4.1. Unequal Cluster-Tree Topology Construction
Table 2 details the list of notations that are used in the paper.
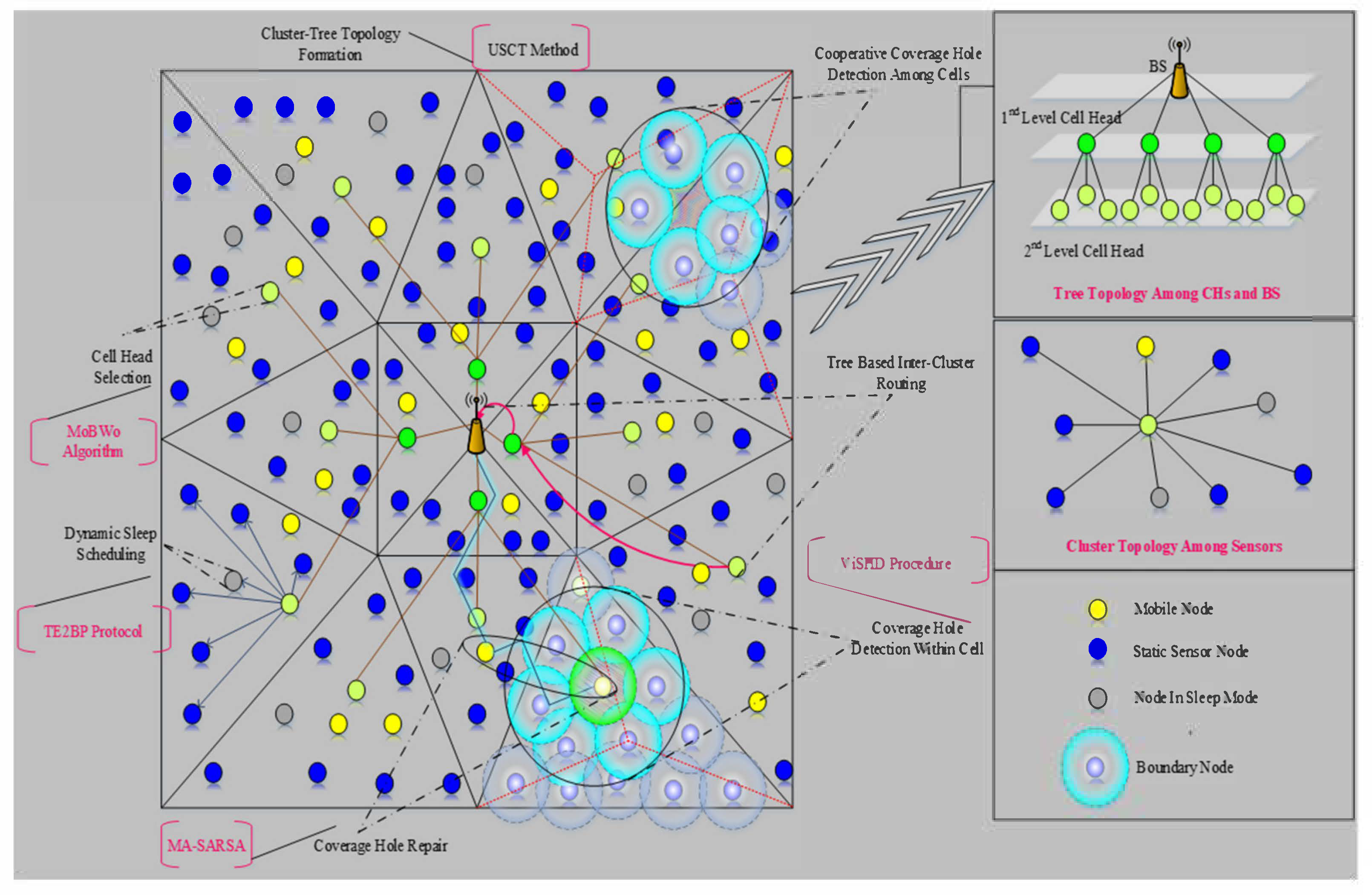
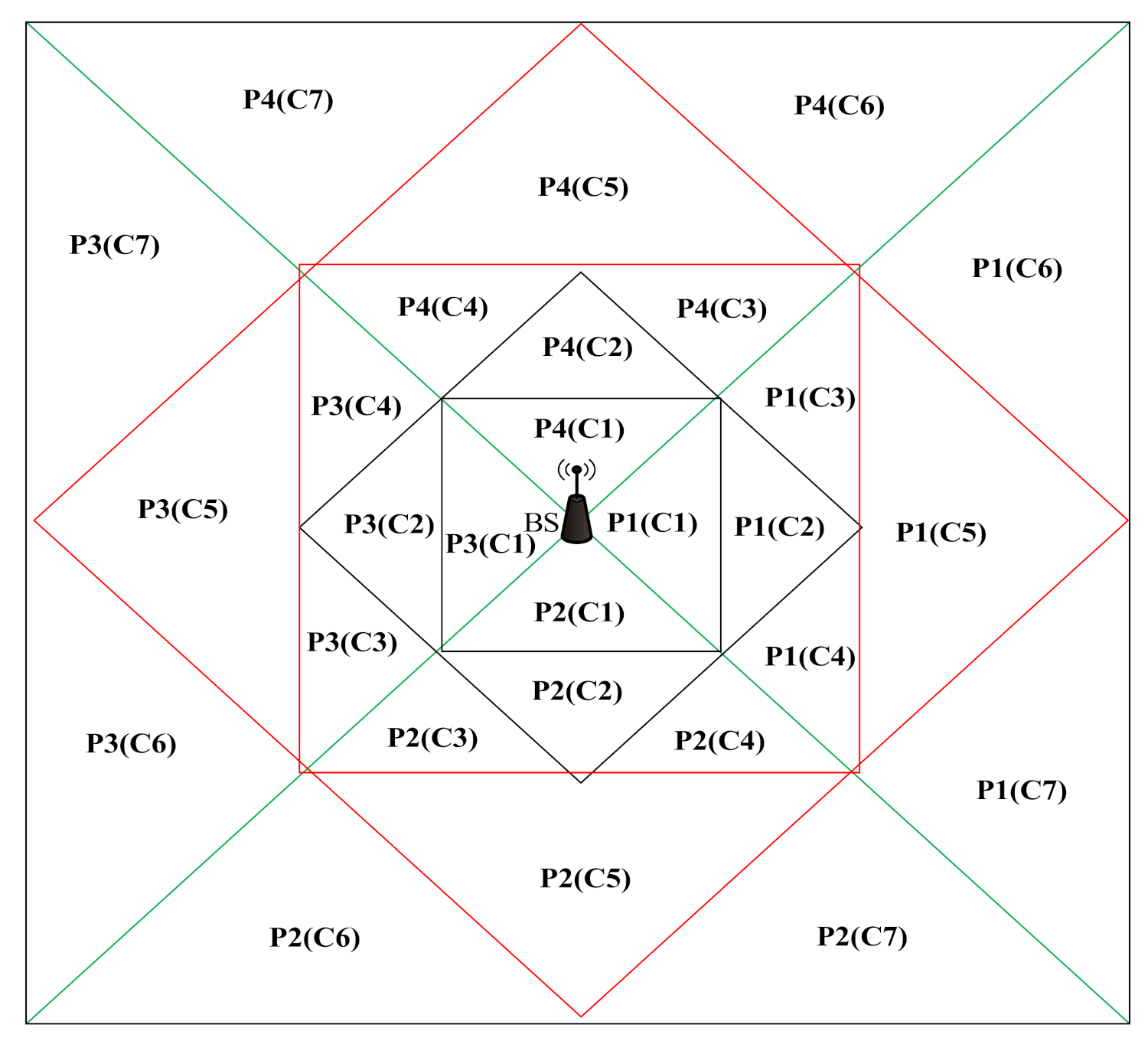
In this phase, we aim to construct a new topology that supports energy efficiency with effectual data transmission. We propose a novel clustering method by considering the triangle-based partitioning of the unequal Sierpinski cluster-tree topology (USCT) construction method in the IoT environment based on the formation of triangle partitions
to avoid the coverage hole as shown in
Figure 2. The proposed USCT method constructs unequal cells by following the procedure of the Sierpinski triangle. Initially, the network is constructed as a graph N =
in which V denotes the sensors deployed and E =
represents the connectivity of the nodes. In which p, q are any two sensor nodes in the network, TR denotes the range of transmission. c = {
} is a cluster comprising of a subset of vertices
(nodes) whose center is denoted as
. The cluster tree topology is utilized in which all the nodes are linked with each other which reduces the data loss problem in the network. The network is divided into four triangles and the remaining triangles are formed by repeating the above process to cover the entire area. By doing so, the unequal clusters are formed in which the size of the triangles nearer to the base station is larger than the size of the triangles that are situated away from the base station. Algorithm 1 describes the steps involved in the formation clusters in the network.
| Algorithm 1 Cluster Formation
|
|
i ← number of iterations;
|
Rectangular zone diagonals are drawn;
Partition formation ;
For each partition do
The clusters are formed, i.e., ;
Where n = 1, 2, 3…, m; |
| While i 1 do |
|
For each cluster do
|
|
The nearest cluster to BS is considered;
|
|
Midpoints of the sides are connected;
|
|
i = i−1;
|
|
End
|
|
End
|
Once the clusters are formed, the cluster head selection takes place by implementing multi-objective black widow optimization (MoBWo). The main purpose of choosing this algorithm is an early convergence, and it obtains the optimized fitness values as compared to other algorithms such as PSO, GA and other traditional algorithms. In order to choose the proper CH for data collection and aggregation, various sets of parameters are biologically optimized in MoBWo that are follows,
The MoBWo is processed by random initialization of the black widow population. Two kinds of spiders’ behavior are inherited in the CH selection, i.e., male black widow and female black widow. The initialization of black widow spiders is given in below,
where
are the initial values of the population. In this paper,
is represented as the total number of nodes in the network for CH selection.
