1. Introduction
In finance, duration is defined as the time interval between two consecutive events. For example, duration data that have been studied by researchers are trade, quote, price, transaction, and volume. As discussed by [
1], financial durations played an important role in understanding and processing of private and public information in a financial market. With the advancement of technology, high frequency financial duration data can be recorded and are collected in irregular time intervals. In general, they show a strong autocorrelation which can be used to study the intraday market behaviours and dynamic of trades.
The duration models originated from the family of autoregressive conditional duration (ACD) model introduced by [
2] and treated the transaction arrival time as a random variable in the dependent point process where its conditional intensity depends on the past duration. In the early stage, ACD models have been expressed in a linear model specification consisting of non-negative model parameters and non-negative error distributions such as the exponential (Exp) and Weibull (Wei) distributions [
2] and the generalised gamma (GG) distribution [
3]. The limitation of these models is whenever some other variables having negative coefficients are assigned to the linear autoregressive equation, the durations might become negative. Meanwhile, it is quite frequent that these ACD models will impose an exponential decay pattern on the autocorrelation function and, in general, will not account for the long-range dependence in durations. Therefore, the logarithmic ACD (LogACD) model of [
4] was introduced with no restrictions on the sign of the parameters to guarantee the positiveness of the process and the fractionally integrated ACD (FIACD) model of [
5] was introduced to capture the long-range dependence in durations, which is shown to be more flexible than the linear ACD model. Recently, several nonlinear ACD models have been developed to better delineate the trade duration process, see for example the threshold ACD model [
6], the asymmetric ACD and asymmetric LogACD models [
7], and the augmented ACD model [
8]. An informative review on the various ACD models with its applications can be obtained in [
9,
10,
11].
It being the case that most of the ACD models belong to the family of one-component models, [
12] introduced the two-component ACD (CACD) model to fit the International Business Machines (IBM) trade durations to measure the impact of durations on the price volatility. The main feature of this duration model is that it consists of a long-run (trend) component and a short-run (transitory) component, and the sum of these two components establishes a long-range dependence in the duration process, which helps in capturing the complexity of duration dynamics in contrast to the one-component ACD models. To this end, [
13] developed an alternative way of capturing long-range dependence in the trade duration series by extending the component multiplicative error model. However, little is known about the extension of the CACD model with no restrictions on the sign of the parameters, and hence we are keen to answer the research question of whether the extended CACD model with no sign restrictions will provide a better fit to the data as compared to the one-component models as well as the CACD model.
The choice of error distributions plays an important role in ACD modelling. [
2] introduced the basic ACD model by considering the Exp and Wei as the error distributions. The Exp distribution with a constant hazard function and the Wei distribution with monotonically increasing or decreasing hazard function, however, are too restrictive, and thus, various error distributions have been considered to provide greater flexibility to the constructed models. Some examples include the GG distribution [
3], the Burr type XII (Burr) distribution [
14], the generalised F distribution [
15], the Pareto distribution [
16], the Lognormal distribution [
17], the extended Weibull distribution [
18], the Fréchet distribution [
19], the generalised beta of type 2 (GB2) distribution [
20] and the mixture of GB2 distribution [
21]. Comparison of the ACD modelling performance using various distributions was addressed by [
22,
23,
24], providing distributions either monotonically increasing, decreasing or non-monotonic shapes such as bathtub or upside-down-bathtub shape of the hazard function constituting of, at most, a single turning point. To the best of our knowledge, there has thus far been relatively little research into this area where most of the ACD models with error distributions have only a single turning point hazard function. In this aspect, we are interested to study this to see if the hazard function of the error distribution consisting of more than one turning point with a roller-coaster shape would help to increase the flexibility of the model.
