1. Introduction
Control system synthesis for industrial processes has long attracted much research attention. However, the increased complexity and granularity of industrial processes make control system design difficult or intractable even for experienced engineers. Despite the sophistication of modern industrial processes, proportional–integral–derivative (PID) controllers remain the primary choice for industrial process control [
1,
2]. It was known that PID controllers could be applied to many control systems [
3]. However, the broad application spectrum of PID controllers literally means that engineers have to find their own ways to tune their PID parameters to satisfy their performance objectives [
4]. The adaptive and/or automatic tuning of the PID controller parameters was accordingly regarded as a course of development to provide feasible solutions to the problem.
Hägglund and Ȧström [
4] proposed the auto-tuning scheme for PID controllers using artificially induced limit-cycle behavior. Papadopoulos et al. [
5] proposed the automatic tuning of PID controllers based on the magnitude optimum criterion. Sarhadi et al. [
6] applied an adaptive PID control for model reference adaptive control of an autonomous underwater vehicle. They derived a PID parameter tuning law based on the Lyapunov stability theory. These foregoing works were the prime examples of automatic PID gain tuning algorithms derived analytically. However, as their developments implicitly assumed that an accurate mathematical model of the plant was available, it might be difficult to apply their results directly to real-world targets.
The application of artificial intelligence to PID tuning is an alternative solution to the problem. Acosta et al. [
7] applied the fuzzy logic algorithm to synthesize an expert PID controller based on the measurements of a closed-loop system. Solihin et al. [
8] proposed the tuning of PID parameters with the particle swarm optimization algorithm proposed by Eberhart and Kennedy [
9]. A PID controller for a temperature control problem of a heat exchanging device was proposed by Reddy and Balaji [
10], whose gains were tuned by a genetic algorithm. These behavior based tuning methods can be applied to a wide range of targets, whereas it might require repetitive plant operations or simulations to determine a set of PID parameters.
The online auto-tuning of PID parameters has been developed in combination with neural networks. Han et al. [
11] proposed a lateral tracking PID controller for their mobile wheeled robot. Their controller parameters were tuned with the help of a neural network and the back propagation algorithm. They used the Lyapunov stability theory to derive the network learning rules.
Recently, increasing interest in the application of reinforcement learning (RL) to control problems has been observed in the literature. RL itself has a structure that can directly issue control actions to a target process. Spielberg et al. [
12] proposed the actor-critic Q-learning system for the control of a multiple-input multiple-output (MIMO) process model in which they introduced deep networks in the actor and critic separately. Zou et al. [
13] used RL to formulate a deterministic greedy control policy for a thermal power generation plant. Fares et al. [
14] formulated online actor-critic RL for the control of an active suspension system and showed that their controller outperformed the optimal PID controller.
Results have also been reported in the literature that uses RL for adaptive tuning of PID controller. The intrinsic advantage of RL in PID controller tuning lies in the “learn from experience” strategy. It introduces robustness to various uncertainties that the real processes might suffer, at the cost of transient unsuccessful attempts that might happen especially in the early stages of learning. Boubertakh et al. [
15] proposed tuning of PD and PI controllers with RL. They formulated Takagi–Sugeno-type fuzzy controllers for robust inference. Wang et al. [
16] proposed an adaptive RL PID control system with a radial basis function (RBF) network for the control of a complex, highly nonlinear single-input single-output (SISO) system. Sedighnizadeh and Rezazadeh [
17] also proposed the use of RL in combination with an RBF network to synthesize an adaptive PID controller for a SISO wind turbine control problem.
The latest trend in the use of RL in PID tuning is the introduction of deep neural networks. Lee et al. [
18] introduced a deep deterministic policy gradient algorithm to synthesize adaptive PID for a dynamic positioning system. Carlucho et al. [
19] synthesized an adaptive deep reinforcement learning MIMO PID controller for model-free control of a mobile robot. These existing works offered a great enhancement to the conventional PID controllers whilst increasing robustness to uncertainties. However, most of the works targeted the control of SISO plants. Although some works treated the synthesis of the PID controller for MIMO plants, the number of inputs and/or outputs was typically limited to two or three.
In this paper, we attempt to synthesize an RL based PI controller with a feed-forward input for a thin film fabrication process that has fifteen inputs for controlling the thickness of the film and sixty-three thickness measurement outputs. We hereafter refer to our controller as the two-DOF PI controller. The objective of the film production process is to produce a film whose thickness should be as uniformly close as possible to its reference, and its perturbation should remain within the pre-specified tolerance for quality assurance of the product. This process is known to suffer from severe input coupling that originates from its mechanical design, as well as a large input lag. The tuning of the embedded PI controller parameters of the process is a difficult problem, and it requires elaborative manual tuning of highly experienced operators in the factory. We aim to provide an automatic self-tuning functionality to the PID controller in this study for automatic high-quality film production.
We use the actor-critic RL algorithm to synthesize the self-tuning two-degree-of-freedom PI control system. We introduced RBF networks to both the actor and critic independently. The critic networks are trained to approximate the value function of the states, whereas the actor networks learn to determine internal policy parameters to maximize the return. We propose to introduce the spatial coefficients for spatial augmentation of the error and the reward to help proceed with appropriate learning under the existence of input coupling. The performance of the proposed control system is evaluated through numerical simulations under several likely scenarios in the operation of industrial processes. The results demonstrate the superiority of the proposed control system over the fixed-gain PI controller.
Although we concentrate on the development of the self-tuning two-DOF PI controller for the film production process in this study, the idea of the spatial augmentation of the error and the reward can be applied to other plants that also suffer from input coupling.
Table 1 summarizes the number of documents published in the past twenty years that state the development of PID control systems for industrial processes.
The figures in the table clearly shows that there exists a consistent and strong demand for the use of PID controllers for process control problems, and their increasing trend predicts that PID controllers will continue to be used in various control problems in the future. The enhancement of PID control for process control problems developed in this article will continue to remain valuable in this light.
2. Description of the Target Process
We aim to synthesize a control system for a thin plastic film fabrication process. The objective of the control system is to fabricate a plastic film that has a spatially uniform designated thickness.
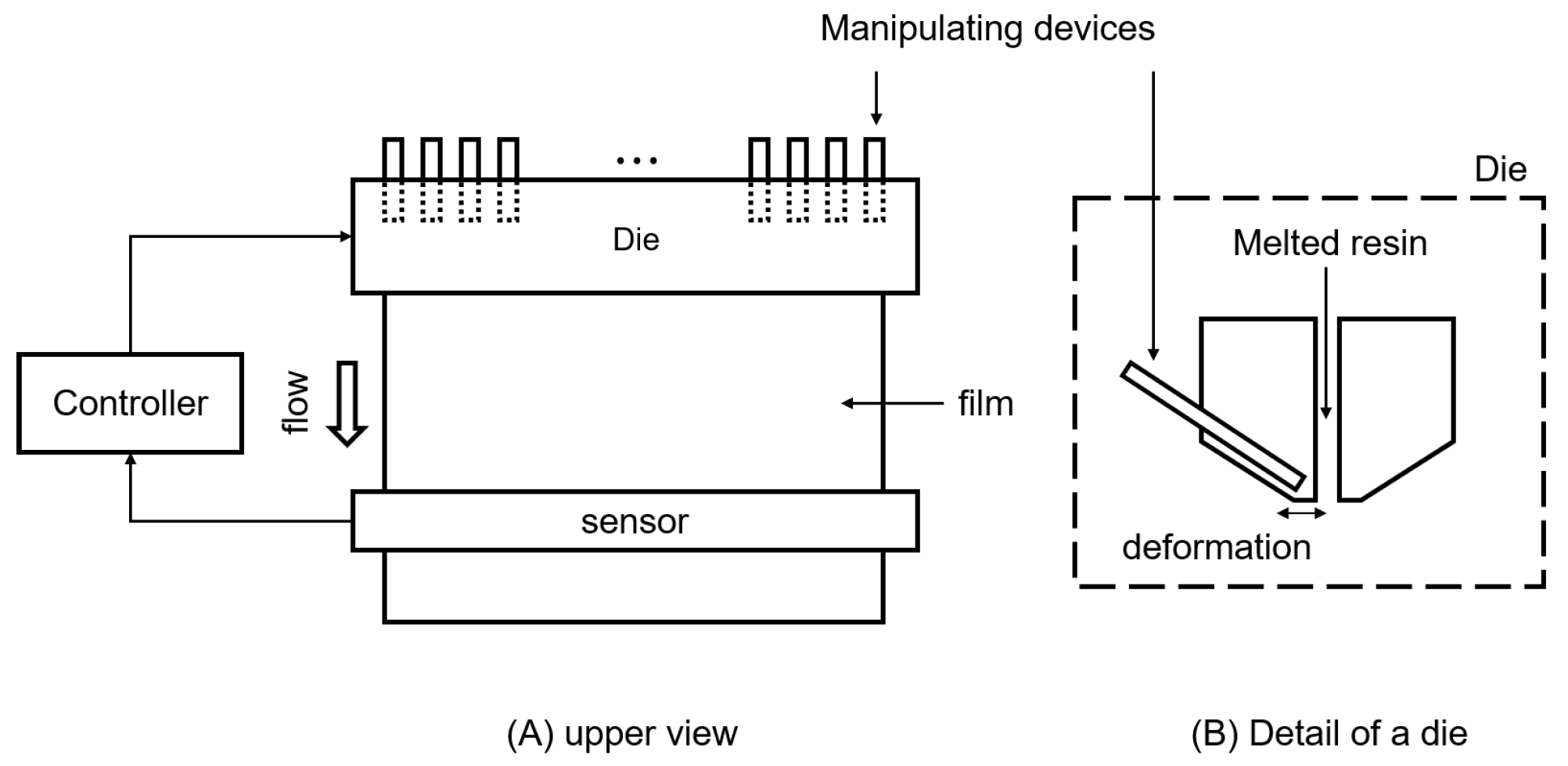
Figure 1 shows the control related schematics of the film fabrication machine. The thickness of the fabricated film is controlled by a die aligned orthogonal to the flow of melted resin. The width of the die is 63 mm. Fifteen die-manipulating devices are aligned linearly on a die with a 4 mm interval, as shown in
Figure 2. We can measure the thickness of a film with a spatial resolution of 1 mm, as shown in
Figure 2; however, we cannot monitor the cross-sectional shape of the die.
