
A Novel Hybrid Method for Landslide Susceptibility Mapping-Based GeoDetector and Machine Learning Cluster: A Case of Xiaojin County, China

 ,
,
Abstract
:1. Introduction
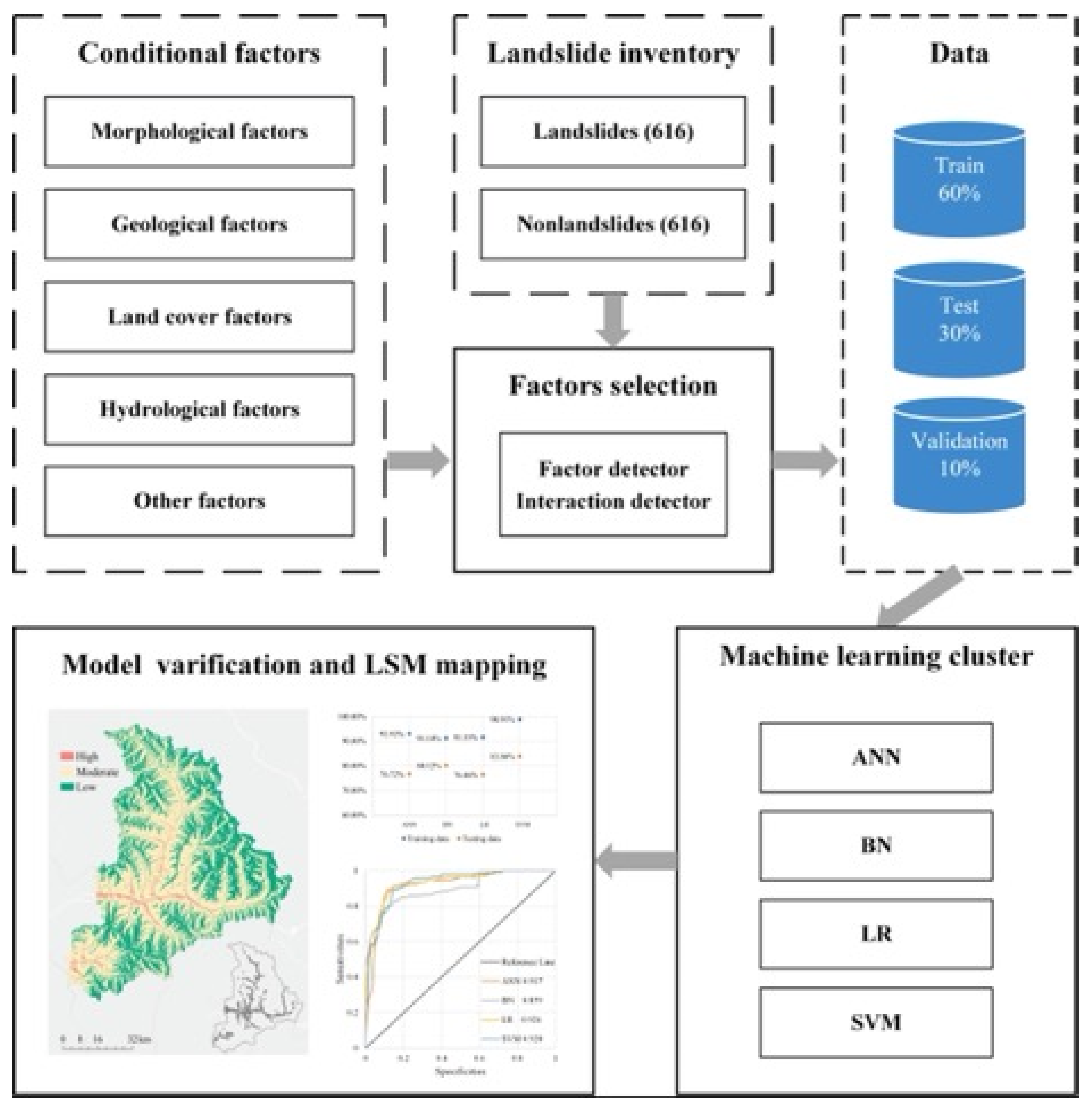
2. Materials and Methods
2.1. Study Area and Data
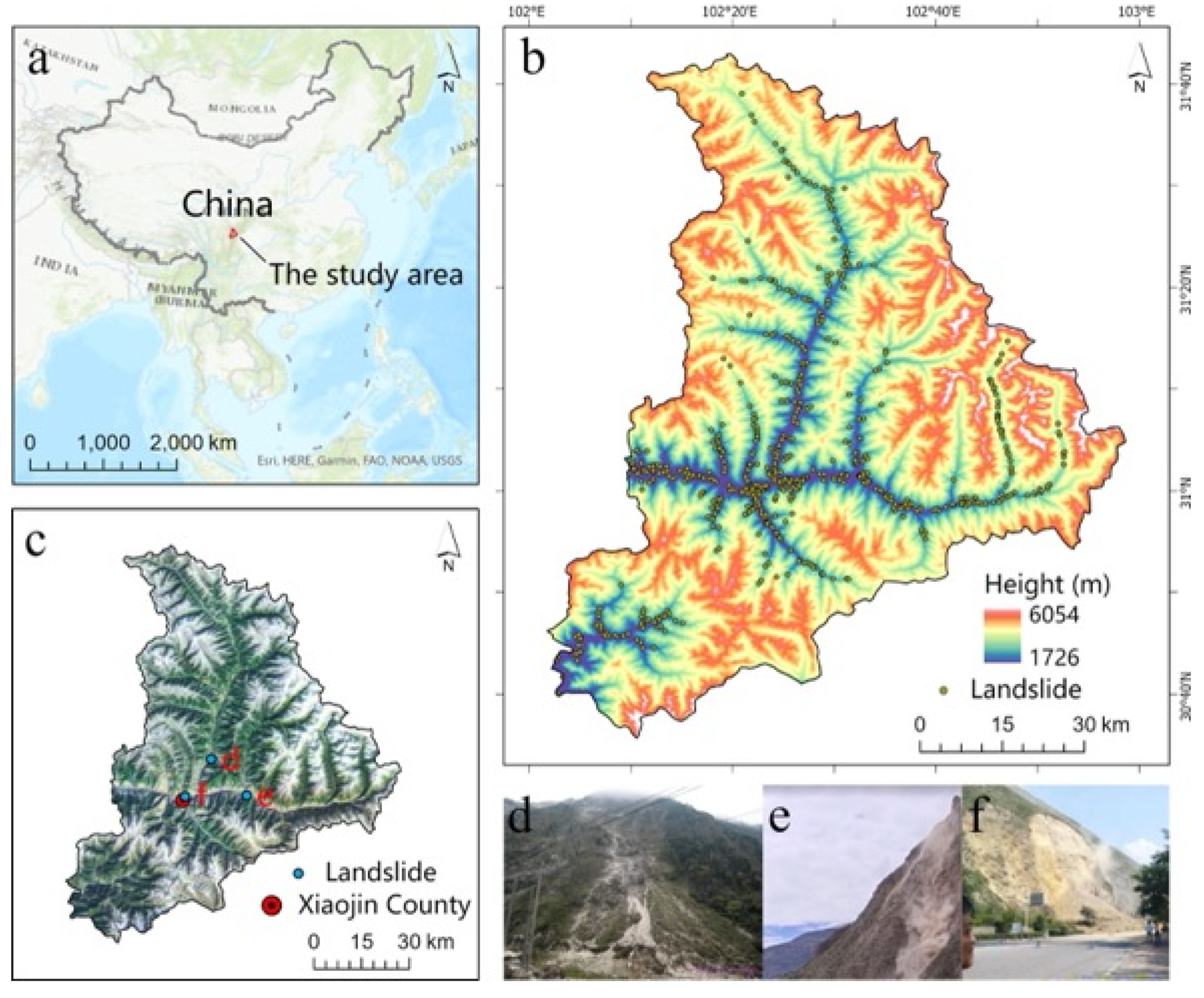
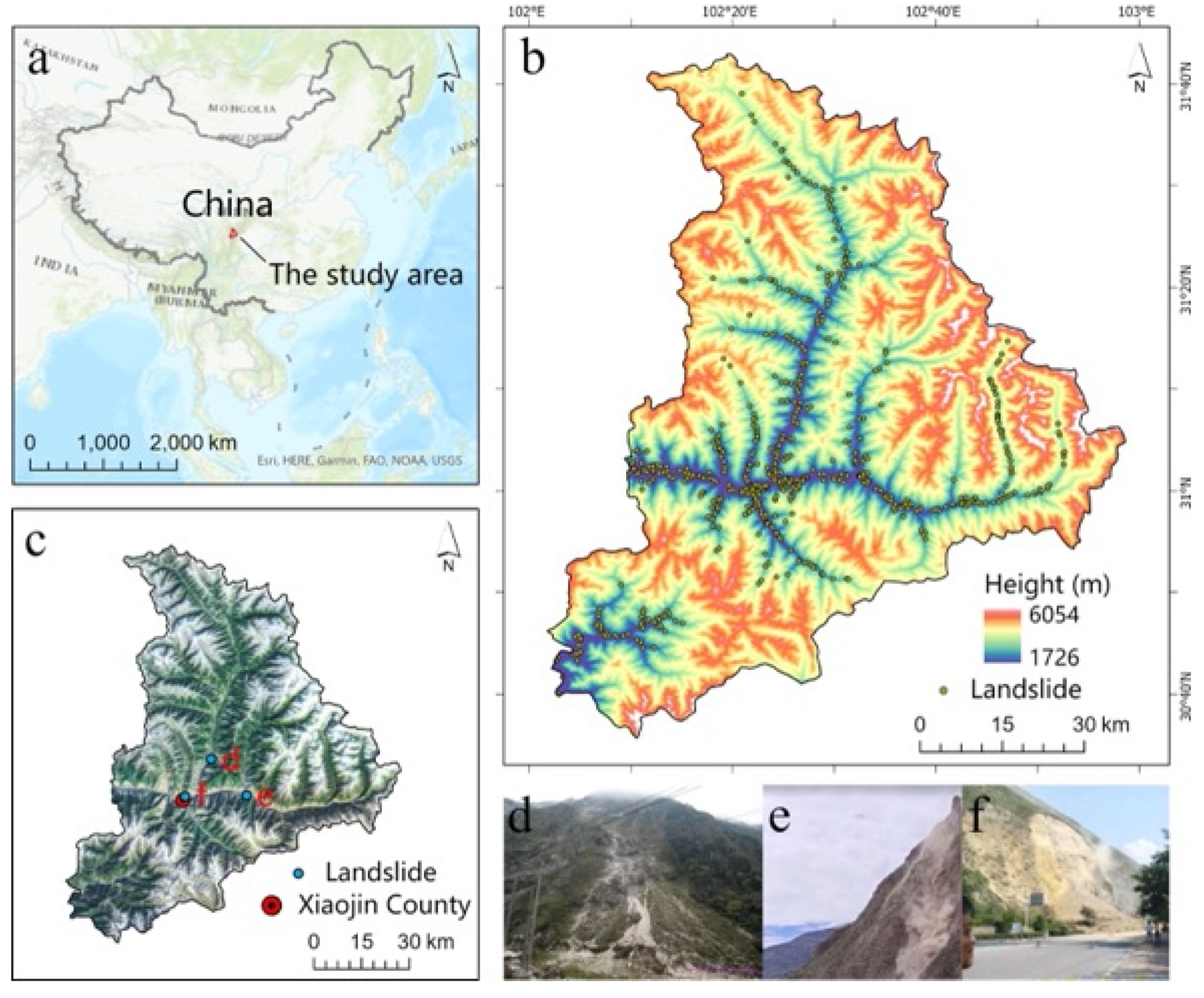
2.1.1. Study Area
2.1.2. Landslide Inventory Map
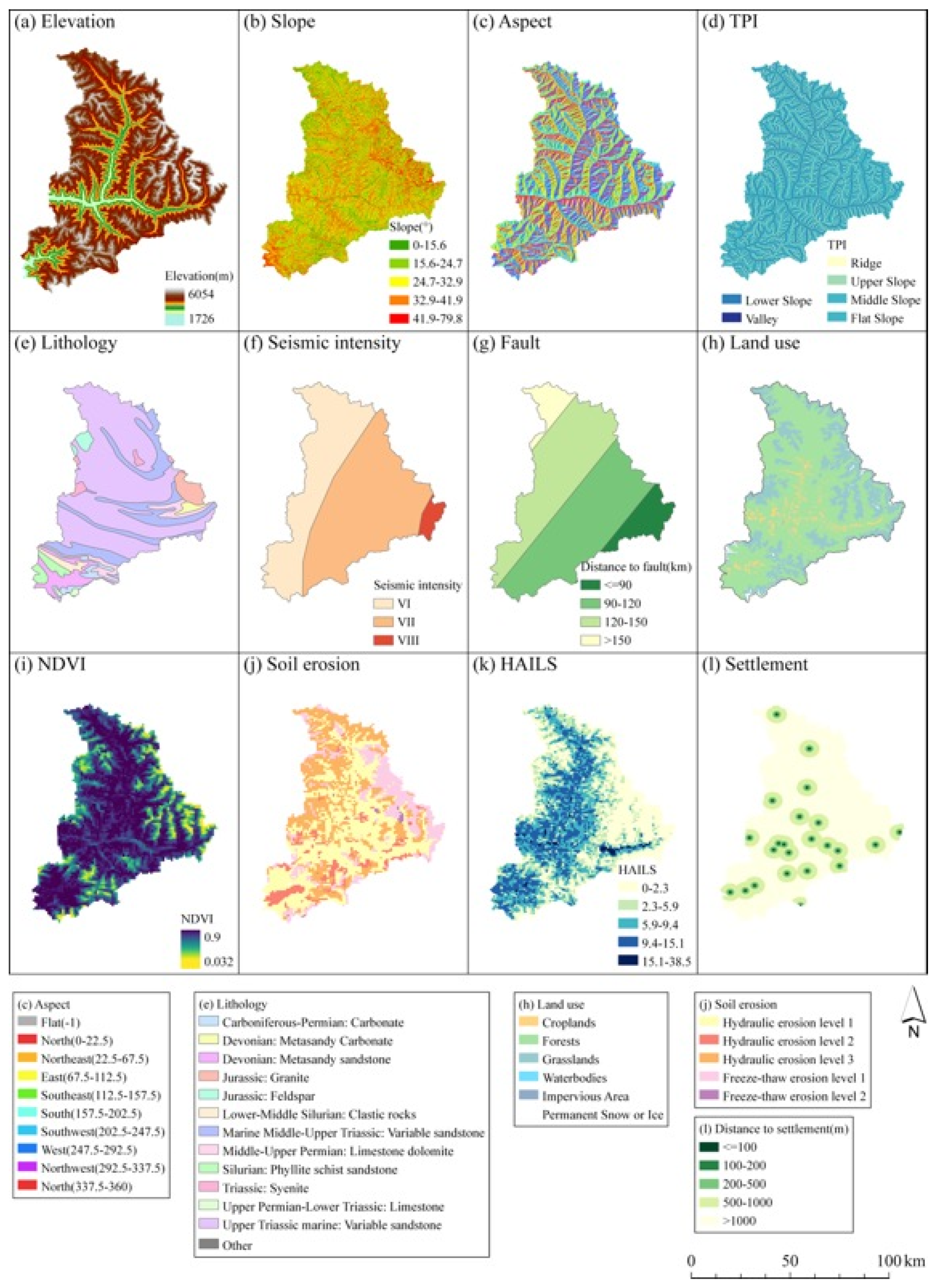
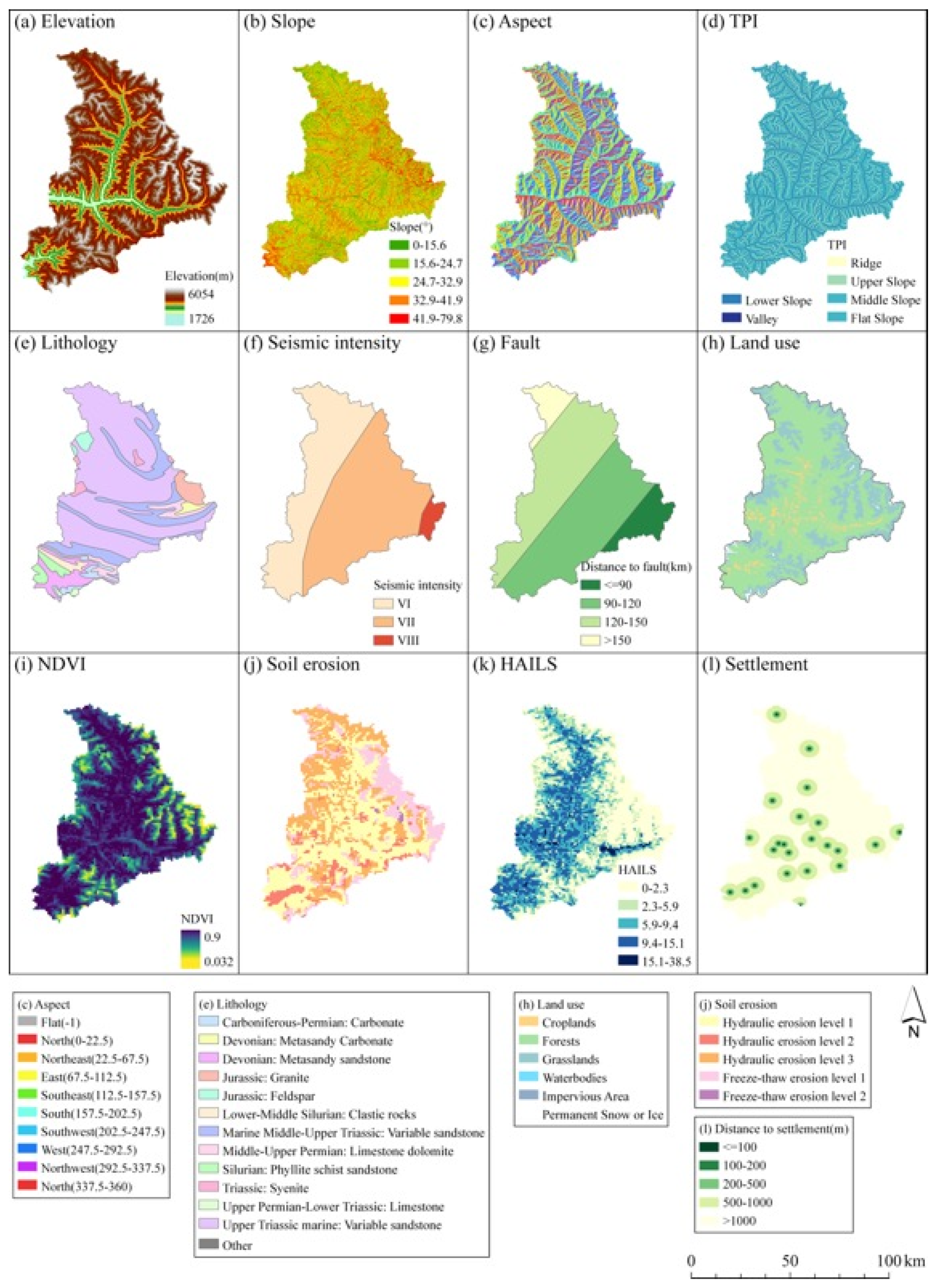
2.1.3. Conditional Factors
- (i)
- Morphological factors
- (ii)
- Geological factors
- (iii)
- Land cover factors
- (iv)
- Hydrological factors
- (v)
- Anthropogenic factors
2.2. Methods
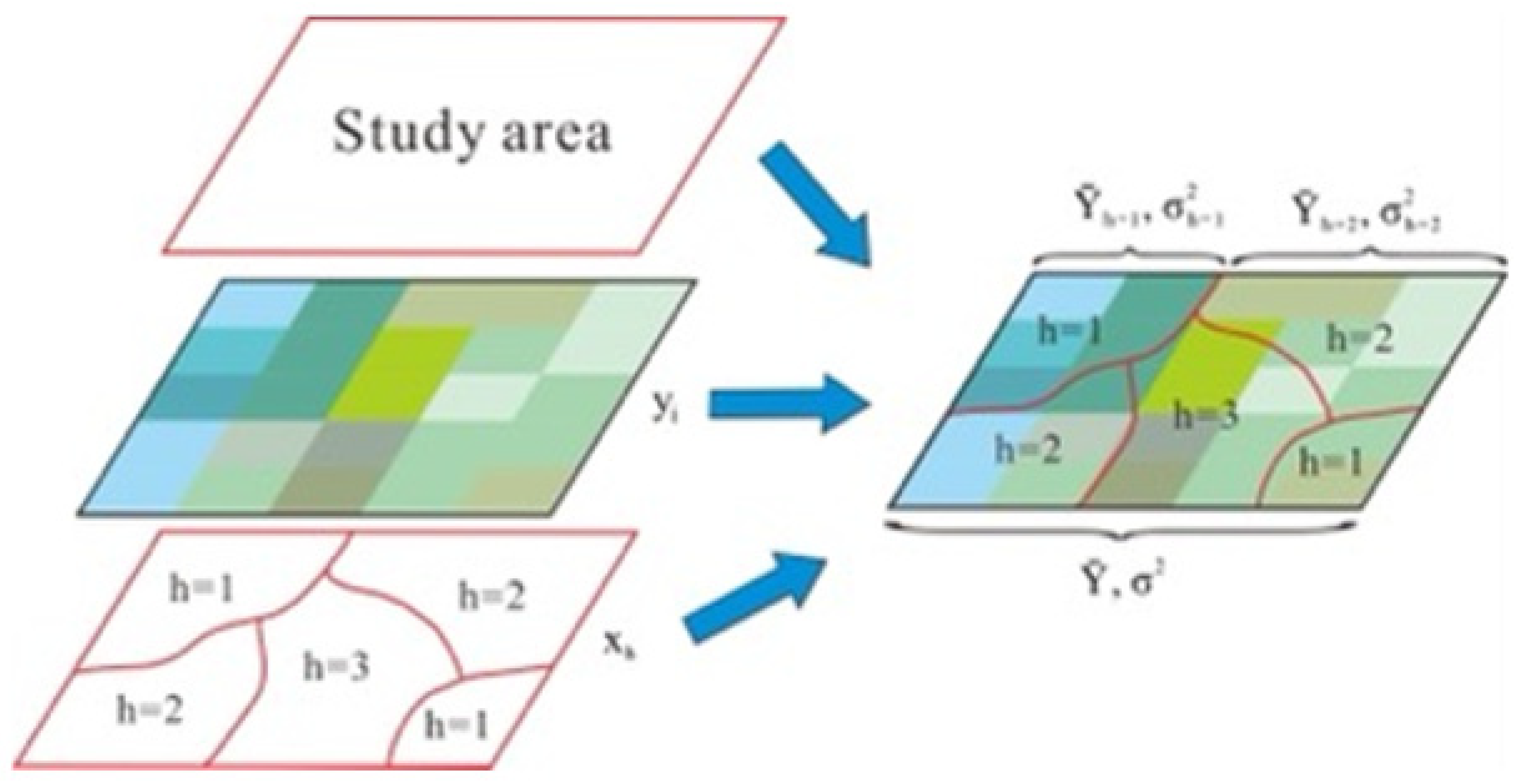
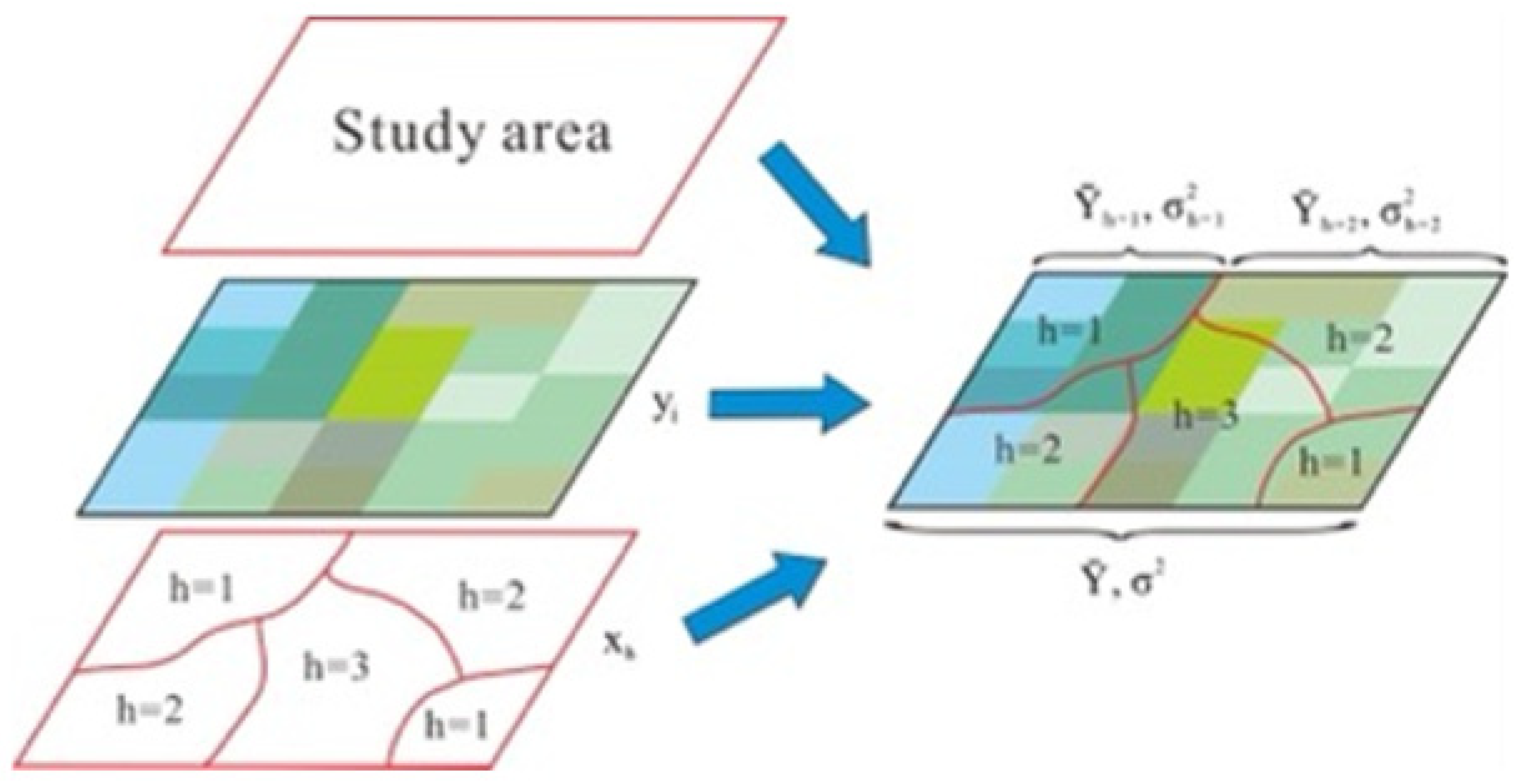
2.2.1. Conditional Factor Selection
2.2.2. Machine Learning Cluster
- (i)
- Artificial neural network (ANN)
- (ii)
- Bayesian network (BN)
- (iii)
- Logistic regression (LR)
- (iv)
- Support Vector Machine (SVM)
2.2.3. Verification
3. Results
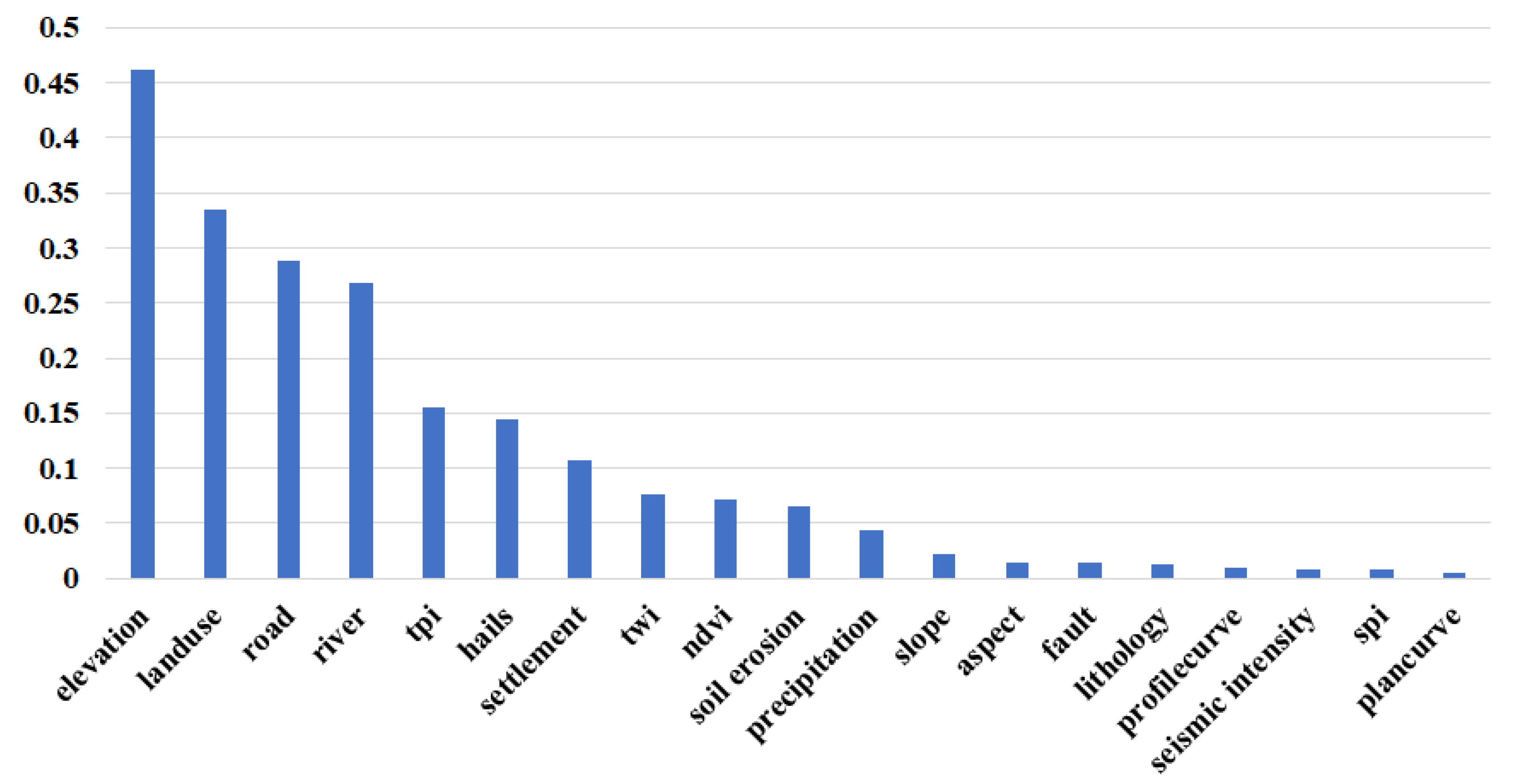
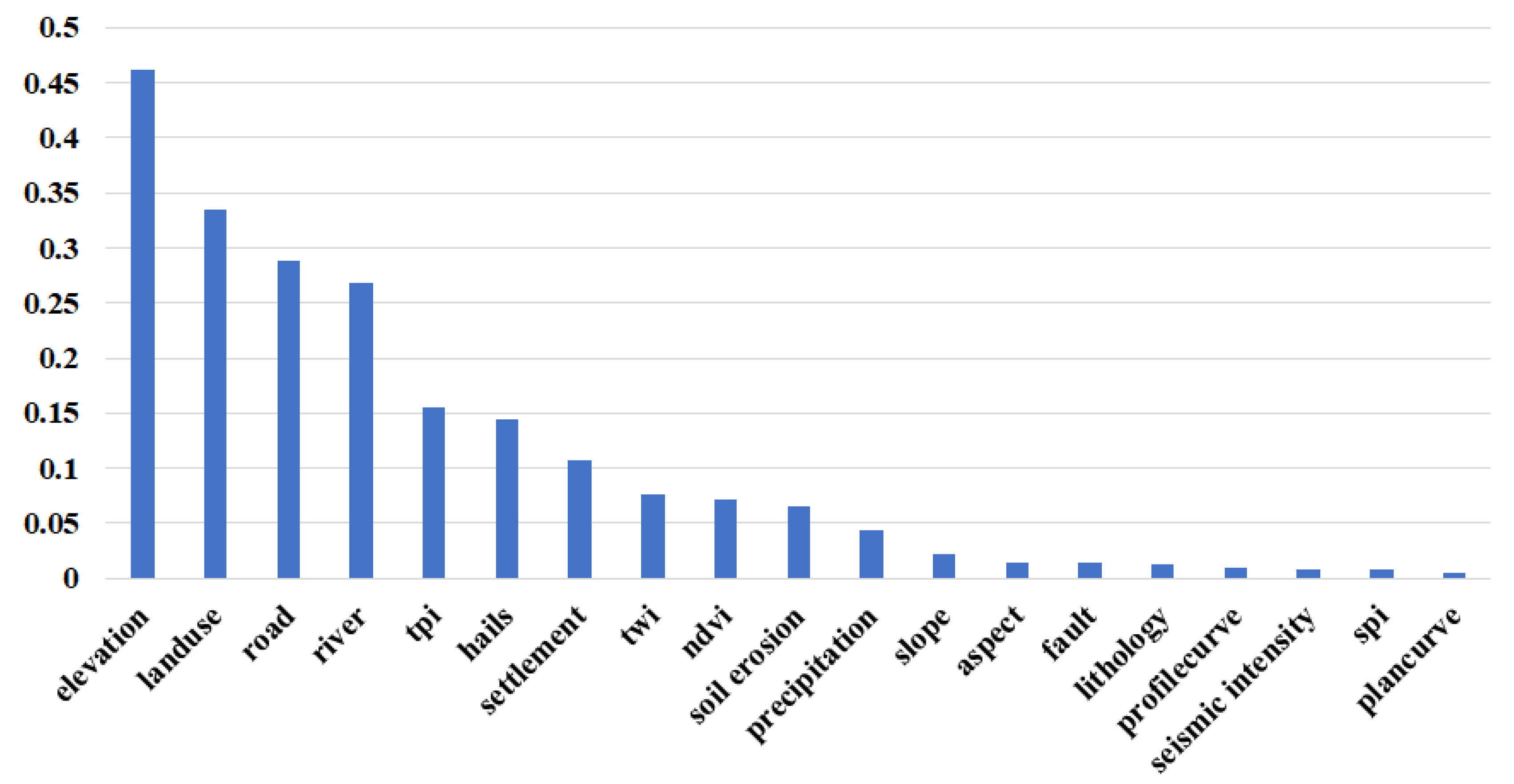
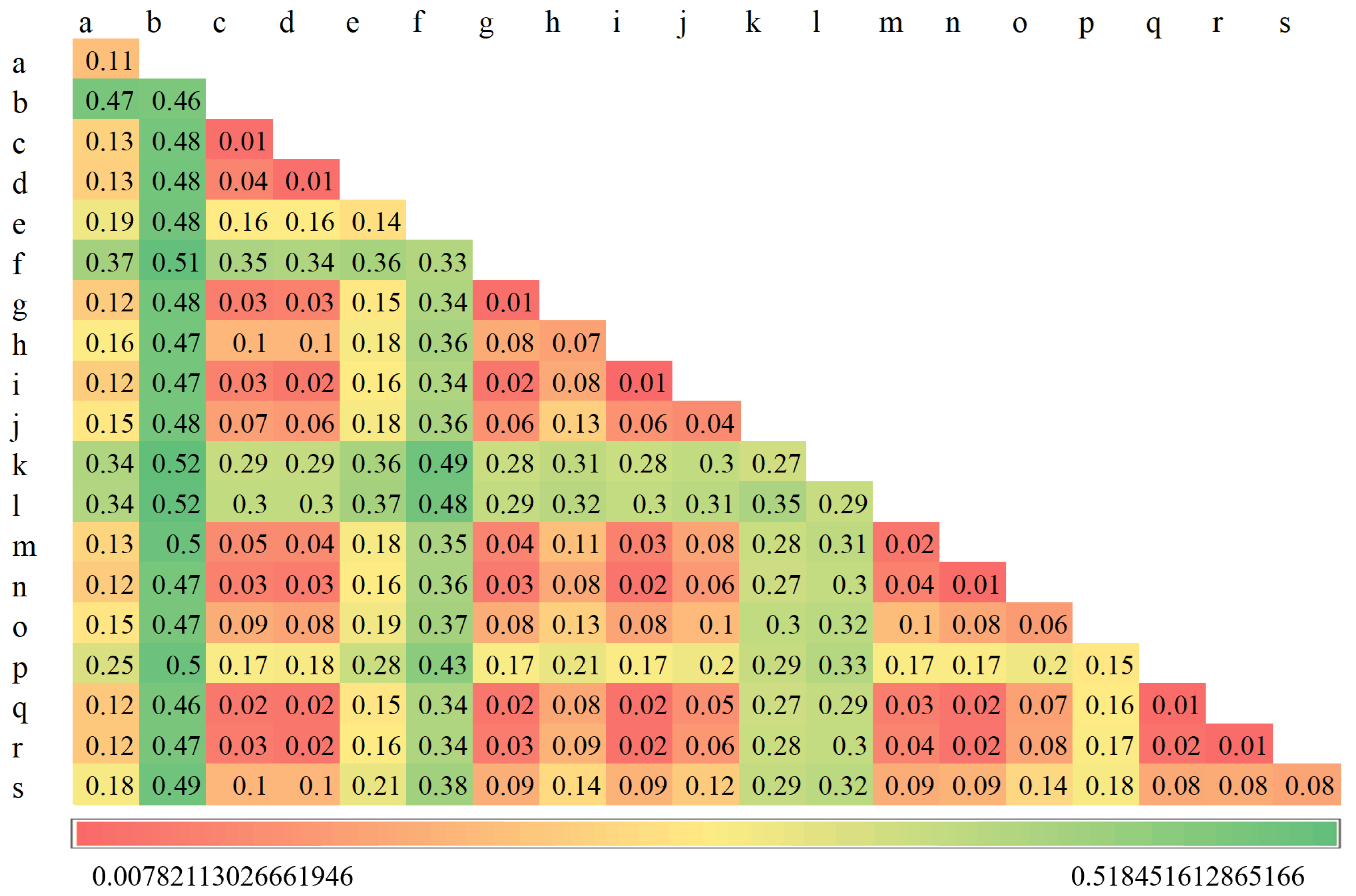
3.1. Results of Conditional Select
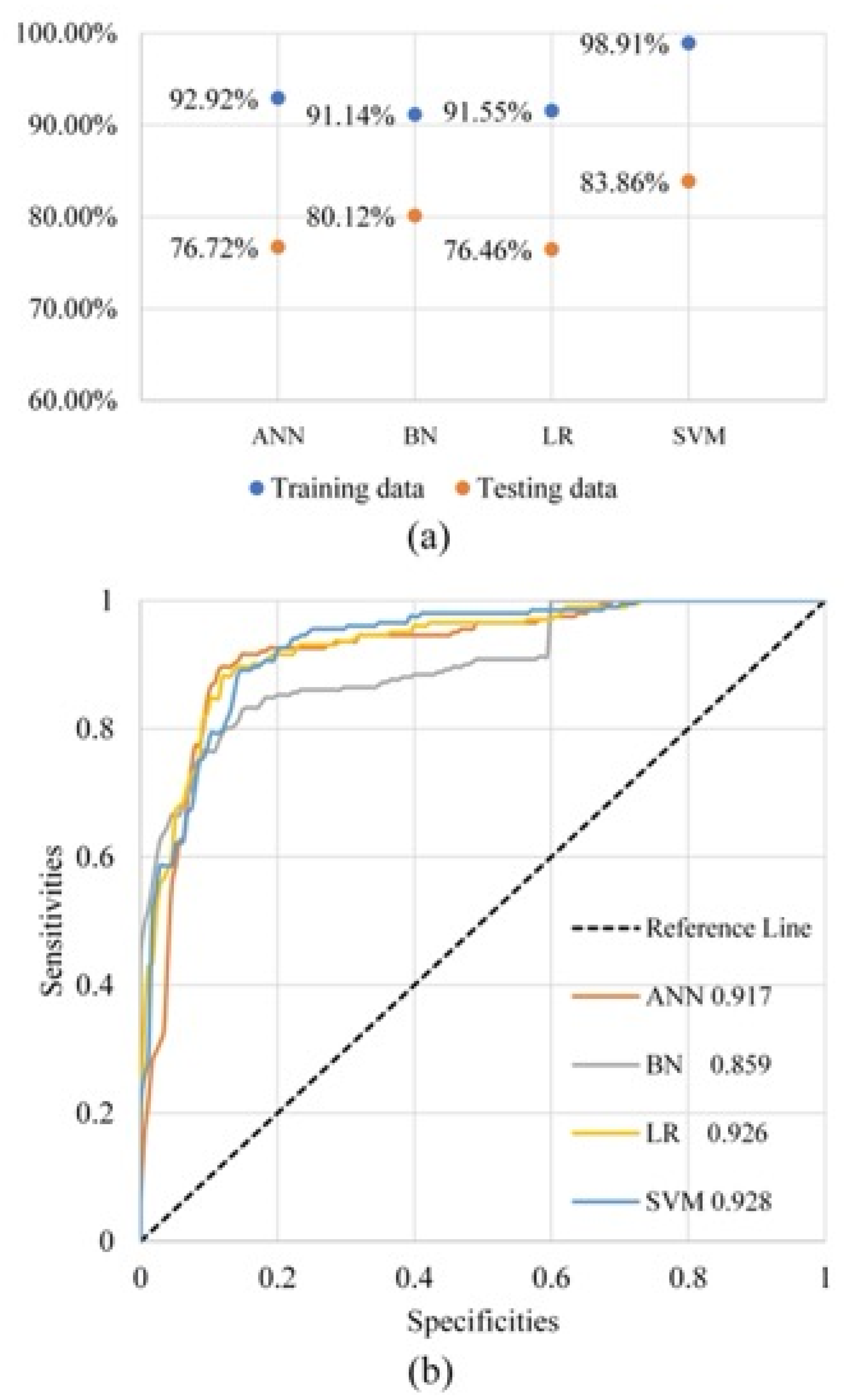
3.2. Accuracy Assessment of the Machine Learning Cluster
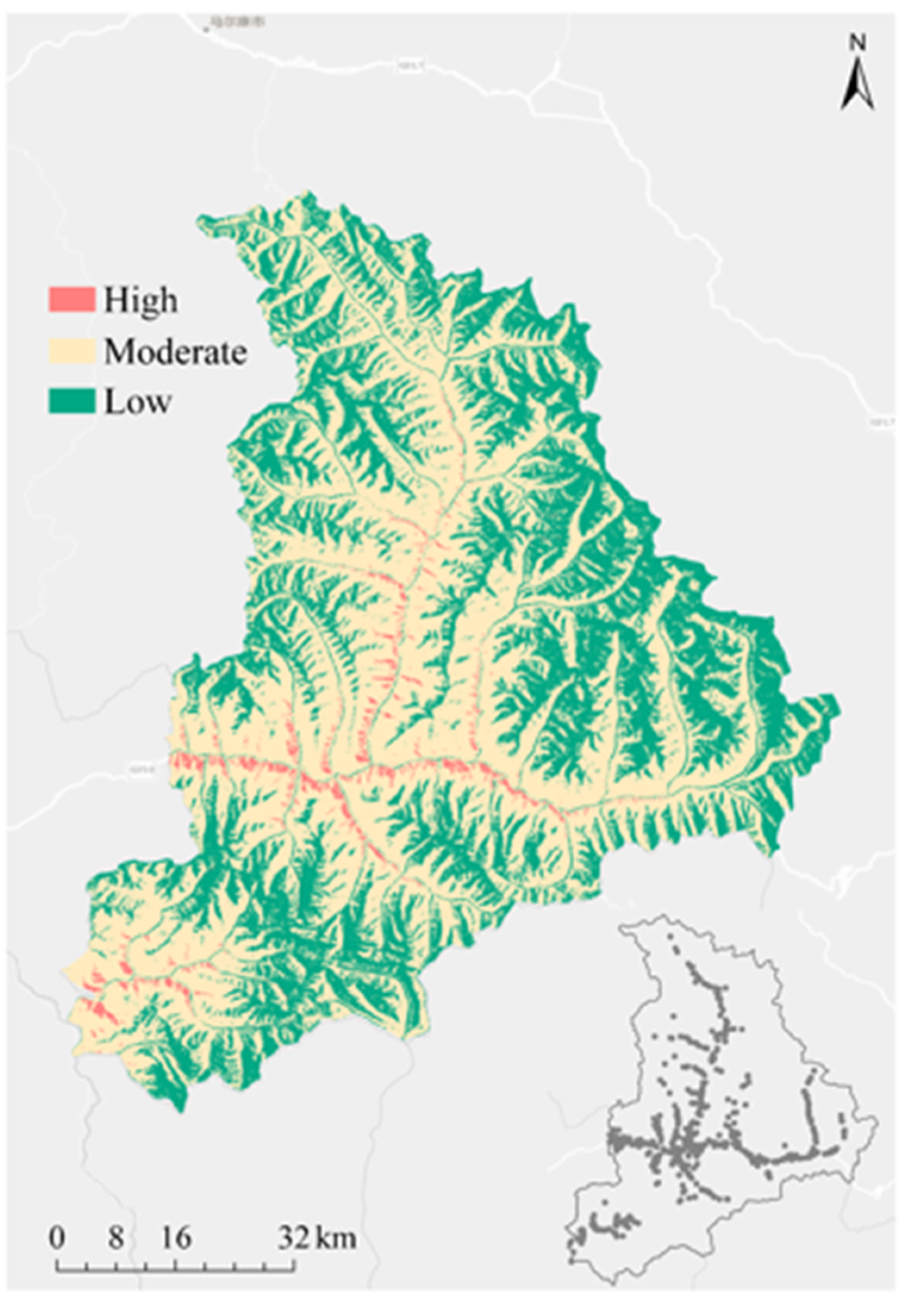
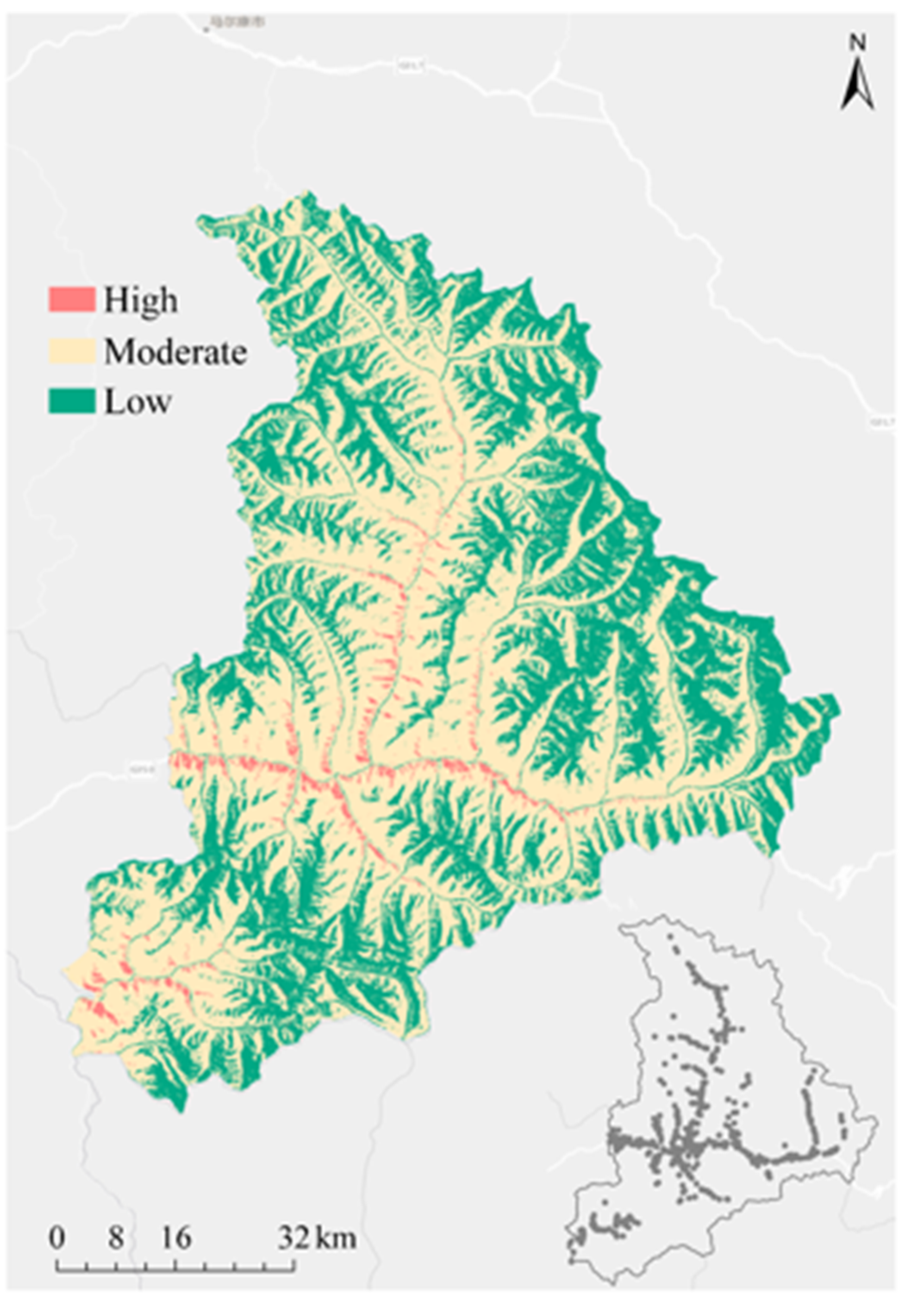
3.3. Landslide Susceptibility Mapping
