Coastal Land Cover Classification of High-Resolution Remote Sensing Images Using Attention-Driven Context Encoding Network



Abstract
:1. Introduction
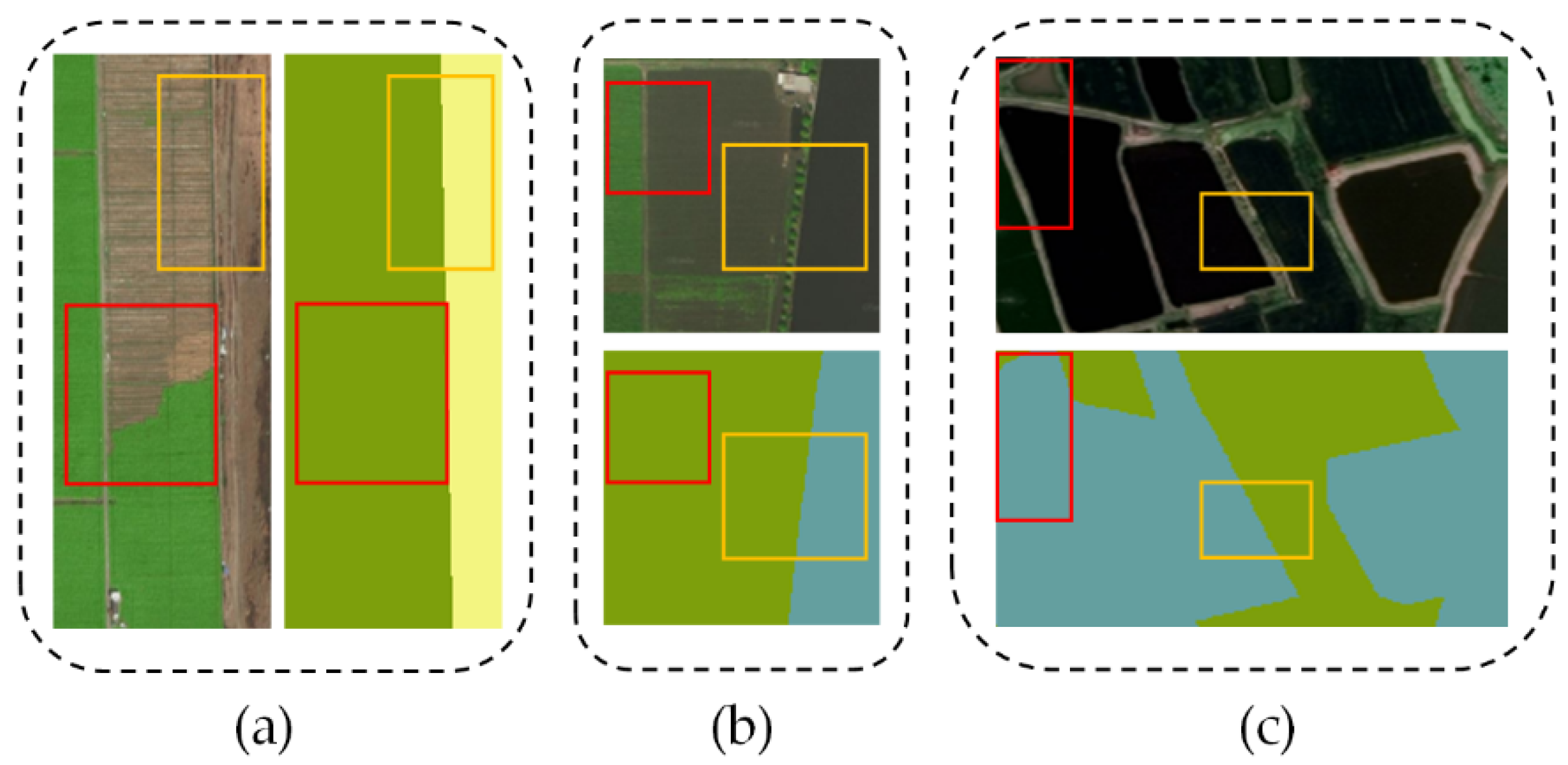
- Considering the characteristics of coastal ground objects, a novel attention-driven method for CLCC is proposed, which emphasizes the important role of context encoding information in pixel-level classification tasks.
- In the decoding phase, the position-channel attention aggregation module and global feature attention module are introduced to perform multi-scale and multi-dimensional global context encoding that enables enhancing the classification consistency. As we know, this is a courageous attempt to apply them to explore better performance for CLCC simultaneously.
- To achieve better classification results, this paper proposes a multi-scale deep supervision strategy and embeds multi-grid operations in the backbone for optimizing the training process.
- Experiments in two coastal study areas show that compared with other state-of-the-art semantic segmentation models, AdCENet can effectively improve the classification performance and generate high-precision CLCC products.