The displacement of each device can be controlled independently. We performed a step response experiment with a single manipulating device and measured its response. The transfer function of a manipulating device from its input
to the displacement
is accordingly identified to be:
where
takes a value within the interval
and
is measured in units of millimeters (mm). We hereafter assume that all manipulating devices are characterized by the transfer function (
1) in their nominal operating condition.
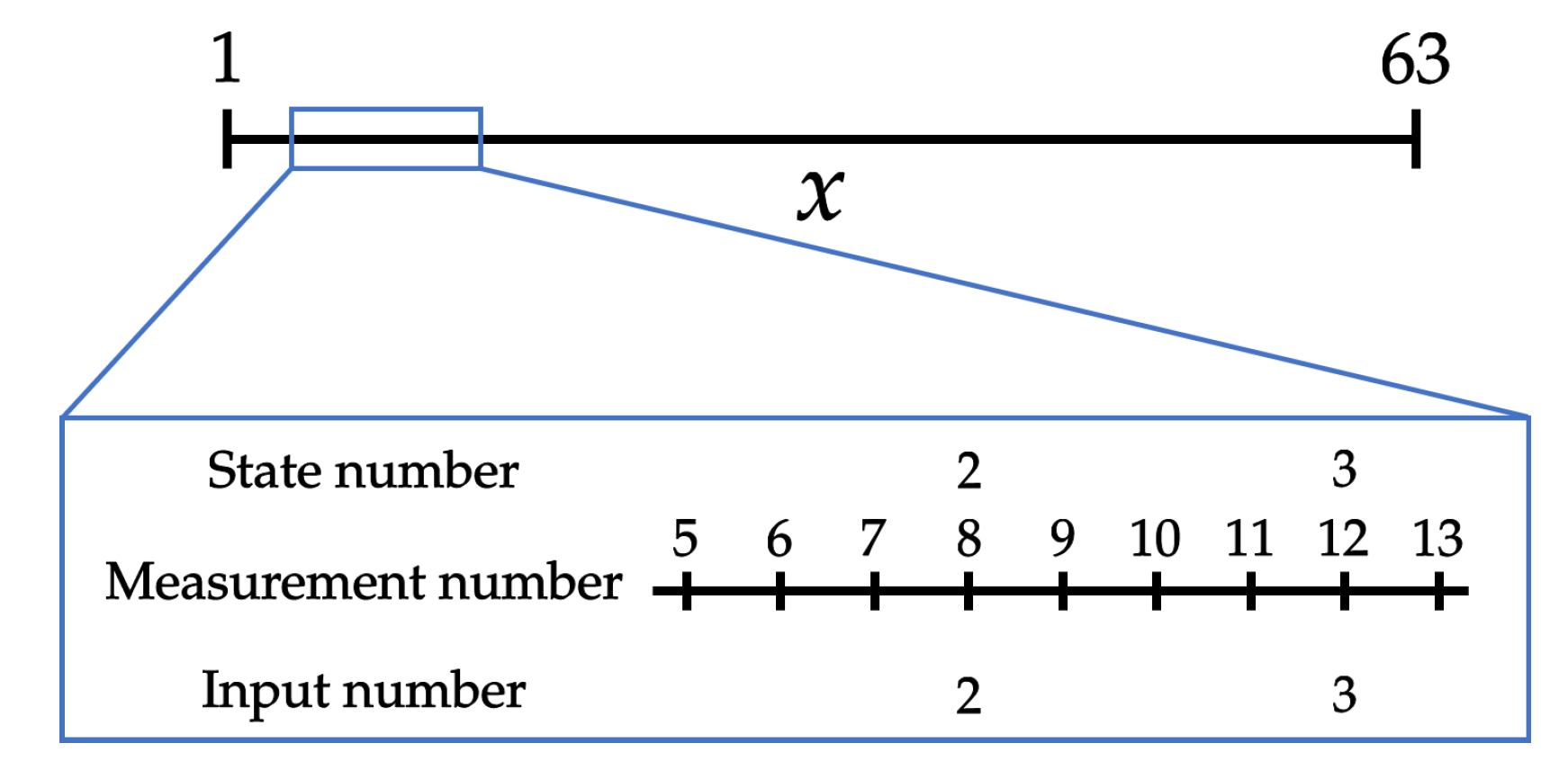
The actual shape of the cross-section of a die is determined by the displacements of the manipulating devices. The displacement of a die where a particular manipulating device is located is determined not only by the displacement of the corresponding device, but also by the displacements of other manipulating devices located nearby. Let
be the position of a film, and let
be the location of the
i-th manipulating device, as shown in
Figure 2. We model the spatial coupling of the manipulating devices with the function
given by:
where
is the distance between the position
x and the
i-th manipulating device. The blue broken lines in
Figure 3 show
for all
i. The displacement of a die at position
x can be calculated as:
where
represents the displacement of the
i-th manipulating device at time
t and
is the number of die-manipulating devices installed in the process.
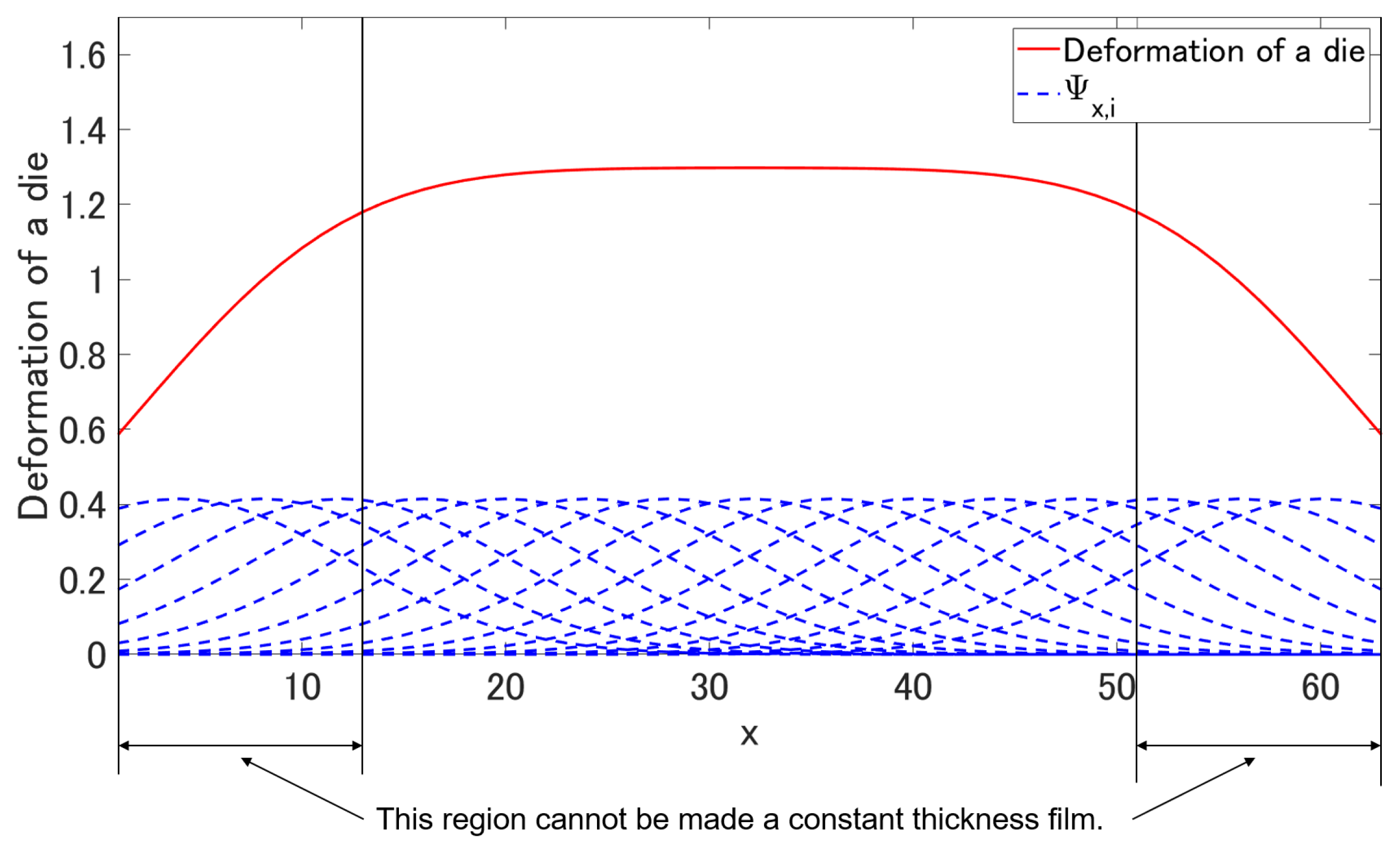
We calculated the steady-state deformation of the die by letting
and kept them until all the outputs
converged. The red solid plot in
Figure 3 shows the final form of the deformation of a die as calculated using Equation (
3). This figure shows that the deformation of the left and right edges of the die will not reach its maximum. Therefore, in some cases, the thickness of the fabricated film cannot be made constant if the reference thickness is too small. We define the control objective accordingly to regulate the thickness of the fabricated film corresponding to the region
of the die to be equal to its reference, denoted hereafter as
.