4. Discussion
4.1. Factor-Detector and Interaction-Detector
4.2. Machine Learning Cluster Performance
4.3. New Contributions and Prospect of Model
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. List of Acronyms
| Acronym | Description |
| ANN | Artificial neural network |
| AUC | Area under the ROC curve |
| BN | Bayesian network |
| DEM | Digital elevation model |
| GIS | Geographic Information System |
| HAILS | Human activity intensity of land surface |
| LR | Logistic regression |
| LSM | Landslide susceptibility mapping |
| MAE | Mean absolute error |
| ML | Machine learning |
| NDVI | Normalized Difference Vegetation Index |
| ROC | Receiver operating characteristic |
| RS | Remote Sensing |
| SAGA | System for Automated Geoscientific Anal-yses |
| SPI | Stream power index |
| SVM | Support vector machines |
| TPI | Topographic position index |
| TWI | Topographic wetness index |
References
- Gariano, S.L.; Guzzetti, F. Landslides in a changing climate. Earth Sci. Rev. 2016, 162, 227–252. [Google Scholar] [CrossRef] [Green Version]
- Paranunzio, R.; Chiarle, M.; Laio, F.; Nigrelli, G.; Turconi, L.; Luino, F. New insights in the relation between climate and slope failures at high-elevation sites. Theor. Appl. Climatol. 2019, 137, 1765–1784. [Google Scholar] [CrossRef]
