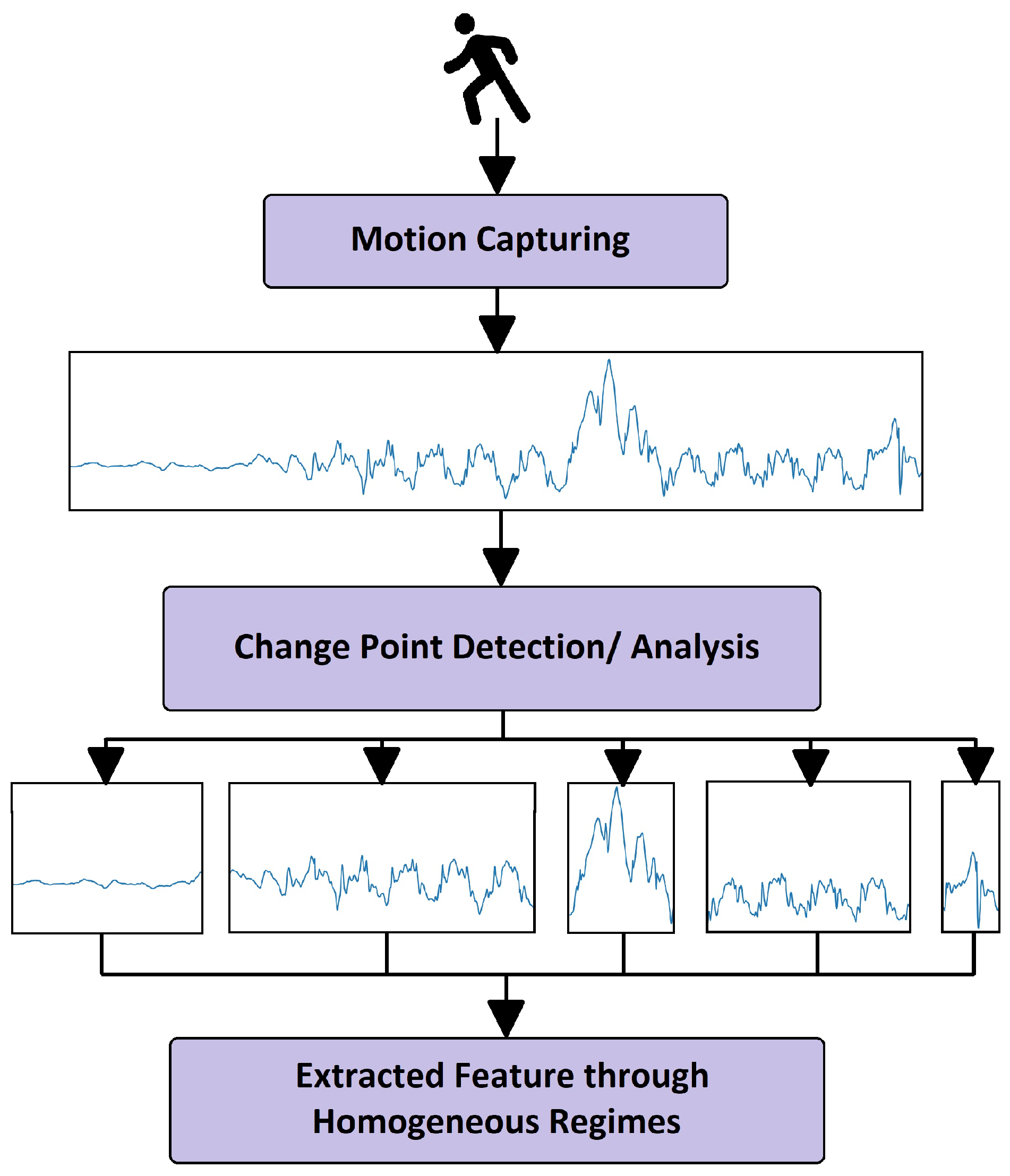
1. Introduction
Machine learning, a substitute for artificial intelligence, is a pivotal part of modern computer society. It involves scientific and algorithmic techniques that are specifically designed to curb user involvement and thus increase the automaticity of the desired work. Nowadays, most computer systems are built for performing general or business-specific tasks through machine learning technologies. Evidence of their applications can be seen in problem domains such as in the medical field, policy-making [
1], fraud detection [
2,
3,
4], and signal processing [
5,
6]. Different machine learning models, also known as mathematical models, possess different attributes that produce accurate results using prediction calculations when exposed to a given dataset. Many accurate decision support systems have been built as black boxes in recent years, i.e., systems that hide their internal logic from the end- user during the estimation process that containing dozens of parameters and other complex formulations for making predictions.