5. Performance Evaluation through Numerical Simulations
We performed numerical simulations under several likely scenarios to demonstrate the performance of the proposed control system. As a representative conventional process control technique, we synthesized a static PI controller using the Ziegler–Nichols (Z.N.) ultimate gain method. We applied the same set of gains to all
N manipulating devices and configured the spatial coupling coefficient
as:
to evaluate how much
would be effective in compensating for the intrinsic mechanical coupling caused by manipulating devices other than the
i-th one.
To quantify the control performance, we calculated the spatial root mean squared error (sRMSE), defined as:
where
is the film thickness measured at the labeled position
x in
Figure 2.
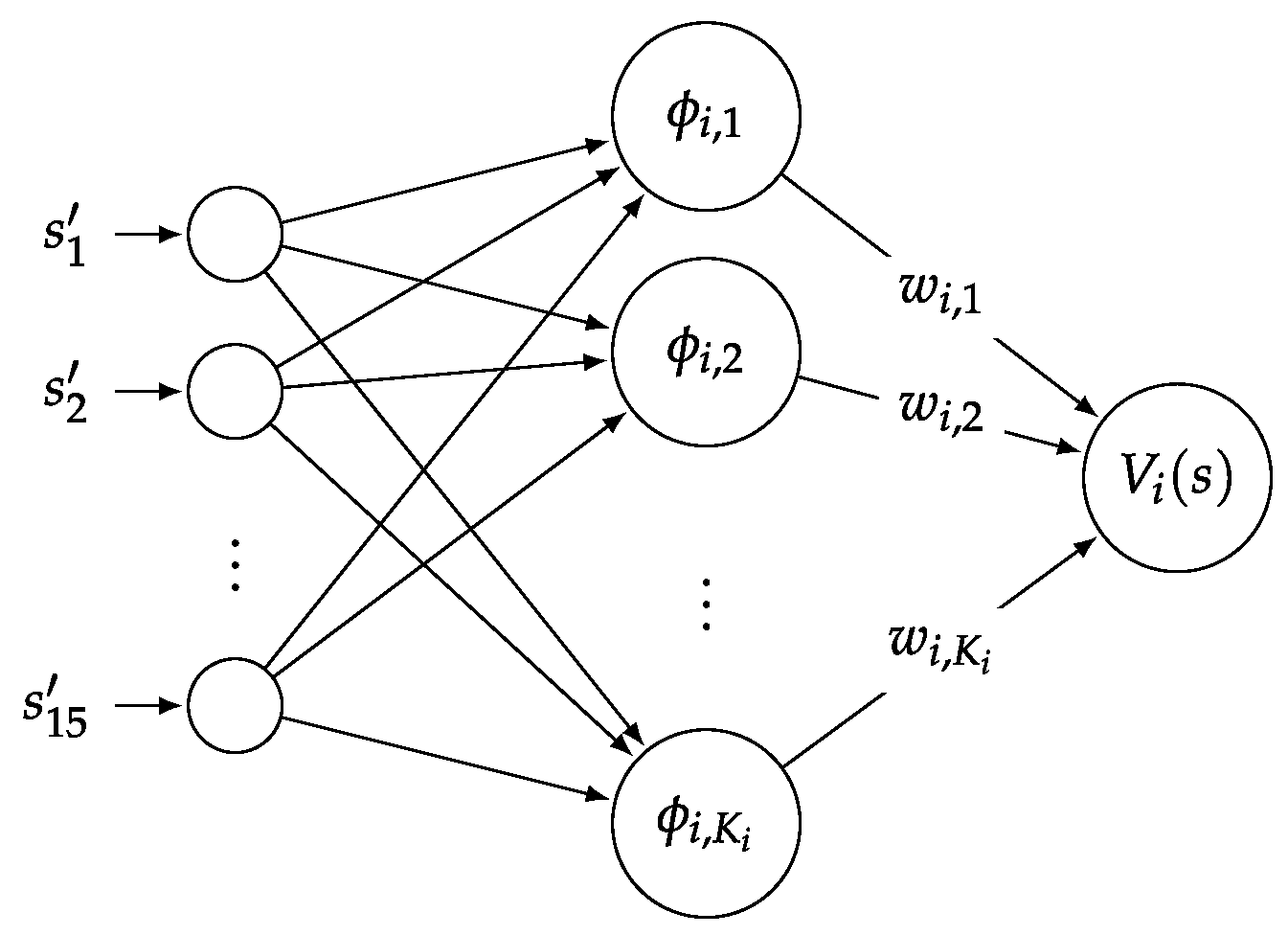
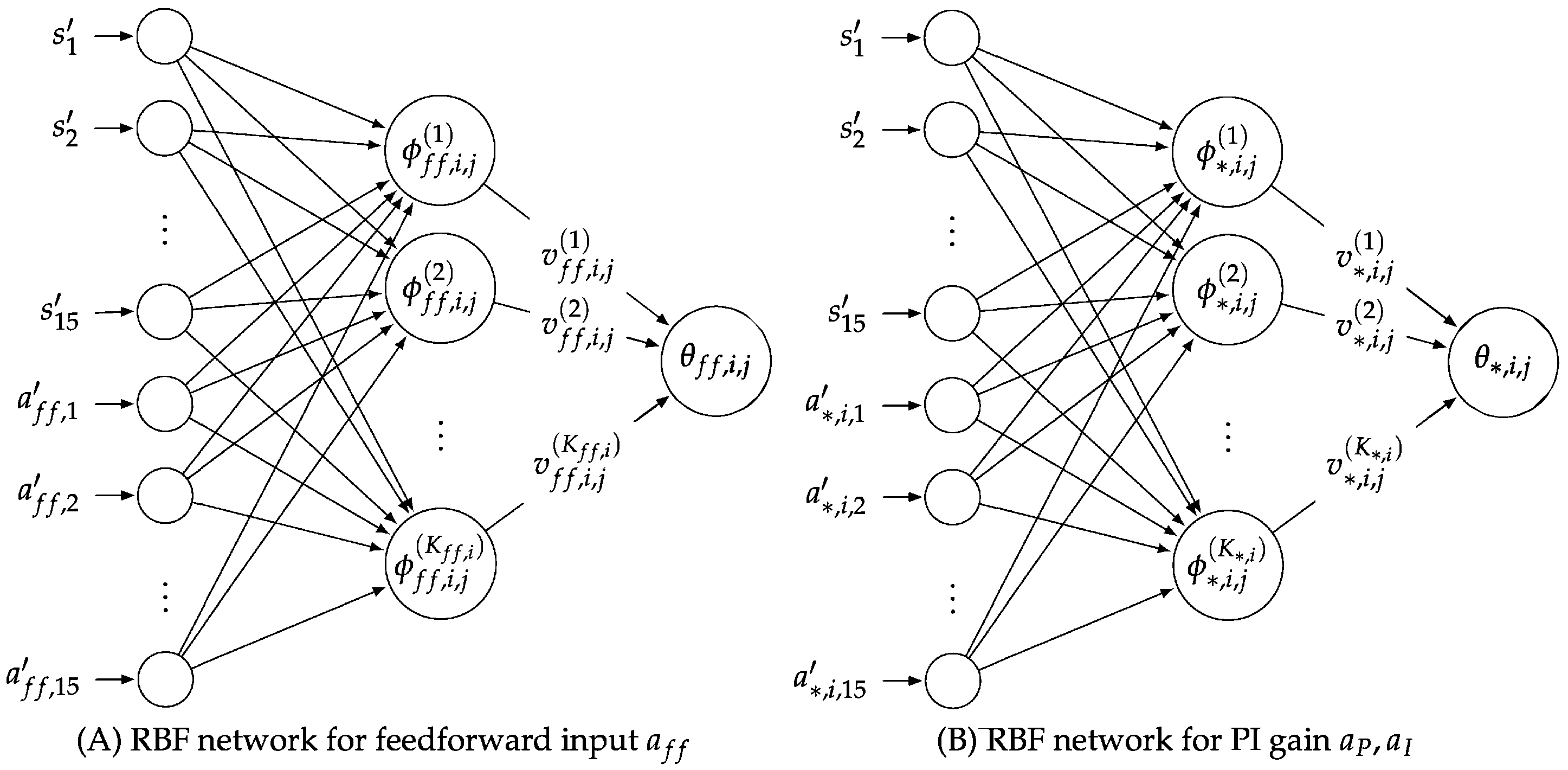
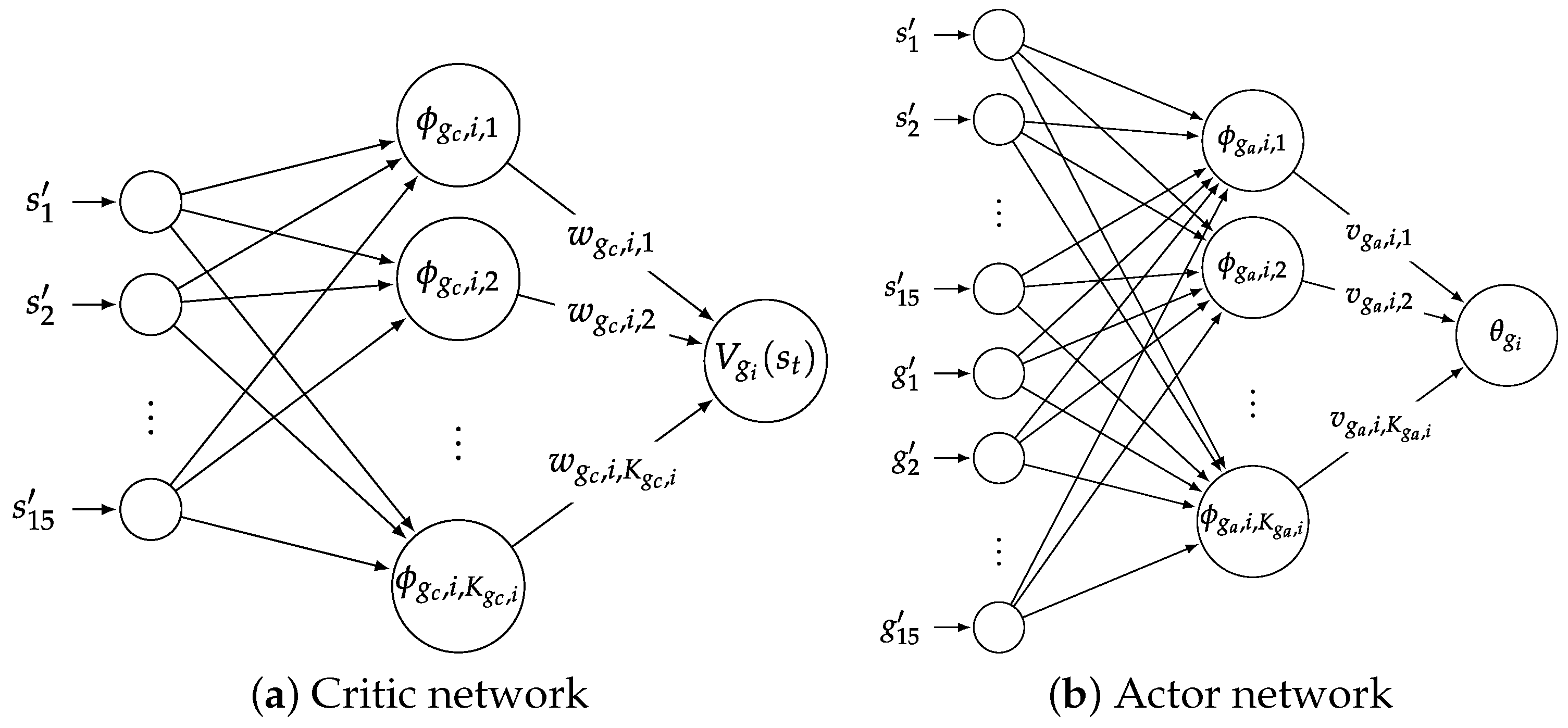
Table 2 and
Table 3 respectively list the actor and critic network parameters used in the simulation.
The sampling interval was set as 3 s in all simulation scenarios. We added random noise to the calculated thickness to simulate measurement noise. The noise was generated within a range of the reference thickness of a film.