- Fan, X.; Scaringi, G.; Korup, O.; West, A.J.; van Westen, C.J.; Tanyas, H.; Hovius, N.; Hales, T.C.; Jibson, R.W.; Allstadt, K.E.; et al. Earthquake-Induced Chains of Geologic Hazards: Patterns, Mechanisms, and Impacts. Rev. Geophys. 2019, 57, 421–503. [Google Scholar] [CrossRef] [Green Version]
- Lin, Q.; Wang, Y. Spatial and temporal analysis of a fatal landslide inventory in China from 1950 to 2016. Landslides 2018, 15, 2357–2372. [Google Scholar] [CrossRef]
- Lee, S.; Talib, J.A. Probabilistic landslide susceptibility and factor effect analysis. Environ. Geol. 2005, 47, 982–990. [Google Scholar] [CrossRef]
- Van Westen, C.J.; Castellanos, E.; Kuriakose, S.L. Spatial data for landslide susceptibility, hazard, and vulnerability assessment: An overview. Eng. Geol. 2008, 102, 112–131. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihir, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Budimir, M.E.A.; Atkinson, P.M.; Lewis, H.G. A systematic review of landslide probability mapping using logistic regression. Landslides 2015, 12, 419–436. [Google Scholar] [CrossRef] [Green Version]
- Đurić, U.; Marjanović, M.; Radić, Z.; Abolmasov, B. Machine learning based landslide assessment of the Belgrade metropolitan area: Pixel resolution effects and a cross-scaling concept. Eng. Geol. 2019, 256, 23–38. [Google Scholar] [CrossRef]
