
Machine-Learning Classification of SAR Remotely-Sensed Sea-Surface Petroleum Signatures—Part 1: Training and Testing Cross Validation



Abstract
:1. Introduction
2. Methods and Materials
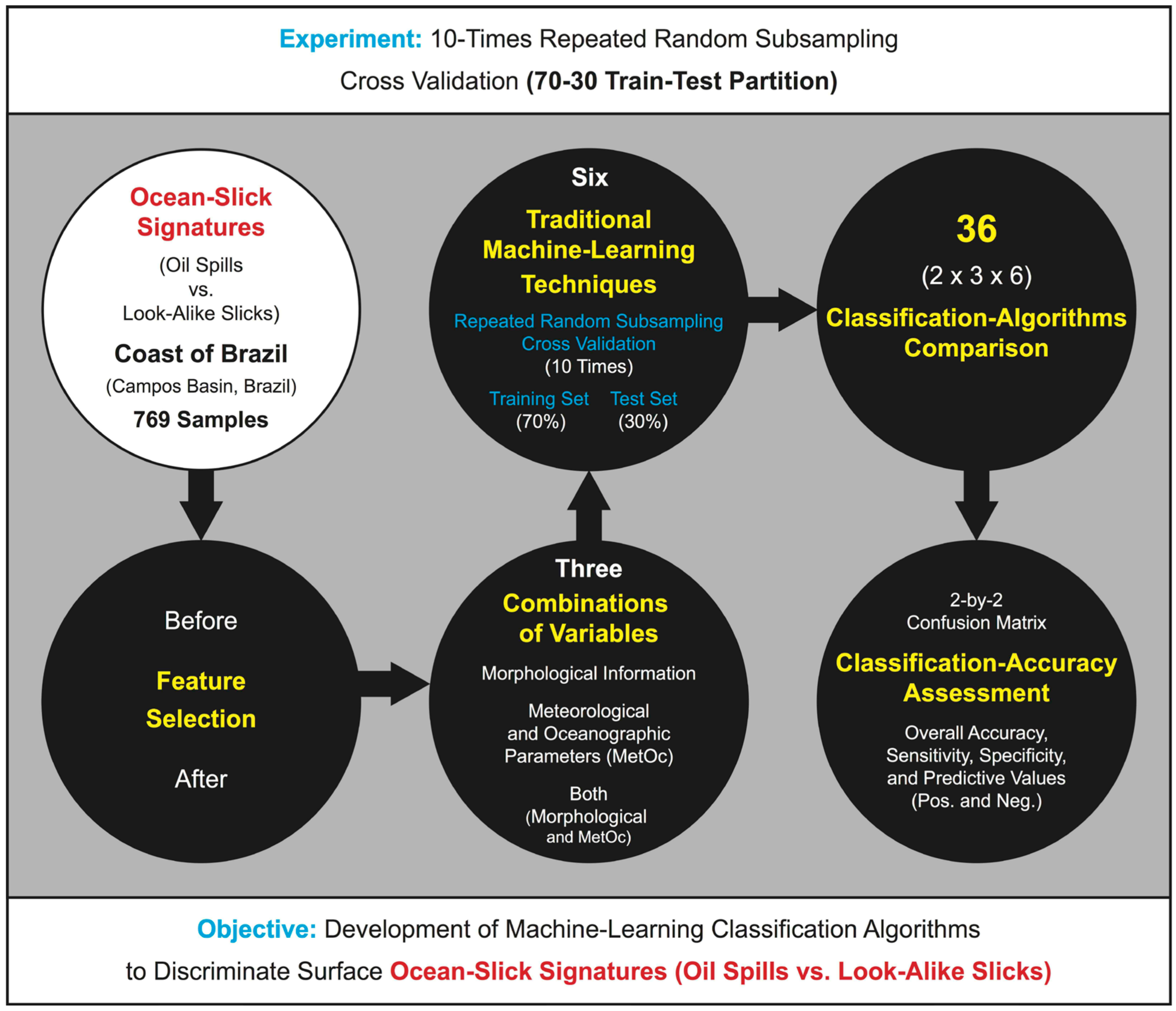
2.1. Research Strategy of Our Training and Testing Experiment
2.1.1. Stage 1: Feature Selection