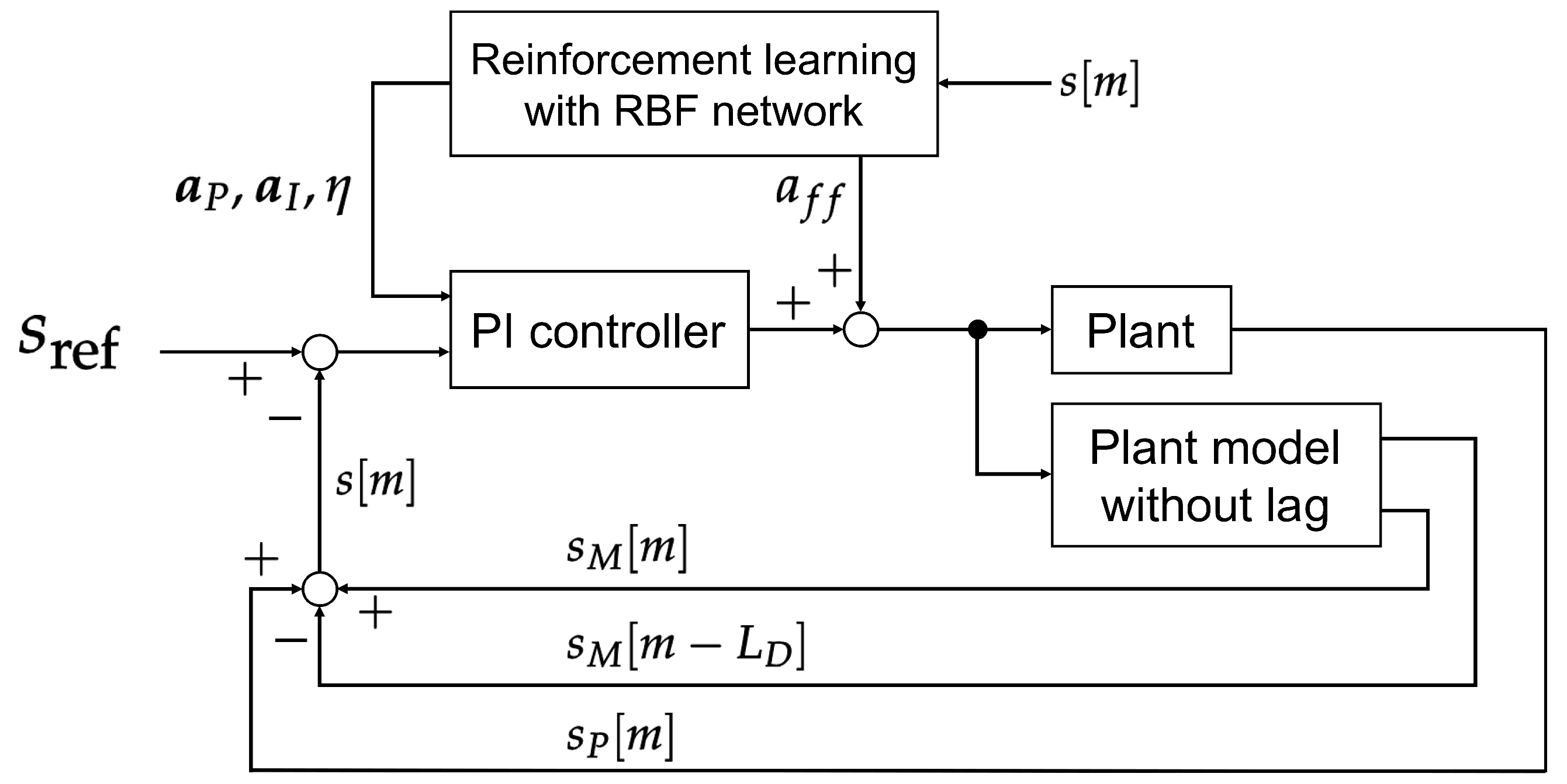
In the following scenarios, we applied three different controllers: (1) the proposed self-tuning two-DOF PI controller, (2) the proposed self-tuning two-DOF PI controller, but with
defined using (
26), and (3) the static gain PI controller whose gains were determined using the Z.N. ultimate gain method. We uniformly applied the feedback control structure shown in
Figure 4 to all three controller setups in all scenarios. We only disabled the RL calculations when we tried to obtain control results with static PI controllers. For the self-tuning control simulations, we repeated the simulation with an identical initial thickness distribution for 40 episodes. The results corresponding to the 41st episode are shown below. We note that the number of RBF nodes in the hidden layer of the actor and critic networks were set to zero initially and increased automatically. We applied the algorithm for the automatic addition of RBF nodes proposed by Kamaya et al. [
21] whilst making necessary changes to adapt to our MIMO control problem.
