
ArCAR: A Novel Deep Learning Computer-Aided Recognition for Character-Level Arabic Text Representation and Recognition



Abstract
:1. Introduction
- First, the approach seeks to minimize the Arabic characters’ normalization by replacing the extended Arabic alphabets that have similar shapes with the basic one but with slightly different meanings such as أ, إ, and آ with ا, alphabet letter ة with ه, or letter ي with ى. Thus, the normalization process will directly affect the contextual meaning of similar shape words; for example, كرة means “football”, كره means “hatred”, علي means “the name of Ali”, على means “on the thing”, فار means “overflowed”, and فأر means “mouse”. In our character-level encoding methodology, we consider the different meanings of all of these characters by encoding them independently. This is to maintain the basic meaning of the different Arabic sentences.
- Second, to avoid the stemming problem, we need to understand the word’s root during the embedding process. The stemming problem is considered a major challenge for the Arabic language [30].
- Third, we also consider and encode stop words (i.e., من, في, إلى, على, etc.) as independent important words to keep the sentence meaning correct. The classical techniques suffered from understanding the stop words, and they removed them during the embedding process to reduce the textual feature dimensionality, but it affected the understanding accuracy of the Arabic sentences.
- Fourth, we solve the problem of alphabet position dependence, which means that the encoding of the Arabic alphabets, based on their positions in a single word, should be different (e.g., at the beginning سـ, middle ـسـ, or at the end س, or ـس).
- The quantization method is used to represent the Arabic text based on the character level.
- We have designed a new deep learning ArCAR system for Arabic text classification based on the capability of the deep convolutional network. The key idea of our system is to eliminate the need for Arabic text pre-processing which is very challenging and to achieve reasonable classification results.
- The deep learning ArCAR system is proposed to represent and recognize Arabic text in character level for two applications: (1) Arabic text documents recognition and (2) Arabic sentiment analysis.
- Finally, we conduct experiments and show the effectiveness of the proposed models for representation and classification to achieve excellent performance in solving many problems such as text recognition at the character level, which is better than at the word level to solve some problems such as out-of-vocabulary problems.
2. Related Works
2.1. Arabic Text Representation (ATR)
2.2. Arabic Text Classification (ATC)
3. Materials and Methods
3.1. Dataset
3.1.1. Arabic Documents Texts Datasets
SANAD Dataset
BBC Arabic Corpus