- Lee, J.H.; Sameen, M.I.; Pradhan, B.; Park, H.J. Modeling landslide susceptibility in data-scarce environments using optimized data mining and statistical methods. Geomorphology 2018, 303, 284–298. [Google Scholar] [CrossRef]
- Brenning, A. Spatial prediction models for landslide hazards: Review, comparison and evaluation. Nat. Hazards Earth Syst. Sci. 2005, 5, 853–862. [Google Scholar] [CrossRef]
- Lee, S.; Pradhan, B. Landslide hazard mapping at Selangor, Malaysia using frequency ratio and logistic regression models. Landslides 2007, 4, 33–41. [Google Scholar] [CrossRef]
- Sharma, S.; Mahajan, A.K. A comparative assessment of information value, frequency ratio and analytical hierarchy process models for landslide susceptibility mapping of a Himalayan watershed, India. Bull. Eng. Geol. Environ. 2019, 78, 2431–2448. [Google Scholar] [CrossRef]
- Ilia, I.; Tsangaratos, P. Applying weight of evidence method and sensitivity analysis to produce a landslide susceptibility map. Landslides 2016, 13, 379–397. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Q.; Liu, Y. Mapping landslide susceptibility using machine learning algorithms and GIS: A case study in Shexian county, Anhui province, China. Symmetry 2020, 12, 1954. [Google Scholar] [CrossRef]
- Lee, S. Application of likelihood ratio and logistic regression models to landslide susceptibility mapping using GIS. Environ. Manag. 2004, 34, 223–232. [Google Scholar] [CrossRef]
