Long Term Memory Assistance for Evolutionary Algorithms


1
Faculty of Electrical Engineering and Computer Science, University of Maribor, 2000 Maribor, Slovenia
2
Department of Computer Science, California State University Fresno, Fresno, CA 93740, USA
*
Author to whom correspondence should be addressed.
Mathematics 2019, 7(11), 1129; https://0-doi-org.brum.beds.ac.uk/10.3390/math7111129
Submission received: 7 September 2019
/
Revised: 28 October 2019
/
Accepted: 12 November 2019
/
Published: 18 November 2019
(This article belongs to the Special Issue Evolutionary Computation and Mathematical Programming)
Abstract
:Short term memory that records the current population has been an inherent component of Evolutionary Algorithms (EAs). As hardware technologies advance currently, inexpensive memory with massive capacities could become a performance boost to EAs. This paper introduces a Long Term Memory Assistance (LTMA) that records the entire search history of an evolutionary process. With LTMA, individuals already visited (i.e., duplicate solutions) do not need to be re-evaluated, and thus, resources originally designated to fitness evaluations could be reallocated to continue search space exploration or exploitation. Three sets of experiments were conducted to prove the superiority of LTMA. In the first experiment, it was shown that LTMA recorded at least more duplicate individuals than a short term memory. In the second experiment, ABC and jDElscop were applied to the CEC-2015 benchmark functions. By avoiding fitness re-evaluation, LTMA improved execution time of the most time consuming problems and between 7% and 28% and 7% and 16%, respectively. In the third experiment, a hard real-world problem for determining soil models’ parameters, LTMA improved execution time between 26% and 69%. Finally, LTMA was implemented under a generalized and extendable open source system, called EARS. Any EA researcher could apply LTMA to a variety of optimization problems and evolutionary algorithms, either existing or new ones, in a uniform way.
1. Introduction
Evolutionary Algorithms (EAs) [1] are stochastic algorithms that originated by utilizing nature-inspired behaviors to search for the global optimum/optima. Over the past few decades, EA research communities concentrated their efforts on expanding EA areas by mimicking a variety of nature-inspired behaviors (e.g., ABC [2], ACO [3], Grasshopper Optimization Algorithm (GOA) [4], Gray Wolf Optimizer (GWO) [5], PSO [6], and Teaching-Learning Based Optimization (TLBO) [7]), although, in many cases, searching for inspiration from nature has gone too far [8]. EA researchers also dedicated themselves to how EA’s parameters may influence the evolutionary processes (e.g., parameter-less [9], parameter tuning [10,11], and parameter control [12,13]). Both research mainstreams (i.e., EA behaviors and EA parameters) consider EAs as balancing an evolutionary process between exploration and exploitation [14], either by controlling EA operations, or EA parameters, or both.
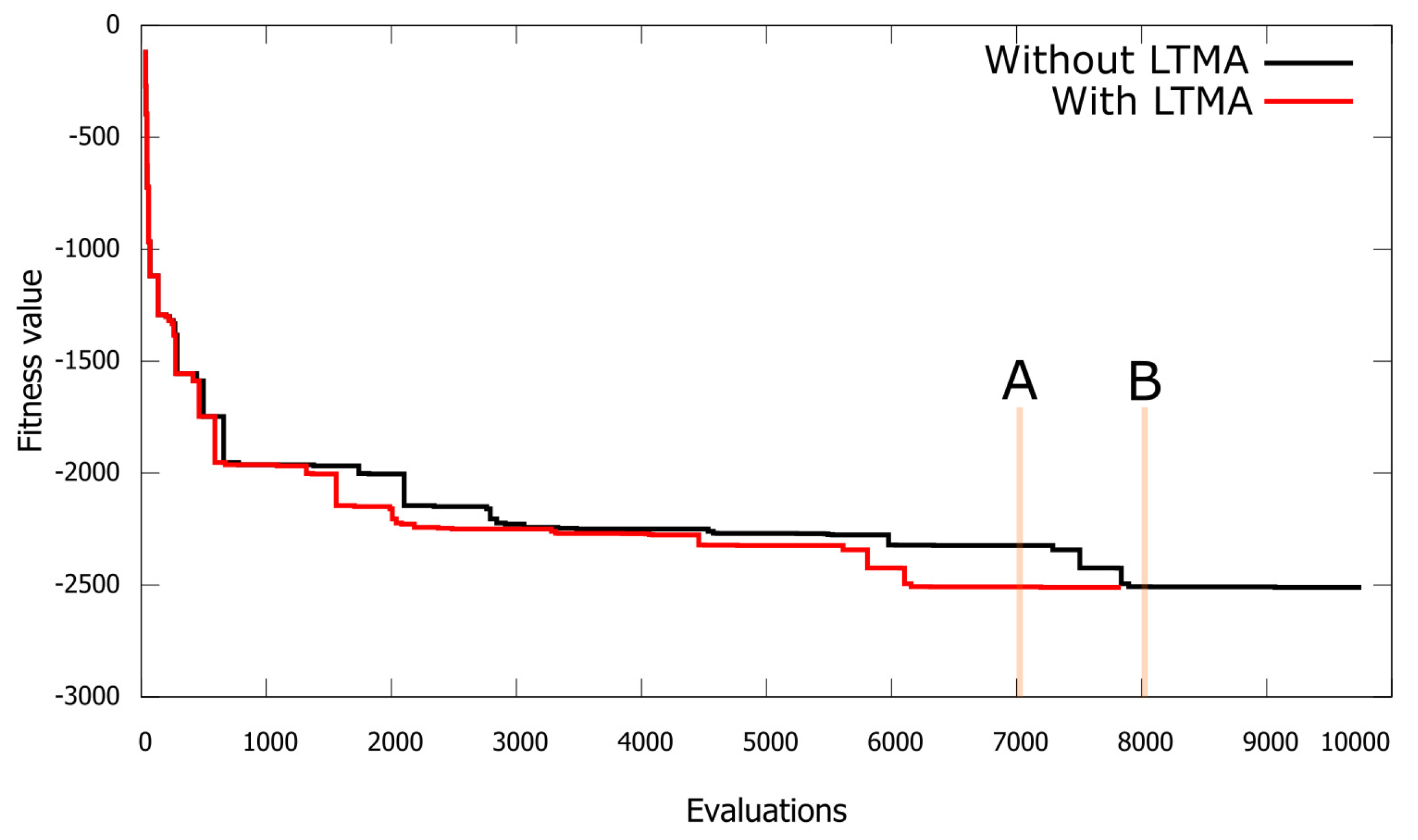
Although duplicate individuals (revisited solutions) have been recognized as unproductive from the beginning of EAs, not enough research has been done to evaluate how costly it is to identify duplicates and how much benefit can be gained if duplicates can be identified and replaced with new solutions. For example, Koza wrote in [15]: “Duplicate individuals in the initial random generation are unproductive deadwood; they waste computational resources and reduce the genetic diversity of the population” undesirably. However, duplicate individuals in Genetic Programming (GP) [15] have been identified only in initial random generation. This is because duplicate random individuals are especially likely to be generated when the trees are small, and discovering duplicates in the later phases when the trees are large would be a costly process, not to mention the cost of keeping track of all solutions (trees in the case of GP) over the entire evolutionary process (over all generations). In Teaching-Learning Based Optimization (TLBO) [7], a duplicate elimination phase has been introduced to replace duplicates generated in one generation with random solutions, but duplicates were not checked with previous solutions found in earlier generations. Even more importantly, in TLBO, fitness evaluations were re-computed on duplicates and only later replaced with random solutions consuming more fitness evaluations [16,17]. The immediate question that arises is: How much can we profit if fitness evaluations are not re-computed on duplicates, and how costly is it to discover duplicates over the whole evolutionary process? However, the question is if this problem is real. Do EAs indeed generate many duplicates? We have often used the Artificial Bee Colony (ABC) algorithm in the past [18,19] and discovered that ABC exploitation performed in employed and onlooker bee phases actually generates many duplicates. Figure 1 shows one such example of using ABC where a convergence graph with duplicates (without Long Term Memory Assistance (LTMA)) is compared with a convergence graph with no duplicates (with LTMA), where duplicates are rather replaced with new solutions. For a fair comparison, a single run was used for both scenarios (red and black lines). LTMA was simulated based on a full run, by removing duplicate solutions that, in the case of using LTMA, would not be generated. As a result, the algorithm with LTMA converged earlier (the flat parts of the line are shorter, where duplicates were generated). Even in this simple example (Figure 1), it is clear that gains can be substantial (e.g., Solution A with Long Term Memory Assistance (LTMA) in Figure 1 can be found at least 1000 evaluations earlier than the same Solution B without LTMA). Especially in real-world problems where fitness evaluations are costly, we can expect large gains on CPU time by not re-computing fitness evaluations of duplicates or even better solutions when duplicates are rather replaced with new solutions enhancing the exploration and exploitation of the search space. However, how much we can gain from discovering duplicates and replacing them with new solutions has not been tested before. Hence, we decided to explore this topic more deeply on problems where solutions are represented as a vector of real numbers. Using graphs and trees (e.g., as in GP) as representations of solutions is out of the scope of this study.
In this paper, we call solutions (population) in the current generation short term memory and all solutions tested so far from the initial population long term memory. When using only the short term memory, we lose information on which solutions have already been visited (generated) in the previous generations, and it is quite possible that some solutions were re-visited. Re-evaluation of duplicate individuals is an unnecessary step and can be eliminated if we have long term memory. In this work, Long Term Memory Assistance (LTMA) is introduced, which can increase efficiency in terms of EA convergence.
