
Inferring HIV Transmission Network Determinants Using Agent-Based Models Calibrated to Multi-Data Sources


Abstract
:1. Background
2. Methods
2.1. Simulation Tool: Simpact Cyan
2.2. Simulation of HIV Epidemic
2.3. Selected Parameters for Calibration
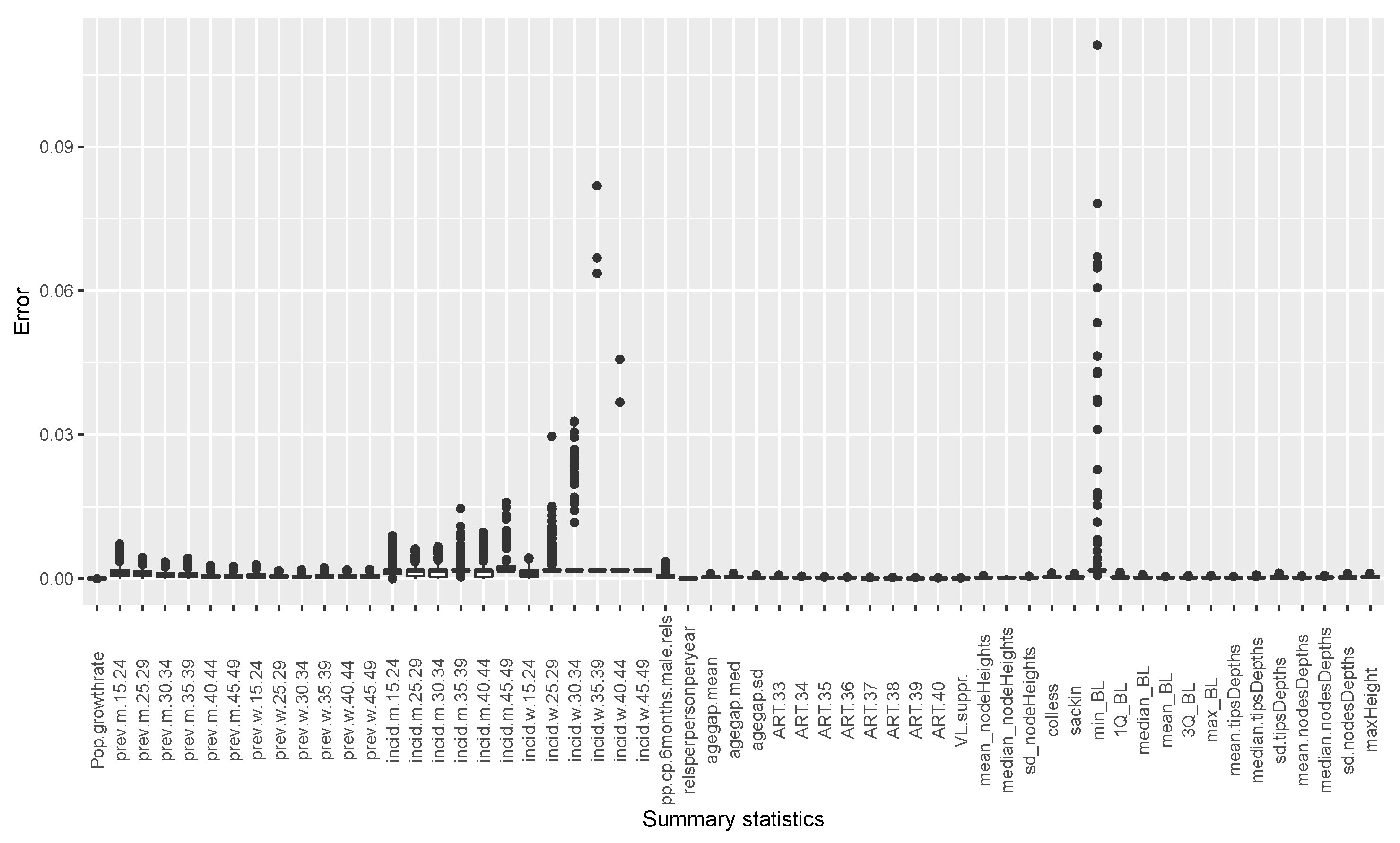
2.4. Selected Summary Features
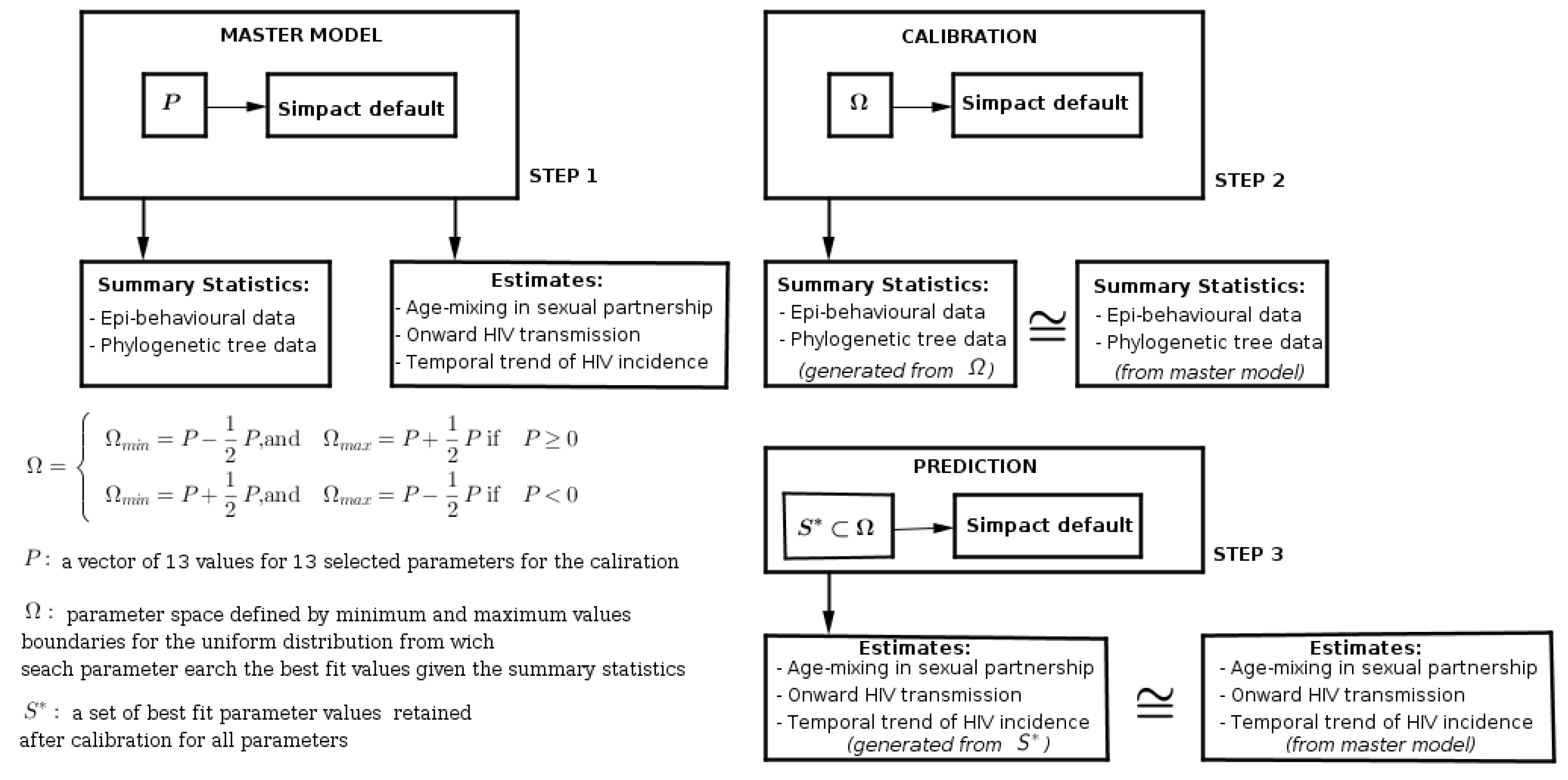
2.5. Calibration Scheme
3. Results
3.1. Age Mixing Patterns in Sexual Partnerships
3.2. Onward Hiv Transmission
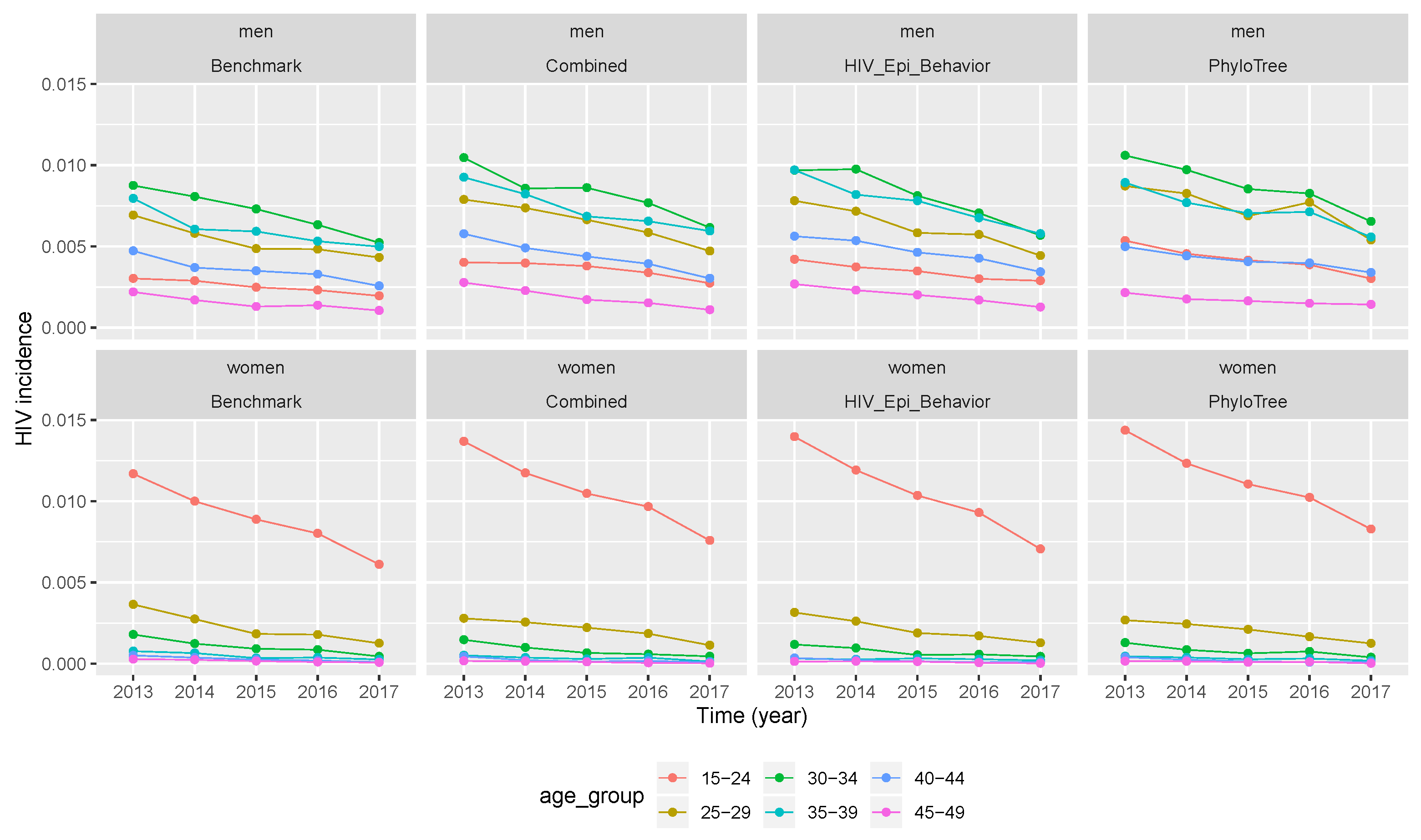
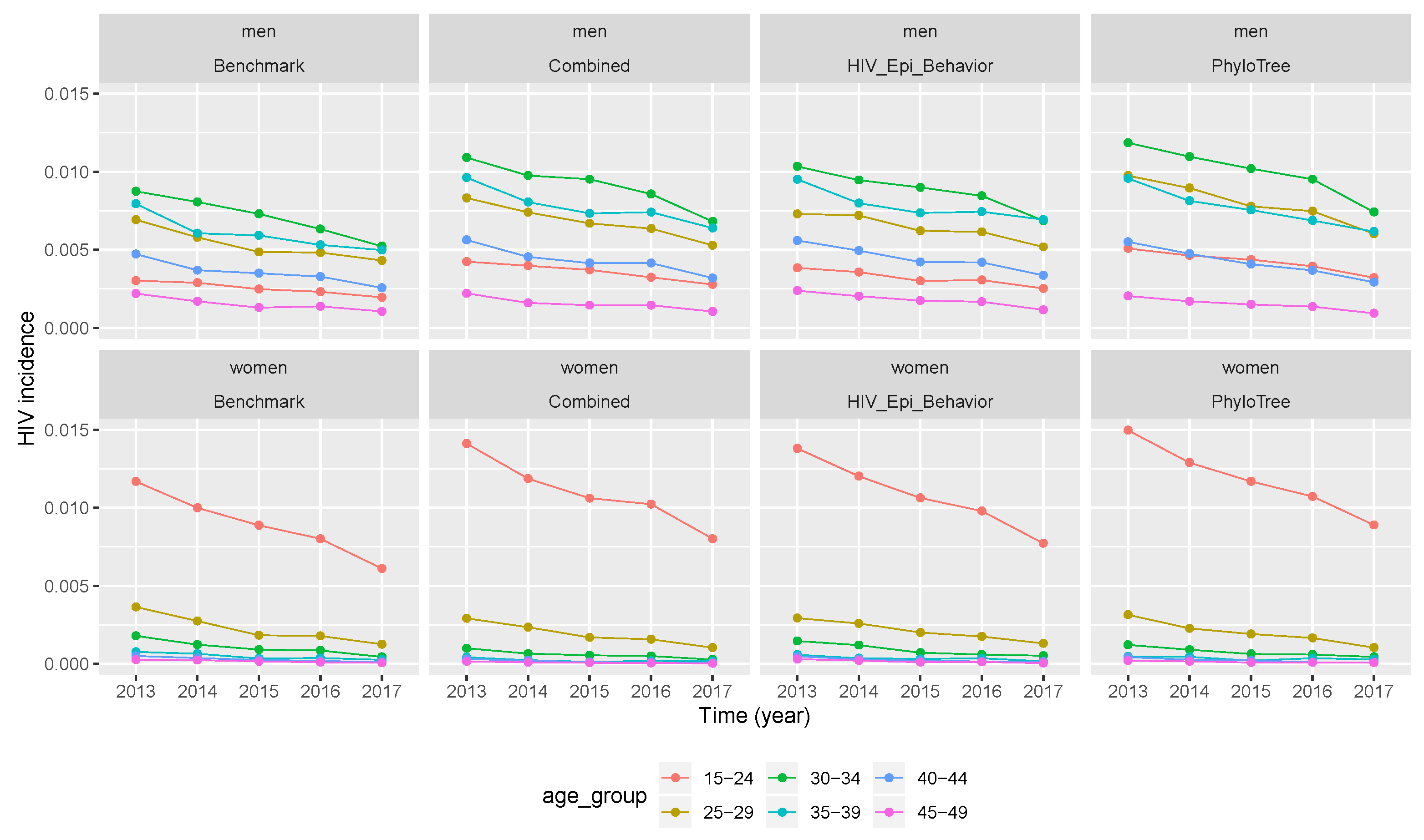
3.3. Temporal Trend of Hiv Incidence
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Simpact Cyan Simulation Model
Appendix A.1. Configuration
Appendix A.1.1. Create the Initial Population
Appendix A.1.2. Schedule the Initial Events
Appendix A.1.3. Hazard Functions and Parameters
Appendix A.2. Model Parameters: Events’ Hazard Functions and Associated Settings
Appendix A.2.1. Sexual Partnership Event
- , the value of in the expression for the hazard, allowing one to establish a baseline value.
- controls , which allows you to vary the preferred age gap with the age of the man in the relationship; and
- controls , which allows you to vary the preferred age gap with the age of the woman in the relationship.
- , the value of in the hazard formula, corresponding to a weight for the number of relationships the man in the relationship has; and
- , the value of in the hazard formula, corresponding to a weight for the number of relationships the woman in the relationship has.
- , the value of in the hazard expression, by which the influence of the difference in number of partners can be specified.
- , the value of weight of in the expression for the hazard, a weight for the average age of the partners.
Appendix A.2.2. Sexual Partnership Dissolution Event
- , the value of in the expression for the hazard, allowing one to establish a baseline value.
- , the value of in the expression for the hazard, corresponding to a weight for the number of relationships the man in the relationship has.
Appendix A.2.3. Relationship-Related Settings
Eagerness
- , represents parameter for a man’s eagerness following a gamma distribution
- , represents parameter for a woman’s eagerness following a gamma distribution
- , represents parameter for a man’s eagerness following a gamma distribution
