1. Introduction
Landslides and floods are the common natural disasters that strike the northwestern provinces of Rwanda due to its topographical, geological features and climatic profile [
1,
2]. According to
The National Risk Atlas of Rwanda report published by the Ministry in Charge of Emergency Management (MINEMA), 42% of areas are classified as moderate to very high susceptible areas to landslides [
3]. Statistics indicate that many people lose their lives in different disaster incidences, and the damages of their properties/infrastructure are worth millions of dollars, and much more money is spent on disaster recovery too [
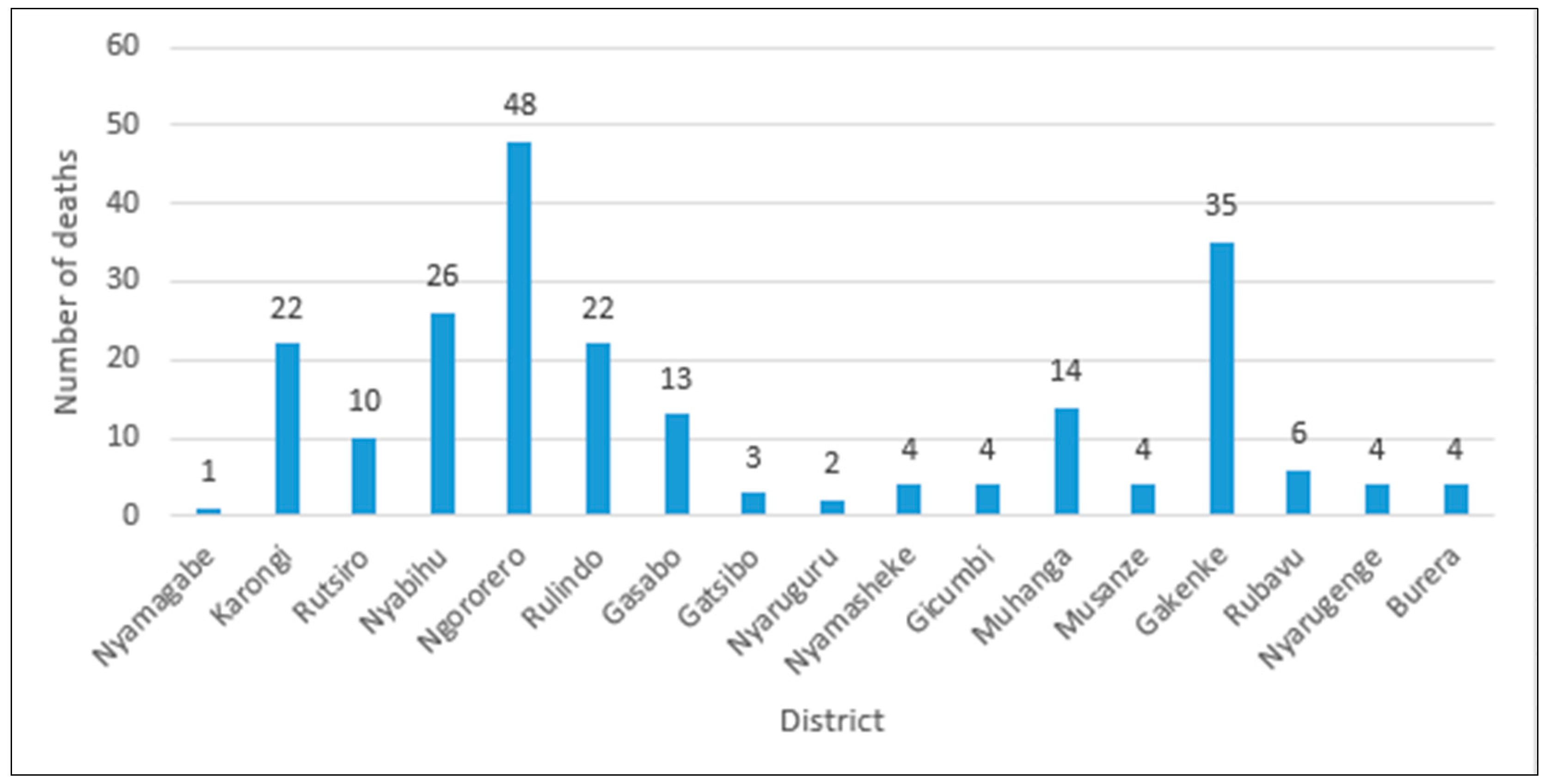
4]. Every year, during the rainfall period, landslides affect many people in mountainous regions. These disasters led to the loss of lives and left many homeless and without a livelihood. Since the establishment of an institution in charge of disaster management (MINEMA) in 2010, systematic records indicate that there were 227 deaths and 160 injuries from 2011–2018 (June). Also many houses collapsed and many hectares of crops have been washed away by landslides and floods [
5].
Table 1 and
Figure 1 summarize the statistics of deaths caused by landslides during the period of 2011–2018 in Rwanda.
In most cases, landslides and floods in Rwanda occur in a cascading manner as debris is dumped into rivers which in turn causes riverine floods [
6]. One example is the case of floods and landslides hazards that occurred in 2016 and 2018 where many people died after heavy rainfalls that caused widespread flooding and landslides across parts of Rwanda. At least 222 died in different landslide events since 2011–2018, where victims drowned in floodwater or others died after houses collapsed due to debris movement or landslides caused by heavy rainfall. The type of floods most threatening Rwanda are riverine floods due to its dense river network and large wetlands [
7].
