
A GIS-Based Landslide Susceptibility Mapping and Variable Importance Analysis Using Artificial Intelligent Training-Based Methods


Abstract
:1. Introduction
2. Literature Review
3. Study Area and Data
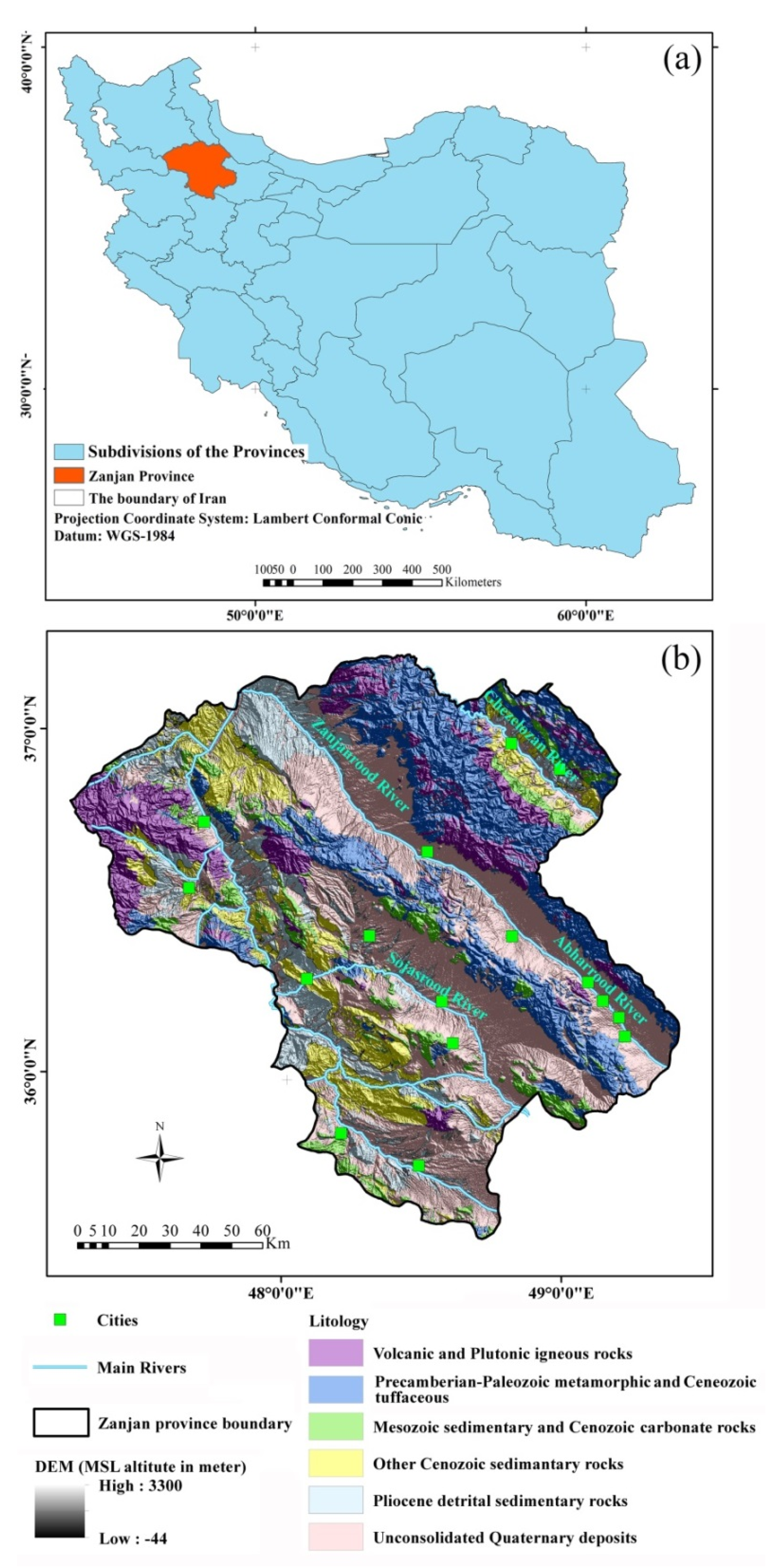
3.1. The Case Study Area
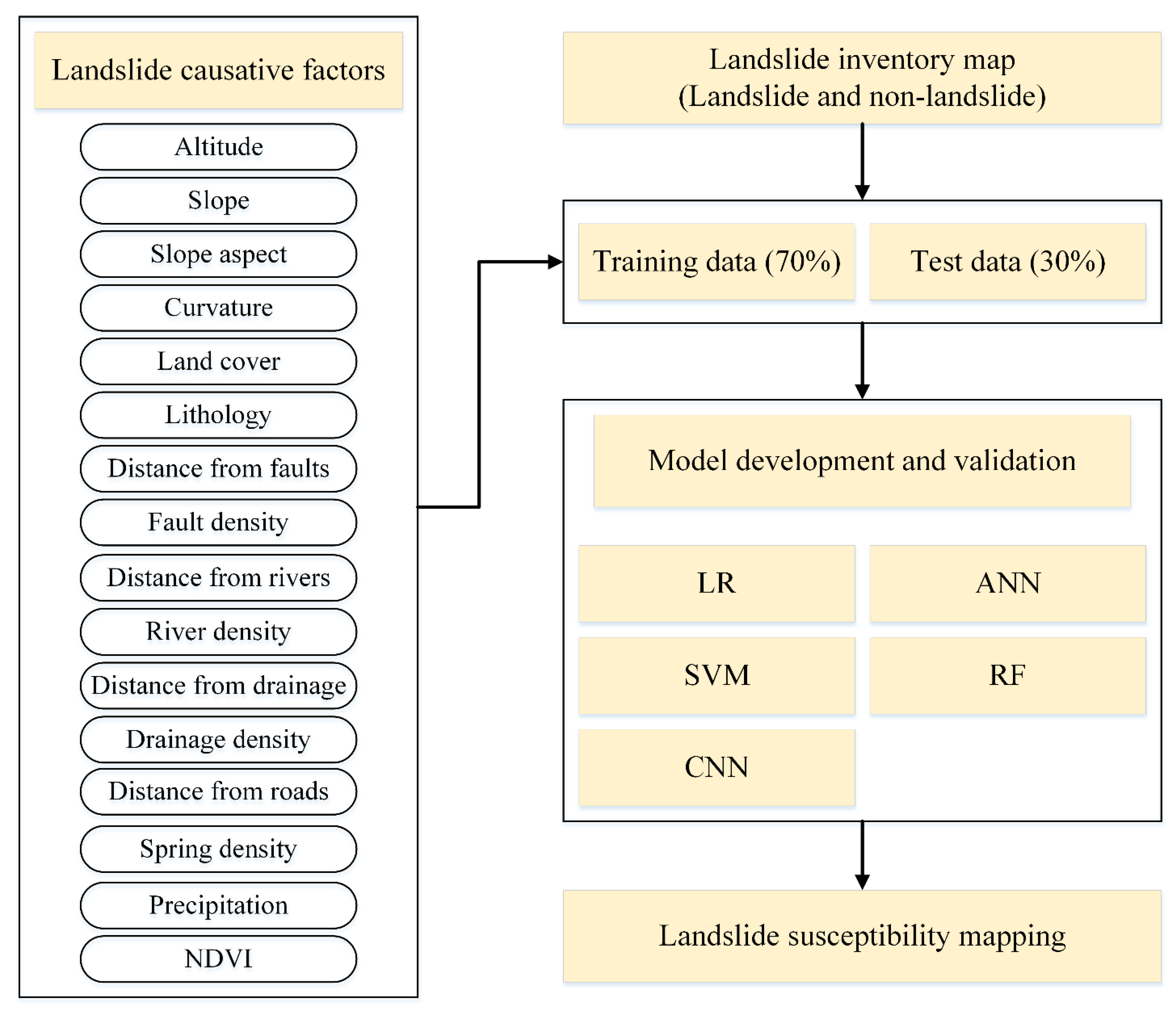
3.2. The Causative Factors of Landslides
3.2.1. Altitude
3.2.2. Slope
3.2.3. Slope Aspect
3.2.4. Topographic Curvature
3.2.5. Land Use
3.2.6. Lithology
3.2.7. Distance from Faults and the Density of Faults
3.2.8. Distance from Rivers and the Density of Rivers
3.2.9. Distance from Roads
3.2.10. The Density of Lineaments
3.2.11. The Density of Springs
3.2.12. NDVI
3.2.13. Precipitation
3.3. Landslide Inventory Map
4. Methodology
4.1. Machine Learning Algorithms
4.1.1. Logistic Regression (LR)
4.1.2. Artificial Neural Network (ANN)
4.1.3. Support Vector Machine (SVM)
4.1.4. Random Forest (RF)
4.1.5. Convolutional Neural Network (CNN)
4.2. Evaluation Measures
4.3. Feature Importance
5. Results and Discussion
5.1. Model Performance Comparison
5.2. Variable Importance Analysis
5.3. Produced LSMs
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Liao, M.; Shi, X.; Zhang, L.; Cunningham, C. Potential loess landslide deformation monitoring using L-band SAR interferometry. Geo-Spat. Inf. Sci. 2016, 19, 273–277. [Google Scholar] [CrossRef]
- Haque, U.; Da Silva, P.F.; Devoli, G.; Pilz, J.; Zhao, B.; Khaloua, A.; Wilopo, W.; Andersen, P.; Lu, P.; Lee, J.; et al. The human cost of global warming: Deadly landslides and their triggers (1995–2014). Sci. Total Environ. 2019, 682, 673–684. [Google Scholar] [CrossRef] [PubMed]
- Betts, H.; Basher, L.; Dymond, J.; Herzig, A.; Marden, M.; Phillips, C. Development of a landslide component for a sediment budget model. Environ. Model. Softw. 2017, 92, 28–39. [Google Scholar] [CrossRef]
- Boroumandi, M.; Khamehchiyan, M.; Nikoudel, M.R. Using of analytic hierarchy process for landslide hazard zonation in Zanjan Province, Iran. In Engineering Geology for Society and Territory; Springer: Cham, Switzerland, 2015; Volume 2, pp. 951–955. [Google Scholar]
- Tsangaratos, P.; Ilia, I. Comparison of a logistic regression and Naïve Bayes classifier in landslide susceptibility assessments: The influence of models complexity and training dataset size. Catena 2016, 145, 164–179. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rahmati, O. Prediction of the landslide susceptibility: Which algorithm, which precision? Catena 2018, 162, 177–192. [Google Scholar] [CrossRef]