- -
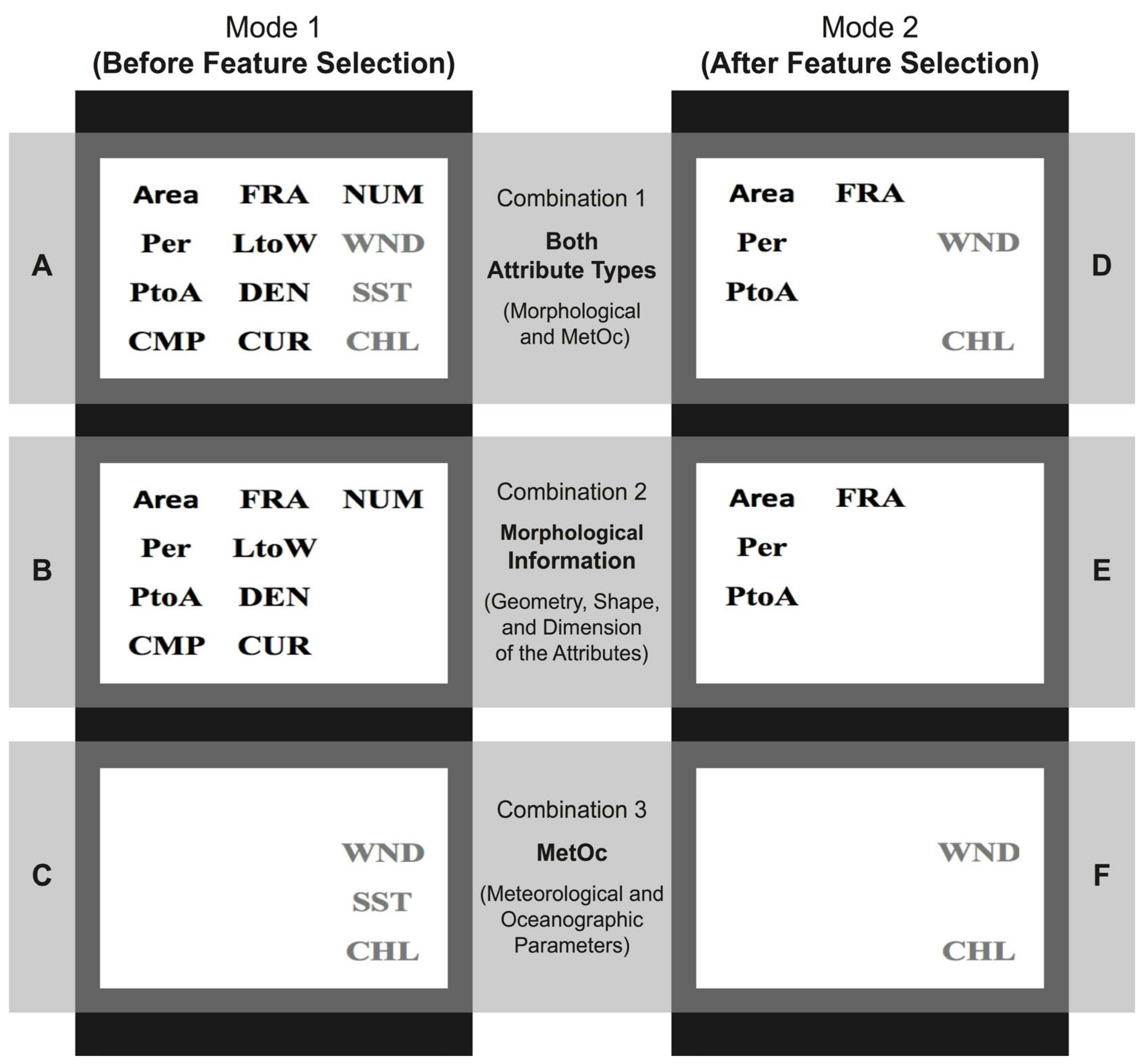
- Mode 1: Before feature selection; and
- -
- Mode 2: After feature selection.
2.1.2. Stage 2: Combinations of Variables
- -
- Combination 1: Both attribute types together;
- -
- Combination 2: Only morphological information; and
- -
- Combination 3: Only MetOc parameters.