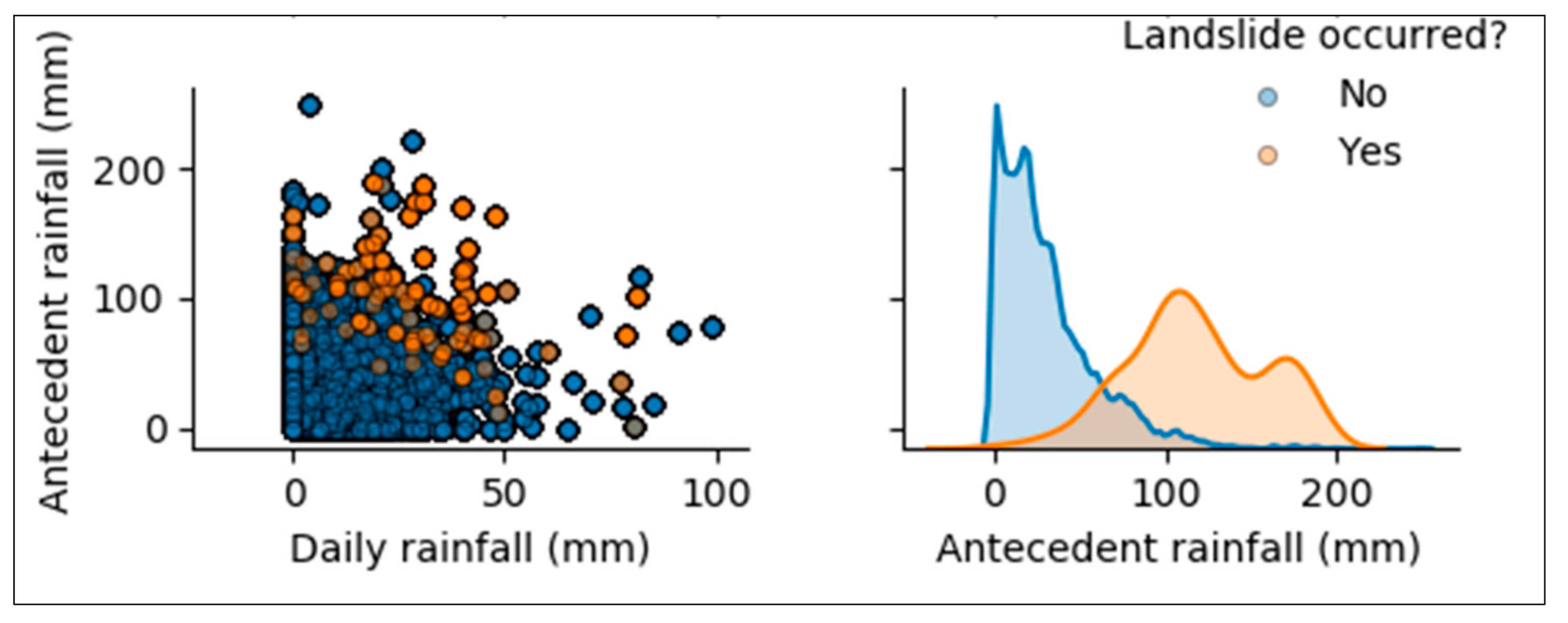
The triggering factor of a landslide is rainfall infiltration into the soil, making the groundwater level increase, resulting in a reduction of the shear strength which is also closely related to antecedent rainfall, cumulative rainfall, and rainfall duration [
8]. The slope instability increases with high intensity or long duration rainfall but does not relate to rainfall alone. It is affected by other factors such as lithological material, type of soil and depth, the surrounding vegetation, slope inclination or aspect, curvature, altitude, land use patterns, and drainage networks [
5,
9,
10].
Although the rainfall intensity may be the same in different regions, landslides may or may not occur according to the geological and topographical characteristics. Therefore, rainfall intensity cannot be the only cause of landslides [
10]. According to the study carried out by MINEMA, the landslide contributing factors have been assigned weights based on the past landslides characteristics in Rwanda: rainfall (20%), slope (20%), altitude (15%), soil type (14%), lithology (10%), land cover (9%), soil depth (7%), distance to the main roads (5%) [
7]. Various machine learning models and assessment studies have been carried out on both landslide susceptibility assessments and flood predictions [
6,
10,
11]. The models are built based on the assumption that landslides are more likely to occur in situations similar to those of past landslides [
4].
Although there have been numerous researches undertaken on disaster susceptibility assessment and prediction models, the literature about landslides data for Rwanda is scarce. Rwanda lacks efficient early warnings about disasters and hence, the risks of vulnerability by incidences are high [
12]. Therefore, there is a need for continuous research on prediction of disasters due to landslides and floods to reduce the risks. Recently, a few studies were conducted on landslide susceptibility in Rwanda, [
5] but none of them were about disaster prediction for early warning and risk reduction.
