
Multi-Object Segmentation in Complex Urban Scenes from High-Resolution Remote Sensing Data

 ,
,  ,
, 
 and
and 
Abstract
:
1. Introduction
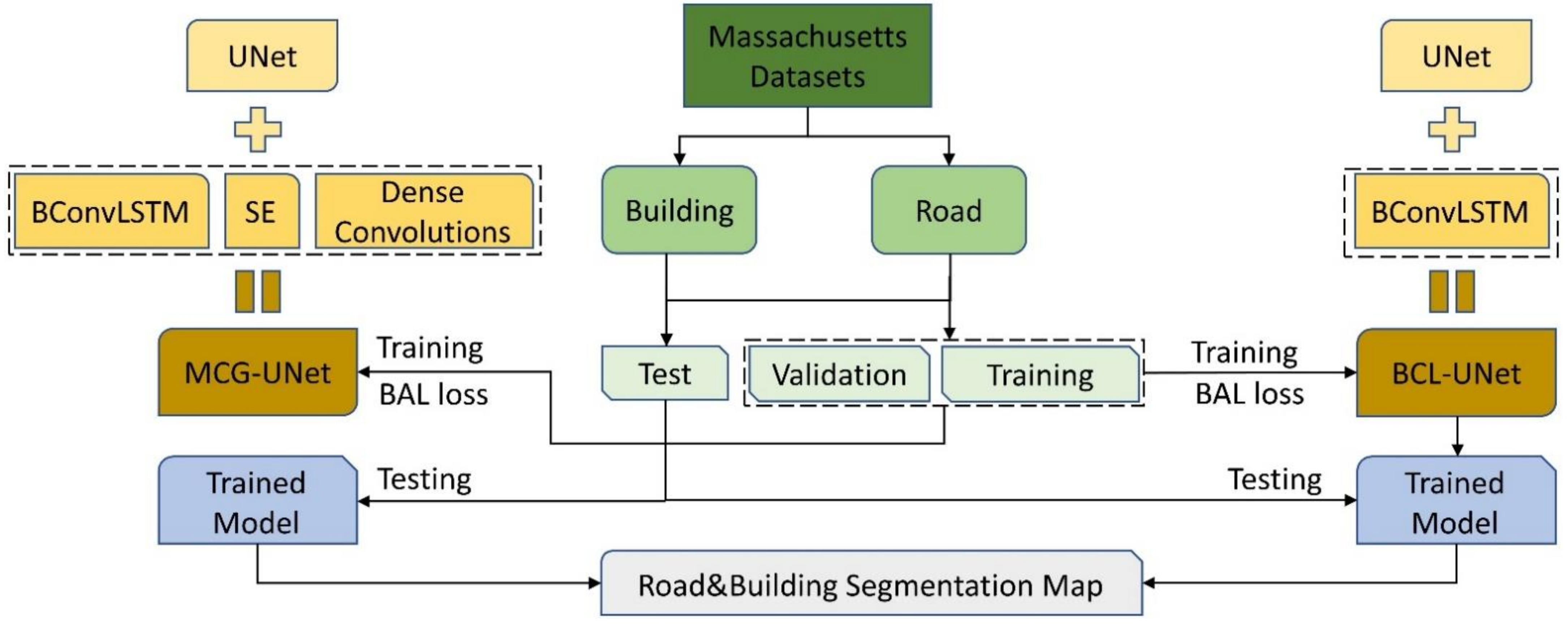
2. Methodology
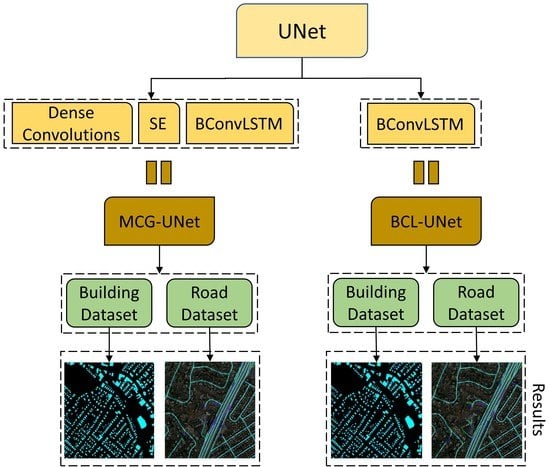
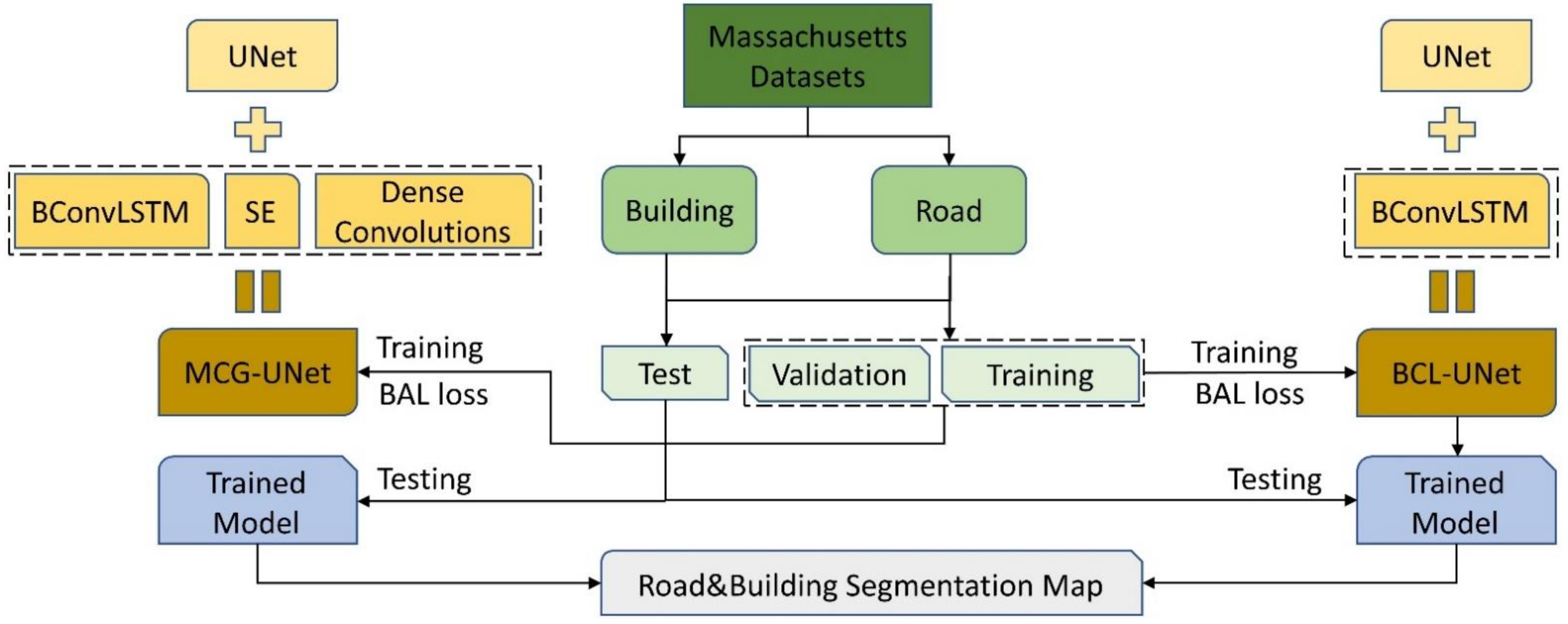
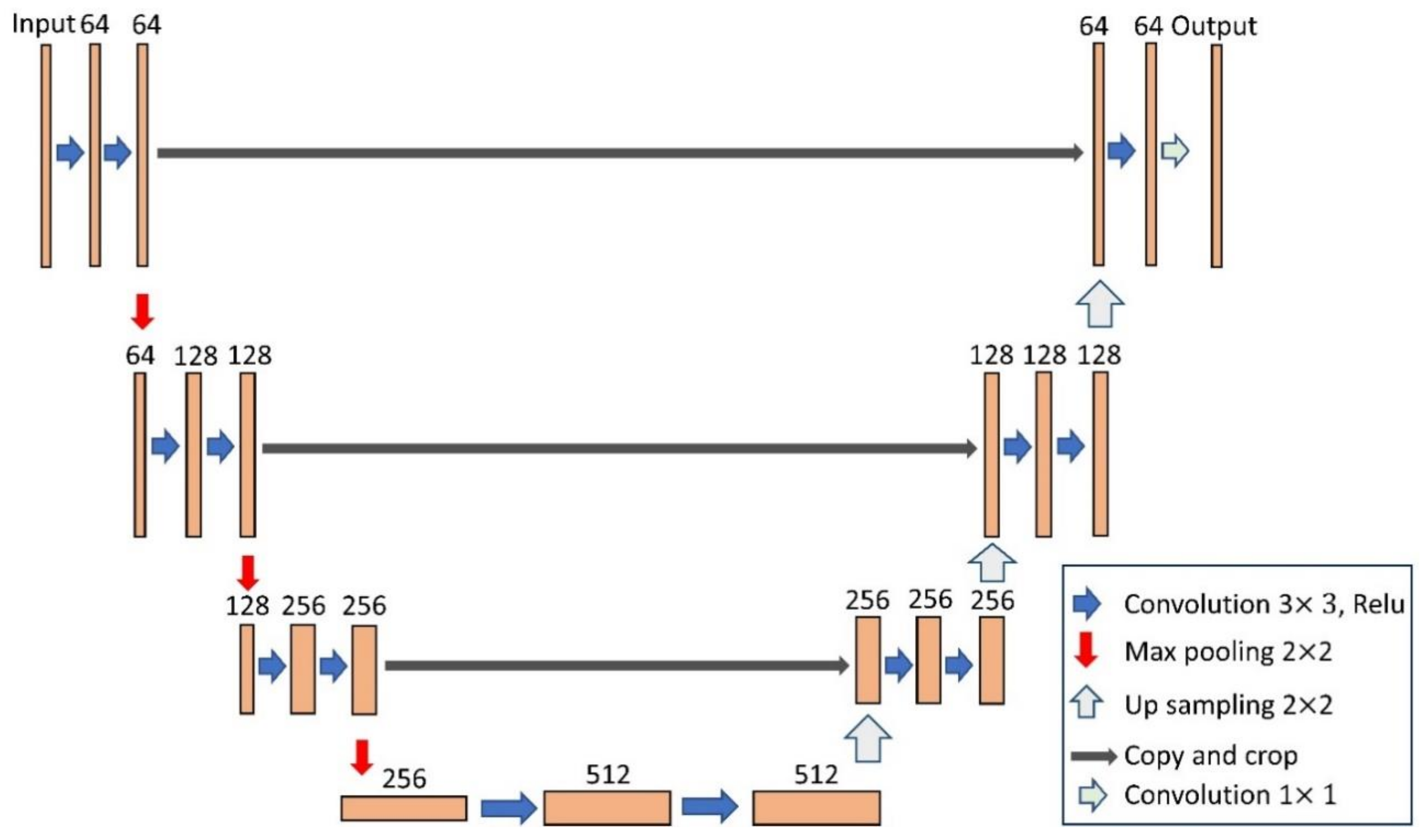
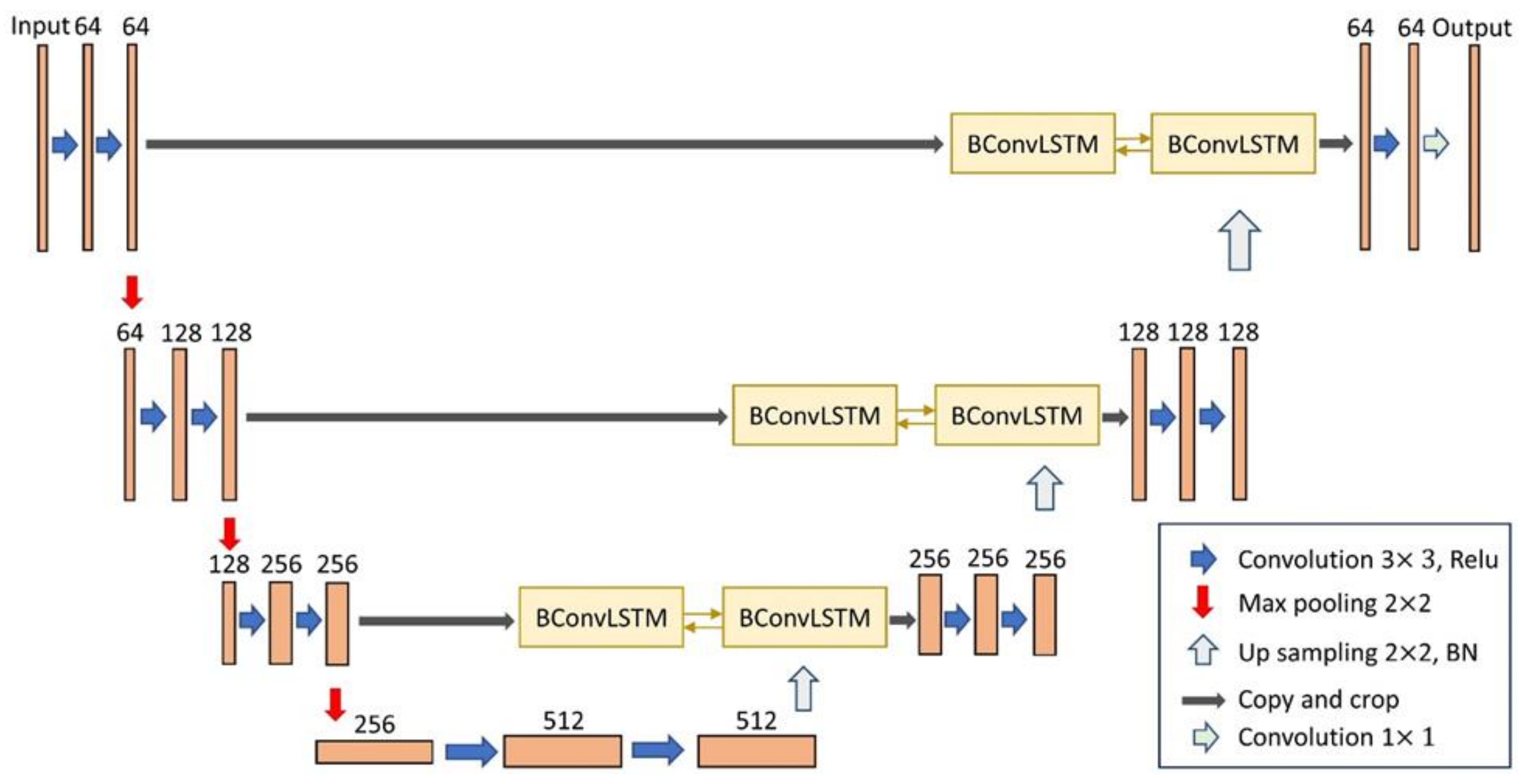
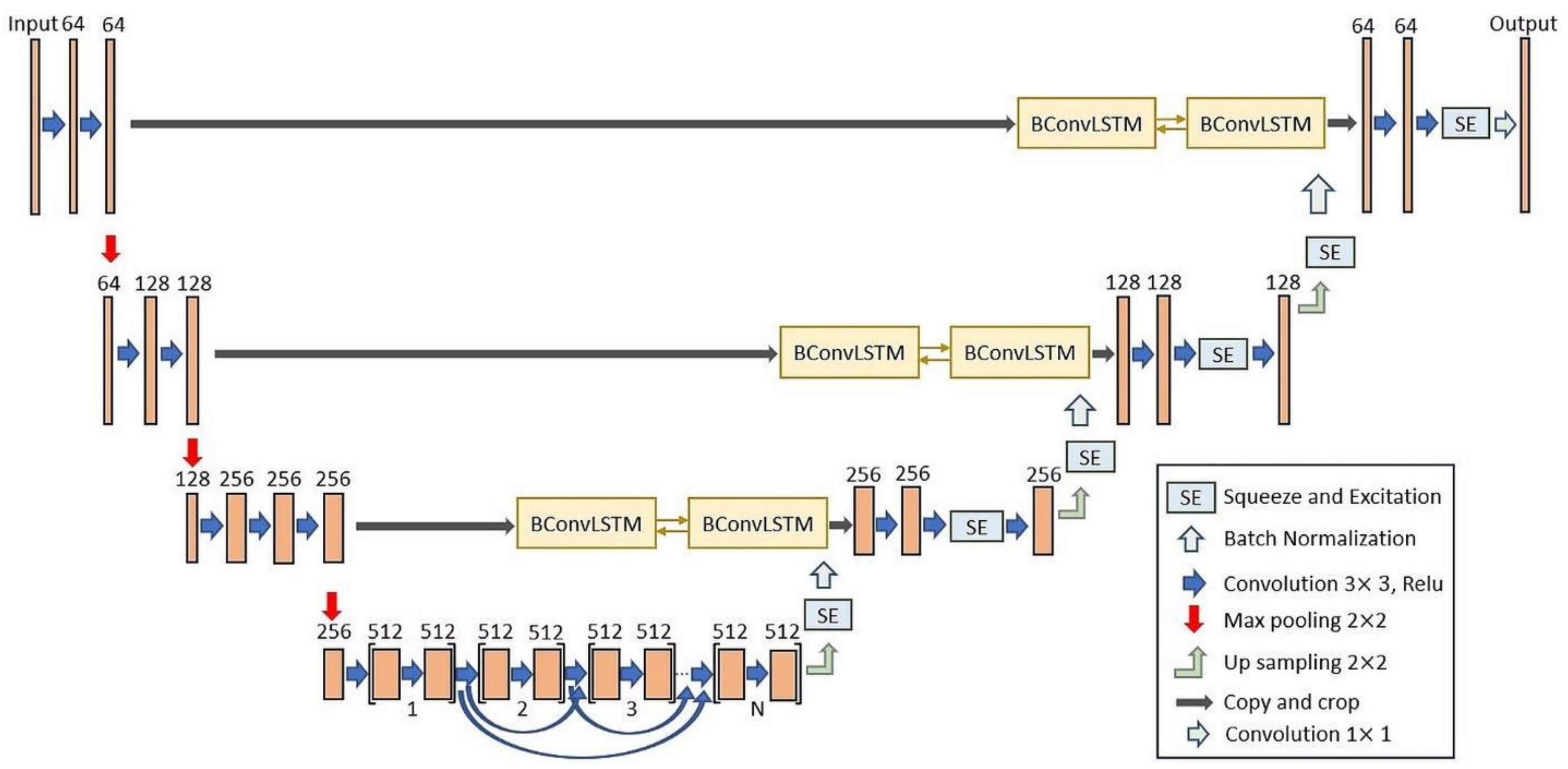
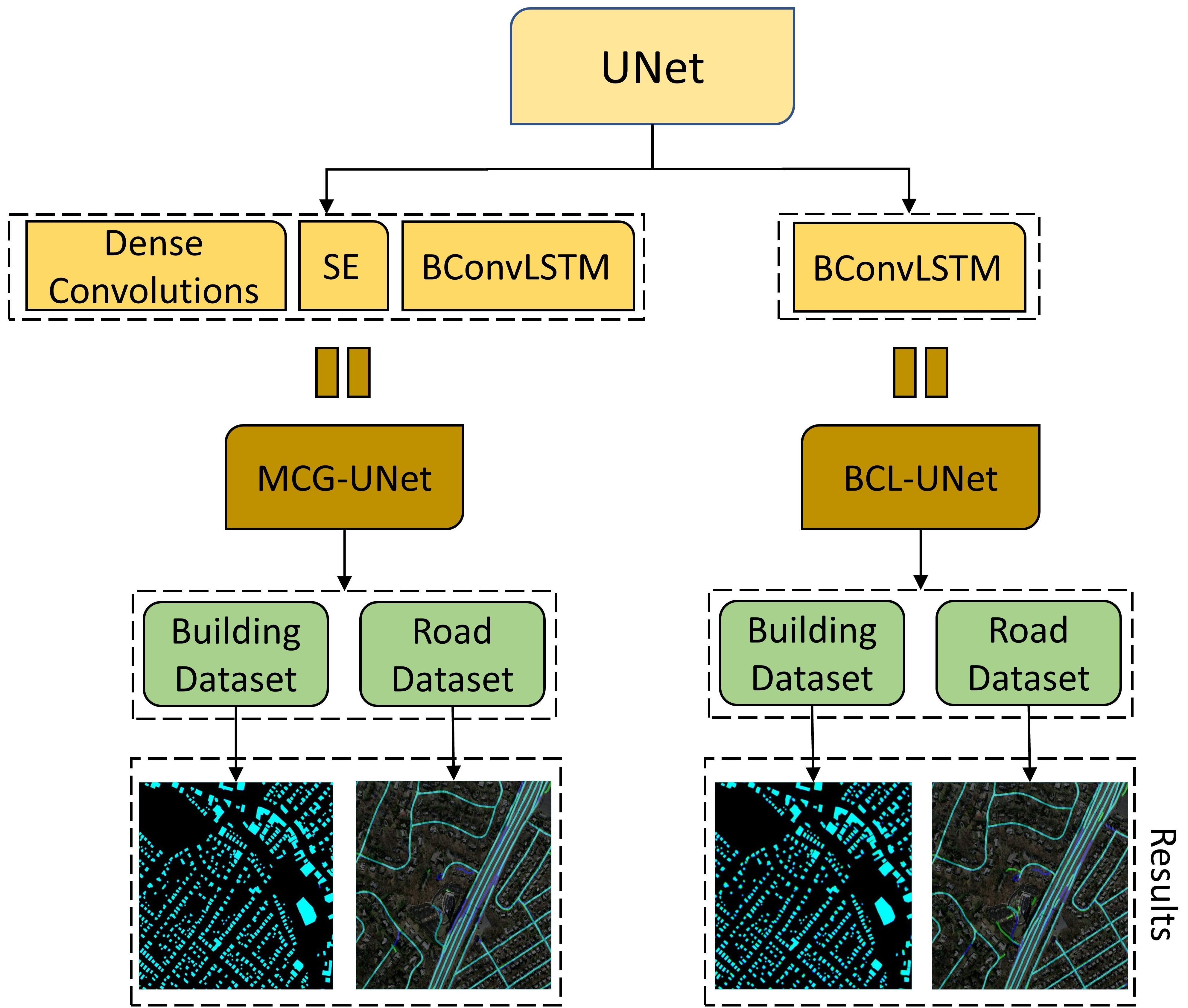
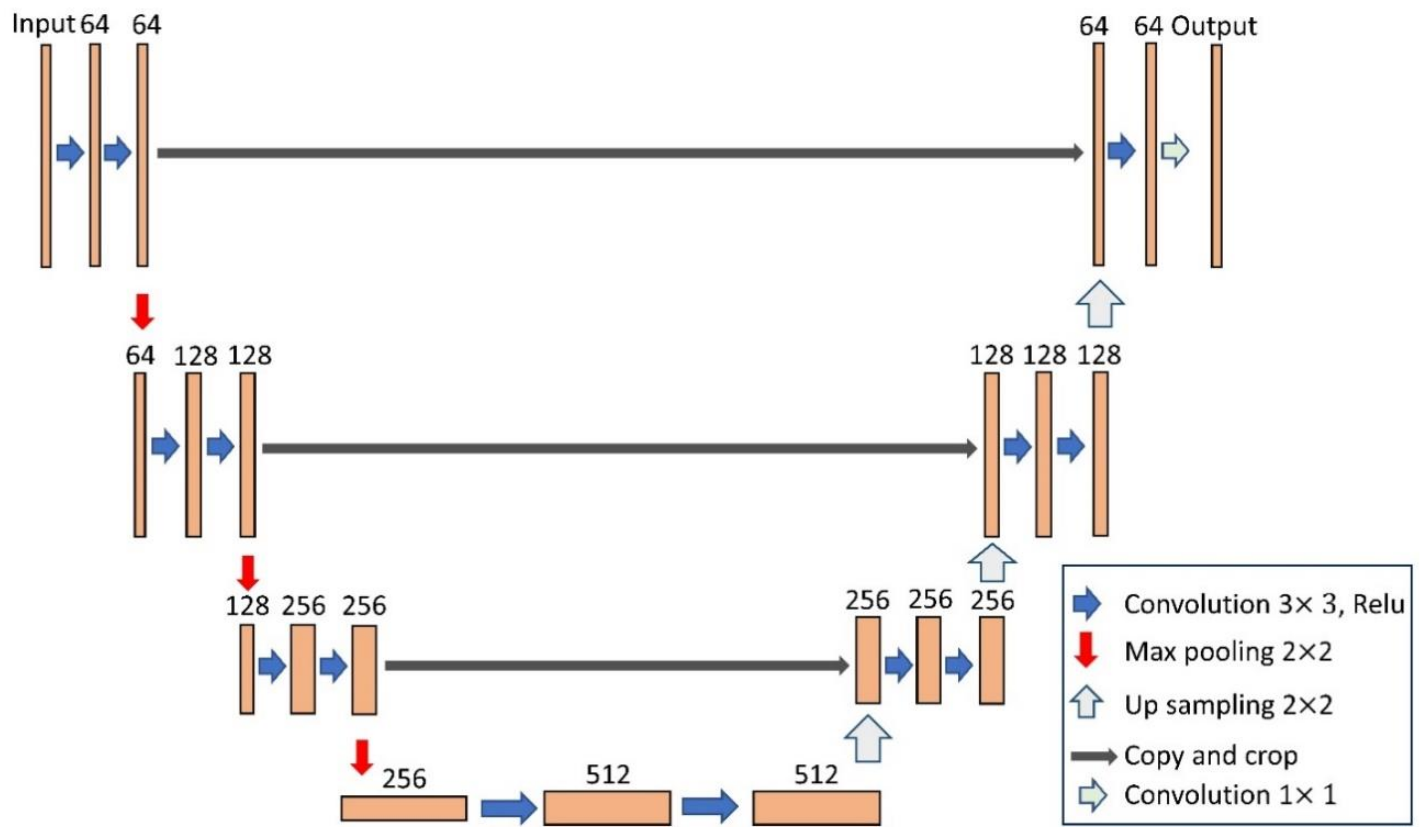
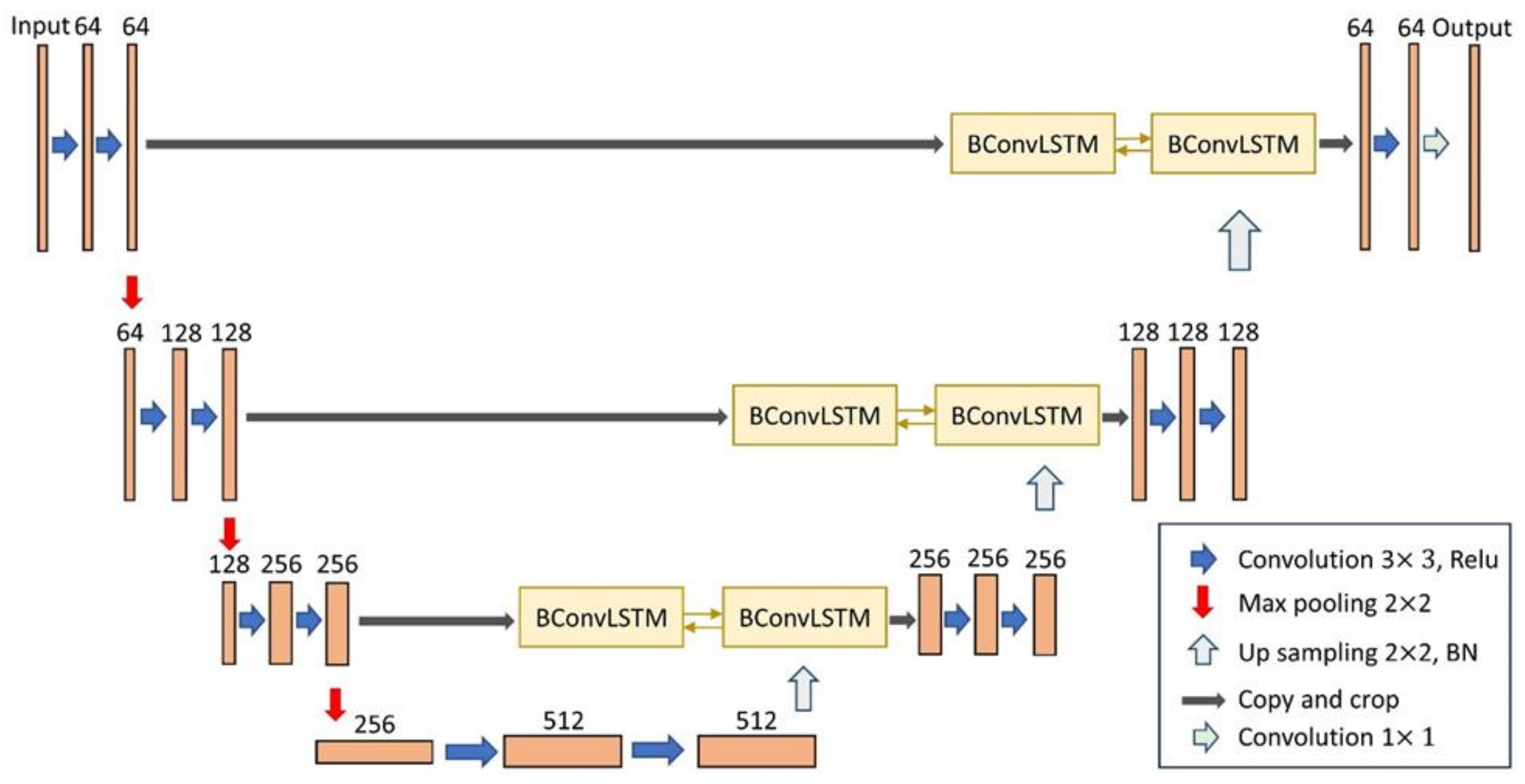
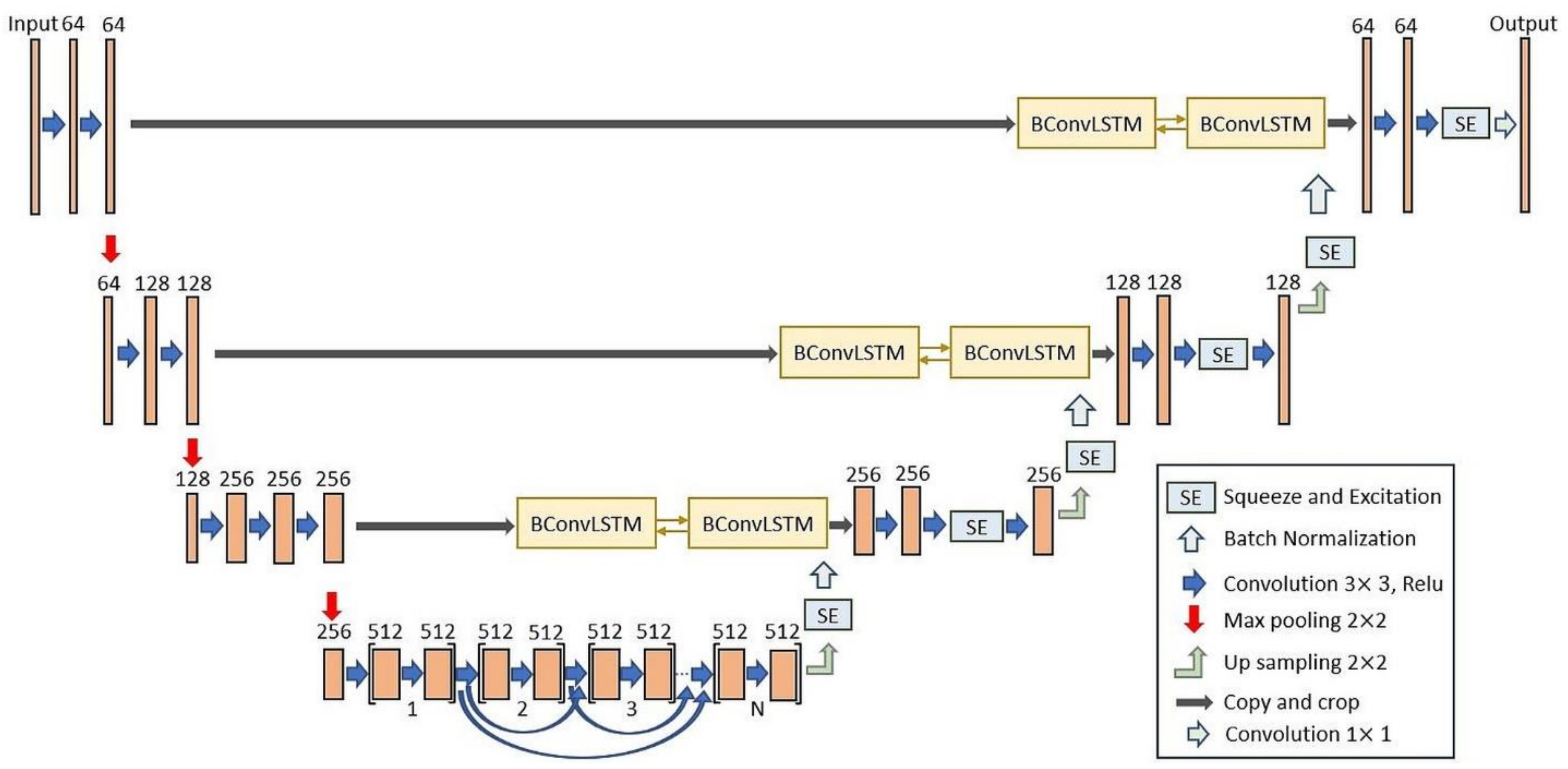
2.1. BCL-UNet and MCG-UNet Architectures
2.2. SE Function
2.3. BN Function
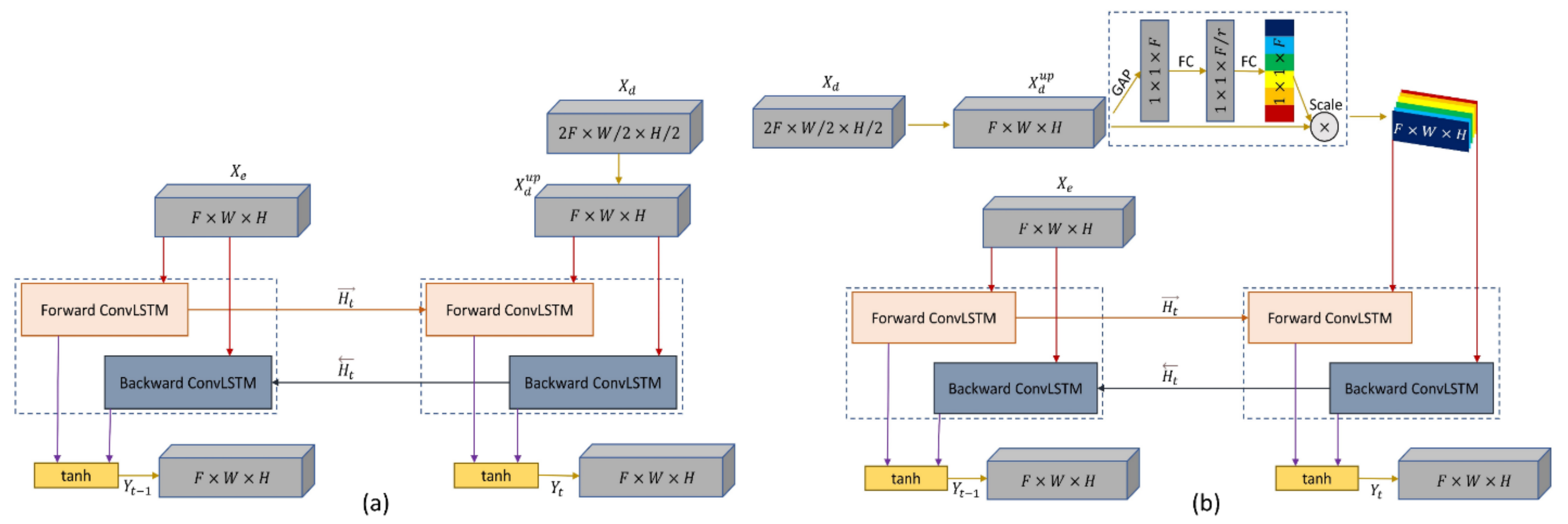
2.4. BConvLSTM Function
2.5. Boundary-Aware Loss
3. Experimental Results
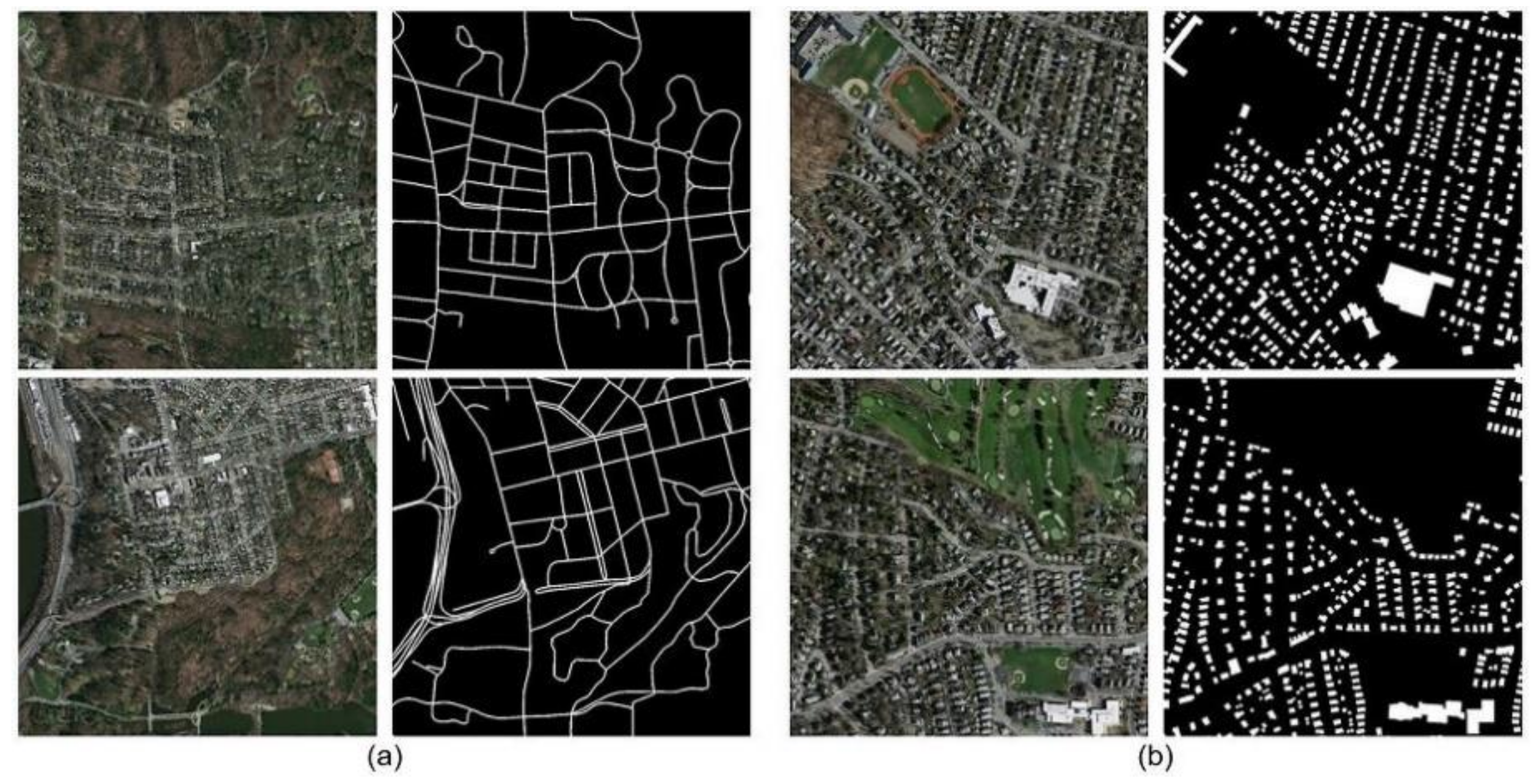
3.1. Road Dataset
3.2. Building Dataset
3.3. Performance Measurement Factors
3.4. Quantitative Results
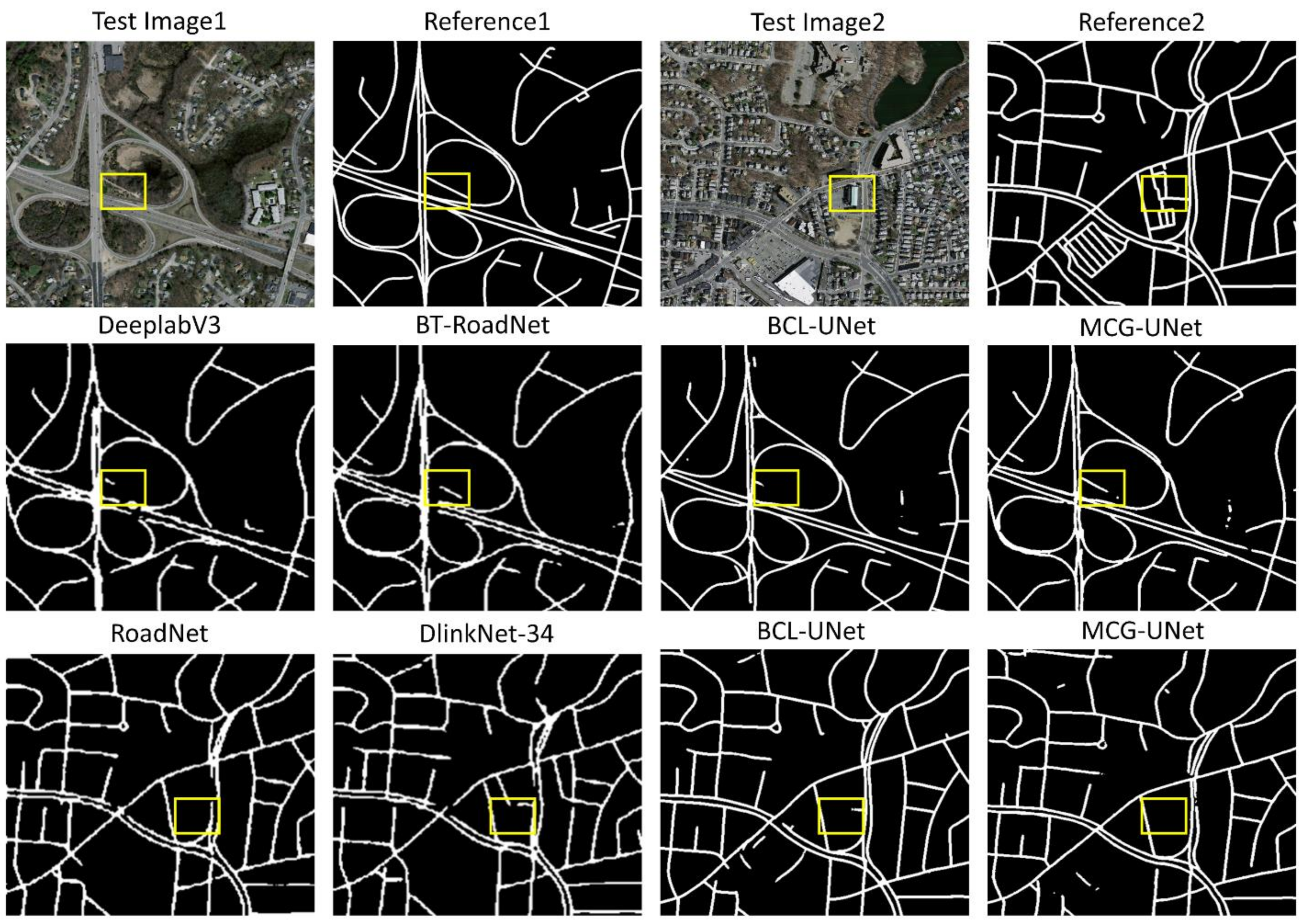
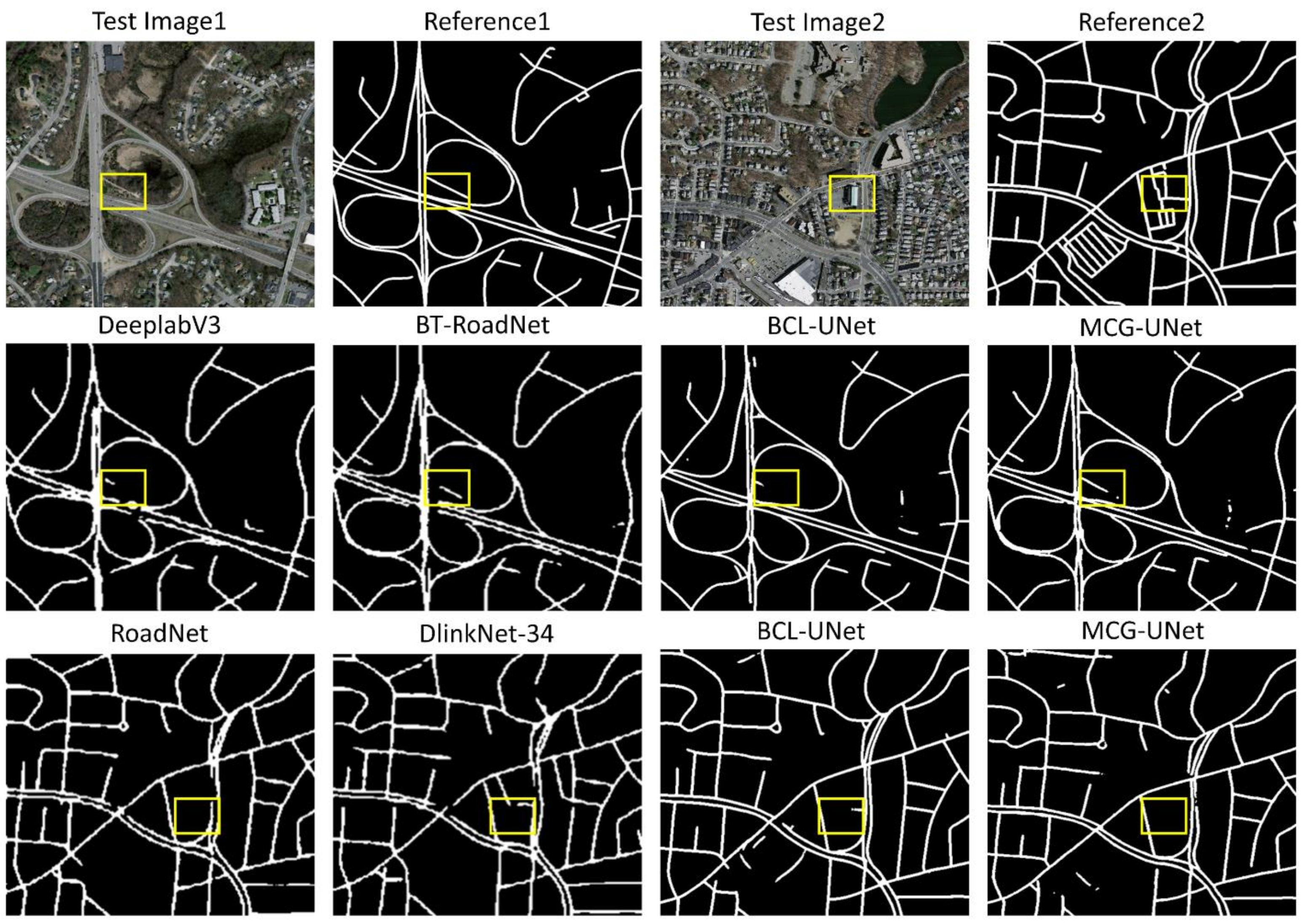
3.5. Qualitative Results
4. Discussion
Other Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. J. Electron. Imaging 2016, 2016, 1–9. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B. Integrated technique of segmentation and classification methods with connected components analysis for road extraction from orthophoto images. Expert Syst. Appl. 2021, 176, 114908. [Google Scholar] [CrossRef]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building Extraction Based on U-Net with an Attention Block and Multiple Losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Elmizadeh, H.; Hossein-Abad, H.M. Efficiency of Fuzzy Algorithms in Segmentation of Urban Areas with Applying HR-PR Panchromatic Images (Case Study of Qeshm City). J. Sustain. Urban Reg. Dev. Stud. 2021, 1, 35–47. [Google Scholar]
- Koutsoudis, A.; Ioannakis, G.; Pistofidis, P.; Arnaoutoglou, F.; Kazakis, N.; Pavlidis, G.; Chamzas, C.; Tsirliganis, N. Multispectral aerial imagery-based 3D digitisation, segmentation and annotation of large scale urban areas of significant cultural value. J. Cult. Herit. 2021, 49, 1–9. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.M. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Brust, C.-A.; Sickert, S.; Simon, M.; Rodner, E.; Denzler, J. Efficient convolutional patch networks for scene understanding. In Proceedings of the CVPR Scene Understanding Workshop, Boston, USA, 2015. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.-C.; Tang, X. Semantic image segmentation via deep parsing network. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1377–1385. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Hong, S.; Noh, H.; Han, B. Decoupled deep neural network for semi-supervised semantic segmentation. arXiv 2015, arXiv:1506.04924. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Abdollahi, A.; Pradhan, B.; Gite, S.; Alamri, A. Building Footprint Extraction from High Resolution Aerial Images Using Generative Adversarial Network (GAN) Architecture. IEEE Access 2020, 8, 209517–209527. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Aryal, J. Deep Learning-Based Semantic Segmentation of Urban Features in Satellite Images: A Review and Meta-Analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Alamri, A. RoadVecNet: A new approach for simultaneous road network segmentation and vectorization from aerial and google earth imagery in a complex urban set-up. GISci. Remote Sens. 2021, 1–24. [Google Scholar] [CrossRef]
- Paisitkriangkrai, S.; Sherrah, J.; Janney, P.; Hengel, V.-D. Effective semantic pixel labelling with convolutional networks and conditional random fields. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 36–43. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.-B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 17–30 June 2016; pp. 1–9. [Google Scholar]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Längkvist, M.; Kiselev, A.; Alirezaie, M.; Loutfi, A. Classification and segmentation of satellite orthoimagery using convolutional neural networks. Remote Sens. 2016, 8, 329. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Q.; Cao, L.; Cheng, M.; Wang, C.; Li, J. Deep neural networks-based vehicle detection in satellite images. In Proceedings of the 2015 International Symposium on Bioelectronics and Bioinformatics (ISBB), Beijing, China, 14–17 October 2015; pp. 184–187. [Google Scholar]
