
Domain Adaptation for Semantic Segmentation of Historical Panchromatic Orthomosaics in Central Africa

 , , , , , and
, , , , , and
Abstract
:1. Introduction
2. Materials and Methods
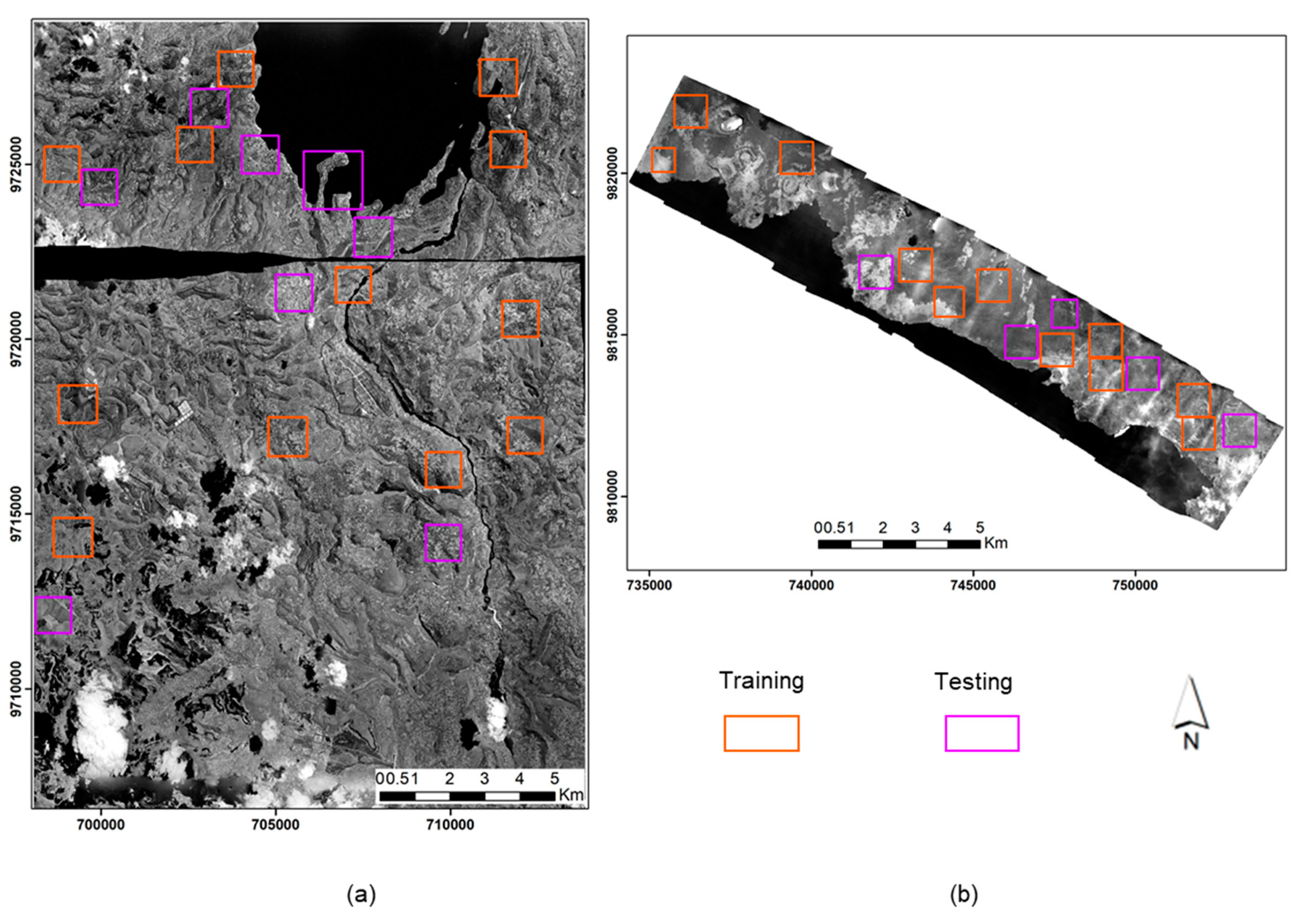
2.1. Data Description
2.2. Domain Adaptation Networks
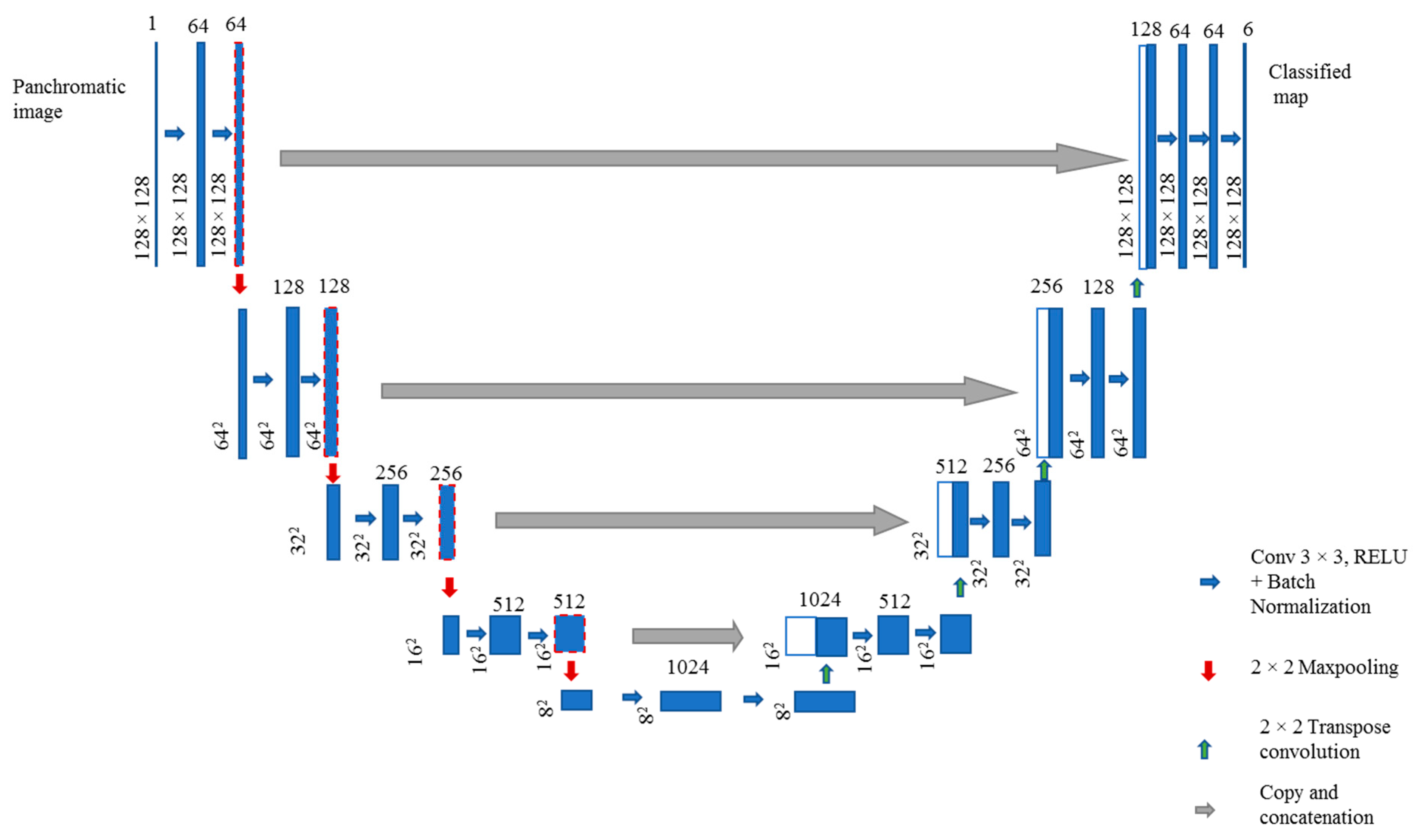
2.2.1. The U-Net Architecture
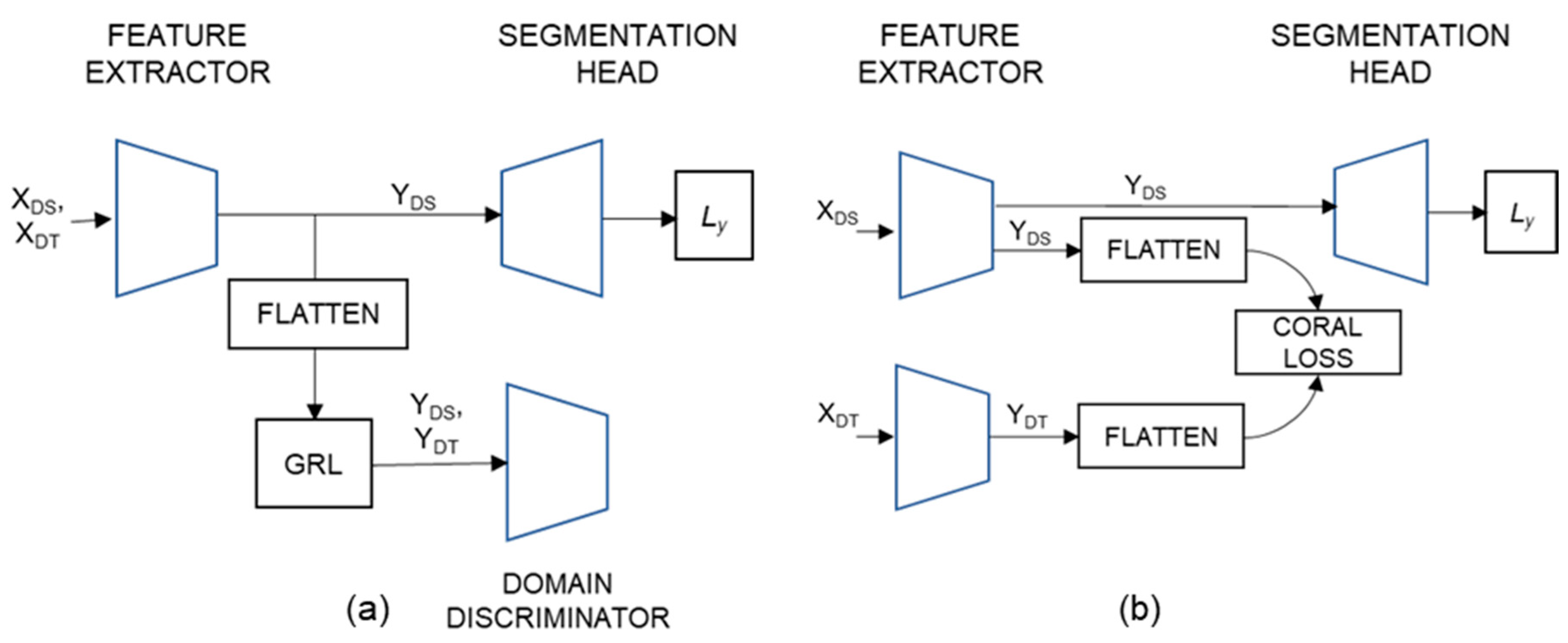
2.2.2. The Domain Adaptation Network
2.2.3. The D-CORAL Domain Adaptation Network
2.3. Experimental Set-Up
3. Results
3.1. Unsupervised Domain Adaptation Results
3.2. Fine-Tuning Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
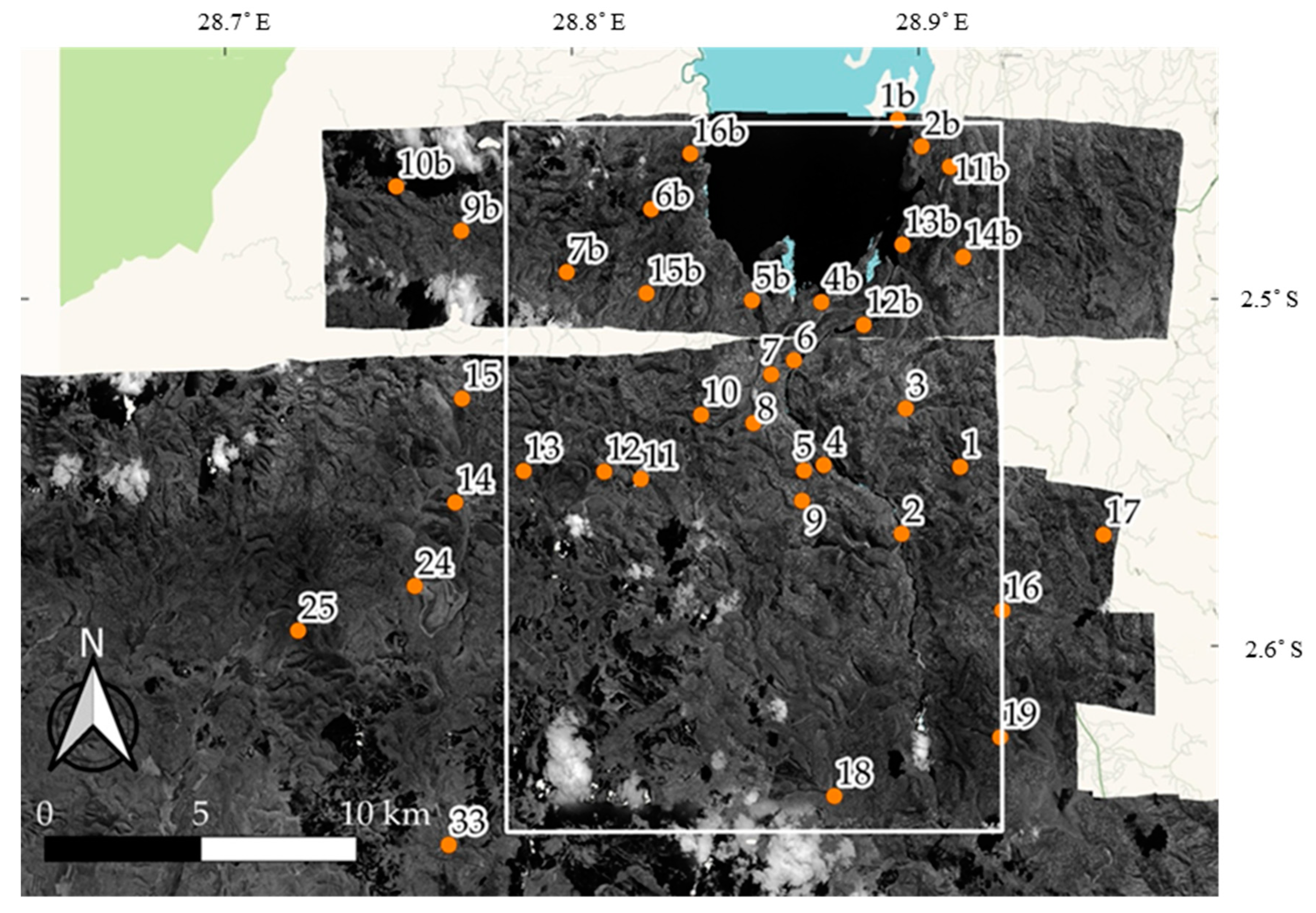
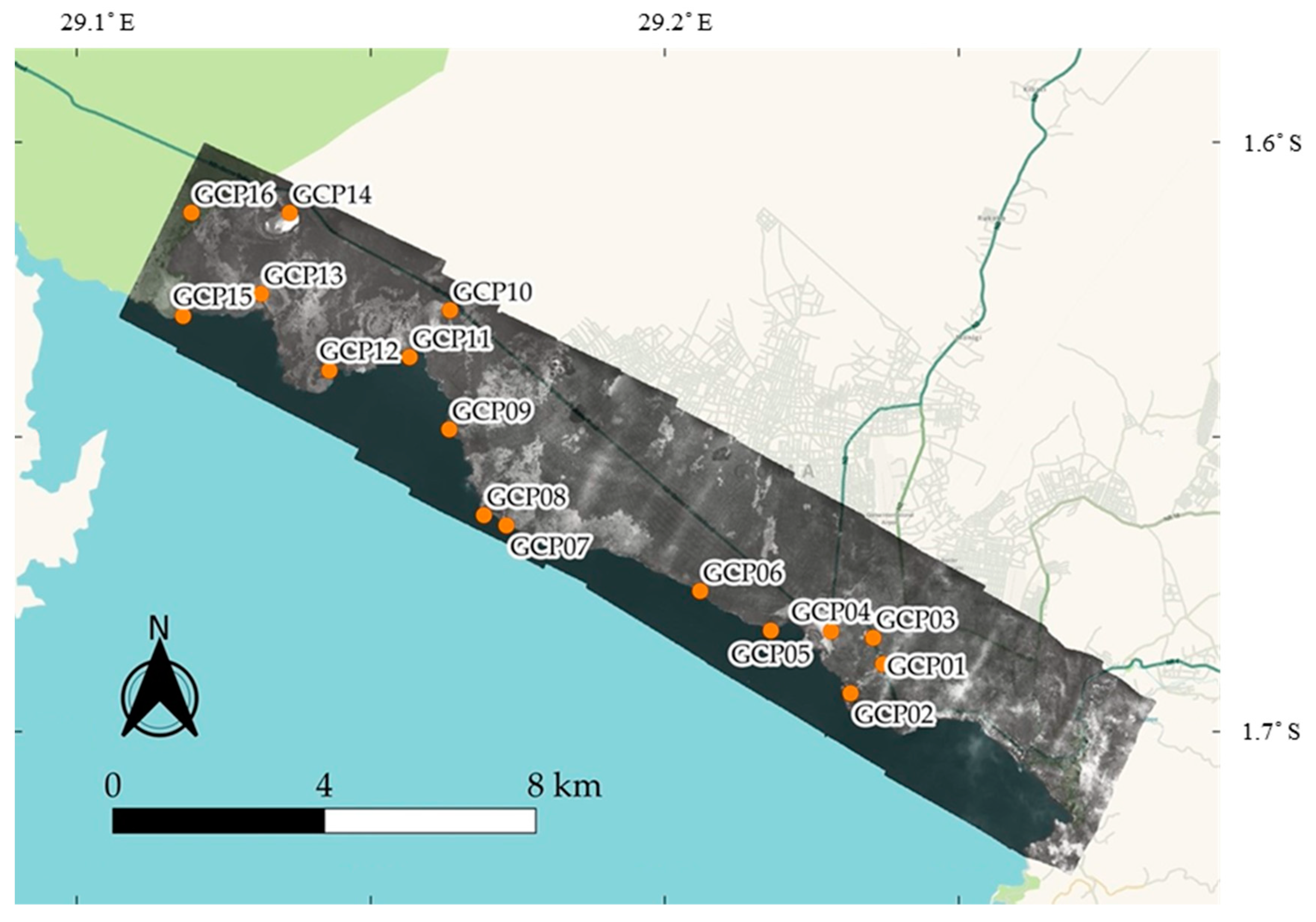
Appendix A. A Methodology to Produce the Historical Orthomosaics


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | X Error (m) | Y Error (m) | Z Error (m) | XY Error (m) | XYZ Error (m) |
|---|---|---|---|---|---|
| point 1b | 3.414 | 9.482 | 10.163 | 10.078 | 14.313 |
| point 2b * | −6.755 | 4.333 | −5.242 | 8.025 | 9.585 |
| point 4b * | 11.369 | 0.919 | 15.110 | 11.406 | 18.932 |
| point 5b * | −7.235 | 5.415 | 4.807 | 9.037 | 10.236 |
