
An Integrated Machine Learning Scheme for Predicting Mammographic Anomalies in High-Risk Individuals Using Questionnaire-Based Predictors


Abstract
:1. Introduction
2. Methods
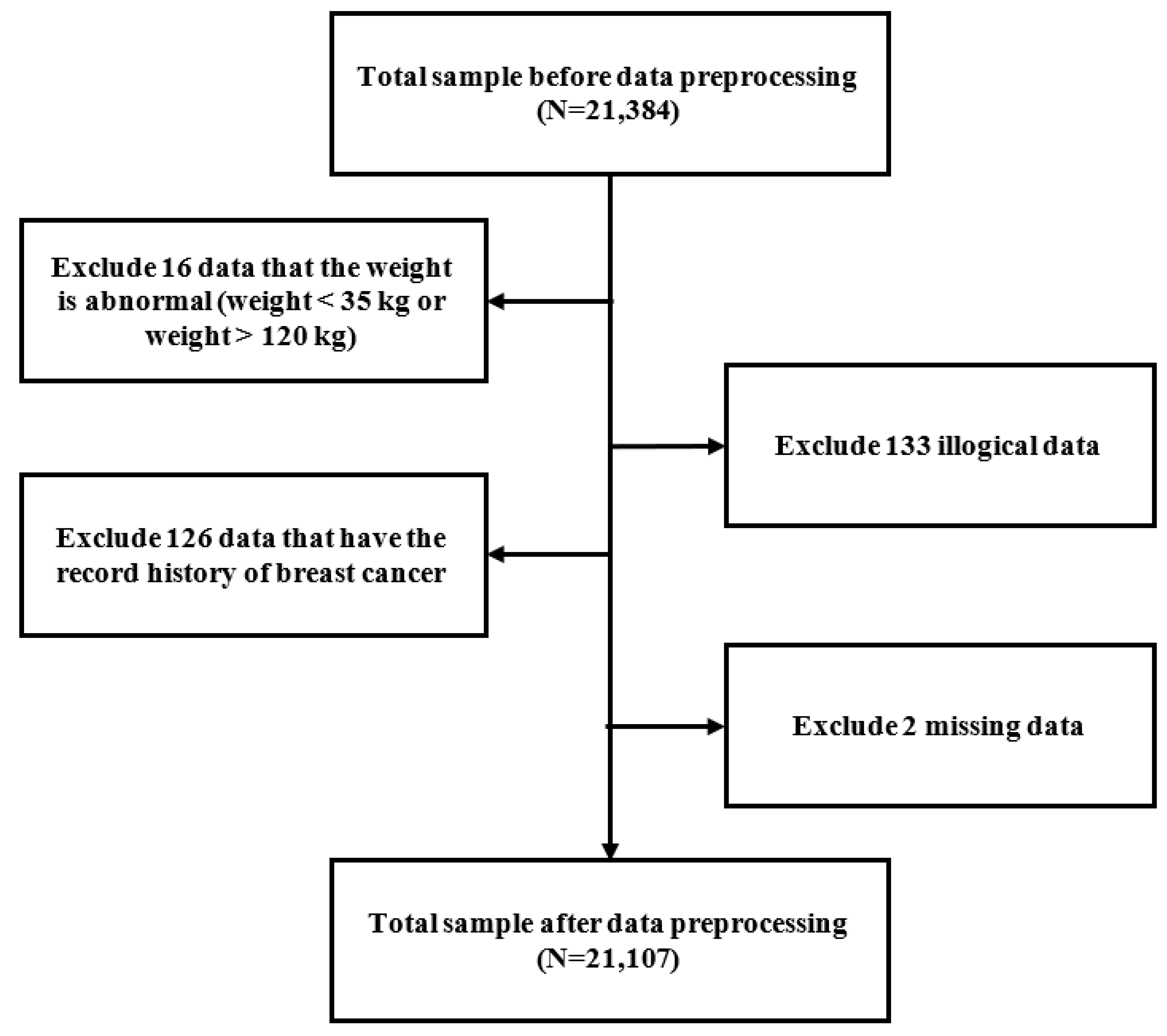
2.1. Study Design and Protocol
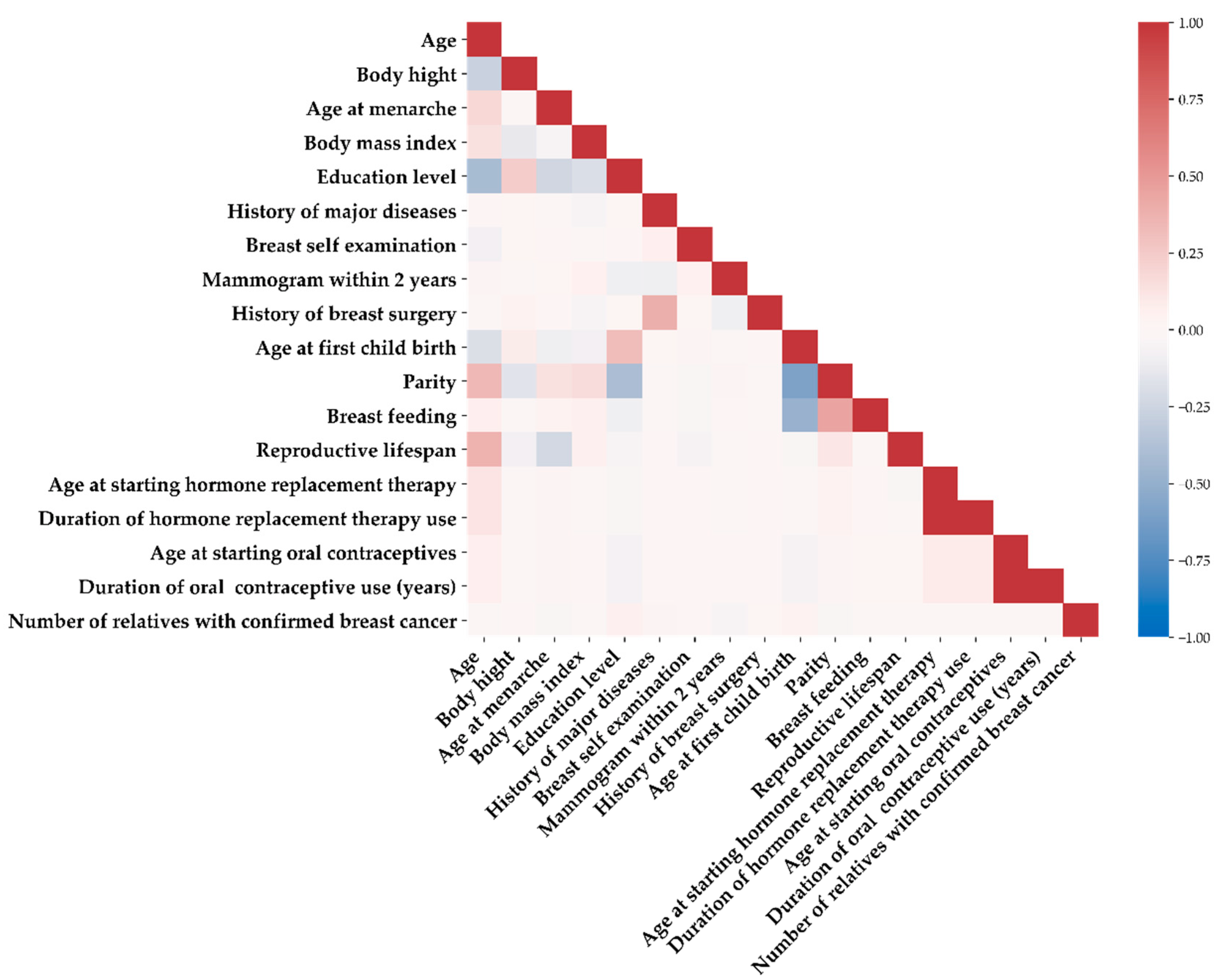
2.2. Study Parameters and Definitions
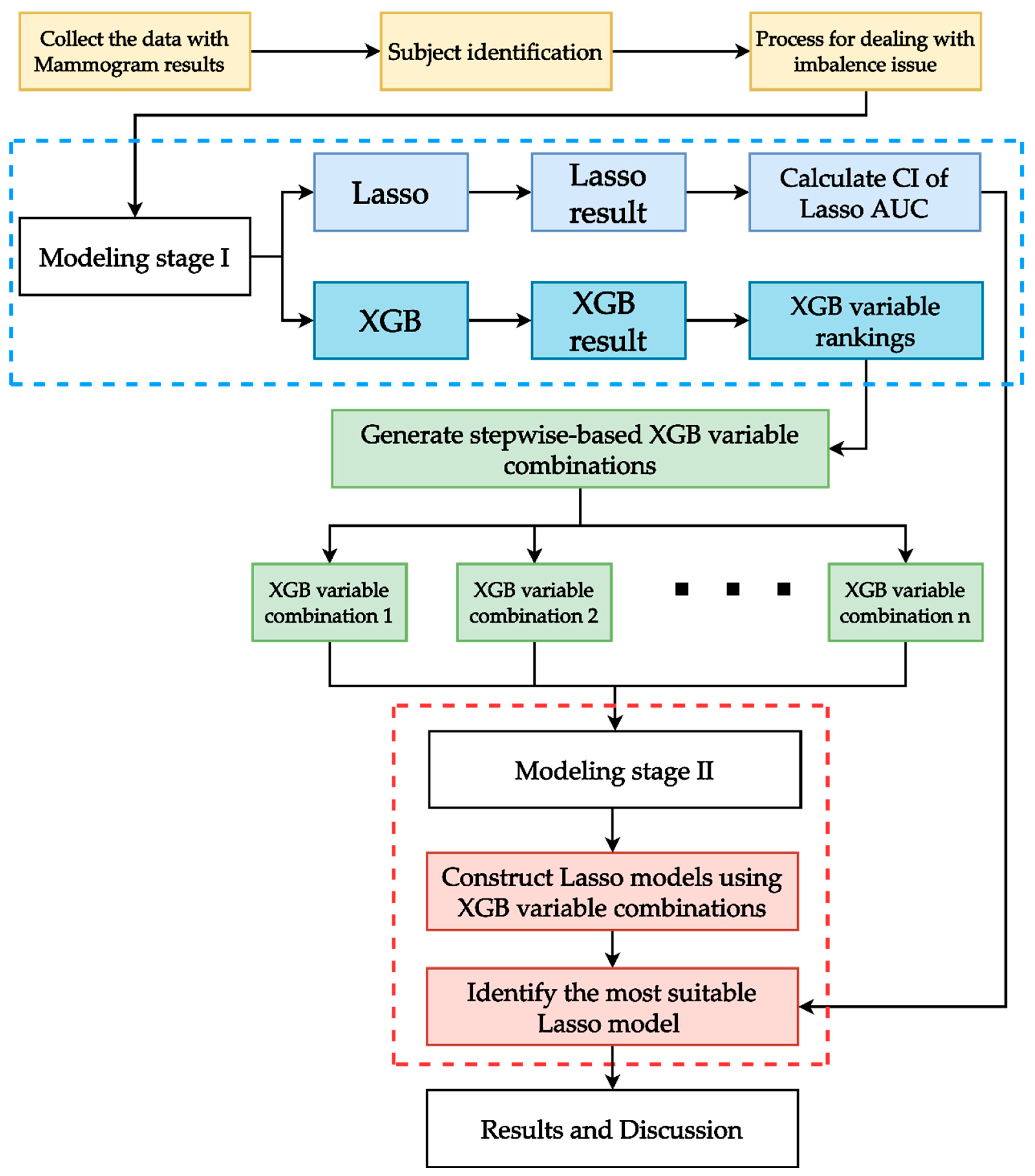
2.3. Proposed Integrated ML Scheme
3. Results
3.1. Models with and without Data Balancing
3.2. Variable Importance Ranking
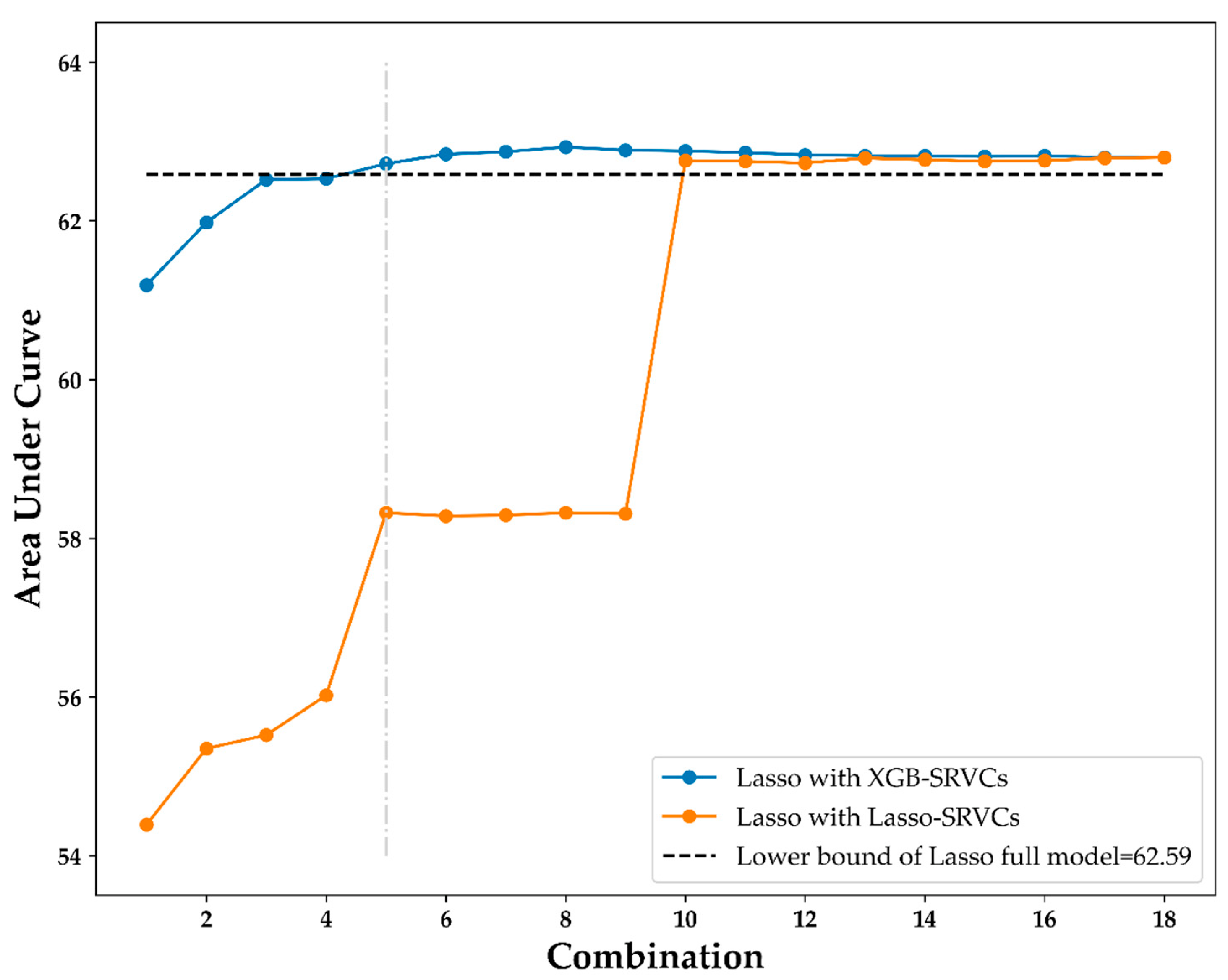
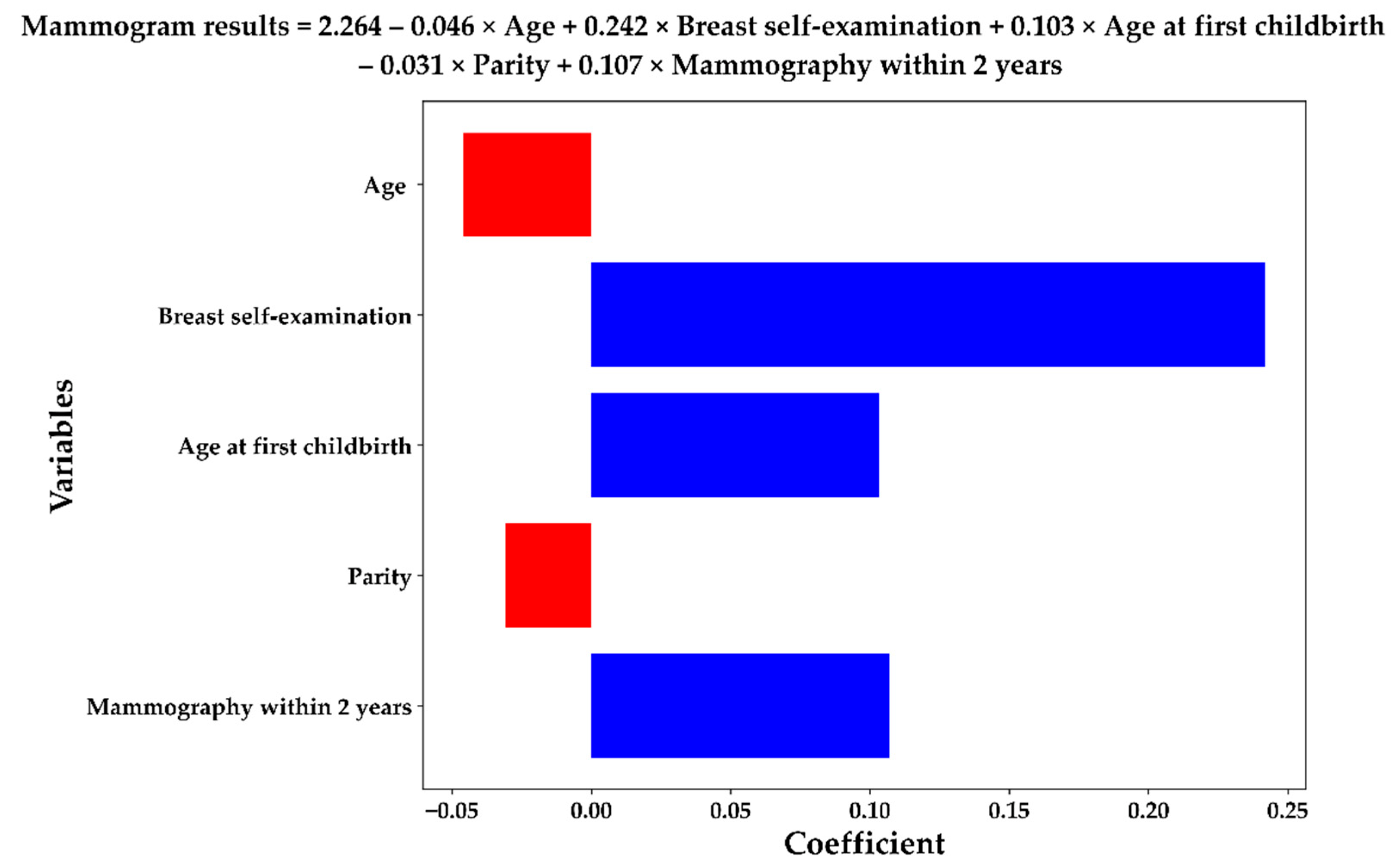
3.3. Lasso Results with XGB-SRVCs
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Torre, L.A.; Bray, F.; Siegel, R.L.; Ferlay, J.; Lortet-Tieulent, J.; Jemal, A. Global cancer statistics, 2012. CA Cancer J. Clin. 2015, 65, 87–108. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nelson, H.D.; Fu, R.; Cantor, A.; Pappas, M.; Daeges, M.; Humphrey, L.L. Effectiveness of Breast Cancer Screening: Systematic Review and Meta-analysis to Update the 2009 U.S. Preventive Services Task Force Recommendation. Ann. Intern. Med. 2016, 164, 244–255. [Google Scholar] [CrossRef] [PubMed]
- Oeffinger, K.C.; Fontham, E.T.; Etzioni, R.; Herzig, A.; Michaelson, J.S.; Shih, Y.C.; Walter, L.C.; Church, T.R.; Flowers, C.R.; LaMonte, S.J.; et al. Breast Cancer Screening for Women at Average Risk: 2015 Guideline Update from the American Cancer Society. JAMA 2015, 314, 1599–1614. [Google Scholar] [CrossRef] [PubMed]
- Bhoo-Pathy, N.; Yip, C.H.; Hartman, M.; Uiterwaal, C.S.; Devi, B.C.; Peeters, P.H.; Taib, N.A.; van Gils, C.H.; Verkooijen, H.M. Breast cancer research in Asia: Adopt or adapt Western knowledge? Eur. J. Cancer. 2013, 49, 703–709. [Google Scholar] [CrossRef] [Green Version]
- Chou, H.-P.; Tseng, L.-M. Outcome of mammography screening in Taiwan. J. Chin. Med. Assoc. 2014, 77, 503–504. [Google Scholar] [CrossRef] [Green Version]
- Runowicz, C.D.; Leach, C.R.; Henry, N.L.; Henry, K.S.; Mackey, H.T.; Cowens-Alvarado, R.L.; Ganz, P.A. American cancer society/American society of clinical oncology breast cancer survivorship care guideline. CA Cancer J. Clinicians. 2016, 66, 43–73. [Google Scholar] [CrossRef]