- , represents parameter for a woman’s eagerness following a gamma distribution
Age Gap Preference
- , for a man’s mean of normal distribution of age preference between men and women
- , for a woman’s mean of normal distribution of age preference between women and men
- , for a man’s standard deviation of normal distribution of age preference between men and women
- , for a woman’s standard deviation of normal distribution of age preference between women and men
HIV Transmission Event
- refers to the value of a in the expression for the hazard, providing a baseline value.
- refers to the value of b in the expression for the hazard. Together with the value of c this specifies the influence of the current viral load of the infected person.
- refers to the value of c in the expression for the hazard. Together with the value of b, this specifies the influence of the current viral load of the infected person.
- refers to the value of in the expression of the hazard.
- refers to the value of in the expression of the hazard. Furthermore, by configuring the weights and , it becomes possible to change the susceptibility of a woman depending on her age.
Appendix A.2.4. Hiv Infection Monitoring Event
- parameter for the threshold set for the infected person to be offered antiretroviral treatment.
- parameter to lower the person’s set-point viral load value if treatment is started.
- ART acceptance.
Appendix A.2.5. Diagnosis Event
- controls the corresponding baseline value in the expression for the hazard.
Appendix A.2.6. Hiv Infection Stage and Viral Load
- : when the viral load during the acute stage is needed, it is determined in such a way that the transmission hazard increases by this factor, possibly clipped to a maximum value ().
- : when the viral load during the initial AIDS stage is needed, it is determined in such a way that the transmission hazard increases by this factor, possibly clipped to a maximum value ().
- : when the viral load during the final AIDS stage is needed, it is determined in such a way that the transmission hazard increases by this factor, possibly clipped to a maximum value ().
Appendix A.2.7. Art Treatment Dropout Event
Appendix A.2.8. Aids Mortality Event
- C is set in the model by
- k is set in the model by
- one dimensional distribution can be used to add some randomness to the survival time until the person dies of AIDS-related causes after becoming infected with HIV.