2.1.3. Stage 3: Traditional Machine-Learning (ML) Classification Techniques
- -
- Naive Bayes (NB);
- -
- K-nearest neighbor (KNN);
- -
- Decision tree (DT);
- -
- Random forest (RF);
- -
- Support vector machine (SVM); and
- -
- Artificial neural network (ANN).
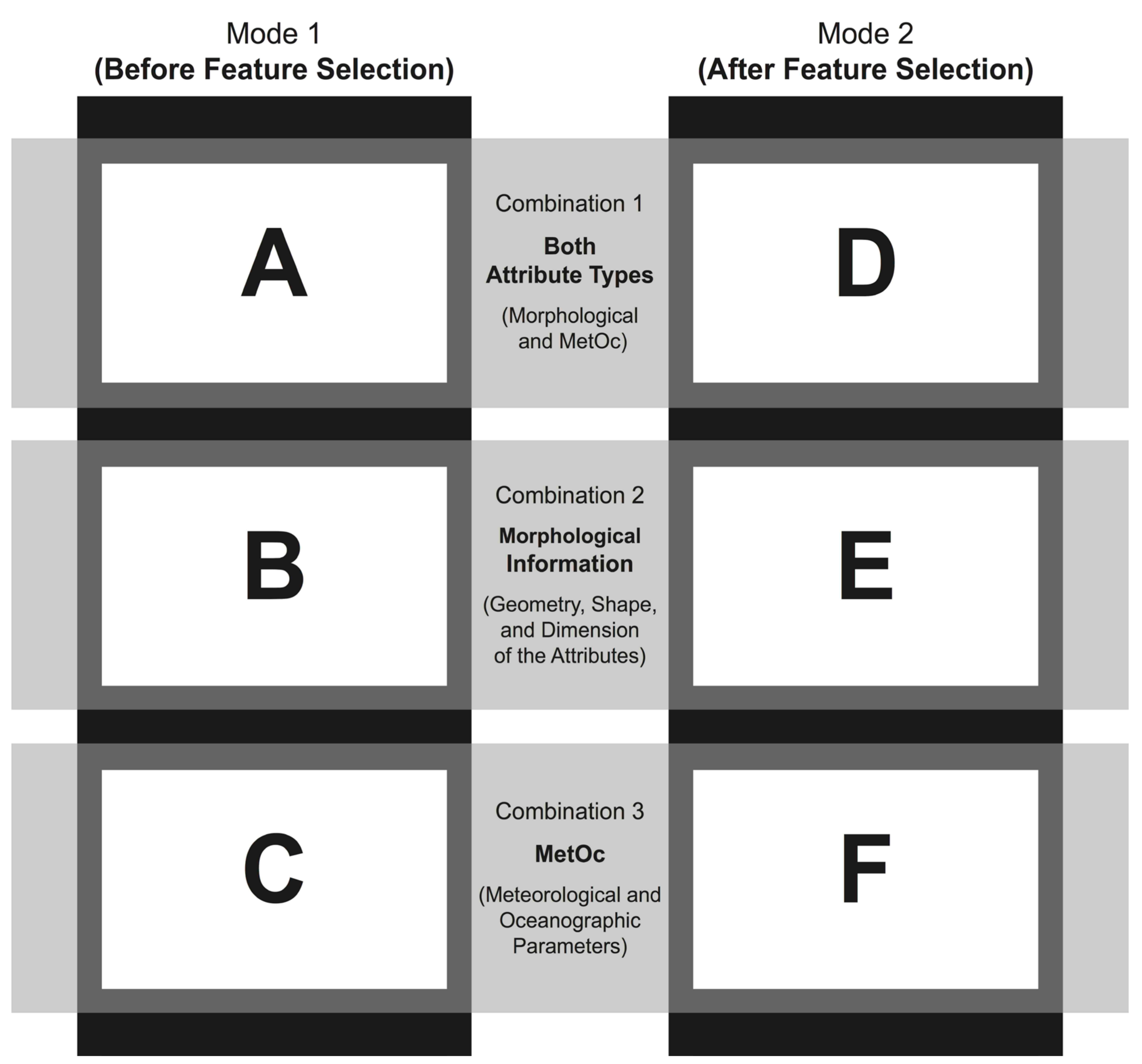
2.1.4. Stage 4: Classification-Algorithms Comparison
- -
- Variable Set A: Mode 1 and Combination 1 (Figure 2A);
- -
- Variable Set B: Mode 1 and Combination 2 (Figure 2B);
- -
- Variable Set C: Mode 1 and Combination 3 (Figure 2C);
- -
- Variable Set D: Mode 2 and Combination 1 (Figure 2D);
- -
- Variable Set E: Mode 2 and Combination 2 (Figure 2E); and
- -
- Variable Set F: Mode 2 and Combination 3 (Figure 2F).