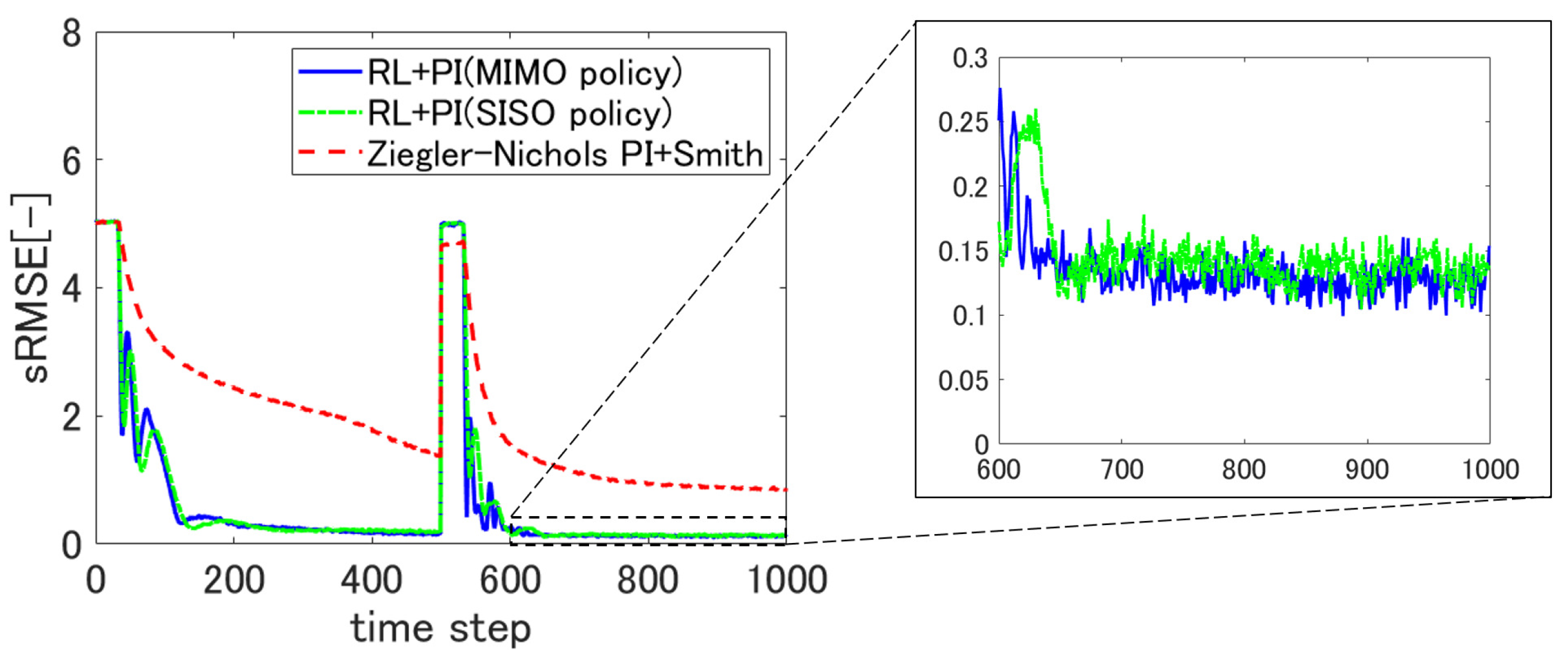
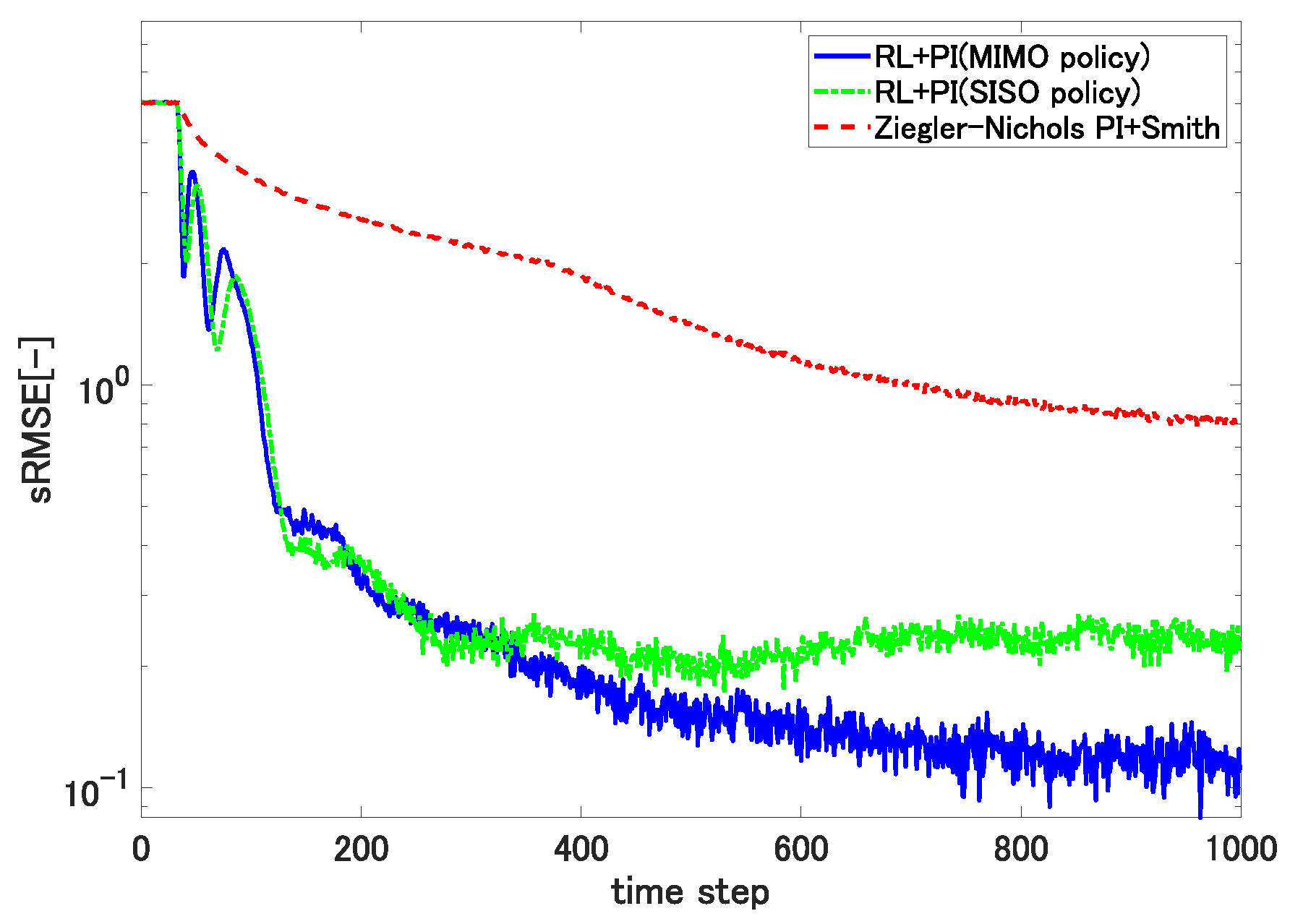
5.1. sRMSE Trajectories for a Fixed Reference Thickness
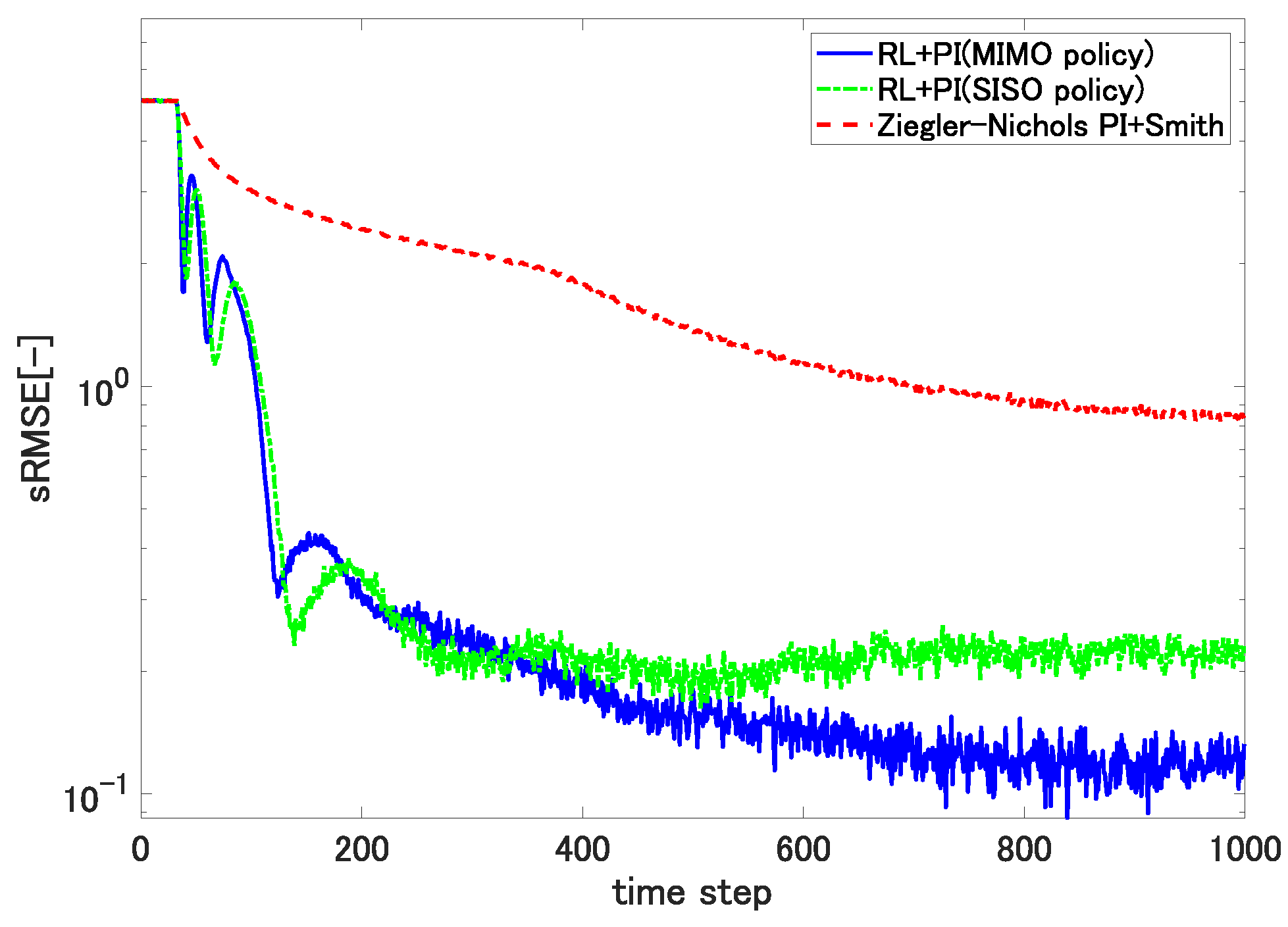
We first set the reference thickness to 70 and observed the transient changes in the sRMSE metrics.
