1. Introduction
The advancement of hyperspectral remote sensing leads to its widespread use in scanning continuous, narrow spectral bands, as it enables the acquisition of information on the reflection or radiation spectrum of objects at various wavelengths [
1,
2,
3]. Digital number (DN) or reflectance value is considered as the feature value for each band and represented as a feature vector. However, there is a large amount of redundant information collected through hyperspectral imaging (HSI) with the electromagnetic spectrum and visible light infrared technology, resulting in high dimensionality [
4]. In essence, data dimensionality reduction helps to trim the redundancy and noise [
5] and improves classification accuracy, which has become an important topic in the processing of HSI datasets.
Generally, there are two methods for removing the redundancy of the dataset: feature extraction and feature selection. Feature extraction involves the linear or nonlinear transformation of the original high-dimensional features, such as combining different features into a new feature set [
6], where the features lose their original physical meaning. Feature selection involves selecting the most representative feature combination from the dataset; it detects representative features and decreases redundant information or noise from data, which improves classification accuracy and enhances comprehensibility [
7]. Due to the difficulty in interpreting selected features from feature extraction, feature selection is widely used in the processing of HSI datasets.
There are three feature selection strategies based on the search rule, namely, filter, wrapper, and embedded [
8]. The filtering strategy analyzes each feature using a proxy measure [
9] and selects a combination with a specified number of features based on the score ranking. However, the score only reflects the correlation with labels, ignoring the feature interactivity that some feature with a low correlation to labels provides greater performance improvement than those with a high correlation to labels. The wrapper strategy combines the process of feature selection with the agent to identify an appropriate combination of features. However, this strategy requires a continuous measure of the feature combination, resulting in high computational complexity and inadequate generalization ability [
10]. The embedded strategy selects features in the learning process [
11,
12], and incorporates the feature selection in training, avoiding the overfitting that may occur in other strategies by adjusting the weights of features. The embedded strategy is usually combined with some iterative searching; the weight is used to guide the next iteration.
Evolutionary algorithm (EA), which mimics the adaptation and survival of the fittest observed in living organisms in nature, uses the searched heuristic information as the guidance; the genetic material of these combinations is then assembled to create new offspring, and the process is repeated over many generations to allow the population evolves towards better solutions [
13]. Traditional EAs update the genetic material through mutation and crossover operations, which are then passed to the next generation. However, those algorithms only consider the stochasticity between agents, but not the similarity between them, which will lead to the occurrence of premature convergence and overfitting phenomena [
14,
15]. To address these limitations, distance-based EAs have been proposed; these algorithms are designed to calculate the distance between agents to determine their similarity and select some of them for crossover and mutation based on the similarity [
16,
17,
18,
19,
20], thereby helping to maintain diversity in the population and prevent premature convergence. Nonetheless, due to the absence of competition or collaboration, the information interaction between agents is insufficient, making it difficult for the EA to overcome local optima and leading to stagnation in the iterative process.
The co-evolution mechanism is a means of enhancing information interaction ability. Due to its robustness, this mechanism has received extensive attention and has been widely used in various fields, including natural language processing and image retrieval [
21,
22]. By combining EA, the co-evolution mechanism improves the search efficiency of the EA in feature selection to some extent [
23,
24,
25]. It divides the original feature set into many subsets; subpopulations are formed based on the agents generated by these subsets, then this mechanism enhances the diversity by information interacting between the agents in different subpopulations. However, the current information interaction only takes into account exchanging the solution encoding with weak representation, leading to the low diversity of agents and the subpopulation imbalance where some agents obtain better combinations after searching than others most of the time. Therefore, a co-evolution mechanism with prominent reliability is necessary to be further searched to fully realize its potential.
In this paper, a feature selection method based on discarding–recovering and co-evolution mechanisms is proposed to obtain a reduced feature combination of the HSI datasets with adequate accuracy. The feature discarding mechanism is introduced to filter out redundant features from the original dataset. Moreover, the co-evolution mechanism is combined with EA to enhance the diversity of agents, and a reliable information interaction is used to enable collaborative search between agents and help EA to jump out of the local optima. To avoid the erroneous discarding of the interactive features that have a low correlation with labels and improve the generalization ability, feature recovery is introduced to raise the probability of discarded features. The purpose of this work is that propose a feature selection method to select an effective feature combination and decrease the redundant information in HSI datasets. The co-evolution mechanism is utilized to promote the subpopulations of EA consistently. Moreover, the feature discarding and recovering mechanisms are used to avoid meaningless searching and enhance the generalization ability. The main contributions of this work are listed as follows:
- (1)
The discarding–recovering mechanism is designed to enhance the generalization ability and decrease the computational load, which filters the original feature space and recovers some features into the population.
- (2)
The co-evolution mechanism is combined with EA, which divides two subpopulations to co-evolve and utilizes reliable information interaction to enhance the diversity of agents in subpopulations.
- (3)
A feature selection method based on discarding–recovering and co-evolution mechanisms is proposed to obtain an effective feature combination, which has a prominent performance in HSI datasets.
The rest of this paper is structured as follows:
Section 2 provides the background information;
Section 3 details the proposed feature selection method;
Section 4 presents the experimental results from different perspectives;
Section 5 exhibits the discussion of the proposed method and
Section 6 outlines the conclusions.
2. Related Work
2.1. The Feature Selection Method Based on Distance-Based EA
The feature selection method based on distance-based EA has received much attention for its effectiveness in data dimensionality reduction, as it iteratively uses heuristic information to guide the next iteration. Wu et al. [
26] developed the particle swarm optimizer (PSO) to reduce the dimensionality of the HSI dataset, where the chaotic sequence was used to initialize the feature space, helping PSO jump out of local optima. Su et al. [
27] proposed a novel feature selection method based on the improved firefly algorithm (FA), which largely outperformed the conventional covariance method. Xie et al. [
28] proposed a comprehensive feature selection method based on the artificial bee colony algorithm (ABC) and subspace division, achieving prominent overall classification accuracy (OA) while reducing a small amount of redundant information. Wang et al. [
29] presented an optimized feature selection method based on the grey wolf optimizer (GWO) in the HSI dataset, which uses the adaptive weight to regulate the balance between optimal individuals and chaos operation to set correlative parameters. Tschannerl et al. [
30] proposed an unsupervised feature selection method based on information theory and a modified discrete gravitational search algorithm (GSA), obtaining a more informative subset of features. However, with the increase of the data dimensionality, the ability of EA for further dimensionality reduction gradually decreases since the monotonous agents, leading to the selected feature combination, are redundant to some extent, and distinguishing between the approximate labels is difficult.