| point 6b * | −9.505 | −1.061 | −15.532 | 9.565 | 18.240 |
| point 7b * | −11.769 | −6.309 | −15.839 | 13.354 | 20.717 |
| point 9b | −15.336 | −1.060 | 9.025 | 15.372 | 17.826 |
| point 10b | 20.457 | 0.891 | 8.558 | 20.477 | 22.193 |
| point 11b * | 3.163 | −3.832 | −0.283 | 4.969 | 4.977 |
| point 12b * | 5.309 | 2.824 | 9.575 | 6.013 | 11.306 |
| point 13b * | −11.498 | −7.404 | −1.221 | 13.675 | 13.730 |
| point 14b * | 4.258 | −8.760 | −10.187 | 9.740 | 14.094 |
| point 15b * | 14.127 | 4.565 | −8.930 | 14.846 | 17.325 |
| point 16b * | −18.834 | −6.824 | −7.904 | 20.032 | 21.535 |
| point 1 * | 2.478 | 3.885 | −8.516 | 4.608 | 9.683 |
| point 2 * | −3.605 | −8.769 | 8.037 | 9.481 | 12.429 |
| point 3 * | 12.600 | −14.801 | −7.462 | 19.438 | 20.821 |
| point 4 * | 5.189 | −2.580 | 6.400 | 5.795 | 8.634 |
| point 5 * | 4.878 | −3.134 | 11.871 | 5.798 | 13.211 |
| point 6 * | 9.286 | 8.257 | 10.528 | 12.425 | 16.286 |
| point 7 * | 15.700 | 8.438 | 10.178 | 17.823 | 20.525 |
| point 8 * | 11.459 | 0.783 | −2.382 | 11.486 | 11.730 |
| point 9 * | −18.172 | 12.862 | 11.192 | 22.263 | 24.918 |
