
Modeling System Risk in the South African Insurance Sector: A Dynamic Mixture Copula Approach


Abstract
:1. Introduction
2. Methodology
2.1. Marginal Expected Shortfall (MES)
Expected Shortfall (ES)
2.2. Dynamic Mixture Copula-Marginal Expected Shortfall (DMC-MES)
2.2.1. Copula
2.2.2. Construction of the DMC-MES
- and are each independent and identically distributed (i.i.d) with unspecified, static distribution and
- , and
- with dynamic copula parameter .
2.3. Estimation Technique of the DMC-MES
- Step 1
- Step 2
- Step 3
2.4. The Symmetrized Joe-Clayton (SJC) Copula
2.5. Robustness Test
2.5.1. Clayton Copula
2.5.2. Gumbel Copula
2.5.3. Vector Autoregressive Model and Impulse Responses
- : an vector of time series variables;
- an vector of intercepts;
- an coefficient matrices;
- an vector of unobservable zero mean error term.
3. Empirical Analysis
3.1. Data
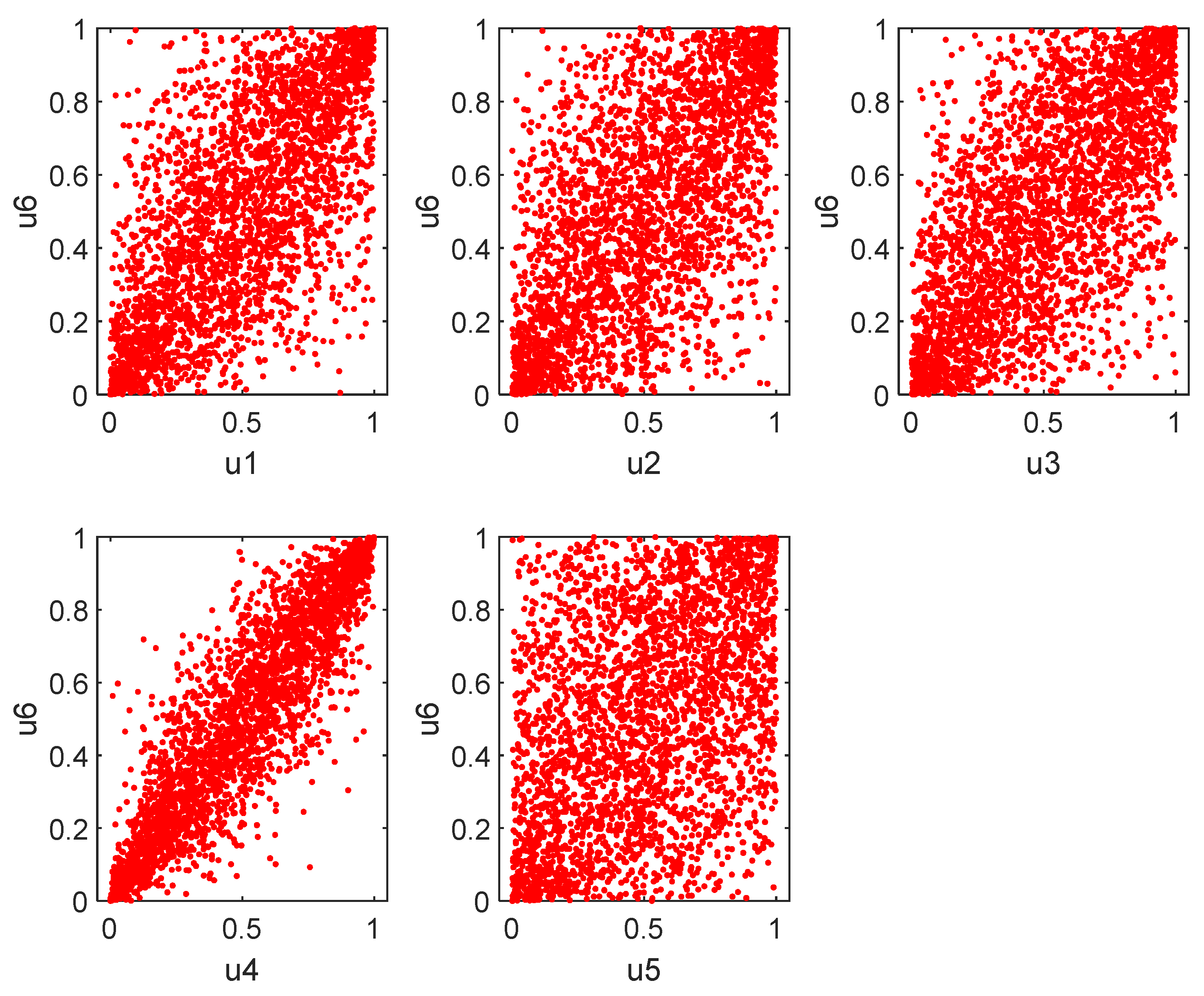
3.2. Marginal Distributions
3.3. Estimation of the Copula Models
3.4. Estimation of the DMC-MES
3.5. Robustness Test
3.5.1. Bivariate Copula
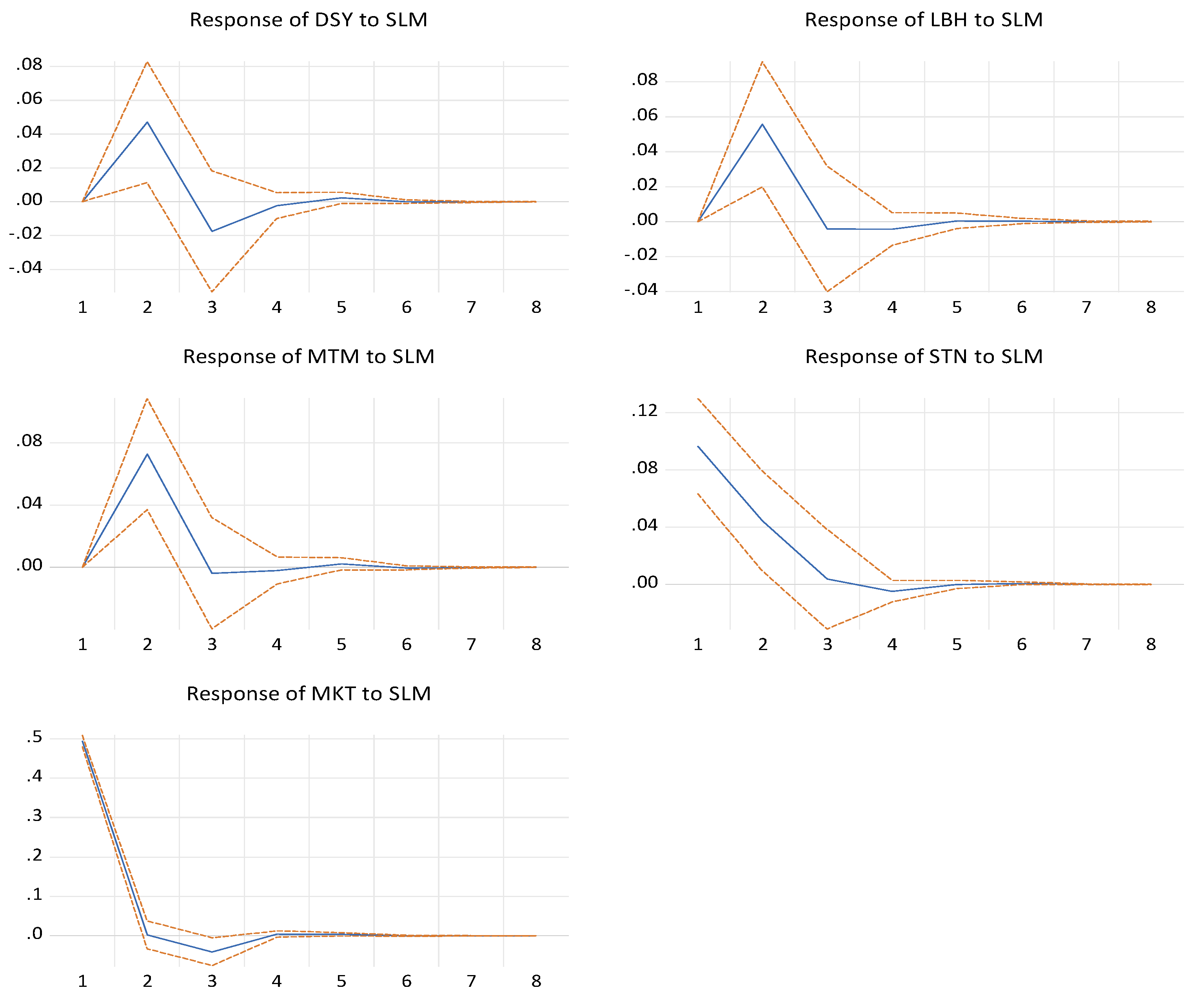
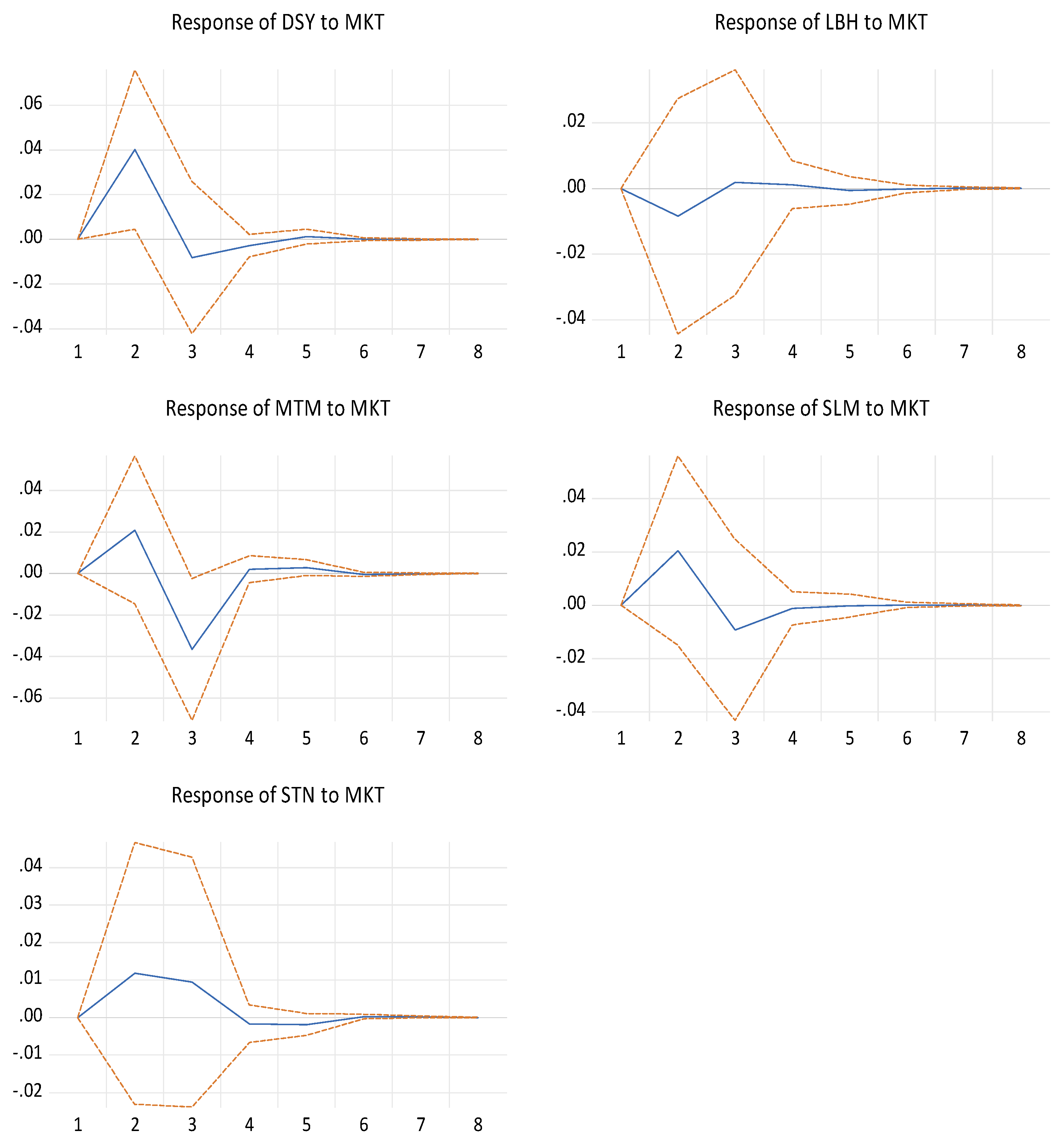
3.5.2. Impulse Response Function
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Acharya, Viral V., and Matthew Richardson. 2014. Is the Insurance Industry Systemically Risky? In Modernizing Insurance Regulation. Edited by John H. Biggs and Matthew P. Richardson. New York: John Wiley & Sons, pp. 151–79. [Google Scholar]
- Berdin, Elia, and Matteo Sottocornola. 2015. Insurance Activities and Systemic Risk. SAFE Working Paper No.121. Frankfurt: Goethe University. [Google Scholar]
- Bernal, Oscar, Jean-Yves Gnabo, and Gregory Guilmin. 2014. Assessing the Contribution of Banks, Insurance, and Other Financial Services to Systemic Risk. Journal of Banking and Finance 47: 270–87. [Google Scholar] [CrossRef]
