
Esoteric Pull and Esoteric Push: Two Simple In-Place Streaming Schemes for the Lattice Boltzmann Method on GPUs


Biofluid Simulation and Modeling—Theoretische Physik VI, University of Bayreuth, 95447 Bayreuth, Germany
Computation 2022, 10(6), 92; https://0-doi-org.brum.beds.ac.uk/10.3390/computation10060092
Submission received: 1 April 2022
/
Revised: 23 May 2022
/
Accepted: 27 May 2022
/
Published: 2 June 2022
Abstract
:I present two novel thread-safe in-place streaming schemes for the lattice Boltzmann method (LBM) on graphics processing units (GPUs), termed Esoteric Pull and Esoteric Push, that result in the LBM only requiring one copy of the density distribution functions (DDFs) instead of two, greatly reducing memory demand. These build upon the idea of the existing Esoteric Twist scheme, to stream half of the DDFs at the end of one stream-collide kernel and the remaining half at the beginning of the next, and offer the same beneficial properties over the AA-Pattern scheme—reduced memory bandwidth due to implicit bounce-back boundaries and the possibility of swapping pointers between even and odd time steps. However, the streaming directions are chosen in a way that allows the algorithm to be implemented in about one tenth the amount of code, as two simple loops, and is compatible with all velocity sets and suitable for automatic code-generation. The performance of the new streaming schemes is slightly increased over Esoteric Twist due to better memory coalescence. Benchmarks across a large variety of GPUs and CPUs show that for most dedicated GPUs, performance differs only insignificantly from the One-Step Pull scheme; however, for integrated GPUs and CPUs, performance is significantly improved. The two proposed algorithms greatly facilitate modifying existing code to in-place streaming, even with extensions already in place, such as demonstrated here for the Free Surface LBM implementation FluidX3D. Their simplicity, together with their ideal performance characteristics, may enable more widespread adoption of in-place streaming across LBM GPU codes.
1. Introduction
The lattice Boltzmann method (LBM) [1] is a type of direct numerical simulation (DNS) to model fluid flow in a physically accurate manner. Its explicit algorithmic structure makes it ideal for parallelization on graphics processing units (GPUs) [2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59]. The LBM works on a mesoscopic scale, representing quantities of fluid molecules by density distribution functions (DDFs) that are exchanged (streamed) between neighboring points on a Cartesian lattice. These DDFs are represented as floating-point numbers, and the streaming consists of copying them to the memory locations associated with neighboring lattice points. So, the LBM algorithm, at its core, copies floating-point numbers in memory with little arithmetic computation in between, meaning its performance is bound by memory bandwidth [3,4,5,6,7,8,9,10,13,14,15,16,17,18,19,20,21,22,33,34,35,36,37,38,39,40,41,42,43,44,45,46,59,60,61,62,63,64,65].
Since each lattice point holds the same number of DDFs and they need to be exchanged between one another at every time step, a strategy for avoiding data dependencies on parallel hardware is needed. The most straightforward and most common approach [12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44] is to have two copies, A and B, of the DDFs residing in memory; the algorithms reads from A and writes to B in even steps and in odd steps vice versa. With two copies of the DDFs, the memory access can even be configured to result in only partially misaligned reads and only coalesced writes (the One-Step-Pull scheme), enabling peak memory efficiency on modern GPUs [13,14,15,16,17,18,19,20,21,22,23]. This solves the data dependencies but comes at the cost of almost doubling memory demand. Unfortunately, memory capacity is the largest constraint on GPUs [58], limiting the maximum possible lattice resolution. To eliminate the higher memory demand and at the same time resolve data dependencies, a class of thread-safe in-place streaming algorithms have been developed. The first of these is termed the AA-Pattern [3], as it reads from A and at the same time writes to A in a special manner that does not violate data dependencies. The algorithm, however, is asymmetric for even and odd time steps, so it has not been widely adopted. A later variant of AA-Pattern is the Shift-and-Swap-Streaming method [4]. Geier and Schönherr recently found a more intricate solution, termed Esoteric Twist [2], that is symmetric for even and odd time steps and, moreover, has the advantage of slightly reduced memory bandwidth and thus higher performance compared to AA-Pattern; however, its implementation is very complicated, hindering widespread adoption. Few works have thus far considered in-place streaming on GPUs [2,3,4,5,6,7,8,9,10,11,12], and apart from the works introducing the methods [2,3,4,5,66], only a few have adopted in-place streaming in their code [6,7,8,11].
This work introduces two new thread-safe in-place streaming schemes, termed Esoteric Pull and Esoteric Push, that are suitable for GPU implementation. They build upon the same idea as Esoteric Twist and offer ideal performance characteristics while at the same time significantly simplifying implementation and allowing for automatic code generation. The very simple and modular implementation is especially well suited to modifying existing LBM implementations, even if various extensions, such as Free Surface LBM, are already in place.
2. Naive Implementation—One-Step Pull and One-Step Push
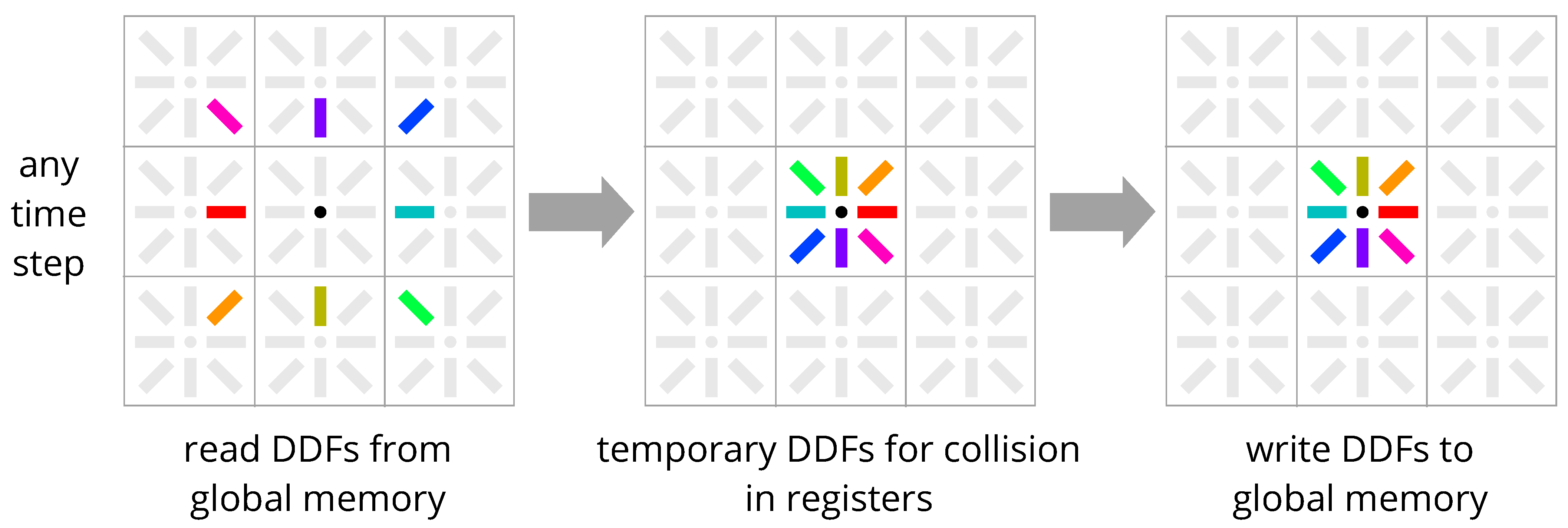
The most common LBM implementation uses two copies of the DDFs in memory to resolve data dependencies in a parallel environment [12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44]. There are two variants, namely One-Step Pull (Figure 1, Listing A1) and One-Step Push (Figure 2, Listing A2). The pull variant is generally preferred on GPUs because the penalty for non-coalesced reads is smaller than that for non-coalesced writes [13,14,15,16,17,18,19,20,21,22,23]. The coloring introduced in Figure 1 and Figure 2 illustrates how loading/storing patterns compare to the regular DDF sequence during collision in registers, in other words, where exactly each DDF is loaded and stored in memory. This makes the more recently introduced, more sophisticated streaming patterns more comprehensible. In the One-Step-Pull scheme, DDFs are pulled in from neighbors (copy A of the DDFs), collided, and stored at the center node (copy B of the DDFs). In the One-Step-Push scheme, DDFs are loaded from the center node (copy A of the DDFs), collided, and then pushed out to neighbors (copy B of the DDFs). For both schemes, after every time step, the pointers to A and B are swapped.