- Harmouzi, H.; Nefeslioglu, H.A.; Rouai, M.; Sezer, E.A.; Dekayir, A.; Gokceoglu, C. Landslide susceptibility mapping of the Mediterranean coastal zone of Morocco between Oued Laou and El Jebha using artificial neural networks (ANN). Arab. J. Geosci. 2019, 12, 696–714. [Google Scholar] [CrossRef]
- Moayedi, H.; Mehrabi, M.; Mosallanezhad, M.; Rashid, A.S.A.; Pradhan, B. Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng. Comput. 2019, 35, 967–984. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Ilia, I. Comparison of a logistic regression and Naïve Bayes classifier in landslide susceptibility assessments: The influence of models complexity and training dataset size. Catena 2016, 145, 164–179. [Google Scholar] [CrossRef]
- Raia, S.; Alvioli, M.; Rossi, M.; Baum, R.L.; Godt, J.W.; Guzzetti, F. Improving predictive power of physically based rainfall-induced shallow landslide models: A probabilistic approach. Geosci. Model Dev. Discuss. 2013, 6, 1367–1426. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Yang, J.; Xu, C.; Xu, C.; Song, C. Local-scale landslide susceptibility mapping using the B-GeoSVC model. Landslides 2019, 16, 1301–1312. [Google Scholar] [CrossRef]
- Xiao, L.; Zhang, Y.; Peng, G. Landslide susceptibility assessment using integrated deep learning algorithm along the china-nepal highway. Sensors 2018, 18. [Google Scholar] [CrossRef] [Green Version]