- World Health Organization. World Health Statistics 2016: Monitoring Health for the SDGs Sustainable Development Goals; World Health Organization: Geneva, Switzerland, 2016. [Google Scholar]
- Youn, H.J.; Han, W. A Review of the Epidemiology of Breast Cancer in Asia: Focus on Risk Factors. Asian Pac. J. Cancer Prev. 2020, 21, 867–880. [Google Scholar] [CrossRef] [Green Version]
- Katapodi, M.C.; Lee, K.A.; Facione, N.C.; Dodd, M.J. Predictors of perceived breast cancer risk and the relation between perceived risk and breast cancer screening: A meta-analytic review. Prev. Med. 2004, 38, 388–402. [Google Scholar] [CrossRef]
- James, R.E.; Lukanova, A.; Dossus, L.; Becker, S.; Rinaldi, S.; Tjønneland, A.; Olsen, A.; Overvad, K.; Mesrine, S.; Engel, P.; et al. Postmenopausal Serum Sex Steroids and Risk of Hormone Receptor–Positive and -Negative Breast Cancer: A Nested Case–Control Study. Cancer Prev. Res. 2011, 4, 1626–1635. [Google Scholar] [CrossRef] [Green Version]
- Triantafyllidis, A.K.; Tsanas, A. Applications of Machine Learning in Real-Life Digital Health Interventions: Review of the Literature. J. Med. Internet Res. 2019, 21, e12286. [Google Scholar] [CrossRef] [Green Version]
- Peiffer-Smadja, N.; Rawson, T.M.; Ahmad, R.; Buchard, A.; Georgiou, P.; Lescure, F.-X.; Birgand, G.; Holmes, A.H. Machine learning for clinical decision support in infectious diseases: A narrative review of current applications. Clin. Microbiol. Infect. 2020, 26, 584–595. [Google Scholar] [CrossRef] [PubMed]
- Davagdorj, K.; Pham, V.H.; Theera-Umpon, N.; Ryu, K.H. XGBoost-Based Framework for Smoking-Induced Noncommunicable Disease Prediction. Int. J. Environ. Res. Public Health 2020, 17, 6513. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.-C.; Cheng, Y.-C.; Jhou, M.-J.; Chen, M.; Lu, C.-J. Important Risk Factors in Patients with Nonvalvular Atrial Fibrillation Taking Dabigatran Using Integrated Machine Learning Scheme—A Post Hoc Analysis. J. Pers. Med. 2022, 12, 756. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.-Y.; Chen, F.-Y.; Jhou, M.-J.; Kuo, C.-H.; Wu, C.-Z.; Lu, C.-H.; Chen, Y.-L.; Pei, D.; Cheng, Y.-F.; Lu, C.-J. Comparing Multiple Linear Regression and Machine Learning in Predicting Diabetic Urine Albumin–Creatinine Ratio in a 4-Year Follow-Up Study. J. Clin. Med. 2022, 11, 3661. [Google Scholar] [CrossRef]