- Bierth, Christopher, Felix Irresberger, and Gregor N. F. Weiß. 2015. Systemic Risk of Insurers Around the Globe. Journal of Banking and Finance 55: 232–45. [Google Scholar] [CrossRef]
- Blasques, Francisco, Siem Jan Koopman, and Andre Lucas. 2014a. Maximum Likelihood Estimation for Generalized Autoregressive Score Models. Tinbergen Institute Discussion Paper. Amsterdam: VU University Amsterdam and Tinbergen Institute. [Google Scholar]
- Blasques, Francisco, Siem Jan Koopman, and Andre Lucas. 2014b. Stationarity and Ergodicity of Univariate Generalized Autoregressive Score Processes. Electronic Journal of Statistics 8: 1088–112. [Google Scholar] [CrossRef]
- Cerrato, Mario, John Crosby, Minjoo Kim, and Yang Zhao. 2015. Correlated Defaults of UK Banks: Dynamics and Asymmetries. Working paper 2015-24. Glasgow: Business School-Economics, University of Glasgow. [Google Scholar]
- Creal, Drew, Siem Jan Koopman, and Andre Lucas. 2013. Generalized Autoregressive Score Models with Applications. Journal of Applied Econometrics 28: 777–95. [Google Scholar] [CrossRef] [Green Version]
- Drakos, Anastassios A, and Georgios Kouretas. 2015. Bank Ownership, Financial Segments, and the Measurement of Systemic Risk: An Application of CoVaR. International Review of Economics and Finance 40: 127–40. [Google Scholar] [CrossRef]
- Dungey, Mardi, Matteo Luciani, and David Veredas. 2014. The Emergence of Systemically Important Insurers. Econometric Modeling: Capital Markets Risk eJournal. [Google Scholar] [CrossRef] [Green Version]
- Eckernkemper, Tobias. 2018. Modeling Systemic Risk: Time-Varying Tail Dependence when Forecasting Marginal Expected Shortfall. Journal of Financial Econometrics 16: 63–117. [Google Scholar] [CrossRef]