A black box model can either be a function that is excessively complex for humans to understand or a function in whose noisy data are extremely difficult for humans to uncover, potentially leading to incorrect predictions. Deep learning models, gradient boosting or random forest are extremely recursive in nature which is why they are called black box models. Here, an explanation is a distinct model that is expected to duplicate most of the behavior of a black box, which is the most popular sense in which the term is currently used; in this research, however, the term explanation refers to an understanding of how a model of machine learning systems works [
7].
Interpretable machine learning refers to machine learning models that can provide explanations regarding why certain predictions are made. This is also known as white box/glass box models which are comparatively much easier to understand and audit than complex/black box models. Traditional machine learning metrics such as AUC, accuracy and recall may not be sufficient in many applications where user trust in a machine’s predictions is required. Although there is no mathematical definition of interpretability, [
8] found that ’Interpretability is the degree to which a human can understand the cause of a decision’. Similarly, [
9] found that ’Interpretability is the degree to which a human can consistently predict the model’s result’. Thus, to summarize the previous statements, one can say that if a machine learning model has higher interpretability, then comprehending the behavior behind the prediction that the black box model has made will be easier. Generally, there are two categories of interpretable approaches: one focuses on personalized interpretation, a situation in which the specific prediction of a specific instance is interrogated, called local interpretability, while the second summarizes prediction models at a population level which means that we can understand the whole logic and reasoning of an entire model consisting of all possible outcomes—what we call global interpretability [
10].
In this article, black box models refer to models that are not directly understandable by the end-user which are complex due to a large number of parameters or rules involved that give it higher accuracy. In contrast, simple models are models that comprise fewer parameters or have less rules (tree-based classifiers with medium depth), thus enabling the end-user to understand and adjust them according to their rationales; these are considered easily understandable by humans. If we specify examples of complex models, these include: random forest (RF) [
11]; support vector machines (SVMs) [
12]; gradient boosting (GB) [
13]; deep neural networks (DNNs) [
14,
15]. Meanwhile, simple/glass box/white box models (sometimes called interpretable models [
16]) include decision trees (DT) [
17]; and linear regression (LR)/logistic regression (LOR) [
18].
There are several sensitive applications [
19,
20,
21,
22] for which an explanation behind the prediction is essential. Therefore, in the absence of explanation, no one can simply rely on machines. Another downfall of using is the possibility of making the drawing an incorrect prediction from the artifacts (data), thus affecting the overall performance of the machine’s efficiency [
23].
The availability of transparency in machine learning predictions could foster awareness of and some level of trust in machines. Moreover, the trade-off factor between the interpretability and accuracy of the model while mimicking the black box models for an explanation is indeed another gap to address when explaining the complex/black box models—b. Sometimes, such tasks are computationally expensive as well.
This research work focuses on explaining the black box model via some available interpretable methods without compromising the accuracy of the black box for multiple problem domains such as classification and regression. This will eventually gain the trust of the end-user. This requires some methodology that contains certain mathematical techniques which will assist us in performing multiple tasks at a time. These tasks include dealing with trade-off factors as mentioned earlier, automatic feature engineering tasks for feature transformation and mimicking the underlying black box model in a way that is directly comprehensible by humans as an explanation.
For the sake of the transparency of the black box, we follow these two most important concerns in a machine learning paradigm. First, describing how black box models work (capturing the behavior) and secondly, explaining that captured behavior in human-understandable language. In brief, we can say that explanation is the core priority for describing how a black box model works. In this research work, we denote the complex/black box as b. b is an obscure machine learning and data mining model whose inner working is unknown—or if it is known, then it is not understandable by humans. To interpret means to provide an explanation or meaning and present it in human-understandable terms. Hence, machine learning models are interpretable models when b is complex in nature but understandable by humans. Thus, if these conditions are satisfied, then the underlying machine learning model is interpretable. Interpretable models, henceforth, build trust and encourage users to use them to take decisions according to what the machine has estimated. After considering the previous statements, we achieved results with higher accuracy that were also interpretable. The technique we propose is capable of acknowledging both the regression and classification problem domains.