| point 10 * | −15.418 | 11.483 | −3.310 | 19.224 | 19.507 |
| point 11 * | 0.231 | 2.820 | −4.672 | 2.829 | 5.462 |
| point 12 * | −32.857 | 5.203 | −1.095 | 33.266 | 33.285 |
| point 13 * | 12.522 | 7.157 | 5.794 | 14.423 | 15.543 |
| point 14 | 24.354 | 13.152 | 13.609 | 27.679 | 30.843 |
| point 15 | 15.121 | 12.907 | 5.236 | 19.881 | 20.559 |
| point 16 | −18.571 | −1.010 | −22.021 | 18.598 | 28.824 |
| point 17 | −14.467 | −19.705 | −26.199 | 24.446 | 35.833 |
| point 18 * | −2.337 | −11.347 | 14.526 | 11.585 | 18.580 |
| point 19 * | −1.907 | 3.032 | −7.031 | 3.581 | 7.890 |
| point 20 | 0.885 | 14.277 | 3.106 | 14.305 | 14.638 |
| point 21 | −4.874 | 12.142 | 1.021 | 13.084 | 13.124 |
| point 22 | −4.813 | 4.648 | −9.204 | 6.691 | 11.379 |
| point 23 | −0.185 | −9.206 | 16.397 | 9.207 | 18.806 |
| point 24 | −10.286 | 7.173 | −1.423 | 12.540 | 12.620 |
| point 25 | 9.475 | −5.874 | 14.731 | 11.148 | 18.474 |
| point 26 | −7.180 | −10.746 | −6.214 | 12.924 | 14.340 |
| point 27 | 1.830 | 27.020 | 8.350 | 27.082 | 28.340 |
| point 28 | 0.531 | 3.849 | −1.587 | 3.886 | 4.198 |
| point 29 | 4.043 | −9.259 | 2.476 | 10.103 | 10.402 |