3. State-of-the-Art Methods for In-Place Streaming on GPUs
The data dependency problem with in-place streaming on parallel hardware has already been solved by two major approaches, termed AA-Pattern and Esoteric Twist. Both provide the great advantage of significantly reducing memory demand for the LBM; however, both also pose various difficulties in GPU implementation, hindering widespread adoption.
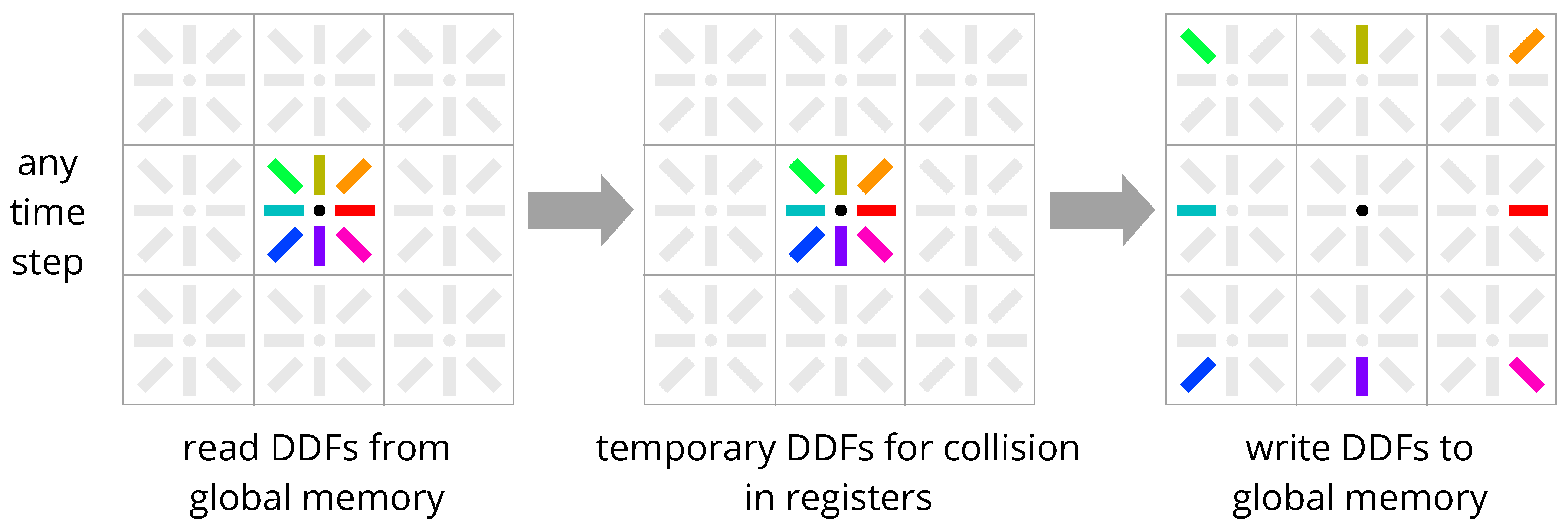
3.1. AA-Pattern
When performing the LBM streaming step on parallel hardware, the issue arises that neighboring lattice points may be processed in parallel, and the exact order of execution is random. One or more threads may not write an updated value to a memory address from which another concurrent thread is reading, because then either the old or the new value may be used by the reading thread. This error is known as a race condition. To perform the LBM streaming step in parallel with only a single buffer for the DDFs, one must write updated values only to the same memory addresses that one thread has previously read the values from. Then, no two threads access the same memory addresses. Bailey et al. [3] have found that this is possible if, for even time steps combining one streaming step, the collision and a second streaming step are performed, and for odd time steps, only the collision step is performed. This makes the processed DDFs always end up in the same locations as they were read from, resolving data dependencies on concurrent hardware with only one copy of the DDFs in memory. To make the DDFs actually stream through memory locations, in even time steps, the DDFs are stored at the neighbor nodes in opposite orientation after the collision, and in odd time steps, before the collision, the DDFs are loaded from the center node in opposite orientation. The resulting algorithm reads the DDFs from copy A of the DDFs and writes to the same copy A in place, so it was termed AA-Pattern (Figure 3, Listing A3). It is a popular but mistaken belief that the different even and odd time steps require duplicate implementation of the stream_collide kernel because the pointers to the DDFs cannot be swapped in between time steps. The loading and storing of the DDFs before and after collision can be placed in functions, and when the LBM time step is passed as a parameter, these functions then switch between loading/storing the DDFs from/to neighbors or at the center point (see Listing A3). The stream_collide kernel then contains calls to these two functions before and after collision, and no duplicate implementation is required. Note that there are also two more modern variants of the AA-Pattern, termed Shift-and-Swap Streaming (SSS) [4] and Periodic Shift (PS) [5], offering benefits in programming languages where pointer arithmetic is available.
3.2. Esoteric Twist
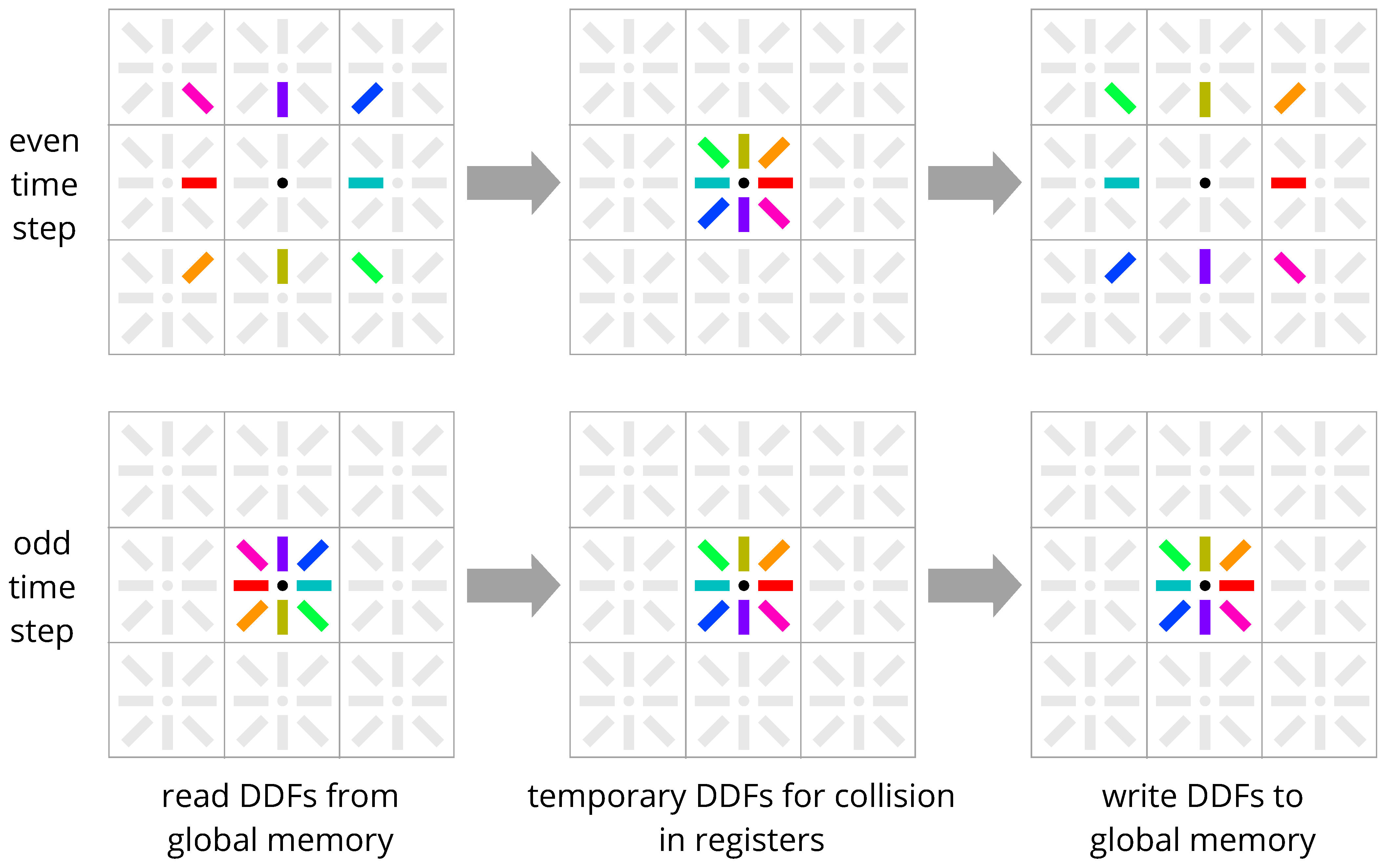
The idea of the Esoteric Twist in-place streaming scheme (Figure 4, Listing A4) is to pull only DDFs for negative directions, execute the collision, and then push only DDFs for positive directions [2]. To resolve data dependencies on concurrent hardware, in even steps, the DDFs are stored in opposite orientation after the collision, and in odd time steps, before the collision, the DDFs are loaded in opposite orientation.
Esoteric Twist resembles a criss-cross access pattern shifted north-east by half a node, accessing the DDFs at a total of 4 nodes (in the 2D case) or up to 8 nodes (in 3D). For certain implementations, this reduces the number of ghost nodes required, but it makes the implementation of the index calculation tedious as it requires manually writing the indices, which are different across velocity sets. On top of this, for some velocity sets such as D3Q15, additional streaming directions must be computed beyond the streaming directions of the velocity set (see Listing A4), making the already tedious implementation even more cumbersome. This is an obstacle to implementing different velocity sets in a modular manner or with code generation. With some LBM extensions such as Volume-of-Fluid, duplicate (inverse) implementation of the streaming is required, so Esoteric Twist becomes very impractical.
4. New Methods: Esoteric Pull and Esoteric Push
My two novel in-place streaming algorithms are based on the same idea as the Esoteric Twist scheme, namely that only DDFs in negative directions are pulled before collision, and that after collision only DDFs in positive directions are pushed. Thus, half of the DDFs are streamed at the end of one stream_collide kernel and the other half at the beginning of the next.
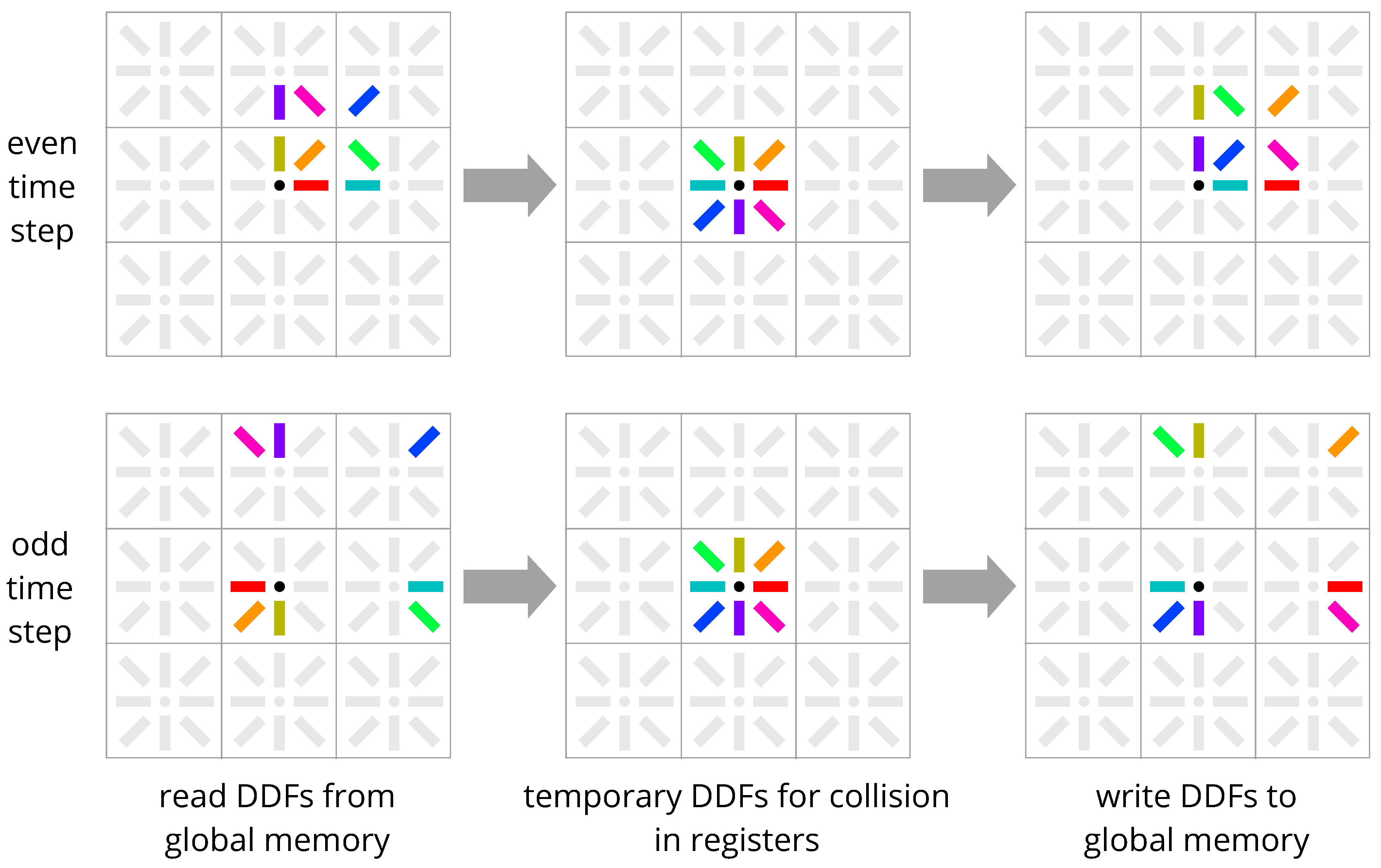
The important observation I made is that the shifted criss-cross pattern of Esoteric Twist is not essential for the swap algorithm to work. I waive shifting the north-west to south-east DDFs north by one node in 2D, and waive shifting other diagonal directions in 3D, abandoning the shifted criss-cross pattern. Instead, the regular streaming direction neighbors are used. This enables a trivial index calculation in two four-line loops (unrolled by the compiler) for loading and storing in a way that works with all velocity sets out of the box. This also makes the implementation less redundant and much less prone to errors, and it further enables automatic code generation.
The Esoteric Pull scheme (Figure 5, Listing A5) in 2D differs from Esoteric Twist (Figure 4) only in the positions of the DDFs for the north-west to south-east directions, which are loaded/stored in their regular locations instead of shifted north by one node. In 3D, other diagonal directions are also not shifted, and their regular streaming directions are used instead to determine the streaming neighbor nodes. This has not only the advantage of trivial index calculation, but also improves memory coalescence for the DDFs in these diagonal directions that would be otherwise shifted by one lattice point with Esoteric Twist, leading to slightly higher performance demands.