Explainability is usually referred to as an interface between the decision maker and humans that is an accurate proxy and comprehensible by humans at the same time. Comprehensibility means that humans can understand why the machine has made a specific prediction and what specific prediction it has made before taking decisions accordingly, which means that if any changes are required, then humans can easily incorporate them after knowing the reasoning behind the predictions. (We will be interchangeably using the term comprehensibility with interpretability in this work.) Thus, the main motivation behind a such research work was to make a black box model (in which the internal behavior is almost impossible to trace) interpretable/auditable/understandable/explainable/comprehensible [
24].
Now, coming to the general problem formulation for the interpretable machine learning model paradigm, the predictor could mathematically be defined as
where
b is the predictor/black box model which allows the mapping of tuples
x from a feature space
along with
m inputs to decision
y in a target space
Y. We can write
as a decision made by a
b. Thus,
b is basically a target to model in order to interpret how the model is making predictions upon a given dataset
. In supervised learning, the predictor
b is trained on data
and then evaluated upon feeding test data
. The accuracy is then measured on the basis of matches between
and
. If the difference between them is the lowest or equal to none, then model
b is efficient in its performance.
The factor that contributes in model interpretation is the interpretable predictor
C which is processed with the motivation that it will yield a decision
for a symbolic interpretation understandable/comprehensible by humans. The extent to which
C is accurate can be determined by comparing the accuracy of both
b and
C over
and secondly fidelity, which evaluates that how well
C has mimicked the predictor
b upon the given
. We can formally denote fidelity by
Note that C is regarded as interpretable and is also known as the white box model as mentioned earlier.
We then need to understand how the black box b explanation can be practically implemented in a way that would be able to provide a global explanation through an interpretable model C. This means that we need to produce a surrogate model f that can imitate the behavior of b and should be understandable by humans through some explanatory model . We can also formalize this problem by assuming that the interpretable global predictor is derived from some dataset of instances X and the black box b. The user will provide some dataset X for the sampling of the domain which may include actual values which will allow the evaluation of the accuracy of the interpretable model. b will thus be trained on dataset X. The process for extracting the interpretable predictor could further expand X. Hence, we can organize the whole model explanation problem as: ‘Given a predictor b and a set of instances X, the surrogate model f assists in explaining via some explanator
where is the domain directly comprehensible by humans with the help of an interpretable global predictor = that is derived from b and the instances X using some process f(·, ·) as the surrogate function. Then, an explanation E is obtained through , if E = ’.
1.1. Scope and Objective
To interpret the black box model b, a surrogate function , approximates the behavior of b by mimicking it as accurately as possible (or performing even better) in terms of the available performance measurement tools. The methodology includes feature transformation from X to . Then, the explanation is produced through an explanator which will enable the end-user to comprehend how b is behaving upon giving inputs (features). Henceforth, the main objective of this research is to make the black box model interpretable through a proposed technique that is computationally cheaper than those proposed in previous work(s), supports the automatic feature engineering task, ensures the trade-off between interpretability and accuracy and acknowledges both the classification as well as the regression problem domains. This led us to build a surrogate model that is capable of mimicking and explaining the behavior of the underlying black box model.
1.2. Problem Statements
Comprehending the black box machine learning model’s behavior is difficult which hinders the end-user’s willingness to take further decisions based on the machine’s prediction. If interpretability is achieved, then there is a trade-off between the interpretability and accuracy of a model [
25,
26] which is another critical problem. According to [
27,
28], the interpretability of a model decreases if we are not willing to compromise the actual accuracy of the learning model. In other words, these two factors—interpretability and accuracy—are inversely proportional to each other and can be mathematically described as
In Equation (
3),
denoted accuracy,
M is the underlying machine learning model and in this article, we set it as
b, as discussed in detail in the previous subsection and
is the interpretation extracted for model
M. Furthermore, this problem is also visually described in
Figure 1.