Appendix A.2.9. Conception Event
- set by baseline for a conception hazard function

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Explanation | Value |
|---|---|---|
| Initial configuration | ||
| Simulation time | 40 | |
| Same sex sexual partnership | no | |
| Initial male population | 5000 | |
| Initial female population | 5000 | |
| Time to introduce HIV into the population | 10 | |
| Consider the amount not proportion of seeded individuals among the population | ||
| Amount of HIV seeded individuals | 10 | |
| Minimum age for seeded individuals | 20 | |
| Maximum age for seeded individuals | 50 | |
| Age of being sexually active | 15 | |
| Maximum events to be simulated (beyond this number of events, the simulation will stop, it can also stop with population.simtime) | 1.2 million 1 | |
| Specify how many persons of the opposite sex (who are sexually active), specified as a fraction, someone can possibly have relationships | 0.2 | |
| Demographic | ||
| boy/girl ratio | ||
| Baseline for conception event | ||
| Sexual partnership | ||
| parameter for male eagerness following a gamma distribution | 0.23 | |
| parameter for female eagerness following a gamma distribution | 0.23 | |
| parameter for male eagerness following a gamma distribution | 45 | |
| parameter for female eagerness following a gamma distribution | 45 | |
| Distribution type for age gap preference for men | Normal | |
| Distribution type for age gap preference for women | Normal | |
| Baseline for sexual partnerships | 2 | |
| Mean for the normal distribution of the age gap preference for men | 10 | |
| Mean for the normal distribution of the age gap preference for women | 10 | |
| Standard deviation for the normal distribution of the age gap preference for men | 5 | |
| Standard deviation for the normal distribution of the age gap preference for women | 5 | |
| Allows varying of the preferred age gap with the age of the man in the relationship | ||
| Allows varying of the preferred age gap with the age of the woman in the relationship | ||
| Corresponding to a weight for the number of relationships the man in the relationship has | −0.3 | |
| Corresponding to a weight for the number of relationships the man in the relationship has | −0.3 | |
| Influence of the difference in number of partners can be specified | −0.1 | |
| Baseline for relationship dissolution | ||
| Weight for the average age of the partners in relationship dissolution | ||
| HIV transmission | ||
| Baseline value for HIV transmission. | ||
| Influence of the current viral load of the infected person. | ||
| Influence of the current viral load of the infected person. | ||
| Weight for susceptibility of a woman depending on her age. | ||
| Weight for susceptibility of a woman depending on her age. | ||
| HIV infection stages | ||
| Viral load during the acute stage. | 5 | |
| Viral load during the initial AIDS stage. | 7 | |
| Viral load during the final AIDS stage. | 12 | |
| HIV infection monitoring | ||
| Lower the person’s set-point viral load value when someone started ART. | 0 | |
| ART interventions | ||
| For ART intervention we have: | ||
| Time for ART intervention | ||
| Diagnosis baseline | ||
| CD4 count eligibility cutoff | ||
| ART introduction 1: | ||
| 23 (2000 **) | ||
| −2 | ||
| 100 | ||
| ART introduction 2: | ||
| 25 (2002 **) | ||
| −1.8 | ||
| 150 | ||
| ART introduction 3: | ||
| 28 (2005 **) | ||
| −1.5 | ||
| 200 | ||
| ART introduction 4: | ||
| 33 (2010 **) | ||
| −1 | ||
| 350 | ||
| ART introduction 5: | ||
| 36 (2013 **) | ||
| −1 | ||
| 500 | ||
| ART introduction 6: | ||
| 39 (2016 **) | ||
| −1 | ||
| 700 | ||
| ART acceptance | ||
| Specification of ART dropout distribution | Uniform | |
| Minimum value of the uniform dropout distribution | ||
| Maximum value of the uniform dropout distribution | ||
| AIDS mortality and survival | ||
| Relationship between set-point viral load and survival. | 65 | |
| Relationship between set-point viral load and survival. | −0.2 | |
| Type of distribution type for survival time randomness. | Normal | |
| Mean of the normal distribution for survival time randomness. | ||
| Standard deviation of the normal distribution for survival time randomness. |
| Sub-Component | Assumptions |
|---|---|
| Demographic | Birth: when there is a sexual partnership formation, a conception event will be scheduled; after a conception event is triggered, a new birth event will be scheduled, so that the woman in the relationship will give birth to a new person at a specific time, and the gender will be determined by the boy/girl ratio. Mortality: normal mortality model follows Weibull distribution, and the time for AIDS mortality was determined as the time of infection plus the survival time. |