Elsewhere, numerous machine learning techniques have been used to predict landslide occurrence but most of them have been focusing on disaster susceptibility mapping using internal (geological, topographical, environmental) factors without taking into consideration the triggering internal factors such as rainfall [
12,
13].Those that include rainfall in dataset do not consider antecedent rainfall or vice versa [
5,
14,
15], others use both daily and cumulated previous precipitations without internal conditioning parameters [
16]. False negative rate was not considered to measure the performance of the models, yet it is a crucial evaluation metric in landslide predictions.
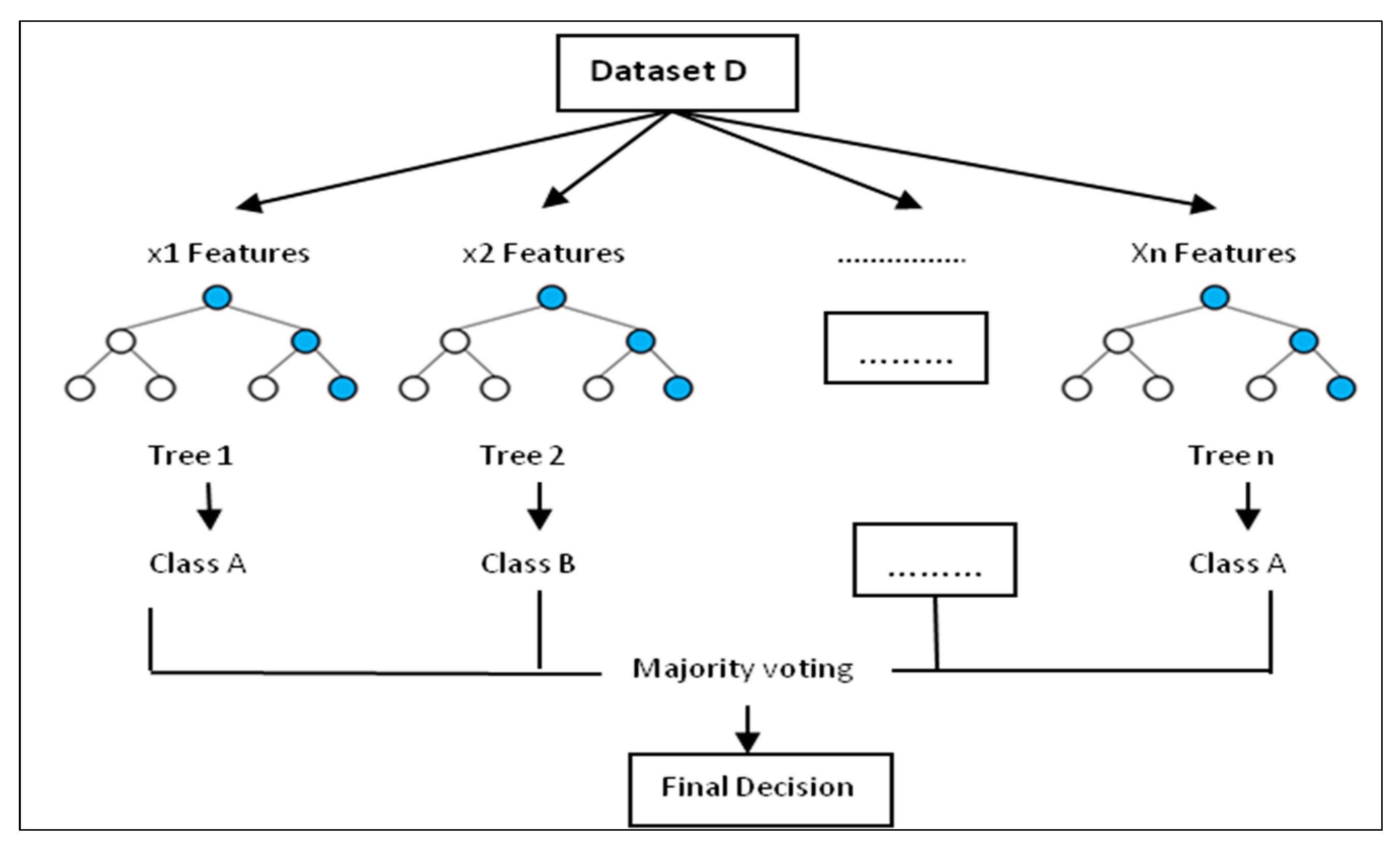
The main purpose of this research is to improve the performance of the prediction models by including the antecedent rainfall data among other parameters used in the previous studies such as daily rainfall, hill slope angle, soil type, soil depth, and land cover. Another objective is to minimize the incorrect predictions (FNR) as this is a very important metric to be considered since this one counts landslide cases that have not been seen by the prediction model and has a significance in early warning systems. The preferred MLTs are random forest (RF) and logistic regression (LR). These two MLTs were selected among others because of being among the most broadly used in landslide prediction [
4] and due to their ability to deal with discrete and continuous data for classification problems. Besides, LR calculates regression coefficients while RF can show up the importance of different parameters, its training speed is high and the computational cost is low [
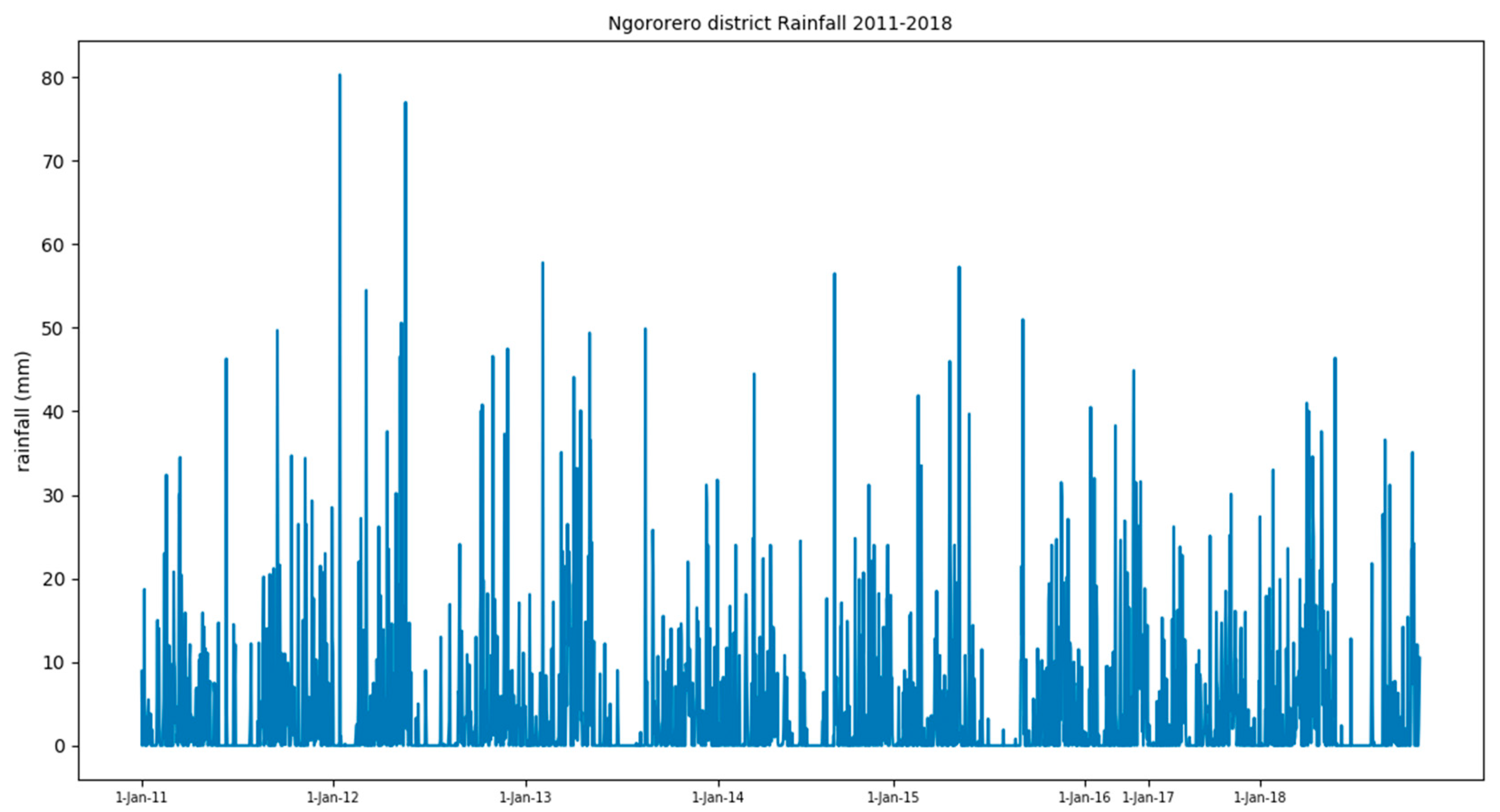
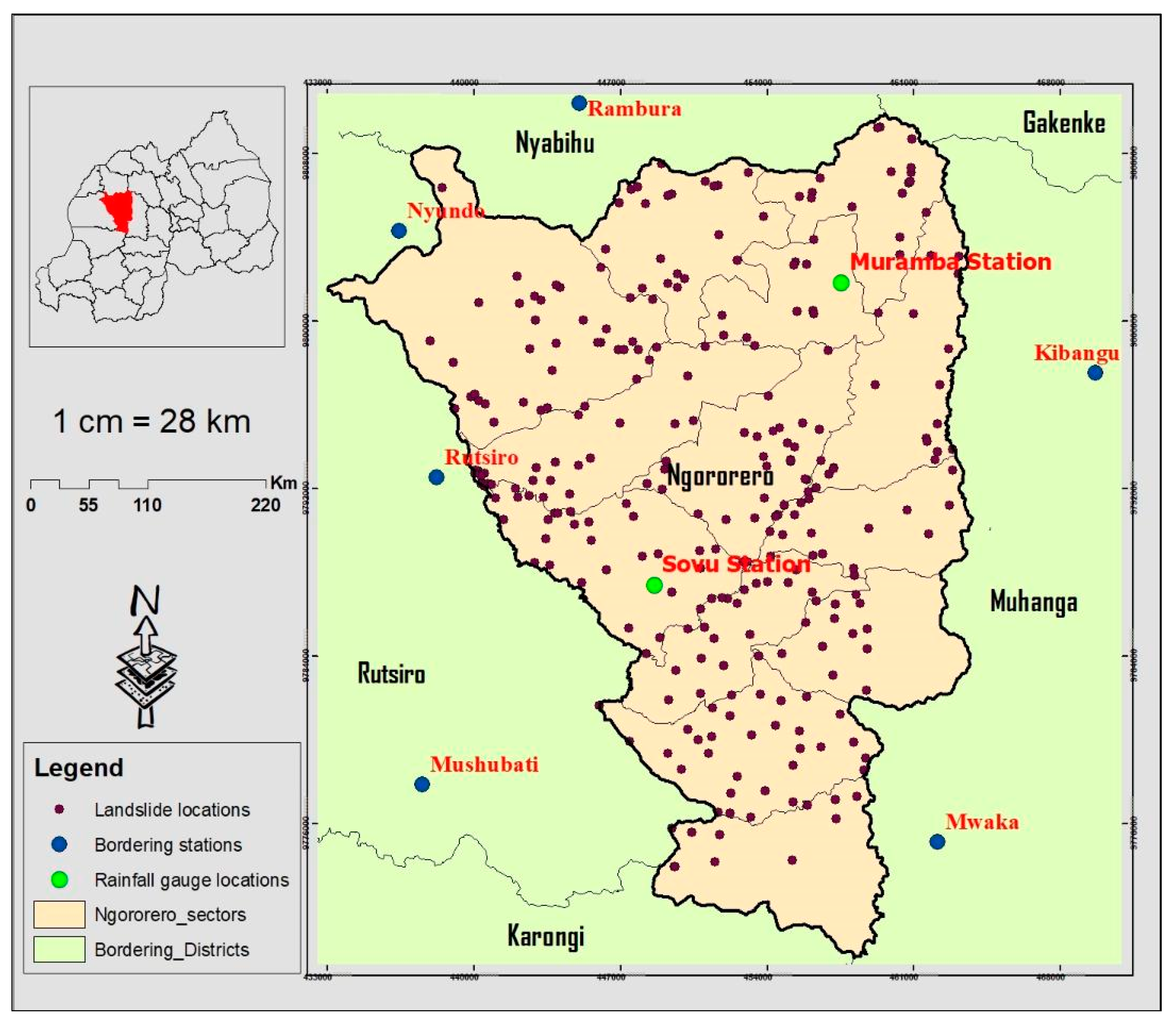
4]. This study is aimed at: (1) to analyze the correlation between rainfall historical data and other topographical and geological factors impacting landslide occurrence in Rwanda and (2) propose a machine learning model for the prediction of this disaster which can be used for early warning. This study is geographically limited to the Ngororero district in Rwanda and the period of study was from 2011–2018.
4. Discussion
Prediction of landslide occurrence and early warning systems are the primary keys for the awareness and preparedness for risk reduction from this type of disaster. Different prediction models and warning systems (both local and regional) are available for this purpose [