| point 30 | −0.248 | −4.221 | −11.690 | 4.228 | 12.432 |
| point 31 | 8.532 | −33.427 | −4.353 | 34.499 | 34.772 |
| point 32 | 6.098 | −8.682 | −14.070 | 10.609 | 17.622 |
| point 33 | −9.640 | −16.103 | −1.320 | 18.768 | 18.815 |
| point 34 | 5.560 | −9.205 | −2.927 | 10.754 | 11.145 |
| point 35 | −10.319 | 5.718 | −19.248 | 11.797 | 22.576 |
| point 36 | 7.716 | 7.628 | 11.264 | 10.850 | 15.639 |
| point 37 | −3.609 | −4.374 | 0.014 | 5.671 | 5.671 |
| RMSE | 11.267 | 10.171 | 10.253 | 15.178 | 18.317 |
| RMSE * | 11.937 | 7.072 | 9.111 | 13.875 | 16.599 |

| Label | X Error (m) | Y Error (m) | Z Error (m) | XY Error (m) | XYZ Error (m) |
|---|---|---|---|---|---|
| GCP01 | 5.921 | −1.088 | 2.568 | 6.020 | 6.545 |
| GCP02 | 6.657 | −5.622 | −4.152 | 8.713 | 9.652 |
| GCP03 | 3.288 | −0.270 | −4.614 | 3.299 | 5.672 |
| GCP04 | −26.120 | 7.834 | 3.178 | 27.269 | 27.454 |
| GCP05 | 2.794 | −3.783 | −0.755 | 4.703 | 4.763 |
| GCP06 | 4.143 | 2.316 | 5.284 | 4.746 | 7.102 |
| GCP07 | 2.000 | 0.381 | −1.497 | 2.036 | 2.527 |
| GCP08 | −2.499 | 0.873 | 5.282 | 2.647 | 5.908 |