- -
- Primary comparison level: The six techniques were compared among themselves six times using the same set of attributes, i.e., six variable sets (white boxes in Figure 2: A, B, C, D, E, and F);
- -
- Secondary comparison level: Each technique was compared using different sets of attributes three times before and three times after feature selection (vertical black boxes in Figure 2: A-B-C and D-E-F, respectively); and
- -
- Tertiary comparison level: Every technique was compared using different sets of attributes two times per combination of variables (horizontal gray boxes in Figure 2: A-D, B-E, and C-F, respectively).
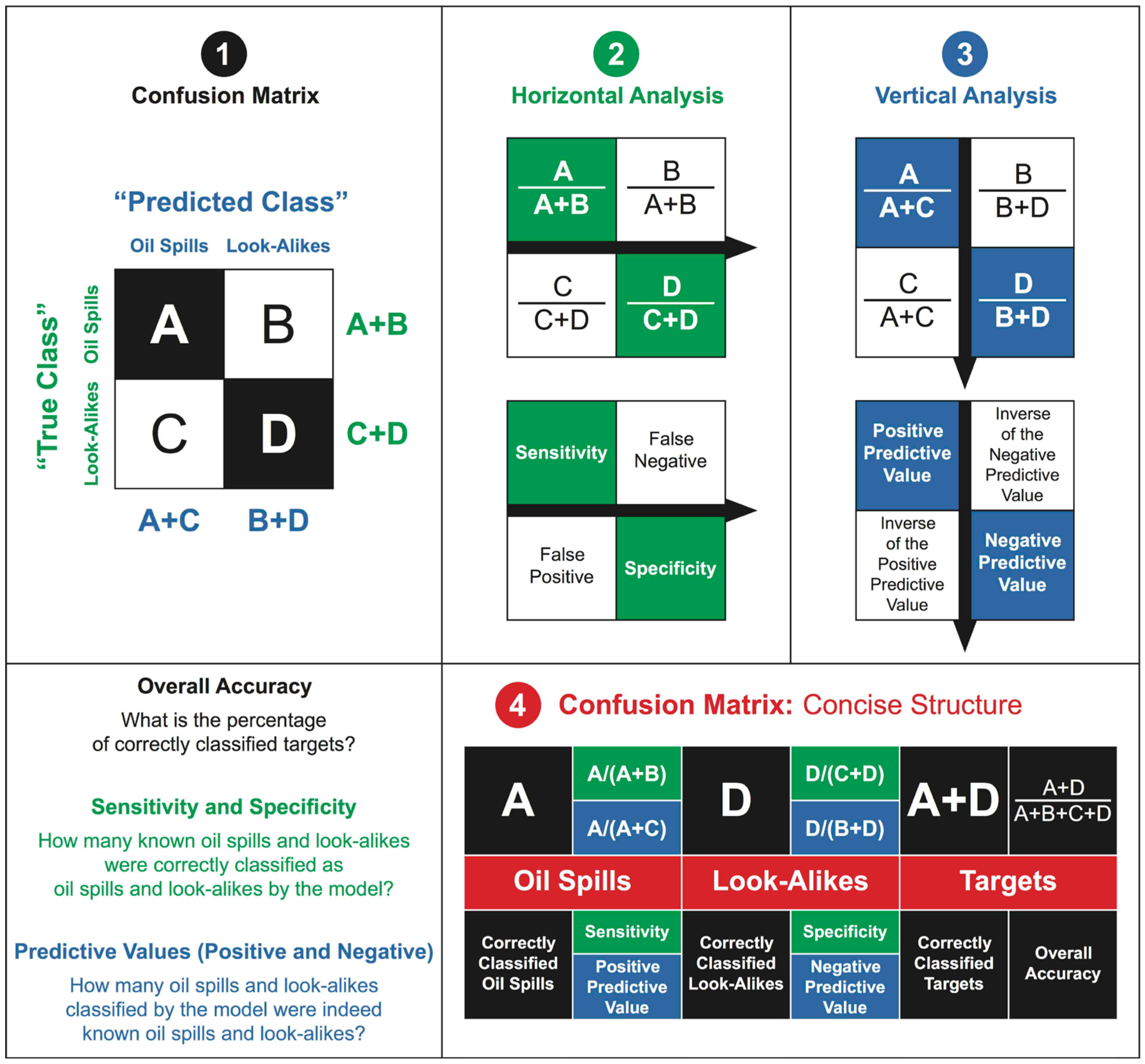
2.1.5. Stage 5: Classification-Accuracy Assessment
2.2. Database
2.2.1. Train-Test Set (769 Samples)