Figure 8 shows the result.
The plots indicate that the proposed self-tuning controllers not only yielded much faster convergence, but also achieved significantly smaller sRMSE values than the conventional static PI controller. The figure also shows that incorporating the spatial coupling coefficient
defined using (
14) and the associated learning scheme resulted in a smaller sRMSE than that achieved with the decoupled self-tuning controller corresponding to
defined using (
26).
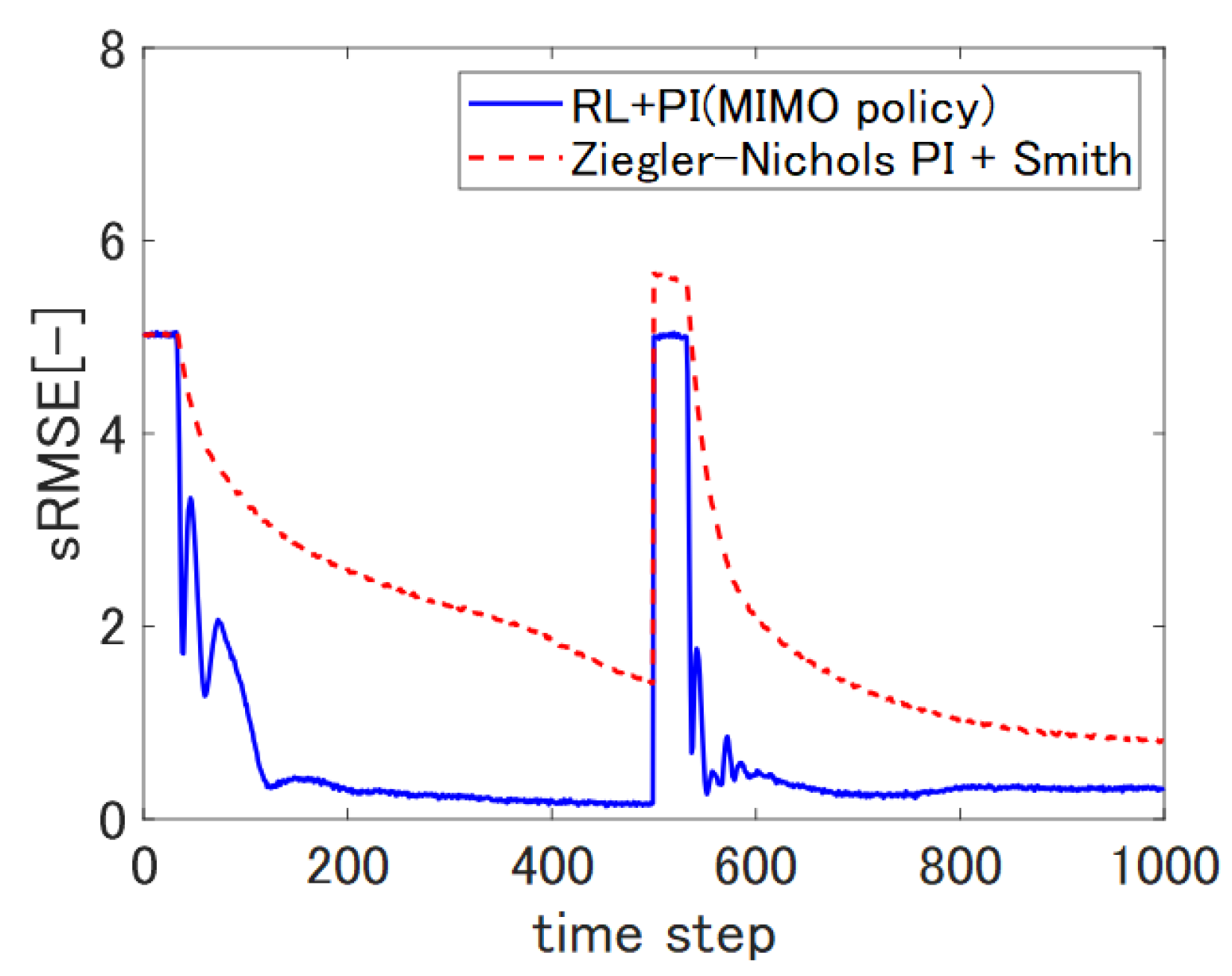
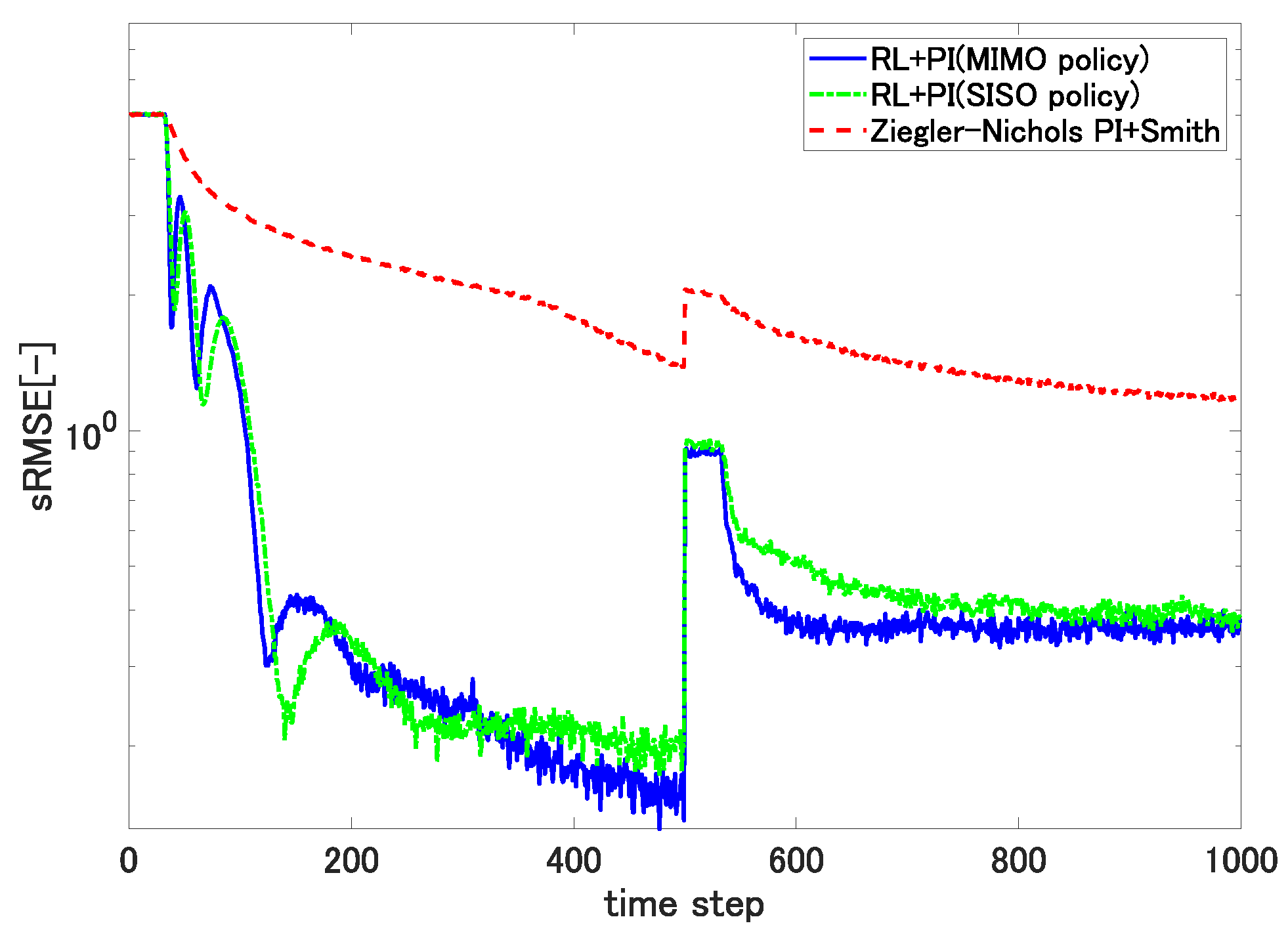
5.2. Response to Changes in Reference Film Thickness
Although the real film production process does not change the reference thickness within a single production batch, we changed the reference thickness from 70 to 65 at the 500th sampling step in the 41st episode to observe the response after completing 40 episodes with a constant reference thickness of 70.