The CH is selected based on multiple objectives like energy objective, distance objective and capacity objective. For optimum CH selection, these objectives must be defined as follows:
Energy objective: residual energy must be higher to elect that node for CH, since minimum energy causes packet retransmission or packet losses issues.
Distance objective: distance must be lower than the BS to choose it as the CH. Longer distance causes the huge end-to-end delay.
Capacity objective: a node must consist of lower capacity because a lower capacity node can carry the huge amount of packets from the CM.
Based on the above objectives, the best set of nodes is selected as CH in the number of triangles. Each objective metric can be calculated by the following.
The remaining energy of the sensor node is expressed as,
In which,
denotes energy required for transmission,
denotes power consumption of amplifier in free space and multi-path fading channel models and
denotes the signal processing energy, IE represents initial energy,
denotes energy required for amplification and k represents length of message bits.
In order to compute the energy consumption of the CH, both the energy consumption during inter-cluster and intra-cluster routing are to be calculated which are expressed as the following equations. Equation (5) represents the energy required for CH in intra-cluster routing
which is equal to the sum of the energy required for reception of signals inside the cluster
and the energy required for aggregation of received signals
. In Equation (6), the energy consumption of CH in inter-cluster routing
is computed which equals to the sum of energy required for the transmission of signals between the clusters
and the energy required for the sensing of signals
, where
denotes the compression ratio and
denotes the sensing cost. The total energy consumption of the wireless sensor network is found from the remaining energy, which can be calculated from Equations (8)–(10).
denotes energy required for reception,
denotes energy required in idle state and
denotes energy required in sleep state. The remaining energy for all the nodes is calculated to select the optimal cluster head. The distance between two nodes a and b in the cluster is formulated as,
In which y and z denote the location coordinates of the sensors, respectively. The capacity of the node is referred in terms of buffer size which can be represented as,
The MoBWo computes the fitness value for each node based on the objective and selects the optimal cluster head. In the procreation mode two nodes are selected as parents and two nodes are selected as children in which the child nodes are expressed as,
Once the procreation mode selects the nodes, the cannibalism mode is carried out in which only the fittest nodes are selected. Based on the population of the procreation mode, the mutation is carried out and finally the optimal CH is selected. The nodes in each cell form clusters with the CH while the CHs form tree with BS. Data transmission takes place through the CHs selected optimally by the MoBWo algorithm. This phase minimizes energy consumption and increases data transmission efficiency. Algorithm 2 explains the process of selection the optimal node as the cluster head.
| Algorithm 2 CH selection
|
| Input: No.of. iterations, PP, CR, PM
|
| Output: Optimal cluster head
|
|
Population initialization of nodes;
|
| Calculate reproduction number “”; |
| From select best results |
| For k = 1 to do |
| From arbitrarily select two nodes as parents; |
|
Using Equation(4) generate children;
|
|
Father is destroyed;
|
|
Destroy some children based on CR;
|
| Save no. of. Nodes into ; |
| End for |
| Calculate the no. of mutation nodes based on PM; |
| For k = 1 to do |
| Select a node from ; |
|
Generate new node by random mutation
|
| Save the new nodes into ; |
| End for |
| Update ; |
| Get the best node from ; |
4.2. Dynamic Sleep Scheduling
To further reduce the energy consumption, we enable dynamic sleep scheduling in this phase. We propose a new Tsallis entropy enabled Bayesian probability (TE2BP) algorithm to schedule the sensor nodes into sleep and active mode. The algorithm operates upon residual energy level, buffer factor and coverage expected rate metrics. The sleep scheduling slots are assigned to the sensor nodes by the corresponding cell headers. The involvement of sleep scheduling is to improve the energy efficiency in the network. The probability of a node being in active mode without considering the parameters is defined as
P(
A) and the probability of the node being in sleep node without considering the parameters is expressed as
P(
S). Let R be the sum of evidence of the values of residual energy, buffer factor and coverage expected rate. The probability of a node being in active mode with respect to the parameter evidence is represented as,
Similarly, the probability of a node being in sleep mode with respect to the parameter evidence is expressed as,
The threshold value for each metric is set by the Tsallis entropy and nodes having the values above the threshold value are set to active mode whereas other nodes are set to sleep mode which will be changed periodically. The entropy condition is expressed as,
In which, y is the entropy index and Ty is the threshold value. Through this method the nodes are scheduled into sleep and active mode in order to improve the energy efficiency of the network, thereby preventing the coverage holes.
