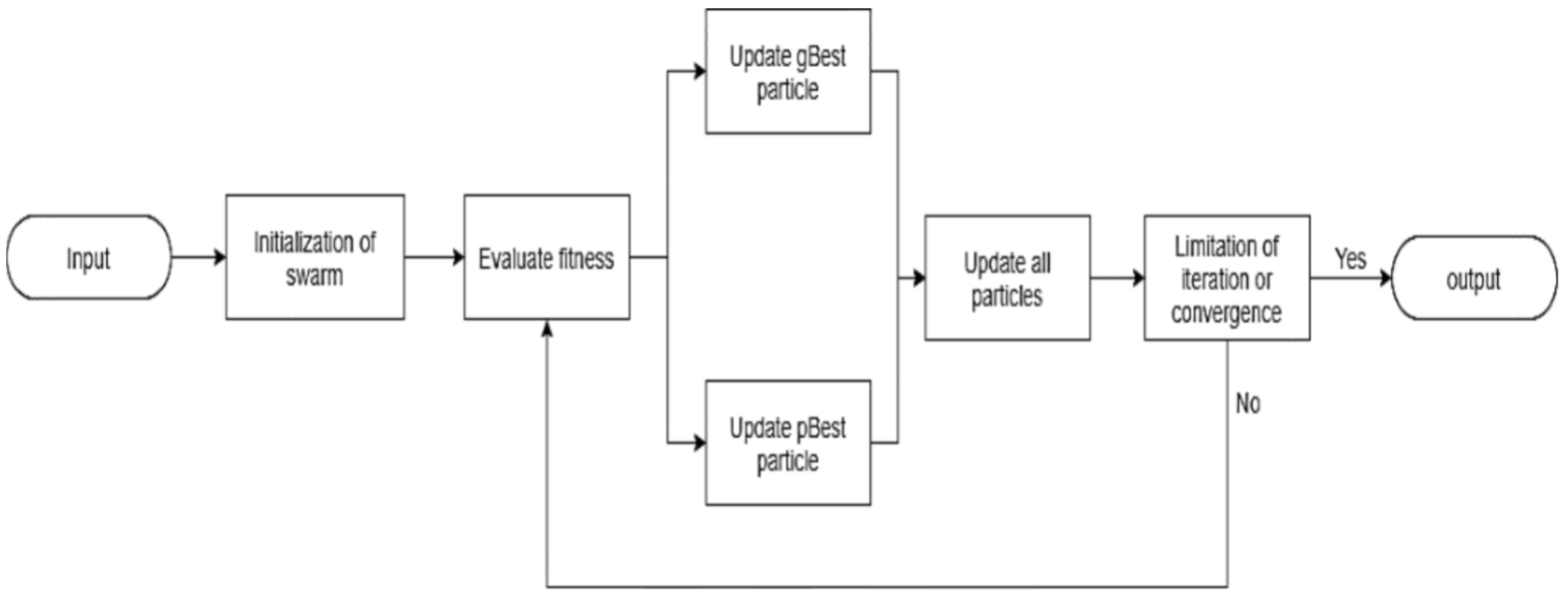
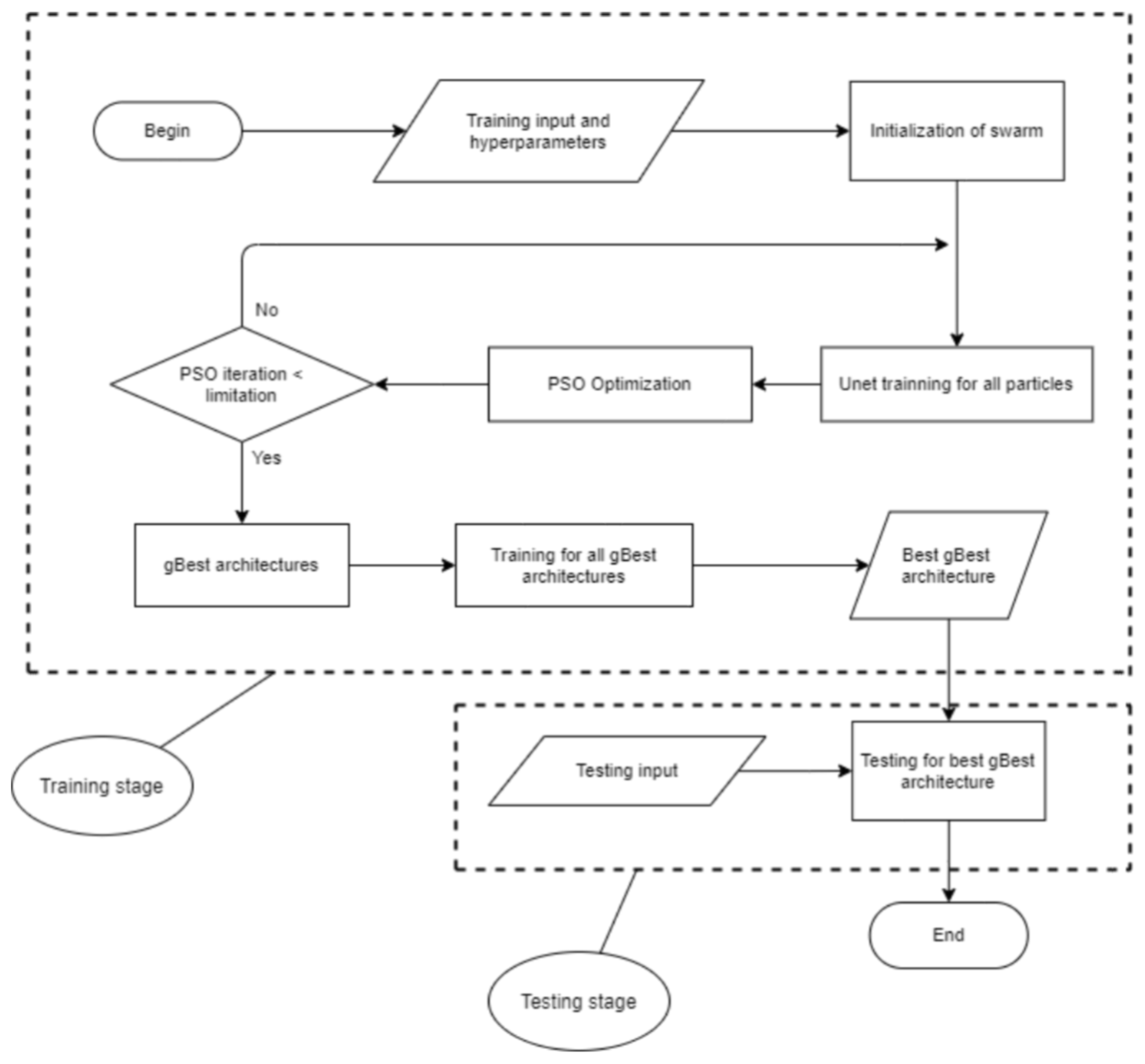
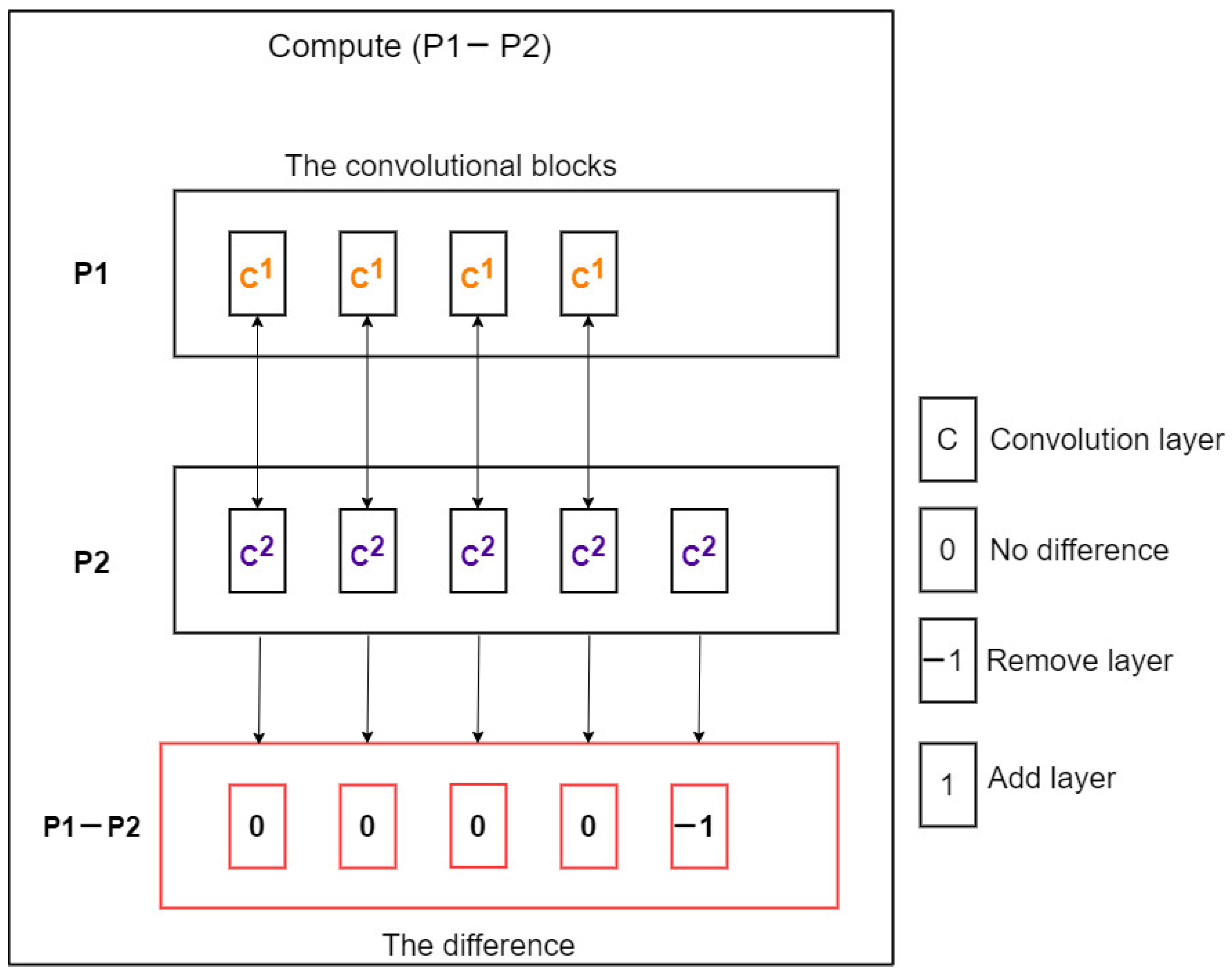
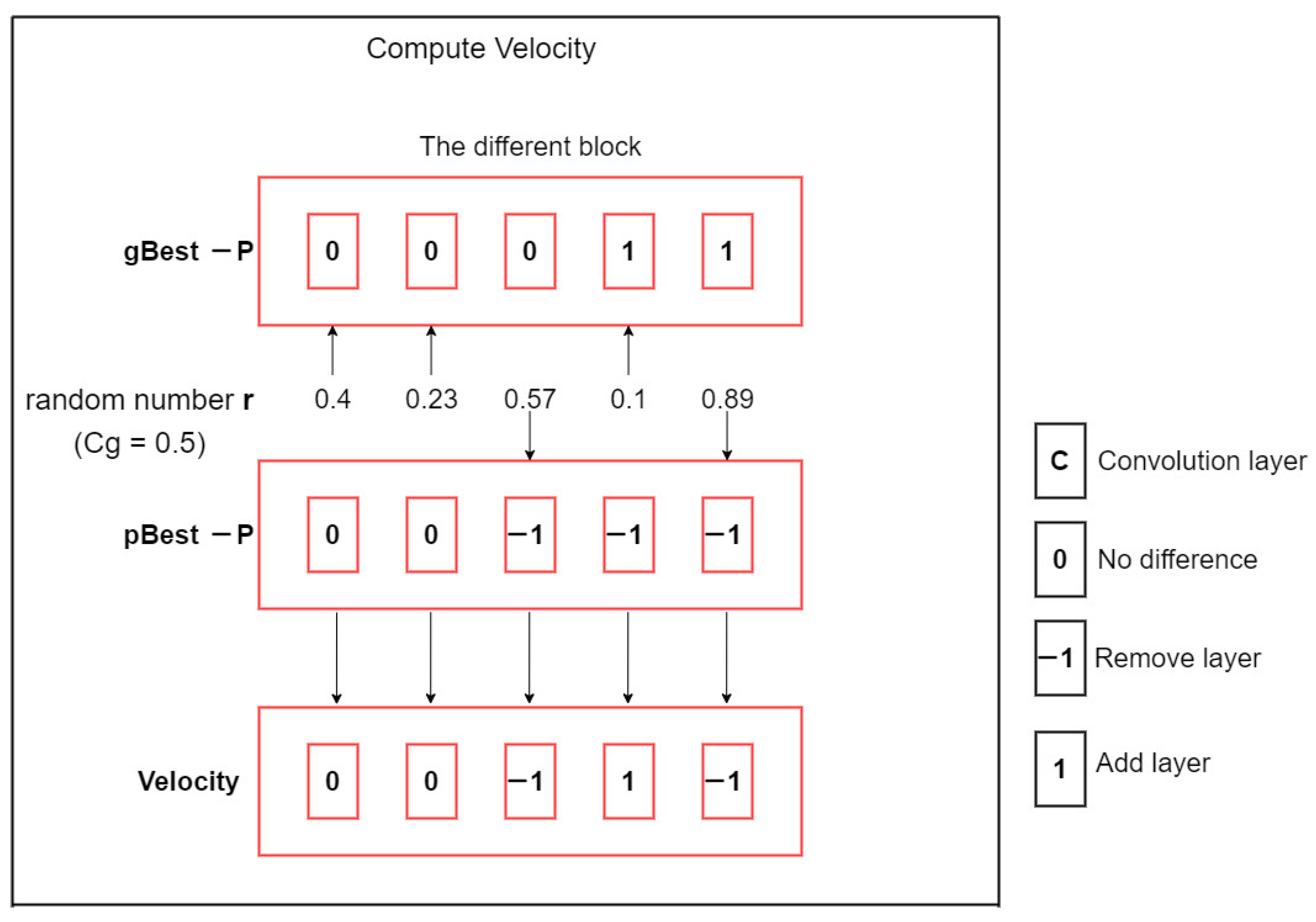
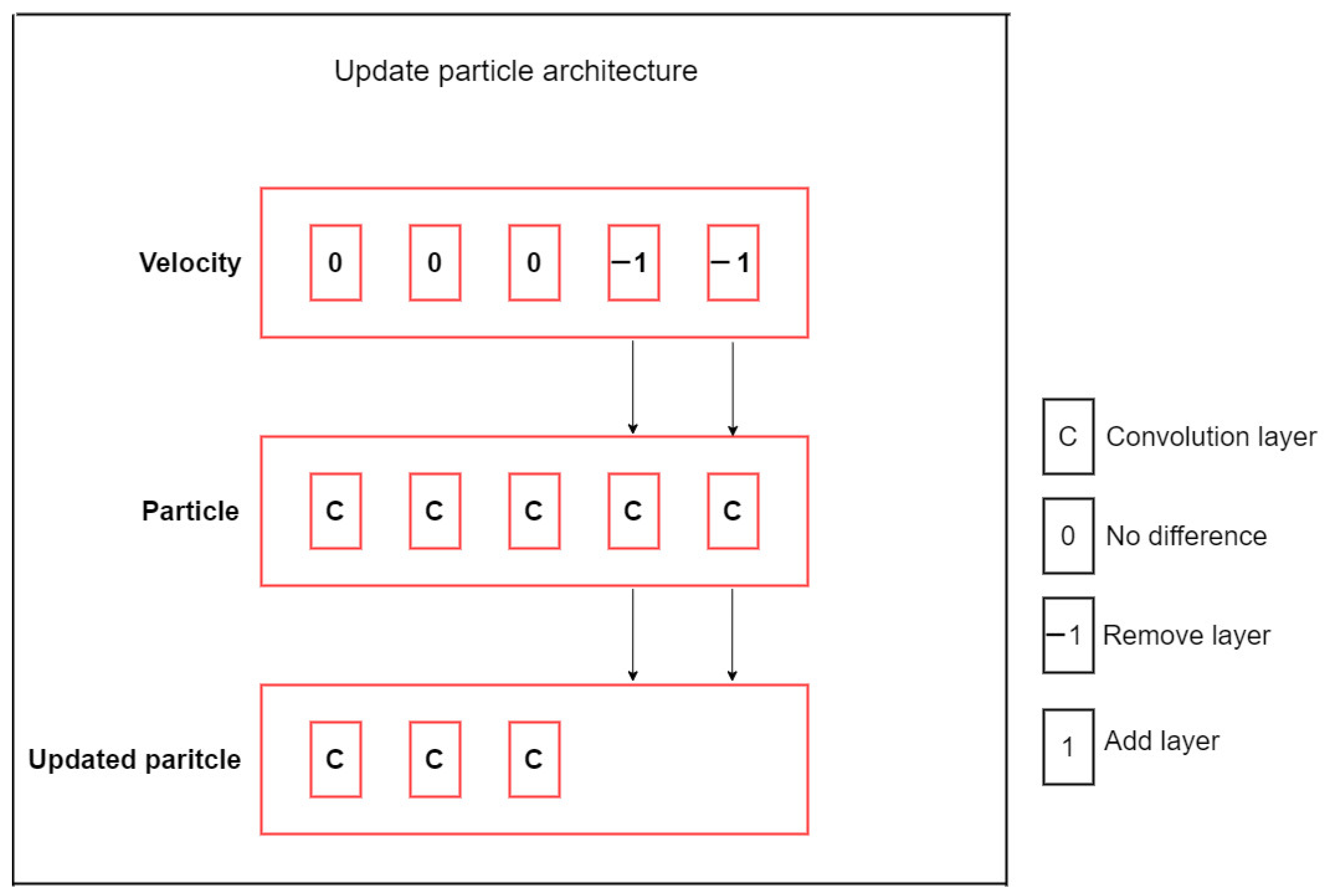
All the above-mentioned research used ML techniques to find a solution in a particular field. However, there are few articles using Deep Learning for the flash flood segmentation. In this paper, we propose a novel Deep Learning architecture, namely PSO-UNET, which combines the Particle