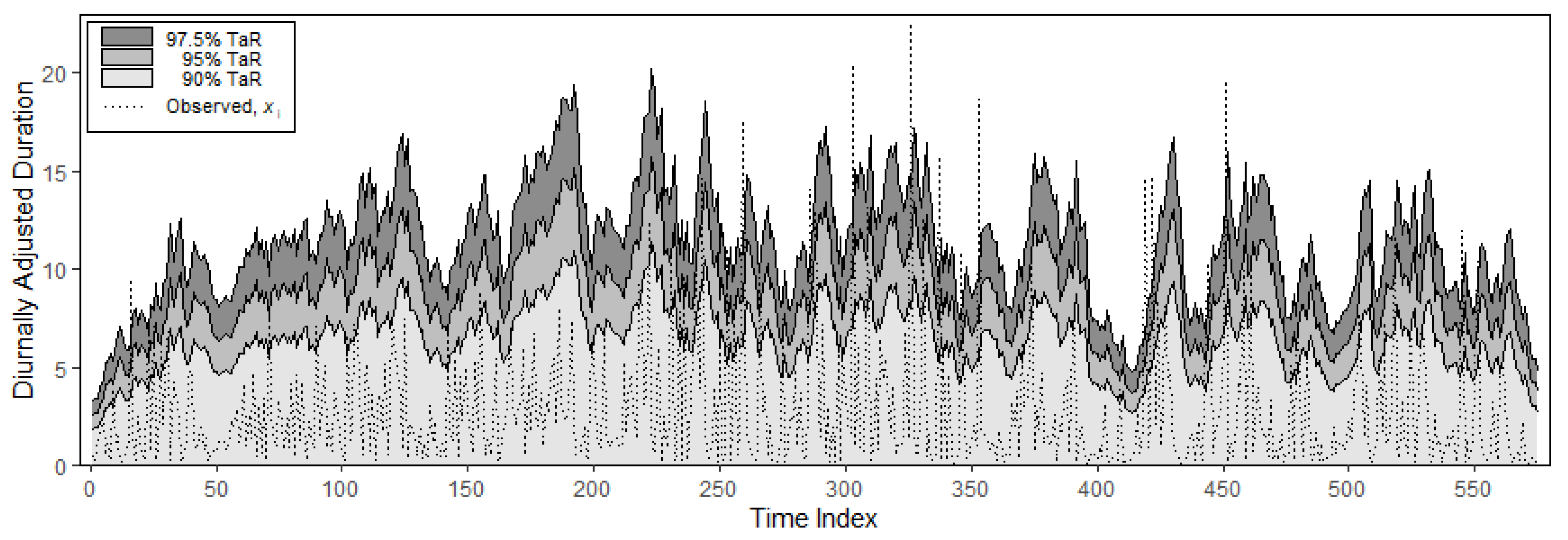
The liquidity risk such as the minimal time without any trade occurring is valuable for market makers and traders and is analogous to the value-at-risk introduced in volatility literature. Time-at-risk (TaR) is defined as the extreme risk of time between two consecutive transactions at a certain risk level. [
25] showed that the TaR can be calculated from the product of the conditional expectation of durations and the inverse of the cumulative distribution associated with the error term. In the meantime, [
21] used the basic ACD models with mixed distribution to compute the TaR and conditional TaR (CTaR) forecasts of trade durations, and the TaR performance was then evaluated using violation rate and quantile loss function. The performances of TaR and CTaR were further tested by employing some other common backtests as illustrated by [
26,
27] to confirm the accuracy of their forecasts.
The contribution of this paper is threefold. Firstly, we propose the logarithmic CACD (LogCACD) model, which allows for no restrictions on the sign of the parameters while the conditional expectation of durations is decomposed into the long- and short-run components. As the error distribution is a crucial factor in constructing a model, our second aim is to model the duration data using the LogCACD model with flexible extended generalised inverse Gaussian (EGIG) distribution having the roller-coaster-shaped hazard function. The effects of model specification and error distribution on the performances of various ACD models are then examined by comparing the in-sample model fits and out-of-sample forecasts. Subsequently, the in-sample model fitting performance is evaluated using several criteria and loss functions while the out-of-sample forecasts are tested using the model confidence set (MCS) procedure of [
28] to acquire a superior set of models (SSM). Lastly, the empirical study of IBM trade durations is investigated with the detailed illustration of the model fitting and forecasts of TaR under various risk levels. It follows that the SSM are computed and the accuracy of the TaR forecasts is tested by the Kupiec likelihood ratio (KLR) test [
26].
The remainder of this paper is organised as follows.
Section 2 reviews several existing ACD models including the CACD model and the motivation of the LogCACD model, while
Section 3 introduces the EGIG distribution and other error distributions adopted for these duration models.
Section 4 describes the empirical data used in the preliminary analysis, and
Section 5 reports the model fitting and forecasting results as well as the forecast of TaR. Finally,
Section 6 concludes the paper.
3. Error Distributions for ACD Models and Estimation
To improve the flexibility of hazard function in ACD models, we use the EGIG distribution proposed by [
31], which contains more than one turning point in the hazard function. Further details of the EGIG distribution, its statistical properties, inferences and applications are available in [
32,
33,
34]. To facilitate the comparison, several error distributions such as Wei, GG, Burr and GB2 are also considered.
Let
be a EGIG distributed random variable, such that
. The pdf, cumulative density function (cdf) and hazard function of
, are, respectively, given by
and
where
,
,
,
,
is the modified Bessel function of the third kind with index
and
is the generalised incomplete gamma function, which can be defined as the power series expansion in its general form of
given by
with
is the ordinary incomplete gamma function.