- Reel, P.S.; Reel, S.; Pearson, E.; Trucco, E.; Jefferson, E. Using machine learning approaches for multi-omics data analysis: A review. Biotechnol. Adv. 2021, 49, 107739. [Google Scholar] [CrossRef]
- Liu, P.; Fu, B.; Yang, S.X.; Deng, L.; Zhong, X.; Zheng, H. Optimizing Survival Analysis of XGBoost for Ties to Predict Disease Progression of Breast Cancer. IEEE Trans. Biomed. Eng. 2020, 68, 148–160. [Google Scholar] [CrossRef]
- Li, Q.; Yang, H.; Wang, P.; Liu, X.; Lv, K.; Ye, M. XGBoost-based and tumor-immune characterized gene signature for the prediction of metastatic status in breast cancer. J. Transl. Med. 2022, 20, 177. [Google Scholar] [CrossRef]
- McEligot, A.J.; Poynor, V.; Sharma, R.; Panangadan, A. Logistic LASSO Regression for Dietary Intakes and Breast Cancer. Nutrients 2020, 12, 2652. [Google Scholar] [CrossRef]
- Gupta, M.; Gupta, B. A novel gene expression test method of minimizing breast cancer risk in reduced cost and time by improving SVM-RFE gene selection method combined with LASSO. J. Integr. Bioinform. 2020, 18, 139–153. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, Q.; Yu, B.; Yu, Z.; Skillman-Lawrence, P.; Ma, Q.; Zhang, Y. Improving protein-protein interactions prediction accuracy using XGBoost feature selection and stacked ensemble classifier. Comput. Biol. Med. 2020, 123, 103899. [Google Scholar] [CrossRef]
- Zhang, S.; Zhu, F.; Yu, Q.; Zhu, X. Identifying DNA -binding proteins based on multi-features and LASSO feature selection. Biopolymers 2021, 112, e23419. [Google Scholar] [CrossRef]
- Wu, T.-E.; Chen, H.-A.; Jhou, M.-J.; Chen, Y.-N.; Chang, T.-J.; Lu, C.-J. Evaluating the Effect of Topical Atropine Use for Myopia Control on Intraocular Pressure by Using Machine Learning. J. Clin. Med. 2020, 10, 111. [Google Scholar] [CrossRef]