Swarm Optimization (PSO) with the UNET model to improve the performance of the flash flood detection from satellite images. UNET is a convolutional network designed for biomedical image segmentation [
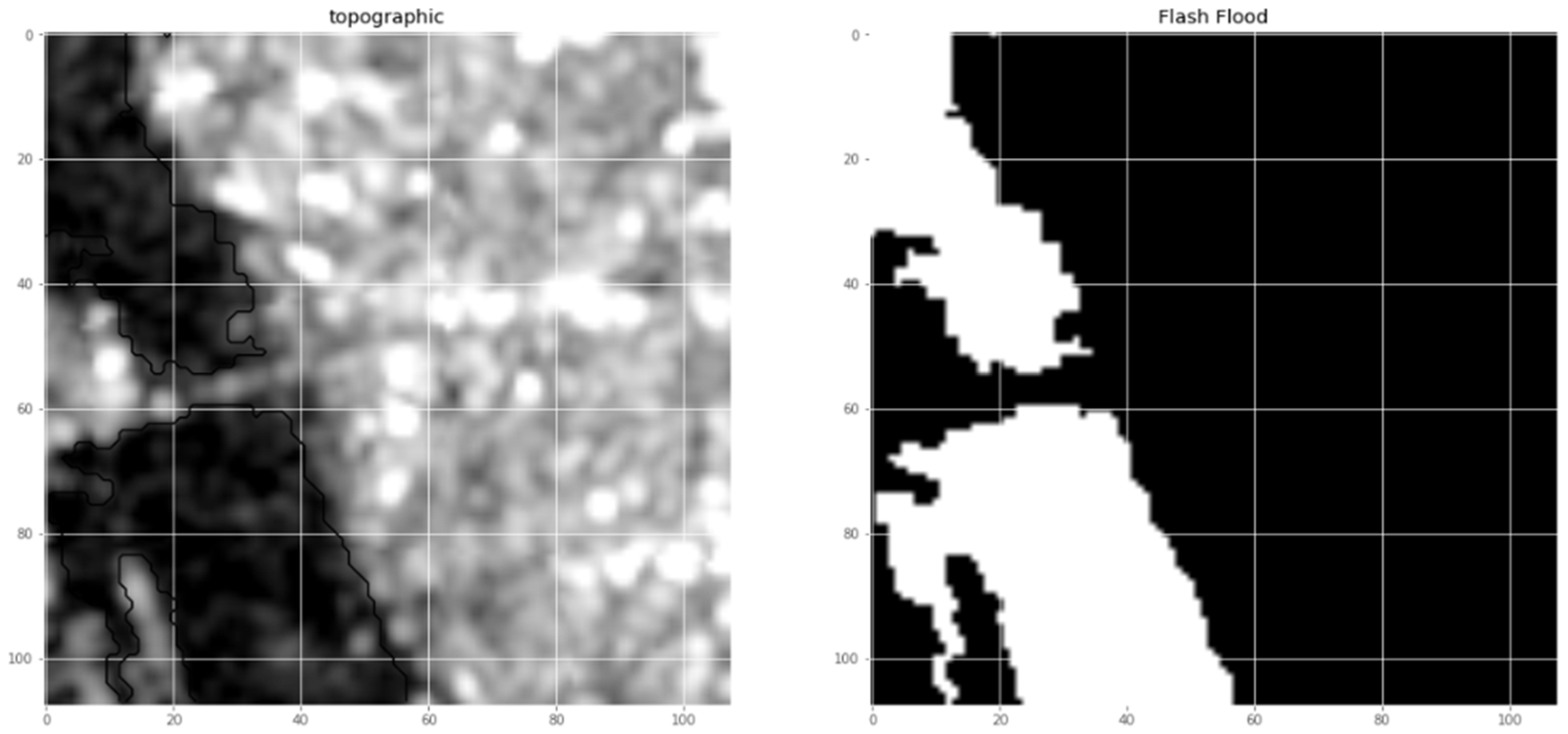
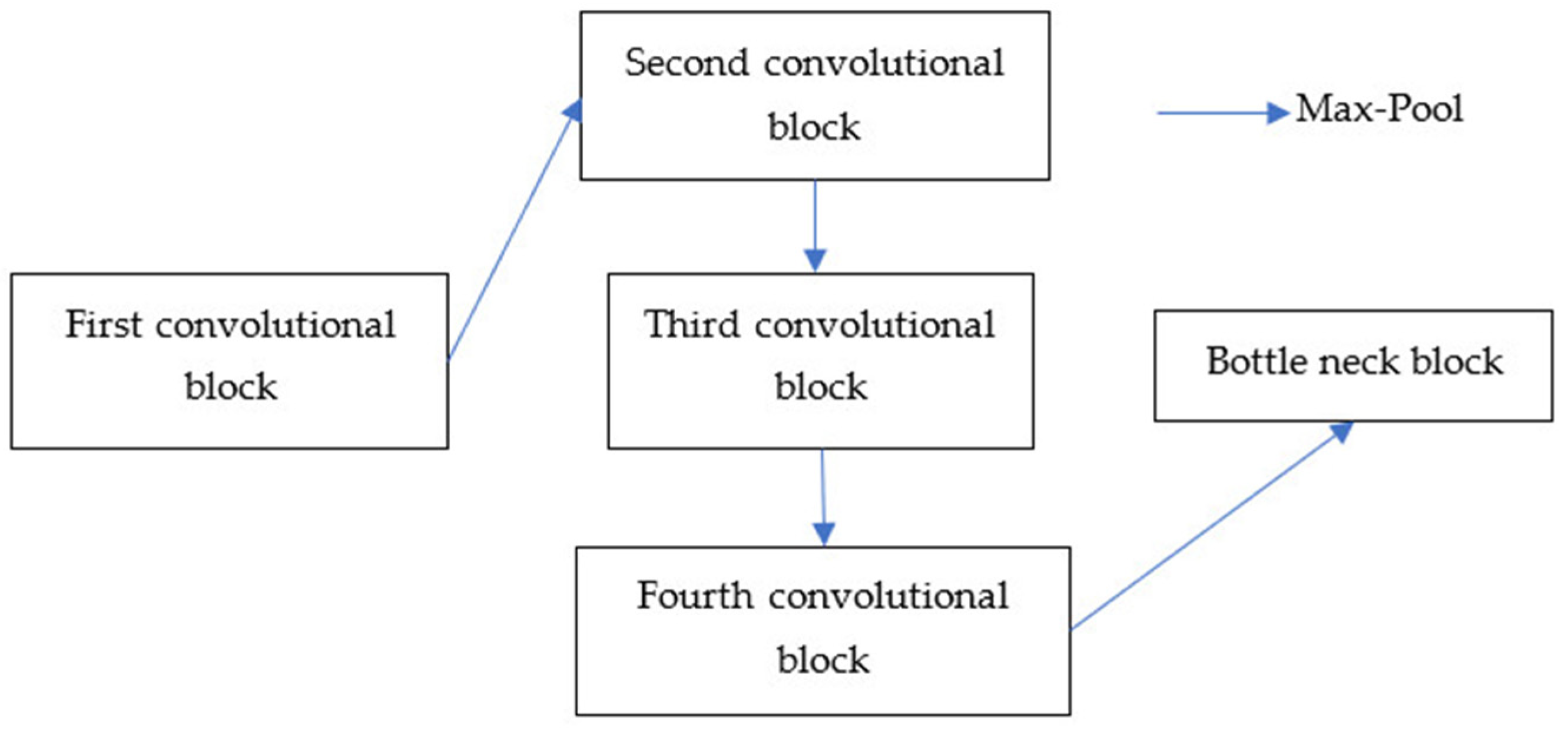
24]. Its architecture is symmetric and comprises of two main parts namely a contracting path and an expanding path, which can be widely seen as an encoder followed by a decoder. Since the original UNET has a