Figure 9 shows the result.
The proposed self-tuning controllers again exhibited much smaller sRMSE metrics than the static PI controller.
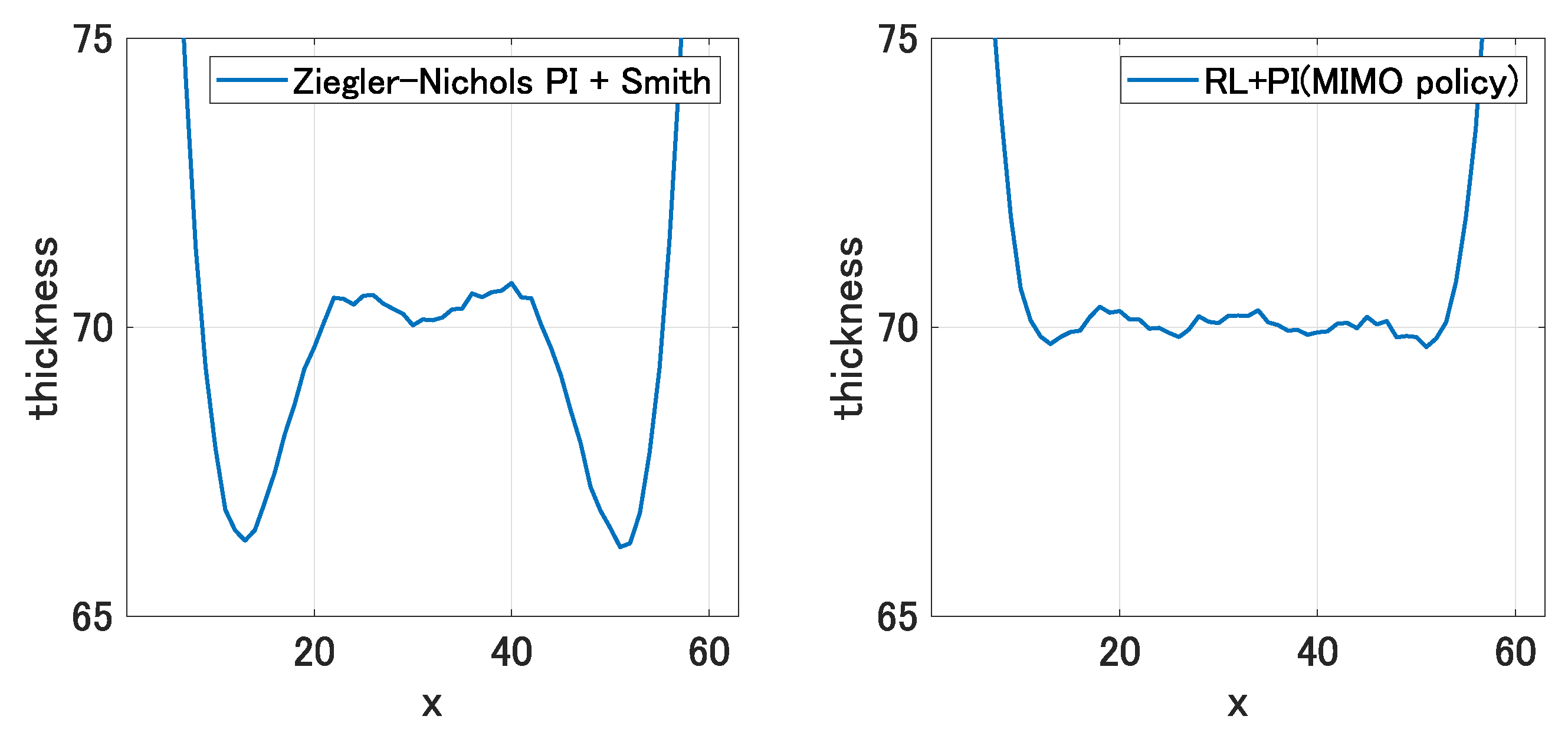
defined using (
14) with the associated RL produced better accuracy than the SISO self-tuning controller, as was also observed in the previous scenario. Although the self-tuning controllers temporarily exhibited larger sRMSEs than the static PI controller after the reference thickness was altered, this was an incidental issue as evidenced by the film thickness distributions corresponding to the Z.N. PI and the proposed controller in
Figure 10. Since the film corresponding to the Z.N. PI controller has portions apparently thinner than 70 and closer to the new reference of 65, it temporarily exhibited a smaller sRMSE metric than film generated by the proposed controller whose thickness was uniformly close to 70. Our inference was further justified by the additional simulation in which the new reference was set to be 75, which is larger than 70. The result is shown in
Figure 11.
The recovery of the sRMSE metric after the change of the reference thickness corresponding to our proposed controller as shown in
Figure 9 and
Figure 11 revealed that the proposed controller exhibited much faster response as compared to the Z.N. PI controller. The result in
Figure 9 shows that using
in (
14) contributes to a smaller steady-state sRMSE.
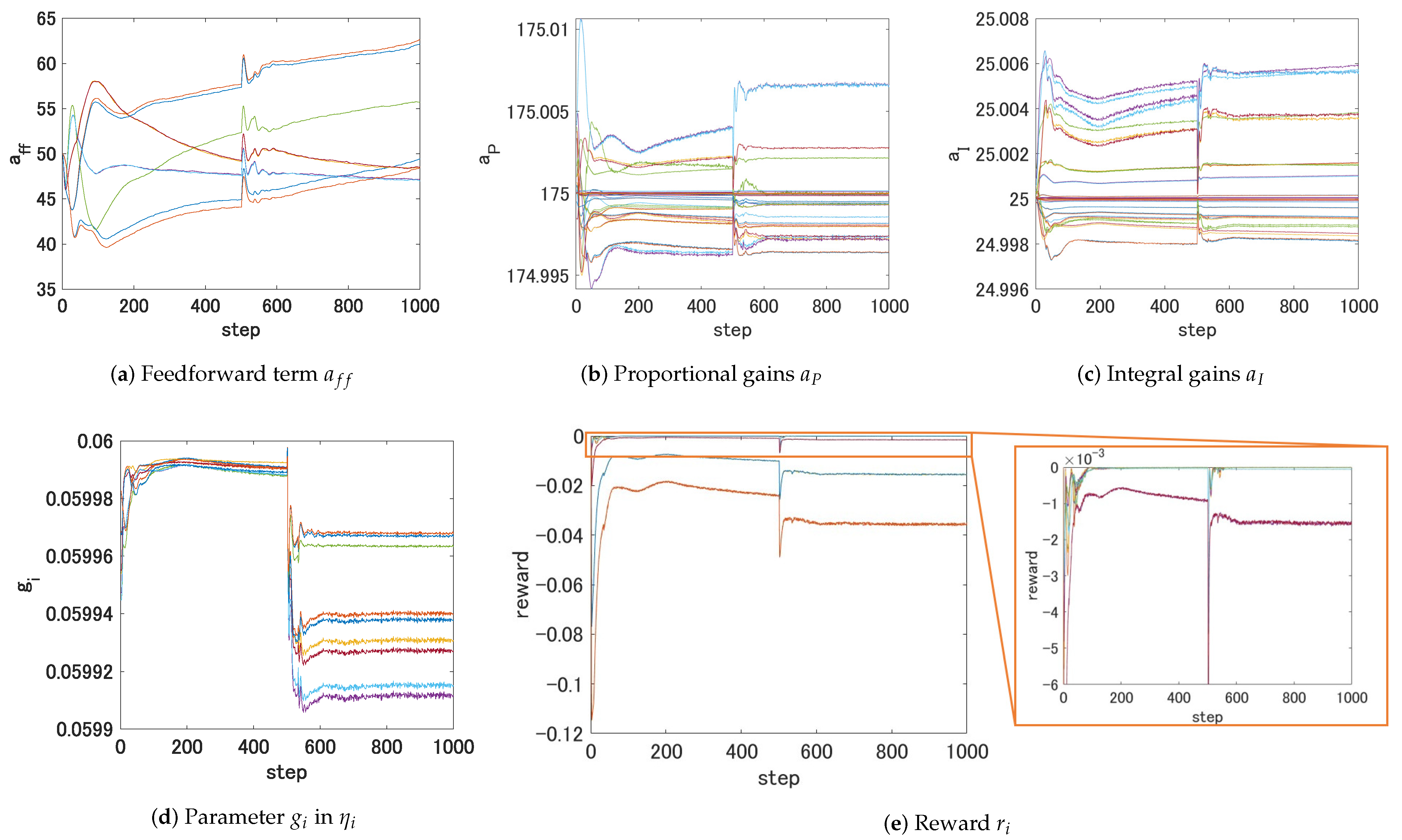
We next show how our proposed controller reacted to the changes of reference. Since the left and the three right devices were excluded as explained earlier in this manuscript, we provide the changes of the controller related parameters of the fourth to twelfth manipulating devices.