- Chiu, Y.-L.; Jhou, M.-J.; Lee, T.-S.; Lu, C.-J.; Chen, M.-S. Health Data-Driven Machine Learning Algorithms Applied to Risk Indicators Assessment for Chronic Kidney Disease. Risk Manag. Health Policy 2021, 14, 4401–4412. [Google Scholar] [CrossRef]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation Coefficients: Appropriate Use and Interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Tomkinson, J. Age at first birth and subsequent fertility: The case of adolescent mothers in France and England and Wales. Demogr. Res. 2019, 40, 761–798. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Garcia-Carretero, R.; Vigil-Medina, L.; Barquero-Perez, O.; Mora-Jimenez, I.; Soguero-Ruiz, C.; Goya-Esteban, R.; Ramos-Lopez, J. Logistic LASSO and Elastic Net to Characterize Vitamin D Deficiency in a Hypertensive Obese Population. Metab. Syndr. Relat. Disord. 2020, 18, 79–85. [Google Scholar] [CrossRef]
- Peng, C.-Y.J.; Lee, K.L.; Ingersoll, G.M. An Introduction to Logistic Regression Analysis and Reporting. J. Educ. Res. 2002, 96, 3–14. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the lasso. J. R. Stat. Soc. Ser. B Wiley 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Mohammed, R.; Rawashdeh, J.; Abdullah, M. Machine Learning with Oversampling and Undersampling Techniques: Overview Study and Experimental Results. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 243–248. [Google Scholar]
- Khushi, M.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Uddin, S.; Luo, S.; Yang, X.; Reyes, M.C. A Comparative Performance Analysis of Data Resampling Methods on Imbalance Medical Data. IEEE Access 2021, 9, 109960–109975. [Google Scholar] [CrossRef]
- Efron, B.; Gong, G. A leisurely look at the bootstrap, the jackknife, and cross-validation. Am. Stat. 1983, 37, 36–48. [Google Scholar]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.E.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A publishing format for reproducible computational workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas; IOS Press: Amsterdam, The Netherlands, 2016; pp. 87–90. [Google Scholar] [CrossRef]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. arXiv 2013, arXiv:1309.0238. [Google Scholar]