CNN Arabic Corpus
Open Source Arabic Corpus (OSAC)
Arabic Influencer Twitter Dataset (AITD)
3.1.2. Arabic Sentiment Analysis Dataset
Book Reviews in Arabic Dataset (BRAD2.0)
Hotel Arabic Reviews Dataset (HARD)
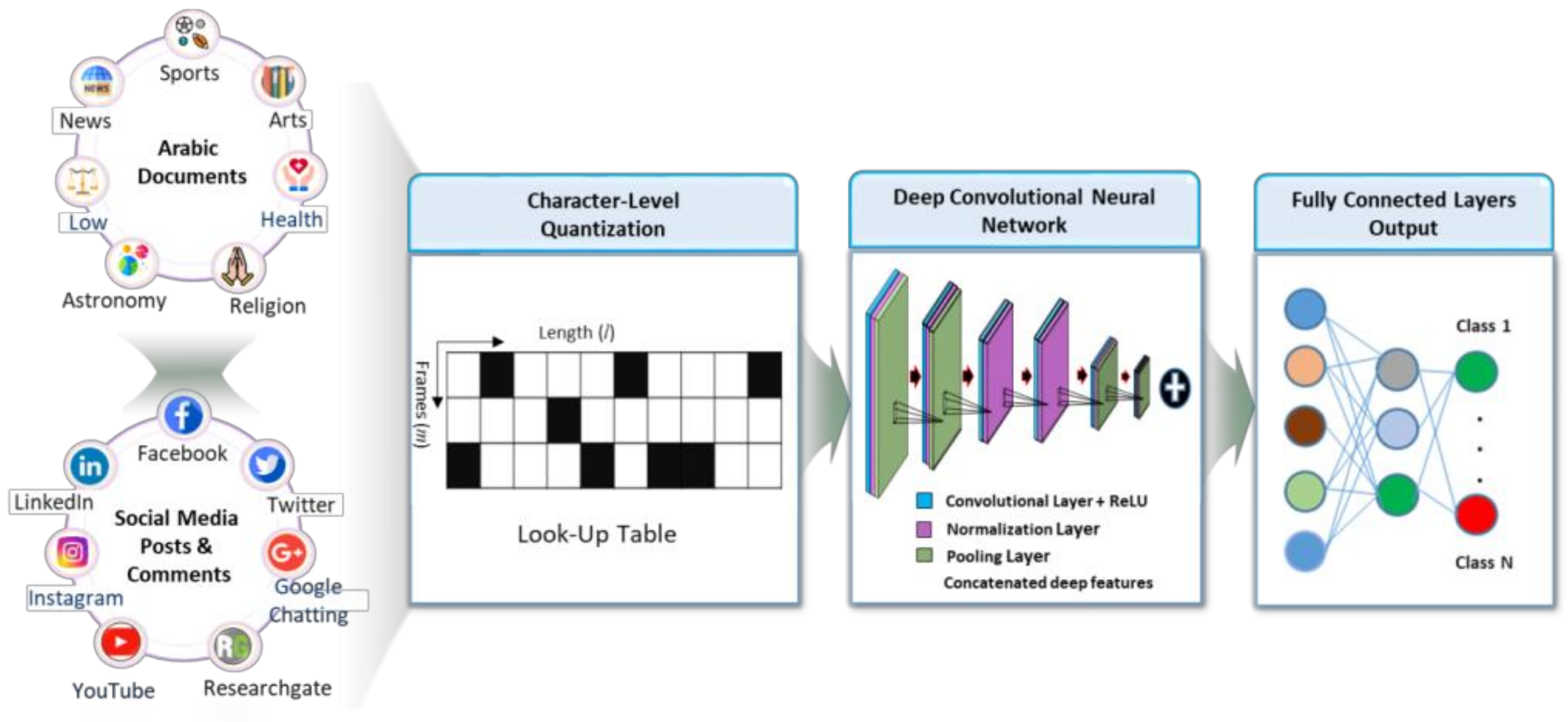
3.2. Arabic Character-Level Quantization

3.3. Data Preprocessing
3.4. Data Preparation: Training, Validation, and Testing
3.5. The Proposed ArCAR System
3.6. Experimental Settings
3.7. Evaluation Strategy
3.8. Implementation Environment
4. Results
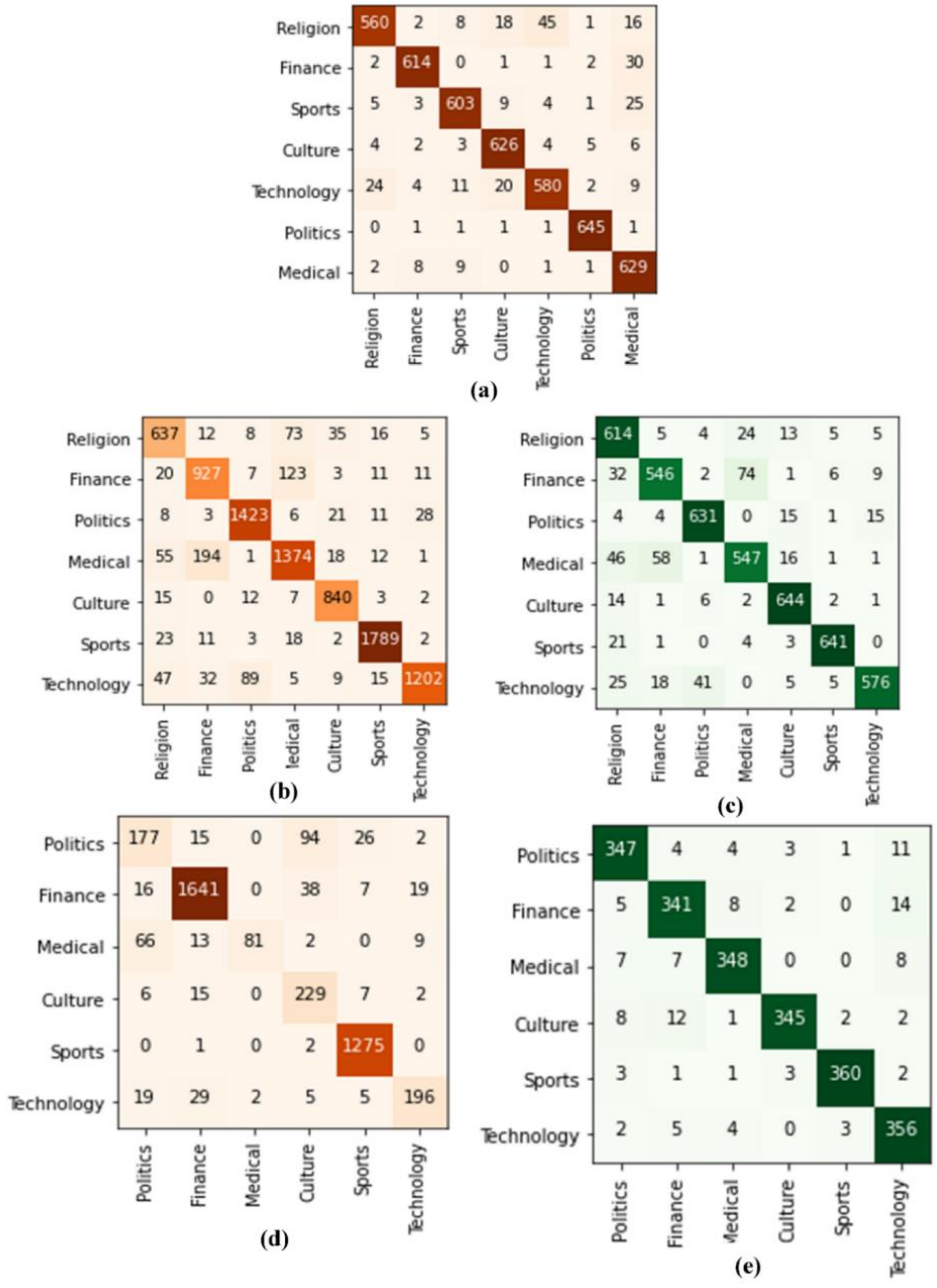
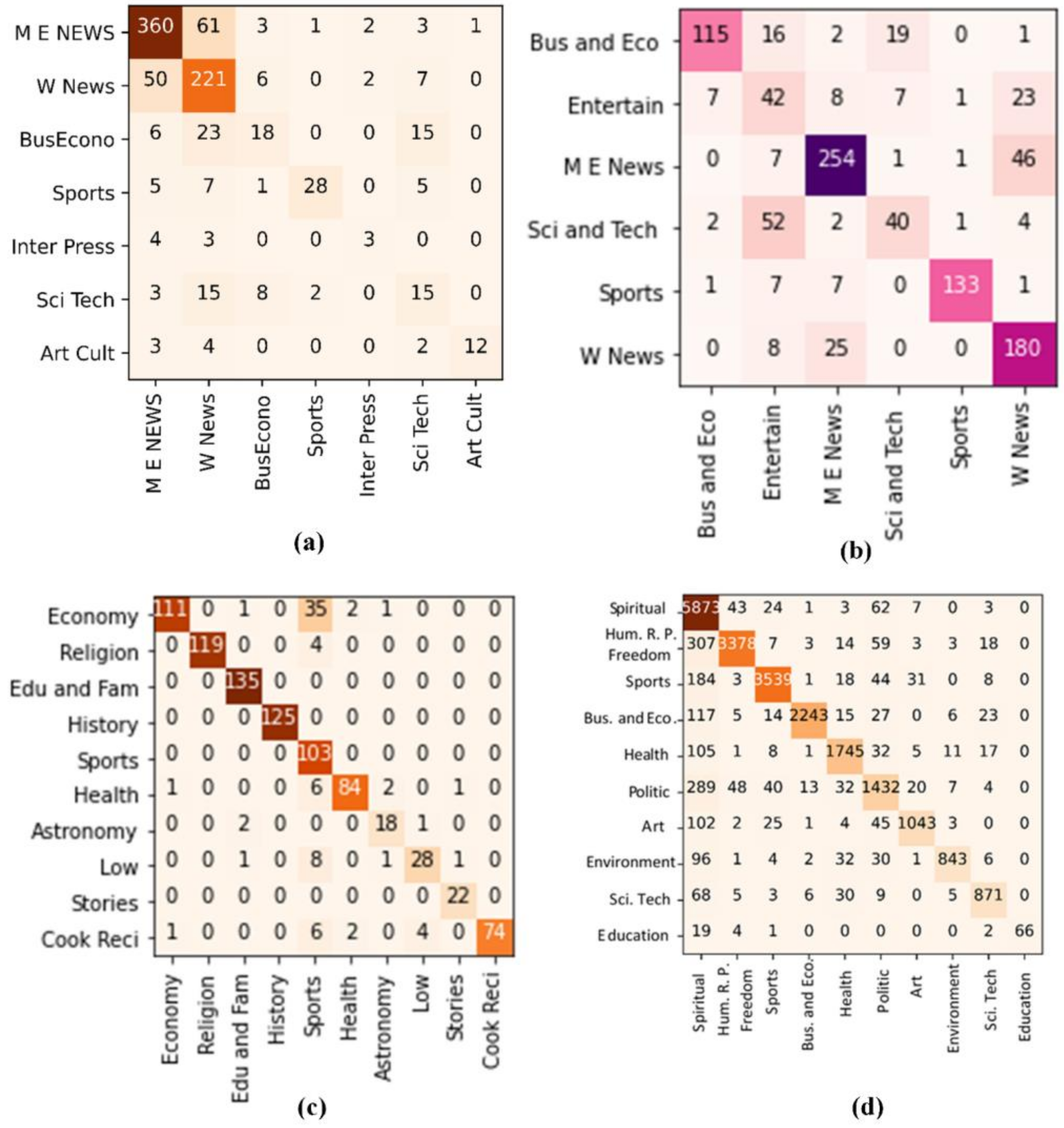
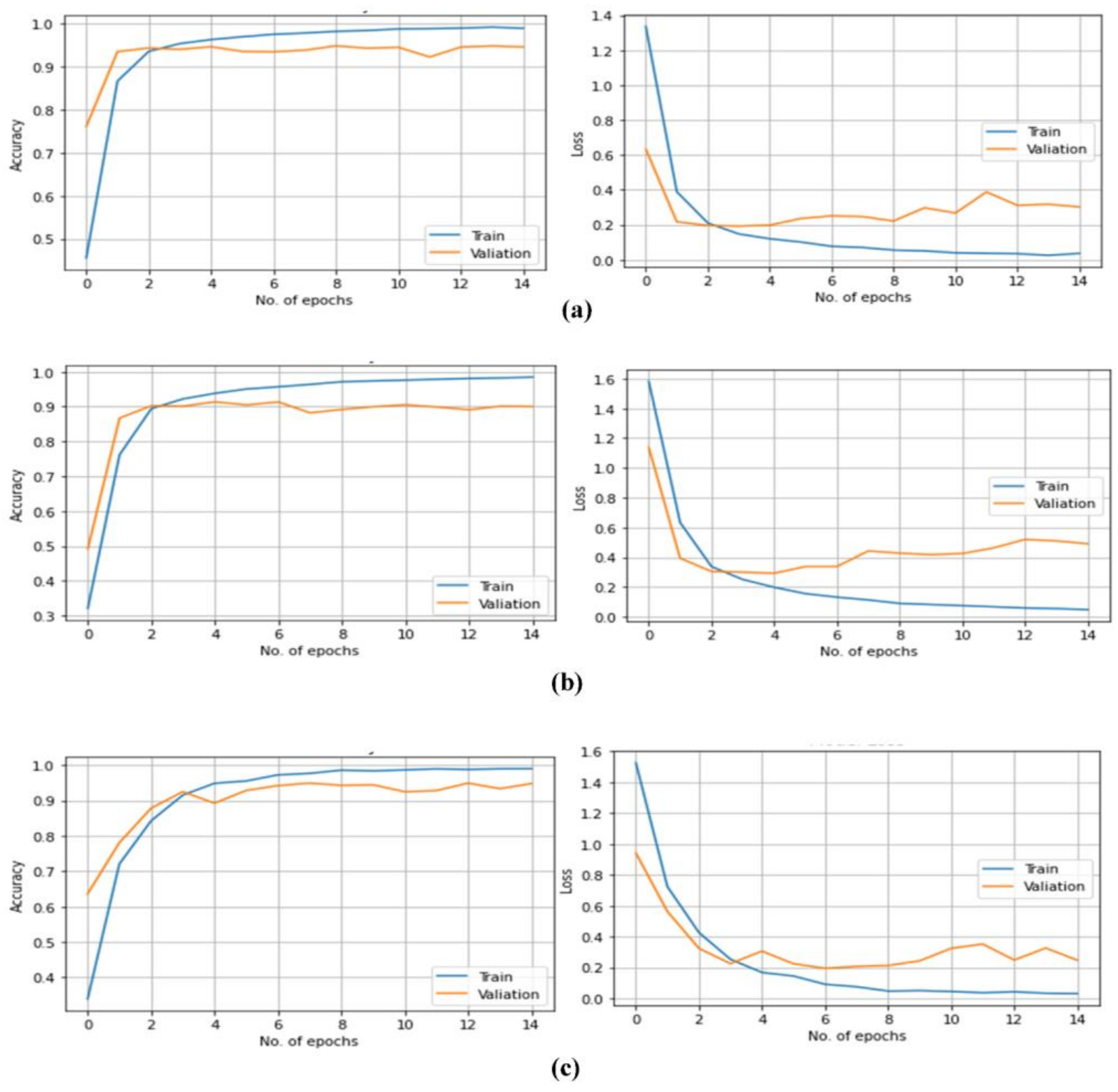
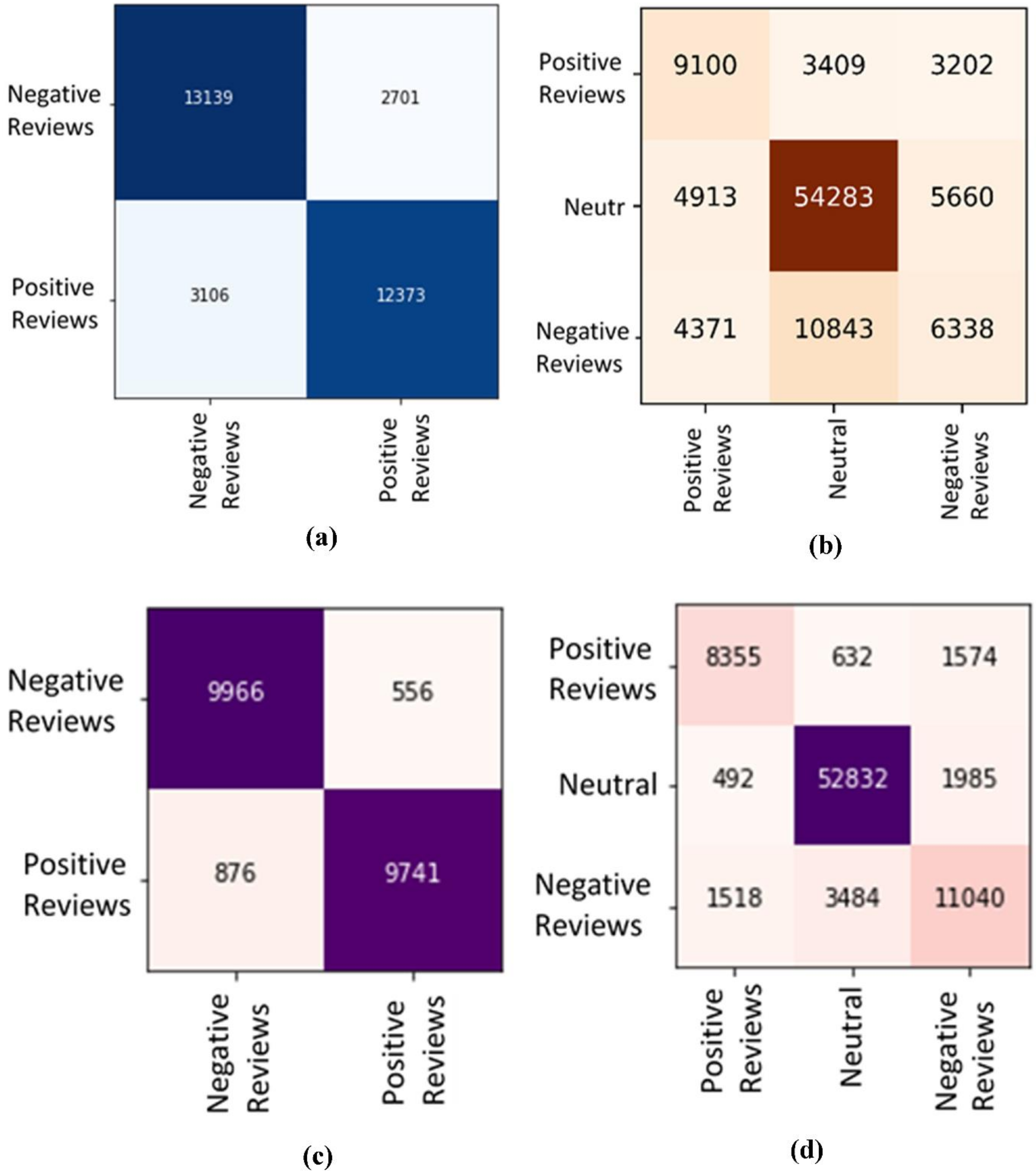
4.1. Arabic Documents Text Recognition
4.2. Arabic Sentiment Analysis
5. Discussion
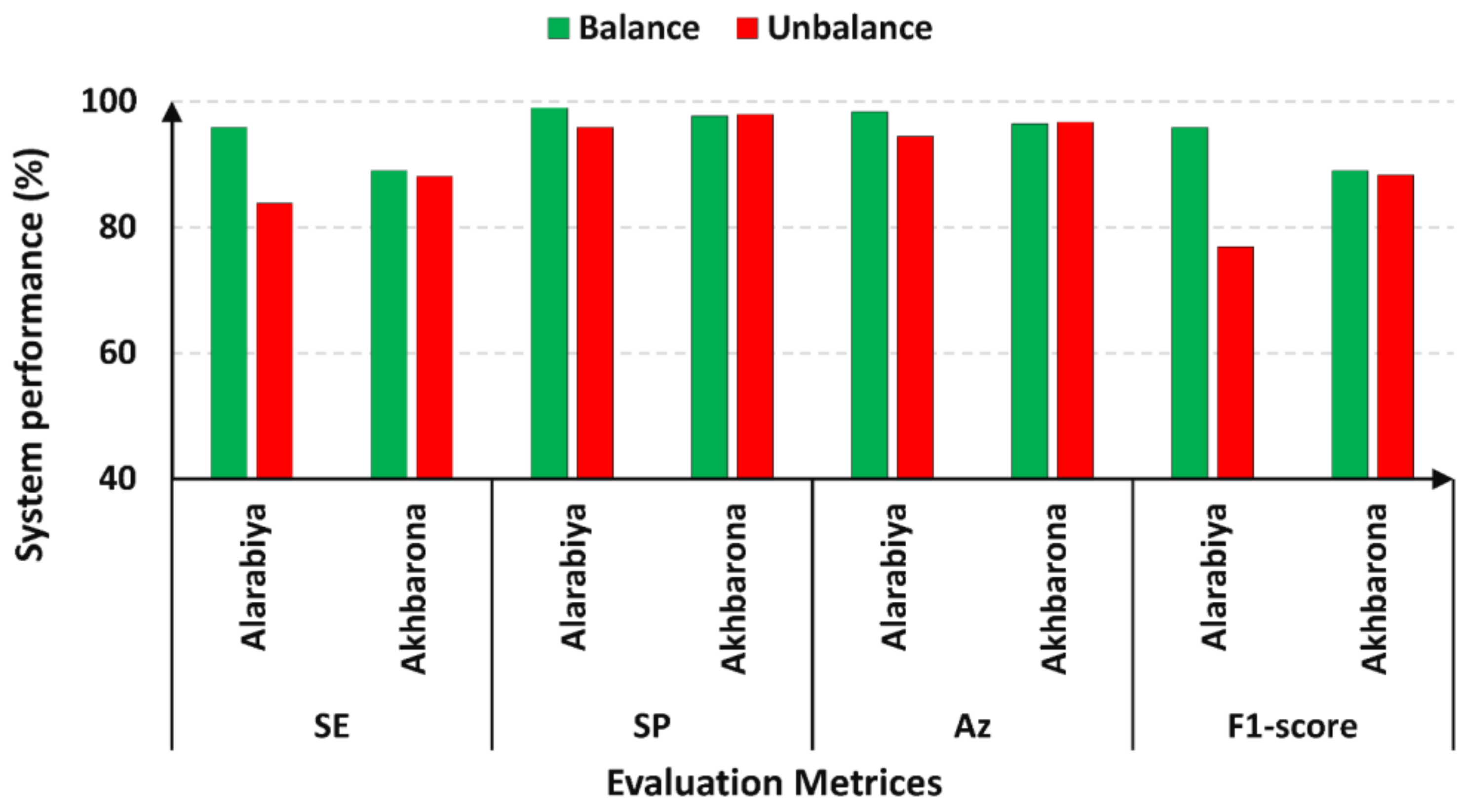
5.1. Arabic Documents Text Recognition
5.2. Arabic Sentiment Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Aggarwal, C.C.; Zhai, C. A survey of text classification algorithms. In Mining Text Data; Springer: New York, NY, USA, 2012; pp. 163–222. [Google Scholar]
- Ameur, M.; Belkebir, R.; Guessoum, A. Robust Arabic Text Categorization by Combining Convolutional and Recurrent Neural Networks. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2020, 19, 1–16. [Google Scholar] [CrossRef]
- Larkey, L.S.; Connell, M.E. Arabic information retrieval at UMass in TREC-10. In Proceedings of the Tenth Text Retrieval Conference, Gaithersburg, MD, USA, 13–16 November 2001. [Google Scholar]
- Mohammed, O.A.; Salah, A. Translating Ambiguous Arabic Words Using Text Mining. Int. J. Comput. Sci. Mob. Comput. 2019, 8, 130–140. [Google Scholar]
- Harrat, S.; Meftouh, K.; Smaili, K. Machine translation for Arabic dialects (survey). Inf. Process. Manag. 2019, 56, 262–273. [Google Scholar] [CrossRef] [Green Version]
- El-Halees, A.M. Filtering Spam E-Mail from Mixed Arabic and English Messages: A Comparison of Machine Learning Techniques. Int. Arab. J. Inf. Technol. 2009, 6, 1. [Google Scholar]
- Shehab, M.A.; Badarneh, O.; Al-Ayyoub, M.; Jararweh, Y. A supervised approach for multi-label classification of Arabic news articles. In Proceedings of the 2016 7th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 13–14 July 2016; pp. 1–6. [Google Scholar]
- Hakak, S.; Kamsin, A.; Tayan, O.; Idris, M.Y.I.; Gilkar, G.A. Approaches for preserving content integrity of sensitive online Arabic content: A survey and research challenges. Inf. Process. Manag. 2019, 56, 367–380. [Google Scholar] [CrossRef]
- Elnagar, A.; Al-Debsi, R.; Einea, O. Arabic text classification using deep learning models. Inf. Process. Manag. 2020, 57, 102121. [Google Scholar] [CrossRef]
- Al-Sabahi, K.; Zhang, Z.; Long, J.; Alwesabi, K. An enhanced latent semantic analysis approach for arabic document summarization. Arab. J. Sci. Eng. 2018, 43, 8079–8094. [Google Scholar] [CrossRef] [Green Version]