| GCP09 | −1.990 | −0.082 | 0.872 | 1.992 | 2.174 |
| GCP10 | 23.171 | 5.186 | −4.376 | 23.745 | 24.145 |
| GCP11 | −4.471 | −2.118 | 3.156 | 4.947 | 5.868 |
| GCP12 | −4.477 | −8.620 | −5.717 | 9.713 | 11.271 |
| GCP13 | −7.450 | 5.992 | −3.027 | 9.560 | 10.028 |
| GCP14 | −10.464 | −0.739 | 0.733 | 10.490 | 10.515 |
| GCP15 | 5.092 | 2.185 | −4.333 | 5.541 | 7.034 |
| GCP16 | 4.448 | −4.314 | 7.488 | 6.196 | 9.719 |
| RMSE | 9.998 | 4.186 | 4.038 | 10.839 | 11.566 |
References
- Grippa, T.; Lennert, M.; Beaumont, B.; Vanhuysse, S.; Stephenne, N. An Open-Source Semi-Automated Processing Chain for Urban Object-Based Classification. Remote Sens. 2017, 9, 358. [Google Scholar] [CrossRef] [Green Version]
- Georganos, S.; Brousse, O.; Dujardin, S.; Linard, C.; Casey, D.; Milliones, M.; Parmentier, B.; van Lipzig, N.P.M.; Demuzere, M.; Grippa, T.; et al. Modelling and mapping the intra-urban spatial distribution of Plasmodium falciparum parasite rate using very-high-resolution satellite derived indicators. Int. J. Health Geogr. 2020, 19, 38. [Google Scholar] [CrossRef]