2.2. The Co-Evolution Mechanism of Feature Selection
The co-evolution mechanism uses the “divide and conquer” approach to divide the population, identify the current optimal subsets in the feature space, and eventually join them together into a global subset. Song et al. [
31] proposed an adaptive subpopulation size adjustment mechanism based on co-evolution and a feature importance-oriented spatial partition strategy, decreasing the calculating time of particle evaluation and providing a competitive solution for the feature selection of high-dimensional data. Zhao et al. [
32] proposed a multiple populations co-evolution mechanism and multi-stage interaction learning (OL) mechanism to fully search the prospective features in the stagnant state and increase the possibility of jumping out of local optima. Zhou et al. [
33] proposed a feature selection method based on a cooperative co-evolution mechanism (CC-DFS). This method used a heterogeneous model to search for feature combinations with cut-off points and feature combinations without cut-off points, resulting in improved performance and generalization ability. Rashid et al. [
34] proposed a feature selection method based on a cooperative co-evolution mechanism and random feature grouping (CC-RFG). Three ways were introduced to decompose the feature set dynamically to ensure the interactive features were divided into the same subpopulation. However, the above co-evolution mechanisms for feature selection only exchange the feature combination with weak representation, leading to the difficulty of regulating those features.
2.3. Motivation
To tackle the problem of the EA in data dimensionality reduction caused by the large feature space and redundant information, the preliminary filtering of the original feature set is required, which helps to decrease the redundancy information of the dataset. To further enhance the performance and effectiveness of EA, it is important to speed up the search process, increase the diversity of agents, and facilitate effective information interaction to improve the quality of the selected features.
Regarding the co-evolution mechanism, when agents from different subpopulations interact, they exchange information that is likely to improve the OA or decrease the number of selected features searched by agents. However, if weak features are not considered, it will lead to an imbalance problem. To overcome these limitations, increasing the probability of selecting the weak features and promoting diverse information interaction between agents is necessary. By this, the co-evolution mechanism achieves a balanced and effective optimization process, leading to a prominent result in HSI datasets.
In all, to improve search efficiency, it is necessary to remove the redundant features in the original feature set while recovering some of these features when detecting update stagnation. Additionally, the co-evolution mechanism is introduced to enhance the diversity of agents in corresponding subpopulations, given that interaction with diverse information is required to maintain the balance between subpopulations. All these measures help improve the performance and stability of agents in feature selection, making them more effective for real-world applications.
3. The Proposed Method
There is a certain of redundant information in the HSI dataset, and the performance in the reduction of data dimensionality has room to improve for EA. As a result, the feature discarding mechanism is implemented that uses some measure criteria to roughly filter the feature space, and the co-evolution mechanism is utilized to divide the population and take the reliable information interaction between agents to enhance the generalization ability. During the iteration process, if a stagnation phenomenon is detected, it is likely caused by the previous erroneous discarding of the interactive features, so the feature recovering mechanism is detonated to increase the selected probability of weak features by adaptive weights, and some of them will be recovered into the subpopulations.
3.1. The Feature Discarding Mechanism
Given the high degree of redundant features in the original dataset, removing it on a large scale is necessary. This eliminates the need for a thorough analysis of each feature and allows for a fast return of selected features. The evaluation measure for each feature is defined as follows:
where
,
, and
the
indicates that
feature is discarded. Note that
is the kernel function mapped to a high-dimensional space, and
represents the optimized parameters obtained from the SVM-based classifier [
35].
The feature discarding mechanism, which is based on forward filtering and reverse learning, is implemented to obtain the ranking of feature scores using Equations (1) and (2), drops the specified number of features, and recovers groups of features with low score ranking through reverse learning [
36]. In addition, to improve the generalization ability, the feature discarding mechanism calculates the compromise value of recovery groups [
37]. The mathematical model is defined as follows:
where
and
denote the utility measure and the regret measure between
features, respectively,
is the weight vector,
is the maximum value of
feature of the decision matrix,
is the minimum value of
feature of the decision matrix.
and
are the maximum value of
, respectively.
,
are the minimum value of
, respectively.
represents the compromise value for each sample. The feature discarding mechanism obtains the compromise value of feature groups using Equations (3) and (4); the smallest one is selected as the original feature set.
3.2. The EA-Based Co-Evolution Mechanism
After feature discarding, the original feature set still has a high degree of redundant features, necessitating further decrease. The EA-based co-evolution mechanism can effectively search for the remaining features. Specifically, it divides the population into many subpopulations and uses information interaction to achieve a balance between them.
3.2.1. The Population Division Based on Feature Correlation
Generally, the population division involves partitioning the original feature set into multiple clusters (i.e., feature subsets) and initializing the agents generated in subpopulations based on these clusters. In addition, agents only search for features within their corresponding subsets while obtaining the rest via information interaction. Ideally, the population division considers the correlation between features or between features and labels commonly to minimize the correlation between features and maximize the correlation between features and labels [
38]. However, when interactive features are partitioned into different subsets, subpopulations may fall into local traps that are not the local optimum of the original feature set and rather the local optimum resulting from the incorrect division. Therefore, the population division should ensure the feature subsets corresponding to subpopulations are sufficiently different, and the interactive features are partitioned together as much as possible, with the correlation between features considered.