- Hasanuzzaman, H. Arabic language: Characteristics and importance. Echo J. Humanit. Soc. Sci. 2013, 1, 11–16. [Google Scholar]
- Salah, R.E.; binti Zakaria, L.Q. A comparative review of machine learning for Arabic named entity recognition. Int. J. Adv. Sci. Eng. Inf. Technol. 2017, 7, 511–518. [Google Scholar] [CrossRef] [Green Version]
- Marie-Sainte, S.L.; Alalyani, N.; Alotaibi, S.; Ghouzali, S.; Abunadi, I. Arabic natural language processing and machine learning-based systems. IEEE Access 2018, 7, 7011–7020. [Google Scholar] [CrossRef]
- Bounhas, I.; Soudani, N.; Slimani, Y. Building a morpho-semantic knowledge graph for Arabic information retrieval. Inf. Process. Manag. 2020, 57, 102124. [Google Scholar] [CrossRef]
- Kowsari, K.; Meimandi, K.J.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Al-Smadi, M.; Al-Ayyoub, M.; Jararweh, Y.; Qawasmeh, O. Enhancing aspect-based sentiment analysis of Arabic hotels’ reviews using morphological, syntactic and semantic features. Inf. Process. Manag. 2019, 56, 308–319. [Google Scholar] [CrossRef]
- Al-antari, M.A.; Al-masni, M.A.; Metwally, M.K.; Hussain, D.; Park, S.-J.; Shin, J.-S.; Han, S.-M.; Kim, T.-S. Denoising images of dual energy X-ray absorptiometry using non-local means filters. J. X-ray Sci. Technol. 2018, 26, 395–412. [Google Scholar] [CrossRef]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very deep convolutional networks for text classification. arXiv 2016, arXiv:1606.01781. [Google Scholar]
- Duque, A.B.; Santos, L.L.J.; Macêdo, D.; Zanchettin, C. Squeezed Very Deep Convolutional Neural Networks for Text Classification. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; pp. 193–207. [Google Scholar]
- Daif, M.; Kitada, S.; Iyatomi, H. AraDIC: Arabic Document Classification using Image-Based Character Embeddings and Class-Balanced Loss. arXiv 2020, arXiv:2006.11586. [Google Scholar]
- Zhang, X.; LeCun, Y. Text understanding from scratch. arXiv 2015, arXiv:1502.01710. [Google Scholar]
- Einea, O.; Elnagar, A.; al Debsi, R. Sanad: Single-label arabic news articles dataset for automatic text categorization. Data Brief 2019, 25, 104076. [Google Scholar] [CrossRef]
- Al-Masni, M.A.; Al-Antari, M.A.; Choi, M.T.; Han, S.M.; Kim, T.S. Skin lesion segmentation in dermoscopy images via deep full resolution convolutional networks. Comput. Methods Programs Biomed. 2018, 162, 221–231. [Google Scholar] [CrossRef]
- Al-Masni, M.A.; Al-Antari, M.A.; Park, J.-M.; Gi, G.; Kim, T.-Y.; Rivera, P.; Valarezo, E.; Choi, M.-T.; Han, S.-M. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput. Methods Programs Biomed. 2018, 157, 85–94. [Google Scholar] [CrossRef] [PubMed]
- Al-Antari, M.A.; Al-Masni, M.A.; Choi, M.T.; Han, S.M.; Kim, T.S. A fully integrated computer-aided diagnosis system for digital X-ray mammograms via deep learning detection, segmentation, and classification. Int. J. Med Inform. 2018, 117, 44–54. [Google Scholar] [CrossRef]