2.2.2. Satellite Sensors
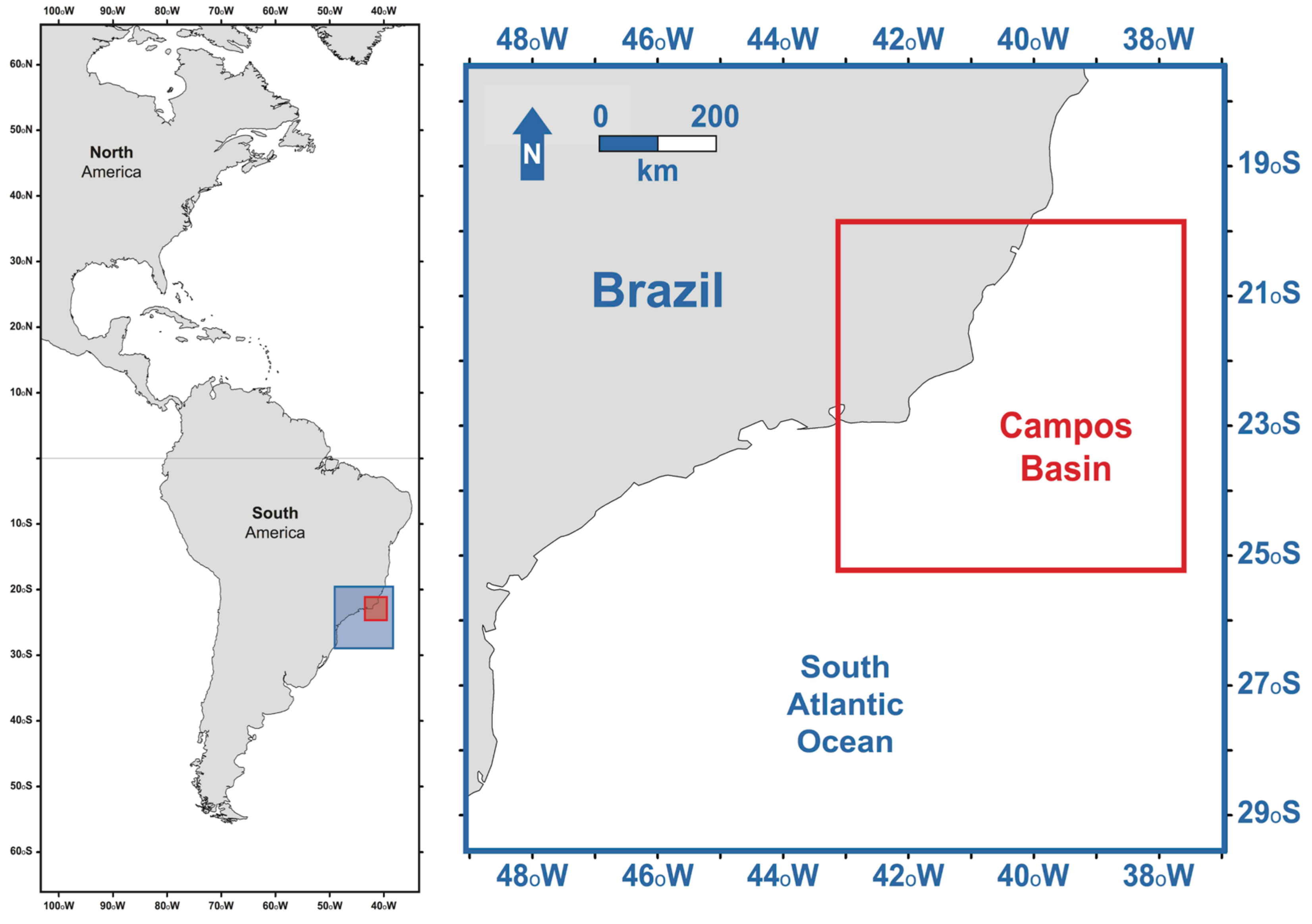
2.3. Regions of Interest
2.4. Machine-Learning (ML) Methods
2.4.1. Performance Benchmark
- -
- Linear Discriminant Analysis (LDA): This is one of the simplest, long-established techniques widely used for classification problems [40,72]. LDAs focus on maximizing the separability between the known classes by computing a set of discriminant functions and thus allocating a sample to the class of maximum function value. Although several LDA extensions and variations exist (e.g., flexible, global-local, quadratic, dual-space, null-space, regularized, penalized, probabilistic, etc.), the considered one is the regular LDA derived from the Fisher LDA—in which only linear combinations of inputs are used [26].