The main contributions of this study are:
- estimation of the cost (memory and CPU time usage) for duplicate identification when solutions are represented as a vector of real numbers,
- estimation of how many fitness evaluations can be saved by not re-evaluating existing solutions for a few selected EAs and problems,
- demonstrating how we can “attach” long term memory in a uniform way to existing EAs and provide a general solution for this topic.
This paper is organized as follows. In Section 2, related work on how the past partial or complete search history has been recorded and utilized is reviewed briefly. The motivation of the research is proposed in Section 3. In Section 4, the proposed LTMA and its implementation are described briefly. In Section 5, duplicates’ generation is analyzed, as well as their effects on benchmark and real-world problems. Finally, the paper concludes in Section 6.
2. Related Work
For EAs, the short term memory concept has been an essential component realized through selection processes. For example, genetic algorithms [20] utilize a selection process to choose individuals for the next generation randomly, based on different strategies (e.g., tournament selection and fitness proportional selection). Although most selection processes use fitness values to guide selection, due to random selection, fitter individuals are not necessarily guaranteed to propagate to the next generation. Later, Evolution Strategies (ESs) [20] introduced a deterministic approach to select individuals based on the fitness ranking of individuals. Survival is guaranteed for a certain number of current best individuals. For example, (1+1)-ESs select the best between the parent and its mutated offspring for the next generation. Elitism represents an important milestone of introducing the long term memory concept to single-objective evolutionary algorithms [20,21], such that the current best individual(s) can survive throughout the evolutionary process. The elitism concept was later adapted as an external archive in most multi-objective evolutionary algorithms. All the non-dominated solutions found during the evolutionary process are retained in an external archive, so that they can be used to compare with current solutions. Some notable examples are SPEA2 [22], PAES [23], and EAG-MOEA/D [24]. Note that, although external archives are a commonly used approach in multi-objective evolutionary algorithms, NSGA-II [25] and its successor NSGA-III [26] still adopt elitism to retain the best individuals from both parents and offspring. External archives are also applied to some single-objective evolutionary algorithms. For example, JADE [27] introduced an optional external archive that stores a set of recently explored inferior solutions to guide the evolutionary process and improve diversity. Tanabe and Fukunaga [28] extended JADE, but recorded the history of parameters instead of recently explored solutions. Another EA sub-area that utilizes memory mechanisms is changing optimization problems or dynamic/uncertain environments [29,30,31,32]. Since this paper does not discuss changing optimization problems, readers may refer to those related works if interested.
Note that, although elitism or external archives introduced long term memory concepts to single-objective and multi-objective evolutionary algorithms, only partial solutions are recorded from the entire evolutionary process. During the past decade, several EA researchers have introduced new data structures to store the information obtained during the entire evolutionary process. For example, Chow and Yeun introduced non-revising GA [33] and the history driven evolutionary algorithm [34]. Both algorithms utilize the Binary Space Partition (BSP) tree to partition the search space and memorize the search history to avoid revisiting same solutions. They also introduced the continuous Non-revisiting Genetic Algorithm (cNrGA) for continuous variables and, later, introduced pruning mechanisms to maintain constant memory usage [35]. Leung et al. [36] extended the work to utilize past history to compute an approximate fitness landscape to control the evolutionary processes. Zhang and Wu [37] applied a BSP tree to the ABC algorithm to record and utilize the entire search history to improve the quality of regenerated solutions from the scout bee phase. Zabihi and Nasiri also applied a BSP tree to ABC algorithms for data clustering [38]. Nasiri et al. [39] used a BSP tree to approximate the landscape information of dynamic and uncertain optimization problems. In addition to a BSP tree, Črepinšek et al. [40] introduced an ancestry tree data structure to record the evolution history of a population and invented exploration and exploitation metrics based on the tree structure.
From the above discussions and references, long term memory has been proven as a useful mechanism for many EAs. Yet, due to memory constraints and the focus of introducing or improving EAs, to our best knowledge, there have not been many related works on recording and memorizing the entire search history of an evolutionary process for long term memory, where the cost of identifying re-visited solutions and the profit of not re-computing fitness evaluations have been investigated. Additionally, the aforementioned related work applied the entire search history for specific algorithms. LTMA, conversely, provides a general and extendable solution by decoupling long term memory from algorithms and problems.
Please note that Long Short-Term Memory (LSTM) [41] has been introduced in the deep learning research field (e.g., [42,43,44,45]). Unlike LTMA, LSTM introduces cells and gates to form a “highway” to retain gradient information in a long sequence of a recurrent neural network. In [46], a genetic algorithm was integrated with an LSTM network to optimize time window size and architectural factors, to better predict the Korea Composite Stock Price Index.
3. Memory
3.1. How Much Memory Do We Need?
To calculate how much memory we need for completing long term memory recall, we need to know some data about the EA used, the problem being solved, and its stopping criteria. In our work, the following assumptions were made:
- Only memory needed to store all individuals (populations over whole generations) is computed, although different EAs need extra memory for additional computations. This algorithm specific memory usage is not taken into account in our work.
- Only single-objective continuous optimization problems have been studied, where a point in a search space (genotype) is represented as a vector x of length n, , and fitness (phenotype) . To represent a real value ℜ, often eight bytes of memory are used (e.g., Java). Therefore, bytes are needed for one member of a population and its fitness value. A different memory consumption is needed in the case of discrete optimization, where the representation of a population member is problem dependent. In the case of multi-objective optimization, a solution (kth objectives) and more memory are needed to store a fitness value.
- The stopping criteria determine how many solutions are going to be generated. The fixed-cost (vertical) and the fixed-target (horizontal) approaches were identified in [47]. In the fixed-cost approach, solutions are generated until we reach a pre-defined number of iterations, or pre-defined number of fitness evaluations (), or pre-defined CPU time. In the fixed-target approach, solutions are generated until a (sub-)optimal solution is found. Some hybrid stopping criteria, blending vertical and horizontal approaches, have also been employed in EAs. Among the aforementioned approaches, it is often unknown how many solutions will be generated (e.g., based on CPU time or based on the maximum number of iterations when some extra local search is also included). Hence, in this study, is used as a stopping condition. It indicates directly the number of generated solutions.
Based on the aforementioned assumptions, we need bytes to store all solutions and their fitness values. Table 1 shows typical memory consumption for different dimensions (n) and numbers of generated solutions ().
From the memory calculations, we can observe that the limitation of using just computer RAM memory currently starts with large scale optimization problems where n is 200 or more, where just raw data that describe solutions take ≈ GB of memory. If we compare Table 1 with the needed RAM and Table 2 with recommended personal computer RAM, we can get some clues about why long term memory has not been used in the past.
However, these calculations are theoretical. In practice, a solution can be represented as an object (in object oriented languages such as Java [48,49]) that has additional data that requires memory. In these cases, memory consumption is higher. Nevertheless, we can observe from Table 1 that, with current personal computers, indeed all generated solutions can be kept in memory achieving a long term memory concept in EAs. This is only worthwhile if we can make some profit from it. Below, we will show that this is indeed the case.
3.2. How Much Can We Profit?
By using the proposed approach, Long Term Memory Assistance (LTMA), there is no need for re-evaluation of a duplicate individual. As such, the gain is the time not needed for a fitness evaluation. On the other hand, we also need to know the time to identify a duplicate. The time needed for a fitness evaluation is obviously problem dependent. In the case of synthetic benchmarks, this is usually very low (one evaluation takes a few ms), but in the case of real-world problems, it can require much more resources (from seconds to hours for one evaluation). Special cases are evaluations with a partial computer simulated model, where an experiment in the physical world is executed for every solution evaluation. The price of such an evaluation is usually very high, and often, surrogate models are used [50,51,52,53]. Therefore, in this study, we are using both problems, i.e., synthetic benchmarks, as well as real-world problems, to investigate this topic more thoroughly. Since we need to take into account the time to identify a duplicate individual, a simple measure would be , as the ratio between CPU time needed when duplicates are not identified, and duplicate individuals are re-evaluated, denoted as , against CPU time with LTMA (denoted as ). By measuring the time of a whole run of a specific EA, the time needed by algorithm specific operations is also taken into account. Therefore, despite dealing with the same problem and the same number of fitness evaluations, EAs will run for different amounts of time. A speedup of would mean that using LTMA would be more time efficient.
We expect an increased speedup whenever the average time for identifying duplicates would be smaller than re-evaluating the fitness of duplicates . Let denote the number of all duplicate individuals. For every individual, we need to check if it is a duplicate individual. Hence, there will be individuals in the whole search. Therefore, an increased speedup is achieved when:
Since is not statically known, this cannot be computed in advance.
To investigate some theoretical speedups, we will set as one unit of time, and will be a multiple of . The results are presented in Table 3, where we can observe that, in the case where is equal to , we get negative speedups. This trend turns when takes 10-times longer than . This ratio is common, even in the case of simple synthetic problems. In this case, we can observe (Table 3) that a speedup of can already be achieved when an EA generates or more duplicate individuals.
Instead of generating a duplicate individual, it would be better to generate a new solution. In such a manner, the search space is going to be explored/exploited better [14]. Note that there is no benefit of revisiting the same solution (a good or a bad solution) two or more times. Hence, another measure to quantify the profit of duplicate elimination is the number of new solutions that can be generated instead of duplicates. The success of a particular EA also depends on the number of duplicate individuals that can be used more wisely in other search regions. However, the factor of non-revisiting solutions is not the only one that determines the efficiency of an EA. For example, the Random Walk Algorithm () will most likely not generate two identical solutions, but is rarely competitive with any EA due to the lack of guided search. On the other hand, the simple Hill Climbing Algorithm () will start to generate the same solutions in a local optimum. Since generating the same optimal solution several times is still a waste of precious CPU time, we decided to differentiate both cases:
- is the number of duplicates before an optimum is found in one independent run.