2. Related Work
2.1. CLCC Implementation for HRRS Images
2.2. Contextual Information Aggregation
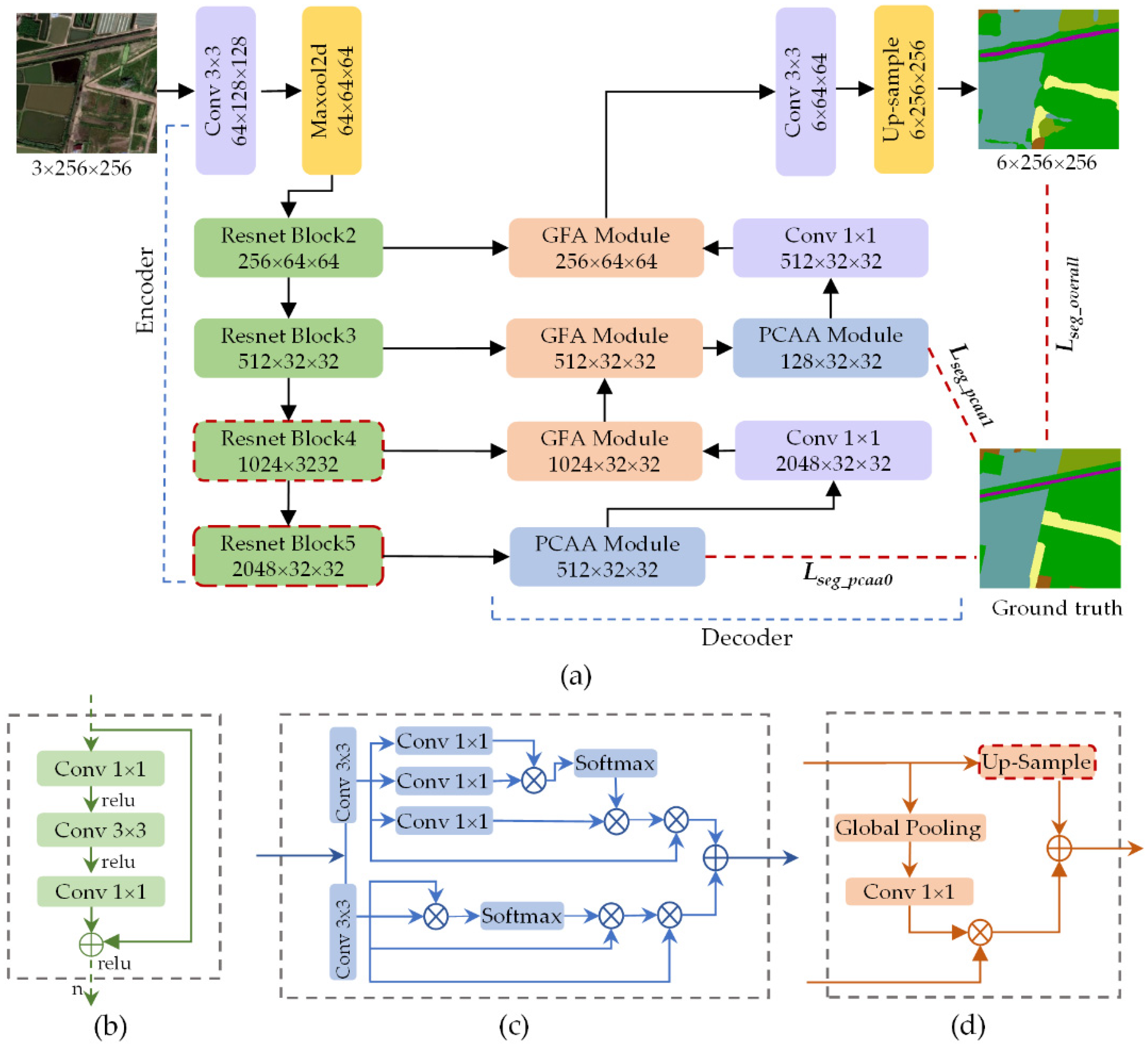
3. Methodology
3.1. Overview
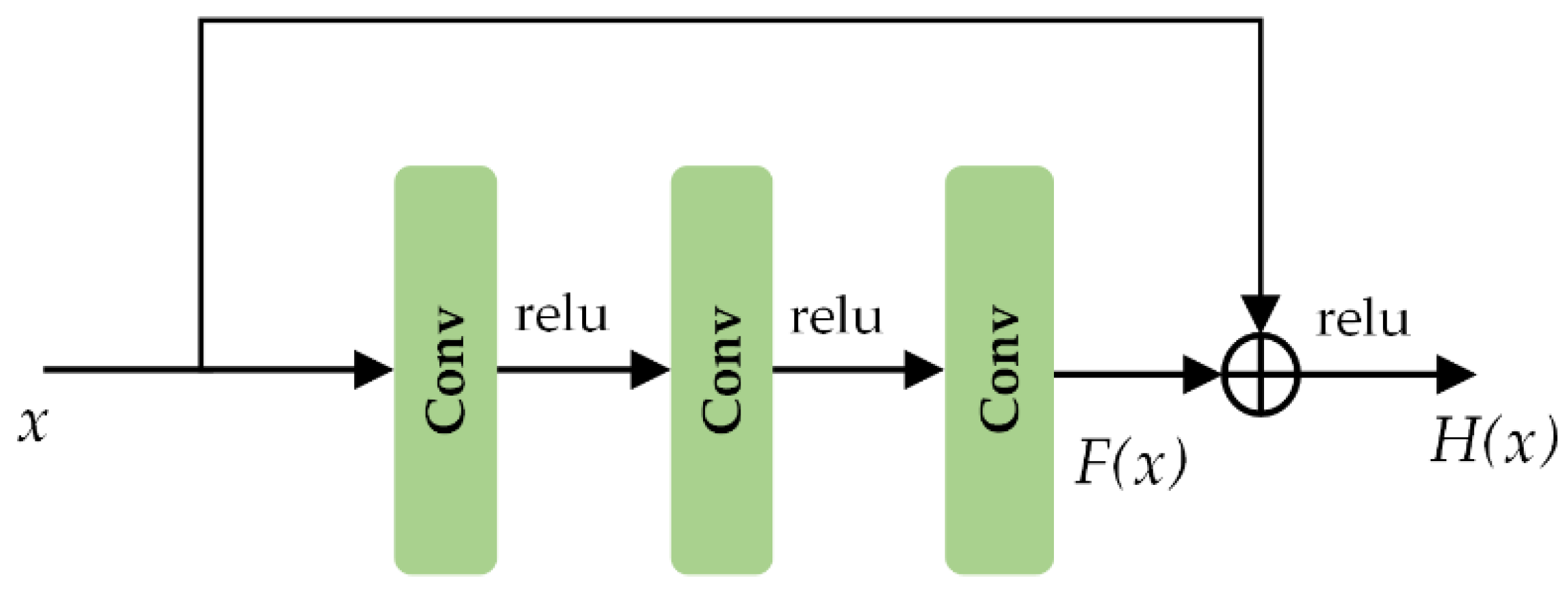
3.2. Residual Learning Framework
3.3. Position–Channel Relation Aggregation Module
3.3.1. Position Relation Attention Block
3.3.2. Channel Relation Attention Block
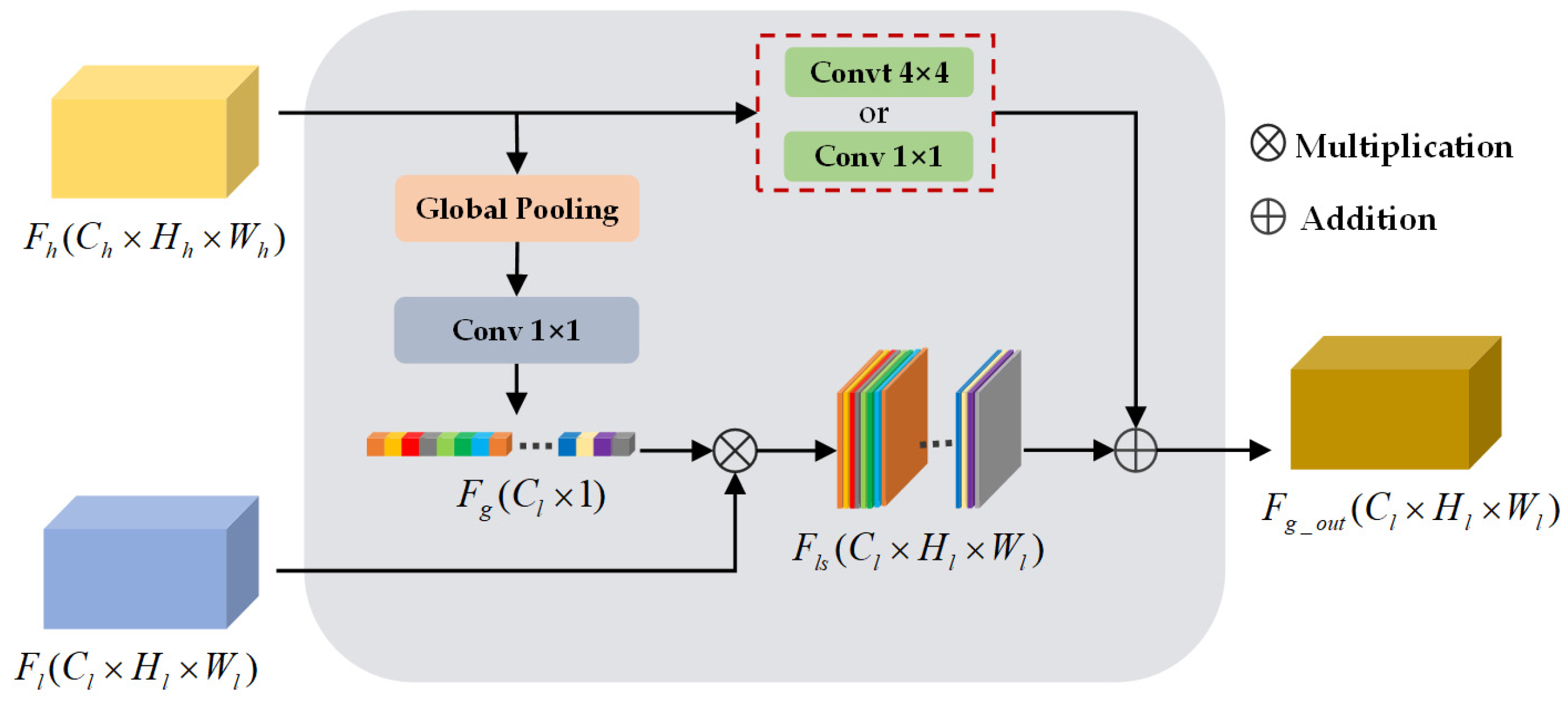
3.4. Global Feature Attention Module
3.5. Multi-Scale Supervision
4. Experiment
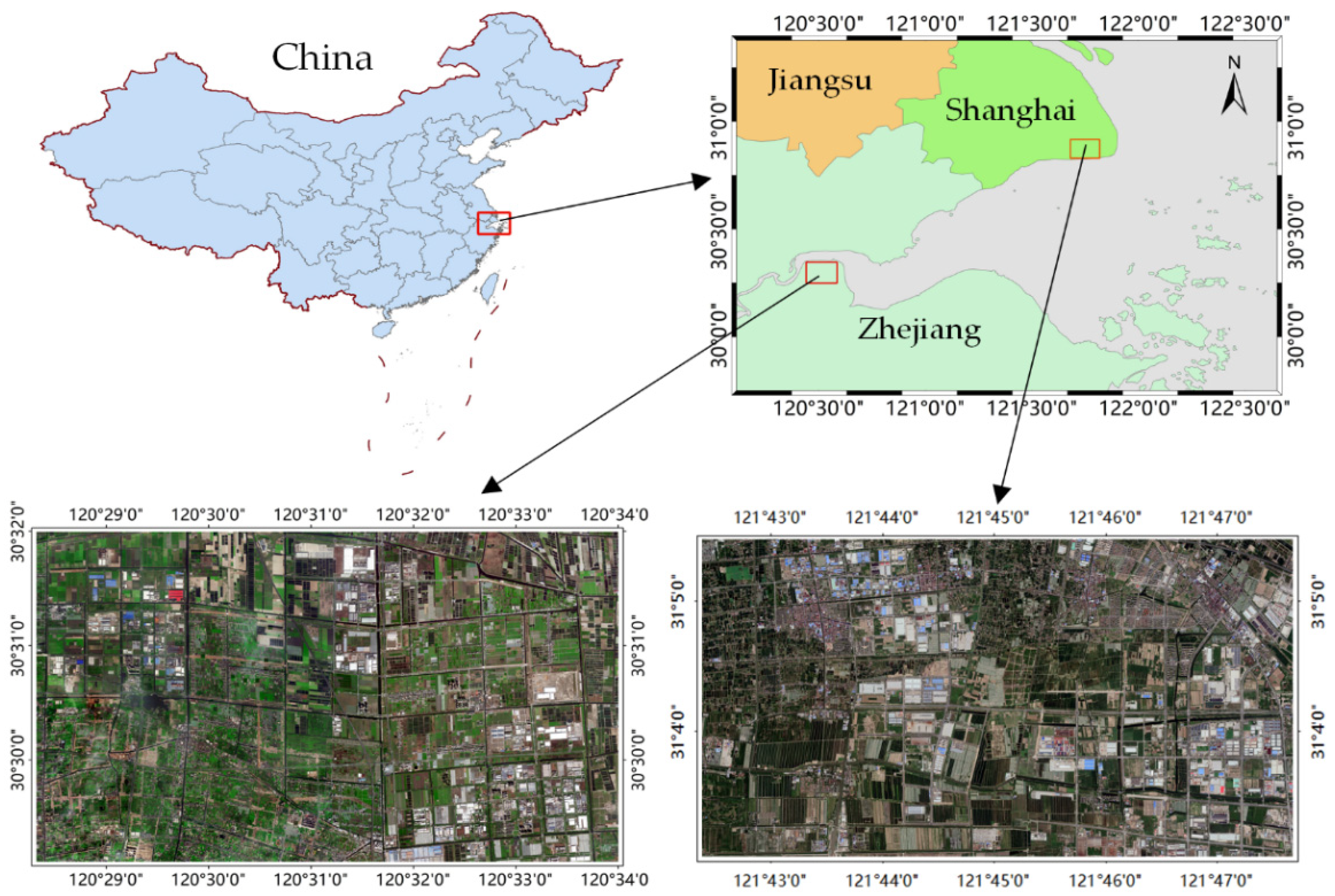
4.1. Datasets Description
4.2. Evaluation Metrics
4.3. Experimental Setup
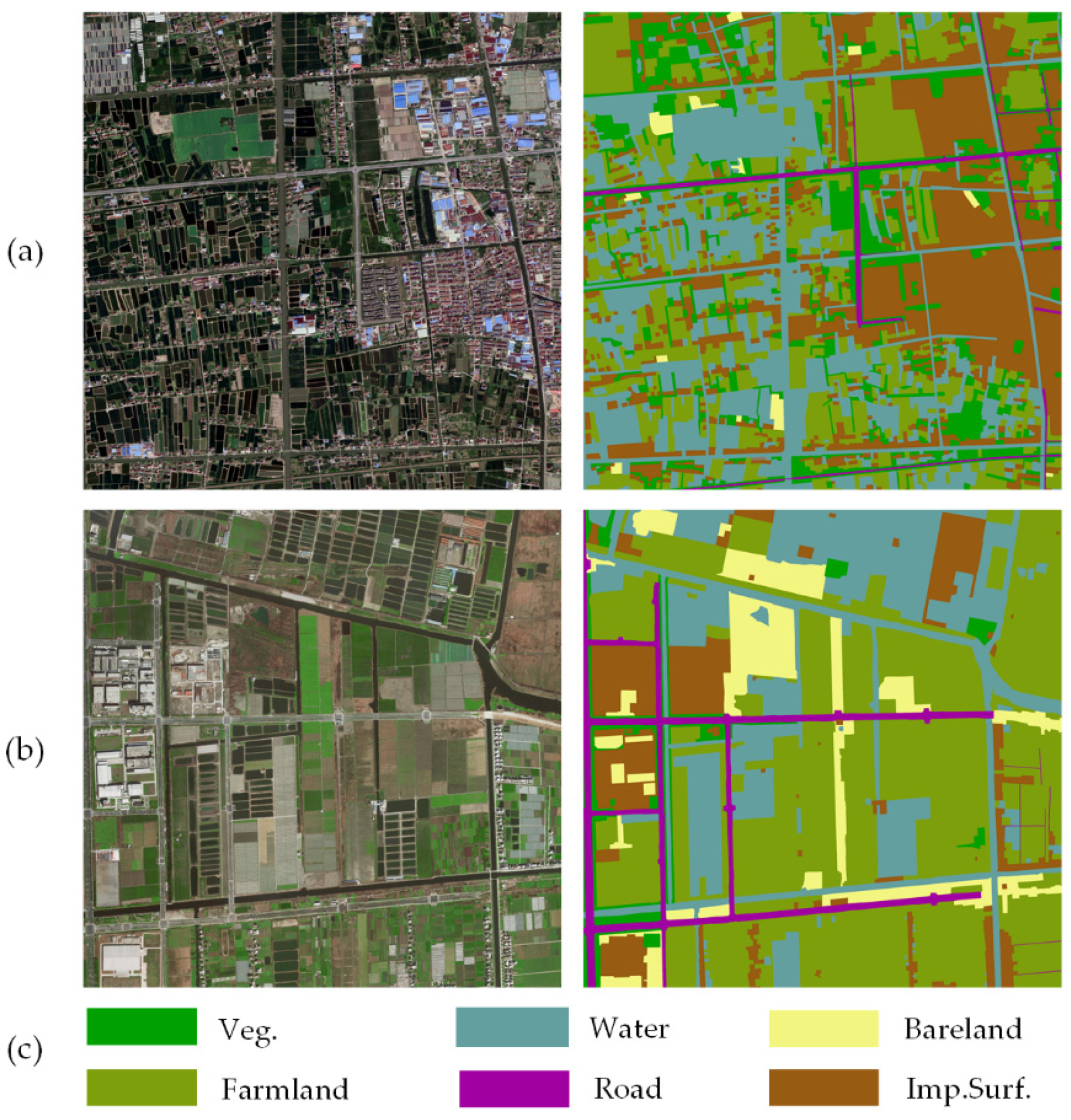
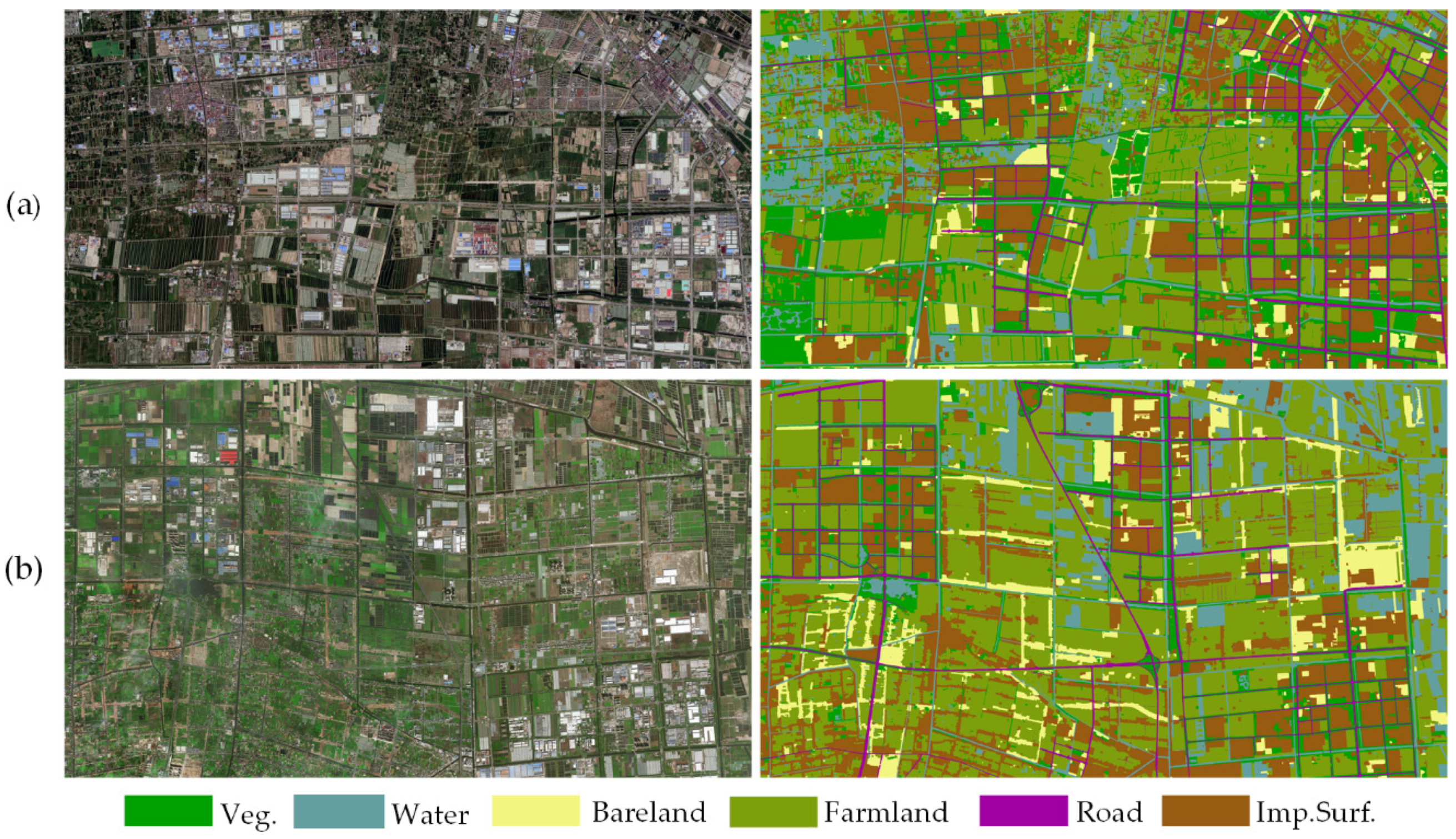
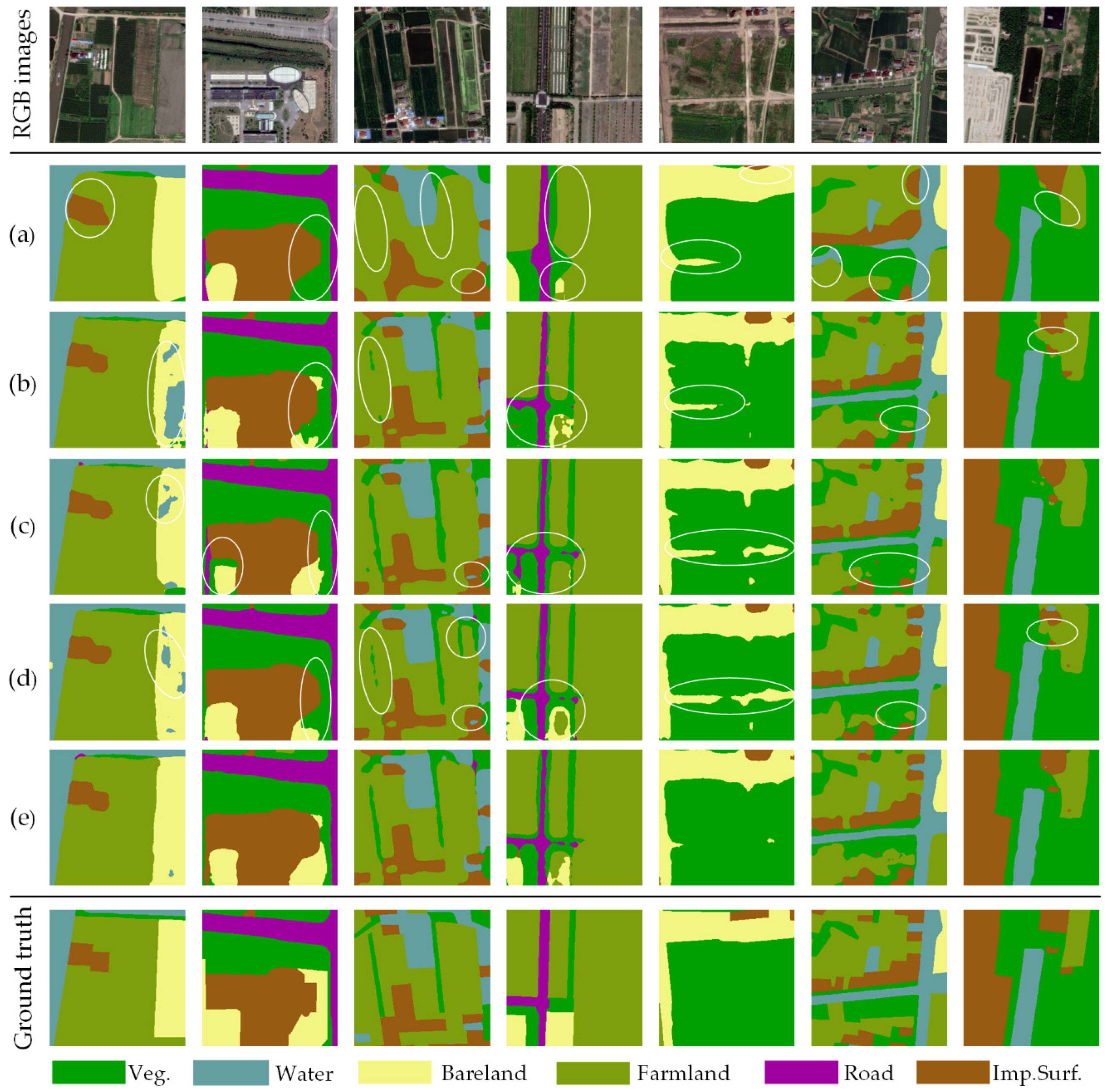
4.4. Results and Analysis
5. Discussion
5.1. Ablation Study for Attention Modules
5.1.1. Effectiveness of Attention Modules
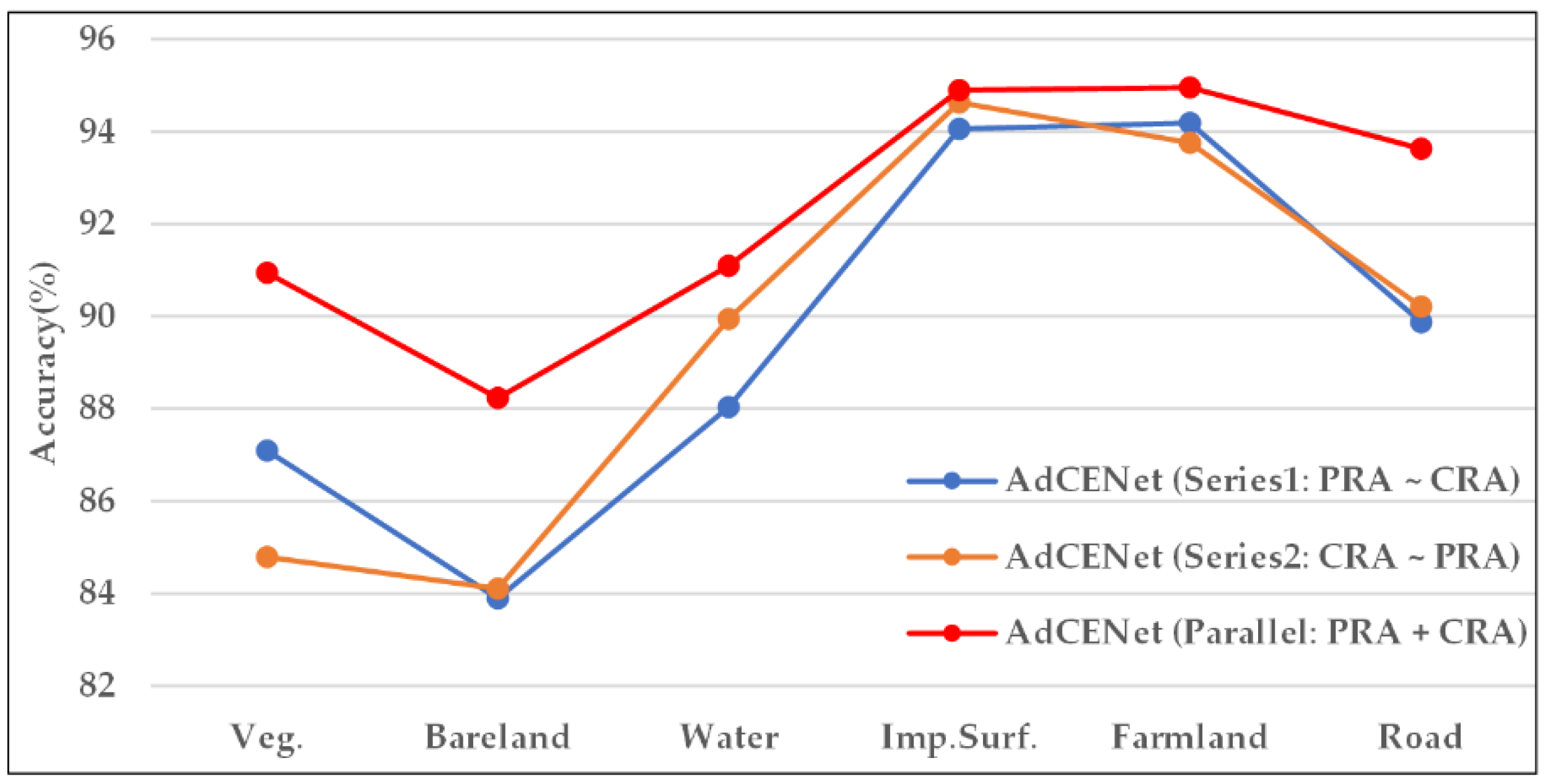
5.1.2. Influence of Connection Mode
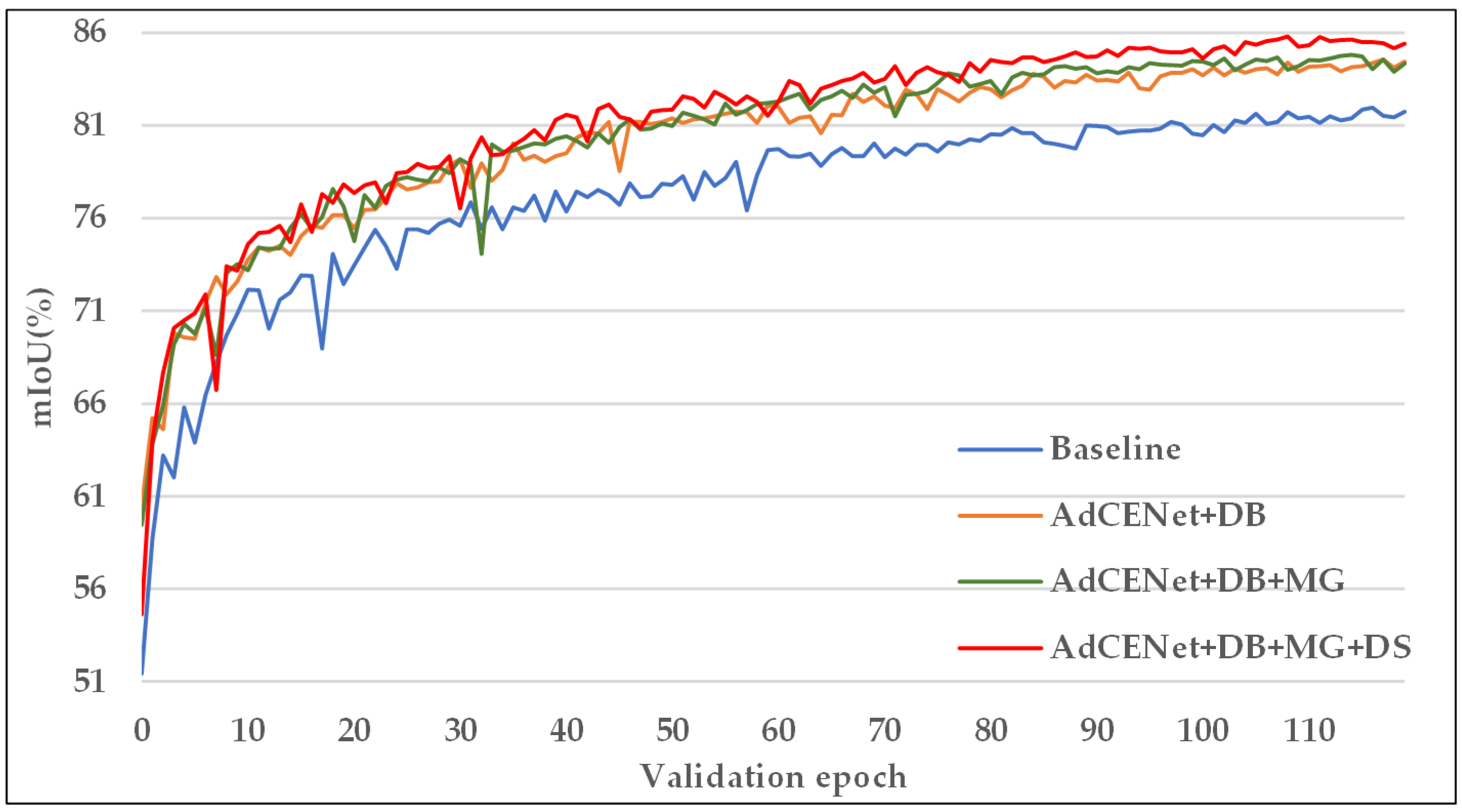
5.2. Effectiveness Analysis of Improvement Strategies