The Esoteric Push scheme (Figure 6, Listing A6) is essentially Figure 5 flipped by 180 degrees (except for the temporary DDFs in registers), highlighting two distinct symmetry flips that can be performed independently of each other: a) switching streaming for positive/negative directions, and b) switching even/odd time steps.
Both schemes yield simulations that are bitwise identical to Esoteric Twist. If pointer arithmetic is available, the pointers of DDFs in positive and negative directions can be swapped in between time steps such that memory addressing is the same for all time steps, in the very same manner as for Esoteric Twist.
4.1. Implicit Bounce-Back
In the very same manner as for the Esoteric Twist scheme [2], both Esoteric Pull and Esoteric Push offer the benefits of the ingeniously emerging implicit bounce-back boundaries. Due to the way the DDFs are flipped in orientation for regular fluid nodes, and because boundary nodes are not processed at all (with a guard clause at the very beginning of the stream_collide kernel), the DDFs of boundary nodes are not flipped in memory, so for neighboring fluid nodes, it appears as if their DDFs are already correctly flipped such that bounce-back boundaries automatically apply.
There are three distinct benefits to this side-effect of the Esoteric streaming schemes: (a) fluid nodes do not have to check the flags of their neighbors at all to apply bounce-back boundaries, reducing overall memory bandwidth and increasing performance slightly, (b) memory access is more coalesced, and (c) the implementation is simplified.
4.2. Comparison with Existing Streaming Schemes
When comparing the different streaming algorithms in Table 1 for DdQq LBM, the advantages of in-place streaming become evident, such as reduced storage and, for the Esoteric algorithms, also reduced bandwidth. In-place streaming reduces memory demand by Bytes/node. The Esoteric algorithms further reduce memory bandwidth by Byte/node per time step, as neighbor flags do not have to be checked for implicit bounce-back boundaries. Based on their storage and performance properties, Esoteric Pull/Push appear identical to Esoteric Twist, apart from slightly improved memory coalescence for the DDFs in some of the diagonal directions. The main improvements of Esoteric Pull/Push are located in the much more straightforward implementation that is compatible with all velocity sets. Instead of having to manually unroll the loops over the streaming directions and make sure that all indices are typed correctly for each velocity set, the streaming can now be written in a generic way as two short loops that are unrolled by the compiler (compare Listing A4 and Listing A5). This also allows for automatic code generation that many LBM implementations heavily rely on and significantly improves code maintainability.
A recently proposed method for reducing storage and bandwidth by resorting to FP32/16-bit mixed precision [13] makes in-place streaming with the Esoteric schemes even more compelling, reducing memory storage from 169 to 55 Bytes/node—less than one third—and reducing bandwidth from 171 to 77 Bytes/node per time step for D3Q19. Less memory demand per node enables much larger lattice resolutions.
When comparing D3Q19 SRT performance of the different streaming algorithms on the Nvidia A100 40GB GPU with a FP32 single-precision floating-point, One-Step Pull serves as the baseline at (). One-Step Push is slightly slower at (). The AA-Pattern runs with (), Esoteric Twist mitigates the efficiency losses with reduced bandwidth due to implicit bounce-back at (), and Esoteric Pull/Push offer even slightly higher performance at (), due to better memory coalescence for the diagonals that are shifted by one lattice point for Esoteric Twist. Looking at additional performance benchmarks across different hardware configurations (Figure 7), the benefit of less memory bandwidth usage due to implicit bounce-back approximately cancels out the drawback of more inefficient, partially misaligned writes due to the inherent symmetry of the memory access. In comparison with the One-Step-Pull streaming scheme [13], although memory efficiency is lower, performance changes only insignificantly on most dedicated GPUs, with some performance increase for FP32/FP16 mixed precision. On integrated GPUs and on CPUs, however, there is a significant increase in performance due to more efficient use of on-chip cache with in-place memory access. The benchmark case used is an empty box with a default size of , with no extensions enabled except bounce-back boundaries, following [13]. For devices where not enough memory was available, the box size was reduced, and for the AMD Radeon VII, the box size was increased to .
5. Esoteric Pull for Free Surface LBM on GPUs
Here, to further underline the substantial perks of the added simplicity of Esoteric Pull over Esoteric Twist, the modification of existing Free Surface LBM (FSLBM) code from One-Step Pull to Esoteric Pull in-place streaming is briefly discussed using the example of FluidX3D [14].
Although the One-Step-Pull scheme makes an FSLBM implementation the simplest and most efficient, it can easily be modified to the Esoteric Pull in-place streaming scheme. FSLBM on a GPU requires three more kernels in addition to the stream_collide kernel. To distinguish between node types, three flag bits are required and can be represented as follows: fluid (001, F), interface (010, I), gas (100, G), interface→fluid (011, IF), interface→gas (110), and gas→interface (111, GI). These kernels are first introduced for the implementation of One-Step Pull:
- stream_collide: Immediately return for G nodes. Stream in DDFs from neighbors, but for F and I nodes also load outgoing DDFs from the center node to compute the mass transfer for Volume-of-Fluid [67]. Apply excess mass for F or I nodes by summing it from all neighboring F and I nodes. Compute the local surface curvature with PLIC [26] and reconstruct DDFs from neighboring G nodes. After collision, compare mass m and post-collision density ; along with neighboring flags, mark whether the center node should remain I or change to IF or IG. Store post-collision DDFs at the local node.