- Gerzsenyi, D.; Albert, G. Landslide inventory validation and susceptibility mapping in the Gerecse Hills, Hungary. Geo-Spat. Inf. Sci. 2021, 24, 498–508. [Google Scholar] [CrossRef]
- Broeckx, J.; Vanmaercke, M.; Duchateau, R.; Poesen, J.N. A data-based landslide susceptibility map of Africa. Earth-Sci. Rev. 2018, 185, 102–121. [Google Scholar] [CrossRef]
- Kornejady, A.; Pourghasemi, H.R. Producing a Spatially Focused Landslide Susceptibility Map Using an Ensemble of Shannon’s Entropy and Fractal Dimension (Case Study: Ziarat Watershed, Iran). In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2019; pp. 689–732. [Google Scholar]
- Hervás, J.; Bobrowsky, P. Mapping: Inventories, susceptibility, hazard and risk. In Landslides–Disaster Risk Reduction; Springer: Berlin/Heidelberg, Germany, 2019; pp. 321–349. [Google Scholar]
- Maleki, J.; Masoumi, Z.; Hakimpour, F.; Coello, C.A.C. A spatial land-use planning support system based on game theory. Land Use Policy 2020, 99, 105013. [Google Scholar] [CrossRef]
- Masoumi, Z.; van Genderen, J.L.; Mesgari, M.S. Modelling and predicting the spatial dispersion of skin cancer considering environmental and socio-economic factors using a digital earth approach. Int. J. Dig. Earth 2020, 13, 661–682. [Google Scholar] [CrossRef]
- Ngo, P.T.T.; Panahi, M.; Khosravi, K.; Ghorbanzadeh, O.; Kariminejad, N.; Cerda, A.; Lee, S. Evaluation of deep learning algorithms for national scale landslide susceptibility mapping of Iran. Geosci. Front. 2021, 12, 505–519. [Google Scholar]
- Masoumi, Z.; Van Genderen, J.L.; Maleki, J. Fire Risk Assessment in Dense Urban Areas Using Information Fusion Techniques. ISPRS Int. J. Geo-Inf. 2019, 8, 579. [Google Scholar] [CrossRef] [Green Version]
- Dickson, M.E.; Perry, G.L.W. Identifying the controls on coastal cliff landslides using machine-learning approaches. Environ. Model. Softw. 2016, 76, 117–127. [Google Scholar] [CrossRef]
- Chen, W.; Pourghasemi, H.R.; Kornejady, A.; Zhang, N. Landslide spatial modeling: Introducing new ensembles of ANN, MaxEnt, and SVM machine learning techniques. Geoderma 2017, 305, 314–327. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R. Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region, Saudi Arabia. Geosci. Front. 2021, 12, 639–655. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Prakash, I.; Dholakia, M.B. Hybrid integration of Multilayer Perceptron Neural Networks and machine learning ensembles for landslide susceptibility assessment at Himalayan area (India) using GIS. Catena 2017, 149, 52–63. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Gayen, A.; Park, S.; Lee, C.W.; Lee, S. Assessment of landslide-prone areas and their zonation using logistic regression, logitboost, and naïvebayes machine-learning algorithms. Sustainability 2018, 10, 3697. [Google Scholar] [CrossRef] [Green Version]
- Kavzoglu, T.; Colkesen, I.; Sahin, E.K. Machine learning techniques in landslide susceptibility mapping: A survey and a case study. In Landslides: Theory, Practice and Modelling; Springer: Cham, Switzerland, 2019; pp. 283–301. [Google Scholar]
- Nguyen, V.V.; Pham, B.T.; Vu, B.T.; Prakash, I.; Jha, S.; Shahabi, H.; Shirzadi, A.; Ba, D.N.; Kumar, R.; Chatterjee, J.M.; et al. Hybrid machine learning approaches for landslide susceptibility modeling. Forests 2019, 10, 157. [Google Scholar] [CrossRef] [Green Version]
- Achour, Y.; Pourghasemi, R.H. How do machine learning techniques help in increasing accuracy of landslide susceptibility maps? Geosci. Front. 2020, 11, 871–883. [Google Scholar] [CrossRef]
- Di Napoli, M.; Carotenuto, F.; Cevasco, A.; Confuorto, P.; Di Martire, D.; Firpo, M.; Pepe, G.; Raso, E.; Calcaterra, D. Machine learning ensemble modelling as a tool to improve landslide susceptibility mapping reliability. Landslides 2020, 17, 1897–1914. [Google Scholar] [CrossRef]
- Huang, F.; Cao, Z.; Guo, J.; Jiang, S.H.; Li, S.; Guo, Z. Comparisons of heuristic, general statistical and machine learning models for landslide susceptibility prediction and mapping. Catena 2020, 191, 104580. [Google Scholar] [CrossRef]
- Orhan, O.; Bilgilioglu, S.S.; Kaya, Z.; Ozcan, A.K.; Bilgilioglu, H. Assessing and mapping landslide susceptibility using different machine learning methods. Geocarto Int. 2020, 1–26. [Google Scholar] [CrossRef]
- Ali, S.A.; Parvin, F.; Vojteková, J.; Costache, R.; Linh, N.T.T.; Pham, Q.B.; Vojtek, M.; Gigović, L.; Ahmad, A.; Ghorbani, M.A. GIS-based landslide susceptibility modeling: A comparison between fuzzy multi-criteria and machine learning algorithms. Geosci. Front. 2021, 12, 857–876. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H. Comparison of convolutional neural networks for landslide susceptibility mapping in Yanshan County, China. Sci. Total Environ. 2019, 666, 975–993. [Google Scholar] [CrossRef] [PubMed]