All the quantities suffered steep changes at the 500th step. Since 40 episodes of training were completed before applying this scenario, the feedforward control inputs seemed to be dominant in the control behavior, whereas small transient adjustments could be observed in
and
, as evidenced by the plots in
Figure 12.
Figure 13 shows the plots corresponding to only the fifth manipulating device. On the changes of PI controller gains, it is of technical interest to note that although
and
were the largest, the gains corresponding to their closest neighbors (
and
for
) exhibited a similar magnitude, indicating that errors measured at the nearest neighbor devices were important in the control under coupling.
5.3. sRMSE Trajectory under Plant Perturbation
We then introduced perturbations to the dynamics of the manipulating devices. Because the devices were modeled using first-order transfer functions with a lag, we added perturbations to their DC gains and time constants randomly; the perturbed parameters should stay within the interval of of their nominal values. We note that the perturbation was introduced only in the 41st episode in the self-tuning control scenarios.
We note that the proposed self-tuning controller again exhibited much smaller sRMSE metrics than the static PI controller in this scenario as shown in
Figure 14. The use of the adaptive coefficient
in the self-tuning control system resulted in a continuous improvement in the sRMSE metric after the 400th step, whereas the metric did not decrease with the SISO policy controller.
5.4. Disturbance Rejection
We empirically know that we should sometimes expect a disturbance that would worsen the film thickness precision at the left and right edges. We modeled the disturbance as a perturbation of the thickness around the right edge, which was characterized by:
and added it to the thickness after the 500th time step. We did not perturb the plant dynamics in this scenario, and the reference was set to 70 throughout the episode.
Figure 15 shows the result.
All three controllers suffered increased sRMSE metrics when a disturbance was introduced. However, the self-tuning controllers quickly rejected the disturbance, whereas the sRMSE metric of the static PI controller continued to decrease even after 500 sampling steps, indicating its very slow transient behavior. Notably, the self-tuning controller with
defined using (
14) showed faster convergence than the SISO self-tuning controller in this scenario, likely because of the spatially monotonic sign of the introduced disturbance.
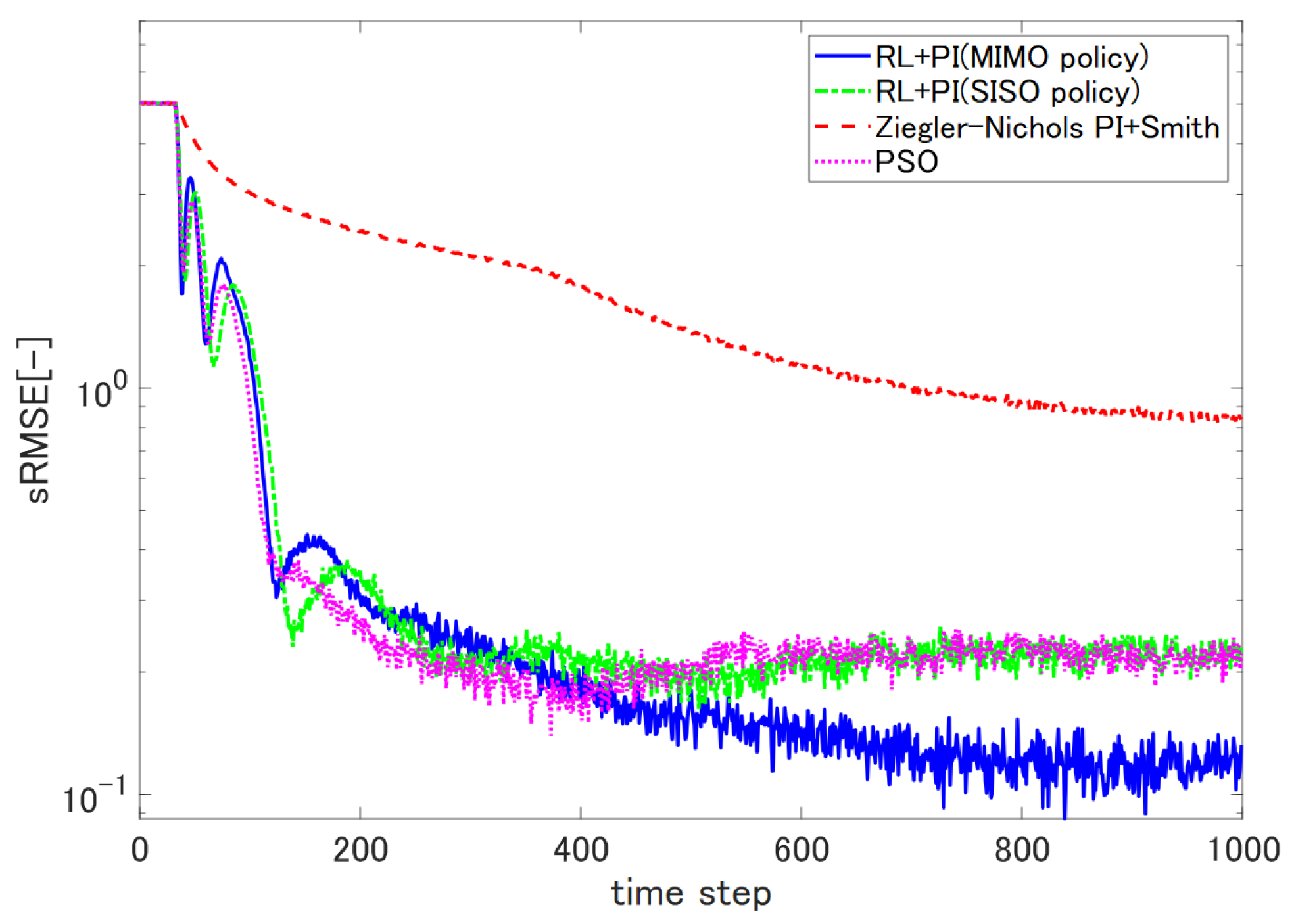
5.5. Comparison with Online Tuning by Particle Swarm Optimization
In order to illustrate the performance enhancement of our proposed control system further, we conducted a comparative on-line tuning of our two-DOF PI controller parameters by particle swarm optimization (PSO). PSO is classified as a swarm intelligence algorithm. It can be applied to various global optimization problems, and it is known to exhibit fast convergence.
We tuned the parameters of the proposed two-DOF PI control system in the SISO setup (
only if
; otherwise, it was set to zero). A particle includes all the policy parameters
, which amounts to a point in the 45th-dimensional space (there are 15 manipulating devices, each of which is assigned a two-DOF PI controller that has three parameters). We prepared 20 initial particles that were distributed within the ±35% range of the initial value. The initial velocities of the particles were randomly initialized within the interval
. We needed to define
pbest and
gbest to evaluate the fitness of the particles (please see [
9] for details). We decided to use the sRMSE metric as a fitness evaluation. The updates of the particles were carried out at every 100 steps of episodes, and we performed 40 episodes also for the tuning parameters with PSO. The reference was set to be 70, which was identical to the value used for the numerical evaluation of the proposed control system.
Figure 16 below shows the changes of sRMSE metrics corresponding to the controllers tuned by four different methods. It shows the superior fast adaptation performance of PSO tuning. However, PSO tuning was outperformed by the proposed control system, which explicitly took input coupling into account. It can be said that PSO did not exhibit significant performance improvement over our proposed control system in a SISO setup. We concluded that the proposed control system exhibited not only improved steady-state thickness accuracy, but also comparable learning speed to PSO.
6. Conclusions and Future Work
This study proposes a self-tuning two-DOF PI control system for a MIMO film production process. The adaptive tuning laws of the controller parameters are synthesized based on the actor-critic-type RL algorithm. As the target process intrinsically suffers spatial mechanical coupling, we introduce the tunable coefficient to improve the thickness control performance under the existence of spatial couplings of the inputs.
We conduct numerical simulations under several likely scenarios and confirm better control performance compared to that of the conventional static-gain PI controller whose gains are determined using the Z.N. method. The numerical results indicate that the proposed controller exhibits better performance in all likely scenarios.
We observe transient oscillation in the sRMSE thickness error metrics of the proposed control in almost all cases. We will continue to investigate the cause of this phenomenon and will try to synthesize an improved control system with a smaller oscillatory response.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}