- -
- Past LDA Papers: Carvalho et al. [31,32] published LDA analyses to classify spills from look-alikes. Even though these past studies used the same dataset used here (Section 2.2), they did not carry out cross validation and all samples were used in their training phase. While Carvalho et al. [31] used all 769 samples, Carvalho et al. [32] performed quality-control filters and only used 560 samples. They exploited various combinations of variables using morphological information and MetOc parameters: Carvalho et al. [31,32] compared 39 and 114 combinations of variables, respectively; these included the application of different data transformations (i.e., log10 and cube root). Their best non-transformed overall-accuracy LDA results, using the same combinations of variables to those defined here in Section 2.1.2 (i.e., both types together, only morphological information, and only MetOc parameters), are taken as our benchmark. These are shown in Table 1: ~83% with morphological and MetOc attributes, ~79% only morphological information, ~77% only MetOc parameters. When other combinations, using aspects of morphological and MetOc attributes, were used, a slightly improved overall accuracy of ~84% was reached ([31]), and further progress was possible when a Geo-Loc attribute (bathymetry) was accounted for: ~85% ([32]). The other four performance metrics ranged between ~73% and ~91% (Table 1).
2.4.2. Simple Techniques
- -
- Naive Bayes (NB): This simple technique is derived from the application of Bayes’ theorem of posterior probability—it is often named as naive Bayes (NB). Bayesian classifiers often outperform, or are comparable in performance to, more powerful classifiers and are faster in terms of computer time [73]. The class membership probabilities are predicted by a given sample belonging to a specific class. In this technique, it is assumed that the influence of the values of the variables on any class does not affect the values of the other variables—this is known as class conditional independence [39]. Indeed, because of the assumption that the variables are independent of the classes, the application of the Bayes’ theorem is considered “naive” [39].
- -
- K-Nearest Neighbor (KNN): This method works as follows: in the attributes n-dimensional space, it seeks the k closest samples among all existing samples, i.e., each time it predicts a new sample, it searches the “nearest neighbor” in the entire dataset used for training [40,74]. The value of k, the number of neighbors, used here was 5. The measure of closeness is given by a metric distance, e.g., Euclidean distance. Different from all other methods analyzed here, KNN is regarded a “lazy learner”, mostly because it creates numerous local target function approximations making them slower and only able to generalize once needed, as opposed to the other five techniques that are “eager learners”, as they create a global approximation and can generalize before a query is given [39].
- -
- Decision Tree (DT): Decision trees are tree-structure flowcharts. In this top-down recursive tree-induction method, the internal nodes (i.e., non-leaf nodes) indicate tests per attribute and the tree branches correspond to the test outcomes. Terminal nodes (i.e., leaf nodes) represent the predicted class label, while the uppermost node is known as the root node [39].
2.4.3. Advanced Techniques
- -
- Random Forest (RF): This technique is one of the many types of ensemble methods, i.e., it combines the learning from a series of other individual methods [75]. RFs can be considered as a collection of DTs, which gives rise to the name “forest”, with a flowchart-like tree structure [76,77]. In simple terms, each of these DTs start with a “random” choice of variable, and the chosen class of each sample is given by the vote of each DT.