- is the number of all duplicates in one independent run.
In order to count duplicate individuals, we need to define them first. An individual is a duplicate if there exists an individual in the long term memory with the same genotype. Genotypes and are the same if , for every . The precision of double values is defined by software and computer configuration. In our experiments, we used the Java programming language. In Java, the precision of native double values is up to 16 digits; thus, comparison of double numbers is possible up to 16 digits. In real-world problems, the need for such a high precision is rare, and because of that, we will limit the precision of double values and conducted experiments with three different precisions (): 3, 6, and 9 decimal places. We need to stress here that precision is a problem based parameter and needs to be set accordingly. To identify duplicate individuals, we used a hash table where the key is the genotype represented as a formatted string. The representation of individuals was not memory space optimized, but it did not present any problems in our experiments.
The following research questions were investigated in the experiments:
- How many duplicate individuals are generated during the optimization process? To answer this question we have to count all duplicate individuals based on precision , as well as how many duplicate individuals are found before the global optimum is reached based on precision .
- How much CPU time can be gained by not evaluating duplicate individuals (speedup)?
- How can convergence be improved by replacing duplicate individuals with new solutions?
For easier interpretation of results, the success rate was added [1]. Finally, the number of duplicates most likely also depends on the optimization problem. We expected more duplicates on a multimodal problem with many local optima. Two different experimental scenarios have been envisioned. In the first scenario, denoted as , we will use LTMA to achieve potential time speedups. On the other hand, we can take an even further step. In cases where the stopping criterion is set by and EA does not re-evaluate duplicate individuals, then EA can use this unused fitness evaluation. In this LTMA usage scenario, denoted as , we can expect a better or equal result, but optimization time will be increased by . In practice, it is expected that for real-world problems, .
4. Implementation
Traditionally, in order to make EA frameworks/systems/tools generalized and extendable, many EA frameworks/systems/tools are decoupled into two separate modules: optimization problems and evolutionary algorithms. Some notable examples are the Evolutionary Algorithms Rating System (EARS) [54], EvoSuite [55], and the MOEA framework [56]. EARS is a Java-based open source system that compares and ranks evolutionary algorithms using a chess rating system [57]. Its source code is available on GitHub. We extended EARS by adding a Long Term Memory Assistance (LTMA) module between the Optimization Problem (OP) module and Evolutionary Algorithm (EA) module. Figure 2 shows the implementation of the proposed work.
In the implementation of LTMA, users first interact with the OP module to select an optimization problem and problem specific parameters such as constraints, dimension, upper and lower bounds, among others (Figure 2, Step 1). Then, users determine the EA and its parameters (e.g., , mutation and crossover probabilities () in the case of genetic algorithms), which are forwarded to the EA module (Figure 2, Step 2). Finally, execution parameters such as stopping criterion will be requested and passed to the LTMA module. Once all the configurations are done, EA will start to run the optimization process (Figure 2, Step 3). During a run of the optimization, the EA module explores or exploits a solution (x), which is then passed to the LTMA module to check whether the solution has been re-visited or not. Only if the solution has not been visited before will it be passed to the OP module to compute its fitness value (). Namely, the LTMA module records all duplicate individuals and prevents redundant time-consuming re-evaluations. Finally, the fitness value will be passed back to the EA module (Figure 2, Step 4). The experiment will continue until the stopping criterion is met. Note that the LTMA module is in charge of the termination of a run. This is because LTMA possesses visited solutions, which could be used as useful information to determine whether to continue to consume unused fitness evaluations before the stopping criterion is met. Since the LTMA module is integrated in EARS, a generalized and extendable EA framework, the proposed work featuring long term memory can be applied to a variety of optimization problems and algorithms in a uniform way.
The LTMA was designed to be implemented easily and used in combination with different EA frameworks or in combination with standalone EAs. The focus in this implementation was on continuous optimization problems, but it can be adapted to discrete optimization problems such as job shop scheduling, the traveling salesman problem, or the knapsack problem [58,59].
5. Experiment
The experiment is divided into the following parts:
- analysis of duplicate individuals’ occurrences on three simple, but well known problems, to gain a first insight into the topic,
- duplicate analysis on CEC-2015 benchmark problems, and
- duplicate analysis on a real-world problem.
The phase of exploration and exploitation of evolutionary algorithms [14] affects how the search space is searched. Since each EA has its own approach, we used five different EAs in the experiment to demonstrate the viability of the proposed approach. The EAs’ control parameters were not tuned for the experiment, and default settings of the control parameters were used. A meticulous reader will notice that EAs in this study used different population sizes as a result of default settings. However, since we used as a stopping condition, this did not expose additional threats to validity.
The main objective of the experiments was not to show which algorithm was better, but to investigate the phenomena of duplicate individuals and the influence of the proposed LTMA. The selected EAs were: Artificial Bee Colony (ABC) [2] with and , the self-adaptive differential evolution algorithm (jDElscop) [60] with , Teaching-Learning Based Optimization (TLBO) [7] with , Gray Wolf Optimizer (GWO) [5] with , and the Grasshopper Optimization Algorithm (GOA) [4] with . The source codes of all used algorithms are included in the open source EARS framework [54].
5.1. Experiment I: The First Insight
Our main objective in this experiment was to get a first insight into the generated duplicate individuals. The scenario was used for this analysis. Therefore, we selected three classical synthetic problems: Sphere, Ackley, and Schwefel 2.26. Usually, these problems are used by developers of new evolutionary algorithms for their initial evaluation. The Sphere problem was expected to be very easy, while the Ackley and Schwefel 2.26 problems were somewhat more difficult, but solvable. Visualization of their landscape will help us understand and interpret the results.
Every problem was analyzed with different scenarios, based on the dimension of the problem n and the stopping criterion (maximum number of fitness evaluations ):
- and = 10,000,
- and = 30,000, and
- and = 100,000.
When multiplying the number of problems, the number of different dimensions, the number of selected EAs, and number of different precisions, we obtained: , in total 135 combinations of different configurations, each of which was repeated 50 times.
Stochastic algorithms rely on Random Number Generators (RNGs) to generate new solutions. Therefore, it was crucial to select a good RNG, which will not generate duplicate individuals. In our experiments, we used the Mersenne Twister Random Number Generator [61]. To test it, we made a simple experiment, where we generated random solutions based on selected dimensions and for every precision. The experiment was repeated 50 times. The selected random number generator did not generate any duplicate individuals, except in one run with settings: , = 10,000, and precision , one duplicate individual was generated. The results confirmed that it was very unlikely that the selected RNG would generate duplicate individuals.
5.1.1. Sphere Problem
The Sphere function problem has no local optima and is one of the easiest global optimization problems; thus, it has one basin of attraction (Figure 3). The minimization problem is characterized by the equation:
where . The fitness value for the global optimum is zero. Its characteristics help us understand an algorithm’s exploitation behavior, and it is used commonly as the first test problem for EA’s convergence analysis. It is expected that the global solution will be found fast and with high precision.
From Table 4, we can observe that:
- the most duplicates are generated at the global optimum (after the global optimum is obtained).
- the numbers of and will decrease with higher precision (from 3 to 6 and 9).
For , we had a very small number of duplicate individuals before the global optimum was found (); from ≈0% in the case of the GWO algorithm to () in the case of the ABC algorithm for and . With increased precision, the number of duplicates () dropped almost to zero and, using LTMA, was not contributing in the global optimum search. The number of all duplicate individuals was high. The number of duplicate individuals () in the case of GWO was even ≈97% for (, ), whilst for ABC around ≈40% for ( and ). This indicated that the selected problem was easy to solve and the stopping criterion could be set to less. The Success Rate (SR) in all configurations was , except for GOA (). We tested if duplicates () could be identified using only short term memory (current population). Around of duplicates would not be identified in such a case.