Furthermore, generating many subsets requires an equal number of subpopulations to match them, leading to a large computation load. Additionally, interactive features may be divided into different subsets, resulting in mature convergence. To minimize the redundant features of the entire dataset, the population division decomposes the original feature set into two subsets, generating agents to form subpopulations within them.
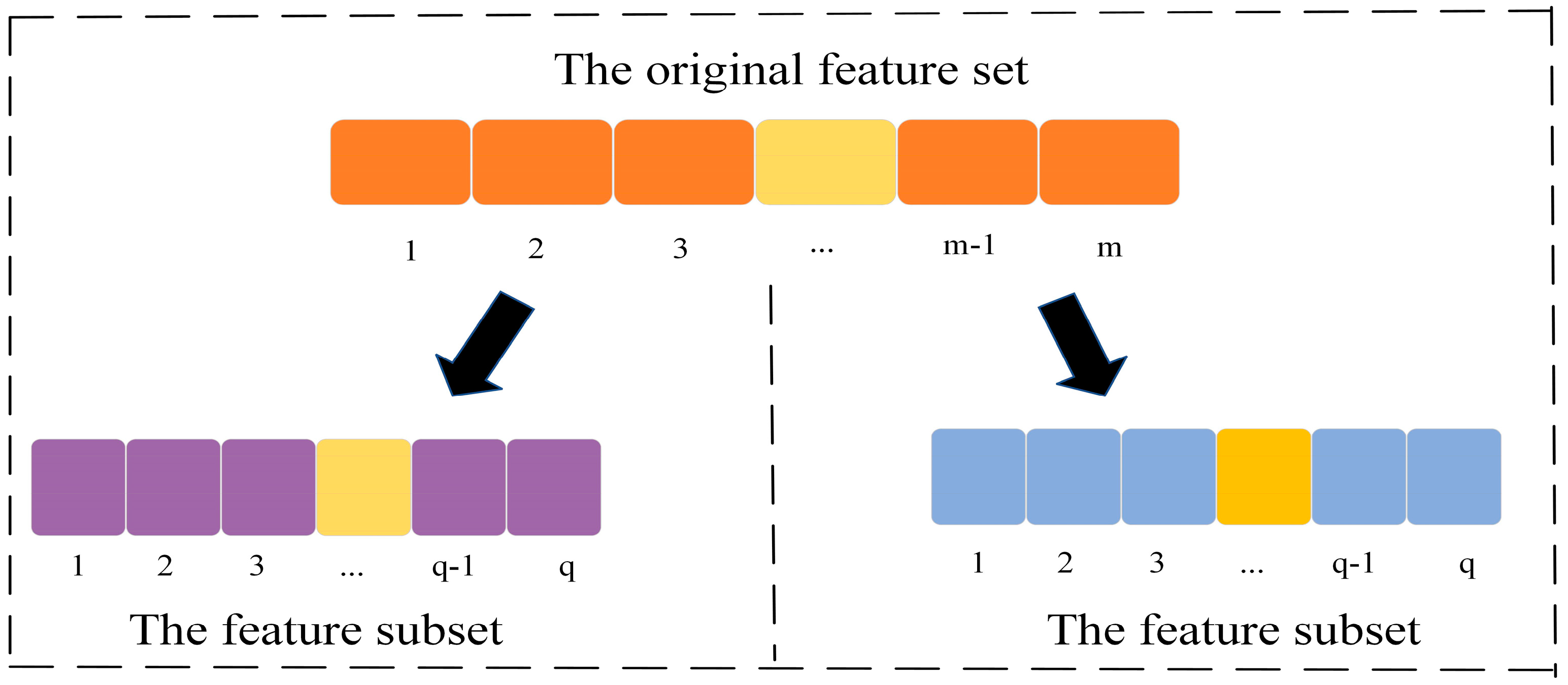
Figure 1 shows an example of the population division. The original feature set is partitioned according to the correlation between features, assuming that it has m features waiting for selection, two subsets are formed after the population division, and the number of features is
To maintain subpopulations’ balance,
is equal to
, the
is the integer-value function.
3.2.2. The Reliable Information Interaction
The agents in different subpopulations are designed to exchange the information in parallel to facilitate interaction. If a feature does not belong to the current feature subset, it is searched with a probability of 0. Moreover, subpopulations should be provided with representative information to keep balance. Features with unsatisfactory scores may be the result of not finding other interactive features [
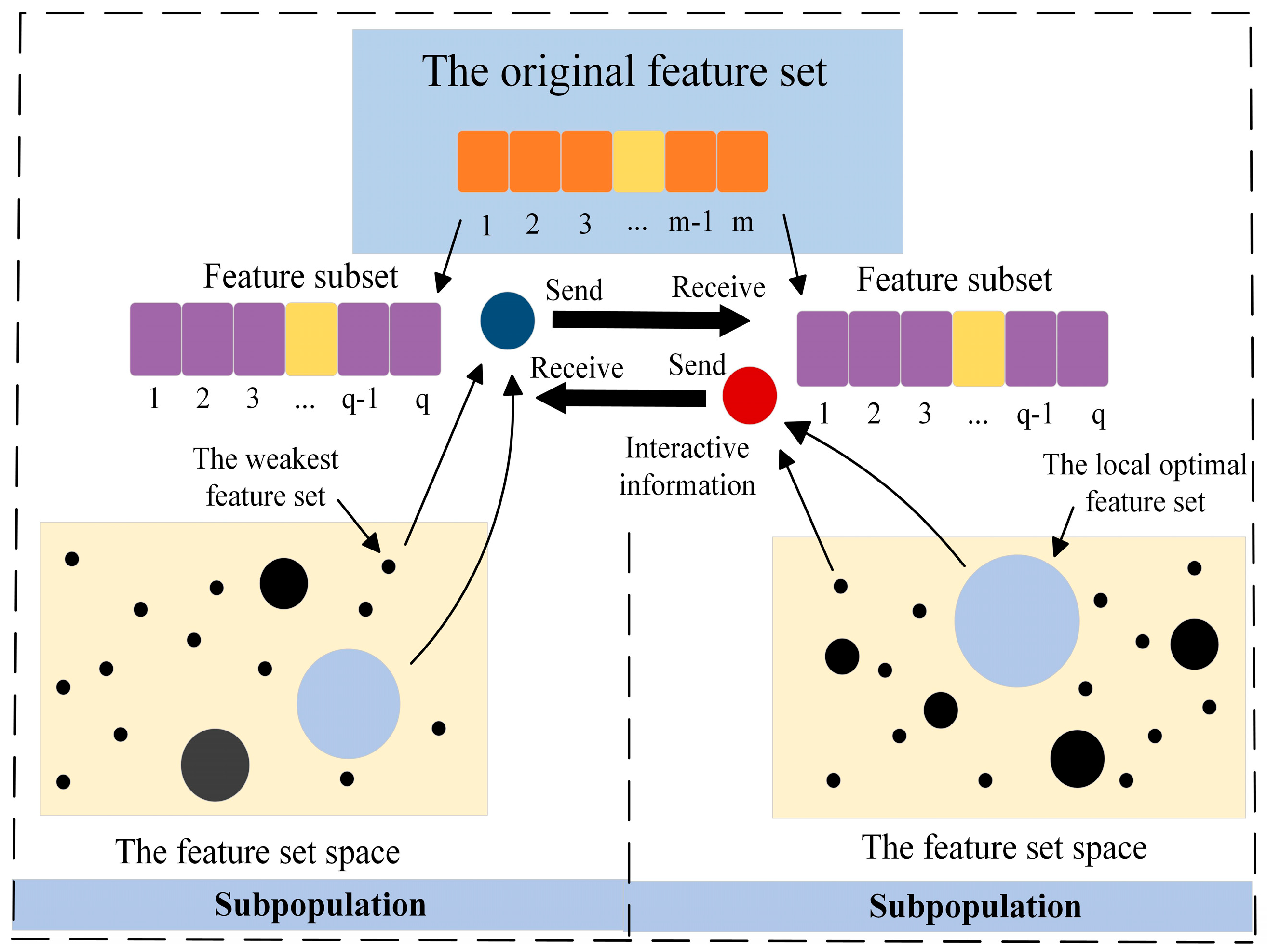
39]. With the representative information, the features’ performance will be boosted. The representative information is defined as the best and worst combinations searched by agents in the corresponding subpopulation, and one of them is selected as the interaction object to enhance the reliability of the co-evolution mechanism.