- Zhou, L.; Zhang, C.; Wu, M. D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar] [CrossRef]
- Buslaev, A.; Seferbekov, S.S.; Iglovikov, V.; Shvets, A. Fully Convolutional Network for Automatic Road Extraction from Satellite Imagery. In Proceedings of the CVPR Workshops, Salt Lake City, Utah, USA, 2018; pp. 207–210. [Google Scholar] [CrossRef] [Green Version]
- Constantin, A.; Ding, J.-J.; Lee, Y.-C. Accurate Road Detection from Satellite Images Using Modified U-net. In Proceedings of the 2018 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Chengdu, China, 26–30 October 2018; pp. 423–426. [Google Scholar] [CrossRef]
- Xu, Y.; Feng, Y.; Xie, Z.; Hu, A.; Zhang, X. A Research on Extracting Road Network from High Resolution Remote Sensing Imagery. In Proceedings of the 2018 26th International Conference on Geoinformatics, Kunming, China, 28–30 June 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Kestur, R.; Farooq, S.; Abdal, R.; Mehraj, E.; Narasipura, O.; Mudigere, M. UFCN: A fully convolutional neural network for road extraction in RGB imagery acquired by remote sensing from an unmanned aerial vehicle. J. Appl. Remote Sens. 2018, 12, 016020. [Google Scholar] [CrossRef]
- Varia, N.; Dokania, A.; Senthilnath, J. DeepExt: A Convolution Neural Network for Road Extraction using RGB images captured by UAV. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1890–1895. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Alamri, A. VNet: An End-to-End Fully Convolutional Neural Network for Road Extraction from High-Resolution Remote Sensing Data. IEEE Access 2020, 8, 179424–179436. [Google Scholar] [CrossRef]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A Dual-Attention Network for Road Extraction from High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Wang, S.; Mu, X.; Yang, D.; He, H.; Zhao, P. Road Extraction from Remote Sensing Images Using the Inner Convolution Integrated Encoder-Decoder Network and Directional Conditional Random Fields. Remote Sens 2021, 13, 465. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, S.; Vanneschi, L. Improved fully convolutional network with conditional random fields for building extraction. Remote Sens. 2018, 10, 1135. [Google Scholar] [CrossRef] [Green Version]