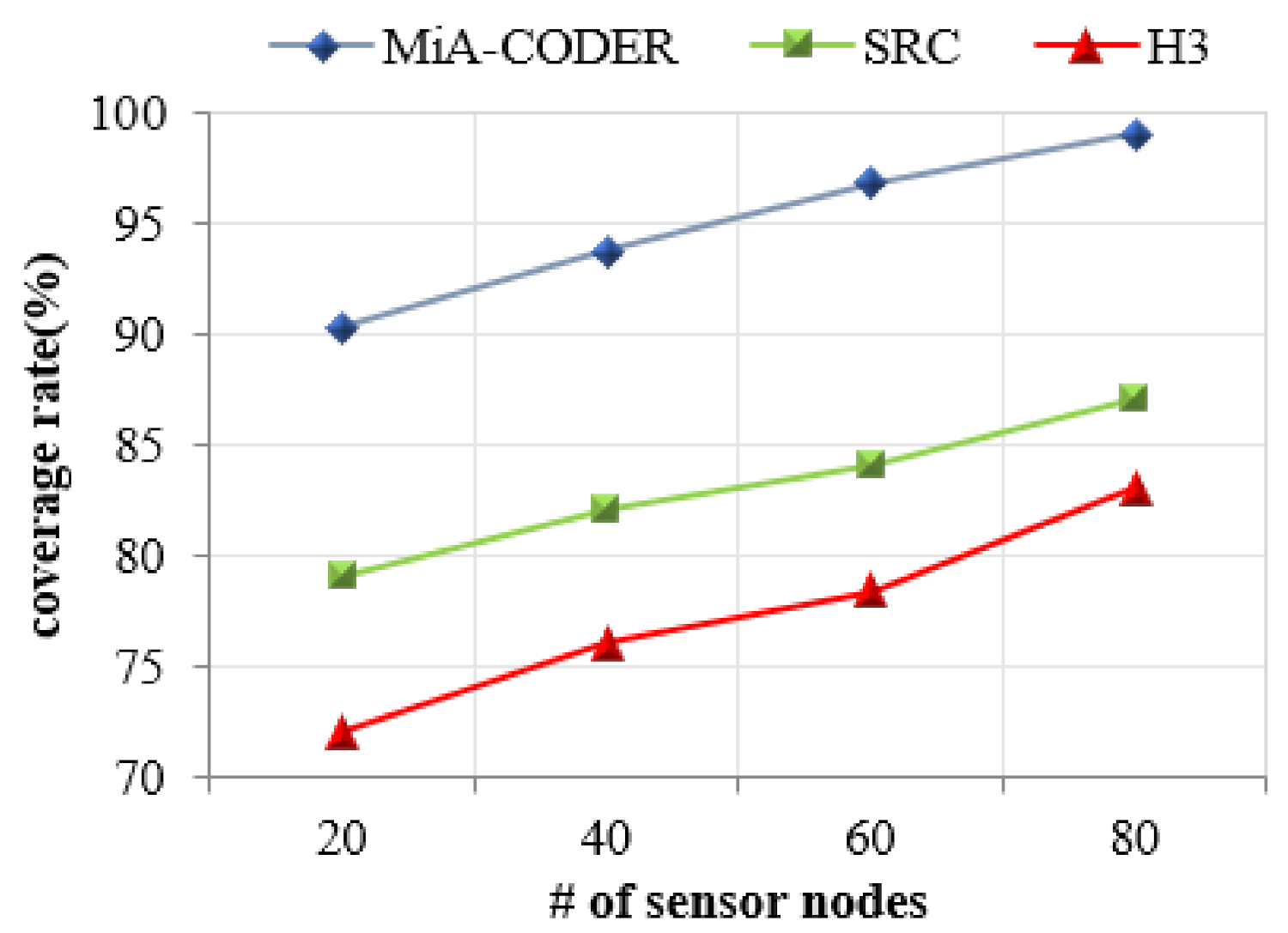
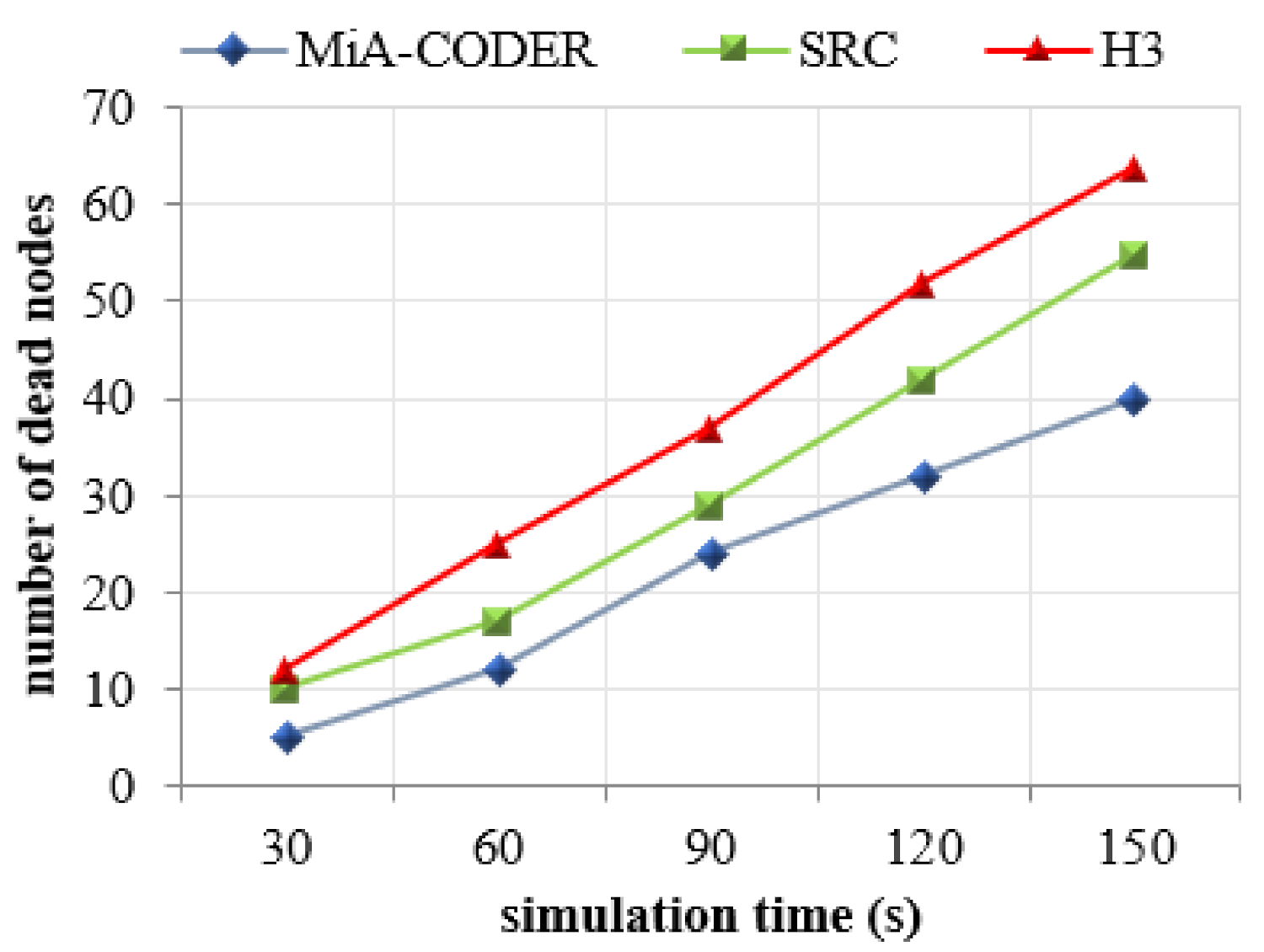
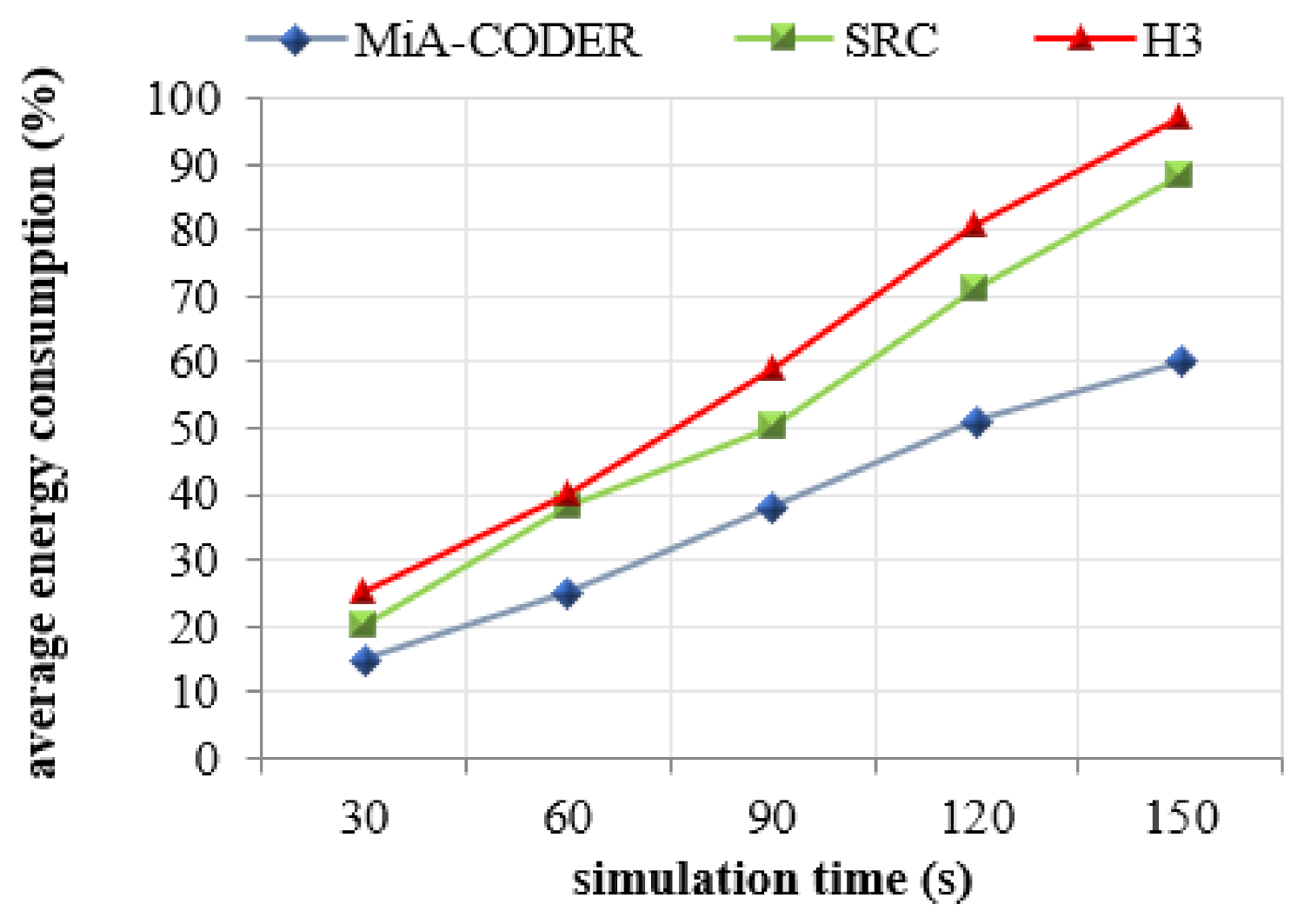
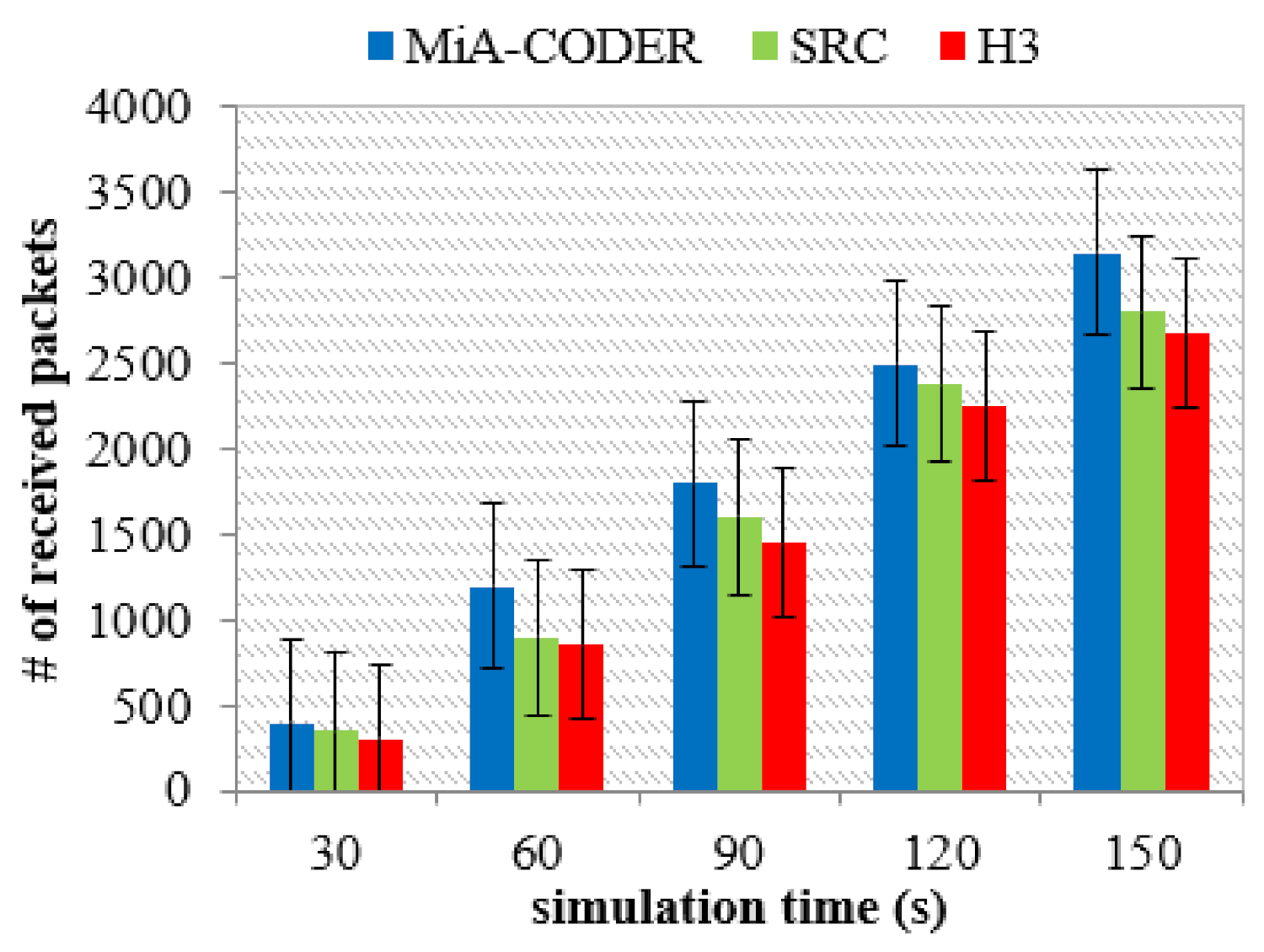
Table 3 presents the consumption of energy by every node in each mode which depicts that the energy consumption of each node in sleep mode is zero. Hence, the lifetime of the nodes in the network is further increased.
4.3. Coverage Hole Detection and Repair
The above processes improve the energy efficiency which prevents the coverage hole, while this phase detects and repairs the coverage hole if this occurs. The coverage holes occur mainly due to the deployment of sensors in a random manner. Repairing coverage holes drastically improves the QoSensing. In our work, CHs are responsible for hole detection and BS is responsible for hole repair. The CHs detect the hole by the virtual sector-based hole detection (ViSHD) protocol. This