35]. The most popular machine learning models that have recently been used for landslide prediction are namely random forest [
20,
25,
36], artificial neural network [
37,
38], support vector machine [
4,
25], logistic regression [
36,
38,
39], etc. The results obtained from these different studies were good depending on the variables used and metrics used to evaluate their performance. In some studies, only internal factors were used to determine landslide susceptibility, some others have used rainfall, while a few of them included antecedent precipitation to determine its impact on the disaster occurrence. In this study, we preferred to use RF and LR for the reason explained earlier and more particularly to be applied in Rwanda as, to the best of our knowledge, there is no such study carried out on this territory. The use of both internal (geological and morphological) factors together with external (triggering) factor (rainfall: antecedent & current) led us to the better performance of the models compared to when either one of these factors is not considered. The results from a comparative analysis of one-day rainfall and 5-days antecedent cumulative rainfall before landslide occurrence revealed that antecedent cumulative rainfall has more impact on landslide occurrence than one-day rainfall (
Table 6). This is because the shear strength of the soil is degraded by rainfall and continuous if the interval between two or more rainfall events is short (few hours) but also depending on the hydraulic conductivity of the soil [
40].
All performance metrics improve when the antecedent rainfall (Ar) is used for both models. For correct predictions, RF improves 10.58 and 3.73% for recall and specificity respectively while LR improves 5.77 and 4.46% on the same metrics. Incorrect predictions improve in the same manner as the correct predictions as ones are the opposite of the other ones. FN is a very important parameter to consider in the case of landslide prediction as its low value means few incidence cases were not predicted. In this case, LR performs better than RF as
Table 6 shows that only 3.84% cases were not predicted.