Let
be a standardised EGIG distributed random variable such that
Then, the scale parameter
can be reparametrised as
By substituting the
into Equations (12)–(14), the corresponding pdf, cdf and hazard function of
are expressed as
and
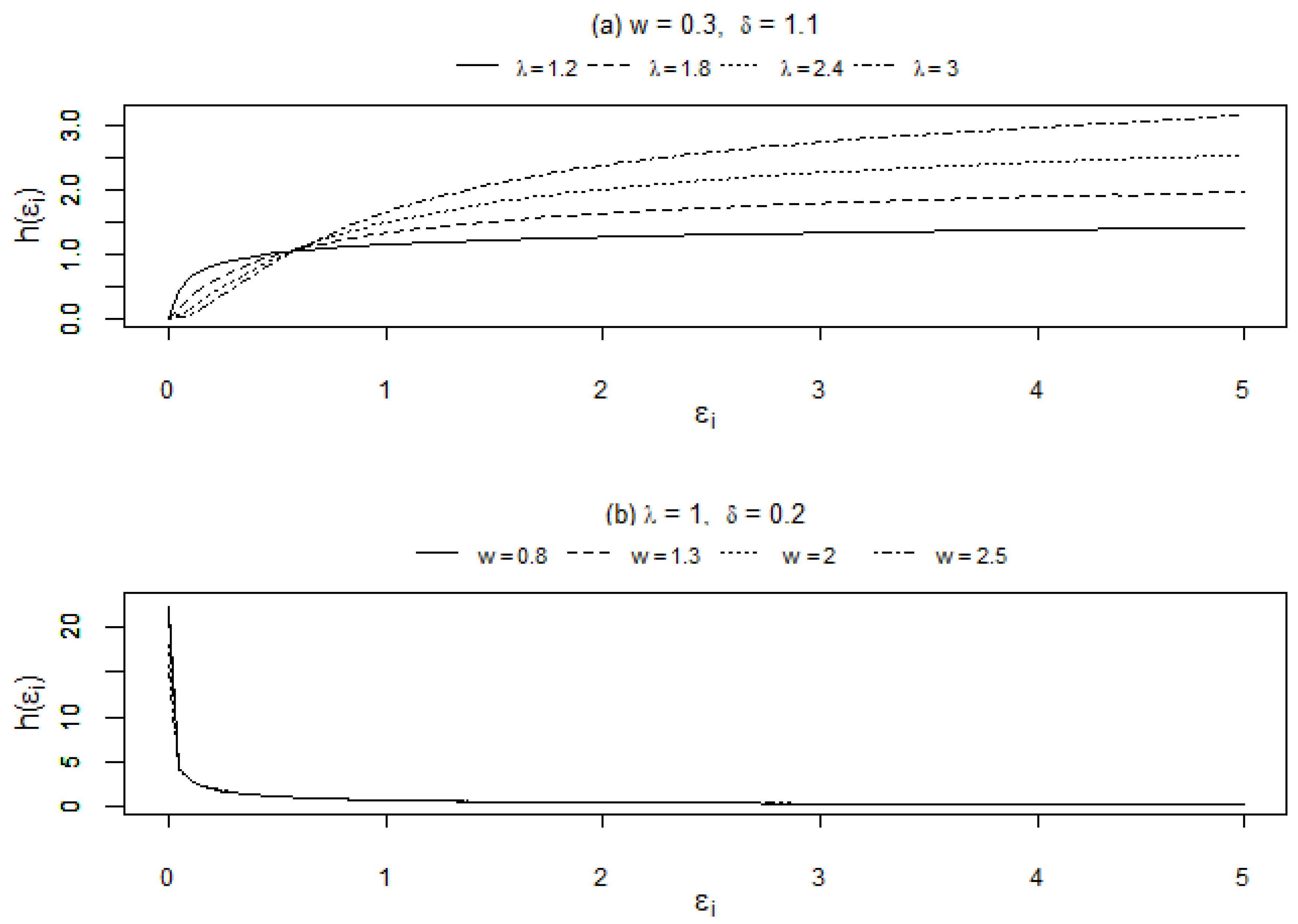
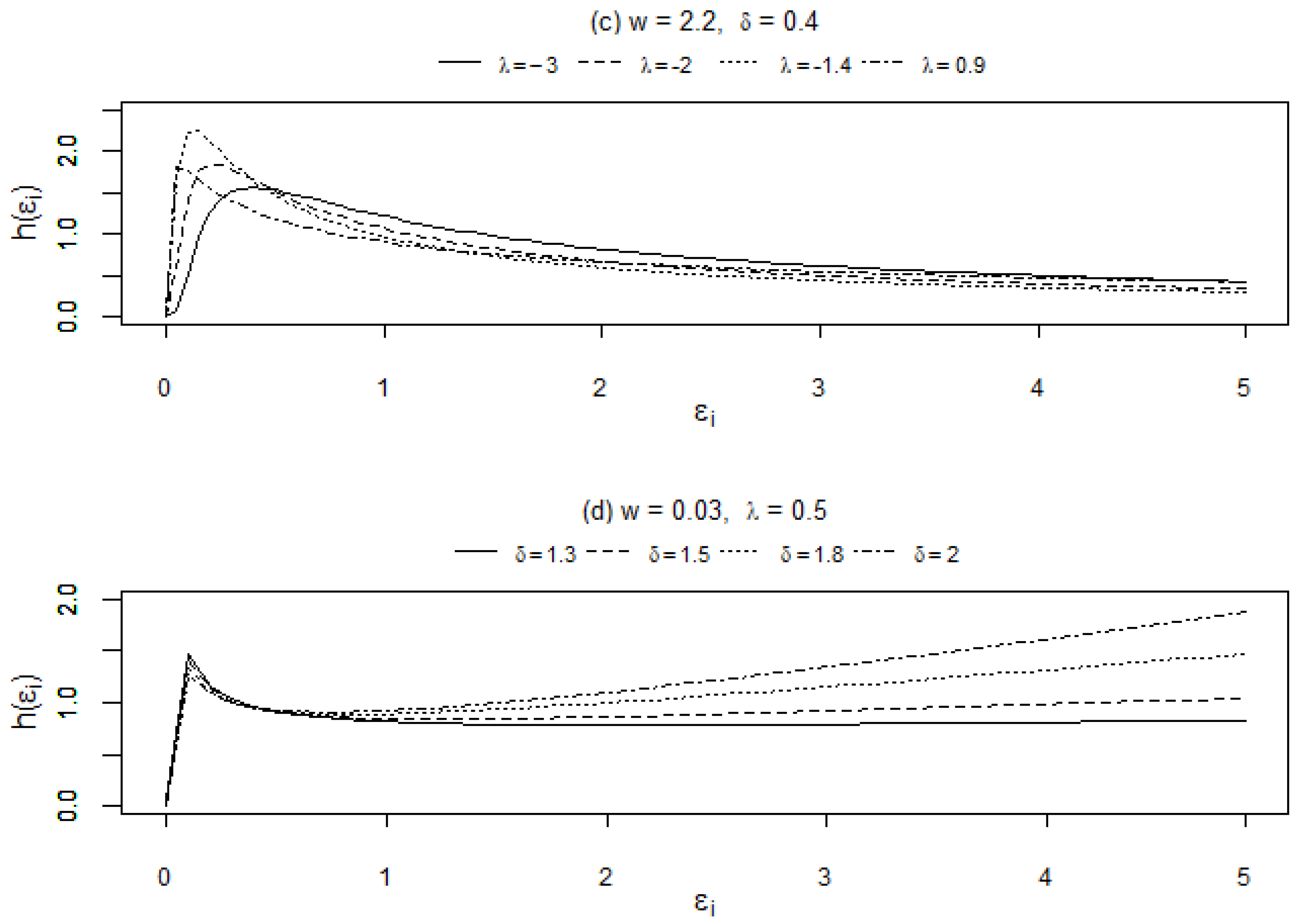
The hazard functions of the standardised EGIG distribution will allow for various shapes such as monotonically increasing (I), monotonically decreasing (D), upside-down bathtub (UB) and upside-down bathtub then bathtub (UBB). Different shapes of the standardised EGIG hazard function can be acquired and subjected to the constraint,
, that is
and other constraints on the distribution parameters as presented in
Table 1 (see [
33] for further details).
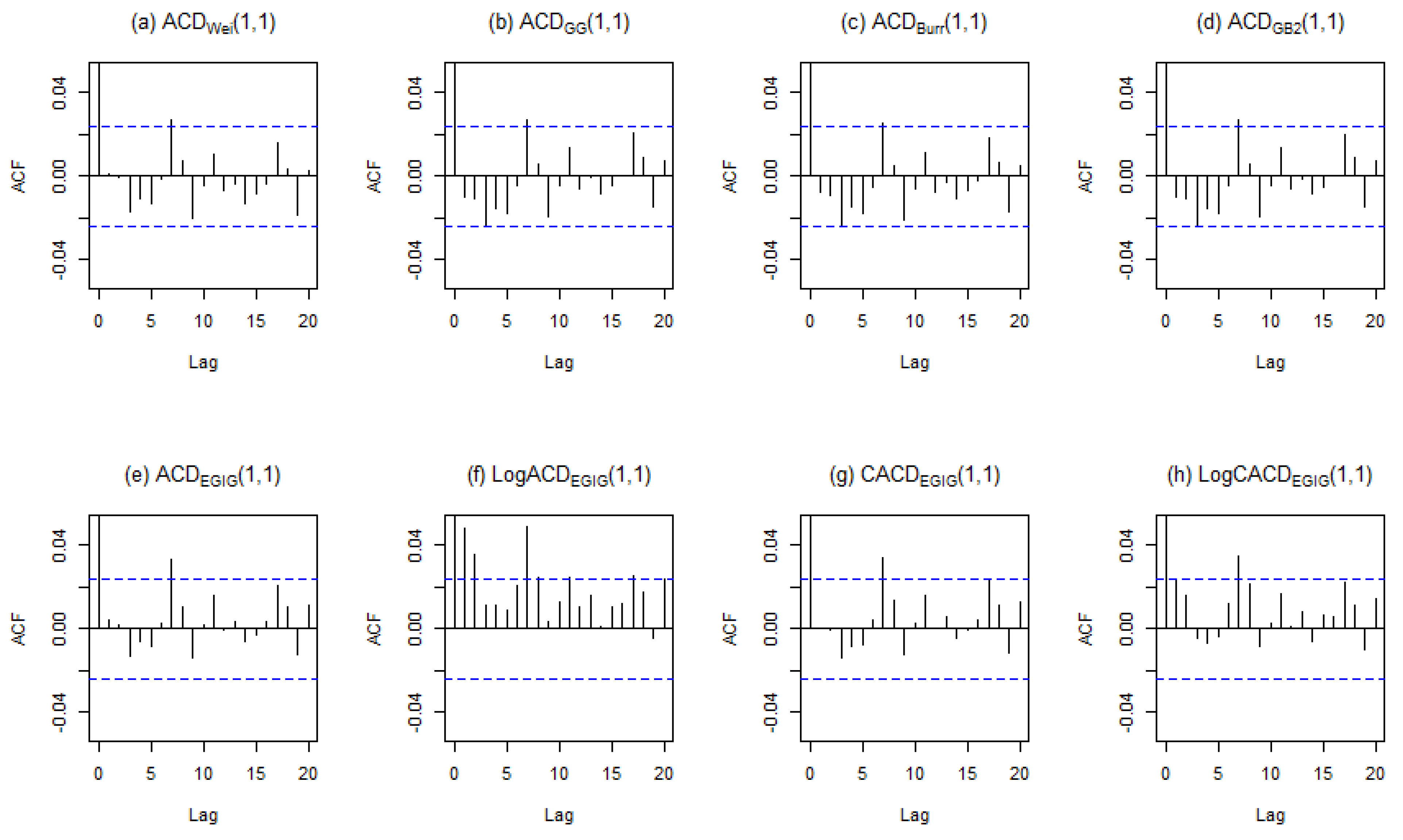
Figure 1 shows the plots for hazard shapes using different sets of parameters with (a) monotonically increasing (I), (b) monotonically decreasing (D), (c) upside-down bathtub (UB) and (d) upside-down bathtub then bathtub (UBB) which consists of more than one turning point.