- -
- Support Vector Machine (SVM): This technique can classify any sort of data, i.e., both linear and nonlinear, with a smaller chance of suffering from overfitting than other methods [39]. This non-tree-based classifier transforms the original data into a higher dimension level to search for a unique and optimal hyperplane, i.e., a linear decision boundary [78]. This hyperplane separates the classes in this new multidimensional feature space, and, in general terms, this separates the data by using selected essential training samples—the so-called “support vectors” [79]. From these vectors, the maximal margin between the two classes is defined [80,81]. There is a compromise between reaching high accuracies and long processing times [82]. Other reference sources are: Cherkassky and Ma [83], for the selection of hyper-parameter settings, and Mountrakis et al. [84], for broad review of remote-sensing data SVM applications.
- -
- Artificial Neural Network (ANN): ANNs, commonly referred to as “neural networks”, try to mimic the way human “neurons” connect to each other [39]. This neuron-like process consists of several node layers made of two units: input unit (input layer) and output unit (this output layer may contains one or more in-between hidden layers—neurodes) [85]. A multilayer ANN with a single hidden layer is said to be a two-layer network—the input layer is not counted because it only delivers the input information [39]. The network nodes, also known as “artificial neurons”, have an organized, developed structure and are fully interconnected—when one node feeds the next node, weights and thresholds are associated with the passing of information at each connection [39]. While the input corresponds to the values of the attributes used in the training samples, the output is the prediction for those samples [39]. The ANN learns from these connections while it adjusts the weights, so it is able to predict the class label of each sample. This ANN learning process is known as connectionist learning [39]. Even though ANNs are capable of handling noisy data, they usually have long run times, have a long list of required hyper-parameter settings, and are difficult to interpret, as compared to other advanced techniques, e.g., SVM [71].
2.5. Algorithms’ Accuracies
3. Results
3.1. Feature Selection (Stage 1)
3.2. Combinations of Variables (Stage 2)
3.3. Classification-Accuracy Assessment (Stage 5)
3.3.1. Primary Comparison Level
- -
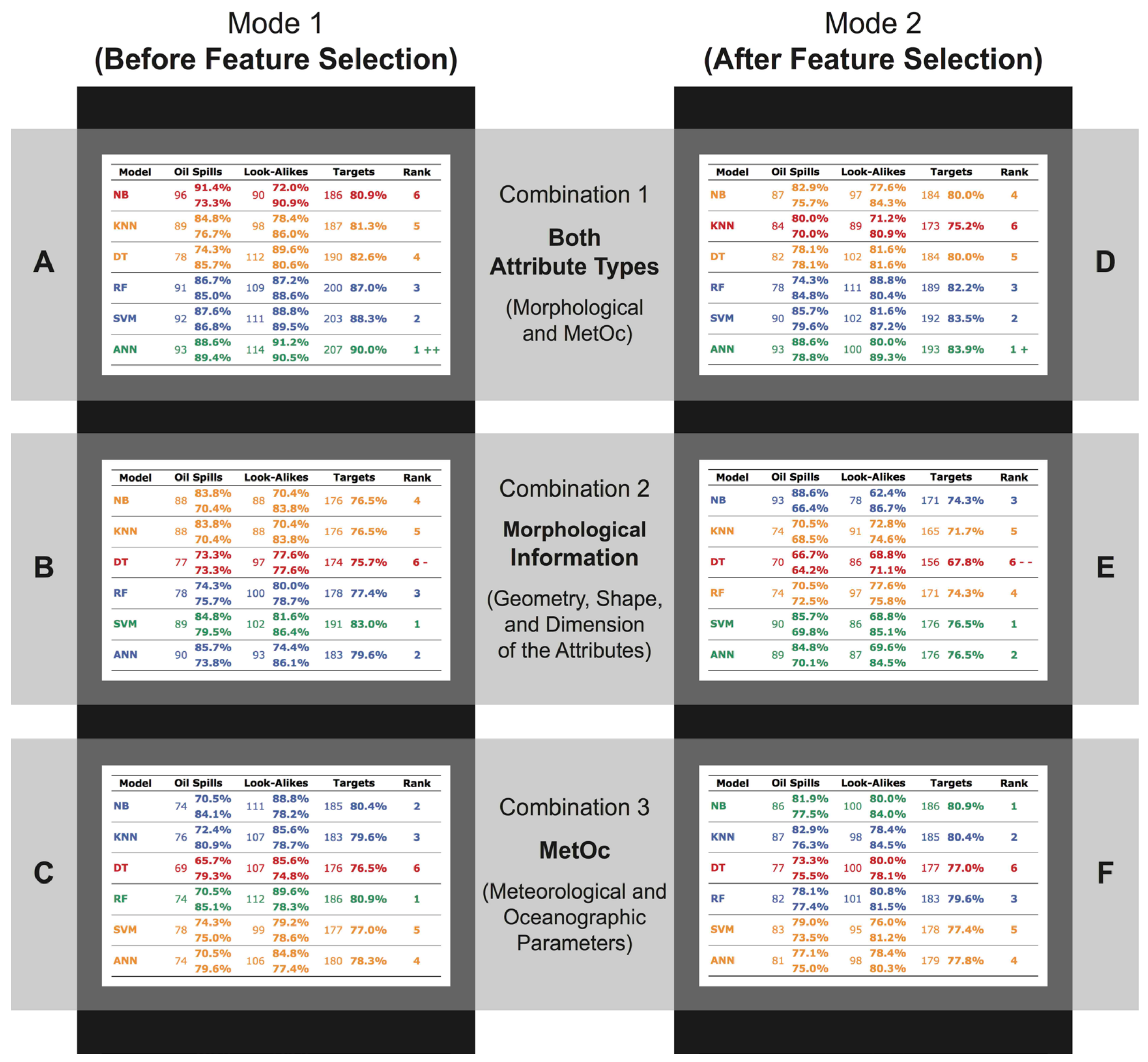