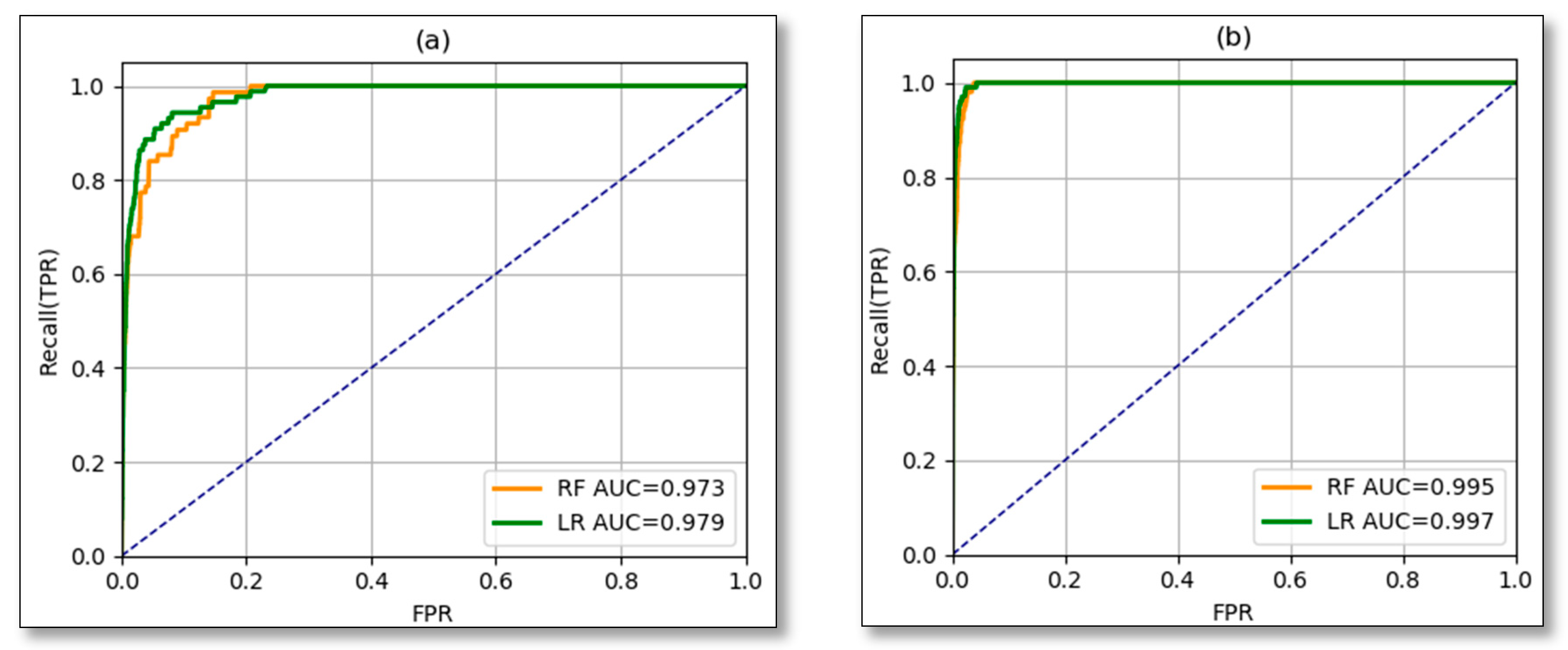
The receiver operating curve was used to identify the performance of the models at different classification threshold and the AUC was used to compare two models by including or not including antecedent cumulated rainfall. Considering ROC-AUC, RF performs with AUC = 0.973 (
Figure 12a) if only daily rainfall is considered as landslide triggering factor and AUC = 0.995 by including antecedent rainfall as additional landslide triggering factor (
Figure 12b). This means that antecedent cumulated rainfall implicates better performance of the model to the rate of 2.2%. Likewise, Ar improved the LR model as before the inclusion of previous cumulative precipitations AUC was 0.979 (
Figure 12a). However, after including the Ar, AUC was equal to 0.997 (
Figure 12b), hence this parameter contributed 1.8% to the model prediction.
Both models indicated that 5-days antecedent precipitation has a high impact on the occurrence of landslides in the study area.