For illustration purposes, other standardised error distributions were also considered in ACD models, with their respective pdfs and standardisation constraints reflected in
Table 2. Henceforth, the ACD model with any distribution D will be notated as ACD
D.
From Equation (2), the conditional pdf of
for the ACD
EGIG(1,1) and CACD
EGIG(1,1) models can be written as
i.e.,
.
The corresponding conditional log-likelihood (LL) function is given by
However, since the initial is unknown, we set , where is the sample mean of
From Equation (9), the conditional pdf of
for the LogACD
EGIG(1,1) and LogCACD
EGIG(1,1) models can be written as
i.e.,
.
The corresponding conditional LL function is given by
with that
.
For the estimation parts, the maximum likelihood estimates are obtained by maximising the LL functions given by Equations (19) and (21) using the R functions such as gosolnp and optim, where the gosolnp is to find some suitable initial values of the parameters and the optim is utilised in optimisation process. The standard errors of the estimates can then be acquired via the R function such as numericHessian.
4. Data Description
The intra-daily trading times and prices from 3–16 December 2019 in the IBM stock listed on the New York Stock Exchange (NYSE) were retrieved from the Bloomberg Terminal. By removing the data recorded outside the regular operating hours of NYSE, a total of 125,658 transactions were collected from 9:30:00 a.m. to 4:00:00 p.m. and these transactions were treated consecutively from day to day for the calculation of the duration between two consecutive transactions. After filtering out the zero-valued durations and the durations between two consecutive days, a series of 46,288 transactions is obtained. For the given series, we define an event as the IBM stock price changes being greater than or equal to
$0.02, which is a similar procedure to that demonstrated by [
35]. To be more concrete, we first calculated the duration of each event that occurred and removed the durations between two consecutive days to obtain a series of 7208 durations. The first
N = 6633 durations from 3–13 December 2019 were then used for in-sample model fitting, and the one-step-ahead rolling-window technique was used to forecast the out-of-sample duration for
h = 575 durations on the next trading day of 16 December 2019.