- Bui, D.T.; Tsangaratos, P.; Nguyen, V.-T.; Van Liem, N.; Trinh, P.T. Comparing the prediction performance of a Deep Learning Neural Network model with conventional machine learning models in landslide susceptibility assessment. Catena 2020, 188, 104426. [Google Scholar] [CrossRef]
- Van Dao, D.; Jaafari, A.; Bayat, M.; Mafi-Gholami, D.; Qi, C.; Moayedi, H.; Van Phong, T.; Ly, H.B.; Le, T.T.; Trinh, P.T.; et al. A spatially explicit deep learning neural network model for the prediction of landslide susceptibility. Catena 2020, 188, 104451. [Google Scholar]
- Mandal, K.; Saha, S.; Mandal, S. Applying deep learning and benchmark machine learning algorithms for landslide susceptibility modelling in Rorachu river basin of Sikkim Himalaya, India. Geosci. Front. 2021, 12, 101203. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Teke, A.; Yilmaz, E.O. Shared Blocks-Based Ensemble Deep Learning for Shallow Landslide Susceptibility Mapping. Remote Sens. 2021, 13, 4776. [Google Scholar] [CrossRef]
- Gupta, S.K.; Shukla, D.P.; Thakur, M. Selection of weightages for causative factors used in preparation of landslide susceptibility zonation (LSZ). Geomat. Nat. Hazards Risk 2018, 9, 471–487. [Google Scholar] [CrossRef] [Green Version]
- Lombardo, L.; Mai, M. Presenting logistic regression-based landslide susceptibility results. Eng. Geol. 2018, 244, 14–24. [Google Scholar] [CrossRef]
- Zhou, C.; Yin, K.; Cao, Y.; Ahmed, B.; Li, Y.; Catani, F.; Pourghasemi, H.R. Landslide susceptibility modeling applying machine learning methods: A case study from Longju in the Three Gorges Reservoir area, China. Comput. Geosci. 2018, 112, 23–37. [Google Scholar] [CrossRef] [Green Version]
- Yilmaz, I. Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: A case study from Kat landslides (Tokat—Turkey). Comput. Geosci. 2009, 35, 1125–1138. [Google Scholar] [CrossRef]
- Dou, J.; Bui, D.T.; Yunus, A.P.; Jia, K.; Song, X.; Revhaug, I.; Xia, H.; Zhu, Z. Optimization of causative factors for landslide susceptibility evaluation using remote sensing and GIS data in parts of Niigata, Japan. PLoS ONE 2015, 10, e0133262. [Google Scholar] [CrossRef] [Green Version]
- Kornejady, A.; Ownegh, M.; Bahremand, A. Landslide susceptibility assessment using maximum entropy model with two different data sampling methods. Catena 2017, 152, 144–162. [Google Scholar] [CrossRef]
- Van Westen, C.J.; Castellanos, E.; Kuriakose, S.L. Spatial data for landslide susceptibility, hazard, and vulnerability assessment: An overview. Eng. Geol. 2008, 102, 112–131. [Google Scholar] [CrossRef]