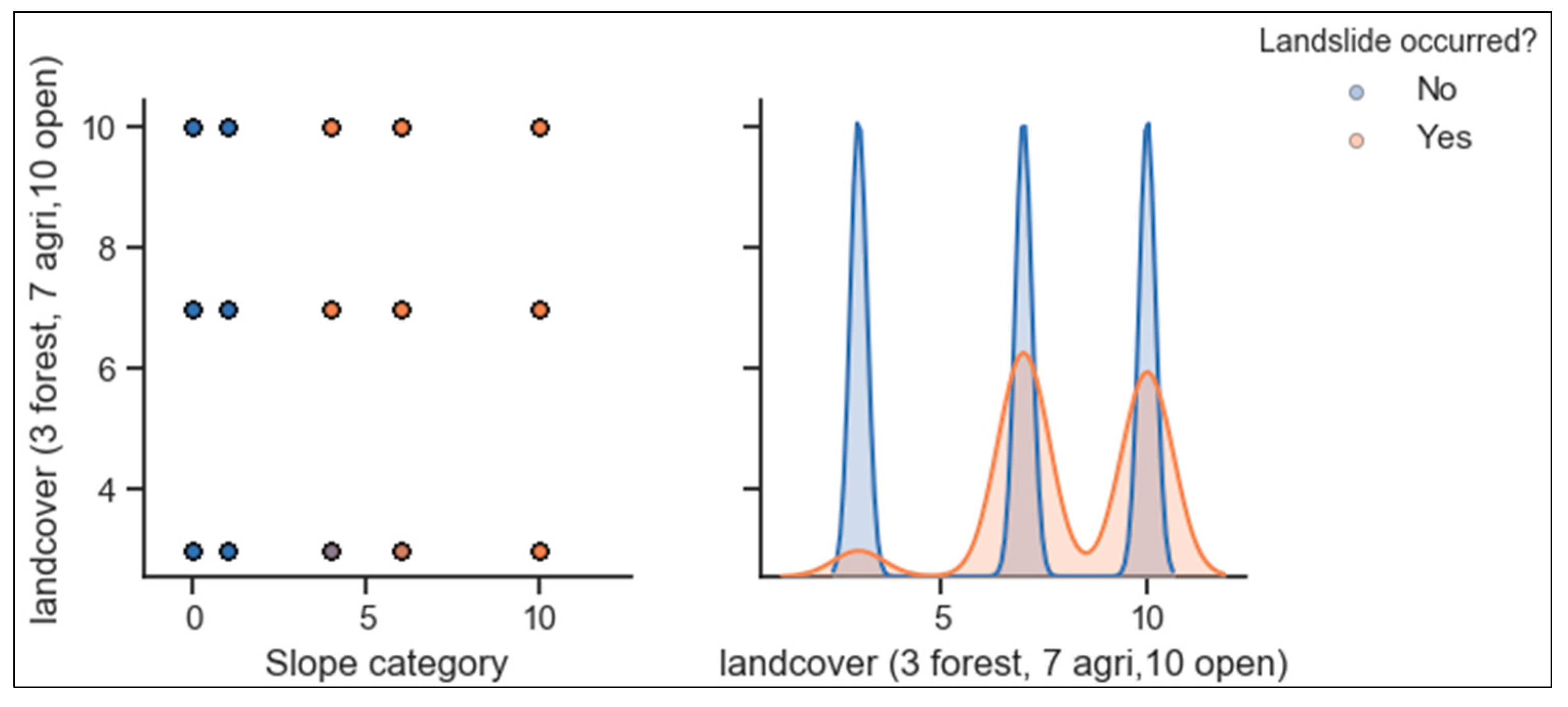
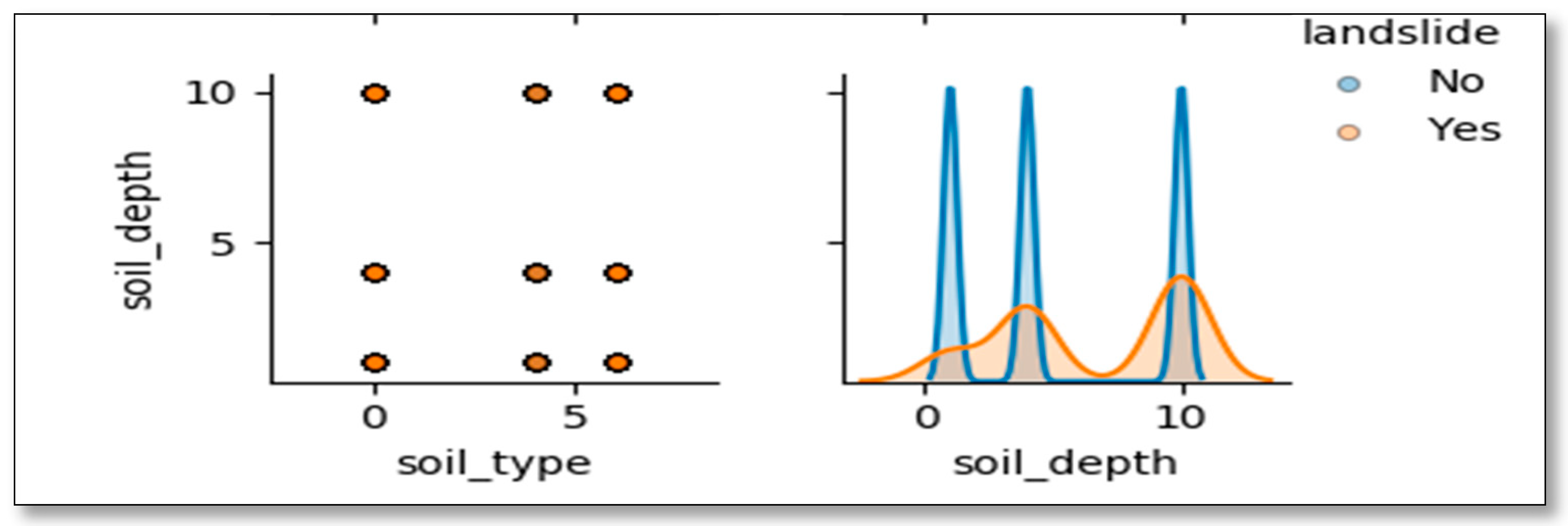
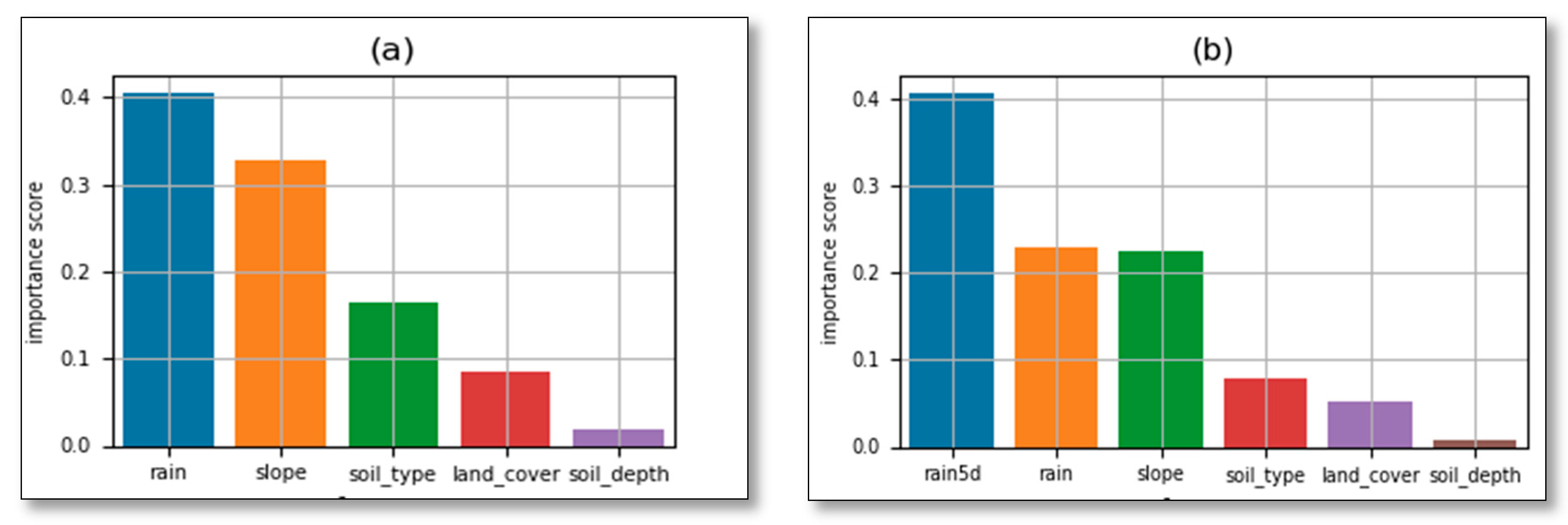
Table 5 shows that the features most triggering landslide incidences are rainfall (one-day, 5-days antecedent) as indicated by their coefficients of 2.47 and 1.32, respectively. Among the internal factors, the slope is the most affecting the occurrence of the disaster. The magnitude of the impact increases as slope increases or vice versa. For low slopes (less than 15 degrees coefficients are negative while the probability of landslide incidence is very high on slopes of 25–45 degrees with a coefficient of 6.49. This means that high slope zones are prone to landslides and people should not reside in such areas to reduce risks. The silt soil, the soil of more than 1m deep, and agriculture land are the most vulnerable to the landslide (
Table 5).