Figure 2 illustrates the reliable information interaction between subpopulations. It can be seen that during the interaction, each subpopulation receives representative information from the other. The agent then combines this information to make an overall evaluation after conducting a search. By following this process, features will be fully searched to obtain a prominent classification accuracy through the support vector machine (SVM)-based classifier on the testing set.
In subpopulations, the position of the next iteration of agents (
) is updated based on the distance (
) between the current agent’s position (
) and the optimal position. Here, the positions of the current agents are updated based on the optimal agent obtained using Equation (5).
where
refers to the distance between the current agent and the global optimum, while
denotes the social status of the optimum with a random value selected from the range of [−1, 1].
3.3. The Feature Recovering Mechanism
After the feature discarding, only the features with high ranking are selected, but the interactive features are not considered, which may lead to stagnation [
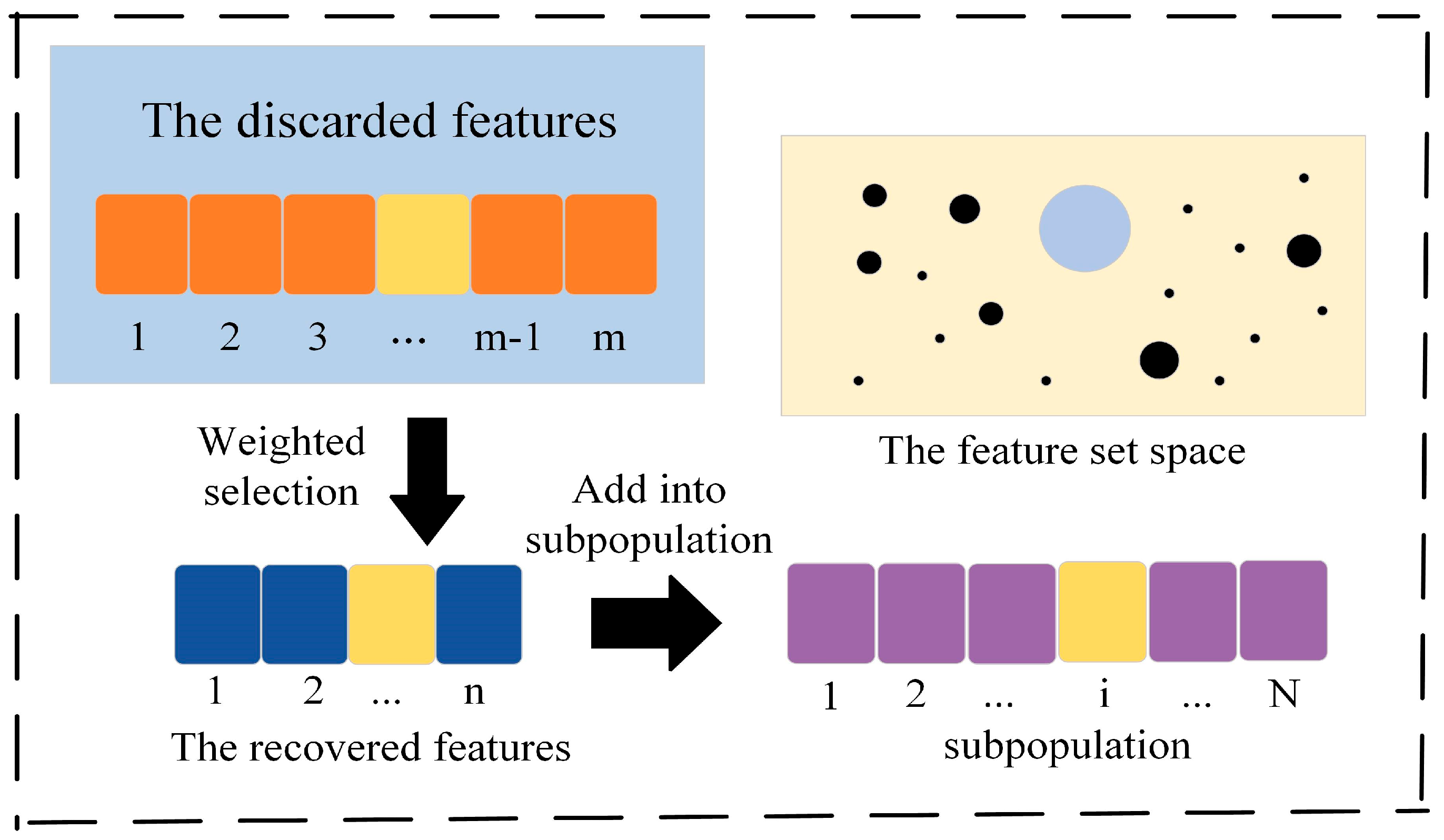
40]. Consequently, the performance of feature subsets searched by agents may fall into local optima. Moreover, EA generally operates within the original feature set, and it is difficult to recycle the discarded features. To address these limitations, the feature recovering mechanism is applied to incorporate the recycled discarded features into the recovery subset, thereby increasing the probability of selection. The feature recovery mechanism has two stages. The first stage is reverse learning, which increases the probability of selecting features with low score ranking. Moreover, if training stagnation is detected, indicating that the subpopulation is not improved in successive iterations, some of the discarded features should be recycled. This will allow agents to fully search features later.