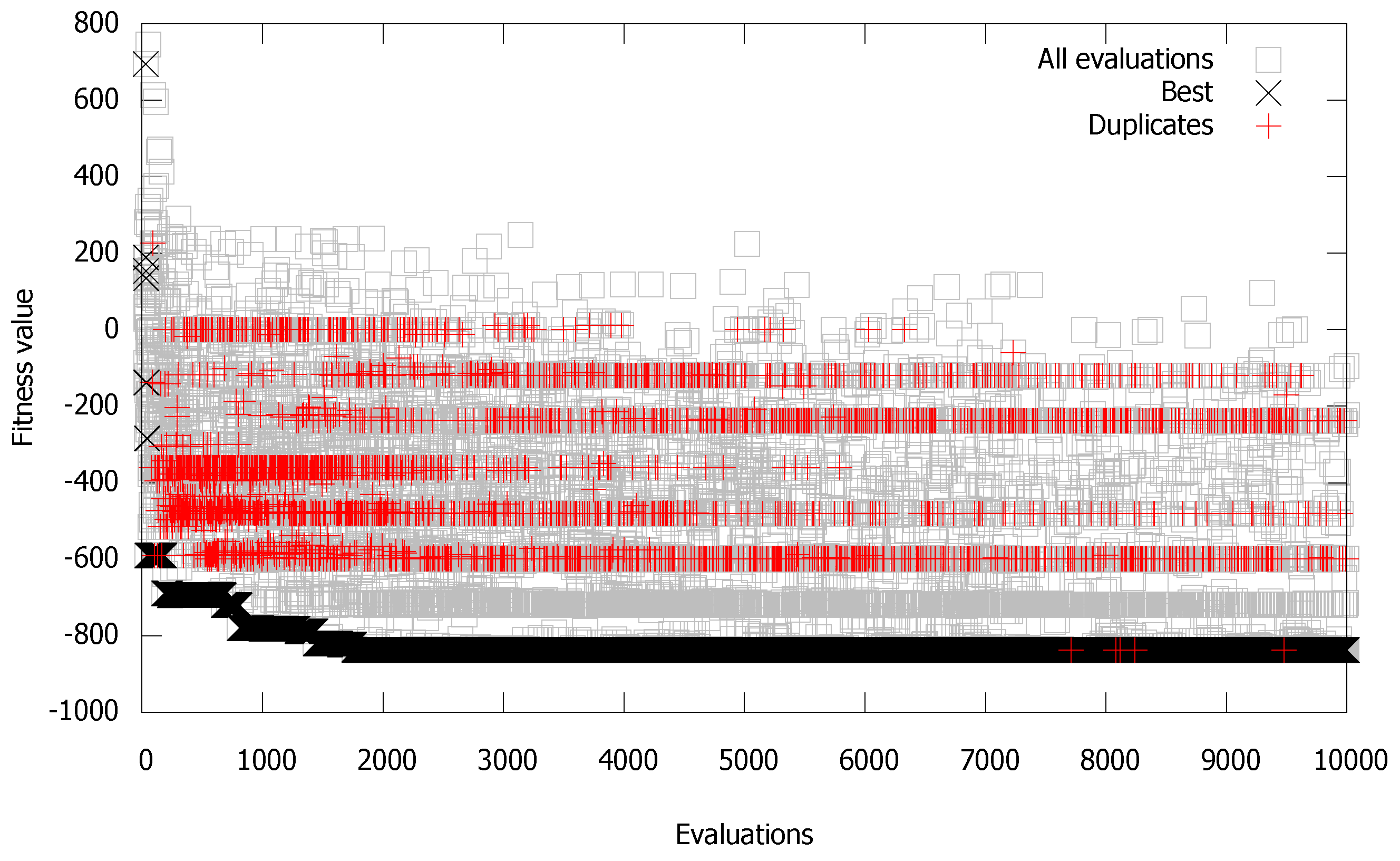
A better insight into the duplicates’ generation of a specific EA was obtained by observing the convergence graph of a particular independent run. Visualization of the convergence graph (black crosses) was enhanced with visualization of all generated solutions (gray squares) and duplicate solutions (red pluses). In particular, we would like to know how good the generated solutions (gray squares) were in terms of fitness, in which phases duplicates (red pluses) appeared (e.g., early in the search, when approaching local or global optima), and what was the convergence graph of the best solutions so far (black crosses). Such visualization helped us to understand better how specific EAs performed exploitation and exploration of the search space [14]. Namely, if the newly generated solutions (gray squares) were close to local optima or even to the best current solution (black crosses), then the EA was in the process of exploitation. On the other hand, if newly generated solutions (gray squares) were far from the best current solutions (black crosses), then the EA must be in the phase of exploration. On the graph, the x axis (horizontal) represents execution time represented by the number of evaluations and the y axis (vertical) the success of the algorithm represented by the fitness value. The graph has three types of data. The first type is all evaluations (gray squares), which represent all fitness evaluations and their values (10,000 of them). The second type of data represents the best solution found so far (best, black crosses) and describes the convergence of the algorithm. The last type of data represents the generated duplicate individuals (duplicates, red pluses). We need to note here that all solutions in the graph are presented by their fitness value (phenotype) and not by the actual result vector x (genotype).
Figure 4 represents one run of the ABC algorithm for and on the Sphere problem. From the graph (Figure 4), we can observe clearly two exploration phases of the ABC algorithm (all evaluations). The first exploration phase was in the interval from zero to ≈1500 evaluations, and the second started at ≈6000 and ended at 10,000 evaluations. The exploitation phase was in the interval from 1500 to 6000 (almost all generated solutions ended in the global optimum). Most duplicate individuals were generated in the global optimum in the interval from 4000 to 7000 evaluations when ABC was in the exploitation phase, whilst only a few duplicates were generated in the two exploration intervals.
5.1.2. Ackley Problem
The Ackley function problem has many local optima with a small basin of attraction and global optima with a large basin of attraction (Figure 5). The fitness value for the global optimum is zero. The minimization problem is characterized by the equation:
where and e is Euler’s number (≈2.7182818284).
Because of the local optima, it was expected that finding the global optimum would be harder than in the case of the Sphere problem, but due to the relatively small local optima basin of attraction compared to the global optima basin of attraction, EAs were able to make the exploration “jump” from local to global optimum.
The results are shown in Table 5 where we can observe that the number of duplicate individuals () was higher than for the Sphere function (Table 4). For example, the ABC algorithm for and had, on average, more than ≈ of ; for and it had ≈ of . Indeed, among the selected EAs, the ABC algorithm had the highest number of , showing that the proposed LTMA might be useful. The number of all duplicate individuals was similar (ABC around ) as in the case of the Sphere function (Table 4), indicating again that the number of could be lower. The of showed again that this EA was not competitive for this kind of optimization problem. Around of duplicates would not be identified when only short term memory (current population) was used.
From the graph (Figure 6), we can again observe two exploration phases of ABC. Since the Ackley problem was harder than the Sphere problem, the first exploration phase of ABC was longer (up to 6000 evaluations) and generated more duplicates than the first exploration phase on the Sphere problem (Figure 4). Those duplicates were unnecessary, and it would be better if new unique solutions could be generated in an unexplored search space. In the exploitation phase (from 6000 to 8500 evaluations), many duplicates were actually at the global optimum. The ABC algorithm was no longer in the exploitation phase at ≈8500 evaluations, again generating a few duplicates.
5.1.3. Schwefel 2.26 Problem
The Schwefel 2.26 optimization problem had the most demanding fitness landscape among the three selected problems, with a lot of small and big basins of attraction (Figure 7). The minimization problem is characterized by the equation:
where .
The fitness value at the global optimum is .
From Table 6, we can observe that the number of duplicate individuals before the global optimum () increased in comparison with the Sphere or Ackley problems (Table 4 and Table 5). Again, ABC generated the most among the selected EAs (more than ), although it was the runner-up regarding , where jDElscop had the best performance. It is interesting that the number of duplicates was not much higher than , indicating that the most duplicates were actually sub-optimal solutions. Around of duplicates would not be identified when only short-term memory (current population) was used.
The graph on Figure 8 for ABC indicates that duplicate individuals were generated throughout the whole optimization process. Most duplicates were generated at six different fitness values (red stripes on the graph). These were the values of the local optima. About of all generated solutions were . Clearly, re-visited solutions would be better spent on exploring new regions. The proposed LTMA would again be very beneficial.
5.2. Experiment II: CEC-2015 Benchmark
In this experiment, we wanted to test selected EAs on benchmarks that are often used to compare EAs. The focus of the experiment was not just on the number of generated duplicate individuals ( and ), but also on the time t needed to execute the optimization (a single independent run presented in seconds). For this, we used the scenario. Furthermore, we were interested in how the convergence of an EA could be improved by replacing duplicates (before their fitness function was re-evaluated) with non-revisited solutions. In this scenario, , each EA was run until different solutions were checked. We also report the percentage of runs where the final solution was improved. This scenario showed directly the impact of the LTMA on the improvement of the EA’s convergence.
The execution time of an experiment depends on the running environment: software and hardware. The experiment was executed on a computer with Intel(R) Core(TM) i7-7500U CPU @ 2.7 GHz with 16 GB RAM and the Windows 10 64-bit operating system. The execution was not multi-core CPU optimized.
For this experiment, we selected the ABC algorithm and the most successful algorithm from previous experiments: jDElscop. EA control parameters were the same as in Experiment I. For the benchmark, we selected the CEC-2015 benchmark from the Competition on Real-Parameter Single Objective Optimization [62]. The benchmark has 10 different minimization problems (from to ). For our scenario, we set and 100,000. The global optimum for problem was 100, for 200, ..., and for 1000. LTMA was also compared to a standard version (i.e., without LTMA), and its results are shown in the last two columns in Table 7 and Table 8.
The number of different configurations (10 different problems, different precisions, 2 EAs, 2 scenarios: and ) in total was 120, each of which was performed on 100 independent runs.
5.2.1. Scenario
In this experiment, we measured how much CPU time could be saved by not re-evaluating the fitness of revisited solutions (i.e., the fitness value was just read from the LTMA module).
From the results in Table 7 and Table 8, we can observe that the ratio of generated duplicate individuals was surprisingly high. The reason for this was that the problems in the benchmark were difficult (e.g., many different local optima). In the case of ABC, more than of the generated solutions were (e.g., for , , , , and ); whilst jDElscop generated more than for problems –. Around of duplicates would not be identified when only short term memory (current population) was used.
Although the number of was high, the speedup using LTMA was not achieved in most cases. The reason was that for the most problems (–, except and ), fitness evaluations were fast and took, on average, less than s for one optimization run; whilst identifying duplicates took on average s. In such cases, the use of LTMA was not justified. It should be noted that ABC did not find a suitable solution for problems , and , whilst jDElscop did.
and were more difficult problems that could clearly show the profits of applying LTMA (see the bold values in Table 7 and Table 8). When LTMA was not applied, these two problems took s and s (Table 7), respectively. Yet, with LTMA, the execution times taken by ABC dropped to s and s, respectively. Equivalently, this means that LTMA increased speedup by for the problem and by for the problem. From Table 7, we noticed that precisions did not play an important role for these two problems: There was almost no difference between scenarios with precision of six and nine.
Since generating duplicates was algorithm dependent, LTMA driven profits were different between ABC and jDElscop. Table 8 shows that took s on average, and spent s. On average, jDElscop with LTMA improved the execution time, expressed as speedup, for the problem and for the problem. Overall, we can expect increased speedup and faster EA execution by not re-evaluating duplicates for time consuming problems. In such cases, termination based on the maximum CPU time should also produce equal or better results using the LTMA approach.