- Bittner, K.; Cui, S.; Reinartz, P. Building extraction from remote sensing data using fully convolutional networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.-ISPRS Arch. 2017, 42, 481–486. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Cheng, G.; Wang, H.; Li, H.; Shi, L.; Pan, C. Building extraction from multi-source remote sensing images via deep deconvolution neural networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1835–1838. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- Chen, Y.; Tang, L.; Yang, X.; Bilal, M.; Li, Q. Object-based multi-modal convolution neural networks for building extraction using panchromatic and multispectral imagery. Neurocomputing 2020, 386, 136–146. [Google Scholar] [CrossRef]
- Jiwani, A.; Ganguly, S.; Ding, C.; Zhou, N.; Chan, D.M. A Semantic Segmentation Network for Urban-Scale Building Footprint Extraction Using RGB Satellite Imagery. arXiv 2021, arXiv:2104.01263. [Google Scholar]
- Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Maltezos, E. Stacked autoencoders driven by semi-supervised learning for building extraction from near infrared remote sensing imagery. Remote Sens. 2021, 13, 371. [Google Scholar] [CrossRef]
- Deng, W.; Shi, Q.; Li, J. Attention-Gate-Based Encoder-Decoder Network for Automatical Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2611–2620. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, J.; Fan, Y.; Gao, H.; Shao, Y. An efficient building extraction method from high spatial resolution remote sensing images based on improved mask R-CNN. Sensors 2020, 20, 1465. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, H.; Wu, P.; Yao, X.; Wu, Y.; Wang, B.; Xu, Y. Building Extraction in Very High Resolution Imagery by Dense-Attention Networks. Remote Sens. 2018, 10, 1768. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 4700–4708. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Song, H.; Wang, W.; Zhao, S.; Shen, J.; Lam, K.-M. Pyramid dilated deeper convlstm for video salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 715–731. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image Computing and Computer-assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Van Opbroek, A.; Ikram, M.A.; Vernooij, M.W.; De Bruijne, M. Transfer learning improves supervised image segmentation across imaging protocols. IEEE Trans. Med. Imaging 2014, 34, 1018–1030. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Asadi-Aghbolaghi, M.; Azad, R.; Fathy, M.; Escalera, S. Multi-level Context Gating of Embedded Collective Knowledge for Medical Image Segmentation. arXiv 2020, arXiv:2003.05056. [Google Scholar]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2015; pp. 802–810. [Google Scholar]
- Wu, H.C.; Li, Y.; Chen, L.; Liu, X.; Li, P. Deep boundary--aware semantic image segmentation. Comput. Animat. Virtual Worlds 2021, e2023. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Abdollahi, A.; Pradhan, B. Urban Vegetation Mapping from Aerial Imagery Using Explainable AI (XAI). Sensors 2021, 21, 4738. [Google Scholar] [CrossRef] [PubMed]
- Abdollahi, A.; Pradhan, B.; Alamri, A.M. An Ensemble Architecture of Deep Convolutional Segnet and Unet Networks for Building Semantic Segmentation from High-resolution Aerial Images. Geocarto Int. 2020, 1–16. [Google Scholar] [CrossRef]
- Schütze, H.; Manning, C.D.; Raghavan, P. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008; Volume 39. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhou, M.; Sui, H.; Chen, S.; Wang, J.; Chen, X. BT-RoadNet: A boundary and topologically-aware neural network for road extraction from high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 168, 288–306. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xia, M.; Wang, X.; Liu, Y. Roadnet: Learning to comprehensively analyze road networks in complex urban scenes from high-resolution remotely sensed images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2043–2056. [Google Scholar] [CrossRef]