The main reason for such setback was the difficulty entailed in exploring and understanding all the parameters involved in providing the higher accuracy
of complex models. The explanation
of the estimated behavior of
b is another cumbersome phase where the explanation is provided or produced by function
f is either comprehensible by humans or not. On the other hand, the execution time for approximating [
29,
30,
31]
b through
which is approximately equal to
is indeed another crucial point of the machine learning model’s interpretability while dealing with a large volume of available data. Thus, we can summarize our problem as follows: we need to produce a surrogate function
that can assist in building an interpretation for
b through some
after approximating via
and a blank equation would be:
Finding Equation (
4) is the backbone of this whole research. This equation has already been discussed in textual format.
1.3. Research Contribution
We considered different datasets from different resources elaborated in
Section 4 in which insights into the datasets are provided. Moreover, these datasets belong to both classification and regression problem domains. With the help of the surrogate model, we were able to perform automatic feature engineering tasks. Then,
b was mimicked with the assistance of available global surrogate methods (elaborated in
Section 3.6)—also known as white box models—before providing an explanation that is comprehensible for end-users. While mimicking the underlying
b, in most cases, our proposed methodology outperforms the
b which means that we accomplished our objective of retaining the high accuracy of the model and explaining the inner working of
b in a way that simultaneously exposes how
b acts when exposed to the specific features of the original dataset.
There are several areas in which interpretation is necessary because of the legal requirements by target area [
32]. Interpretability thus encourages the development of the analysis of interpretable patterns from trained models by allowing one to identify the causes behind poor predictions by machines. If
b becomes comprehensible by the end-user, it will surely engender trust in machines and help users detect biasness in machine learning models—as we are doing herein.
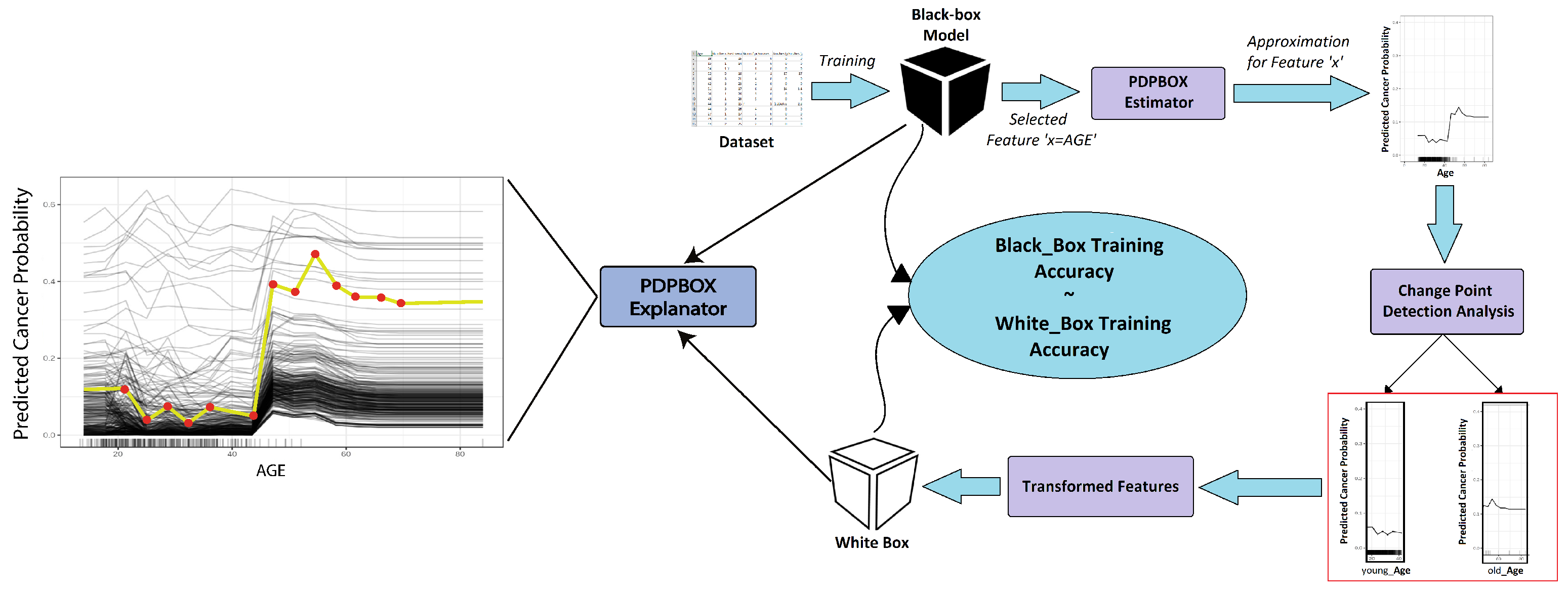
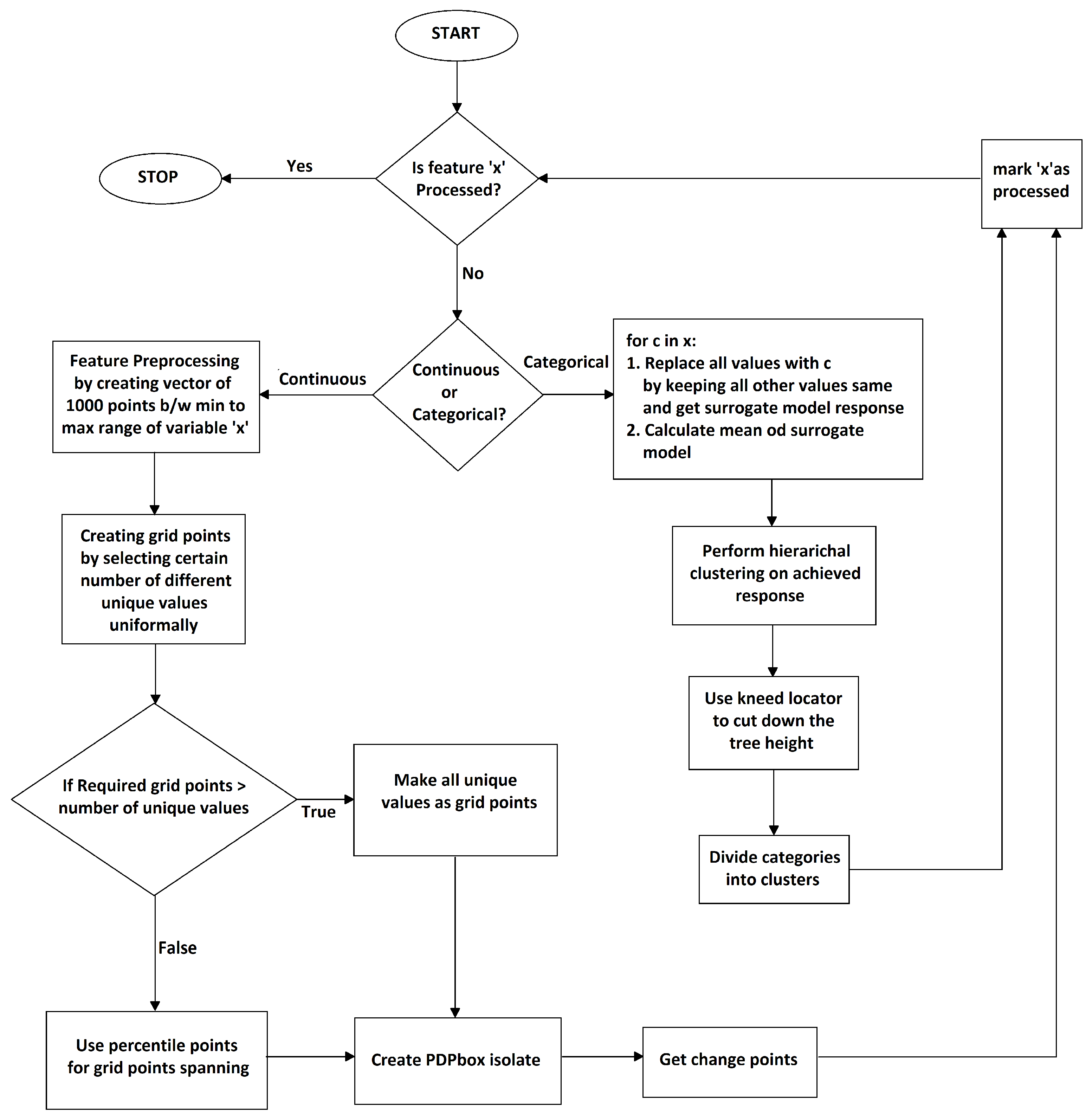
In this work, we propose a technique called enhanced surrogate-assisted feature engineering (ESAFE) for machine learning models, which is an extension of surrogate-assisted feature extraction for model learning (SAFE ML) [
33]. It will address all such issues that general interpretable desiderata (explained in
Section 3.1), which requires the incorporation of Equations (
1) and (
2).