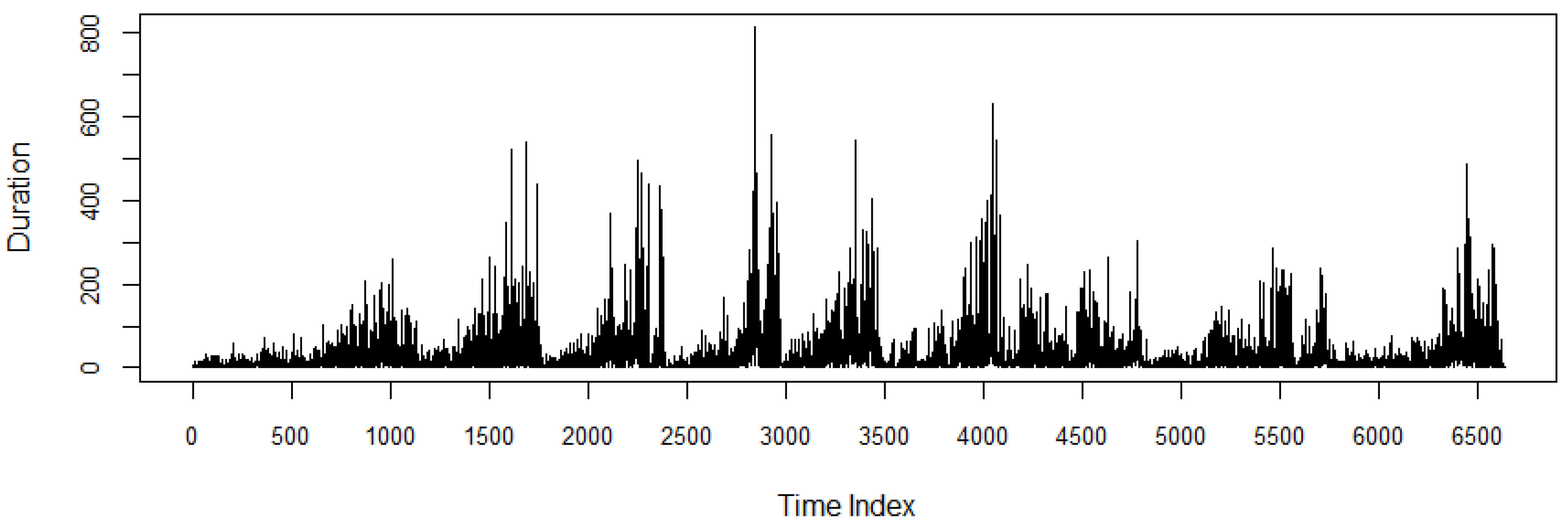
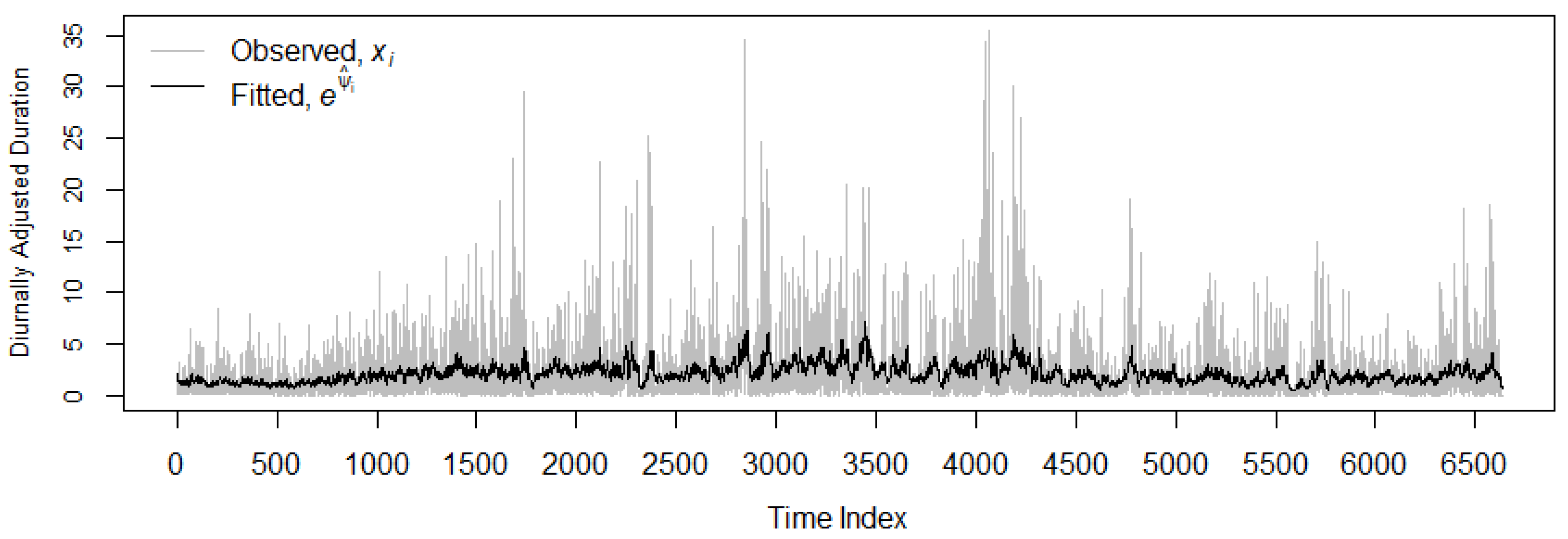
The time series plot of the duration series for the period 3–13 December 2019 is depicted in
Figure 2. The graph clearly illustrates that the durations consist of a diurnal pattern, with high trading activities (short duration) at the start and end of each trading day, and low trading activities (long duration) in the middle parts. By employing the approach that uses the deterministic function (see [
29], pp. 253–254) to remove the diurnal effect and obtain the diurnally adjusted duration series by dividing the duration with the fitted deterministic function (see Equation (1)).