- surface_1: Prevent neighbors of IF nodes from becoming/being G nodes; update flags of such neighbors to either I (from IF) or GI (from G).
- surface_2: For GI nodes, reconstruct and store DDFs based on the average density and velocity of all neighboring F, I, or IF nodes. For IG nodes, turn all neighboring F or IF nodes to I.
- surface_3: Change IF nodes to F, IG nodes to G, and GI nodes to I. Compute excess mass for each case separately as well as for F, I, and G nodes, then divide the local excess mass by the number of neighboring F, I, IF, and GI nodes and store the excess mass on the local node.
After modifying the streaming scheme from One-Step Pull to Esoteric Pull, a fifth kernel must be added preceding the stream_collide kernel because in the stream_collide kernel, the outgoing DDFs cannot be loaded as neighboring nodes may overwrite them in memory within the same time step (race condition):
- surface_0: Immediately return for G nodes. Stream in DDFs as in Figure 5 (incoming DDFs), but also load outgoing DDFs in opposite directions to compute the mass transfer for Volume-of-Fluid. For I nodes, compute the local surface curvature with PLIC and reconstruct DDFs for neighboring G nodes; store these reconstructed DDFs in the locations at the neighbors from which they will be streamed in in the following stream_collide kernel. Apply excess mass for F or I nodes by summing from all neighboring F and I nodes.
- surface_1, surface_2, surface_3: unchanged
In the surface_0 kernel, additional streaming in inverted directions is necessary to load outgoing DDFs and store reconstructed DDFs for neighboring G nodes. Having to perform manual index calculations here, as with Esoteric Twist, would vastly elongate and over-complicate the code and reduce maintainability. With the Esoteric Pull/Push variants, only two simple loops of four lines of code each are required. The full FSLBM OpenCL C implementation with Esoteric Pull is provided in the Appendix B in Listing A7.
The change to the Esoteric Pull in-place streaming algorithm reduces the memory demand for FSLBM from 181 to 105 Bytes/node while only decreasing performance by approximately due to the duplicate loading of incoming DDFs and having to store reconstructed DDFs for G nodes. When combined with FP32/16-bit mixed precision [13], the memory demand is further reduced to 67 Bytes/node or about of vanilla FSLBM, comparable to or even less than the memory requirements of other (Navier–)Stokes solvers [68,69,70,71].
This, in turn, enables colossal lattice resolutions as illustrated by an example in Figure 8: a (188 lattice point) diameter raindrop, (7700 time steps) after impacting a deep pool at [24] and inclination, was simulated with the FluidX3D implementation with FP32/FP16C mixed precision [13]. Lattice resolution is or 707 million lattice points. The simulation was conducted on an Nvidia Quadro RTX 8000 GPU with video memory and took 27 min, including the rendering of the image. The code for this setup is provided in Appendix C in Listing A8.
6. Conclusions
In-place streaming is essential for any LBM GPU implementation as it significantly reduces memory demand and increases the maximum lattice resolution. However, existing thread-safe solutions for GPUs, such as AA-Pattern and Esoteric Twist, never gained widespread adoption due to the difficulty of implementation. The new Esoteric Pull and Esoteric Push schemes presented in this work should change that. They build upon the same idea as the Esoteric Twist scheme—streaming half of the DDFs at the end of one stream_collide kernel and the other half at the beginning of the next—but greatly simplify the implementation because of their trivial index calculations, even allowing for automatic code generation. For existing GPU implementations of the common One-Step-Pull scheme, the switch to Esoteric Pull requires only moderate modifications to the code, even if several extensions are already implemented, as demonstrated herein with Free Surface LBM. In contrast, the implementation of Esoteric Twist would be much more difficult and error-prone in such a case, as the index calculation has to be implemented twice in different variations for regular LBM streaming and for FSLBM mass exchange.
The Esoteric Pull and Esoteric Push schemes share the same performance advantage as Esoteric Twist over AA-Pattern: slightly reduced bandwidth due to implicit bounce-back. Moreover, compared to Esoteric Twist, memory coalescence is slightly improved on the otherwise shifted diagonal directions. This allows the Esoteric Pull/Push schemes, with only one DDF buffer, to provide GPU performance on par with the One-Step-Pull scheme with double DDF buffers, despite requiring less efficient misaligned writes. In addition, on integrated GPUs and CPUs, performance is significantly increased.
Supplementary Materials
The following supporting information can be downloaded at: https://0-www-mdpi-com.brum.beds.ac.uk/article/10.3390/computation10060092/s1, Video S1: Esoteric Pull in-place streaming with FP16C memory compression.
Funding
This study was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)—Project Number 391977956—SFB 1357.
Data Availability Statement
All data are archived and available upon request. All code beyond what is provided in the listings is archived and available upon reasonable request.
Acknowledgments
I acknowledge support through the computational resources provided by BZHPC, LRZ and JSC. I acknowledge the NVIDIA Corporation for donating a Titan Xp GPU and an A100 40GB GPU for my research. I acknowledge Stephan Gekle for motivating me to write this paper.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LBM | lattice Boltzmann method |
| DDF | density distribution function |
| GPU | graphics processing unit |
| CPU | central processing unit |
| SRT | single-relaxation-time |
| OSP | One-Step Pull/Push |
| AA | AA-Pattern |
| ET | Esoteric Twist |
| EP | Esoteric Pull/Push |
Appendix A. OpenCL C Implementation of the Different Streaming Schemes
Appendix A.1. One-Step Pull
Listing A1. One-Step-Pull implementation in OpenCL C.