- Chang, Y.-S.; Park, H.-S.; Moon, I.-J. Predicting the Cochlear Dead Regions Using a Machine Learning-Based Approach with Oversampling Techniques. Medicina 2021, 57, 1192. [Google Scholar] [CrossRef] [PubMed]
- Kosters, J.P.; Gotzsche, P.C. Regular self-examination or clinical examination for early detection of breast cancer. Cochrane Database Syst Rev. 2003, CD003373. [Google Scholar] [CrossRef]
- Thomas, D.B.; Gao, D.L.; Ray, R.M.; Wang, W.W.; Allison, C.J.; Chen, F.L.; Porter, P.; Hu, Y.W.; Zhao, G.L.; Da Pan, L.; et al. Randomized Trial of Breast Self-Examination in Shanghai: Final Results. JNCI J. Natl. Cancer Inst. 2002, 94, 1445–1457. [Google Scholar] [CrossRef]
- Meier-Abt, F.; Bentires-Alj, M. How pregnancy at early age protects against breast cancer. Trends Mol. Med. 2014, 20, 143–153. [Google Scholar] [CrossRef]
- Meier-Abt, F.; Bentires-Alj, M.; Rochlitz, C. Breast Cancer Prevention: Lessons to be Learned from Mechanisms of Early Pregnancy–Mediated Breast Cancer Protection. Cancer Res. 2015, 75, 803–807. [Google Scholar] [CrossRef] [Green Version]
- Kelsey, J.L.; Gammon, M.D.; John, E.M. Reproductive Factors and Breast Cancer. Epidemiolog. Rev. 1993, 15, 36–47. [Google Scholar] [CrossRef]
- Bruzzi, P.; Negri, E.; La Vecchia, C.; Decarli, A.; Palli, D.; Parazzini, F.; Del Turco, M.R. Short term increase in risk of breast cancer after full term pregnancy. BMJ 1988, 297, 1096–1098. [Google Scholar] [CrossRef] [Green Version]
- Collaborative Group on Hormonal Factors in Breast Cancer. Menarche, menopause, and breast cancer risk: Individual participant meta-analysis, including 118 964 women with breast cancer from 117 epidemiological studies. Lancet Oncol. 2012, 13, 1141–1151. [Google Scholar] [CrossRef]