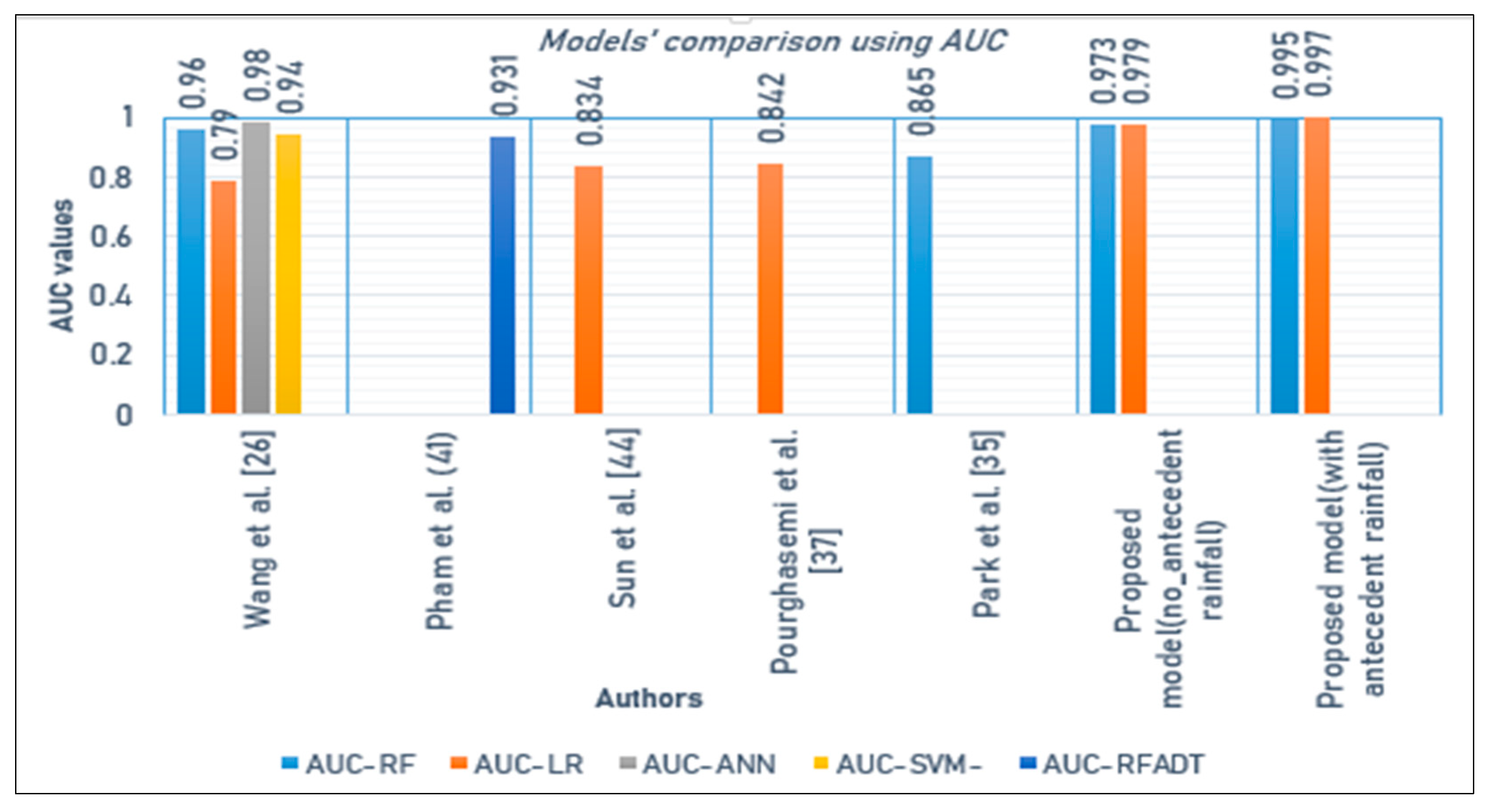
Table 6 shows that both models performed well in terms of different performance indicators such as accuracy, errors, and AUC. The use of antecedent precipitation made the models predict better. We also compared the performance of these prediction models with other recently established models using the same machine learning algorithms, [
26,
41,
42,
43,
44] and the ones used different models such as artificial neural networks (ANNs) [
26], support vector machine (SVM) [
26], event-class predictor [
45], and rotation forest with alternating decision tree (RFADT) [
41]. The comparison of the models was done using AUC which seems to be widely used by researchers and FNR which has been used by a few. The ANN proposed by Wang et al. [
26] performed better compared to the RF and LR models proposed in this study before the use of antecedent rainfall data, but after including the antecedent rainfall data in the dataset both RF and LR models predict better with good AUC results compared to ANN and other models. Thus, adding antecedent rainfall data has made the RF and LR models proposed in the current study achieve good results (
Figure 13).