| Sexual partnership | We considered sexual partnerships such that the preferred age gap differed from one person to the next, but there was also an age dependent component in this preferred age gap, and we allowed for the weight of the age gap terms to be age-dependent. We assumed the age gap to be normally distributed. The hazard function for partnership depended on the number of partners the man and woman in the relationship had. The debut age was set to be 15 years for men and women. Once a sexual partnership was established, it was subject to dissolution as well. |
| HIV transmission | Transmission is likely to occur when one individual in a sexual partnership is infected with HIV. Transmission depends on the viral load level of an infected individual. A woman’s susceptibility to HIV infection was considered to depend on her age. Set-point viral load is the viral load that the person has during the chronic stage. In the acute stage or in the Acquired immunodeficiency syndrome (AIDS) stages, the configuration values , and cause the real viral load to differ from the set-point viral load in such a way that the transmission probability is altered: the hazard for transmission will increase by the factor x that is defined in this way. We also assumed that, once an infected individual is on ART, s/he cannot transmit the infection; thus, we set to 0. |
| ART interventions | If this CD4 count is below the threshold set in , the person will be offered antiretroviral treatment (ART). Depending on the person’s willingness to accept treatment, treatment will then be started. We considered gradually increasing ART eligibility based on CD4 count thresholds as implemented in real life. |
| Disease progression | Follow up on the progress of the disease is performed by inspecting the person’s CD4 count. When a person receives treatment, the viral load is lowered and if the person drops out of treatment the viral load will increase. |
Appendix A.3. Hiv Evolutionary Dynamic
| Name | Value |
|---|---|
| Relative Frequencies | |
| Adenine (A) | 0.3857 |
| Cytosine (C) | 0.1609 |
| Guanine (G) | 0.2234 |
| Thymine (T) | 0.2300 |
| Relative substitution rates | |
| r(A → G) = r(G → A) | 2.9114 |
| r(A → C) = r(C → A) | 12.5112 |
| r(A → T) = r(T → A) | 1.2569 |
| r(G → C) = r(C → G) | 0.8559 |
| r(G → T) = r(T → G) | 12.9379 |
| r(C → T) = r(T → C) | 1.0000 |
| Rate heterogeneity | |
| Shape parameter | 0.9 |
| Number of gamma rate categories | 4 |
| Fraction of invariant sites | |
| Proportion of invariant sites (I) | 0.5230 |
| Evolutionary rate | |
| Substitutions/site/year 2 |
Appendix B. Calibration of Simpact Cyan: Parameters and Summary Features
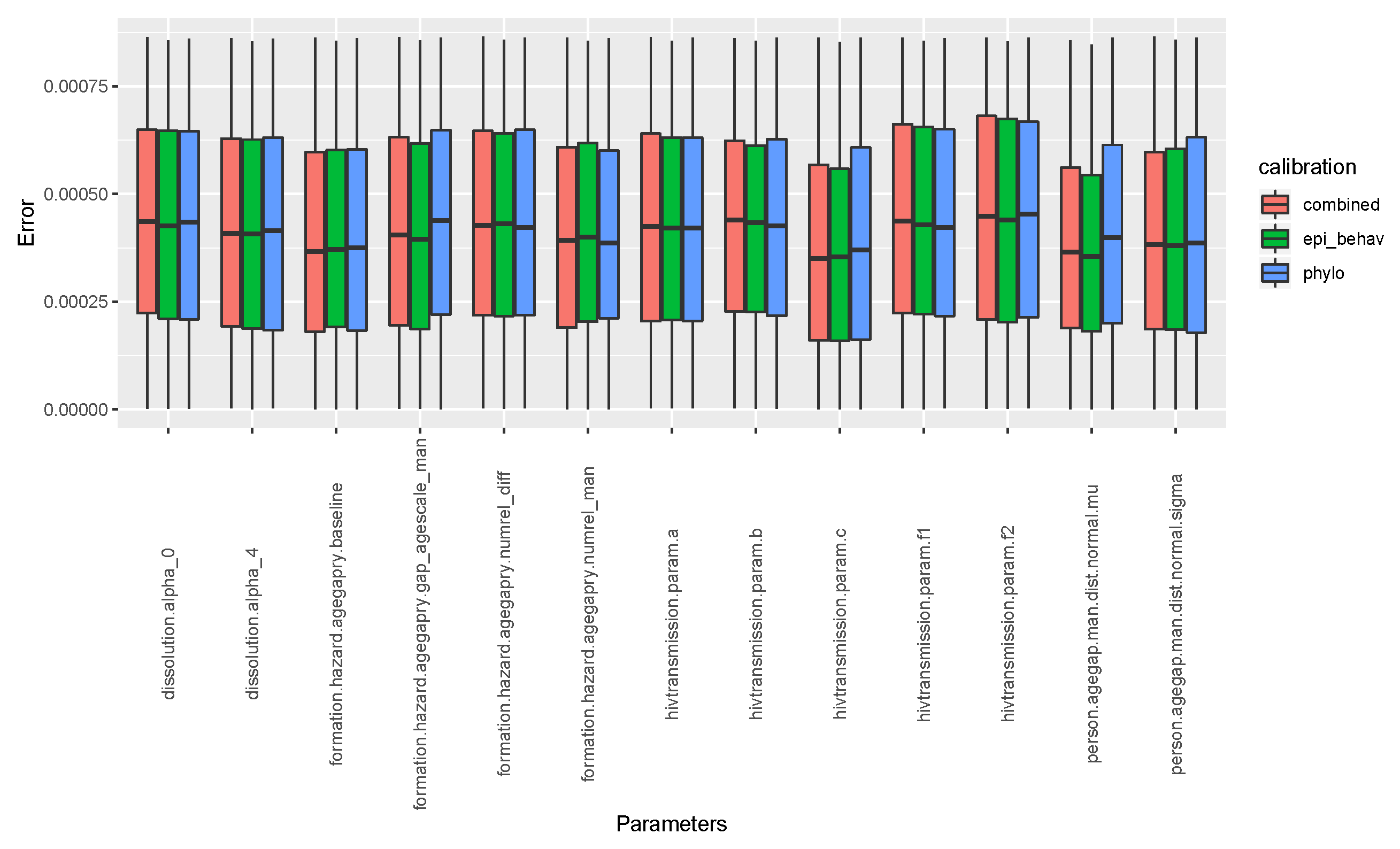
Appendix B.1. Selected Parameters for Calibration
cfg.list["dissolution.alpha_0"] <- inputvector[1] cfg.list["dissolution.alpha_4"] <- inputvector [2] cfg.list["formation.hazard.agegapry.baseline"] <- inputvector[3] cfg.list["person.agegap.man.dist.normal.mu"] <- inputvector[4] cfg.list["person.agegap.woman.dist.normal.mu"] <- inputvector[4] cfg.list["person.agegap.man.dist.normal.sigma"] <- inputvector[5] cfg.list["person.agegap.woman.dist.normal.sigma"] <- inputvector[5] cfg.list["formation.hazard.agegapry.gap_agescale_man"] <- inputvector[6] cfg.list["formation.hazard.agegapry.gap_agescale_woman"] <- inputvector[6] cfg.list["formation.hazard.agegapry.numrel_man"] <- inputvector[7] cfg.list["formation.hazard.agegapry.numrel_woman"] <- inputvector[7] cfg.list["formation.hazard.agegapry.numrel_diff"] <- inputvector[8] cfg.list["hivtransmission.param.a"] <- inputvector[9] cfg.list["hivtransmission.param.b"] <- inputvector[10] cfg.list["hivtransmission.param.c"] <- inputvector[11] cfg.list["hivtransmission.param.f1"] <- inputvector[12] cfg.list["hivtransmission.param.f2"] <- inputvector[13]
| Parameter | Calibration 1 | Calibration 2 | Calibration 3 | Input | Space |
|---|---|---|---|---|---|
| −0.514 [−0.654, −0.397] | −0.52 [−0.652, −0.39] | −0.514 [−0.653, −0.391] | −0.52 | [−0.78, −0.26] | |
| −0.053 [−0.064, −0.041] | −0.052 [−0.063, −0.04] | −0.053 [−0.064, −0.041] | −0.05 | [−0.075, −0.025] | |
| 1.957 [1.513, 2.401] | 1.976 [1.546, 2.409] | 1.965 [1.54, 2.398] | 2 | [1, 3] | |
| 10.277 [8.287, 12.324] | 9.666 [7.433, 11.913] | 10.11 [7.949, 12.195] | 10 | [5, 15] | |
| 4.898 [3.84, 6.128] | 4.989 [3.728, 6.248] | 4.96 [3.839, 6.191] | 5 | [2.5, 7.5] | |
| 0.255 [0.2, 0.308] | 0.244 [0.186, 0.299] | 0.252 [0.198, 0.306] | 0.25 | [0.125, 0.375] | |
| −0.299 [−0.371, −0.23] | −0.302 [−0.37, −0.237] | −0.302 [−0.371, −0.239] | −0.3 | [−0.45, −0.15] | |
| −0.101 [−0.126, −0.076] | −0.099 [−0.122, −0.074] | −0.1 [−0.124, −0.075] | −0.1 | [−0.15, −0.05] | |
| −1.016 [−1.215, −0.739] | −0.977 [−1.195, −0.726] | −0.997 [−1.216, −0.739] | −1 | [−1.5, −0.5] | |
| −85.888 [−109.426, −65.1] | −84.888 [−107.133, −64.703] | −85.927 [−109.915, −65.038] | −90 | [−135, −45] | |