Appendix A.2. One-Step Push
Listing A2. One-Step-Push implementation in OpenCL C.


Appendix A.3. AA-Pattern
Listing A3. AA-Pattern implementation in OpenCL C.

Appendix A.4. Esoteric Twist
Listing A4. Esoteric-Twist implementation in OpenCL C.



Appendix A.5. Esoteric Pull
Listing A5. Esoteric Pull implementation in OpenCL C.

Appendix A.6. Esoteric Push
Listing A6. Esoteric Push implementation in OpenCL C.

Appendix B. OpenCL C Implementation of the FSLBM with Esoteric Pull







Appendix C. Setup Script for the Raindrop Impact Simulation
Listing A8. C++ setup script for the raindrop impact simulation in Figure 8.


References
- Krüger, T.; Kusumaatmaja, H.; Kuzmin, A.; Shardt, O.; Silva, G.; Viggen, E.M. The Lattice Boltzmann Method; Springer International Publishing: Cham, Switzerland, 2017; Volume 10, pp. 978–983. [Google Scholar]
- Geier, M.; Schönherr, M. Esoteric twist: An efficient in-place streaming algorithmus for the lattice Boltzmann method on massively parallel hardware. Computation 2017, 5, 19. [Google Scholar] [CrossRef]
- Bailey, P.; Myre, J.; Walsh, S.D.; Lilja, D.J.; Saar, M.O. Accelerating lattice Boltzmann fluid flow simulations using graphics processors. In Proceedings of the 2009 International Conference on Parallel Processing, Vienna, Austria, 22–25 September 2009; pp. 550–557. [Google Scholar]
- Mohrhard, M.; Thäter, G.; Bludau, J.; Horvat, B.; Krause, M. An Auto-Vecotorization Friendly Parallel Lattice Boltzmann Streaming Scheme for Direct Addressing. Comput. Fluids 2019, 181, 1–7. [Google Scholar] [CrossRef]
- Kummerländer, A.; Dorn, M.; Frank, M.; Krause, M.J. Implicit Propagation of Directly Addressed Grids in Lattice Boltzmann Methods. Comput. Fluids 2021. [Google Scholar] [CrossRef]
- Schreiber, M.; Neumann, P.; Zimmer, S.; Bungartz, H.J. Free-surface lattice-Boltzmann simulation on many-core architectures. Procedia Comput. Sci. 2011, 4, 984–993. [Google Scholar] [CrossRef] [Green Version]
- Riesinger, C.; Bakhtiari, A.; Schreiber, M.; Neumann, P.; Bungartz, H.J. A holistic scalable implementation approach of the lattice Boltzmann method for CPU/GPU heterogeneous clusters. Computation 2017, 5, 48. [Google Scholar] [CrossRef] [Green Version]
- Aksnes, E.O.; Elster, A.C. Porous rock simulations and lattice Boltzmann on GPUs. In Parallel Computing: From Multicores and GPU’s to Petascale; IOS Press: Amsterdam, The Netherlands, 2010; pp. 536–545. [Google Scholar]
- Holzer, M.; Bauer, M.; Rüde, U. Highly Efficient Lattice-Boltzmann Multiphase Simulations of Immiscible Fluids at High-Density Ratios on CPUs and GPUs through Code Generation. arXiv 2020, arXiv:2012.06144. [Google Scholar] [CrossRef]
- Duchateau, J.; Rousselle, F.; Maquignon, N.; Roussel, G.; Renaud, C. Accelerating physical simulations from a multicomponent Lattice Boltzmann method on a single-node multi-GPU architecture. In Proceedings of the 2015 10th International Conference on P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC), Krakow, Poland, 4–6 November 2015; pp. 315–322. [Google Scholar]
- Li, W.; Ma, Y.; Liu, X.; Desbrun, M. Efficient Kinetic Simulation of Two-Phase Flows. ACM Trans. Graph. 2022, 41, 114. [Google Scholar]
- Walsh, S.D.; Saar, M.O.; Bailey, P.; Lilja, D.J. Accelerating geoscience and engineering system simulations on graphics hardware. Comput. Geosci. 2009, 35, 2353–2364. [Google Scholar] [CrossRef]
- Lehmann, M.; Krause, M.J.; Amati, G.; Sega, M.; Harting, J.; Gekle, S. On the accuracy and performance of the lattice Boltzmann method with 64-bit, 32-bit and novel 16-bit number formats. arXiv 2021, arXiv:2112.08926. [Google Scholar]
- Lehmann, M. High Performance Free Surface LBM on GPUs. Master’s Thesis, University of Bayreuth, Bayreuth, Germany, 2019. [Google Scholar]
- Takáč, M.; Petráš, I. Cross-Platform GPU-Based Implementation of Lattice Boltzmann Method Solver Using ArrayFire Library. Mathematics 2021, 9, 1793. [Google Scholar] [CrossRef]
- Mawson, M.J.; Revell, A.J. Memory transfer optimization for a lattice Boltzmann solver on Kepler architecture nVidia GPUs. Comput. Phys. Commun. 2014, 185, 2566–2574. [Google Scholar] [CrossRef] [Green Version]
- Delbosc, N.; Summers, J.L.; Khan, A.; Kapur, N.; Noakes, C.J. Optimized implementation of the Lattice Boltzmann Method on a graphics processing unit towards real-time fluid simulation. Comput. Math. Appl. 2014, 67, 462–475. [Google Scholar] [CrossRef]
- Tran, N.P.; Lee, M.; Hong, S. Performance optimization of 3D lattice Boltzmann flow solver on a GPU. Sci. Program. 2017, 1205892. [Google Scholar] [CrossRef] [Green Version]
- Obrecht, C.; Kuznik, F.; Tourancheau, B.; Roux, J.J. Multi-GPU implementation of the lattice Boltzmann method. Comput. Math. Appl. 2013, 65, 252–261. [Google Scholar] [CrossRef]
- Obrecht, C.; Kuznik, F.; Tourancheau, B.; Roux, J.J. A new approach to the lattice Boltzmann method for graphics processing units. Comput. Math. Appl. 2011, 61, 3628–3638. [Google Scholar] [CrossRef] [Green Version]
- Feichtinger, C.; Habich, J.; Köstler, H.; Hager, G.; Rüde, U.; Wellein, G. A flexible Patch-based lattice Boltzmann parallelization approach for heterogeneous GPU–CPU clusters. Parallel Comput. 2011, 37, 536–549. [Google Scholar] [CrossRef] [Green Version]
- Calore, E.; Gabbana, A.; Kraus, J.; Pellegrini, E.; Schifano, S.F.; Tripiccione, R. Massively parallel lattice–Boltzmann codes on large GPU clusters. Parallel Comput. 2016, 58, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Obrecht, C.; Kuznik, F.; Tourancheau, B.; Roux, J.J. Global memory access modelling for efficient implementation of the lattice Boltzmann method on graphics processing units. In Proceedings of the International Conference on High Performance Computing for Computational Science, Berkeley, CA, USA, 22–25 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 151–161. [Google Scholar]
- Lehmann, M.; Oehlschlägel, L.M.; Häusl, F.P.; Held, A.; Gekle, S. Ejection of marine microplastics by raindrops: A computational and experimental study. Microplastics Nanoplastics 2021, 1, 18. [Google Scholar] [CrossRef]
- Laermanns, H.; Lehmann, M.; Klee, M.; Löder, M.G.; Gekle, S.; Bogner, C. Tracing the horizontal transport of microplastics on rough surfaces. Microplastics Nanoplastics 2021, 1, 11. [Google Scholar] [CrossRef]
- Lehmann, M.; Gekle, S. Analytic Solution to the Piecewise Linear Interface Construction Problem and Its Application in Curvature Calculation for Volume-of-Fluid Simulation Codes. Computation 2022, 10, 21. [Google Scholar] [CrossRef]
- Häusl, F. MPI-Based Multi-GPU Extension of the Lattice Boltzmann Method. Bachelor’s Thesis, University of Bayreuth, Bayreuth, Germay, 2019. [Google Scholar]
- Häusl, F. Soft Objects in Newtonian and Non-Newtonian Fluids: A Computational Study of Bubbles and Capsules in Flow. Master’s Thesis, University of Bayreuth, Bayreuth, Germay, 2021. [Google Scholar]
- Limbach, H.J.; Arnold, A.; Mann, B.A.; Holm, C. ESPResSo—An extensible simulation package for research on soft matter systems. Comput. Phys. Commun. 2006, 174, 704–727. [Google Scholar] [CrossRef]
- Institute for Computational Physics, Universität Stuttgart. ESPResSo User’s Guide. 2016. Available online: http://espressomd.org/wordpress/wp-content/uploads/2016/07/ug_07_2016.pdf (accessed on 15 June 2018).
- Hong, P.Y.; Huang, L.M.; Lin, L.S.; Lin, C.A. Scalable multi-relaxation-time lattice Boltzmann simulations on multi-GPU cluster. Comput. Fluids 2015, 110, 1–8. [Google Scholar] [CrossRef]
- Xian, W.; Takayuki, A. Multi-GPU performance of incompressible flow computation by lattice Boltzmann method on GPU cluster. Parallel Comput. 2011, 37, 521–535. [Google Scholar] [CrossRef]
- Ho, M.Q.; Obrecht, C.; Tourancheau, B.; de Dinechin, B.D.; Hascoet, J. Improving 3D Lattice Boltzmann Method stencil with asynchronous transfers on many-core processors. In Proceedings of the 2017 IEEE 36th International Performance Computing and Communications Conference (IPCCC), San Diego, CA, USA, 10–12 December 2017; pp. 1–9. [Google Scholar]
- Habich, J.; Feichtinger, C.; Köstler, H.; Hager, G.; Wellein, G. Performance engineering for the lattice Boltzmann method on GPGPUs: Architectural requirements and performance results. Comput. Fluids 2013, 80, 276–282. [Google Scholar] [CrossRef] [Green Version]