- Rosner, B.; Colditz, G.; Willett, W.C. Reproductive Risk Factors in a Prospective Study of Breast Cancer: The Nurses’ Health Study. Am. J. Epidemiol. 1994, 139, 819–835. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marmot, M.; Screening, T.I.U.P.O.B.C.; Altman, D.G.; Cameron, D.A.; Dewar, J.A.; Thompson, S.G.; Wilcox, M. The benefits and harms of breast cancer screening: An independent review. Br. J. Cancer 2013, 108, 2205–2240. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Myers, E.R.; Moorman, P.; Gierisch, J.M.; Havrilesky, L.J.; Grimm, L.J.; Ghate, S.; Davidson, B.; Mongtomery, R.C.; Crowley, M.J.; McCrory, D.C.; et al. Benefits and Harms of Breast Cancer Screening: A Systematic Review. JAMA 2015, 314, 1615–1634. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Metrics |
|---|---|
| Mean (SD) | |
| X1: Age | 55.16 (7.13) |
| X2: Height | 157.56 (5.35) |
| X3: Age at menarche | 13.87 (1.61) |
| X4: Body mass index | 23.65 (3.57) |
| N (%) | |
| X5: Education level | |
| 0: Primary school | 3036 (14%) |
| 1: Lower secondary school | 2668 (13%) |
| 2: Upper secondary school | 7295 (35%) |
| 3: University | 6891 (33%) |
| 4: Postgraduate | 1217 (6%) |
| X6: History of major diseases | |
| 0: No | 17,809 (84%) |
| 1: Benign | 2702 (13%) |
| 2: Cancer (other than breast) | 596 (3%) |
| X7: Breast self-examination | |
| 0: Breast self-exam negative | 15,435 (73%) |
| 1: Never breast self-exam | 4540 (22%) |
| 2: Mass or pain or tenderness | 1132 (5%) |
| X8: Mammography within 2 years | |
| 0: No | 8338 (40%) |
| 1: Yes | 12,769 (60%) |
| X9: History of breast surgery | |
| 0: No | 19,345 (91%) |
| 1: Yes | 1762 (9%) |
| X10: Age at first childbirth | |
| 0: Age < 21 | 1635 (8%) |
| 1: 21 ≤ Age < 35 | 15,741 (75%) |
| 2: Age ≥ 35 | 1037 (5%) |
| 3: No childbirth | 2694 (13%) |
| X11: Parity | |
| 0: 0 times | 2694 (13%) |
| 1: 1 time | 3136 (15%) |
| 2: 2 times | 9319 (44%) |
| 3: 3 times | 4688 (22%) |
| 4: ≥4 times | 1270 (6%) |
| X12: Breastfeeding | |
| 0: Nulliparous | 2694 (13%) |
| 1: No | 9554 (45%) |
| 2: Yes | 8859 (42%) |
| X13: Reproductive lifespan | |
| 0: lifespan < 25 | 430 (2%) |
| 1: 25 ≤ lifespan < 30 | 1272 (6%) |
| 2: 30 ≤ lifespan < 35 | 6357 (30%) |
| 3: 35 ≤ lifespan < 40 | 9447 (45%) |
| 4: lifespan ≥ 40 | 3601 (17%) |
| X14: Age at starting hormone replacement therapy | |
| 0: No use | 19,655 (93%) |