symmetrical architecture, which means the expansive path is created following the contracting path, we only need to pay attention to the contracting path for the evolutionary computation. The UNET convolutional process is performed four times. Indeed, we consider each process as a block of the convolution having two convolutional layers in the original architecture. The training of inputs and hyper-parameters is performed by the PSO algorithm. By doing so, we acquire the optimal parameterization for the UNET, which is the innovative idea of this paper. Experimental results on various satellite images of Quangngai province located in Vietnam prove the advantages and superiority of the PSO-UNET approach against the original UNET.
The remainder of this paper comprises of 4 sections and is organized as follows: The UNET architecture and Particle Swarm Optimization, which are the two major components of the proposed method, are presented in
Section 2. The PSO-UNET which is the combination of the UNET and the PSO algorithm is presented in detail in
Section 3. In
Section 4, the experimental results of the proposed method are presented. Finally, the conclusion and directions are given in
Section 5.
5. Discussions
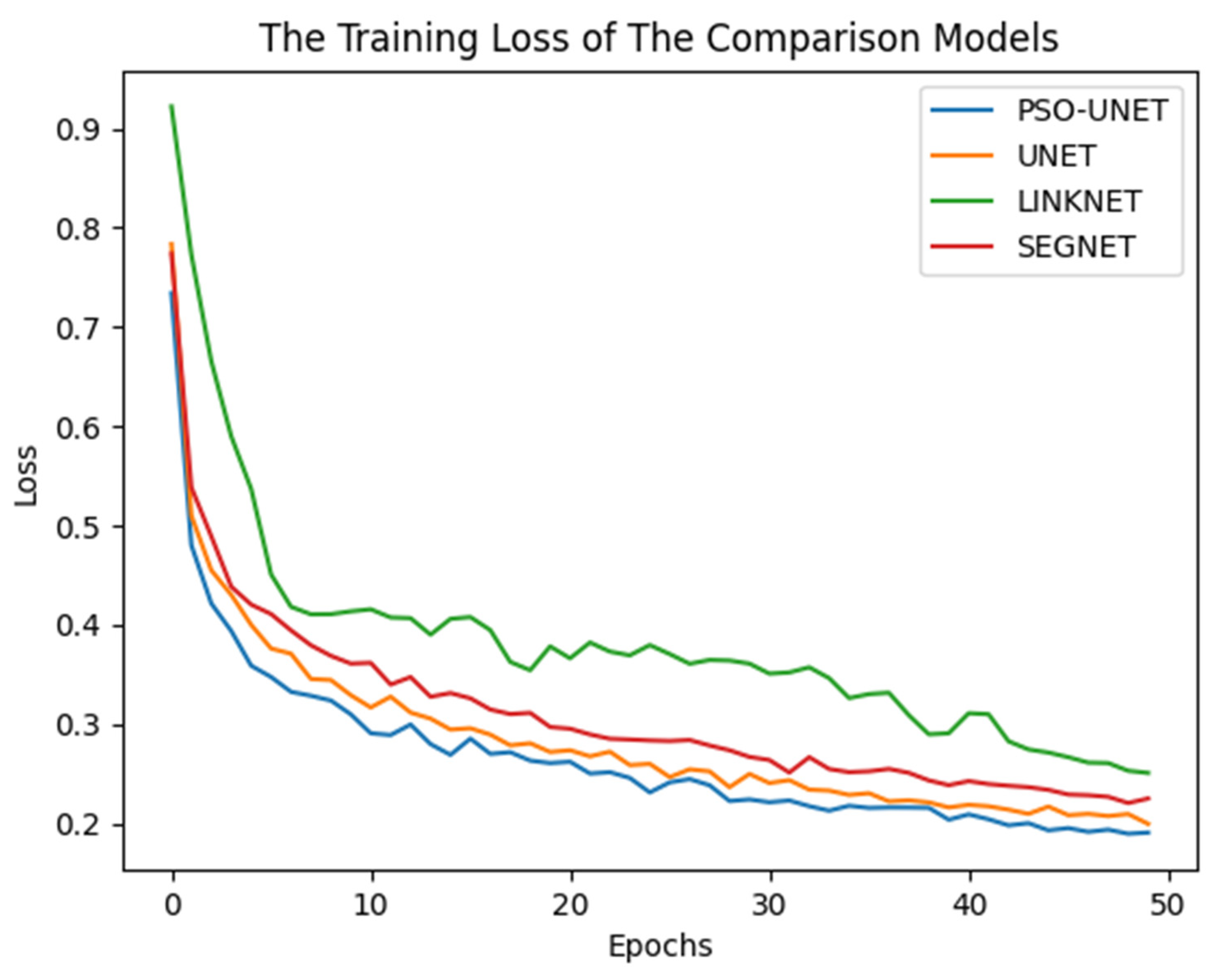
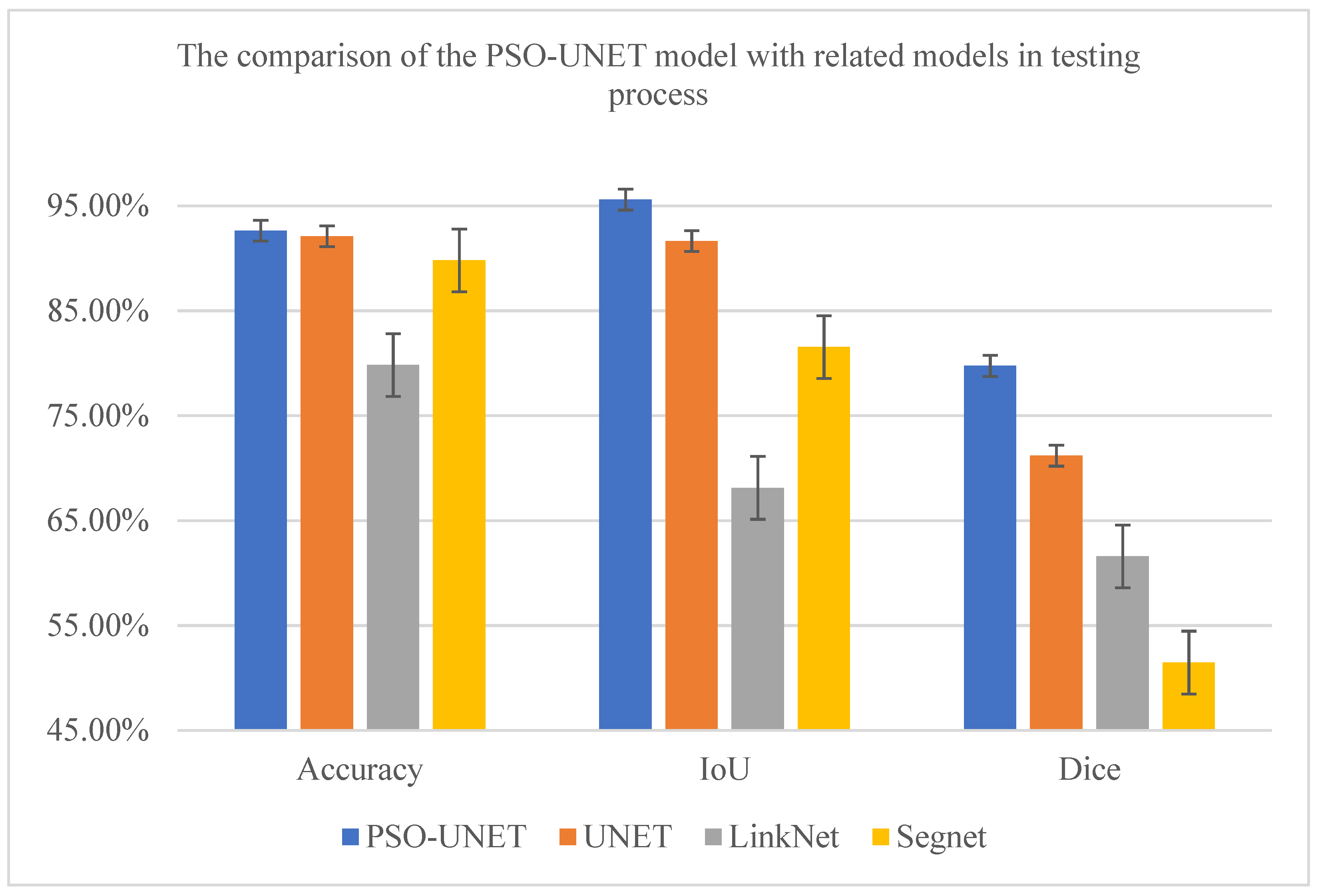
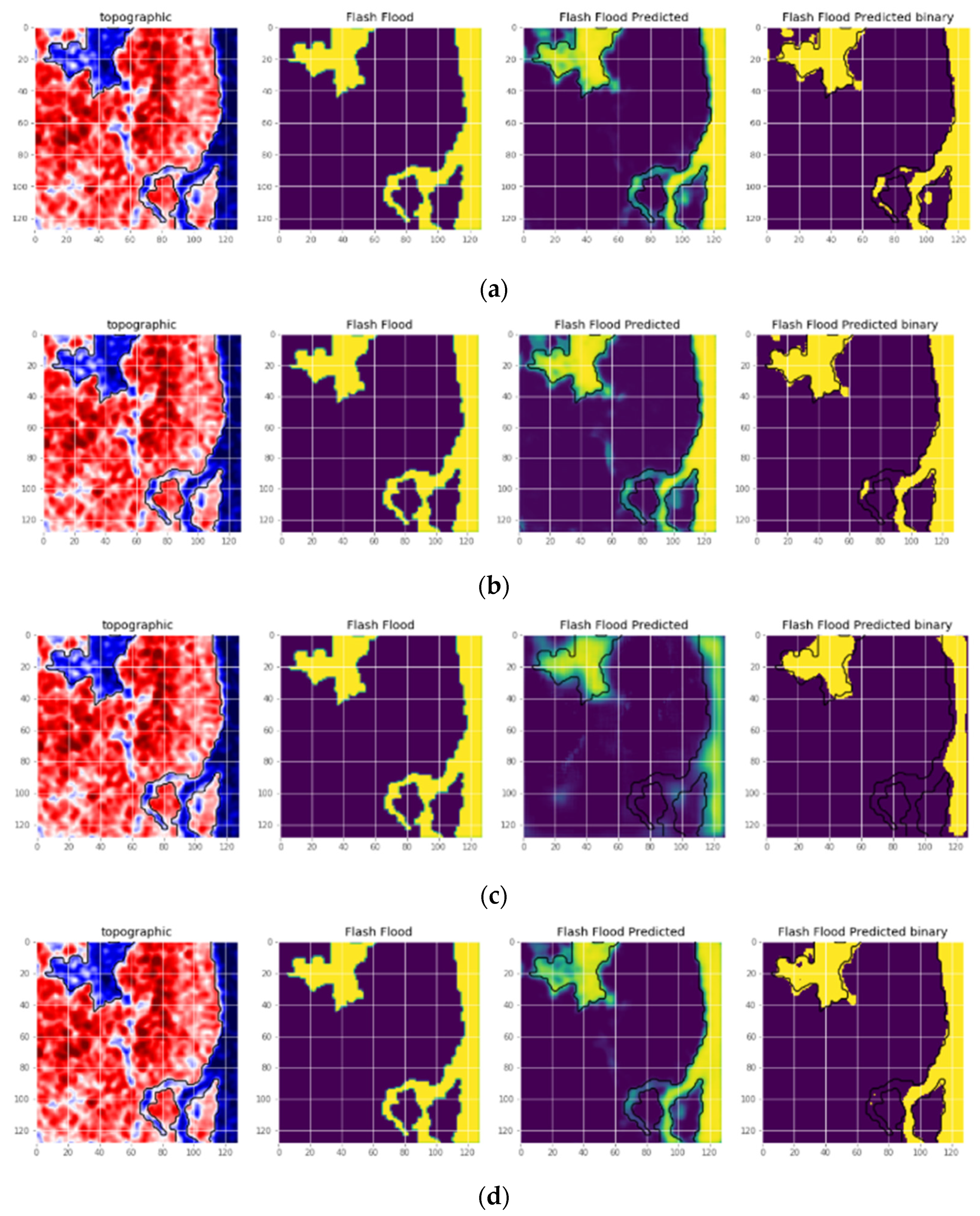
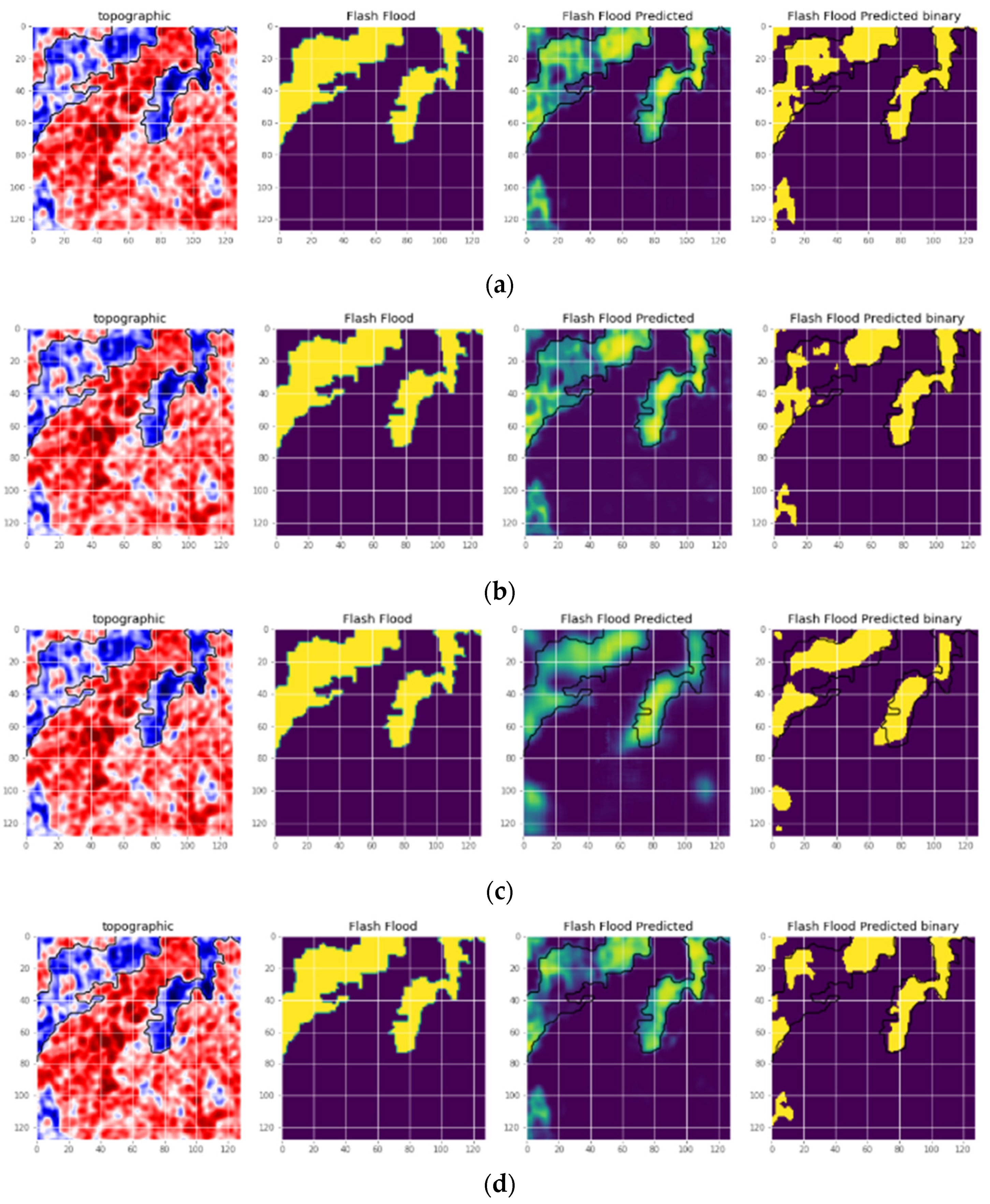
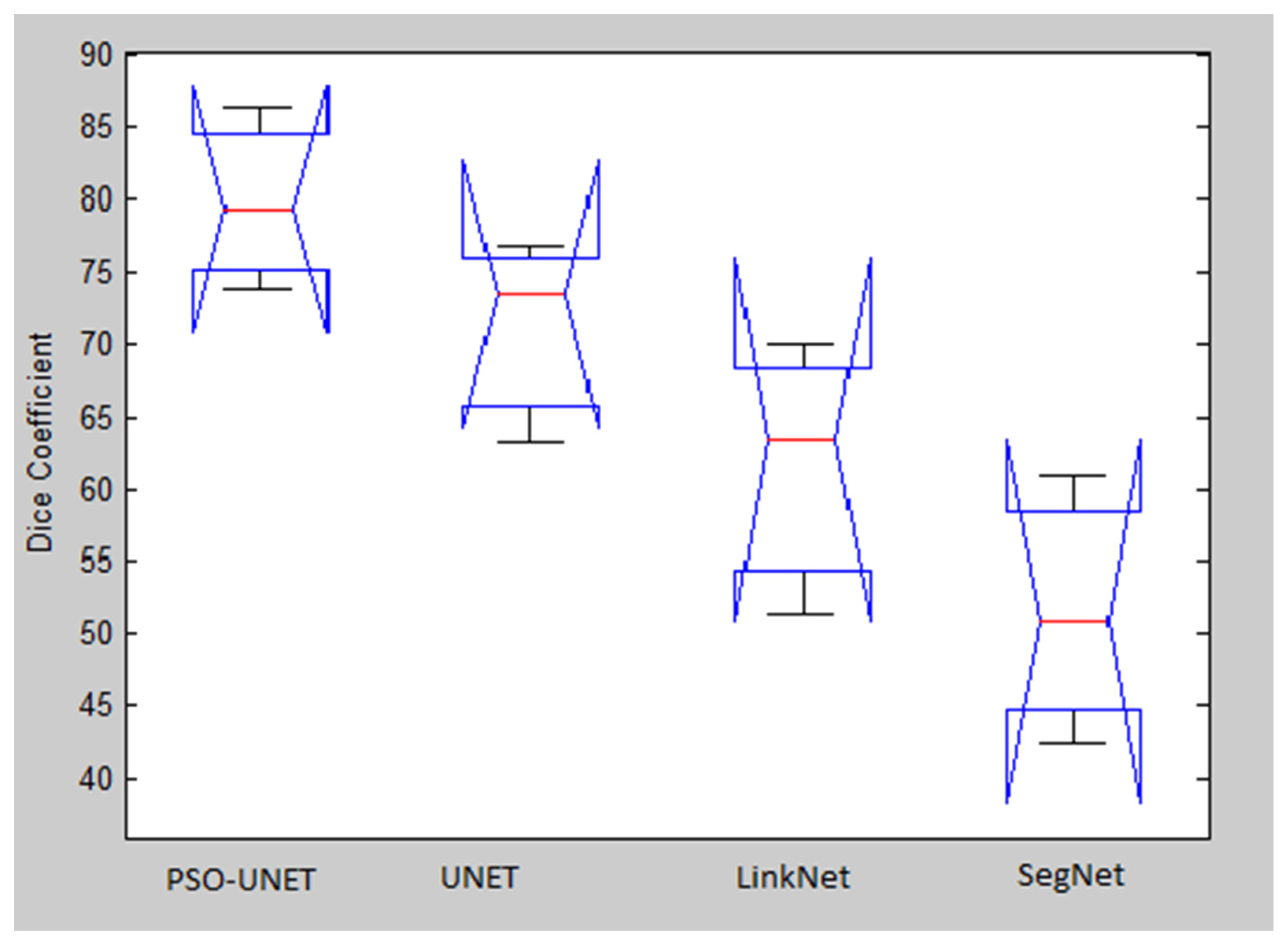
With the results presented in the previous subsections, the proposed model shows the ability and the better performance of the approach when we have experimented in the satellite images dataset. We combined the original UNET with the PSO algorithm, while the initial architectures of the UNET evolved through each iteration. These architectures approach gradually to the optimal one by adding essential layers or removing redundant layers in every convolution blocks. After each iteration, the new version of the architecture appears, so the final result has a better score when compared to related models.
In addition to these advantages, there are an existent of the time consuming in the whole training stage of the proposed model. While related models are straightforward in order to reach the best parameters of the networks, the PSO-UNET experience compulsorily through two stages of the PSO algorithm and the model training process. However, the longer running time is compensated by the better performance of all measures. For the hyper-parameters of the PSO algorithm, as the number of iterations and populations increases, the resulting architecture is better. In this paper, we just confine these hyper-parameters to improve the running time.
In the future, thanks to the unstoppable development of state-of-the-art in the computer industry, the computation speed will increase considerably, and we believe that the running time will be further improved.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}