- Tölke, J.; Krafczyk, M. TeraFLOP computing on a desktop PC with GPUs for 3D CFD. Int. J. Comput. Fluid Dyn. 2008, 22, 443–456. [Google Scholar] [CrossRef]
- Herschlag, G.; Lee, S.; Vetter, J.S.; Randles, A. GPU data access on complex geometries for D3Q19 lattice Boltzmann method. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Vancouver, BC, Canada, 21–25 May 2018; pp. 825–834. [Google Scholar]
- de Oliveira, W.B., Jr.; Lugarini, A.; Franco, A.T. Performance analysis of the lattice Boltzmann method implementation on GPU. In Proceedings of the XL Ibero-Latin-American Congress on Computational Methods in Engineering, ABMEC, Natal, Brazil, 11–14 November 2019. [Google Scholar]
- Rinaldi, P.R.; Dari, E.; Vénere, M.J.; Clausse, A. A Lattice-Boltzmann solver for 3D fluid simulation on GPU. Simul. Model. Pract. Theory 2012, 25, 163–171. [Google Scholar] [CrossRef]
- Rinaldi, P.R.; Dari, E.A.; Vénere, M.J.; Clausse, A. Fluid Simulation with Lattice Boltzmann Methods Implemented on GPUs Using CUDA. In Proceedings of the HPCLatAm 2009, Buenos Aires, Argentina, 26–27 August 2009. [Google Scholar]
- Ames, J.; Puleri, D.F.; Balogh, P.; Gounley, J.; Draeger, E.W.; Randles, A. Multi-GPU immersed boundary method hemodynamics simulations. J. Comput. Sci. 2020, 44, 101153. [Google Scholar] [CrossRef]
- Xiong, Q.; Li, B.; Xu, J.; Fang, X.; Wang, X.; Wang, L.; He, X.; Ge, W. Efficient parallel implementation of the lattice Boltzmann method on large clusters of graphic processing units. Chin. Sci. Bull. 2012, 57, 707–715. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Xu, X.; Huang, G.; Qin, Z.; Wen, B. An Efficient Graphics Processing Unit Scheme for Complex Geometry Simulations Using the Lattice Boltzmann Method. IEEE Access 2020, 8, 185158–185168. [Google Scholar] [CrossRef]
- Kuznik, F.; Obrecht, C.; Rusaouen, G.; Roux, J.J. LBM based flow simulation using GPU computing processor. Comput. Math. Appl. 2010, 59, 2380–2392. [Google Scholar] [CrossRef] [Green Version]
- Horga, A. With Lattice Boltzmann Models Using CUDA Enabled GPGPUs. Master’s Thesis, University of Timsoara, Timsoara, Romania, 2013. [Google Scholar]
- Geveler, M.; Ribbrock, D.; Göddeke, D.; Turek, S. Lattice-Boltzmann simulation of the shallow-water equations with fluid-structure interaction on multi-and manycore processors. In Facing the Multicore-Challenge; Springer: Wiesbaden, Germany, 2010; pp. 92–104. [Google Scholar]
- Beny, J.; Latt, J. Efficient LBM on GPUs for dense moving objects using immersed boundary condition. arXiv 2019, arXiv:1904.02108. [Google Scholar]
- Tekic, P.M.; Radjenovic, J.B.; Rackovic, M. Implementation of the Lattice Boltzmann method on heterogeneous hardware and platforms using OpenCL. Adv. Electr. Comput. Eng. 2012, 12, 51–56. [Google Scholar] [CrossRef]
- Bény, J.; Kotsalos, C.; Latt, J. Toward full GPU implementation of fluid-structure interaction. In Proceedings of the 2019 18th International Symposium on Parallel and Distributed Computing (ISPDC), Amsterdam, The Netherlands, 3–7 June 2019; pp. 16–22. [Google Scholar]
- Boroni, G.; Dottori, J.; Rinaldi, P. FULL GPU implementation of lattice-Boltzmann methods with immersed boundary conditions for fast fluid simulations. Int. J. Multiphysics 2017, 11, 1–14. [Google Scholar]
- Griebel, M.; Schweitzer, M.A. Meshfree Methods for Partial Differential Equations II; Springer: Cham, Switzerland, 2005. [Google Scholar]
- Zitz, S.; Scagliarini, A.; Harting, J. Lattice Boltzmann simulations of stochastic thin film dewetting. Phys. Rev. E 2021, 104, 034801. [Google Scholar] [CrossRef] [PubMed]
- Janßen, C.F.; Mierke, D.; Überrück, M.; Gralher, S.; Rung, T. Validation of the GPU-accelerated CFD solver ELBE for free surface flow problems in civil and environmental engineering. Computation 2015, 3, 354–385. [Google Scholar] [CrossRef] [Green Version]
- Habich, J.; Zeiser, T.; Hager, G.; Wellein, G. Performance analysis and optimization strategies for a D3Q19 lattice Boltzmann kernel on nVIDIA GPUs using CUDA. Adv. Eng. Softw. 2011, 42, 266–272. [Google Scholar] [CrossRef]
- Calore, E.; Marchi, D.; Schifano, S.F.; Tripiccione, R. Optimizing communications in multi-GPU Lattice Boltzmann simulations. In Proceedings of the 2015 International Conference on High Performance Computing & Simulation (HPCS), Amsterdam, The Netherlands, 20–24 July 2015; pp. 55–62. [Google Scholar]
- Onodera, N.; Idomura, Y.; Uesawa, S.; Yamashita, S.; Yoshida, H. Locally mesh-refined lattice Boltzmann method for fuel debris air cooling analysis on GPU supercomputer. Mech. Eng. J. 2020, 7, 19–00531. [Google Scholar] [CrossRef] [Green Version]
- Falcucci, G.; Amati, G.; Fanelli, P.; Krastev, V.K.; Polverino, G.; Porfiri, M.; Succi, S. Extreme flow simulations reveal skeletal adaptations of deep-sea sponges. Nature 2021, 595, 537–541. [Google Scholar] [CrossRef]
- Zitz, S.; Scagliarini, A.; Maddu, S.; Darhuber, A.A.; Harting, J. Lattice Boltzmann method for thin-liquid-film hydrodynamics. Phys. Rev. E 2019, 100, 033313. [Google Scholar] [CrossRef] [Green Version]
- Wei, C.; Zhenghua, W.; Zongzhe, L.; Lu, Y.; Yongxian, W. An improved LBM approach for heterogeneous GPU-CPU clusters. In Proceedings of the 2011 4th International Conference on Biomedical Engineering and Informatics (BMEI), Shanghai, China, 15–17 October 2011; Volume 4, pp. 2095–2098. [Google Scholar]
- Gray, F.; Boek, E. Enhancing computational precision for lattice Boltzmann schemes in porous media flows. Computation 2016, 4, 11. [Google Scholar] [CrossRef] [Green Version]
- Wellein, G.; Lammers, P.; Hager, G.; Donath, S.; Zeiser, T. Towards optimal performance for lattice Boltzmann applications on terascale computers. In Parallel Computational Fluid Dynamics 2005; Elsevier: Amsterdam, The Netherlands, 2006; pp. 31–40. [Google Scholar]
- Wittmann, M.; Zeiser, T.; Hager, G.; Wellein, G. Comparison of different propagation steps for lattice Boltzmann methods. Comput. Math. Appl. 2013, 65, 924–935. [Google Scholar] [CrossRef]
- Wittmann, M. Hardware-effiziente, hochparallele Implementierungen von Lattice-Boltzmann-Verfahren für komplexe Geometrien. Ph.D. Thesis, Friedrich-Alexander-Universität, Erlangen, Germany, 2016. [Google Scholar]
- Krause, M. Fluid Flow Simulation and Optimisation with Lattice Boltzmann Methods on High Performance Computers: Application to the Human Respiratory System. Ph.D. Thesis, Karlsruhe Institute of Technology (KIT), Universität Karlsruhe (TH), Karlsruhe, Germany, 2010. Available online: https://publikationen.bibliothek.kit.edu/1000019768 (accessed on 20 February 2019).
- Succi, S.; Amati, G.; Bernaschi, M.; Falcucci, G.; Lauricella, M.; Montessori, A. Towards exascale lattice Boltzmann computing. Comput. Fluids 2019, 181, 107–115. [Google Scholar] [CrossRef]
- D’Humières, D. Multiple–relaxation–time lattice Boltzmann models in three dimensions. Philos. Trans. R. Soc. London. Ser. A Math. Phys. Eng. Sci. 2002, 360, 437–451. [Google Scholar] [CrossRef]
- Latt, J. Technical Report: How to Implement Your DdQq Dynamics with Only q Variables per Node (Instead of 2q); Tufts University: Medford, MA, USA, 2007; pp. 1–8. [Google Scholar]
- Bogner, S.; Rüde, U.; Harting, J. Curvature estimation from a volume-of-fluid indicator function for the simulation of surface tension and wetting with a free-surface lattice Boltzmann method. Phys. Rev. E 2016, 93, 043302. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Crane, K.; Llamas, I.; Tariq, S. Real-Time Simulation and Rendering of 3d Fluids; GPU gems 3.1, Addison-Wesley Professional: Boston, MA, USA, 2007; Volume 3. [Google Scholar]
- Gerace, S. A Model Integrated Meshless Solver (MIMS) for Fluid Flow and Heat Transfer. Ph.D. Thesis, University of Central Florida, Orlando, FL, USA, 2010. [Google Scholar]
- Lynch, C.E. Advanced CFD Methods for Wind Turbine Analysis; Georgia Institute of Technology: Atlanta, GA, USA, 2011. [Google Scholar]
- Keßler, A. Matrix-Free Voxel-Based Finite Element Method for Materials with Heterogeneous Microstructures. Ph.D. Thesis, der Bauhaus-Universität Weimar, Weimar, Germnay, 2019. [Google Scholar]
Figure 1.
One-Step-Pull streaming scheme. Two copies of the DDFs are used to resolve data dependencies.
Figure 1.
One-Step-Pull streaming scheme. Two copies of the DDFs are used to resolve data dependencies.