- Al-Antari, M.A.; Kim, T.-S. Evaluation of Deep Learning Detection and Classification towards Computer-aided Diagnosis of Breast Lesions in Digital X-ray Mammograms. Comput. Methods Programs Biomed. 2020, 196, 105584. [Google Scholar] [CrossRef] [PubMed]
- Al-antari, M.A.; Hua, C.-H.; Bang, J.; Lee, S. Fast deep learning computer-aided diagnosis of COVID-19 based on digital chest x-ray images. Appl. Intell. 2020, 51, 2890–2907. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gambäck, B.; Sikdar, U.K. Using convolutional neural networks to classify hate-speech. In Proceedings of the First Workshop on Abusive Language Online, Vancouver, BC, Canada, 4 August 2017; pp. 85–90. [Google Scholar]
- Habash, N.Y. Introduction to Arabic natural language processing. Synth. Lect. Hum. Lang. Technol. 2010, 3, 1–187. [Google Scholar] [CrossRef]
- Lo, S.L.; Cambria, E.; Chiong, R.; Cornforth, D. Multilingual sentiment analysis: From formal to informal and scarce resource languages. Artif. Intell. Rev. 2017, 48, 499–527. [Google Scholar] [CrossRef]
- Cambria, E.; Das, D.; Bandyopadhyay, S.; Feraco, A. Affective computing and sentiment analysis. In A Practical Guide to Sentiment Analysis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–10. [Google Scholar]
- Durou, A.; Aref, I.; Al-Maadeed, S.; Bouridane, A.; Benkhelifa, E. Writer identification approach based on bag of words with OBI features. Inf. Process. Manag. 2019, 56, 354–366. [Google Scholar] [CrossRef]
- El Kourdi, M.; Bensaid, A.; Rachidi, T.-E. Automatic Arabic document categorization based on the Naïve Bayes algorithm. In Proceedings of the Workshop on Computational Approaches to Arabic Script-based Languages, Geneva, Switzerland, 28 August 2004; pp. 51–58. [Google Scholar]
- Al-Harbi, S.; Almuhareb, A.; Al-Thubaity, A.; Khorsheed, M.; Al-Rajeh, A. Automatic Arabic Text Classification; In Proceedings of the 9th International Conference on the Statistical Analysis of Textual Data, Lyon, France, 12–14 March 2008.
- Etaiwi, W.; Awajan, A. Graph-based Arabic text semantic representation. Inf. Process. Manag. 2020, 57, 102183. [Google Scholar] [CrossRef]
- Suleiman, D.; Awajan, A.; al Etaiwi, W. The use of hidden Markov model in natural arabic language processing: A survey. Procedia Comput. Sci. 2017, 113, 240–247. [Google Scholar] [CrossRef]
- Al-Ayyoub, M.; Khamaiseh, A.A.; Jararweh, Y.; Al-Kabi, M.N. A comprehensive survey of arabic sentiment analysis. Inf. Process. Manag. 2019, 56, 320–342. [Google Scholar] [CrossRef]
- Boukil, S.; Biniz, M.; el Adnani, F.; Cherrat, L.; el Moutaouakkil, A.E. Arabic text classification using deep learning technics. Int. J. Grid Distrib. Comput. 2018, 11, 103–114. [Google Scholar] [CrossRef]