- Eling, Martin, and David Antonius Pankoke. 2016. Systemic Risk in the Insurance Sector: A review and Direction for Future Research. Risk Management and Insurance Review 19: 249–84. [Google Scholar] [CrossRef] [Green Version]
- ECB, European Central Bank. 2013. Financial Stability Review. Frankfurt: European Central Bank. [Google Scholar]
- Glosten, Lawrence. R., Ravi Jagannathan, and David E. Runkle. 1993. On the Relation Between the Expected Value and the Volatility of Nominal Excess Return on Stocks. Journal of Finance 48: 1779–801. [Google Scholar] [CrossRef]
- Grace, Martin F. 2011. The Insurance Industry and Systemic Risk: Evidence and Discussion. Working Paper. Atlanta: Georgia State University. [Google Scholar]
- Hansen, Bruce E. 1994. Autoregressive Conditional Density Estimation. International Economic Review 35: 705–30. [Google Scholar] [CrossRef]
- IMF, International Monetary Fund. 2009. Global Financial Stability Report. Washington: International Monetary Fund. [Google Scholar]
- IISA, Insurance Institute of South Africa. 2016. Business unusual. Paper presented at 43rd Annual Insurance Conference, Rustenburg, South Africa, July 2016. [Google Scholar]
- Kaserer, Christoph, and Christian Klein. 2019. Systemic Risk in Financial Markets: How Systemically Important Are Insurers? Journal of Risk and Insurance 86: 729–59. [Google Scholar] [CrossRef]
- National Treasury of South Africa. 2011. A Safer Financial Sector to Serve South Africa Better. Pretoria: National Treasury. [Google Scholar]
- Sklar, A. 1959. Fonctions de Repartition a n Dimensions et Leurs Marges. Paris: Publications de l’Institut de Statistique de l’Universite de Paris, vol. 8, pp. 229–31. [Google Scholar]