Figure 2.
One-Step-Push streaming scheme. Two copies of the DDFs are used to resolve data dependencies.
Figure 2.
One-Step-Push streaming scheme. Two copies of the DDFs are used to resolve data dependencies.

Figure 3.
AA-Pattern in-place streaming scheme [3]. Even time steps: DDFs are pulled in from neighbors, collided, and then pushed out to the neighbors again, but stored in opposite orientation. Odd time steps: DDFs are loaded from the center node in opposite orientation, collided, and stored at the center node again in the same orientation as during collision. DDFs are always stored in the same memory locations where they were loaded from, so only one copy of the DDFs is required.
Figure 3.
AA-Pattern in-place streaming scheme [3]. Even time steps: DDFs are pulled in from neighbors, collided, and then pushed out to the neighbors again, but stored in opposite orientation. Odd time steps: DDFs are loaded from the center node in opposite orientation, collided, and stored at the center node again in the same orientation as during collision. DDFs are always stored in the same memory locations where they were loaded from, so only one copy of the DDFs is required.

Figure 4.
Esoteric Twist in-place streaming scheme [2]. Even time steps: DDFs are loaded in a criss-cross pattern shifted north-east by half a node. After collision, DDFs are stored in the same pattern but in opposite orientation. Odd time steps: DDFs are loaded in opposite orientation in a shifted criss-cross pattern that covers only DDFs not touched in the even time step. After collision, DDFs are written back in the same pattern but with regular orientation once again. DDFs are always stored in the same memory locations where they were loaded from, so only one copy of the DDFs is required.
Figure 4.
Esoteric Twist in-place streaming scheme [2]. Even time steps: DDFs are loaded in a criss-cross pattern shifted north-east by half a node. After collision, DDFs are stored in the same pattern but in opposite orientation. Odd time steps: DDFs are loaded in opposite orientation in a shifted criss-cross pattern that covers only DDFs not touched in the even time step. After collision, DDFs are written back in the same pattern but with regular orientation once again. DDFs are always stored in the same memory locations where they were loaded from, so only one copy of the DDFs is required.

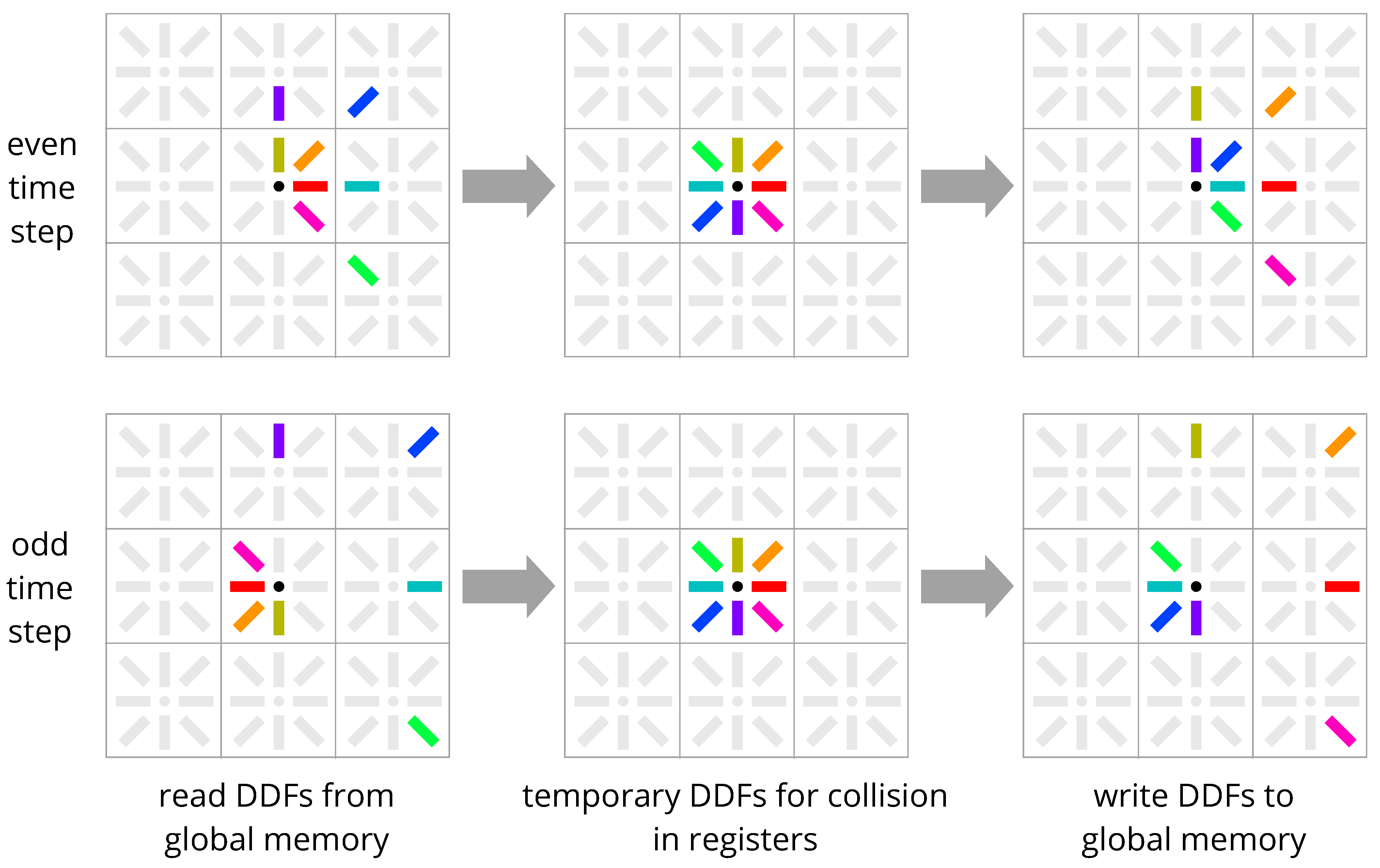
Figure 5.
Esoteric Pull in-place streaming scheme. Even time steps: DDFs in positive directions are loaded from the center node, and DDFs from negative directions are pulled in from their regular streaming direction neighbors and are collided. Then, DDFs in positive directions are pushed out to neighbors and stored in opposite orientation, and DDFs in negative directions are stored at the center node in opposite orientation. Odd time steps: DDFs in positive directions are loaded from the center node in opposite orientation, and DDFs from negative directions are pulled in from their regular streaming direction neighbors in opposite orientation and are collided. Then, DDFs in positive directions are pushed out to neighbors, and DDFs in negative directions are stored at the center node. DDFs are always stored in the same memory locations where they were loaded from, so only one copy of the DDFs is required.
Figure 5.
Esoteric Pull in-place streaming scheme. Even time steps: DDFs in positive directions are loaded from the center node, and DDFs from negative directions are pulled in from their regular streaming direction neighbors and are collided. Then, DDFs in positive directions are pushed out to neighbors and stored in opposite orientation, and DDFs in negative directions are stored at the center node in opposite orientation. Odd time steps: DDFs in positive directions are loaded from the center node in opposite orientation, and DDFs from negative directions are pulled in from their regular streaming direction neighbors in opposite orientation and are collided. Then, DDFs in positive directions are pushed out to neighbors, and DDFs in negative directions are stored at the center node. DDFs are always stored in the same memory locations where they were loaded from, so only one copy of the DDFs is required.