- Almuzaini, H.A.; Azmi, A.M. Impact of stemming and word embedding on deep learning-based arabic text categorization. IEEE Access 2020, 8, 127913–127928. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Abdul-Mageed, M. Modeling arabic subjectivity and sentiment in lexical space. Inf. Process. Manag. 2019, 56, 291–307. [Google Scholar] [CrossRef]
- Oueslati, O.; Cambria, E.; HajHmida, M.B.; Ounelli, H. A review of sentiment analysis research in Arabic language. Future Gener. Comput. Syst. 2020, 112, 408–430. [Google Scholar] [CrossRef]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A.M. Character-aware neural language models. arXiv 2015, arXiv:1508.06615. [Google Scholar]
- Romeo, S.; Martino, G.d.; Belinkov, Y.; Barrón-Cedeño, A.; Eldesouki, M.; Darwish, K.; Mubarak, H.; Glass, J.; Moschitti, A. Language processing and learning models for community question answering in arabic. Inf. Process. Manag. 2019, 56, 274–290. [Google Scholar] [CrossRef]
- Alayba, A.M.; Palade, V.; England, M.; Iqbal, R. Improving sentiment analysis in Arabic using word representation. In Proceedings of the 2018 IEEE 2nd International Workshop on Arabic and Derived Script Analysis and Recognition (ASAR), London, UK, 12–14 March 2018; pp. 13–18. [Google Scholar]
- Al-Taani, A.T.; Al-Sayadi, S.H. Classification of Arabic Text Using Singular Value Decomposition and Fuzzy C-Means Algorithms. In Applications of Machine Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 111–123. [Google Scholar]
- Elfaik, H. Deep Bidirectional LSTM Network Learning-Based Sentiment Analysis for Arabic Text. J. Intell. Syst. 2020, 30, 395–412. [Google Scholar] [CrossRef]
- El-Alami, F.-Z.; El Mahdaouy, A.; El Alaoui, S.O.; En-Nahnahi, N. A deep autoencoder-based representation for arabic text categorization. J. Inf. Commun. Technol. 2020, 19, 381–398. [Google Scholar] [CrossRef]
- Elzayady, H.; Badran, K.M.; Salama, G.I. Arabic Opinion Mining Using Combined CNN-LSTM Models. Int. J. Intell. Syst. Appl. 2020, 12, 25–36. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 2015, 28, 649–657. [Google Scholar]
- Saad, M.K.; Ashour, W.M. Osac: Open Source Arabic Corpora. In Proceedings of the 6th International Conference on Electrical and Computer Systems (EECS’10), Lefke, North Cyprus, 25–26 November 2010. [Google Scholar]
- Chowdhury, S.A.; Abdelali, A.; Darwish, K.; Soon-Gyo, J.; Salminen, J.; Jansen, B.J. Improving Arabic Text Categorization Using Transformer Training Diversification. In Proceedings of the Fifth Arabic Natural Language Processing Workshop, Barcelona, Spain, 1 December 2020; pp. 226–236. [Google Scholar]
- Elnagar, A.; Einea, O. Brad 1.0: Book reviews in arabic dataset. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–8. [Google Scholar]