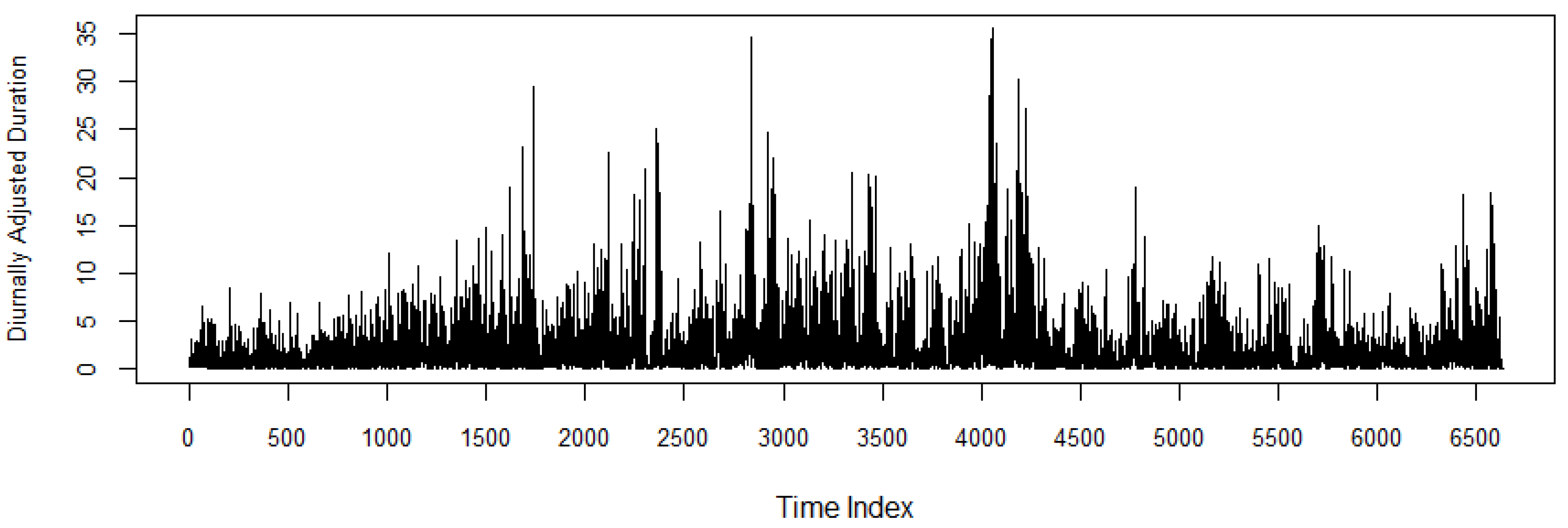
Figure 3 shows the diurnally adjusted duration series; the summary statistics of the series are reported in
Table 3. The data shows that the durations have an average of 2.1294, with 50% of the diurnally adjusted durations above 1.1201. The skewness of 3.5687 and kurtosis of 20.4377 indicates that the data is positively skewed and has a leptokurtic distribution. Both Ljung-Box (LB) test statistics
and
at lags 10 and 20, respectively, are significant at 1% significance level, implying a strong autocorrelation in the series.