- Pradhan, A.M.; Kang, H.S.; Kim, K.Y. Mapping Climate Change, Landslide Hazards, and Vulnerability: A Case Study from Seoul, South Korea. In Proceedings of the Geotechnical and Structural Engineering Congress 2016, Phoenix, AZ, USA, 14–17 February 2016. [Google Scholar]
- Ilia, I.; Tsangaratos, P. Applying weight of evidence method and sensitivity analysis to produce a landslide susceptibility map. Landslides 2016, 13, 379–397. [Google Scholar] [CrossRef]
- Li, G.; West, A.; Densmore, A.L.; Jin, Z.; Zhang, F.; Wang, J.; Hilton, R.G. Distribution of earthquake-triggered landslides across landscapes: Towards understanding erosional agency and cascading hazards. In Fault-Zone Guided Wave, Ground Motion, Landslide and Earthquake Forecast; De Gruyter: Berlin, Germany, 2018; pp. 160–190. [Google Scholar]
- Haigh, M.; Rawat, J.S. Landslide Disasters: Seeking Causes—A Case Study from Uttarakhand, India. In Management of Mountain Watersheds; Springer: Dordrecht, The Netherlands, 2012; pp. 218–253. [Google Scholar]
- Dar, I.A.; Sankar, K.; Dar, M.A. Remote sensing technology and geographic information system modeling: An integrated approach towards themapping of groundwater potential zones in Hardrock terrain, Mamundiyar basin. J. Hydrol. 2010, 394, 285–295. [Google Scholar] [CrossRef]
- Magesh, N.S.; Chandrasekar, N.; Soundranayagam, J.P. Delineation of groundwater potential zones in Theni district, Tamil Nadu, using remote sensing, GIS and MIF techniques. Geosci. Front. 2012, 3, 189–196. [Google Scholar] [CrossRef] [Green Version]
- Boualla, O.; Mehdi, K.; Fadili, A.; Makan, A.; Zourarah, B. GIS-based landslide susceptibility mapping in the Safi region, West Morocco. Bull. Eng. Geo. Environ. 2019, 78, 2009–2026. [Google Scholar] [CrossRef]
- Zhao, P.; Kwan, M.P.; Zhou, S. The uncertain geographic context problem in the analysis of the relationships between obesity and the built environment in Guangzhou. Int. J. Environ. Res. Public Health 2018, 15, 308. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Feng, L.; Li, S.; Ren, F.; Du, Q. A hybrid model considering spatial heterogeneity for landslide susceptibility mapping in Zhejiang Province, China. Catena 2020, 188, 104425. [Google Scholar] [CrossRef]
- Guzzetti, F.; Mondini, A.C.; Cardinali, M.; Fiorucci, F.; Santangelo, M.; Chang, K.-T. Landslide inventory maps: New tools for an old problem. Earth-Sci. Rev. 2012, 112, 42–66. [Google Scholar] [CrossRef] [Green Version]