protocol segments each triangle at the degree of 60. The coverage hole is formed in between the sensors deployed in a ring-like structure. The coverage hole is formed as there is no sensor to cover the area or the sensor covering the respective area has become redundant. Then, the hole detection is performed by locating the boundary nodes. Let the boundary nodes be {bn0, bn1… bnm} the maximum distance between any two nodes is computed in order to locate the hole center. The maximum distance is expressed as,
The center point of the distance is defined as the hole center which can be expressed as,
Hole area computation procedure is applied in two cases as,
Case 1 (within a cell): In this case, the holes are detected within a cell for which the corresponding CH is responsible. The CH initiates the boundary nodes to find the hole area.
Case 2 (among cells): In this case, the holes are formed among two cells. In this case, two CHs are responsible to compute the area of the hole. Here, both CHs work cooperatively to determine the hole area.
Once the coverage hole is detected, the BS takes appropriate action to repair the coverage holes. The repair process constitutes isolating the redundant node and replacing the redundant node with another optimal sensor node. We propose a novel multi-agent SARSA (MA-SARSA) algorithm. The proposed MA-SARSA learns the environment and selects optimal mobile to repair the hole. Here, we frame multiple parameters such as distance, node lifetime and coverage level. The distance of the node is obtained from the distance calculation between two nodes which is formulated in Equation (2). Selecting the node only based on distance may not be appropriate as the mobile nodes may travel in opposite directions to the location of the hole; therefore, the direction of the mobile node should also be considered for precise node selection. The direction of the mobile node is calculated from the formula given below,
In which (
is denoted as the center of the line segment between two nodes and the lifetime of the node is computed based on the future level of energy of the node which is denoted as
and is calculated from the prior energy history
(t). It can be formulated as,
In which m denotes the number of history samples taken for the calculation of the future energy level. Hence, the lifetime of the node is computed as,
The coverage of the node is defined as the area up to which the sensor can sense the data packets and can be calculated as,
Algorithm 3 explains the process for the optimal mobile node selection is described above using the calculation of necessary factors that affect the mobile node selection.