| 0.589 [0.501, 0.662] | 0.599 [0.512, 0.676] | 0.59 [0.507, 0.662] | 0.5 | [0.25, 0.75] | |
| 0.048 [0.036, 0.061] | 0.048 [0.036, 0.06] | 0.048 [0.036, 0.06] | 0.048 | [0.024, 0.072] | |
| −0.142 [−0.177, −0.106] | −0.142 [−0.18, −0.106] | −0.141 [−0.177, −0.105] | −0.14 | [−0.21, −0.07] |
Appendix B.2. Parameter Space

Appendix B.3. Summary Features
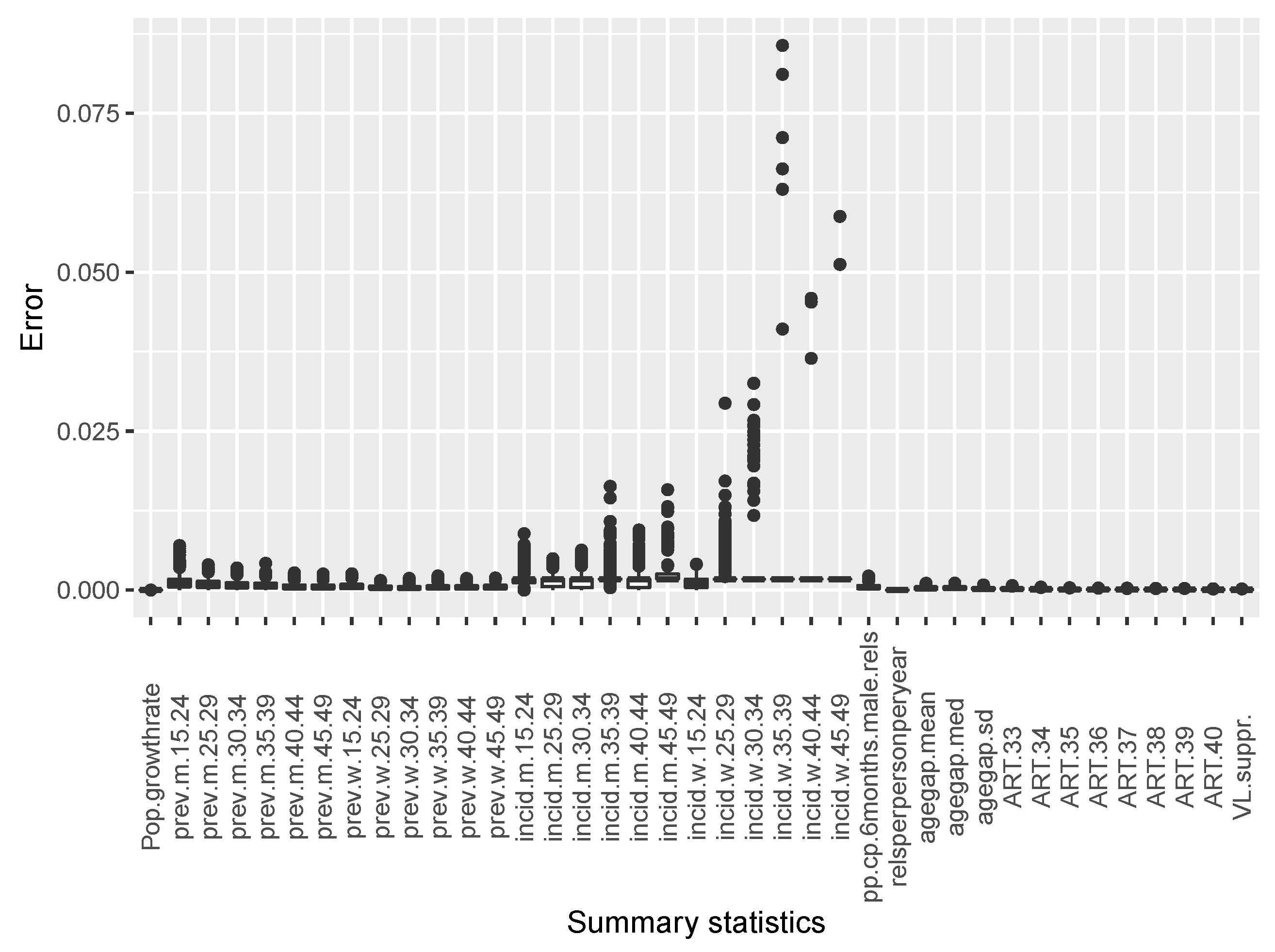
Appendix B.3.1. Summary Features from Epidemiological and Sexual Behaviour Data
| Parameter | Value |
|---|---|
| Demographic | |
| Population growth rate | 0.97933 |
| HIV epidemiology & ART intervention | |
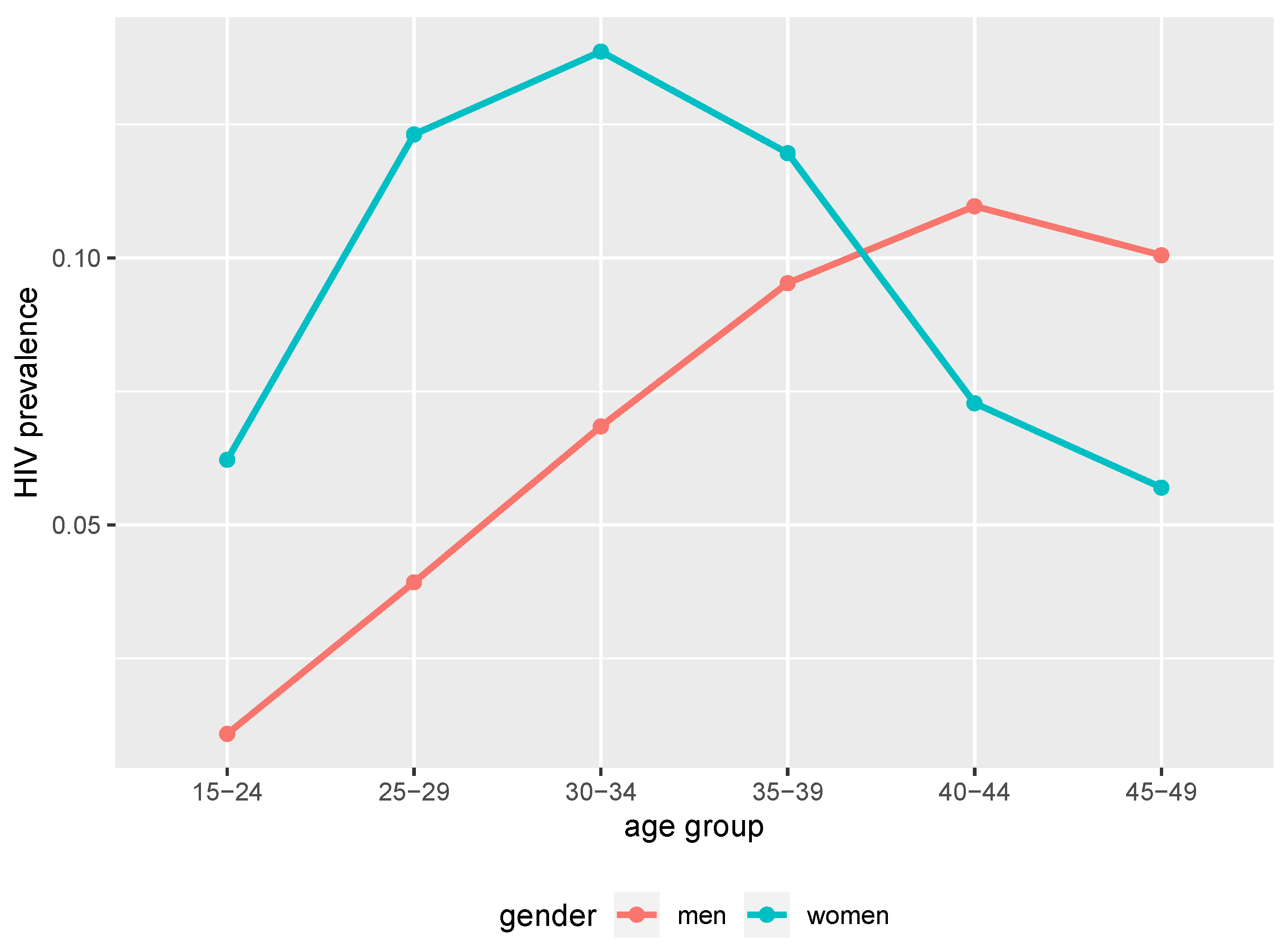
| Prevalence for men aged between 15 and 24 years | 0.0113 |
| Prevalence for men aged between 25 and 29 years | 0.04081 |
| Prevalence for men aged between 30 and 34 years | 0.07115 |
| Prevalence for men aged between 35 and 39 years | 0.09903 |
| Prevalence for men aged between 40 and 44 years | 0.114 |
| Prevalence for men aged between 45 and 49 years | 0.10446 |
| Prevalence for women aged between 15 and 24 years | 0.06467 |
| Prevalence for women aged between 25 and 29 years | 0.12797 |
| Prevalence for women aged between 30 and 34 years | 0.14411 |
| Prevalence for women aged between 35 and 39 years | 0.1243 |
| Prevalence for women aged between 40 and 44 years | 0.07557 |
| Prevalence for women aged between 45 and 49 years | 0.05917 |
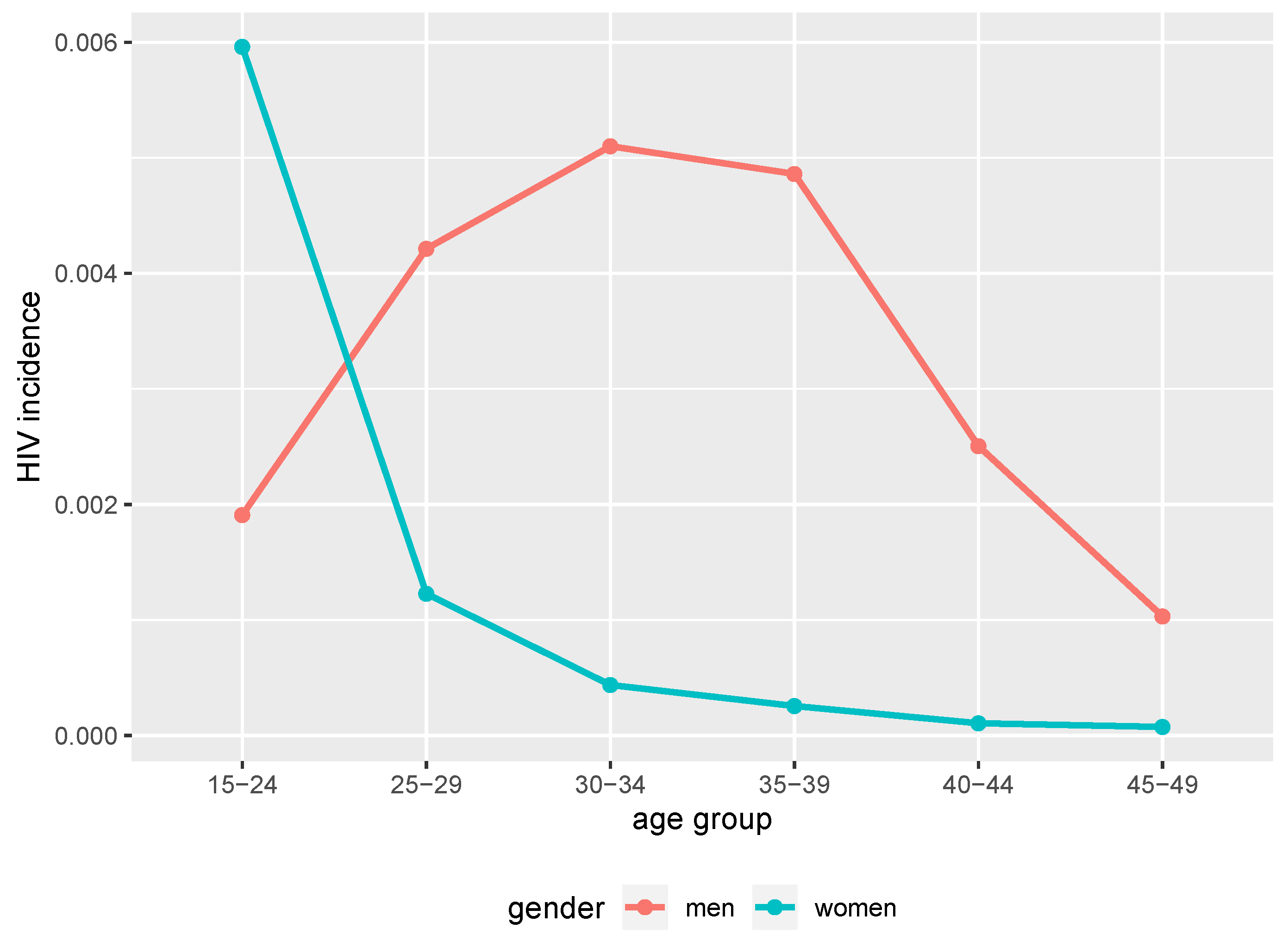
| Incidence for men aged between 15 and 24 years | 0.00198 |
| Incidence for men aged between 25 and 29 years | 0.00438 |
| Incidence for men aged between 30 and 34 years | 0.0053 |
| Incidence for men aged between 35 and 39 years | 0.00505 |
| Incidence for men aged between 40 and 44 years | 0.0026 |
| Incidence for men aged between 45 and 49 years | 0.00107 |
| Incidence for women aged between 15 and 24 years | 0.00619 |
| Incidence for women aged between 25 and 29 years | 0.00128 |
| Incidence for women aged between 30 and 34 years | 0.00045 |
| Incidence for women aged between 35 and 39 years | 0.00027 |
| Incidence for women aged between 40 and 44 years | 0.00011 |
| Incidence for women aged between 45 and 49 years | 0.00008 |
| Antiretrovial treatment coverage at 33 years of simulation time | 0.30333 |
| Antiretrovial treatment coverage at 34 years of simulation time | 0.42936 |
| Antiretrovial treatment coverage at 35 years of simulation time | 0.46119 |
| Antiretrovial treatment coverage at 36 years of simulation time | 0.48869 |
| Antiretrovial treatment coverage at 37 years of simulation time | 0.61132 |
| Antiretrovial treatment coverage at 38 years of simulation time | 0.64089 |
| Antiretrovial treatment coverage at 39 years of simulation time | 0.66607 |
| Antiretrovial treatment coverage at 40 years of simulation time | 0.79465 |
| Viral suppression | 0.84 |
| Sexual behaviour | |
| Point prevalence of concurrent partnerships for men | 0.01935 |
| Average number of relationships per person per year | 0.4 |
| Mean of age gap | 14.91719 |
| Median of age gap | 15.28017 |
| Standard deviation of age gap | 6.76228 |

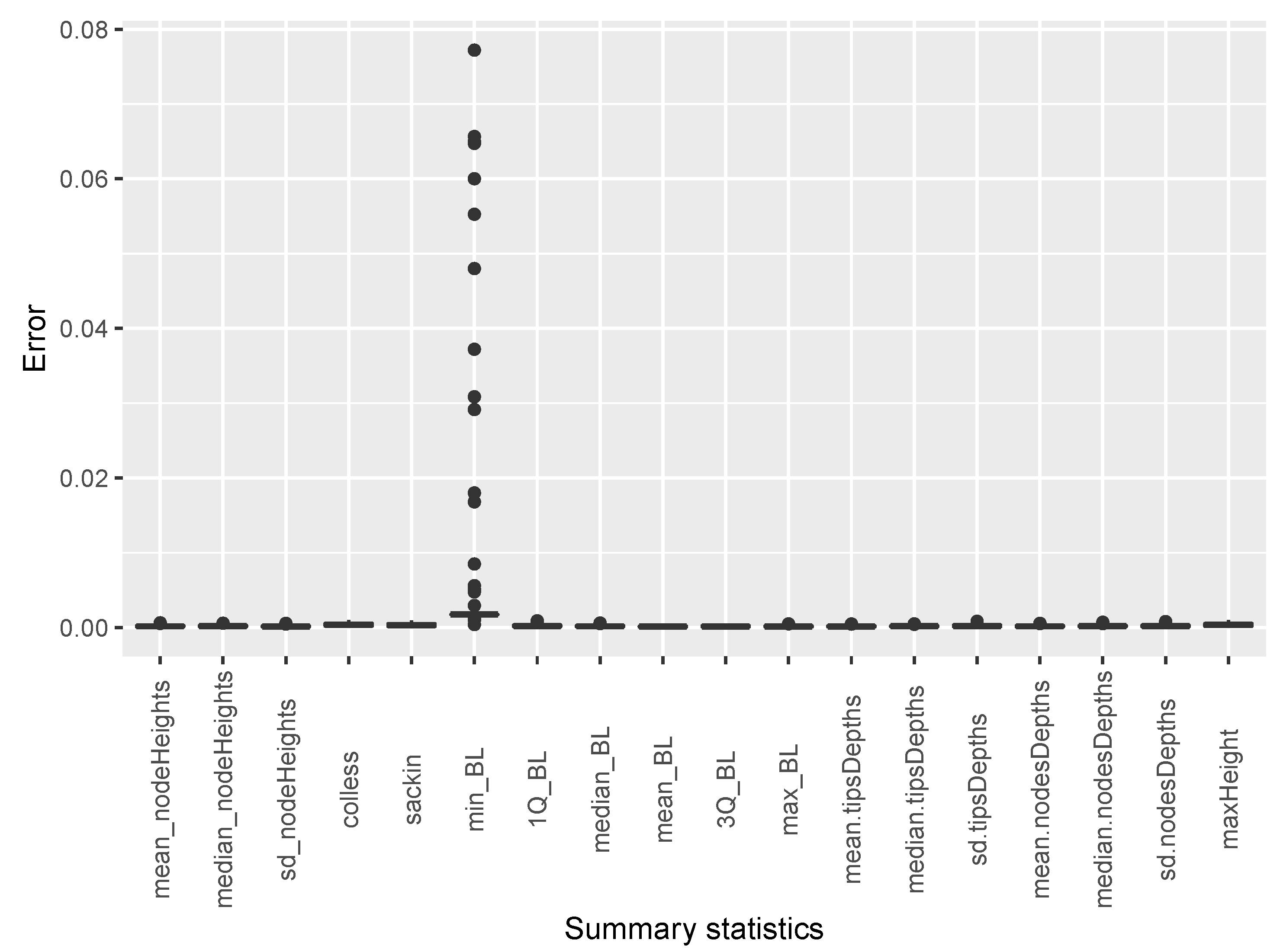
Appendix B.3.2. Summary Features from Phylogenetic Tree Data
| Parameter | Value |
|---|---|
| Phylogenetic tree topology | |
| Mean of node heights | 14.26082 |
| Median of node heights | 15.38992 |
| Standard deviation of node heights | 5.96359 |
| Colless index | 0.08942 |
| Sackin index | 0.13846 |
| Mean for tips’ depths | 13.55503 |
| Median for tips’ depths | 13.26482 |
| Standard deviation for tips’ depths | 5.26124 |
| Mean for nodes’ depths | 11.62515 |
| Median for nodes’ depths | 11.34367 |
| Standard deviation for nodes’ depths | 5.38234 |
| Phylogenetic tree branch length | |
| Minimum value of branch length | 0.00105 |
| First quantile of branch length | 0.69956 |
| Median value of branch length | 2.33402 |
| Mean value of branch length | 3.87808 |
| Third quantile of branch length | 5.50728 |
| Maximum value of branch length | 20.1533 |
| Maximum Height | 0.13391 |

Appendix B.3.3. Combined Summary Features

References
- Fettig, J.; Swaminathan, M.; Murrill, C.S.; Kaplan, J.E. Global epidemiology of HIV. Infect. Dis. Clin. 2014, 28, 323–337. [Google Scholar] [CrossRef] [Green Version]
- Kharsany, A.B.; Karim, Q.A. HIV infection and AIDS in sub-Saharan Africa: Current status, challenges and opportunities. Open AIDS J. 2016, 10, 34. [Google Scholar] [CrossRef] [Green Version]
- Ward, H.; Rönn, M. The contribution of STIs to the sexual transmission of HIV. Curr. Opin. HIV AIDS 2010, 5, 305. [Google Scholar] [CrossRef] [Green Version]
- Fox, A.M. The social determinants of HIV serostatus in sub-Saharan Africa: An inverse relationship between poverty and HIV? Public Health Rep. 2010, 125, 16–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kalichman, S.C.; Ntseane, D.; Nthomang, K.; Segwabe, M.; Phorano, O.; Simbayi, L.C. Recent multiple sexual partners and HIV transmission risks among people living with HIV/AIDS in Botswana. Sex. Transm. Infect. 2007, 83, 371–375. [Google Scholar] [CrossRef] [Green Version]