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Congalton, R.; Gu, J.; Yadav, K.; Thenkabail, P.; Ozdogan, M. Global Land Cover Mapping: A Review and Uncertainty Analysis. Remote Sens. 2014, 6, 12070–12093. [Google Scholar] [CrossRef] [Green Version]
- Adam, E.; Mutanga, O.; Odindi, J.; Abdel-Rahman, E.M. Land-use/cover classification in a heterogeneous coastal landscape using RapidEye imagery: Evaluating the performance of random forest and support vector machines classifiers. Int. J. Remote Sens. 2014, 35, 3440–3458. [Google Scholar] [CrossRef]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training Deep Convolutional Neural Networks for Land–Cover Classification of High-Resolution Imagery. IEEE Geosci. Remote Sens. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Fang, B.; Kou, R.; Pan, L.; Chen, P. Category sensitive domain adaptation for land cover mapping in aerial scenes. Remote Sens. 2019, 11, 2631. [Google Scholar] [CrossRef] [Green Version]
- Thanh Noi, P.; Kappas, M. Comparison of Random Forest, k-Nearest Neighbor, and Support Vector Machine Classifiers for Land Cover Classification Using Sentinel-2 Imagery. Sensors 2018, 18, 18. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Cham, Switzerland, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Shuai, B.; Zuo, Z.; Wang, B.; Wang, G. Scene segmentation with dag-recurrent neural networks. IEEE Trans. Pattern Anal. 2018, 40, 1480–1493. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the 2015 Medical Image Computing and Computer-Assisted Intervention (MICCAI), Cham, Switzerland, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Szuster, B.W.; Chen, Q.; Borger, M. A comparison of classification techniques to support land cover and land use analysis in tropical coastal zones. Appl. Geogr. 2011, 31, 525–532. [Google Scholar] [CrossRef]