- Elnagar, A.; Khalifa, Y.S.; Einea, A. Hotel Arabic-reviews dataset construction for sentiment analysis applications. In Intelligent Natural Language Processing: Trends and Applications; Springer: Berlin/Heidelberg, Germany, 2018; pp. 35–52. [Google Scholar]
- Alsharhan, E.; Ramsay, A. Improved Arabic speech recognition system through the automatic generation of fine-grained phonetic transcriptions. Inf. Process. Manag. 2019, 56, 343–353. [Google Scholar] [CrossRef]
- Farha, I.A.; Magdy, W. A comparative study of effective approaches for Arabic sentiment analysis. Inf. Process. Manag. 2021, 58, 102438. [Google Scholar] [CrossRef]
- Park, H.-G.; Bhattacharjee, S.; Deekshitha, P.; Kim, C.-H.; Choi, H.-K. A Study on Deep Learning Binary Classification of Prostate Pathological Images Using Multiple Image Enhancement Techniques. J. Korea Multimed. Soc. 2020, 23, 539–548. [Google Scholar]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Li, Y.; Xu, L.; Rao, J.; Guo, L.; Yan, Z.; Jin, S. A Y-Net deep learning method for road segmentation using high-resolution visible remote sensing images. Remote Sens. Lett. 2019, 10, 381–390. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Class Type | AlKhaleej | Akhbarona | Alarabiya |
|---|---|---|---|---|
| 1 | Finance | 6500 | 9280 | 30,076 |
| 2 | Sports | 6500 | 15,755 | 23,058 |
| 3 | Culture | 6500 | 6746 | 5619 |
| 4 | Technology | 6500 | 12,199 | 4410 |
| 5 | Politics | 6500 | 13,979 | 4368 |
| 6 | Medical | 6500 | 12,947 | 3715 |
| 7 | Religion | 6500 | 7552 | - |
| # | Class Type | BBC | CNN |
|---|---|---|---|
| 1 | Middle East News | 2356 | 1462 |
| 2 | World News | 1489 | 1010 |
| 3 | Business and Economy | 296 | 836 |
| 4 | Sports | 219 | 762 |
| 5 | International Press | 49 | - |
| 6 | Science and Technology | 232 | 526 |
| 7 | Entertainments | - | 474 |
| 8 | Art and Culture | 122 | - |
| # | Class Type | No. of Documents |
|---|---|---|
| 1 | Economy | 3102 |
| 2 | Religion | 3171 |
| 3 | Education and Family | 3608 |
| 4 | History | 3233 |
| 5 | Sports | 2419 |
| 6 | Health | 2296 |
| 7 | Astronomy | 557 |
| 8 | Low | 944 |
| 9 | Stories | 726 |
| 10 | Cooking Recipes | 2373 |
| # | Class Type | No. of Documents |
|---|---|---|
| 1 | Spiritual | 29,554 |
| 2 | Human-Rights-Press-Freedom | 19,477 |
| 3 | Sports | 18,875 |
| 4 | Business and Economy | 12,270 |
| 5 | Health | 9456 |
| 6 | Politics | 9369 |
| 7 | Art | 6247 |
| 8 | Environment | 5010 |
| 9 | Science and Technology | 4936 |
| 10 | Education | 498 |
| Class Type | BRAD2.0 | HARD | ||
|---|---|---|---|---|
| Multi-Class (Unbalance) | Binary-Class (Balance) | Multi-Class (Unbalance) | Binary-Class (Balance) | |
| Negative Reviews | 78,380 | 78,380 | 40,953 | 52,849 |
| Positive Reviews | 325,433 | 78,126 | 286,695 | 52,849 |
| Neutral | 106,785 | - | 81,912 | - |
| # | Layer Type | Filter Size, Maps | Pooling |
|---|---|---|---|