- Mah, T.L.; Halperin, D.T. Concurrent sexual partnerships and the HIV epidemics in Africa: Evidence to move forward. AIDS Behav. 2010, 14, 11–16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hunter, D.J. AIDS in sub-Saharan Africa: The epidemiology of heterosexual transmission and the prospects for prevention. Epidemiology 1993, 4, 63–72. [Google Scholar] [CrossRef] [PubMed]
- Shang, Y. Modeling epidemic spread with awareness and heterogeneous transmission rates in networks. J. Biol. Phys. 2013, 39, 489–500. [Google Scholar] [CrossRef] [Green Version]
- Beauclair, R. Age Differences in Sexual Relationships and HIV Transmission: Statistical Analyses of Bio-Behavioural Survey Data from Southern Africa. Ph.D. Thesis, Ghent University, Ghent, Belgium, 2018. [Google Scholar]
- Nelson, K.E.; Galai, N.; Safaeian, M.; Strathdee, S.A.; Celentano, D.D.; Vlahov, D. Temporal trends in the incidence of human immunodeficiency virus infection and risk behavior among injection drug users in Baltimore, Maryland, 1988–1998. Am. J. Epidemiol. 2002, 156, 641–653. [Google Scholar] [CrossRef] [Green Version]
- Grabowski, M.K.; Serwadda, D.M.; Gray, R.H.; Nakigozi, G.; Kigozi, G.; Kagaayi, J.; Ssekubugu, R.; Nalugoda, F.; Lessler, J.; Lutalo, T.; et al. HIV prevention efforts and incidence of HIV in Uganda. N. Engl. J. Med. 2017, 377, 2154–2166. [Google Scholar] [CrossRef]
- Riedner, G.; Hoffmann, O.; Rusizoka, M.; Mmbando, D.; Maboko, L.; Grosskurth, H.; Todd, J.; Hayes, R.; Hoelscher, M. Decline in sexually transmitted infection prevalence and HIV incidence in female barworkers attending prevention and care services in Mbeya Region, Tanzania. Aids 2006, 20, 609–615. [Google Scholar] [CrossRef] [PubMed]
- Smith, J.; Nyamukapa, C.; Gregson, S.; Lewis, J.; Magutshwa, S.; Schumacher, C.; Mushati, P.; Hallett, T.; Garnett, G. The distribution of sex acts and condom use within partnerships in a rural sub-Saharan African population. PLoS ONE 2014, 9, e88378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hazelbag, C.M.; Dushoff, J.; Dominic, E.M.; Mthombothi, Z.E.; Delva, W. Calibration of individual-based models to epidemiological data: A systematic review. PLoS Comput. Biol. 2020, 16, e1007893. [Google Scholar] [CrossRef] [PubMed]
- Helleringer, S.; Kohler, H.P. Sexual network structure and the spread of HIV in Africa: Evidence from Likoma Island, Malawi. Aids 2007, 21, 2323–2332. [Google Scholar] [CrossRef] [PubMed]
- Helleringer, S.; Mkandawire, J.; Kalilani-Phiri, L.; Kohler, H.P. Cohort profile: The Likoma network study (LNS). Int. J. Epidemiol. 2014, 43, 545–557. [Google Scholar] [CrossRef] [Green Version]
- Grabowski, M.K.; Redd, A.D. Molecular tools for studying HIV transmission in sexual networks. Curr. Opin. HIV AIDS 2014, 9, 126. [Google Scholar] [CrossRef]
- De Oliveira, T.; Kharsany, A.B.; Gräf, T.; Cawood, C.; Khanyile, D.; Grobler, A.; Puren, A.; Madurai, S.; Baxter, C.; Karim, Q.A.; et al. Transmission networks and risk of HIV infection in KwaZulu-Natal, South Africa: A community-wide phylogenetic study. Lancet HIV 2017, 4, e41–e50. [Google Scholar] [CrossRef] [Green Version]
- Robinson, K.; Fyson, N.; Cohen, T.; Fraser, C.; Colijn, C. How the dynamics and structure of sexual contact networks shape pathogen phylogenies. PLoS Comput. Biol. 2013, 9, e1003105. [Google Scholar] [CrossRef]
- Leigh Brown, A.J.; Lycett, S.J.; Weinert, L.; Hughes, G.J.; Fearnhill, E.; Dunn, D.T. Transmission network parameters estimated from HIV sequences for a nationwide epidemic. J. Infect. Dis. 2011, 204, 1463–1469. [Google Scholar] [CrossRef] [Green Version]
- Baum, D. Reading a phylogenetic tree: The meaning of monophyletic groups. Nat. Educ. 2008, 1, 190. [Google Scholar]
- Stadler, T.; Kühnert, D.; Bonhoeffer, S.; Drummond, A.J. Birth–death skyline plot reveals temporal changes of epidemic spread in HIV and hepatitis C virus (HCV). Proc. Natl. Acad. Sci. USA 2013, 110, 228–233. [Google Scholar] [CrossRef] [Green Version]
- Grabowski, M.K.; Lessler, J.; Redd, A.D.; Kagaayi, J.; Laeyendecker, O.; Ndyanabo, A.; Nelson, M.I.; Cummings, D.A.; Bwanika, J.B.; Mueller, A.C.; et al. The role of viral introductions in sustaining community-based HIV epidemics in rural Uganda: Evidence from spatial clustering, phylogenetics, and egocentric transmission models. PLoS Med. 2014, 11, e1001610. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hallinan, N. Tree shape: Phylogenies & macroevolution. Integr. Biol. B 2011, 9. Available online: http://ib.berkeley.edu/courses/ib200b/lect/ib200b_lect16_Nat_Hallinan_Lindberg_tree_shape2.pdf (accessed on 10 July 2020).