| 1: Age ≥ 60 | 50 (<1%) |
| 2: 50 ≤ Age < 60 | 681 (3%) |
| 3: 40 ≤ Age < 50 | 590 (3%) |
| 4: 30 ≤ Age < 40 | 103 (<1%) |
| 5: Age < 30 | 28 (<1%) |
| X15: Duration of hormone replacement therapy use | |
| 0: duration = 0 | 19,655 (93%) |
| 1: 0 < duration < 5 | 1027 (5%) |
| 2: duration ≥ 5 | 425 (2%) |
| X16: Age at starting oral contraceptives | N% |
| 0: No use | 19,903 (94%) |
| 1: Age > 25 | 754 (4%) |
| 2: Age ≤ 25 | 450 (2%) |
| X17: Duration of oral contraceptive use (years) | |
| 0: No use | 19,903 (94%) |
| 1: year ≤ 5 | 929 (4%) |
| 2: year > 5 | 275 (1%) |
| X18: Number of relatives with confirmed breast cancer | |
| 0: 0 | 18,746 (89%) |
| 1: 1 | 2190 (10%) |
| 2: ≥2 | 171 (1%) |
| Y: Mammogram findings | |
| 0: Negative | 18,089 (86%) |
| 1: Positive | 3018 (14%) |
| Data Balancing | Methods | Metrics | |||
|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | AUC | ||
| Mean (SD) | Mean (SD) | Mean (SD) | Mean (SD) | ||
| Without balancing | Lasso | 85.70 (0.48) | 0.00 | 100 (0.01) | 63.00 (1.11) |
| XGB | 84.73 (3.17) | 3.08 (8.91) | 98.35 (5.12) | 63.22 (1.04) | |
| With undersampling balancing | Lasso | 58.97 (0.94) | 60.97 (2.03) | 58.64 (1.19) | 62.80 (1.05) |
| XGB | 54.30 (16.56) | 63.00 (15.38) | 52.87 (21.83) | 62.32 (1.25) | |
| With oversampling balancing | Lasso | 58.23 (0.83) | 60.67 (1.89) | 58.89 (0.99) | 62.66 (1.10) |
| XGB | 25.62 (6.69) | 87.65 (6.72) | 15.26 (8.86) | 59.26 (1.19) | |
| Rank | Variable | Lasso Method | Variable | XGB Method |
|---|---|---|---|---|
| 1 | X7 | Breast self-examination | X1 | Age |
| 2 | X8 | Mammography within 2 years | X7 | Breast self-examination |
| 3 | X15 | Duration of hormone replacement therapy | X10 | Age at first childbirth |
| 4 | X6 | Major diseases | X11 | Parity |
| 5 | X10 | Age at first childbirth | X8 | Mammography within 2 years |
| 6 | X16 | Age at starting oral contraceptives | X6 | Major diseases |
| 7 | X14 | Age at starting hormone replacement therapy | X5 | Education level |
| 8 | X17 | Duration of oral contraceptive use | X4 | Body mass index |
| 9 | X9 | History of breast surgery | X16 | Age at starting oral contraceptives |