- Luman, D.E.; Stohr, C.; Hunt, L. Digital Reproduction of Historical Aerial Photographic Prints for Preserving a Deteriorating Archive. Am. Soc. Photogramm. Remote Sens. 1997, 63, 1171–1179. [Google Scholar]
- Corbane, C.; Florczyk, A.; Pesaresi, M.; Politis, P.; Syrris, V. GHS-BUILT R2018A—GHS built-up grid, derived from Landsat, multitemporal (1975-1990-2000-2014). Eur. Comm. Jt. Res. Cent. JRC. [Dataset] 2018. [Google Scholar] [CrossRef]
- United Nations, Department of Economic and Social Affairs, Population Division. World Urbanization Prospects: The 2018 Revision (ST/ESA/SER.A/420). United Nations: New York, NY, USA, 2019. [Google Scholar]
- UNSTATS Overview—SDG Indicators. Available online: https://unstats.un.org/sdgs/report/2018/overview/ (accessed on 20 May 2021).
- European Space Agency (ESA). EARTH OBSERVATION FOR SDG Compendium of Earth Observation Contributions to the SDG Targets and Indicators; European Space Agency (ESA): Paris, France, 2020. [Google Scholar]
- European Space Agency (ESA). Satellite Earth Observations in Support of the Sustainable Development Goals. 2018. Available online: https://data.jrc.ec.europa.eu/dataset/jrc-ghsl-10007 (accessed on 30 May 2021).