More attention should be paid to the features with low scores in the evaluative measures when recovering features. However, the low score does not necessarily mean that corresponding features should be simply discarded. Therefore, the lower-ranked features will receive higher weights. Assuming the dimension of input data is
, the calculation for weight is described below:
where
denotes the feature weight, and
represents the feature score set obtained from feature discarding,
represents the
ith feature score. More weights obtained through Equation (6) are assigned to weak features, thus increasing their chances of being selected. As illustrated in
Figure 3, after the features recovered through weighted screening are added to the corresponding subpopulation’s feature subset, a new feature space is generated for agents.
3.4. The Objective Function
The main target of feature selection is obtaining a representative feature combination from the original feature set to maximize the OA [
41], which is an important evaluation criterion, but how to decrease the number of selected features is also a crucial target in feature selection. In this paper, the objective function is used to evaluate the feature combination searched by agents [
42]; it is described in Equation (7).
where
represents the fitness value of the feature combination searched by agents,
represents the overall classification accuracy obtained by SVM. Note that
and
are the number of total features in the dataset and the number of selected features.
is a weight factor of
and the number of selected features; it takes
= 0.9 in this paper.
3.5. Implementation of the Proposed Method
The proposed feature selection method updates the agent based on distance, and its key process involves the information interaction between agents. Moreover, in the event of stalling, it recycles some of the discarded features, thereby improving the probability of features with low score ranking. The proposed feature selection method is described as follows (Algorithm 1):
| Algorithm 1: Discarding–recovering and co-evolution mechanisms for HSI feature selection |
Input: the n m dataset D, the agent size Agesize, the number of feature groups M by reverse learning, and the maximum number of iterations Maxiter
Output: the effective feature combination selected by agents Undergo the feature discarding process through the feature discarding mechanism and obtain the SS and DS using the Equations (1)–(4) by reverse learning M feature groups for i in SS: do end for
The SS is divided into two subsets SS1 and SS2 based on the correlation
Selectgroup1 SS1, Selectgroup2 SS2 Two subpopulations are generated in Selectgroup1 and Selectgroup2 and Agesize agents are obtained t 0 while t < Maxiter: do Update the location of each agent by Equation (5)
Update the fitness value of each agent by Equation (7)
if the optimal solution has been updated then Exchange the information through interaction end if if one of the subpopulations has stalled then h Recover(subset) SS Add(SS, h), DS Sub(DS, h), Selectgroup1,2 Add (Selectgroup1,2, h), S Add(s, h) end if t t + 1 end while return The OA of effective feature combination
|
In the beginning, the feature evaluation is performed on all agents to discard the features with low score ranking, resulting in a selected set (SS) of features and a discarded set (DS) of features. The SS is then divided into two subsets: selectgroup1 and selectgroup2. Representative information is exchanged between these subsets when the optimal agent is updated. Moreover, if the stagnation phenomenon is detected, the feature recovering mechanism is triggered to recycle a recovery feature subset with a certain number based on the adaptive weight W. These features will be added to the SS and removed from the DS. The iteration process continues until the maximum iteration is reached.
4. Experimental Results
The proposed feature selection method is implemented using Python 3.8 on a personal computer that has a 2.30 GHz CPU, 8.00 GB RAM, and the Windows 8 operating system. To evaluate the performance of the proposed method, three HSI datasets, namely KSC (176 bands), Salinas (204 bands), and Longkou (270 bands), are used in the study. The experimental results are compared with some feature selection methods with EA-based, co-evolution mechanism-based, and others, and each independent experiment is performed in 30 operations with 50 iterations of each operation.
4.1. Dataset Description
The first dataset was acquired by NASA at the Kennedy Space Center (KSC) in Florida. It was obtained from a distance of approximately 20 km and contained 224 bands with a spatial resolution of 18 m. After removing bands with water absorbance and low signal-to-noise ratio, 176 bands were used for verification. The image consists of 512 614 pixels.
The second HSI dataset, named Salinas, was obtained by an AVIRIS sensor in the Salinas Valley of California, USA. It consists of 204 bands with a spatial resolution of 3.7 m and a pixel size of 512 217. The spectral range of the dataset spans from 0.4 to 2.5 μm, and the spectral resolution is 10 nanometers.