- Weiß, Gregor N.F, and Janina Muhlnickel. 2014. Why do Some Insurers Become Systemically Relevant? Journal of Financial Stability 13: 95–117. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Company | Symbol | Sector |
|---|---|---|
| Discovery Limited | DSY | Life Insurance |
| Liberty Holdings Limited | LBH | Life Insurance |
| Momentum Metropolitan Holdings | MTM | Life Insurance |
| Sanlam Limited | SLM | Life Insurance |
| Santam Limited | SNT | Nonlife Insurance |
| Discovery | Liberty | Momentum | Sanlam | Santam | |
|---|---|---|---|---|---|
| Mean | 0.041 | −0.005 | 0.005 | 0.03 | 0.026 |
| Std.Dev. | 1.957 | 1.892 | 1.868 | 1.959 | 1.712 |
| Skewness | −0.527 | 0.129 | −0132 | −0.429 | −0.474 |
| Kurtosis | 12.695 | 17.853 | 7.183 | 7.703 | 14.13 |
| JB test p-value | 0.001 | 0.001 | 0.001 | 0.001 | 0.001 |
| Model | Ljung–Box Test | Arch LM Test | ||
|---|---|---|---|---|
| Discovery | AR(1)-GJRGARCH(1,1) | Standardized residuals Standardized squared residuals | 0.4106 0.06036 | 0.3931 |
| Liberty | AR(1)-GJRGARCH(1,1) | Standardized residuals Standardized squared residuals | 0.4117 0.2674 | 0.8041 |
| Momentum | AR(1)-GJRGARCH(1,1) | Standardized residuals Standardized squared residuals | 0.1185 0.0823 | 0.6793 |
| Sanlam | AR(1)-GJRGARCH(1,1) | Standardized residuals Standardized squared residuals | 0.6952 0.7390 | 0.5538 |
| Santam | AR(1)-GJRGARCH(1,1) | Standardized residuals Standardized squared residuals | 0.9213 0.7559 | 0.5491 |
| Market | AR(1)-GJRGARCH(1,1) | Standardized residuals Standardized squared residuals | 0.31172 0.4614 | 0.4527 |
| AR (1) | GJR-GARCH (1,1) | Kurtosis | Skewness | |||||
|---|---|---|---|---|---|---|---|---|