5.2.2. Scenario
In this experiment, we tested the scenario. Namely, when a duplicate was identified, but not re-evaluated, it was replaced with a new non-revisited individual. With additional search points, it was expected to obtain better or equal results. To present possible benefits better, we counted runs where solutions were improved. They are presented as the percentage of improved runs (B) (Table 9 and Table 10).
How much the algorithm gained with additional evaluations was problem and algorithm dependent. In the case of the ABC algorithm, most improvements were shown on problem , where, in more than of runs, the results were improved, with almost no improvements in the case of problem (Table 9). The jDElscop algorithm gained the most in the case of problems and , where around of all runs resulted in optimal solution improvement (Table 10). Overall, with the proposed LTMA approach, the search space would be explored better and exploited since duplicate individuals were eliminated. In most cases, a better solution was found.
5.3. Experiment III: Real-World Problem
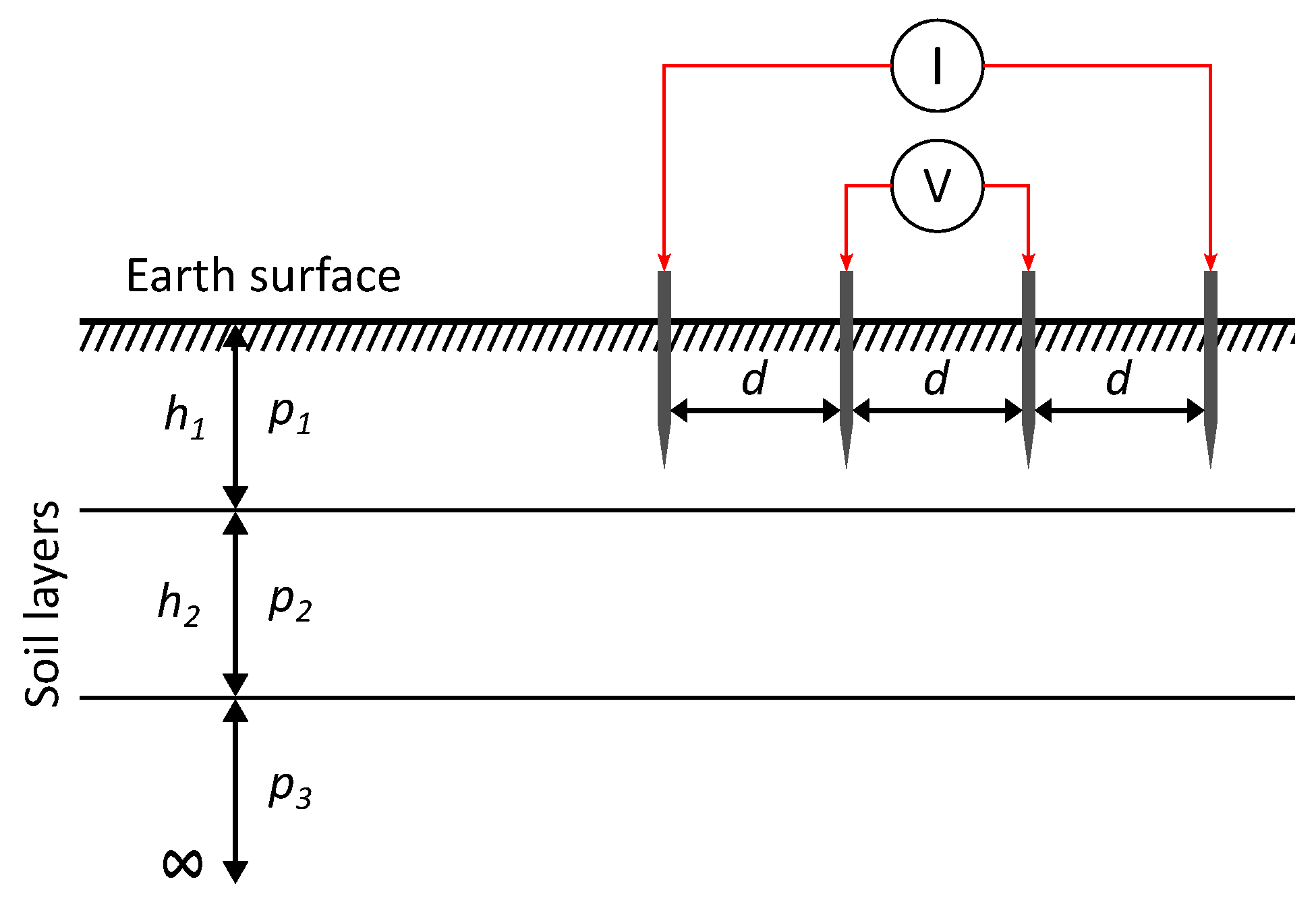
The real-world optimization problem we used in our experiments dealt with searching for soil models’ parameters, namely the thicknesses of the soil layers and their resistances [63]. It was assumed that the soil was homogeneous within each layer. In our calculations, we used the three-layer soil model, which was shown to obtain the best results in [64]. The three-layered model is shown in Figure 9, where and are the thicknesses of the soil layers and to are specific soil resistances of the soil layers. The obtained soil parameters based on the soil model were used in the Finite Element Method (FEM) for proper dimensioning of the grounding systems. Grounding systems play an important role in protecting people and devices in cases of defects in electro-energetic systems or lightning strikes. In order to determine the soil’s parameters, information is required regarding the soil’s structure in the surroundings of the grounding system. These data were obtained with different measuring methods. In our experiments, we used three different measured datasets (problem instances , , and ) obtained with the most commonly used Wenner four-electrode method [65]. In the Wenner method, four electrodes are inserted into the earth at equal spacings d (Figure 9).
The earth’s apparent resistivity is then measured according to:
where d is the distance between two consecutive electrodes, I is the current injected between the two outer electrodes, and U is the voltage measured between the two inner electrodes. Based on the same definition, the analytical expression for apparent resistivity is calculated as:
where is the specific resistivity of the first soil layer and is the zero order Bessel’s function of the first kind, calculated using Equation (8).
For the three-layered soil model, was calculated with the equations presented in Equation (9).
A numerical integration was adapted for the integration. Infinity was replaced with a large value, denoted by , and was set according to [66]. The goal of the optimization was to find the soil parameters that best fit the measurement data. The fitness function was defined as:
where are the measured and the calculated values of apparent resistivity, respectively. n is the number of measured points.
For the experiment, we set 20,000. For EA assistance (ABC, jDElscop), we selected . Every experiment was repeated 50 times. In this section, we had 12 different configurations (3 problem instances, 3 scenarios, and 2 EAs).
In the case of the ABC algorithm ( problem), there were ≈7000 duplicate individuals, which was and was unexpectedly high, and it was similar for the and problems (Table 11). In the case of the jDElscop algorithm, the percentage of duplicates was much lower, but, in the case of the problem, the duplicate percentage was still high at .
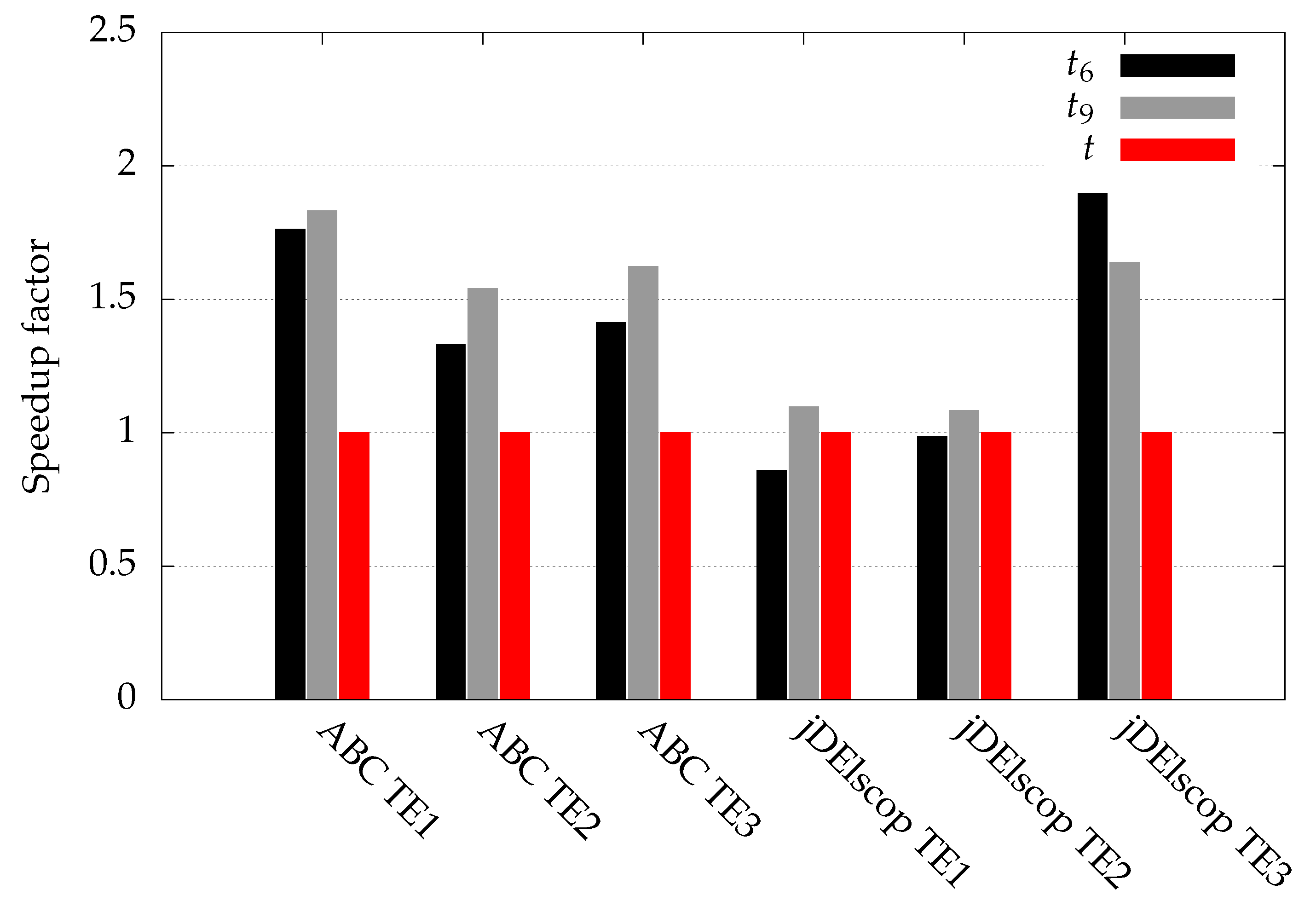
The execution time of a single independent run (t) in the case of the real-world can fluctuate greatly. On average, for the (, , and ) optimization process of a singe run for the ABC algorithm, we needed s for , s for , and s without (Table 11). We obtained speedups: for and for . In the case of the jDElscop algorithm, the number of generated duplicate individuals was lower than in the case of the ABC algorithm. On average, for the (, and ) optimization process of a singe run, we needed s for , s for , and s without . We obtained speedups: for and for (Table 11).