- Cabrera, A.F. Logistic regression analysis in higher education: An applied perspective. In Higher Education: Handbook of Theory and Research; Springer: Cham, Switzerland, 1994; Volume 10, pp. 225–256. [Google Scholar]
- Lee, S.; Ryu, J.H.; Won, J.S.; Park, H.J. Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Eng. Geol. 2004, 71, 289–302. [Google Scholar] [CrossRef]
- Can, R.; Kocaman, S.; Gokceoglu, C. A Convolutional Neural Network Architecture for Auto-Detection of Landslide Photographs to Assess Citizen Science and Volunteered Geographic Information Data Quality. ISPRS Int. J. Geo-Inf. 2019, 8, 300. [Google Scholar] [CrossRef] [Green Version]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Minh, V.Q. Assessment of Sentinel-1A data for rice crop classification using random forests and support vector machines. Geocarto Int. 2018, 33, 587–601. [Google Scholar] [CrossRef]
- Pun, L.; Zhao, P.; Liu, X. A multiple regression approach for traffic flow estimation. IEEE Access 2019, 7, 35998–36009. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.X.; Chen, W. Application of fuzzy weight of evidence and data mining techniques in construction of flood susceptibility map of Poyang County, China. Sci. Total Environ. 2018, 625, 575–588. [Google Scholar] [CrossRef]
- Xu, L.; Li, J.; Brenning, A. A comparative study of different classification techniques for marine oil spill identification using RADARSAT-1 imagery. Remote Sens. Environ. 2014, 141, 14–23. [Google Scholar] [CrossRef]
- Hagenauer, J.; Helbich, M. A comparative study of machine learning classifiers for modeling travel mode choice. Expert Syst. Appl. 2017, 78, 273–282. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gregorutti, B.; Michel, B.; Saint-Pierre, P. Correlation and variable importance in random forests. Stat. Comput. 2017, 27, 659–678. [Google Scholar] [CrossRef] [Green Version]
- Kumar, I.E.; Venkatasubramanian, S.; Scheidegger, C.; Friedler, S. Problems with Shapley-value-based explanations as feature importance measures. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 5491–5500. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Information | Related Factor Maps | Source | Scale/Resolution |
|---|---|---|---|
| Digital Elevation Model (DEM) | Altitude, Aspect, Slope, Plan curvature, Profile curvature | National Cartographic Center of Iran | 1:25,000 |
| Lithology | Lithology | Geological Survey & Mineral Explorations of Iran (GSI)/Land sat8 images | 1: 50,000 30 m |