- Xin, J.; Zhang, X.; Zhang, Z.; Fang, W. Road Extraction of High-Resolution Remote Sensing Images Derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef] [Green Version]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A Fully Convolutional Neural Network for Automatic Building Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Iglovikov, V.; Seferbekov, S.S.; Buslaev, A.; Shvets, A. TernausNetV2: Fully Convolutional Network for Instance Segmentation. In Proceedings of the CVPR Workshops, Salt Lake City, UT, USA, 18–22 June 2018; Volume 237. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote. Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Wang, Y. JointNet: A common neural network for road and building extraction. Remote Sens. 2019, 11, 696. [Google Scholar] [CrossRef] [Green Version]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Chen, Q.; Wang, L.; Wu, Y.; Wu, G.; Guo, Z.; Waslander, S.L. Aerial imagery for roof segmentation: A large-scale dataset towards automatic mapping of buildings. ISPRS J. Photogramm. Remote Sens. 2018, 147, 42–55. [Google Scholar] [CrossRef] [Green Version]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), Saint Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | Number of Parameters | Number of Layers | Batch Size | Input Shape | Computer Configuration |
|---|---|---|---|---|---|
| UNet | 9,090,499 | 30 | 2 | 768 × 768 × 3 | A GPU: Nvidia Quadro RTX 6000 24 GB and a computation capacity of 7.5 Python: 3.6.10 TensorFlow: 1.14.0 |
| BCL-UNet | 13,580,995 | 42 | 2 | 768 × 768 × 3 | |
| MCG-UNet | 27,891,901 | 74 | 2 | 768 × 768 × 3 |
| Metrics | UNet | BCL-UNet | MCG-UNet | |
|---|---|---|---|---|
| Image1 | Recall | 0.8592 | 0.8604 | 0.8643 |
| Precision | 0.8757 | 0.8801 | 0.9051 | |
| F1 | 0.8674 | 0.8701 | 0.8842 | |
| MCC | 0.8431 | 0.8465 | 0.8637 | |
| IOU | 0.7657 | 0.7701 | 0.7924 | |
| Image2 | Recall | 0.8277 | 0.8374 | 0.8984 |
| Precision | 0.884 | 0.887 | 0.8984 | |
| F1 | 0.8549 | 0.8615 | 0.8984 | |
| MCC | 0.8283 | 0.8358 | 0.8797 | |
| IOU | 0.7466 | 0.7567 | 0.8156 | |