- Huang, F.; Zhang, J.; Zhou, C.; Wang, Y.; Huang, J.; Zhu, L. A deep learning algorithm using a fully connected sparse autoencoder neural network for landslide susceptibility prediction. Landslides 2020, 17, 217–229. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Teimoori Yansari, Z.; Panagos, P.; Pradhan, B. Analysis and evaluation of landslide susceptibility: A review on articles published during 2005–2016 (periods of 2005–2012 and 2013–2016). Arab. J. Geosci. 2018, 11, 1–12. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]
- Van Asch, T.W.J.; Buma, J.; Van Beek, L.P.H. A view on some hydrological triggering systems in landslides. Geomorphology 1999, 30, 25–32. [Google Scholar] [CrossRef]
- Hungr, O.; Leroueil, S.; Picarelli, L. The Varnes classification of landslide types, an update. Landslides 2014, 11, 167–194. [Google Scholar] [CrossRef]
- Jebur, M.N.; Pradhan, B.; Tehrany, M.S. Optimization of landslide conditioning factors using very high-resolution airborne laser scanning (LiDAR) data at catchment scale. Remote Sens. Environ. 2014, 152, 150–165. [Google Scholar] [CrossRef]
- Chen, W.; Zhao, X.; Shahabi, H.; Shirzadi, A.; Khosravi, K.; Chai, H.; Zhang, S.; Zhang, L.; Ma, J.; Chen, Y.; et al. Spatial prediction of landslide susceptibility by combining evidential belief function, logistic regression and logistic model tree. Geocarto Int. 2019, 34, 1177–1201. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Jones, S.; Shabani, F.; Martínez-Álvarez, F.; Tien Bui, D. A novel ensemble modeling approach for the spatial prediction of tropical forest fire susceptibility using LogitBoost machine learning classifier and multi-source geospatial data. Theor. Appl. Climatol. 2019, 137, 637–653. [Google Scholar] [CrossRef]
- Zhao, C.; Lu, Z. Remote sensing of landslides-A review. Remote Sens. 2018, 10, 279. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Li, S.; Li, X.; Jiang, Y.; Wei, W.; Wang, Z.; Bai, Y. An integrated approach for landslide susceptibility mapping by considering spatial correlation and fractal distribution of clustered landslide data. Landslides 2019, 16, 715–728. [Google Scholar] [CrossRef]
- Pawluszek, K.; Borkowski, A. Impact of DEM-derived factors and analytical hierarchy process on landslide susceptibility mapping in the region of Rożnów Lake, Poland. Nat. Hazards 2017, 86, 919–952. [Google Scholar] [CrossRef] [Green Version]
- Weiss, A.D. Topographic position and landforms analysis. In Proceedings of the ESRI User Conference, San Diego, CA, USA, 9–13 July 2001; Volume 64, pp. 227–245. Available online: http://www.jennessent.com/downloads/tpi-poster-tnc_18x22.pdf (accessed on 22 December 2020).