- Hua, L.; Zhang, X.; Chen, X.; Yin, K.; Tang, L. A feature-based approach of decision tree classification to map time series urban land use and land cover with Landsat 5 TM and Landsat 8 OLI in a Coastal City, China. ISPRS Int. J. Geo-Inf. 2017, 6, 331. [Google Scholar] [CrossRef] [Green Version]
- Shang, R.; Zhang, J.; Jiao, L.; Li, Y.; Marturi, N.; Stolkin, R. Multi-scale Adaptive Feature Fusion Network for Semantic Segmentation in Remote Sensing Images. Remote Sens. 2020, 12, 872. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Liu, C.; Zeng, D.; Wu, H.; Wang, Y.; Jia, S.; Xin, L. Urban land cover classification of high-resolution aerial imagery using a relation-enhanced multiscale convolutional network. Remote Sens. 2020, 12, 311. [Google Scholar] [CrossRef] [Green Version]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building Extraction Based on U-Net with an Attention Block and Multiple Losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Cao, K.; Zhang, X. An Improved Res-UNet Model for Tree Species Classification Using Airborne High-Resolution Images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhang, L.; Wu, J.; Fan, Y.; Gao, H.; Shao, Y. An Efficient Building Extraction Method from High Spatial Resolution Remote Sensing Images Based on Improved Mask R-CNN. Sensors 2020, 20, 1465. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Ding, W.; Liu, C.; Liu, Y.; Wang, Y.; Li, H. ERN: Edge loss reinforced semantic segmentation network for remote sensing images. Remote Sens. 2018, 10, 1339. [Google Scholar] [CrossRef] [Green Version]
- He, C.; Li, S.; Xiong, D.; Fang, P.; Liao, M. Remote Sensing Image Semantic Segmentation Based on Edge Information Guidance. Remote Sens. 2020, 12, 1501. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large kernel matters-improve semantic segmentation by global convolutional network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1743–1751. [Google Scholar]
- Ghiasi, G.; Fowlkes, C.C. Laplacian pyramid reconstruction and refinement for semantic segmentation. In Proceedings of the 2016 European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 519–534. [Google Scholar]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-wise Spatial Attention Network for Scene Parsing. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Cham, Switzerland, 8–14 September 2018; pp. 270–286. [Google Scholar]
- Yuan, Y.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. CCNet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3141–3149. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. In Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Mou, L.; Hua, Y.; Zhu, X.X. A relation-augmented fully convolutional network for semantic segmentation in aerial scenes. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 12416–12425. [Google Scholar]
- Sinha, A.; Dolz, J. Multi-scale self-guided attention for medical image segmentation. IEEE J. Biomed. Health 2020, in press. [Google Scholar] [CrossRef] [Green Version]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef]
- Available online: http://labelme.csail.mit.edu/Release3.0/ (accessed on 23 March 2020).