Figure 3 depicts the coverage hole detection and repair process.
| Algorithm 3 Optimal node selection
|
|
Input: coverage hole location, mobile nodes around coverage hole
|
|
Output: optimal node for replacement
|
|
For nodes near coverage hole do
|
|
Calculate the distance using Equation (11);
|
|
Select the nearest nodes having less distance;
|
|
Calculate the direction for those nodes and save in list L1;
|
|
End for
|
|
For nodes moving towards hole in L1do;
|
| Calculate the lifetime of the node using ; |
|
Select the node with longer lifetime;
|
|
Calculate the coverage of those nodes and save in list L2;
|
|
End for
|
|
Return optimal node
|
Let
denote the state at time stamp t and
represent the set of actions that each SARSA agent takes in the respective state. During coverage hole repair, the location and sensing of the optimal mobile node is changed which is considered as the change in action. Then the possible action is represented as,
In which
= (
is the present position of the mobile node and its future position is represented as
and
denote the current and future sensing range of the mobile nodes, respectively.
is the reward set comprising of rewards
obtained for the action taken by the agent. Hence, the goal of the agent is to obtain high reward which can be expressed as,
The Q function is represented as,
And the optimal Q function can be formulated as
From the optimal
function, the optimal policy can be determined by,
The rule for updating the Q function for the next state
based on the reward obtained for the action carried out in previous state
is expressed as,
The selected mobile node is positioned at the optimal position to repair the hole. Thus, we repair the coverage hole with the minimum number of mobiles nodes without increasing in complexity. Algorithm 4 explains the process for the MA-SARSA is presented below in which the Q function is initiated arbitrarily for which the state and action is initiated and in each trial step the reward is obtained. This process is repeated until the coverage hole is repaired.
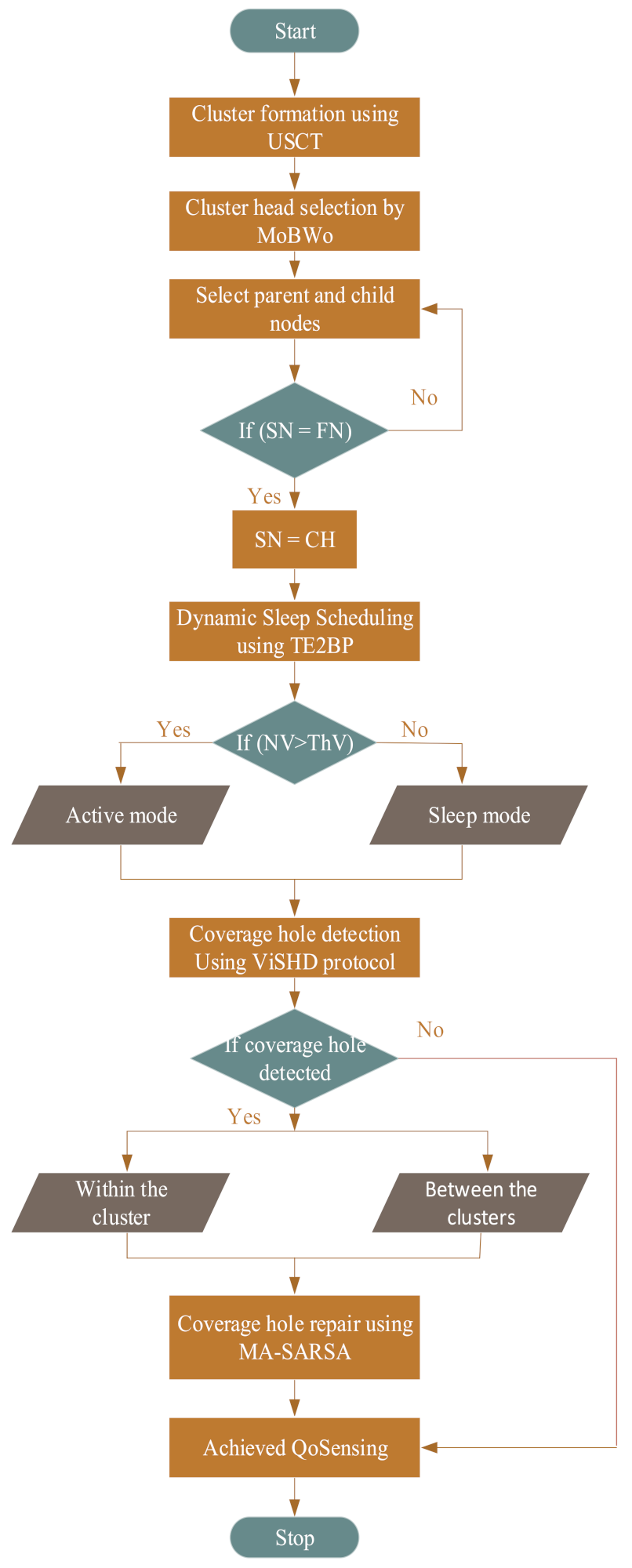
Figure 4 depicts the overall flowchart of the proposed MiA-CODER approach.
| Algorithm 4 Coverage hole repair
|
| Initialization of Q( in a randomly; |
|
For each trial repeat:
|
| Initialization of |
|
For each trial step repeat:
|
| Perform obtain , ; |
| Choose from using policy; |
|
|
| Until |
|
Until coverage hole is recovered
|



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}