| 1 | Input data: 70 × 1014 (2D) | - | - |
| 2 | CONV. 1 | 7 × 7, 64 | 2 |
| 3 | CONV. 2 | 5 × 5, 128 | 2 |
| 4 | CONV. 3 | 3 × 3, 256 | NA |
| 5 | CONV. 4 | 3 × 3, 256 | NA |
| 6 | CONV. 5 | 3 × 3, 256 | 2 |
| 7 | CONV. 6 | 3 × 3, 256 | 2 |
| 8 | Dense 1 | 1024 | - |
| 9 | Dense 2 | 1024 | - |
| 10 | Softmax (Output) | Based on the number of classes | - |
| DATASET | SE | SP | Az | F1-Score | MCC | PPV | NPV |
|---|---|---|---|---|---|---|---|
| AlKhaleej balance | 92.64 | 98.28 | 97.47 | 92.63 | 91.55 | 92.75 | 98.28 |
| Akhbarona balance | 88.99 | 97.67 | 96.43 | 88.98 | 78.31 | 89.16 | 97.67 |
| Akhbarona unbalance | 88.08 | 97.93 | 96.68 | 88.28 | 86.55 | 88.60 | 97.94 |
| Alarabiya balance | 94.08 | 98.50 | 97.76 | 94.09 | 93.01 | 94.16 | 98.50 |
| Alarabiya unbalance | 83.80 | 95.88 | 94.43 | 76.87 | 74.40 | 73.01 | 96.69 |
| BBC | 69.02 | 85.44 | 81.63 | 69.62 | 57.43 | 71.18 | 83.43 |
| CNN | 74.72 | 94.58 | 91.56 | 75.43 | 70.72 | 77.46 | 84.86 |
| OSAC | 91.26 | 98.49 | 97.60 | 91.40 | 90.85 | 93.10 | 98.39 |
| AIDT | 90.15 | 97.11 | 96.59 | 90.17 | 88.58 | 90.73 | 98.18 |
| Dataset | * Train Time/Epoch (sec) | No. of Epochs | * Testing Time/Testing Set (sec) |
|---|---|---|---|
| AlKhaleej | 36.89 | 14 | 1.2 |
| Akhbarona unbalance | 1065.096 | 10 | 7.651 |
| Akhbarona balance | 1134.466 | 14 | 3.611 |
| Alarabiya unbalance | 307.265 | 10 | 3.689 |
| Alarabiya balance | 556.531 | 14 | 1.706 |
| BBC | 8.10 | 20 | 0.22 |
| CNN | 44.76 | 25 | 0.4 |
| OSAC | 179.251 | 10 | 0.746 |
| AIDT | 109.67 | 10 | 2.90 |
| Dataset | SE | SP | Az. | F1-Score | MCC | PPV | NPV |
|---|---|---|---|---|---|---|---|
| BRAD Binary-class | 81.44 | 81.44 | 81.46 | 81.45 | 62.92 | 81.48 | 81.48 |
| BRAD Multiclass | 68.35 | 71.61 | 77.13 | 67.25 | 40.87 | 66.77 | 75.00 |
| HARD Binary-class | 93.23 | 93.23 | 93.58 | 93.23 | 86.49 | 93.26 | 93.26 |
| HARD Multiclass | 80.98 | 94.35 | 93.23 | 81.63 | 76.34 | 82.33 | 95.00 |
| Dataset | * Train Time/Epoch (sec) | No. of Epochs | * Testing Time/Epoch (sec) |
|---|---|---|---|
| BRAD Binary-class | 1594.02 | 11 | 3.3 |
| BRAD Multiclass | 3511.13 | 10 | 10.76 |
| HARD Binary-class | 93.03 | 10 | 2.44 |
| HARD Multiclass | 648.03 | 12 | 9.83 |
| Classification | World-Level and Character-Level Representations | |||||
|---|---|---|---|---|---|---|
| CNN Dataset (Unbalance) | AlKhaleej Dataset (Balance/Unbalance) | |||||
| Word-Level Representation | Char Level Representation | Word-Level Representation | Char Level Representation | |||
| TFIDF | BOW | TFIDF | BOW | |||
| MultinomialNB | 64.00 | 88.00 | - | 91.00 | 93.00 | - |
| BernoulliNB | 61.00 | 61.00 | 87.00 | 85.00 | ||
| LogisticRegression | 90.00 | 91.30 | 94.00 | 96.00 | ||
| SGDClassifier | 91.20 | 91.00 | 94.00 | 95.00 | ||
| Support Vector Classifier(SVC) | 90.00 | 90.00 | 95.00 | 96.00 | ||