With the help of technique [
34], the proposed methodology achieved a drastic change in terms of computational cost whilst simultaneously respecting all the constraints mentioned in the interpretable desiderata
Section 3.1. This technique will help us build
. The surrogate model
f will assist us in transforming features
and thus produce
as a result. With enhanced visual interpretability accurately imitating quality and without compromising the accuracy of the machine learning model, we hereby provide a novel technique in the form of the Python package so that the end-user may be satisfied with its results. This will enable the end-user to ascertain different features of the relationships and their effects on the overall prediction of
b.
The significance of such a technique is to assist the end-user in terms of ensuring the explainability of b’s inner workings—rendering it auditable and the data scientist comfortable with skipping the time-consuming process of undertaking a feature engineering task. Therefore, both communities would enjoy ESAFE’s multifaceted features.
1.4. Paper Orientation
This paper is organized as follows.
Section 2 discusses related work. The working of the proposed algorithm is presented in
Section 3.6. The results and benchmarks are discussed in detail in
Section 4. The conclusion and future extensions are elaborated in
Section 5. The references are provided at the end of the paper.
2. Related Work
In this section, the aim was to critically analyze several studies related to machine learning model interpretability and identify the gaps of previous research. Moreover, we will compare the different techniques proposed by different authors with respect to their distinct dimensions which are adjacently compared in tabular form (as can be seen in
Table 1).
In [
35], the authors proposed a methodology called single-tree approximation (STA), which was an extension of [
36]. The research work aimed to resolve the issue arising when machine learning models encounter a problem in the trade-off between predictive accuracy and model interpretability. They tackled this issue by using DT for explanation
, and adopting the same DT technique as a global predictor/estimator
for mimicking purposes. They aimed to explain RF as a black box
b. STA leveraged them in the construction of the final decision tree
through testing a hypothesis to understand the best splits for Gini indexes in the RF
b. Consequently, this allowed inspection under such produced oracle settings. They further incorporated such a test in building a tree to ensure the stability and performance of their approximation trees. Moreover, they also presented the interpretability of their procedure on real data for the validation and response times of their technique which was quite fast. Without compromising accuracy, they achieved higher interpretability. Their technique, however, works well on classification problems as it was solely made for classification domains but not for regression problems. The authors also claimed that their approach was generalizable, which means it is capable of explaining any
b, but no proof is mentioned or simulated in their article. They briefly explained their methodology which consisted of reflecting the main purposes of the surrogate model, as their technique was capable of accurately mimicking the behavior of the black box model.
In [
37], the approach
f was based on a recommendation produced by the RF model
b for the transformation of true negative examples into positively predicted examples by shifting their position in the feature space
X. The authors of the article also highlighted a similar problem, mentioned in the previous subsection, of frequently having to sacrifice models’ prediction power in favor of making their interpretable. They also targeted another interesting flaw in machine learning interpretability that is feature engineering which they (authors) had to prioritize as the most time-consuming task. This article represented the problem of adjusting the specific features of interest by modifying them through their proposed technique and then altered a prediction upon mutating an instance by inputting it back to the model after prediction. This phenomenon, however, involved human interaction to some extent but was helpful for the end-user as it eventually increased trust in machines. Their proposed technique basically exploits the inner working of ensemble tree-based classifiers that provide recommendations for the transformation of true negative instances into positively predicted examples. For the validity of their approach, they used an online advertising application and processed the RF classifier to separate the different ads into low- (negative) and high- (positive) quality ads (examples). Then, in the following process, they applied their surrogate model
f to the recommendation process. They only used one problem domain and their approach was restricted to only one problem of one domain, i.e., the advertisement application of the Yahoo Gemini4 advertisement network in the classification domain.