- Colijn, C.; Gardy, J. Phylogenetic tree shapes resolve disease transmission patterns. Evol. Med. Public Health 2014, 2014, 96–108. [Google Scholar] [CrossRef] [PubMed]
- Giardina, F.; Romero-Severson, E.O.; Albert, J.; Britton, T.; Leitner, T. Inference of transmission network structure from HIV phylogenetic trees. PLoS Comput. Biol. 2017, 13, e1005316. [Google Scholar] [CrossRef] [Green Version]
- Lewis, F.; Hughes, G.J.; Rambaut, A.; Pozniak, A.; Brown, A.J.L. Episodic sexual transmission of HIV revealed by molecular phylodynamics. PLoS Med. 2008, 5, e50. [Google Scholar] [CrossRef] [Green Version]
- Volz, E.M.; Pond, S.L.K.; Ward, M.J.; Brown, A.J.L.; Frost, S.D. Phylodynamics of infectious disease epidemics. Genetics 2009, 183, 1421–1430. [Google Scholar] [CrossRef] [Green Version]
- Rasmussen, D.A.; Volz, E.M.; Koelle, K. Phylodynamic inference for structured epidemiological models. PLoS Comput. Biol. 2014, 10, e1003570. [Google Scholar] [CrossRef]
- Liesenborgs, J.; Hendrickx, D.M.; Kuylen, E.; Niyukuri, D.; Hens, N.; Delva, W. SimpactCyan 1.0: An Open-source Simulator for Individual-Based Models in HIV Epidemiology with R and Python Interfaces. Sci. Rep. 2019, 9, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Vasylyeva, T.I.; Friedman, S.R.; Paraskevis, D.; Magiorkinis, G. Integrating molecular epidemiology and social network analysis to study infectious diseases: Towards a socio-molecular era for public health. Infect. Genet. Evol. 2016, 46, 248–255. [Google Scholar] [CrossRef] [Green Version]
- Paraskevis, D.; Nikolopoulos, G.; Magiorkinis, G.; Hodges-Mameletzis, I.; Hatzakis, A. The application of HIV molecular epidemiology to public health. Infect. Genet. Evol. 2016, 46, 159–168. [Google Scholar] [CrossRef] [PubMed]
- Grenfell, B.T.; Pybus, O.G.; Gog, J.R.; Wood, J.L.; Daly, J.M.; Mumford, J.A.; Holmes, E.C. Unifying the epidemiological and evolutionary dynamics of pathogens. Science 2004, 303, 327–332. [Google Scholar] [CrossRef] [Green Version]
- Niyukuri, D.; Nyasulu, P.; Delva, W. Assessing the uncertainty around age-mixing patterns in HIV transmission inferred from phylogenetic trees. PLoS ONE 2021, 16, e0249013. [Google Scholar] [CrossRef]
- Liesenborgs, J. Simpact Cyan. 2017. Available online: https://simpactcyan.readthedocs.io/en/latest/index.html (accessed on 10 July 2020).
- Plazy, M.; Dabis, F.; Naidu, K.; Joanna, O.G.; Barnighausen, T.; Rosemary, D.S. Change of treatment guidelines and evolution of ART initiation in rural South Africa: Data of a large HIV care and treatment programme. BMC Infect. Dis. 2015, 15, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Tymejczyk, O.; Brazier, E.; Yiannoutsos, C.; Wools-Kaloustian, K.; Althoff, K.; Crabtree-Ramírez, B.; Van Nguyen, K.; Zaniewski, E.; Dabis, F.; Sinayobye, J.d.; et al. HIV treatment eligibility expansion and timely antiretroviral treatment initiation following enrollment in HIV care: A metaregression analysis of programmatic data from 22 countries. PLoS Med. 2018, 15, e1002534. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zuma, K.; Shisana, O.; Rehle, T.M.; Simbayi, L.C.; Jooste, S.; Zungu, N.; Labadarios, D.; Onoya, D.; Evans, M.; Moyo, S.; et al. New insights into HIV epidemic in South Africa: Key findings from the National HIV Prevalence, Incidence and Behaviour Survey, 2012. Afr. J. AIDS Res. 2016, 15, 67–75. [Google Scholar] [CrossRef]
- Bicego, G.T.; Nkambule, R.; Peterson, I.; Reed, J.; Donnell, D.; Ginindza, H.; Duong, Y.T.; Patel, H.; Bock, N.; Philip, N.; et al. Recent patterns in population-based HIV prevalence in Swaziland. PLoS ONE 2013, 8, e77101. [Google Scholar]
- Justman, J.; Reed, J.B.; Bicego, G.; Donnell, D.; Li, K.; Bock, N.; Koler, A.; Philip, N.M.; Mlambo, C.K.; Parekh, B.S.; et al. Swaziland HIV Incidence Measurement Survey (SHIMS): A prospective national cohort study. Lancet HIV 2017, 4, e83–e92. [Google Scholar] [CrossRef] [Green Version]
- Rambaut, A.; Grass, N.C. Seq-Gen: An application for the Monte Carlo simulation of DNA sequence evolution along phylogenetic trees. Bioinformatics 1997, 13, 235–238. [Google Scholar] [CrossRef]
- West, B.T.; Welch, K.B.; Galecki, A.T. Linear Mixed Models: A Practical Guide Using Statistical Software; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting linear mixed-effects models using lme4. arXiv 2014, arXiv:1406.5823. [Google Scholar]
- Stein, M. Large sample properties of simulations using Latin hypercube sampling. Technometrics 1987, 29, 143–151. [Google Scholar] [CrossRef]
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 2000, 42, 55–61. [Google Scholar] [CrossRef]
- Csilléry, K.; Blum, M.G.; Gaggiotti, O.E.; François, O. Approximate Bayesian computation (ABC) in practice. Trends Ecol. Evol. 2010, 25, 410–418. [Google Scholar] [CrossRef]
- Akullian, A.; Bershteyn, A.; Klein, D.; Vandormael, A.; Bärnighausen, T.; Tanser, F. Sexual partnership age pairings and risk of HIV acquisition in rural South Africa. AIDS 2017, 31, 1755. [Google Scholar] [CrossRef] [PubMed]
- Cohen, M.S.; Chen, Y.Q.; McCauley, M.; Gamble, T.; Hosseinipour, M.C.; Kumarasamy, N.; Hakim, J.G.; Kumwenda, J.; Grinsztejn, B.; Pilotto, J.H.; et al. Prevention of HIV-1 infection with early antiretroviral therapy. N. Engl. J. Med. 2011, 365, 493–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Willem, L. Agent-Based Models for Infectious Disease Transmission: Exploration, Estimation & Computational Efficiency. Ph.D. Thesis, University of Antwerp, Antwerp, Belgium, 2015. [Google Scholar]
- Hunter, E.; Mac Namee, B.; Kelleher, J.D. A Comparison of Agent-Based Models and Equation Based Models for Infectious Disease Epidemiology. In Proceedings of the 26th AIAI Irish Conference on Artificial Intelligence and Cognitive Science, Dublin, Ireland, 6–7 December 2018. [Google Scholar]
- Shang, Y. Mixed SI (R) epidemic dynamics in random graphs with general degree distributions. Appl. Math. Comput. 2013, 219, 5042–5048. [Google Scholar] [CrossRef]
- Arnaout, R.A.; Lloyd, A.L.; O’Brien, T.R.; Goedert, J.J.; Leonard, J.M.; Nowak, M.A. A simple relationship between viral load and survival time in HIV-1 infection. Proc. Natl. Acad. Sci. USA 1999, 96, 11549–11553. [Google Scholar] [CrossRef] [Green Version]
- Leventhal, M.G.E. An R package ‘expoTree’, r2013. Available online: http://www2.uaem.mx/r-mirror/web/packages/expoTree/expoTree.pdf (accessed on 7 July 2020).
- Revell, L.J. phytools: An R package for phylogenetic comparative biology (and other things). Methods Ecol. Evol. 2012, 3, 217–223. [Google Scholar] [CrossRef]
- LANL. HIV-1 Subtype C. 2017. Available online: https://www.hiv.lanl.gov/components/sequence/HIV/asearch/query_one.comp?se_id=JN188292 (accessed on 7 July 2020).
- LANL. Landmarks of the HIV-1 Genome. 2017. Available online: https://www.hiv.lanl.gov/content/sequence/HIV/MAP/landmark.html (accessed on 7 July 2020).
- Darriba, D.; Posada, D. jModelTest 2 Manual v0. 1.10. Parallel Comput. 2016, 9, 772. [Google Scholar]
- Lemey, P.; Rambaut, A.; Pybus, O.G. HIV evolutionary dynamics within and among hosts. AIDS Rev. 2006, 8, 125–140. [Google Scholar]
- Frost, S.D.; Pybus, O.G.; Gog, J.R.; Viboud, C.; Bonhoeffer, S.; Bedford, T. Eight challenges in phylodynamic inference. Epidemics 2015, 10, 88–92. [Google Scholar] [CrossRef] [Green Version]
- Metcalf, C.; Birger, R.; Funk, S.; Kouyos, R.; Lloyd-Smith, J.; Jansen, V. Five challenges in evolution and infectious diseases. Epidemics 2015, 10, 40–44. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gog, J.R.; Pellis, L.; Wood, J.L.; McLean, A.R.; Arinaminpathy, N.; Lloyd-Smith, J.O. Seven challenges in modeling pathogen dynamics within-host and across scales. Epidemics 2015, 10, 45–48. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Volz, E.M.; Romero-Severson, E.; Leitner, T. Phylodynamic inference across epidemic scales. Mol. Biol. Evol. 2017, 34, 1276–1288. [Google Scholar] [CrossRef] [Green Version]