- Dewitte, O.; Dille, A.; Depicker, A.; Kubwimana, D.; Maki Mateso, J.C.; Mugaruka Bibentyo, T.; Uwihirwe, J.; Monsieurs, E. Constraining landslide timing in a data-scarce context: From recent to very old processes in the tropical environment of the North Tanganyika-Kivu Rift region. Landslides 2021, 18, 161–177. [Google Scholar] [CrossRef]
- Depicker, A.; Jacobs, L.; Mboga, N.; Smets, B.; Van Rompaey, A.; Lennert, M.; Wolff, E.; Kervyn, F.; Michellier, C.; Dewitte, O.; et al. Historical dynamics of landslide risk from population and forest cover changes in the Kivu Rift. Nat. Sustain. 2021, in press. [Google Scholar]
- Mboga, N.; Grippa, T.; Georganos, S.; Vanhuysse, S.; Smets, B.; Dewitte, O.; Wolff, E.; Lennert, M. Fully convolutional networks for land cover classification from historical panchromatic aerial photographs. ISPRS J. Photogramm. Remote Sens. 2020, 167, 385–395. [Google Scholar] [CrossRef]
- Caridade, C.M.R.; Marc, A.R.S.; Mendonc, T. The use of texture for image classification of black & white air-photographs. Int. J. Remote Sens. 2008, 29, 593–607. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 42609. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic Segmentation of Aerial Images with an Ensemble of CNSS. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 473–480. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Wegner, J.D.; Lucchi, A. Topological map extraction from overhead images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1715–1724. [Google Scholar]
- Bergado, J.R.; Persello, C.; Stein, A. Recurrent Multiresolution Convolutional Networks for VHR Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning Aerial Image Segmentation from Online Maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Tardy, B.; Inglada, J.; Michel, J. Assessment of optimal transport for operational land-cover mapping using high-resolution satellite images time series without reference data of the mapping period. Remote Sens. 2019, 11, 1047. [Google Scholar] [CrossRef] [Green Version]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain adaptation for the classification of remote sensing data: An overview of recent advances. IEEE Geosci. Remote Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A Survey of Transfer Learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Csurka, G. A comprehensive survey on domain adaptation for visual applications. In Domain Adaptation in Computer Vision Applications; Csurka, G., Ed.; Springer International Publishing: Cham, Switzerland, 2017; pp. 1–35. [Google Scholar]
- Bolte, J.A.; Kamp, M.; Breuer, A.; Homoceanu, S.; Schlicht, P.; Huger, F.; Lipinski, D.; Fingscheidt, T. Unsupervised domain adaptation to improve image segmentation quality both in the source and target domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1404–1413. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Bejiga, M.B.; Melgani, F.; Beraldini, P. Domain adversarial neural networks for large-scale land cover classification. Remote Sens. 2019, 11, 1153. [Google Scholar] [CrossRef] [Green Version]
- Elshamli, A.; Taylor, G.W.; Areibi, S.; Member, S. Multisource Domain Adaptation for Remote Sensing Using Deep Neural Networks. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3328–3340. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 443–450. [Google Scholar]
- Koga, Y.; Miyazaki, H.; Shibasaki, R. A Method for Vehicle Detection in High-Resolution Satellite Images That Uses a Region-Based Object Detector and Unsupervised Domain Adaptation. Remote Sens. 2020, 12, 575. [Google Scholar] [CrossRef] [Green Version]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep Domain Confusion: Maximizing for Domain Invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Jordan, M.I.; Edu, J.B. Learning Transferable Features with Deep Adaptation Networks. arXiv 2015, arXiv:1502.02791v2. [Google Scholar]
- Courty, N.; Flamary, R.; Habrard, A.; Rakotomamonjy, A. Joint distribution optimal transport for domain adaptation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 447–463. [Google Scholar]
- Smets, B.; Dewitte, O.; Michellier, C.; Munganga, G.; Dille, A.; Kervyn, F. Insights into the SfM photogrammetric processing of historical panchromatic aerial photographs without camera calibration information. ISPRS Int. J. Geo-Inform. 2020, in press. [Google Scholar]
- Dille, A.; Kervyn, F.; Bibentyo, T.M.; Delvaux, D.; Ganza, G.B.; Mawe, G.I.; Buzera, C.K.; Nakito, E.S.; Moeyersons, J.; Monsieurs, E.; et al. Causes and triggers of deep-seated hillslope instability in the tropics—Insights from a 60-year record of Ikoma landslide (DR Congo). Geomorphology 2019, 345, 106835. [Google Scholar] [CrossRef]