Partition aware local model (PALM) is another robust surrogate
f discussed in [
38] wherein the black box
b is mimicked with the help of a two-part surrogate model
f: the meta-model was used for partitioning the training data
, then those partitioned data were approximated with the assistance of a set of sub-models enabling patterns in a datum to be exposed by approximating patterns within each partition. The meta-model used DT as the predictor
so that the user can determine the structure and analyze whether rules created or generated by DT followed their intuition. PALM is a method that can summarize and learn the overall structure of the data provided for machine learning debugging. Sub-models in this article linked to the leaves of the tree were complex models capable of capturing local patterns whilst remaining directly interpretable by humans. With the final sub-model of the PALM, the proposed technique was both a black box
b and explanator
agnostic. The proposed technique was not only limited to the specific data but was also data-agnostic. Furthermore, queries to PALM were 30x faster than queries to the nearest neighbor to identify the relevant data—this trait of the proposed technique weighed the highest in terms of its credibility. Moreover, this model was not model- and data-specific, which is another plus point of this article. The article did not provide the automatic featuring engineering ability at any step of model
f and the whole technique was classification specific.
Tree ensemble models such as boosted trees and RF are renowned for their higher prediction accuracy but their interpretation is limited. Therefore, [
39] addressed this issue by proposing a post-processing technique
f to enable the interpretation of a complex model
b such as via tree ensembles. Their technique used the first step as the learning process for
b which was then approximated through DT as
, before a generative model was presented to humans for interpretation. They targeted additive tree models (ATMs) [
40] as
b wherein large numbers of small regions are generated that were not directly understandable by humans. Therefore, the goal was to reduce those number of small regions and minimize the model error. They successfully achieved the previous requirements (problems) by using their surrogate
f which mimicked
b after learning that ATMs generated the number of regions as mentioned earlier. They used the comprehensive global predictor
which helped them limit the number of regions to a fixed small number, e.g., ten. These were able to achieve minimization through the expectation minimization algorithm [
41]. Authors applied their techniques to the dataset [
42] for the validation of their work. Their work was model specific but data independent. Moreover, their technique can handle both classification and regression problems.
By leveraging the domain knowledge of the data science field, the authors of [
43] were able to the identify optimal parameter settings and instance perturbations. They introduced explain explore (EE)
f, an interactive machine learning model
b explanation system. First, they extracted their local approximation with
which provided contribution scores for every feature used in original dataset that eventually yielded insights into predictions made by
b. Then, the parameters were adjusted in a way that a data scientist could manually choose any machine learning explainer
(specifically the classifiers). To visually explore different explanations, the local context (surrogate) around the instance was represented using a HyperSlice plot from which data scientists (a target audience) would be able to adjust parameters for a perfect explanation. Finally, a global overview helped identify patterns indicating a problem with the model or explanation technique. Their proposed technique was data and model independent, which means that their model was generalizable, but their novel technique was limited to classification problem domains.
In SAFE ML, the authors elaborated their technique to interpret complex black box
b model prediction through customized surrogate model
f which is capable of addressing a feature engineering task by trimming the overwork factor. Through a simple explanator,
, they were able to explain the inner workings of
b in a human-comprehensible way. They incorporated the model’s agnostic technique—the predictor/estimator
traditional partial dependence profile (PDP) [
44]—to generate the outcome expected of the underlying model on the selected feature(s) to further discretize those features; then, the glass box model/explanator
helped them globally explain the reasoning behind the prediction of
b. Although the authors claimed the generalizability of the proposed technique, they did not provide more concise visuals to explain the model’s complex behavior and only used one algorithm gradient boosting regressor (GBR) [
45] as a surrogate model. Furthermore, their technique is computationally costly, considering a vector of 1000 points for generating resolution for the PELT [
46] model while calculating the mean of the surrogate model’s response.