We can observe from Figure 10 that with, the LTMA speedup for real-world problems can be substantial (around 50%).
6. Conclusions
To investigate the generation of duplicate individuals over the whole evolutionary process, we conducted more than 250 different configurations, divided between three experiments, during which we analyzed how much profit we could gain by not re-evaluating duplicate individuals (their fitness values can just be accessed from the memory) and how many new solutions could be generated when eliminating duplicates completely. The main conclusions of this study are:
- For identifying duplicate individuals (re-visited solutions), it is not enough to use a short term memory (current population). The experiments showed that between 50% and 90% of duplicates would not be discovered without long term memory (all generated solutions in the whole evolutionary process).
- Current achievements in hardware allowed us to store all solutions (phenotype and genotype) in the computer’s RAM, where we can identify duplicate individuals easily.
- A speedup of or more can be achieved for hard real-world problems where fitness evaluations are costly, simply by not re-evaluating duplicates (when at least of duplicates are generated). In the case of the soil model problem, ABC generated around duplicate individuals, and, with the proposed LTMA, a speedup of was achieved.
- Better convergence can be achieved when duplicate individuals are replaced with non-revisited individuals. In such a manner, the search space could be explored and exploited better.
- A long term memory can be attached in a uniform way to existing EAs.
Please note that the primary goal of this study was to show how researchers/practitioners may increase/improve their algorithm’s efficiency motivated by detailed analyses obtained from LTMA. Our focus was not to compare the performance of the selected algorithms, which has been done intensively in the research community. Studying an algorithm without an in-depth analysis may deceive us into drawing an inaccurate conclusion on the superiority of one algorithm over another. For example, one might conclude that the ABC algorithm was inferior, because it created more duplicates than the jDElscop algorithm and in most scenarios produced worse results. However, this is not necessarily the case. The ABC algorithm had an innovative mechanism for maintaining diversity using the “limit” parameter, which was, in our implementation, set indirectly by control parameters. Conversely, the jDElscop algorithm used the mechanism of population reduction, which released selection pressure. Both, consequently, influenced the number of duplicates [19]. In conclusion, because the mechanisms of both algorithms depended on the control parameters, one cannot draw conclusions about the superiority of individual algorithms based merely on this study.
EAs are very convenient for black-box optimization where we do not know much about a problem’s characteristics. We are convinced that the long term memory module can be an important contribution in the overall optimization’s success. EA users should be informed about how many duplicate solutions have been generated and how the search spaces has been explored and exploited. The search should not be completely blind. In our future work, we will investigate how visual analytics can help EA researchers and users to understand EA’s inner workings better.
Last but not least, the suggested LTMA did not add much complexity to the EAs’ implementation, and it helped reduce uncertainties about stochastic optimization efficiency by preventing the evaluation of redundant solutions. Therefore, it should be used widely in computationally demanding optimizations. Note that the proposed approach is not suitable for noisy and dynamic problems, where an individual’s fitness changes frequently over time.
Author Contributions
Conceptualization, M.Č., M.M., and M.R.; investigation, S.-H.L.; methodology, M.Č.; software, M.Č.; validation, M.Č., S.-H.L., M.M., and M.R.; writing, original draft, M.Č., S.-H.L., M.M., and M.R.; writing, review and editing, M.Č., S.-H.L., M.M., and M.R.
Funding
This research was funded by the Slovenian Research Agency Grant Number P2-0041 (B).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Eiben, A.G.; Smith, J.E. Introduction to Evolutionary Computing; Springer: Heidelberg, Germany, 2015. [Google Scholar]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Dorigo, M.; Gambardella, L.M. Ant colony system: A cooperative learning approach to the traveling salesman problem. IEEE Trans. Evol. Comput. 1997, 1, 53–66. [Google Scholar] [CrossRef]
- Saremi, S.; Mirjalili, S.; Lewis, A. Grasshopper optimisation algorithm: Theory and application. Adv. Eng. Softw. 2017, 105, 30–47. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Venkata Rao, R.; Savsani, V.; Vakharia, D.P. Teaching–Learning-Based Optimization: An optimization method for continuous non-linear large scale problems. Inf. Sci. 2012, 183, 1–15. [Google Scholar]
- Sörensen, K. Metaheuristics—The metaphor exposed. Int. Trans. Oper. Res. 2015, 22, 3–18. [Google Scholar] [CrossRef]
- Lobo, F.G.; Goldberg, D.E. The parameter-less genetic algorithm in practice. Inf. Sci. 2004, 167, 217–232. [Google Scholar] [CrossRef]
- Eiben, A.; Smit, S. Parameter tuning for configuring and analyzing evolutionary algorithms. Swarm Evol. Comput. 2011, 1, 19–31. [Google Scholar] [CrossRef]
- Veček, N.; Mernik, M.; Filipič, B.; Črepinšek, M. Parameter tuning with Chess Rating System (CRS-Tuning) for meta-heuristic algorithms. Inf. Sci. 2016, 372, 446–469. [Google Scholar] [CrossRef]
- Eiben, A.E.; Hinterding, R.; Michalewicz, Z. Parameter control in evolutionary algorithms. IEEE Trans. Evol. Comput. 1999, 3, 124–141. [Google Scholar] [CrossRef]
- Karafotias, G.; Hoogendoorn, M.; Eiben, A.E. Parameter Control in Evolutionary Algorithms: Trends and Challenges. IEEE Trans. Evol. Comput. 2015, 19, 167–187. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, M. Exploration and Exploitation in Evolutionary Algorithms: A Survey. ACM Comput. Surv. 2013, 45, 35. [Google Scholar] [CrossRef]
- Koza, J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Črepinšek, M.; Liu, S.H.; Mernik, L. A Note on Teaching-learning-based Optimization Algorithm. Inf. Sci. 2012, 212, 79–93. [Google Scholar] [CrossRef]
- Črepinšek, M.; Liu, S.H.; Mernik, L.; Mernik, M. Is a comparison of results meaningful from the inexact replications of computational experiments? Soft Comput. 2016, 20, 223–235. [Google Scholar] [CrossRef]
- Mernik, M.; Liu, S.H.; Karaboga, D.; Črepinšek, M. On clarifying misconceptions when comparing variants of the Artificial Bee Colony Algorithm by offering a new implementation. Inf. Sci. 2015, 291, 115–127. [Google Scholar] [CrossRef]
- Veček, N.; Liu, S.H.; Črepinšek, M.; Mernik, M. On the importance of the artificial bee colony control parameter ‘Limit’. Inf. Technol. Control 2017, 46, 566–604. [Google Scholar] [CrossRef]
- Michalewicz, Z. Genetic Algorithms + Data Structures = Evolution Programs; Springer: Heidelberg, Germany, 1999. [Google Scholar]
- Coello Coello, C.A. Evolutionary multi-objective optimization: A historical view of the field. IEEE Comput. Intell. Mag. 2006, 1, 28–36. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the Strength Pareto Evolutionary Algorithm; TIK Report 103; Computer Engineering and Networks Laboratory, Swiss Federal Institute of Technology (ETH): Zurich, Switzerland, 2001. [Google Scholar]
- Knowles, J.D.; Corne, D.W. Approximating the Nondominated Front Using the Pareto Archived Evolution Strategy. Evol. Comput. 2000, 8, 149–172. [Google Scholar] [CrossRef]
- Cai, X.; Li, Y.; Fan, Z.; Zhang, Q. An External Archive Guided Multiobjective Evolutionary Algorithm Based on Decomposition for Combinatorial Optimization. IEEE Trans. Evol. Comput. 2015, 19, 508–523. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An Evolutionary Many-Objective Optimization Algorithm Using Reference-Point-Based Nondominated Sorting Approach, Part I: Solving Problems With Box Constraints. IEEE Trans. Evol. Comput. 2014, 18, 577–601. [Google Scholar] [CrossRef]
- Zhang, J.; Sanderson, A.C. JADE: Adaptive Differential Evolution With Optional External Archive. IEEE Trans. Evol. Comput. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A. Success-history based parameter adaptation for Differential Evolution. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 71–78. [Google Scholar]