- Qi, Z.; Yeh, A.G.; Li, X.; Lin, Z. A novel algorithm for land use and land cover classification using RADARSAT-2 polarimetric SAR data. Remote Sens. Environ. 2012, 118, 21–39. [Google Scholar] [CrossRef]
- Zhou, P.; Chen, G.; Wang, M.; Chen, J.; Li, Y. Sediment Classification of Acoustic Backscatter Image Based on Stacked Denoising Autoencoder and Modified Extreme Learning Machine. Remote Sens. 2020, 12, 3762. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 2017 Conference and Workshop on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–10 December 2017; pp. 1–4. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Shanghai Dataset | Zhejiang Dataset |
|---|---|---|
| Mean value of each band | 0.40, 0.43, 0.32 | 0.37, 0.37, 0.33 |
| Variance of each band | 0.15, 0.13, 0.13 | 0.19, 0.17, 0.17 |
| Veg. | 20.07% | 7.86% |
| Farmland | 32.29% | 46.03% |
| Water | 11.44% | 13.46% |
| Bareland | 3.96% | 7.77% |
| Road | 5.79% | 4.23% |
| Imp.Surf. | 26.45% | 20.65% |
| Method | Veg. | Bare Land | Water | Imp. Surf. | Farm Land | Road | OA | KC | mF1 | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|
| FCN [6] | 77.76 | 80.73 | 82.67 | 91.69 | 92.70 | 81.79 | 87.15 | 83.23 | 84.51 | 73.52 |
| RefineNet [18] | 88.07 | 81.98 | 88.92 | 93.42 | 92.72 | 91.44 | 91.00 | 88.29 | 89.41 | 81.11 |
| GCN [33] | 87.11 | 81.43 | 87.96 | 93.73 | 93.62 | 90.88 | 91.02 | 88.29 | 89.28 | 80.91 |
| PSPNet [12] | 88.07 | 86.20 | 91.82 | 94.85 | 95.16 | 93.23 | 92.78 | 90.59 | 91.53 | 84.53 |
| Deeplab [11] | 89.71 | 83.43 | 90.89 | 94.15 | 94.28 | 91.66 | 92.34 | 90.01 | 91.02 | 83.70 |
| OCNet [36] | 88.31 | 86.93 | 91.36 | 94.51 | 94.85 | 92.36 | 92.57 | 90.31 | 91.39 | 84.28 |
| EncNet [39] | 88.51 | 86.38 | 92.14 | 94.55 | 94.84 | 93.33 | 92.74 | 90.54 | 91.56 | 84.57 |
| AdCENet | 90.95 | 88.23 | 91.10 | 94.90 | 94.96 | 93.63 | 93.34 | 91.32 | 92.29 | 85.81 |
| Method | Veg. | Bare Land | Water | Imp. Surf. | Farm Land | Road | OA | KC | mF1 | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|
| FCN [6] | 78.30 | 88.73 | 89.71 | 92.52 | 95.64 | 79.97 | 91.64 | 88.23 | 87.77 | 78.75 |
| RefineNet [18] | 85.32 | 89.47 | 93.01 | 95.18 | 96.76 | 87.70 | 94.07 | 91.66 | 91.60 | 84.81 |
| GCN [33] | 84.02 | 90.07 | 93.15 | 94.64 | 96.56 | 89.51 | 93.90 | 91.43 | 91.39 | 84.46 |
| PSPNet [12] | 86.67 | 91.81 | 95.28 | 95.67 | 97.43 | 90.62 | 95.18 | 93.21 | 93.21 | 87.48 |
| Deeplab [11] | 87.25 | 91.72 | 95.24 | 95.74 | 97.23 | 90.00 | 95.11 | 93.12 | 93.12 | 87.35 |
| OCNet [36] | 84.48 | 91.71 | 94.66 | 95.73 | 97.42 | 89.76 | 94.89 | 92.81 | 92.77 | 86.73 |
| EncNet [39] | 85.30 | 92.90 | 94.41 | 95.63 | 97.43 | 90.78 | 95.06 | 93.04 | 93.06 | 87.25 |
| AdCENet | 87.38 | 93.12 | 95.97 | 96.35 | 97.43 | 92.09 | 95.63 | 93.86 | 93.88 | 88.62 |
| Method | GFA Module | PRA Block | CRA Block | OA (%) | KC (%) | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|
| Baseline | 87.15 | 83.23 | 84.51 | 73.52 | |||
| AdCENet | √ | 90.95 | 88.16 | 89.23 | 80.82 | ||
| AdCENet | √ | √ | 91.33 | 88.70 | 89.78 | 81.68 | |
| AdCENet | √ | √ | 91.28 | 88.63 | 89.58 | 81.38 | |
| AdCENet | √ | √ | √ | 91.51 | 88.94 | 89.96 | 81.96 |
| Method | Connection Mode | Order | OA (%) | KC (%) | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|
| AdCENet | Series | PRA~CRA | 91.35 | 88.71 | 89.80 | 81.70 |
| AdCENet | Series | CRA~PRA | 91.13 | 88.43 | 89.50 | 81.24 |
| AdCENet | Parallel | CRA + PRA | 91.51 | 88.94 | 89.96 | 81.96 |
| Method | DB | MG | DS | OA (%) | KC (%) | mF1 (%) | mIoU (%) |
|---|---|---|---|---|---|---|---|
| Baseline | 91.51 | 88.94 | 89.96 | 81.96 | |||
| AdCENet | √ | 92.80 | 90.81 | 91.54 | 84.55 | ||
| AdCENet | √ | √ | 93.03 | 90.92 | 91.69 | 84.82 | |
| AdCENet | √ | √ | √ | 93.34 | 91.32 | 92.29 | 85.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Chen, G.; Wang, L.; Fang, B.; Zhou, P.; Zhu, M. Coastal Land Cover Classification of High-Resolution Remote Sensing Images Using Attention-Driven Context Encoding Network. Sensors 2020, 20, 7032. https://0-doi-org.brum.beds.ac.uk/10.3390/s20247032
Chen J, Chen G, Wang L, Fang B, Zhou P, Zhu M. Coastal Land Cover Classification of High-Resolution Remote Sensing Images Using Attention-Driven Context Encoding Network. Sensors. 2020; 20(24):7032. https://0-doi-org.brum.beds.ac.uk/10.3390/s20247032
Chicago/Turabian StyleChen, Jifa, Gang Chen, Lizhe Wang, Bo Fang, Ping Zhou, and Mingjie Zhu. 2020. "Coastal Land Cover Classification of High-Resolution Remote Sensing Images Using Attention-Driven Context Encoding Network" Sensors 20, no. 24: 7032. https://0-doi-org.brum.beds.ac.uk/10.3390/s20247032