According to [
47] complex problems are handled by non-linear methodologies. Achieving higher accuracy through such models is not the sole purpose of machine learning technologies. There is a need for some explanation to expose the facts behind how the model learns some particular result. The linear prediction function fails to explain the features’ behavior on the overall prediction of the machine learning model. To tackle such a situation, the authors proposed a technique called the measure of feature importance (MFI), which was an extension of the positional oligomer importance matrices (POIMs) [
48]. For a generalization of POIMs, the feature importance ranking measure (FIRM) [
49] assisted in assigning each feature
with its importance score. According to the authors of this technique, the model’s explanation
was produced with a vector of features’ importance. Thus, with the help of MFI, their own proposed methodology inspired by POIMs and FIRM that is non-linear detects features by itself and explains the impact of the feature on predictions. This technique was not model agnostic and is limited to the classification problem. In addition, it is a data-independent model.
Deep neural networks are highly accurate in predicting unseen data but have a lack of transparency. Therefore, this will limit the scope of practical works. In [
50], the authors were inspired by layer-wise relevance propagation (LRP) [
51] which enabled them to build a relevancy score for each layer by backpropagating the effect of prediction on a particular image upon the level of inputs. This LRP was considered the feature importance teller; then, visualization was performed through saliency masks. The pixel-wise decomposition method (PWD) was used as explanator for non-linear classifiers. LRP was used for working on deep neural networks that are trained to classify EEG analysis data. The proposed DTD was used for interpreting multi-layer neural networks as the black box
b by considering the network decision as relevance propagation against given elements. However, the response time for such a technique to interpret and explain was quite fast but limited to the classification problem. This is a model-specific as well as data-independent technique.
A system’s accurate decisions are obscured when it comes to an internal logic that triggers the results based on prediction methodology. These systems are called black box models which are non-linear in nature. Hence, their wide adoption among societies might deteriorate. The authors in [
52] proposed an agnostic technique called local rule-based explanations (LORE) which are faithful and interpretable. They were successful in achieving interpretability when their proposed technique implemented the
f by learning the predictor’s behavior with the help of a genetic algorithm that allows synthetic neighborhood generation (points on grids). Then, with the help of decision tree, an explanation
is produced. However, their proposed technique is not capable of solving regression problems.
After extensive studies,
Table 1 clearly depicts the motivation behind why this specified surrogate model has become a topic of interest instead of other available robust global surrogate models. In
Table 1, agnostic means that a different surrogate model
f is capable of interpreting any black box
b and can be mimicked through any interpretable predictor
(which will be produced from some
f). Data independent refers to the type of data which mean any tabular data can be handled by given the techniques (i.e., not application-specific). Classification and regression are problem the domains and different solutions are mapped if they are designed to tackle those problems. Automatic feature engineering denotes that while imitating the underlying
b, the feature sample
X is re-sampled to extract more features from the original dataset to unveil new features
and thus enable a linear model that will later be trained on those features, and fast execution refers the approximation/mimicking/imitation of
b to produce
through process
f. Usually, this is affected during the production of additional features for automatic feature engineering tasks. If the model
f is capable of handling feature engineering and other processes involved in model interpretation at the same time at a normal pace, then model
f is considered efficient and the different authors of mentioned techniques have claimed that their techniques are efficient in that regard.
Table 1.
Different models’ comparisons extracted from the literature.
Table 1.
Different models’ comparisons extracted from the literature.
| Name | Ref | Agnostic | Data Ind | Classification | Regression | Auto Feature Eng | Fast Execution |
|---|
| STA | [35] | ✓ | ✓ | ✓ | | | ✓ |
| [37] | | | ✓ | | ✓ | ✓ |
| PALM | [38] | ✓ | ✓ | ✓ | | | ✓ |
| [39] | | ✓ | ✓ | ✓ | | |
| EE | [43] | ✓ | ✓ | ✓ | | ✓ | ✓ |
| SAFE ML | [33] | ✓ | ✓ | ✓ | ✓ | ✓ | |
| MFI | [47] | | ✓ | ✓ | | ✓ | ✓ |
| DTD | [50] | | | ✓ | | ✓ | ✓ |
| LORE | [52] | ✓ | ✓ | ✓ | | ✓ | ✓ |
| ESAFE | [53] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
In this section, issues are discussed in existing techniques regarding black box machine learning model interpretability by referring to up-to-date papers. We were able to tackle such issues in our proposed technique, as discussed in the forthcoming section.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