- Mideo, N.; Alizon, S.; Day, T. Linking within-and between-host dynamics in the evolutionary epidemiology of infectious diseases. Trends Ecol. Evol. 2008, 23, 511–517. [Google Scholar] [CrossRef] [PubMed]





| Estimate | Benchmark | Calibration 1 | Calibration 1 * | Calibration 2 | Calibration 2 * | Calibration 3 | Calibration 3 * |
|---|---|---|---|---|---|---|---|
| AAD | 13.782 | 13.861 | 14.167 | 13.151 | 13.111 | 13.633 | 13.83 |
| SDAD | 6.15 | 6.114 | 6.17 | 6.008 | 6.113 | 6.073 | 6.164 |
| BSD | 2.138 | 2.013 | 2.077 | 2.026 | 2.137 | 2.004 | 2.098 |
| WSD | 1.812 | 1.781 | 1.774 | 1.837 | 1.807 | 1.811 | 1.779 |
| Slope | 0.315 | 0.297 | 0.302 | 0.316 | 0.319 | 0.305 | 0.305 |
| Intercept | −2.378 | −2.111 | −2.336 | −2.099 | −2.2 | −2.164 | −2.264 |
| Estimate | MRE 1 | MRE 1 * | MRE 2 | MRE 2 * | MRE 3 | MRE 3 * |
|---|---|---|---|---|---|---|
| AAD | 0.16399 | 0.03948 | 0.19238 | 0.05177 | 0.16766 | 0.0325 |
| SDAD | 0.10248 | 0.04145 | 0.10447 | 0.04005 | 0.10367 | 0.04208 |
| BSD | 0.17373 | 0.06907 | 0.16063 | 0.06254 | 0.16258 | 0.06986 |
| WSD | 0.09965 | 0.057 | 0.10925 | 0.05368 | 0.10193 | 0.05984 |
| Slope | 0.20558 | 0.08395 | 0.21915 | 0.07315 | 0.20482 | 0.07606 |
| Intercept | 0.37034 | 0.16361 | 0.39138 | 0.16511 | 0.39999 | 0.16004 |
| Estimate | Benchmark | Calibration 1 | Calibration 1 * | Calibration 2 | Calibration 2 * | Calibration 3 | Calibration 3 * |
|---|---|---|---|---|---|---|---|
| Mean | 2.242 | 2.384 | 2.245 | 2.323 | 2.24 | 2.356 | 2.246 |
| Median | 1.391 | 1.351 | 1.31 | 1.391 | 1.303 | 1.354 | 1.337 |
| Standard deviation | 2.12 | 2.622 | 2.27 | 2.428 | 2.296 | 2.579 | 2.273 |
| Estimate | MRE 1 | MRE 1 * | MRE 2 | MRE 2 * | MRE 3 | MRE 3 * |
|---|---|---|---|---|---|---|
| Mean | 0.17513 | 0.1349 | 0.15716 | 0.12686 | 0.16807 | 0.13272 |
| Median | 0.3271 | 0.31999 | 0.34116 | 0.31962 | 0.32561 | 0.32279 |
| Standard deviation | 0.46932 | 0.32561 | 0.39235 | 0.32676 | 0.45539 | 0.33333 |
| Year | Age Group | MRE 1 | MRE 1 * | MRE 2 | MRE 2 * | MRE 3 | MRE 3 * |
|---|---|---|---|---|---|---|---|
| 2013 | 15–24 | 1.05475 | 0.88048 | 1.34137 | 1.0745 | 1.06295 | 0.93416 |
| 25–29 | 0.87811 | 0.76712 | 0.95202 | 0.88461 | 0.89938 | 0.78916 | |
| 30–34 | 0.91606 | 0.8875 | 0.96849 | 0.91955 | 0.96005 | 0.88494 | |
| 35–39 | 0.78408 | 0.66974 | 0.7441 | 0.67547 | 0.75629 | 0.67397 | |
| 40–44 | 0.89173 | 0.78456 | 0.79473 | 0.73747 | 0.91572 | 0.74142 | |
| 45–49 | 1.23131 | 1.04045 | 1.13016 | 0.99237 | 1.22711 | 1.00805 | |
| 2014 | 15–24 | 1.02293 | 0.89883 | 1.26296 | 1.0851 | 1.08533 | 0.97876 |
| 25–29 | 0.96249 | 0.88694 | 1.10231 | 1.02698 | 0.98951 | 0.90741 | |
| 30–34 | 0.86408 | 0.87018 | 0.90373 | 0.89681 | 0.92165 | 0.84121 | |
| 35–39 | 0.97827 | 0.87733 | 0.93042 | 0.88425 | 0.99837 | 0.8737 | |
| 40–44 | 1.06991 | 0.91003 | 0.92059 | 0.91656 | 0.97718 | 0.88609 | |
| 45–49 | 1.45055 | 1.29848 | 1.27103 | 1.16657 | 1.4448 | 1.15002 | |
| 2015 | 15–24 | 1.15855 | 0.89525 | 1.33417 | 1.25347 | 1.27041 | 1.03238 |
| 25–29 | 1.00525 | 0.93552 | 1.09395 | 1.16055 | 1.12176 | 0.9917 | |
| 30–34 | 0.92342 | 0.89038 | 0.91207 | 0.96075 | 0.94996 | 0.93358 | |
| 35–39 | 1.07437 | 0.93358 | 0.95423 | 0.90022 | 0.90746 | 0.87915 | |
| 40–44 | 1.07316 | 0.88081 | 0.96276 | 0.80236 | 1.00017 | 0.85782 | |
| 45–49 | 1.75576 | 1.50713 | 1.53888 | 1.44127 | 1.55175 | 1.37258 | |
| 2016 | 15–24 | 1.13425 | 0.98986 | 1.33453 | 1.22738 | 1.25674 | 1.0544 |
| 25–29 | 1.02155 | 0.96523 | 1.23536 | 1.05684 | 1.05984 | 0.96505 | |
| 30–34 | 0.91918 | 0.94391 | 0.97993 | 1.03122 | 0.97103 | 0.97724 | |
| 35–39 | 1.18662 | 1.2673 | 1.25378 | 1.12695 | 1.16183 | 1.20835 | |
| 40–44 | 1.03665 | 0.96006 | 0.96548 | 0.83396 | 0.90925 | 0.92091 | |
| 45–49 | 1.47005 | 1.41002 | 1.40545 | 1.29973 | 1.38828 | 1.31173 | |
| 2017 | 15–24 | 1.35979 | 1.1209 | 1.35127 | 1.29633 | 1.39386 | 1.21792 |
| 25–29 | 0.95806 | 1.01259 | 1.08813 | 1.01433 | 0.99 | 0.97441 | |
| 30–34 | 1.00497 | 0.97803 | 1.08916 | 1.01595 | 1.02405 | 1.00899 | |
| 35–39 | 1.34227 | 1.46893 | 1.3267 | 1.30232 | 1.35038 | 1.37524 | |
| 40–44 | 1.13972 | 1.07222 | 1.20909 | 0.99736 | 1.05262 | 1.03022 | |
| 45–49 | 1.58792 | 1.51293 | 1.74517 | 1.38875 | 1.47887 | 1.41031 |
| Year | Age Group | MRE 1 | MRE 1 * | MRE 2 | MRE 2 * | MRE 3 | MRE 3 * |
|---|---|---|---|---|---|---|---|
| 2013 | 15–24 | 0.53162 | 0.47872 | 0.52974 | 0.49637 | 0.49674 | 0.46769 |
| 25–29 | 1.1711 | 1.10191 | 1.02598 | 1.08174 | 1.06856 | 1.07796 | |
| 30-34 | 1.4554 | 1.59738 | 1.48093 | 1.4674 | 1.57672 | 1.38211 | |
| 35–39 | 1.27389 | 1.56912 | 1.43407 | 1.45138 | 1.4723 | 1.39072 | |
| 40–44 | 1.5237 | 1.77582 | 1.58568 | 1.65677 | 1.69882 | 1.47681 | |
| 45–49 | 1.41214 | 1.95796 | 1.45311 | 1.63971 | 1.51047 | 1.46651 | |
| 2014 | 15–24 | 0.54265 | 0.50475 | 0.58463 | 0.5347 | 0.54235 | 0.48523 |
| 25–29 | 1.35538 | 1.30714 | 1.25242 | 1.19749 | 1.26711 | 1.21816 | |
| 30–34 | 1.58765 | 1.74194 | 1.51293 | 1.54455 | 1.59564 | 1.3997 | |
| 35–39 | 1.2958 | 1.44317 | 1.48171 | 1.56704 | 1.47045 | 1.27727 | |
| 40–44 | 1.47626 | 1.65227 | 1.57011 | 1.61447 | 1.45799 | 1.44798 | |
| 45–49 | 1.51765 | 1.7599 | 1.51771 | 1.5789 | 1.49514 | 1.36147 | |
| 2015 | 15–24 | 0.57955 | 0.52997 | 0.60027 | 0.57768 | 0.58239 | 0.53849 |
| 25–29 | 1.51821 | 1.57128 | 1.53055 | 1.49222 | 1.59013 | 1.42023 | |
| 30–34 | 1.46685 | 1.64833 | 1.52767 | 1.55935 | 1.57546 | 1.48934 | |
| 35–39 | 1.87122 | 1.85779 | 1.71533 | 1.56098 | 1.75373 | 1.34148 | |
| 40–44 | 1.52558 | 1.72044 | 1.53849 | 1.80755 | 1.46566 | 1.42572 | |
| 45–49 | 1.72515 | 1.60911 | 1.48315 | 1.52458 | 1.62834 | 1.40109 | |
| 2016 | 15–24 | 0.58743 | 0.60129 | 0.61815 | 0.62563 | 0.59805 | 0.60696 |
| 25–29 | 1.46132 | 1.5059 | 1.41493 | 1.4317 | 1.48655 | 1.40186 | |
| 30–34 | 1.52139 | 1.58994 | 1.67728 | 1.57346 | 1.53513 | 1.44627 | |
| 35–39 | 1.67303 | 1.88848 | 1.78009 | 1.90138 | 1.91832 | 1.4736 | |
| 40–44 | 1.40186 | 1.73526 | 1.42221 | 1.50055 | 1.78263 | 1.34671 | |
| 45–49 | 1.52093 | 2.17204 | 2.05912 | 1.89981 | 1.45132 | 1.52321 | |
| 2017 | 15–24 | 0.70051 | 0.6883 | 0.79729 | 0.74652 | 0.75446 | 0.71317 |
| 25–29 | 1.58232 | 1.67152 | 1.58225 | 1.48288 | 1.50227 | 1.45087 | |
| 30–34 | 1.87383 | 2.07842 | 1.77046 | 1.9108 | 1.87073 | 1.54384 | |
| 35–39 | 1.73521 | 1.61932 | 1.6716 | 2.07031 | 1.49161 | 1.6285 | |
| 40–44 | 1.94166 | 2.25749 | 1.89354 | 1.8269 | 1.85843 | 1.5933 | |
| 45–49 | 1.26963 | 1.61916 | 1.24791 | 2.0685 | 1.32776 | 1.45465 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niyukuri, D.; Chibawara, T.; Nyasulu, P.S.; Delva, W. Inferring HIV Transmission Network Determinants Using Agent-Based Models Calibrated to Multi-Data Sources. Mathematics 2021, 9, 2645. https://0-doi-org.brum.beds.ac.uk/10.3390/math9212645
Niyukuri D, Chibawara T, Nyasulu PS, Delva W. Inferring HIV Transmission Network Determinants Using Agent-Based Models Calibrated to Multi-Data Sources. Mathematics. 2021; 9(21):2645. https://0-doi-org.brum.beds.ac.uk/10.3390/math9212645
Chicago/Turabian StyleNiyukuri, David, Trust Chibawara, Peter Suwirakwenda Nyasulu, and Wim Delva. 2021. "Inferring HIV Transmission Network Determinants Using Agent-Based Models Calibrated to Multi-Data Sources" Mathematics 9, no. 21: 2645. https://0-doi-org.brum.beds.ac.uk/10.3390/math9212645