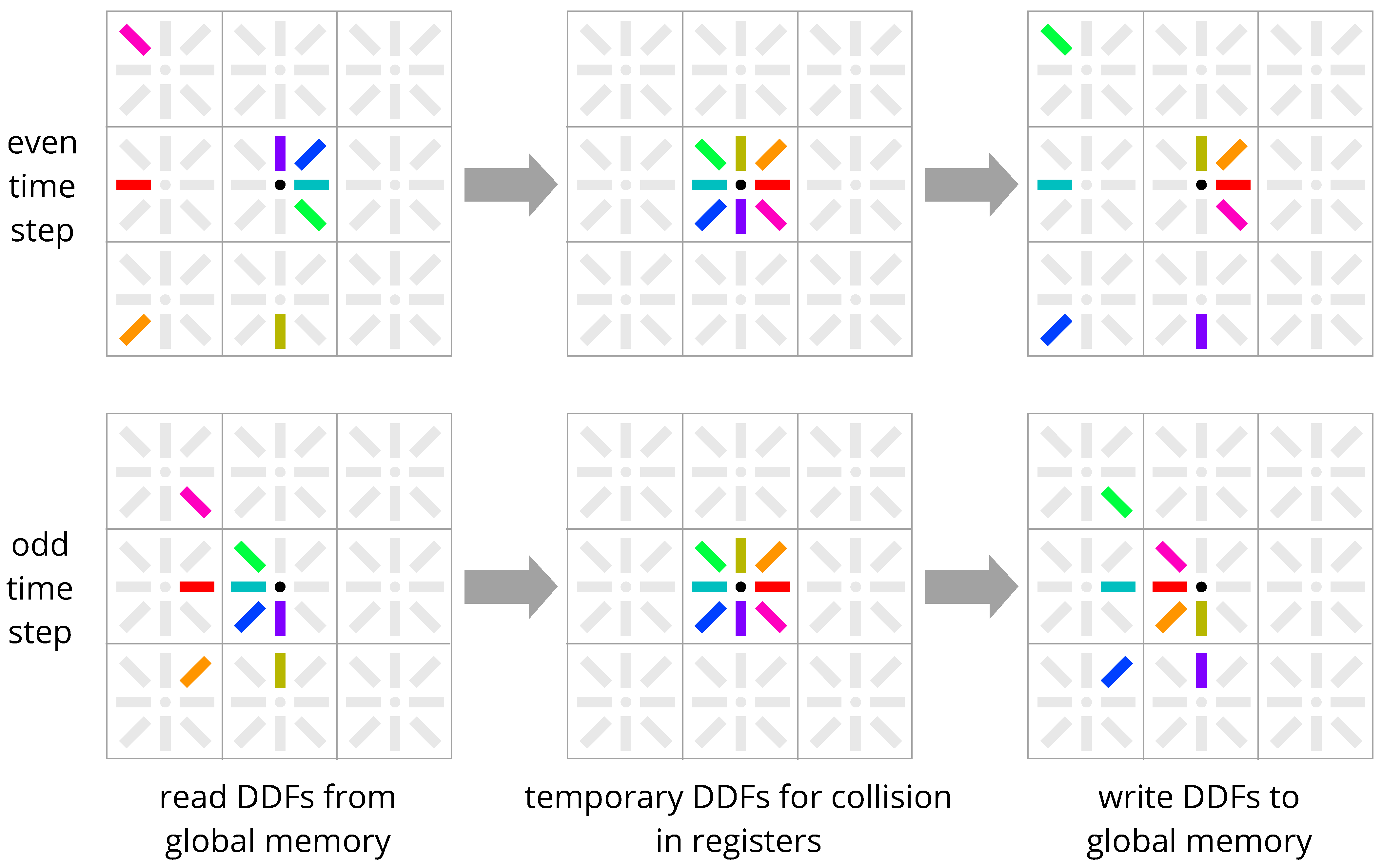
Figure 6.
Esoteric Push in-place streaming scheme. Figure 5 flipped by 180 degrees (except for the temporary DDFs in registers).
Figure 6.
Esoteric Push in-place streaming scheme. Figure 5 flipped by 180 degrees (except for the temporary DDFs in registers).

Figure 7.
Performance of Esoteric Pull with D3Q19 SRT on different hardware configurations in the FluidX3D OpenCL implementation, in million lattice updates per second (MLUPs/s). Efficiency is calculated by dividing the measured MLUPs/s by the data sheet memory bandwidth times the number of bytes transferred per lattice point and time step (Table 1). CPU benchmarks are on all cores. Performance comparison with the One-Step-Pull streaming scheme [13] shows only insignificant differences on most dedicated GPUs, but large gains on integrated GPUs and CPUs.
Figure 7.
Performance of Esoteric Pull with D3Q19 SRT on different hardware configurations in the FluidX3D OpenCL implementation, in million lattice updates per second (MLUPs/s). Efficiency is calculated by dividing the measured MLUPs/s by the data sheet memory bandwidth times the number of bytes transferred per lattice point and time step (Table 1). CPU benchmarks are on all cores. Performance comparison with the One-Step-Pull streaming scheme [13] shows only insignificant differences on most dedicated GPUs, but large gains on integrated GPUs and CPUs.

Figure 8.
Esoteric Pull in-place streaming with FP16C memory compression [13] enables a colossal lattice resolution on a single GPU, such as demonstrated here with a raindrop impact simulation. This figure is included in the Supplementary Files as a video.
Figure 8.
Esoteric Pull in-place streaming with FP16C memory compression [13] enables a colossal lattice resolution on a single GPU, such as demonstrated here with a raindrop impact simulation. This figure is included in the Supplementary Files as a video.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparing memory storage (Bytes/node) and bandwidth (Bytes/node per time step) requirements of the different GPU-compatible streaming algorithms for DdQq LBM with FP32 arithmetic precision and eight available flag bits per node. With the in-place streaming and implicit bounce-back of the Esoteric schemes, and with FP32/16-bit mixed precision as proposed in [13], memory demands and bandwidth are significantly reduced.
Table 1.
Comparing memory storage (Bytes/node) and bandwidth (Bytes/node per time step) requirements of the different GPU-compatible streaming algorithms for DdQq LBM with FP32 arithmetic precision and eight available flag bits per node. With the in-place streaming and implicit bounce-back of the Esoteric schemes, and with FP32/16-bit mixed precision as proposed in [13], memory demands and bandwidth are significantly reduced.
| Algorithm | Storage | Bandwidth |
|---|---|---|
| One-Step Pull | ||
| One-Step Push | ||
| AA-Pattern | ||
| Esoteric Twist | ||
| Esoteric Pull | ||
| Esoteric Push | ||
| OSP + FP32/16-bit | ||
| AA + FP32/16-bit | ||
| ET/EP + FP32/16-bit |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lehmann, M. Esoteric Pull and Esoteric Push: Two Simple In-Place Streaming Schemes for the Lattice Boltzmann Method on GPUs. Computation 2022, 10, 92. https://0-doi-org.brum.beds.ac.uk/10.3390/computation10060092
AMA Style
Lehmann M. Esoteric Pull and Esoteric Push: Two Simple In-Place Streaming Schemes for the Lattice Boltzmann Method on GPUs. Computation. 2022; 10(6):92. https://0-doi-org.brum.beds.ac.uk/10.3390/computation10060092
Chicago/Turabian StyleLehmann, Moritz. 2022. "Esoteric Pull and Esoteric Push: Two Simple In-Place Streaming Schemes for the Lattice Boltzmann Method on GPUs" Computation 10, no. 6: 92. https://0-doi-org.brum.beds.ac.uk/10.3390/computation10060092
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.