| Discovery | 0.0476 (0.0252) | −0.0058 (0.0183) | 0.0385 *** (0.0115) | 0.0517 *** (0.0126) | 0.9058 *** (0.0133) | 0.0669 *** (0.0182) | 4.9419 *** (1.571) | −0.2145 *** (0.0259) |
| Liberty | 0.0159 (0.0251) | −0.0664 *** (0.0165) | 0.0366 *** (0.0054) | 0.0001 (0.0036) | 0.9573 *** (0.0024) | 0.0603 *** (0.0024) | 12.32 *** (0.330) | −0.0801 *** (0.0246) |
| Momentum | 0.0321 (0.0263) | −0.0683 *** (0.0181) | 0.0567 *** (0.0214) | 0.0564 *** (0.0173) | 0.9138 *** (0.0191) | −0.0318 * (0.0171) | 8.3628 *** (0.9165) | 0.0101 *** (0.0027) |
| Sanlam | 0.0221 (0.0259) | −0.0690 *** (0.0180) | 0.0526 *** (0.0154) | 0.0353 *** (0.0123) | 0.9098 *** (0.0138) | 0.0849 *** (0.0182) | 4.7317 *** (1.3719) | −0.1677 *** (0.0153) |
| Santam | 0.0299 (0.0242) | −0.1172 *** (0.0182) | 0.4707 *** (0.1510) | 0.2065 *** (0.0048) | 0.6849 *** (0.0737) | 0.0292*** (0.0046) | 16.038 *** (2.195) | −0.6265 ** (0.249) |
| Weight | GAS (1,1) | ||||||
|---|---|---|---|---|---|---|---|
| Discovery | 0.392 *** (0.031) | 0.109 *** (0.078) | 0.002 *** (0.0001) | 0.233 ** (0.118) | 0.012 *** (0.004) | 0.849 *** (0.107) | 0.998 *** (0.002) |
| Liberty | 0.485 *** (0.039) | 0.0005 *** (0.00001) | 0.0206 (0.021) | 0.036 *** (0.009) | 0.136 (0.097) | 0.998 *** (0.004) | 0.959 *** (0.045) |
| Momentum | 0.463 *** (0.065) | −0.003 *** (0.0001) | 0.007 *** (0.0001) | 0.067 (0.104) | 0.023 *** (0.0012) | 1.003 *** (0.0001) | 0.989 *** (0.0004) |
| Sanlam | 0.347 *** (0.029) | −0.002 *** (0.0001) | −0.001 *** (0.0005) | 0.011 (0.012) | 0.044 *** (0.008) | 1.0014 *** (0.0001) | 1.0013 *** (0.0003) |
| Santam | 0.423 *** (0.057) | −0.002( 0.004) | 0.0001 (0.0004) | 0.094 (0.09) | 0.034 (0.041) | 0.995 *** (0.011) | 0.998 *** (0.003) |
| Weight | GAS (1,1) | ||||||