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef] [Green Version]
- Beguerı, S. Changes in land cover and shallow landslide activity: A case study in the Spanish Pyrenees. Geomorphology 2006, 74, 196–206. [Google Scholar] [CrossRef] [Green Version]
- Yang, W.; Wang, Y.; Sun, S.; Wang, Y.; Ma, C. Using Sentinel-2 time series to detect slope movement before the Jinsha River landslide. Landslides 2019, 16, 1313–1324. [Google Scholar] [CrossRef]
- Guerra, A.J.T.; Fullen, M.A.; Do Carmo Oliveira Jorge, M.; Bezerra, J.F.R.; Shokr, M.S. Slope Processes, Mass Movement and Soil Erosion: A Review. Pedosphere 2017, 27, 27–41. [Google Scholar] [CrossRef]
- Piciullo, L.; Calvello, M.; Cepeda, J.M. Territorial early warning systems for rainfall-induced landslides. Earth Sci. Rev. 2018, 179, 228–247. [Google Scholar] [CrossRef]
- Kim, J.C.; Lee, S.; Jung, H.S.; Lee, S. Landslide susceptibility mapping using random forest and boosted tree models in Pyeong-Chang, Korea. Geocarto Int. 2018, 33, 1000–1015. [Google Scholar] [CrossRef]
- Taalab, K.; Cheng, T.; Zhang, Y. Mapping landslide susceptibility and types using Random Forest. Big Earth Data 2018, 2, 159–178. [Google Scholar] [CrossRef]
- Xu, Y.; Xu, X.; Tang, Q. Human activity intensity of land surface: Concept, methods and application in China. J. Geogr. Sci. 2016, 26, 1349–1361. [Google Scholar] [CrossRef]
- Chi, Y.; Zheng, W.; Shi, H.; Sun, J.; Fu, Z. Spatial heterogeneity of estuarine wetland ecosystem health influenced by complex natural and anthropogenic factors. Sci. Total Environ. 2018, 634, 1445–1462. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.F.; Zhang, T.L.; Fu, B.J. A measure of spatial stratified heterogeneity. Ecol. Indic. 2016, 67, 250–256. [Google Scholar] [CrossRef]
- Wang, J.F.; Li, X.H.; Christakos, G.; Liao, Y.L.; Zhang, T.; Gu, X.; Zheng, X.Y. Geographical detectors-based health risk assessment and its application in the neural tube defects study of the Heshun Region, China. Int. J. Geogr. Inf. Sci. 2010, 24, 107–127. [Google Scholar] [CrossRef]
- Yang, J.; Song, C.; Yang, Y.; Xu, C.; Guo, F.; Xie, L. New method for landslide susceptibility mapping supported by spatial logistic regression and GeoDetector: A case study of Duwen Highway Basin, Sichuan Province, China. Geomorphology 2019, 324, 62–71. [Google Scholar] [CrossRef]
- Ju, H.; Zhang, Z.; Zuo, L.; Wang, J.; Zhang, S.; Wang, X.; Zhao, X. Driving forces and their interactions of built-up land expansion based on the geographical detector—A case study of Beijing, China. Int. J. Geogr. Inf. Sci. 2016, 30, 2188–2207. [Google Scholar] [CrossRef]
- Bai, L.; Jiang, L.; Yang, D.Y.; Liu, Y.B. Quantifying the spatial heterogeneity influences of natural and socioeconomic factors and their interactions on air pollution using the geographical detector method: A case study of the Yangtze River Economic Belt, China. J. Clean. Prod. 2019, 232, 692–704. [Google Scholar] [CrossRef]
- Qi, X.; Si, Z.; Zhong, T.; Huang, X.; Crush, J. Spatial determinants of urban wet market vendor profit in Nanjing, China. Habitat Int. 2019, 94, 102064. [Google Scholar] [CrossRef]
- Wang, J.F.; Hu, Y. Environmental health risk detection with GeogDetector. Environ. Model. Softw. 2012, 33, 114–115. [Google Scholar] [CrossRef]
- Xavier-Júnior, J.C.; Freitas, A.A.; Ludermir, T.B.; Feitosa-Neto, A.; Barreto, C.A.S. An Evolutionary Algorithm for Automated Machine Learning Focusing on Classifier Ensembles: An improved algorithm and extended results. Theor. Comput. Sci. 2019, 805, 1–18. [Google Scholar] [CrossRef]
- Waring, J.; Lindvall, C.; Umeton, R. Arti fi cial Intelligence in Medicine Automated machine learning: Review of the state-of-the-art and opportunities for healthcare. Artif. Intell. Med. 2020, 104, 101822. [Google Scholar] [CrossRef]
- Poudyal, C.P.; Chang, C.; Oh, H.J.; Lee, S. Landslide susceptibility maps comparing frequency ratio and artificial neural networks: A case study from the Nepal Himalaya. Environ. Earth Sci. 2010, 61, 1049–1064. [Google Scholar] [CrossRef]
- Abbaszadeh Shahri, A.; Spross, J.; Johansson, F.; Larsson, S. Landslide susceptibility hazard map in southwest Sweden using artificial neural network. Catena 2019, 183, 104225. [Google Scholar] [CrossRef]
- Song, Y.; Gong, J.; Gao, S.; Wang, D.; Cui, T.; Li, Y.; Wei, B. Susceptibility assessment of earthquake-induced landslides using Bayesian network: A case study in Beichuan, China. Comput. Geosci. 2012, 42, 189–199. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.J.; Jung, H.S.; Lee, S. Landslide susceptibility mapping using Naïve Bayes and Bayesian network models in Umyeonsan, Korea. Geocarto Int. 2020, 35, 1665–1679. [Google Scholar] [CrossRef]
- Pham, B.T.; Pradhan, B.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Model. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Beguería, S. Validation and evaluation of predictive models in hazard assessment and risk management. Nat. Hazards 2006, 37, 315–329. [Google Scholar] [CrossRef] [Green Version]
- Nicu, I.C.; Asăndulesei, A. GIS-based evaluation of diagnostic areas in landslide susceptibility analysis of Bahluieț River Basin (Moldavian Plateau, NE Romania). Are Neolithic sites in danger? Geomorphology 2018, 314, 27–41. [Google Scholar] [CrossRef]
- Paranunzio, R.; Laio, F.; Nigrelli, G.; Chiarle, M. A method to reveal climatic variables triggering slope failures at high elevation. Nat. Hazards 2015, 76, 1039–1061. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Chen, W.; Ly, H.B.; Ho, L.S.; Omidvar, E.; Tran, V.P.; Bui, D.T. A novel intelligence approach of a sequential minimal optimization-based support vector machine for landslide susceptibility mapping. Sustainability 2019, 11, 6323. [Google Scholar] [CrossRef] [Green Version]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.; Chen, C.W.; Han, Z.; Pham, B.T. Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 2020, 17, 641–658. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rahmati, O. Prediction of the landslide susceptibility: Which algorithm, which precision? Catena 2018, 162, 177–192. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | Name | Data Description |
|---|---|---|
| Morphological | Elevation | Height above sea level |
| Slope | Slope angle | |
| Aspect | Slope aspect | |
| Profile curve | Curvature along the slope | |
| Plan curve | Curvature perpendicular to slope | |
| TPI | Topographic position index | |
| Geological | Lithology | Rock feature |
| Seismic intensity | Magnitude of the earthquake | |
| Fault | Distance to fault zone | |
| Land cover | Land use | Land use |
| NDVI | Normalized Difference Vegetation Index | |
| Soil erosion | Hydraulic erosion and freeze-thaw erosion | |
| Hydrological | Precipitation | Mean annual rainfall (1980–2010) |
| River | Distance to river | |
| SPI | Stream power index | |
| TWI | Topographic wetness index, calculated by SAGA | |
| Anthropogenic | HAILS | Human activity intensity of land surface |
| Settlement | Distance to residential area | |
| Road | Distance to road |
| Model | Class | Pixel Number | Area (%) | Number of Landslides | Landslides (%) | SCAI |
|---|---|---|---|---|---|---|
| ANN | High | 140,711 | 8.23 | 317 | 51.46 | 0.16 |
| Moderate | 728,149 | 42.59 | 228 | 37.01 | 1.15 | |
| Low | 840,820 | 49.18 | 71 | 11.52 | 4.27 | |
| BN | High | 193,365 | 11.31 | 258 | 41.88 | 0.27 |
| Moderate | 661,817 | 38.71 | 263 | 42.69 | 0.91 | |
| Low | 854,498 | 49.98 | 95 | 15.42 | 3.24 | |
| LR | High | 135,236 | 7.91 | 325 | 52.76 | 0.15 |
| Moderate | 689,856 | 40.35 | 224 | 36.36 | 1.11 | |
| Low | 884,588 | 51.74 | 67 | 10.88 | 4.75 | |
| SVM | High | 103,094 | 6.03 | 375 | 60.87 | 0.09 |
| Moderate | 641,472 | 37.52 | 197 | 31.98 | 1.17 | |
| Low | 965,114 | 56.45 | 44 | 7.14 | 7.91 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, W.; Li, X.; Jian, W.; Yang, Y.; Liu, H.; Robledo, L.F.; Nie, W. A Novel Hybrid Method for Landslide Susceptibility Mapping-Based GeoDetector and Machine Learning Cluster: A Case of Xiaojin County, China. ISPRS Int. J. Geo-Inf. 2021, 10, 93. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10020093
Xie W, Li X, Jian W, Yang Y, Liu H, Robledo LF, Nie W. A Novel Hybrid Method for Landslide Susceptibility Mapping-Based GeoDetector and Machine Learning Cluster: A Case of Xiaojin County, China. ISPRS International Journal of Geo-Information. 2021; 10(2):93. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10020093
Chicago/Turabian StyleXie, Wei, Xiaoshuang Li, Wenbin Jian, Yang Yang, Hongwei Liu, Luis F. Robledo, and Wen Nie. 2021. "A Novel Hybrid Method for Landslide Susceptibility Mapping-Based GeoDetector and Machine Learning Cluster: A Case of Xiaojin County, China" ISPRS International Journal of Geo-Information 10, no. 2: 93. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10020093