The third dataset was obtained in Longkou Town, Jingzhou City, Hubei Province, China, and includes six classes in an agrarian context. The UAV flew at an altitude of 500 m, and the spatial resolution of the airborne hyperspectral image is approximately 0.463 m. The image size is 550 400, with 270 bands ranging from 400 to 1000 nm.
The class names and corresponding sample numbers of three HSI datasets are described in
Table 1. The image scene and ground truth of them are shown in
Figure 4.
4.2. Parameters Setting of EAs
Before running, some parameters of EAs should be set for the heuristic search. The performance of the effective feature combination is dependent on the setting of parameters to some extent. In this paper, several EA-based feature selection methods, including PSO [
43], FA [
44], GWO [
45], and GSA [
46], are adopted to provide an intuitive performance comparison with the proposed method.
Table 2 shows the parameters setting by these EAs.
4.3. Experiments for the Search Ability
Table 3 presents the OA and Kappa coefficient after 30 independent operations, while WTL is the win/tie/loss indicator of the fitness value.
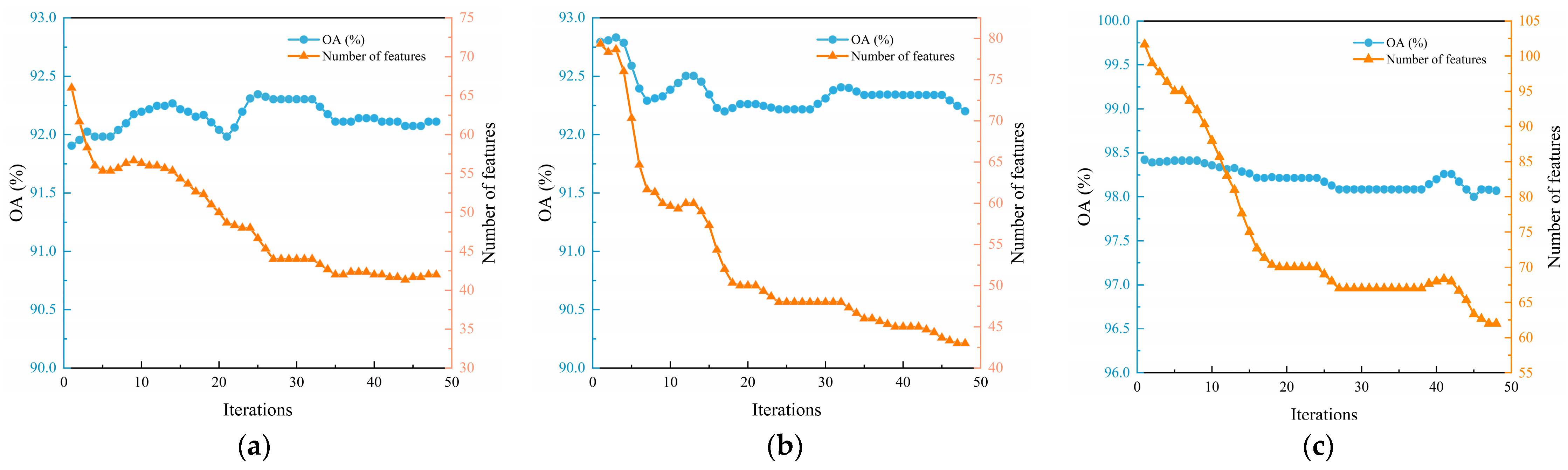
Table 4 shows the number of features (Num) and CPU time (Time) selected by the 30 independent operations. To demonstrate the prominent OA of the effective feature combination achieved in each iteration, the average number of features and OA are obtained for each iteration, as shown in
Figure 5, and the fitness value is shown in
Figure 6.
According to
Table 3, the proposed method outperforms PSO, FA, GWO, and GSA in search capability, which achieves a prominent OA, surpassing PSO, FA, GWO, and GSA by 1.1%, 1.81%, 1.15%, and 1.36%, respectively. Those experimental results exhibit the superior searchability of the proposed method. Moreover, it enhances the development potential of local search by using a feature recovery mechanism. Its winning frequency is higher than 27, especially in Longkou, where it reached 30. These demonstrate the prominent stability of the proposed method and the superior exploration ability.
According to
Table 4, the proposed method exhibits significantly higher reductive efficiency than other EA-based feature selection methods. Specifically, it selects less than 20% of the features from the HSI dataset, resulting in the selection of only 42 features out of a total of 176 bands in the KSC dataset while achieving a prominent OA. The Salinas dataset, it selects approximately half number of features compared with GSA yet achieves a better OA. On average, other methods select 58.7 features, whereas the proposed method selects only 43.1 features, indicating superior performance. In addition, the feature discarding mechanism substantially reduces redundant features, thereby shrinking the feature space and improving the computation time, especially in the Longkou dataset.
As shown in
Figure 5, after feature discarding, the number of selected features searched by agents is still high, and the number of features is decreased after the heuristic search, while the OA is little to no fluctuation, demonstrating the prominent stability of the proposed method. Furthermore, the feature recovering mechanism effectively updates agents before the iteration ends, indicating that the proposed feature selection method possesses a prominent ability to escape from local optima. According to
Figure 6, the fitness value is visualized to comprehensively evaluate the searching ability of each algorithm, and the proposed feature selection method achieves promising results on three HSI datasets and ranks 1
st in terms of average fitness value, followed by GWO, FA, PSO, and GSA. Moreover, the proposed method achieves the optimal fitness value on three HSI datasets compared with other EA-based methods, proving it has a prominent search ability for feature selection.
4.4. Comparison with Other Feature Selection Methods
To assess the impact on each class, some feature selection methods in HSI datasets are compared in the experiment: maximum information minimum redundancy (MRMR) [
47], joint mutual information with class correlation (JOMIC) [
48], joint mutual information maximization (JMIM) [
49], conditional mutual information maximization (CMIM) [
50] and shallow-to-deep feature enhancement (SDFE) [
51]. The experiments are performed on 10% to 25% of the total features. The accuracy for each class and Kappa coefficient are shown in
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13,
Table 14,
Table 15 and
Table 16.