|---|---|---|---|---|---|---|---|
| Discovery | 0.639 *** (0.044) | −0.006 (0.026) | 0.082 (0.113) | 0.144 *** (0.093) | 0.175 (0.235) | 0.659 *** (0.221) | 0.539 (0.606) |
| Liberty | 0.555 *** (0.049) | −0.132 (0.105) | −0.327 (0.241) | 0.229 (0.159) | −0.175 (0.227) | 0.497 (0.329) | 0.394 (0.641) |
| Momentum | 0.567 *** (0.0009) | −0.0006 *** (0.00001) | −0.002 ** (0.0001) | −0.017 *** (0.0001) | 0.048 ** (0.003) | 1.0004 *** (0.0001) | 0.991 *** (0.0004) |
| Sanlam | 0.696 *** (0.045) | 0.019 *** (0.009) | 0.039 (0.029) | 0.032 ** (0.012) | −0.154 (0.114) | 0.982 *** (0.009) | 0.961 *** (0.029) |
| Santam | 0.643 *** (0.086) | −0.003 (0.006) | −1.212 ** (0.524) | 0.042 (0.047) | 2.159 (1.528) | 0.996 *** (0.007) | 0.948 *** (0.316) |
| Time-Varying SJC Copula | |||||
|---|---|---|---|---|---|
| Discovery | Liberty | Momentum | Sanlam | Santam | |
| 1.958 (1.58) | 2.032 ** (0.96) | 0.094 * (0.05) | 8.707 (23.14) | −0.040 (0.37) | |
| −9.999 (8.21) | −9.969 ** (4.99) | −0.493 * (0.28) | 9.761 *** (1.24) | −0.733 (0.84) | |
| 0.431 (0.62) | −0.424 (0.64) | 0.976 *** (0.02) | 4.477 (39.03) | 0.832 *** (0.25) | |
| 2.849 ** (1.41) | 0.111 *** (0.03) | 2.944 *** (0.48) | 9.984 *** (0.99) | −0.094 (0.39) | |
| −9.999 (9.79) | −0.526 *** (0.17) | −9.997 *** (2.45) | 9.889 (92.22) | −1.546 (1.95) | |
| −0.040 (0.33) | 0.974 *** (0.01) | −0.647 *** (0.13) | −9.796 *** (2.15) | 0.143 (0.34) | |
| Copulas | tvSJC | RC&C | RG&G |
|---|---|---|---|
| Copula Likelihood | |||
| Discovery | −1115.9 | −1093.4 | −1117.8 |
| Liberty | −768.0 | −762.9 | −778.4 |
| Momentum | −910.7 | −903.3 | −925.6 |
| Sanlam | −2344.0 | −2693.7 | −2774.4 |
| Santam | −304.1 | −305.9 | −307.5 |
| Mean | Std.Dev | Min | Max | Ranking | |
|---|---|---|---|---|---|