| Image3 | Recall | 0.857 | 0.8589 | 0.8672 |
| Precision | 0.9043 | 0.9165 | 0.9191 | |
| F1 | 0.88 | 0.8868 | 0.8924 | |
| MCC | 0.8546 | 0.8632 | 0.8699 | |
| IOU | 0.7857 | 0.7965 | 0.8057 | |
| Image4 | Recall | 0.7787 | 0.7831 | 0.7658 |
| Precision | 0.8874 | 0.8924 | 0.905 | |
| F1 | 0.8295 | 0.8342 | 0.8296 | |
| MCC | 0.7943 | 0.80 | 0.7969 | |
| IOU | 0.7086 | 0.7154 | 0.7088 | |
| Image5 | Recall | 0.9026 | 0.9097 | 0.9340 |
| Precision | 0.9233 | 0.9410 | 0.9312 | |
| F1 | 0.9128 | 0.9251 | 0.9326 | |
| MCC | 0.9034 | 0.9171 | 0.9251 | |
| IOU | 0.8396 | 0.8606 | 0.8736 | |
| Average | Recall | 0.8450 | 0.8499 | 0.8659 |
| Precision | 0.8949 | 0.9034 | 0.9118 | |
| F1 | 0.8689 | 0.8755 | 0.8874 | |
| MCC | 0.8447 | 0.8525 | 0.8670 | |
| IOU | 0.7692 | 0.7799 | 0.7992 |
| Metrics | UNet | BCL-UNet | MCG-UNet | |
|---|---|---|---|---|
| Image1 | Recall | 0.8802 | 0.8969 | 0.9441 |
| Precision | 0.9076 | 0.9214 | 0.9612 | |
| F1 | 0.8937 | 0.909 | 0.9526 | |
| MCC | 0.8649 | 0.8843 | 0.9398 | |
| IOU | 0.8078 | 0.8331 | 0.9094 | |
| Image2 | Recall | 0.8732 | 0.8921 | 0.9399 |
| Precision | 0.8834 | 0.8984 | 0.9554 | |
| F1 | 0.8783 | 0.8952 | 0.9476 | |
| MCC | 0.8506 | 0.8714 | 0.9357 | |
| IOU | 0.7829 | 0.8103 | 0.9003 | |
| Image3 | Recall | 0.8937 | 0.9122 | 0.938 |
| Precision | 0.8621 | 0.875 | 0.9558 | |
| F1 | 0.8776 | 0.8932 | 0.9468 | |
| MCC | 0.8596 | 0.8775 | 0.9392 | |
| IOU | 0.7819 | 0.807 | 0.8989 | |
| Image4 | Recall | 0.9190 | 0.9400 | 0.9494 |
| Precision | 0.8616 | 0.8758 | 0.9520 | |
| F1 | 0.8894 | 0.9067 | 0.9507 | |
| MCC | 0.8739 | 0.8939 | 0.9438 | |
| IOU | 0.8007 | 0.8294 | 0.9060 | |
| Image5 | Recall | 0.8418 | 0.8511 | 0.9261 |
| Precision | 0.9058 | 0.9223 | 0.9692 | |
| F1 | 0.8726 | 0.8853 | 0.9472 | |
| MCC | 0.8355 | 0.8496 | 0.9302 | |
| IOU | 0.7650 | 0.7942 | 0.8996 | |
| Average | Recall | 0.8816 | 0.8985 | 0.9395 |
| Precision | 0.8841 | 0.8986 | 0.9587 | |
| F1 | 0.8823 | 0.8979 | 0.9490 | |
| MCC | 0.8569 | 0.8753 | 0.9377 | |
| IOU | 0.7877 | 0.8148 | 0.9028 |
| Methods | Precision | Recall | IOU | F1 |
|---|---|---|---|---|