- Branke, J. Memory enhanced evolutionary algorithms for changing optimization problems. In Proceedings of the 1999 Congress on Evolutionary Computation, Washington, DC, USA, 6–9 July 1999; Volume 3, pp. 1875–1882. [Google Scholar]
- Yang, S.; Ong, Y.S.; Jin, Y. (Eds.) Evolutionary Computation in Dynamic and Uncertain Environments; Springer: Heidelberg, Germany, 2007. [Google Scholar]
- Leong, W.; Yen, G.G. PSO-Based Multiobjective Optimization With Dynamic Population Size and Adaptive Local Archives. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 38, 1270–1293. [Google Scholar] [CrossRef]
- Yang, S. Genetic Algorithms with Memory-and Elitism-based Immigrants in Dynamic Environments. Evol. Comput. 2008, 16, 385–416. [Google Scholar] [CrossRef]
- Yuen, S.Y.; Chow, C.K. A Genetic Algorithm That Adaptively Mutates and Never Revisits. IEEE Trans. Evol. Comput. 2009, 13, 454–472. [Google Scholar] [CrossRef]
- Chow, C.K.; Yuen, S.Y. An Evolutionary Algorithm that Makes Decision based on the Entire Previous Search History. IEEE Trans. Evol. Comput. 2011, 15, 741–769. [Google Scholar] [CrossRef]
- Lou, Y.; Yuen, S.Y. Non-revisiting genetic algorithm with adaptive mutation using constant memory. Memet. Comput. 2016, 8, 189–210. [Google Scholar] [CrossRef]
- Leung, S.W.; Yuent, S.Y.; Chow, C.K. Parameter control system of evolutionary algorithm that is aided by the entire search history. Appl. Soft Comput. 2012, 12, 3063–3078. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, Z. An Artificial Bee Colony Algorithm with History-Driven Scout Bees Phase. In Advances in Swarm and Computational Intelligence. ICSI 2015. Lecture Notes in Computer Science; Springer: Heidelberg, Germany, 2015; Volume 9140, pp. 239–246. [Google Scholar]
- Zabihi, F.; Nasiri, B. A Novel History-driven Artificial Bee Colony Algorithm for Data Clustering. Appl. Soft Comput. 2018, 71, 226–241. [Google Scholar] [CrossRef]
- Nasiri, B.; Meybodi, M.; Ebadzadeh, M. History-driven firefly algorithm for optimisation in dynamic and uncertain environments. Appl. Soft Comput. 2016, 172, 356–370. [Google Scholar]
- Črepinšek, M.; Mernik, M.; Liu, S.H. Analysis of Exploration and Exploitation in Evolutionary Algorithms by Ancestry Trees. Int. J. Innov. Comput. Appl. 2011, 3, 11–19. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Maimaiti, M.; Wumaier, A.; Abiderexiti, K.; Yibulayin, T. Bidirectional Long Short-Term Memory Network with a Conditional Random Field Layer for Uyghur Part-Of-Speech Tagging. Information 2017, 8, 157. [Google Scholar] [CrossRef]
- Zhu, J.; Sun, K.; Jia, S.; Lin, W.; Hou, X.; Liu, B.; Qiu, G. Bidirectional Long Short-Term Memory Network for Vehicle Behavior Recognition. Remote Sens. 2018, 10, 887. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Li, C.; Xie, X.; Zhang, G. Long-Short-Term Memory Network Based Hybrid Model for Short-Term Electrical Load Forecasting. Information 2018, 9, 165. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Lu, N.; Wang, S.; Cheng, Y.; Jiang, B. Dynamic Long Short-Term Memory Neural-Network- Based Indirect Remaining-Useful-Life Prognosis for Satellite Lithium-Ion Battery. Appl. Sci. 2018, 8, 2078. [Google Scholar] [CrossRef] [Green Version]
- Chung, H.; Shin, K.S. Genetic Algorithm-Optimized Long Short-Term Memory Network for Stock Market Prediction. Sustainability 2018, 10, 3765. [Google Scholar] [CrossRef] [Green Version]
- Hansen, N.; Auger, A.; Finck, S.; Ros, R. Real-Parameter Black-Box Optimization Benchmarking: Experimental Setup; Technical Report; Institut National de Recherche en Informatique et en Automatique (INRIA): Rapports de Recherche, France, 2013. [Google Scholar]
- Dageförde, J.C.; Kuchen, H. A compiler and virtual machine for constraint-logic object-oriented programming with Muli. J. Comput. Lang. 2019, 53, 63–78. [Google Scholar] [CrossRef]
- Ugawa, T.; Iwasaki, H.; Kataoka, T. eJSTK: Building JavaScript virtual machines with customized datatypes for embedded systems. J. Comput. Lang. 2019, 51, 261–279. [Google Scholar] [CrossRef]
- Bartz-Beielstein, T.; Zaefferer, M. Model-based methods for continuous and discrete global optimization. Appl. Soft Comput. 2017, 55, 154–167. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Cai, X.; Gao, L. Ensemble of surrogates assisted particle swarm optimization of medium scale expensive problems. Appl. Soft Comput. 2019, 74, 291–305. [Google Scholar] [CrossRef]
- Song, H.J.; Park, S.B. An adapted surrogate kernel for classification under covariate shift. Appl. Soft Comput. 2018, 69, 435–442. [Google Scholar] [CrossRef]
- De Falco, I.; Della Cioppa, A.; Trunfio, G.A. Investigating surrogate-assisted cooperative coevolution for large-Scale global optimization. Inf. Sci. 2019, 482, 1–26. [Google Scholar] [CrossRef]
- EARS—Evolutionary Algorithms Rating System (Github). 2016. Available online: https://github.com/UM-LPM/EARS (accessed on 6 September 2019).
- EvoSuite: Automatic Test Suite Generation for Java. 2018. Available online: https://github.com/EvoSuite/evosuite (accessed on 6 September 2019).
- MOEA Framework: A Free and Open Source Java Framework for Mulitiobjective Optimization. 2018. Available online: http://moeaframework.org (accessed on 6 September 2019).
- Veček, N.; Mernik, M.; Črepinšek, M. A chess rating system for evolutionary algorithms: A new method for the comparison and ranking of evolutionary algorithms. Inf. Sci. 2014, 277, 656–679. [Google Scholar] [CrossRef]
- Luan, F.; Cai, Z.; Wu, S.; Liu, S.Q.S.; He, Y. Optimizing the Low-Carbon Flexible Job Shop Scheduling Problem with Discrete Whale Optimization Algorithm. Mathematics 2019, 7, 688. [Google Scholar] [CrossRef] [Green Version]
- Feng, Y.; An, H.; Gao, X. The Importance of Transfer Function in Solving Set-Union Knapsack Problem Based on Discrete Moth Search Algorithm. Mathematics 2019, 7, 17. [Google Scholar] [CrossRef] [Green Version]
- Brest, J.; Sepesy Maučec, M. Self-adaptive differential evolution algorithm using population size reduction and three strategies. Soft Comput. 2011, 15, 2157–2174. [Google Scholar] [CrossRef]
- Matsumoto, M.; Nishimura, T. Mersenne Twister: A 623-dimensionally Equidistributed Uniform Pseudo-random Number Generator. ACM Trans. Model. Comput. Simul. 1998, 8, 3–30. [Google Scholar] [CrossRef] [Green Version]
- Qu, B.; Liang, J.; Wang, Z.; Chen, Q.; Suganthan, P. Novel benchmark functions for continuous multimodal optimization with comparative results. Swarm Evol. Comput. 2016, 26, 23–34. [Google Scholar] [CrossRef]
- Gonos, I.F.; Stathopulos, I.A. Estimation of multilayer soil parameters using genetic algorithms. IEEE Trans. Power Deliv. 2005, 20, 100–106. [Google Scholar] [CrossRef]
- Jesenik, M.; Mernik, M.; Črepinšek, M.; Ravber, M.; Trlep, M. Searching for soil models’ parameters using metaheuristics. Appl. Soft Comput. 2018, 69, 131–148. [Google Scholar] [CrossRef]
- Southey, R.D.; Siahrang, M.; Fortin, S.; Dawalibi, F.P. Using fall-of-potential measurements to improve deep soil resistivity estimates. IEEE Trans. Ind. Appl. 2015, 51, 5023–5029. [Google Scholar] [CrossRef]
- Yang, H.; Yuan, J.; Zong, W. Determination of three-layer earth model from Wenner four-probe test data. IEEE Trans. Magn. 2001, 37, 3684–3687. [Google Scholar] [CrossRef]
Figure 1.
Convergence graph of the ABC algorithm with the Long Term Memory Assistance (LTMA).

Figure 2.
The implementation of LTMA.

Figure 3.
Fitness landscape of a Sphere problem for .

Figure 4.
One run of the ABC algorithm on the Sphere problem for and .

Figure 5.
Fitness landscape of the Ackley problem for .

Figure 6.
One run of the ABC algorithm on the Ackley problem for and .

Figure 7.
Fitness landscape of the Schwefel 2.26 problem for .

Figure 8.
One run of the ABC algorithm on the Schwefel 2.26 problem for and .

Figure 9.
Wenner measuring method and the three-layer soil structure.

Figure 10.
Average speedup for a single run.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Theoretical calculation of needed memory.
| n | MFES | Bytes | MB |
|---|---|---|---|
| 2 | 10,000 | 240,000 | 0.2 |
| 10 | 30,000 | 2,640,000 | 2 |
| 30 | 30,000 | 7,440,000 | 7 |
| 100 | 1,000,000 | 808,000,000 | 770 |
| 200 | 1,000,000 | 1,608,000,000 | 1533 |
| 1000 | 1,000,000 | 8,008,000,000 | 7637 |
Table 2.