- Michellier, C.; Pigeon, P.; Paillet, A.; Trefon, T.; Dewitte, O.; Kervyn, F. The Challenging Place of Natural Hazards in Disaster Risk Reduction Conceptual Models: Insights from Central Africa and the European Alps. Int. J. Disaster Risk Sci. 2020, 11, 316–332. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Cao, K.; Zhang, X. An improved Res-UNet model for tree species classification using airborne high-resolution images. Remote Sens. 2020, 12, 1128. [Google Scholar] [CrossRef] [Green Version]
- Peng, D.; Zhang, Y.; Guan, H. End-to-End Change Detection for High Resolution Satellite Images Using Improved UNet ++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tuia, D.; Roscher, R.; Wegner, J.D.; Jacobs, N.; Zhu, X.; Camps-Valls, G. Toward a Collective Agenda on AI for Earth Science Data Analysis. IEEE Geosci. Remote Sens. Mag. 2021, 9, 88–104. [Google Scholar] [CrossRef]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 95–104. [Google Scholar]







| METHOD | Source | Goma-Gisenyi | Bukavu |
|---|---|---|---|
| Target | Bukavu | Goma-Gisenyi | |
| Target only (upper-bound) % | - | 91.28 | 94.50 |
| DANN % | - | 61.30 | 74.78 |
| D-CORAL % | - | 62.56 | 73.00 |
| Source only (lower-bound) % | - | 62.04 | 72.54 |
| - | - | - | U-Net (Upper-Bound) | DANN | D-CORAL | U-Net (Lower-Bound) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Goma-Gisenyi ->Bukavu | Bukavu (Target) | PA % | UA % | F1 % | PA % | UA % | F1 % | PA % | UA % | F1 % | PA % | UA % | F1 % | |
| BD | Class 1 | 86.1 | 66.4 | 75 | 9.7 | 56.4 | 17 | 7.2 | 62.9 | 13 | 12.7 | 56.9 | 21 | |
| HV | Class 2 | 97.1 | 94.5 | 96 | 61.8 | 53.7 | 58 | 63.0 | 53.9 | 58 | 65.7 | 53.3 | 59 | |
| MBLV | Class 3 | 90.8 | 95.9 | 93 | 55.4 | 37.8 | 45 | 58.7 | 39.7 | 47 | 51.3 | 39.7 | 45 | |
| Class 4 | 90.1 | 96.7 | 93 | 61.9 | 68.1 | 65 | 61.7 | 70.9 | 66 | 62.7 | 69.9 | 66 | ||
| Class 5 | 92 | 88.6 | 90 | 74.5 | 78.1 | 76 | 77.2 | 78.2 | 78 | 74.9 | 75.7 | 75 | ||
| Class 6 | 80.3 | 85.0 | 83 | 72.8 | 76.2 | 74 | 75.9 | 76.0 | 76 | 71.1 | 76.9 | 74 | ||
| Bukavu->Goma-Gisenyi | Goma (Target) | - | - | - | - | - | - | - | - | - | - | - | - | |
| BD | Class 1 | 79.6 | 59.2 | 68 | 19.6 | 4.8 | 8 | 13.5 | 7.97 | 10 | 9.1 | 2.4 | 4 | |
| HV | Class 2 | 96.1 | 97.4 | 97 | 78.9 | 98.2 | 88 | 75.0 | 98.6 | 85 | 74.1 | 98.5 | 85 | |
| MBLV | Class 3 | 90.2 | 93.9 | 92 | 25.1 | 59.6 | 35 | 26.5 | 57.5 | 36 | 27.0 | 55.5 | 36 | |
| Class 4 | 92.3 | 89.8 | 91 | 86.5 | 44.1 | 58 | 87.2 | 42.1 | 57 | 85.5 | 41.7 | 56 | ||
| Class 5 | 92.4 | 88.8 | 91 | 88.4 | 69.8 | 78 | 88.7 | 67.9 | 77 | 90.5 | 68.2 | 78 | ||
| Class 6 | 98.2 | 93.2 | 96 | 81.8 | 86 | 84 | 82.8 | 84.4 | 84 | 84.1 | 86.7 | 85 | ||
| - | Bukavu Target | |||||
|---|---|---|---|---|---|---|
| Number of Samples | 300 | 450 | 600 | |||
| - | OA % | F1 % | OA % | F1 % | OA % | F1 % |
| U-Net (upper bound- only target training) | 79.66 | 74.4 | 81.40 | 76.6 | 82.99 | 78.2 |
| DANN (150 from source + rest from target) | 76.91 | 73.4 | 82.19 | 77.8 | 83.16 | 79 |
| D-CORAL (150 from source + rest from target) | 78.78 | 73.8 | 80.67 | 76.4 | 82.27 | 77.6 |
| U-Net (lower bound—only source) | 63.27 | 58.4 | 62.81 | 57.4 | 62.84 | 57.4 |
| - | Goma-Gisenyi Target | |||||
|---|---|---|---|---|---|---|
| Number of Samples | 300 | 450 | 600 | |||
| - | OA % | F1 % | OA % | F1 % | OA % | F1 % |
| U-Net (upper bound- only target training) | 87.49 | 79.8 | 89.15 | 82.4 | 89.16 | 83.8 |
| DANN (150 from source + rest from target) | 87.78 | 79.8 | 88.59 | 83 | 89.70 | 84.4 |
| D-CORAL (150 from source + rest from target) | 86.94 | 80.4 | 88.94 | 84 | 89.17 | 83.6 |
| U-Net (lower bound—only source) | 72.28 | 55.6 | 72.76 | 58 | 72.21 | 54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mboga, N.; D’Aronco, S.; Grippa, T.; Pelletier, C.; Georganos, S.; Vanhuysse, S.; Wolff, E.; Smets, B.; Dewitte, O.; Lennert, M.; et al. Domain Adaptation for Semantic Segmentation of Historical Panchromatic Orthomosaics in Central Africa. ISPRS Int. J. Geo-Inf. 2021, 10, 523. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10080523
Mboga N, D’Aronco S, Grippa T, Pelletier C, Georganos S, Vanhuysse S, Wolff E, Smets B, Dewitte O, Lennert M, et al. Domain Adaptation for Semantic Segmentation of Historical Panchromatic Orthomosaics in Central Africa. ISPRS International Journal of Geo-Information. 2021; 10(8):523. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10080523
Chicago/Turabian StyleMboga, Nicholus, Stefano D’Aronco, Tais Grippa, Charlotte Pelletier, Stefanos Georganos, Sabine Vanhuysse, Eléonore Wolff, Benoît Smets, Olivier Dewitte, Moritz Lennert, and et al. 2021. "Domain Adaptation for Semantic Segmentation of Historical Panchromatic Orthomosaics in Central Africa" ISPRS International Journal of Geo-Information 10, no. 8: 523. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi10080523