4.4.1. The Result of the KSC Dataset
Based on
Table 5,
Table 6,
Table 7 and
Table 8, it is concluded that the proposed feature selection method outperforms MRMR, JOMIC, JMIM, CMIM, and SDFE in terms of the OA for different numbers of features, with an improvement of over 0.7%. Furthermore, when using 20% of the total number of features, the Kappa coefficient reaches 0.9, demonstrating that its OA is basically anastomotic with the labels. For 25% of the total number of features, other feature selection methods have an OA of below 91.2%, while the proposed method achieves the OA and Kappa coefficients exceeding 92.8% and 0.916, respectively. Moreover, the proposed method takes the OA of over 97% for five classes, with Willow swamp, Cattaial marsh, and Mudflats even reaching 98%. In summary, it is a practical feature selection method for the KSC dataset.
4.4.2. The Result of the Salinas dataset
The experimental results demonstrate that the proposed method outperforms other commonly used feature selection methods, achieving an OA of over 92% while obtaining the total number of features by less than 20%. Moreover, the Kappa coefficient for 25% of the total number of features is 0.2 higher than that of other methods, and the OA is higher for each class, with an OA of over 96% for all 14 classes. Notably, the samples of Brocoli_green_beads_1 are all correctly identified. These indicate that it achieves a prominent OA and Kappa coefficient for each class of the Salinas datasets, demonstrating the superiority of the proposed method.
4.4.3. The Result of the Longkou Dataset
Table 13,
Table 14,
Table 15 and
Table 16 present the OA and Kappa coefficients in the Longkou dataset. It is evident that the proposed method obtains prominent OA and Kappa coefficients, and it maintains a clear advantage in the classification of a small number of features. In the experimental comparison using 10% of the total number of features, MRMR, JOMIC, and SDFE achieve an OA of below 97%, while the proposed method achieves an OA of as high as 97.1%, which is 1.6%, 1.1% and 0.2% higher than MRMR, JOMIC, and SDFE, respectively. The OA of JMIM and CMIM is lower than 89%. The Kappa coefficient also demonstrates an overall advantage for the proposed method. Those results indicate that it is a robust and feasible feature selection method for the Longkou dataset.
5. Discussion
5.1. Design Analysis of the Proposed Method
EA is an effective strategy to obtain a feature combination of HSI datasets with a preferable OA in a limited time, the OA obtained on three HSI datasets exceeds 90%, and some even reach 98%. However, it is prone to stagnation during iteration due to the insufficient interactivity of agents. Co-evolution is a prominent mechanism to improve the agents’ diversity, the original feature set is divided into some subsets, and agents are generated by those to form subpopulations. Moreover, information interaction exchanges the optimal feature combination searched by agents to maintain the balance of subpopulations, but solely exchanging the optimal feature combination reduces the selected probability of interactive features. The proposed method incorporates reliable information interaction and a series of mechanisms focusing on features to address this. The trajectory of the OA for each iteration indicates that the stability of the proposed method, is decreased by less than 0.5% as the feature space condenses, and the computational time is also reduced by an average of 15%.
The proposed method has a prominent OA in most of the classes and even reaches 100% for Brocoli_green_beads_1 in the KSC dataset and Water in the Longkou dataset. Although it is lower than other feature selection methods in a few classes, the difference is not apparent in the class with small samples. Although other methods based on measure criteria stand out in terms of efficiency, it is difficult to distinguish interactive features as the number of instances increases. Feature discarding is an effective mechanism for eliminating redundant information and improving the computational load. Similar to other feature selection methods, the OA is negatively impacted due to improper discarding. To counterbalance this effect, the feature recovering mechanism is employed to improve the generalization ability while maintaining the OA at a high level. Experimental results indicate that the OA of the proposed method surpasses other feature selection methods by an average of 3%, and important features are adequately restored by the feature recovery mechanism, thereby improving the performance and reliability of the proposed method.
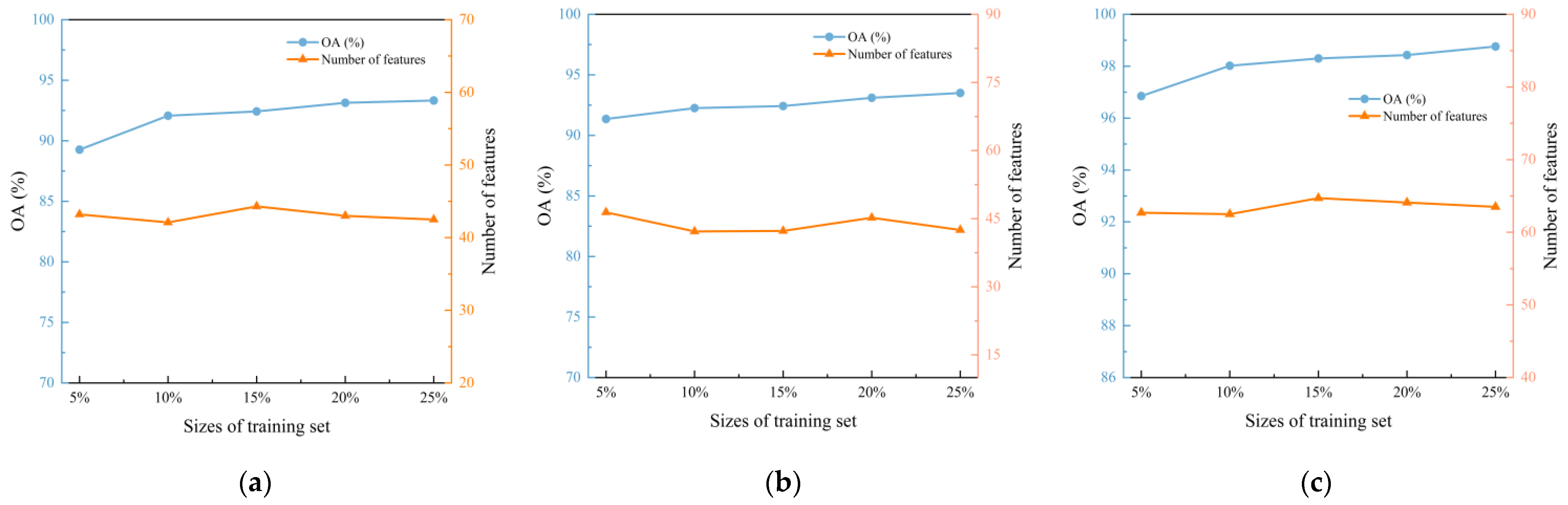
5.2. Discussion for the Training Size
In
Section 4.1, three HSI datasets, namely, KSC, Salinas, and Longkou, are introduced to validate the performance of the proposed method. The OA of effective feature combination and computation time is influenced by the size of the training set. Several tests are conducted on the proportion of the training set, ranging from 5% to 25%, because of the small-sample learning properties to determine the appropriate size of the training set. The change curves for the number of features and the OA of different training sets are shown in
Figure 7.