| DeeplabV3 | 74.16 | 71.82 | 57.60 | 72.97 |
| BT-RoadNet | 87.98 | 78.16 | 74.00 | 82.77 |
| DLinkNet-34 | 76.11 | 70.29 | 57.77 | 73.08 |
| RoadNet | 64.53 | 82.73 | 56.86 | 72.50 |
| GL-DenseUNet | 78.48 | 70.09 | 72.73 | 74.04 |
| BCL-UNet | 0.9034 | 0.8499 | 0.7799 | 87.55 |
| MCG-UNet | 0.9118 | 0.8659 | 0.7992 | 88.74 |
| Methods | Precision | Recall | IOU | F1 |
|---|---|---|---|---|
| BRRNet | - | - | 0.7446 | 84.56 |
| FCN-CRF | 95.07 | 93.40 | 89.08 | 93.93 |
| TernausNetV2 | 0.8596 | 0.8199 | 0.7234 | 83.92 |
| Res-U-Net | 0.8621 | 0.8026 | 0.7114 | 83.12 |
| JointNet | 0.8572 | 0.8120 | 0.7161 | 83.39 |
| BCL-UNet | 0.8986 | 0.8985 | 0.8148 | 89.79 |
| MCG-UNet | 0.9587 | 0.9395 | 0.9028 | 94.90 |
| Methods | Recall | Precision | F1 | MCC | IOU | |
|---|---|---|---|---|---|---|
| ISPRS Building Dataset | Res-U-Net | 0.9197 | 0.9399 | 0.9296 | 0.8999 | 0.8688 |
| JointNet | 0.8982 | 0.9726 | 0.9338 | 0.9084 | 0.8760 | |
| BCL-UNet | 0.9318 | 0.9391 | 0.9353 | 0.9118 | 0.8862 | |
| MCG-UNet | 0.9017 | 0.9891 | 0.9434 | 0.9224 | 0.8928 | |
| DeepGlobe Road Dataset | DeeplabV3 | 0.8115 | 0.8750 | 0.8411 | 0.8139 | 0.7258 |
| LinkNet | 0.8852 | 0.8238 | 0.8486 | 0.8199 | 0.7369 | |
| BCL-UNet | 0.8408 | 0.9047 | 0.8703 | 0.8482 | 0.7705 | |
| MCG-UNet | 0.8597 | 0.9044 | 0.8809 | 0.8595 | 0.7870 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Multi-Object Segmentation in Complex Urban Scenes from High-Resolution Remote Sensing Data. Remote Sens. 2021, 13, 3710. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13183710
Abdollahi A, Pradhan B, Shukla N, Chakraborty S, Alamri A. Multi-Object Segmentation in Complex Urban Scenes from High-Resolution Remote Sensing Data. Remote Sensing. 2021; 13(18):3710. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13183710
Chicago/Turabian StyleAbdollahi, Abolfazl, Biswajeet Pradhan, Nagesh Shukla, Subrata Chakraborty, and Abdullah Alamri. 2021. "Multi-Object Segmentation in Complex Urban Scenes from High-Resolution Remote Sensing Data" Remote Sensing 13, no. 18: 3710. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13183710