| 10 | X1 | Age | X13 | Reproductive lifespan |
| 11 | X12 | Breastfeeding | X2 | Body height |
| 12 | X18 | Number of relatives with confirmed breast cancer | X14 | Age at starting hormone replacement therapy |
| 13 | X5 | Education level | X12 | Breastfeeding |
| 14 | X11 | Parity | X18 | Number of relatives with confirmed breast cancer |
| 15 | X13 | Reproductive lifespan | X3 | Age at menarche |
| 16 | X3 | Age at menarche | X9 | History of breast surgery |
| 17 | X4 | Body mass index | X17 | Duration of oral contraceptive use |
| 18 | X2 | Body height | X15 | Duration of hormone replacement therapy |
| XGB-SRVCs Combinations | Variables | AUC |
|---|---|---|
| C1 | (Age) | 61.19 |
| C2 | (Age) + (Breast self-examination) | 61.98 |
| C3 | (Age) + (Breast self-examination) + (Age at first childbirth) | 62.52 |
| C4 | (Age) + (Breast self-examination) + (Age at first childbirth) + (Parity) | 62.53 |
| C5 | (Age) + (Breast self-examination) + (Age at first childbirth) + (Parity) + (Mammography within 2 years) | 62.72 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, C.-K.; Tang, Y.-X.; Liu, T.-C.; Lu, C.-J. An Integrated Machine Learning Scheme for Predicting Mammographic Anomalies in High-Risk Individuals Using Questionnaire-Based Predictors. Int. J. Environ. Res. Public Health 2022, 19, 9756. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph19159756
Sun C-K, Tang Y-X, Liu T-C, Lu C-J. An Integrated Machine Learning Scheme for Predicting Mammographic Anomalies in High-Risk Individuals Using Questionnaire-Based Predictors. International Journal of Environmental Research and Public Health. 2022; 19(15):9756. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph19159756
Chicago/Turabian StyleSun, Cheuk-Kay, Yun-Xuan Tang, Tzu-Chi Liu, and Chi-Jie Lu. 2022. "An Integrated Machine Learning Scheme for Predicting Mammographic Anomalies in High-Risk Individuals Using Questionnaire-Based Predictors" International Journal of Environmental Research and Public Health 19, no. 15: 9756. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph19159756