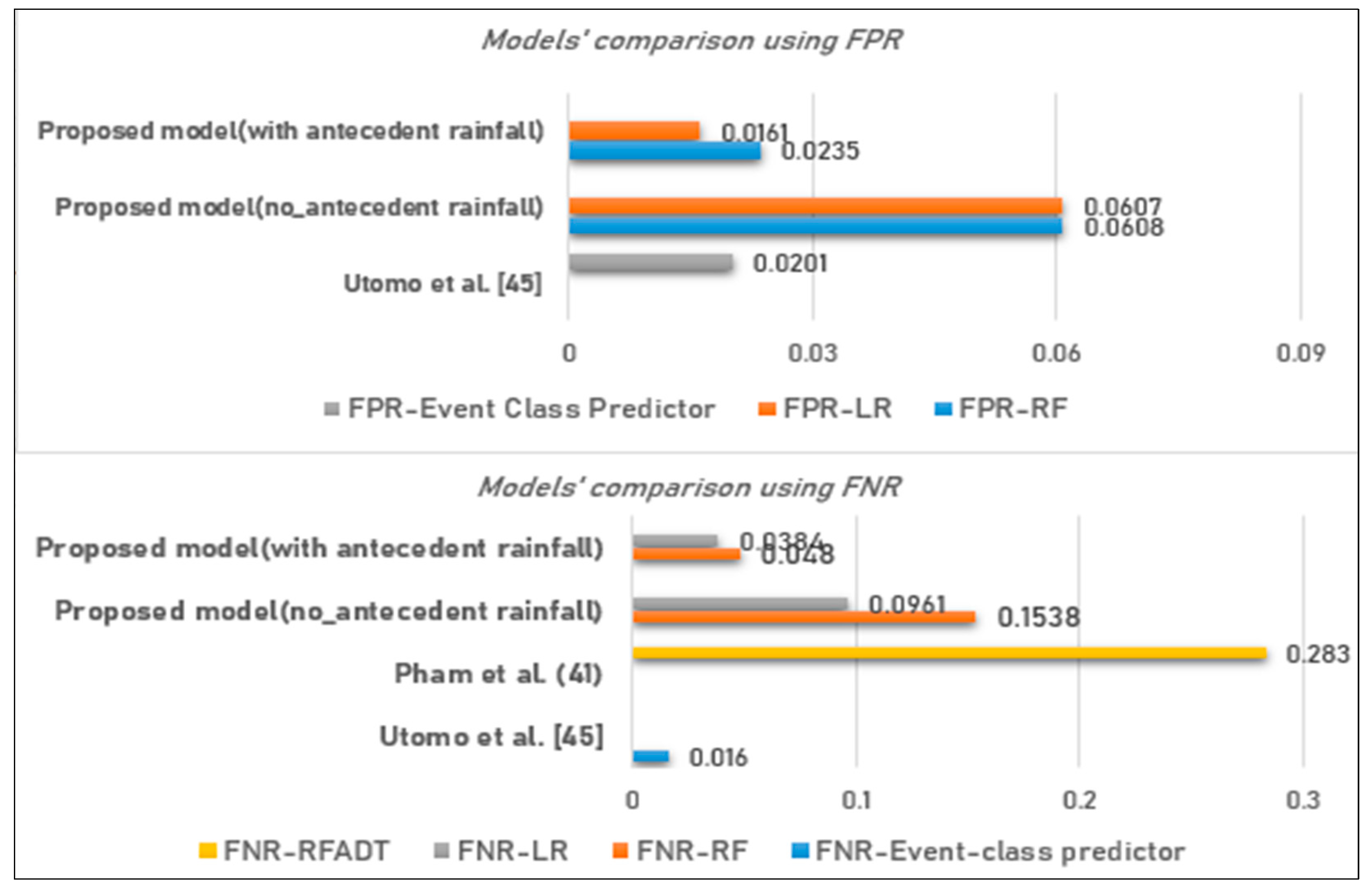
A comparative analysis has also been done with other models on incorrect predictions.
Figure 14 indicates that the model proposed by Utomo et al. [
36] is the best to minimize false negative errors up to 1.60%, while the LR in our study can minimize FNR up to 3.84%. On the other hand, our proposed LR can minimize FP errors up to 1.61% against 2.01% of Utomo et al. [
36].
Comparing the two proposed models RF and LR of the current study among themselves, there is a slight difference in the prediction parameters, like for instance if ROC-AUC is considered both models are good, as indicated in
Figure 12, but in terms of prediction errors, LR is considered the best because its FNR is 3.84% against 4.80% of RF. This evaluation parameter (FNR) should be highly considered because it indicates how many landslide cases were predicted as NO landslides, which can be a dangerous outcome. Minimizing the ratio of false negatives is crucial for better performance of the system and disaster risk reduction. In this regard, logistic regression is the best model to be used due to its performance in terms of error reduction (false negatives). Besides error reduction, LR performs faster than RF which is another important aspect that LR to be considered in the early warning system as the delay is reduced. Though 100% perfect prediction is not achievable through these modelling approaches, the priority is to minimize the false negatives (warning that there will be no landslide yet landslides occur) because it has a negative impact on lives rather than false alarms (warning that there will be a landslide while is false).
5. Conclusions
In this research two approaches, random forest (RF) and logistic regression (LR), were applied to analyze the rainfall data along with other external and internal factors to develop a prediction model for landslide incidences for an early warning system. Performance parameters such as ROC-AUC, error rate (TP and FN) have been used to evaluate the best prediction models. The results prove that the prediction performance of these two models are better than those established in other research studies.
Results from this study revealed that landslides are triggered due to the too much daily (or low intensity prolonged) rainfall, but in most cases they occurred after a few consecutive (like 2–5) days of precipitation. This was proved by the impact of antecedent rainfall on disaster occurrence as marked by prediction models used in this study. Both models indicated that 5-days antecedent precipitation has a high impact on the occurrence of landslides in the study area. In addition to the rainfall data, other parameters have been utilized to assess their impact on the disaster. The slope of hills is the most internal parameter affecting disaster occurrence after rainfalls (external factor), meaning that the areas of high slope angle are more susceptible to landslides than the regions where the terrain is almost a plateau. Agricultural land or non-protected land is the most susceptible to landslide occurrence while land covered by forest had few incidences. As previously discussed, landslides are triggered by current rainfall but very correlated with consecutive precipitation before the day of incidence. This is because the soil strength reduces with water content depending on the type of soil material and gets strong again during the evapotranspiration process or the sunny season. Based on the results, the logistic regression proves to be the best approach to be used for landslide prediction and early warning. LR model’s incorrect prediction rate FNR is 9.61% without including antecedent precipitation data and is 3.84% after including the antecedent precipitation data. Therefore, LR model can be used for the early warning system.
Instead of antecedent cumulated rainfall, in our future work, we will study the correlation between landslide occurrences, rainfall and soil moisture level on different types of the soil which will be gathered by sensors and through WSN, landslides will be predicted and citizens warned earlier. The prediction capability combined with the Internet of Things (IoT) where rainfall gauges can be used to capture rainfall intensity in real-time and soil moisture sensors used to measure the water content in the soil will be used for rescuing citizens from landslide disasters.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}