| Discovery | 0.983 | 7.709 | 0.0551 | 334.3986 | 2 |
| Liberty | 0.583 | 5.748 | 0.0375 | 216.4342 | 4 |
| Momentum | 0.805 | 5.580 | 0.0618 | 223.8966 | 3 |
| Sanlam | 1.942 | 18.132 | 0.1128 | 894.1638 | 1 |
| Santam | −0.007 | 0.100 | −2.3490 | 4.3039 | 5 |
| Copula | Parameters | 95% CI | AIC | BIC |
|---|---|---|---|---|
| Gumbel(MKT) | 3.431 | [3.343, 3.519] | 5160.0 | 5170.0 |
| Clayton(MKT) | 3.568 | [3.462, 3.673] | 4510.0 | 4520.0 |
| Gumbel(DSY) | 1.450 | [1.412, 1.487] | 780.4 | 786.4 |
| Clayton(DSY) | 0.781 | [0.726, 0.837] | 802.1 | 808.1 |
| Gumbel(LBH) | 1.384 | [1.349, 1.419] | 617.6 | 623.7 |
| Clayton(LBH) | 0.636 | [0.582, 0.689] | 594.0 | 600.1 |
| Gumbel(MTM) | 1.455 | [1.418, 1.492] | 791.2 | 797.2 |
| Clayton(MTM) | 0.753 | [0.697, 0.808] | 765.3 | 771.3 |
| Gumbel(STN) | 1.775 | [1.149, 1.206] | 175.5 | 181.6 |
| Clayton(STN) | 0.354 | [0.305, 0.403] | 233.9 | 240.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muteba Mwamba, J.W.; Angaman, E.S.E.F. Modeling System Risk in the South African Insurance Sector: A Dynamic Mixture Copula Approach. Int. J. Financial Stud. 2021, 9, 29. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9020029
Muteba Mwamba JW, Angaman ESEF. Modeling System Risk in the South African Insurance Sector: A Dynamic Mixture Copula Approach. International Journal of Financial Studies. 2021; 9(2):29. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9020029
Chicago/Turabian StyleMuteba Mwamba, John Weirstrass, and Ehounou Serge Eloge Florentin Angaman. 2021. "Modeling System Risk in the South African Insurance Sector: A Dynamic Mixture Copula Approach" International Journal of Financial Studies 9, no. 2: 29. https://0-doi-org.brum.beds.ac.uk/10.3390/ijfs9020029