The experimental results indicate that the increasing size of the training set from 5% to 10% leads to a significant improvement in the OA. However, further increasing the proportion from 10% to 25% only results in a minimal increase, while the computation time also decreases to some extent. Additionally, the number of selected features does not show significant fluctuations, so the size of the training set is designated as 10%. This size strikes a balance between the OA and computational load, making it a practical and effective choice for feature selection in HSI datasets.
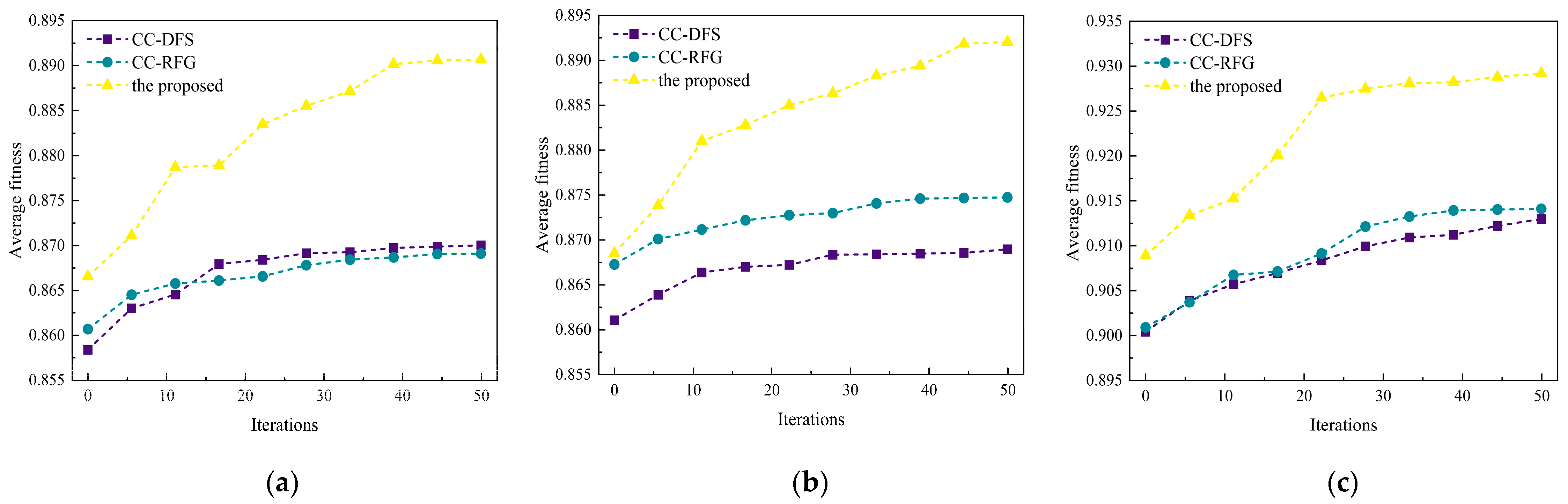
5.3. Comparison with Other Co-Evolution Mechanisms
To verify the search efficiency of the co-evolution mechanism in the proposed method, it is compared with other co-evolution mechanisms named CC-DFS [
33] and CC-RFG [
34]; the average fitness value of each iteration on three HSI datasets is shown in
Figure 8.
In the beginning, the fitness value of the proposed method is higher than that of CC-DFS and CC-RFG in three HSI datasets, which demonstrates that the feature discard mechanism effectively removes the redundant features. With further iterations, the fitness trajectory of CC-DFS and CC-RFG gradually stabilizes while that of the proposed method remains upward. This indicates that the co-evolution mechanism enhances the search efficiency of agents and suggests a prominent ability to escape from local optima. As a result, the reliable co-evolution mechanism effectively interacts with more representative information, largely avoiding the occurrence of stagnation.
6. Conclusions
A feature selection method based on discarding–recovering and co-evolution mechanisms is proposed in this study with the aim of obtaining effective feature combinations in HSI datasets. According to the experimental results, the proposed method outperforms other EA-based feature selection methods, including PSO, FA, GWO, and GSA, in terms of optimization ability and search speed in the feature space. It achieves a prominent OA with a small number of selected features, outperforming other feature selection methods in this regard, and exhibits satisfied stability. In addition, through comparing with the other co-evolution mechanism, the fitness trajectory exhibits that the reliable co-evolution mechanism could interact with more representative information between agents, making them continuously improve. The performance limitations caused by feature discarding are improved through the recovery of dropped features, which guarantees the generalization ability and decreases computational load.
Furthermore, the proposed method outperforms MRMR, JOMIC, JMIM, CMIM, and SDFE in terms of the OA with varying numbers of features, and the reliable information interaction ensures a more balanced learning process, which maintains a positive balance between classification accuracy and the number of selected features, making it become a suitable choice for feature selection. In future studies, more representative criteria will be synthesized in the information interaction to further improve the diversity of agents. Moreover, it is interesting to use feature clustering to take the population division and further avoid population imbalance.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}