| Linear SVC | 91.00 | 91.00 | 94.00 | 96.00 | ||
| Proposed ArCAR | - | - | 91.56 | - | - | 97.47 |
| Dataset | Method | Precision/PPV | Recall/SE | F1-Score | Accuracy |
|---|---|---|---|---|---|
| AlKhaleej | DL-CNN-GRU Elnagar et al. [9] | - | - | - | 96.0 |
| Multinomial Naïve Bays Our Conventional | 90.0 | 90.0 | 90.0 | 90.0 | |
| The proposed ArCAR System | 92.75 | 92.64 | 92.63 | 97.47 | |
| Akhbaronabalance | DL-CNN-GRU Elnagar et al. [9] | - | - | - | 94 |
| The proposed ArCAR System | 89.16 | 88.99 | 88.98 | 96.43 | |
| Alarabiyabalance | DL-CNN-GRU Elnagar et al. [9] | - | - | - | 97.0 |
| The proposed ArCAR System | 94.16 | 94.08 | 94.09 | 97.76 | |
| BBC | Multinomial Naïve Bays Our Conventional | 64.0 | 37.0 | 42.0 | 74.0 |
| The proposed ArCAR System | 71.18 | 69.02 | 69.62 | 81.63 | |
| CNN | Fuzzy C-mean and SVD Kowsari et al. [15] | 60.0 | 61.0 | 62.0 | - |
| Multinomial Naïve Bays Our Conventional | 77.0 | 67.0 | 75.43 | 91.0 | |
| The proposed ArCAR System | 77.46 | 74.72 | 75.43 | 91.56 | |
| OSAC | Multi-Layer Perceptron Saad et al. [43] | 91.0 | 90.0 | 90.0 | - |
| Multinomial Naïve Bays Our Conventional | 97.0 | 88.0 | 89.0 | 87.0 | |
| The proposed ArCAR System | 93.10 | 91.26 | 91.40 | 97.62 | |
| AIDT | BERT model Chowdhury et al. [52] | 86 | - | - | - |
| The proposed ArCAR System | 90.15 | 97.11 | 90.17 | 96.59 |
| Dataset | Method | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|
| BRAD Binary-class | SVM Elnagar et al. [46] | - | - | 80.0 | 82.0 |
| The proposed ArCAR System | 81.48 | 81.44 | 81.45 | 81.46 | |
| BRAD Multiclass | SVM Elnagar et al. [46] | - | - | 71.0 | 78.0 |
| The proposed ArCAR System | 66.77 | 68.35 | 67.25 | 77.13 | |
| HARD Binary-class | SVM Elnagar et al. [47] | - | - | 81.0 | 78.0 |
| The proposed ArCAR System | 93.26 | 93.23 | 93.23 | 93.23 | |
| HARD Multiclass | Random Forest Elnagar et al. [47] | - | - | 51.0 | 88.0 |
| The proposed ArCAR System | 82.33 | 80.98 | 81.63 | 93.58 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muaad, A.Y.; Jayappa, H.; Al-antari, M.A.; Lee, S. ArCAR: A Novel Deep Learning Computer-Aided Recognition for Character-Level Arabic Text Representation and Recognition. Algorithms 2021, 14, 216. https://0-doi-org.brum.beds.ac.uk/10.3390/a14070216
Muaad AY, Jayappa H, Al-antari MA, Lee S. ArCAR: A Novel Deep Learning Computer-Aided Recognition for Character-Level Arabic Text Representation and Recognition. Algorithms. 2021; 14(7):216. https://0-doi-org.brum.beds.ac.uk/10.3390/a14070216
Chicago/Turabian StyleMuaad, Abdullah Y., Hanumanthappa Jayappa, Mugahed A. Al-antari, and Sungyoung Lee. 2021. "ArCAR: A Novel Deep Learning Computer-Aided Recognition for Character-Level Arabic Text Representation and Recognition" Algorithms 14, no. 7: 216. https://0-doi-org.brum.beds.ac.uk/10.3390/a14070216