6. Conclusions
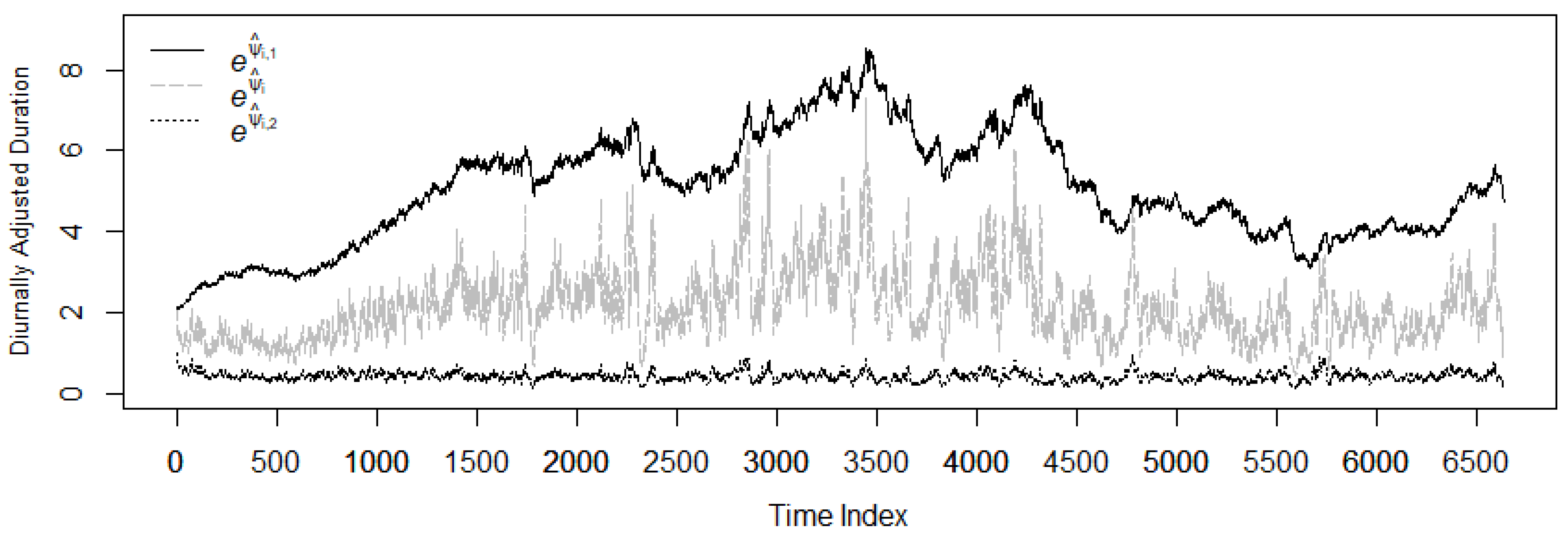
Generally, this paper proposes a novel model called the LogCACD model with no restrictions on the sign of parameters while allowing the expected durations to be decomposed into the long- and short-run components in duration modelling. The aggregation of long- and short-run components leads to a slowly decaying autocorrelation that closely resembles the one observed on trade duration data. We first analysed the goodness of fit of the proposed LogCACD model with three different linear and nonlinear benchmark models, namely ACD, LogACD and CACD for capturing the dynamics of trade durations in terms of their in-sample model-fit and out-of-sample forecast performances. It was then followed by the investigation of the effect of different distribution assumptions for these models, in which a flexible EGIG error distribution with a roller-coaster shaped hazard function was adopted and compared the performance with the Wei, GG, Burr and GB2 error distributions. Finally, for risk measure analysis, the TaR forecasts were computed and evaluated using various performance measures and backtests.
Meanwhile, an empirical application based on IBM trade durations with the preliminary comparison of the in-sample model fit was carried out using the basic linear ACD models under different error distributions. The findings reveal that the ACD
EGIG offers the best model fit and all the estimated parameters fulfil the constraints of the UBB-shaped hazard function (see
Table 1) highlighting the practical advantage of the EGIG distribution as a potential error distribution for ACD modelling. In addition, the linear and nonlinear ACD models were contrasted with the EGIG distribution, and the result appears to warrant the conclusion that the LogCACD
EGIG model tends to outperform the other models, which indicates that the choices of mean specifications and error distributions turn out to be the important factors for improving modelling performance of trade duration.
To further examine the applications of nonlinear mean specifications and EGIG distribution for enhancing the duration forecasts, the forecasting performance of these models was evaluated via loss functions, namely MSFE and QLIKE and tested using the MCS test. The LogCACDEGIG model seems to provide the smallest and the second smallest ranks based on MSFE and QLIKE, respectively, and the MCS test procedure also confirms the predictive ability of LogCACDEGIG model in producing precise forecasts. Concurrently, the computed TaR forecasts of these models were evaluated to assess the forecast accuracy and the results appear to show that the TaR forecasts based on LogCACDEGIG model at all risk levels are reasonably reflected in terms of the ratio of violation rates. The KLR test is also in line with the accuracy of the TaR forecasts.
As a summary, it is worth noting that the LogCACD model with nonlinear mean specification and a flexible EGIG distribution tends to improve the trade durations forecasting performance under study. For illustration purposes, assuming that there are only two types of traders in the market constituted by the uninformed and informed traders. Our proposed component model could be used to explain the trade behaviour of these traders. Both the long- and short-run components represent the uninformed and informed trader’s trade duration, respectively. The long-run component exhibits highly persistent behaviour, which supports the hypothesis that the uninformed trader acquires the delay trading information from the informed trader. This result is in line with the finding of [
37], that uninformed trade responds more to past uninformed trade than it does to past informed trade. Despite the encouraging results of this study, the change of durations might also be affected by other market events such as price and volume. Hence, in future works, it would be interesting to extend our model by incorporating other exogenous variables such as transaction volume, trading intensity and spread associated with trade duration to improve the predictive ability. Moreover, it would be meaningful to consider the application of EGIG distribution in stochastic conditional duration models which can account for the structural change exhibited by the durations.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}