| Land use | Land use | National Cartographic Center of Iran/Land sat8 images | 1:25,000 30 m |
| Faults | Distance from faults | Institute for Advanced Studies in Basic Sciences | 1:50,000 |
| Rivers | Distance from river | National Cartographic Center of Iran (NCC) | 1:25,000 |
| Roads | Distance from roads | NCC | 1:25,000 |
| Springs | Distance from springs | Zanjan regional water company | 1:10,000 |
| NDVI | NDVI | Sentinel 2 satellite images | 10 m |
| Lineament density | Lineament density | Sentinel 2 satellite images/DEM | 10 m |
| Precipitation | Precipitation | Zanjan regional water company/Iran Meteorological Organization | 1:10,000 |
| Measures/Methods | LR | ANN | SVM | RF | CNN |
|---|---|---|---|---|---|
| TP | 624 | 631 | 626 | 648 | 635 |
| TN | 969 | 957 | 962 | 962 | 965 |
| FP | 133 | 126 | 131 | 109 | 122 |
| FN | 14 | 26 | 21 | 21 | 18 |
| Precision | 82.43% | 83.36% | 82.69% | 85.6% | 83.88% |
| Recall | 97.8% | 96.04% | 96.75% | 96.86% | 97.24% |
| Specificity | 87.93% | 88.37% | 88.01% | 89.82% | 88.78% |
| Accuracy | 91.55% | 91.26% | 91.26% | 92.53% | 91.95% |
| F1-measure | 89.46% | 89.25% | 89.17% | 90.88% | 90.07% |
| Methods | LR | ANN | SVM | RF | CNN |
|---|---|---|---|---|---|
| Top-5 most important features | Slope | Slope | Slope | Slope | Slope |
| Curvature | Curvature | Curvature | Curvature | Curvature | |
| Land use | Land use | Geology | Geology | Geology | |
| Precipitation | Geology | Land use | Lineament density | River density | |
| NDVI | Precipitation | NDVI | Precipitation | Precipitation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, P.; Masoumi, Z.; Kalantari, M.; Aflaki, M.; Mansourian, A. A GIS-Based Landslide Susceptibility Mapping and Variable Importance Analysis Using Artificial Intelligent Training-Based Methods. Remote Sens. 2022, 14, 211. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14010211
Zhao P, Masoumi Z, Kalantari M, Aflaki M, Mansourian A. A GIS-Based Landslide Susceptibility Mapping and Variable Importance Analysis Using Artificial Intelligent Training-Based Methods. Remote Sensing. 2022; 14(1):211. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14010211
Chicago/Turabian StyleZhao, Pengxiang, Zohreh Masoumi, Maryam Kalantari, Mahtab Aflaki, and Ali Mansourian. 2022. "A GIS-Based Landslide Susceptibility Mapping and Variable Importance Analysis Using Artificial Intelligent Training-Based Methods" Remote Sensing 14, no. 1: 211. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14010211