Recommended memory for personal computers.
| Release Year | OS | Recommended RAM |
|---|---|---|
| 1981 | MS DOS® | 64 kB |
| 1987 | MS DOS 3.3® | 512 kB |
| 1995 | Windows 95® | 16 MB |
| 1996 | Windows NT® | 32 MB |
| 1998 | Windows 98® | 32 MB |
| 2000 | Windows 2000® | 64 MB |
| 2001 | Windows XP® | 128 MB |
| 2006 | Windows Vista® | 512 MB |
| 2010 | Linux Ubuntu 10 | 1 GB |
| 2012 | Windows 8® | 1 GB |
| 2015 | Windows 10® | 2 GB |
Table 3.
Relations between time, percentage of duplicates, and speedup.
| Speedup 10% | Speedup 20% | Speedup 30% | Speedup 40% | Speedup 90% | Speedup 95% | ||
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0.526 | 0.556 | 0.588 | 0.625 | 0.909 | 0.952 |
| 10 | 1 | 1.000 | 1.111 | 1.250 | 1.429 | 5.000 | 6.667 |
| 100 | 1 | 1.099 | 1.235 | 1.408 | 1.639 | 9.091 | 16.667 |
| 1000 | 1 | 1.110 | 1.248 | 1.427 | 1.664 | 9.901 | 19.608 |
| 10,000 | 1 | 1.111 | 1.250 | 1.428 | 1.666 | 9.990 | 19.960 |
Table 4.
Number of duplicate individuals’ evaluation for the Sphere problem. TLBO, Teaching-Learning Based Optimization; GWO, Gray Wolf Optimizer; GOA, Grasshopper Optimization Algorithm.
Table 4.
Number of duplicate individuals’ evaluation for the Sphere problem. TLBO, Teaching-Learning Based Optimization; GWO, Gray Wolf Optimizer; GOA, Grasshopper Optimization Algorithm.
| EA | n | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ABC | 2 | 10,000 | 100 | ||||||
| jDElscop | 2 | 10,000 | 100 | ||||||
| TLBO | 2 | 10,000 | 100 | ||||||
| GWO | 2 | 10,000 | 100 | ||||||
| GOA | 2 | 10,000 | 100 | ||||||
| ABC | 10 | 30,000 | 11,698.2 | 10,228.5 | 100 | ||||
| jDElscop | 10 | 30,000 | 13,805.4 | 11,140.6 | 100 | ||||
| TLBO | 10 | 30,000 | 100 | ||||||
| GWO | 10 | 30,000 | 28,576.7 | 27,898.6 | 27,129.9 | 100 | |||
| GOA | 10 | 30,000 | 100 | ||||||
| ABC | 30 | 100,000 | 39,304.5 | 38,560.1 | 100 | ||||
| jDElscop | 30 | 100,000 | 48,036.5 | 43,055.4 | 37,904.8 | 100 | |||
| TLBO | 30 | 100,000 | 100 | ||||||
| GWO | 30 | 100,000 | 96,938.2 | 95,218.2 | 93,736.9 | 100 | |||
| GOA | 30 | 100,000 | 0 |
Table 5.
Number of duplicate individuals’ evaluation for the Ackley problem.
| EA | n | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ABC | 2 | 10,000 | 100 | ||||||
| jDElscop | 2 | 10,000 | 100 | ||||||
| TLBO | 2 | 10,000 | 100 | ||||||
| GWO | 2 | 10,000 | 100 | ||||||
| GOA | 2 | 10,000 | 96 | ||||||
| ABC | 10 | 30,000 | 11,703.2 | 100 | |||||
| jDElscop | 10 | 30,000 | 14,116.5 | 11,528.2 | 100 | ||||
| TLBO | 10 | 30,000 | 100 | ||||||
| GWO | 10 | 30,000 | 28,751.1 | 27,977.6 | 27,273.7 | 100 | |||
| GOA | 10 | 30,000 | 4 | ||||||
| ABC | 30 | 100,000 | 40,259.1 | 32,573.8 | 12,076.3 | 100 | |||
| jDElscop | 30 | 100,000 | 48,279.1 | 43,431.3 | 38,226.1 | 100 | |||
| TLBO | 30 | 100,000 | 100 | ||||||
| GWO | 30 | 100,000 | 97,123.6 | 95,477.3 | 93,873.4 | 100 | |||
| GOA | 30 | 100,000 | 0 |
Table 6.
Number of duplicate individuals’ evaluation for the Schwefel 2.26 problem.
| EA | n | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ABC | 2 | 10,000 | 100 | ||||||
| jDElscop | 2 | 10,000 | 100 | ||||||
| TLBO | 2 | 10,000 | 90 | ||||||
| GWO | 2 | 10,000 | 10 | ||||||
| GOA | 2 | 10,000 | 60 | ||||||
| ABC | 10 | 30,000 | 48 | ||||||
| jDElscop | 10 | 30,000 | 100 | ||||||
| TLBO | 10 | 30,000 | 0 | ||||||
| GWO | 10 | 30,000 | 0 | ||||||
| GOA | 10 | 30,000 | 0 | ||||||
| ABC | 30 | 100,000 | 18,168.4 | 18,168.4 | 0 | ||||
| jDElscop | 30 | 100,000 | 24,746.7 | 100 | |||||
| TLBO | 30 | 100,000 | 0 | ||||||
| GWO | 30 | 100,000 | 0 | ||||||
| GOA | 30 | 100,000 | 0 |
Table 7.
ABC algorithm on CEC-2015 with .
| Pro. | Fit | t | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 26,711.8 | 26,711.8 | 13,710.4 | 26,574.3 | 26,574.3 | 12,868.0 | 12,971.5 | ||||
| 23,124.3 | 23,124.3 | 23,058.7 | 23,058.7 | |||||||
| 16,360.0 | 19,455.2 | |||||||||
| 22,551.8 | 22,551.8 | 22,698.8 | 22,698.8 | |||||||
| 21,728.5 | 21,728.5 | 21,908.3 | 21,908.3 | |||||||
| 22,954.7 | 22,954.7 | 11,114.8 ±11,329.6 | 22,803.2 | 22,803.2 | 10,484.4 | 11,546.5 |
Table 8.
jDElscop algorithm on CEC-2015 with .
| Pro. | Fit | t | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 15,142.5 | ||||||||||
| 16,487.8 | 12,137.0 | |||||||||
| 20,848.0 | ||||||||||
| 13,453.9 | 13,500.5 | 12,857.5 | 12,892.5 | |||||||
Table 9.
ABC algorithm on CEC-2015 with .
| Pro. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 26% | 25% | |||||||||
| 36,731.3 | 36,731.3 | 12,767.4 | 23% | 36,503.8 | 36,503.8 | 12,019.9 | 29% | |||
| 30,440.7 | 30,440.7 | 25% | 30,172.2 | 30,172.2 | 40% | |||||
| 18,153.2 | 23,244.3 | 60% | 51% | |||||||
| 29,324.9 | 29,324.9 | 29% | 29,554.8 | 29,554.8 | 29% | |||||
| 2% | 2% | |||||||||
| 0% | 2% | |||||||||
| 12% | 24% | |||||||||
| 27,947.6 | 27,947.6 | 36% | 28,205.2 | 28,205.2 | 40% | |||||
| 30,065.2 | 30,065.2 | 21% | 29,929.6 | 29,929.6 | 12% |
Table 10.
jDElscop algorithm on CEC-2015 with .
| Pro. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 36,269.0 | 5% | ±10,835.2 | 48% | |||||||
| 12,908.8 ±10,847.5 | 41% | 89% | ||||||||
| 12,208.1 ±15,016.7 | 35,757.9 | 2% | ±11,189.7 | 26,191.1 | 1% | |||||
±11,004.4 | 44,841.8 | 17% | 0% | |||||||
| 26,990.6 ±12,096.8 | 27,169.1 ±11,827.0 | 54% | 24,287.9 ±12,501.4 | 24,468.8 ±12,314.9 | 51% | |||||
| 15,763.2 ±15,183.5 | 21,721.5 ±14,162.7 | 12% | 16,266.4 ±14,745.1 | 20,168.4 ±14,010.7 | 11% | |||||
| 15,509.7 ±14,363.5 | 21,797.1 ±13,112.1 | 15% | 14,768.1 ±14,181.0 | 19,777.9 ±13,410.9 | 14% | |||||
| 13,746.8 ±10,436.1 | 13,746.8 ±10,436.1 | 63% | 14,948.1 ±21,325.4 | 14,948.1 ±21,325.4 | 39% | |||||
| 14,896.3 ±10,625.5 | 14,896.3 ±10,625.5 | 66% | 12,068.1 ±15,081.8 | 12,068.1 ±15,081.8 | 55% | |||||
| 95% | 94% |
Table 11.
Optimization of soil problem with the ABC and jDElscop algorithms.
| EA | Pro. | t | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ABC | |||||||||||
| ABC | |||||||||||
| ABC | |||||||||||
| jDElscop | |||||||||||
| jDElscop | |||||||||||
| jDElscop |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Črepinšek, M.; Liu, S.-H.; Mernik, M.; Ravber, M. Long Term Memory Assistance for Evolutionary Algorithms. Mathematics 2019, 7, 1129. https://0-doi-org.brum.beds.ac.uk/10.3390/math7111129
AMA Style
Črepinšek M, Liu S-H, Mernik M, Ravber M. Long Term Memory Assistance for Evolutionary Algorithms. Mathematics. 2019; 7(11):1129. https://0-doi-org.brum.beds.ac.uk/10.3390/math7111129
Chicago/Turabian StyleČrepinšek, Matej, Shih-Hsi Liu, Marjan Mernik, and Miha Ravber. 2019. "Long Term Memory Assistance for Evolutionary Algorithms" Mathematics 7, no. 11: 1129. https://0-doi-org.brum.beds.ac.uk/10.3390/math7111129
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.