- Variable Set A: Figure 6A shows the results of using all twelve variables without feature selection: Area, Per, PtoA, CMP, FRA, LtoW, DEN, CUR, NUM, WND, SST, and CHL (Figure 5A: variable set A). ANN achieved the best accuracy (90%), which was also the most accurate of all 36 algorithms (shown by ++). Such accuracy outperformed the least accurate algorithm in this level by 9.1 percentage points: NB (80.9%). This was the largest overall-accuracy difference between the best and worst accuracy per variable set (Figure 7).
- -
- Variable Set B: Figure 6B shows the results of using the nine pieces of morphological information prior to feature selection: Area, Per, PtoA, CMP, FRA, LtoW, DEN, CUR, and NUM (Figure 5B: variable set B). SVM was the most accurate algorithm (83%) outperforming the least accurate one by 7.4 percentage points: DT (75.7%).
- -
- Variable Set C: Figure 6C shows the results of using the three MetOc parameters before feature selection: WND, SST, and CHL (Figure 5C: variable set C). RF reached the highest accuracy (~81%) with 4.3 percentage points from the least accurate: DT (76.5%). This overall-accuracy difference was one of the smallest of all variable sets (Figure 7).
- -
- Variable Set D: Figure 6D illustrates the outcomes of using the six feature-selected attributes from both attribute types: PtoA, Area, WND, Per, FRA, and CHL (Figure 5D: variable set D). As in Figure 6A, ANN was the most accurate algorithm (~84%). This top accuracy is not just for this specific variable set, but was also the highest accuracy among all variable sets that used feature-selected variables (Figure 7). As shown, feature selection reduced the accuracy by ~6 percentage points.
- -
- Variable Set E: Figure 6E shows the outcomes of using the four feature-selected morphological information: PtoA, Area, Per, and FRA (Figure 5E: variable set E). SVM and ANN tied as the most successful algorithms at ~76% but this was the lowest of all best accuracies within all six variable sets. The least accurate algorithm was DT (~68%), which was also the least accurate of all 36 algorithms (indicated by −−).
- -
- Variable Set F: Figure 6F illustrates the outcomes of using the two feature-selected MetOc parameters: WND and CHL (Figure 5F: variable set F). This was the only case in which a simple technique outperformed the advanced ones: NB reached the highest accuracy (~81%) at 3.9 percentage points above the least-accurate simple technique: DT (77%). This was the smallest overall-accuracy difference between the best and worst classifiers (Figure 7).
3.3.2. Secondary Comparison Level
- -
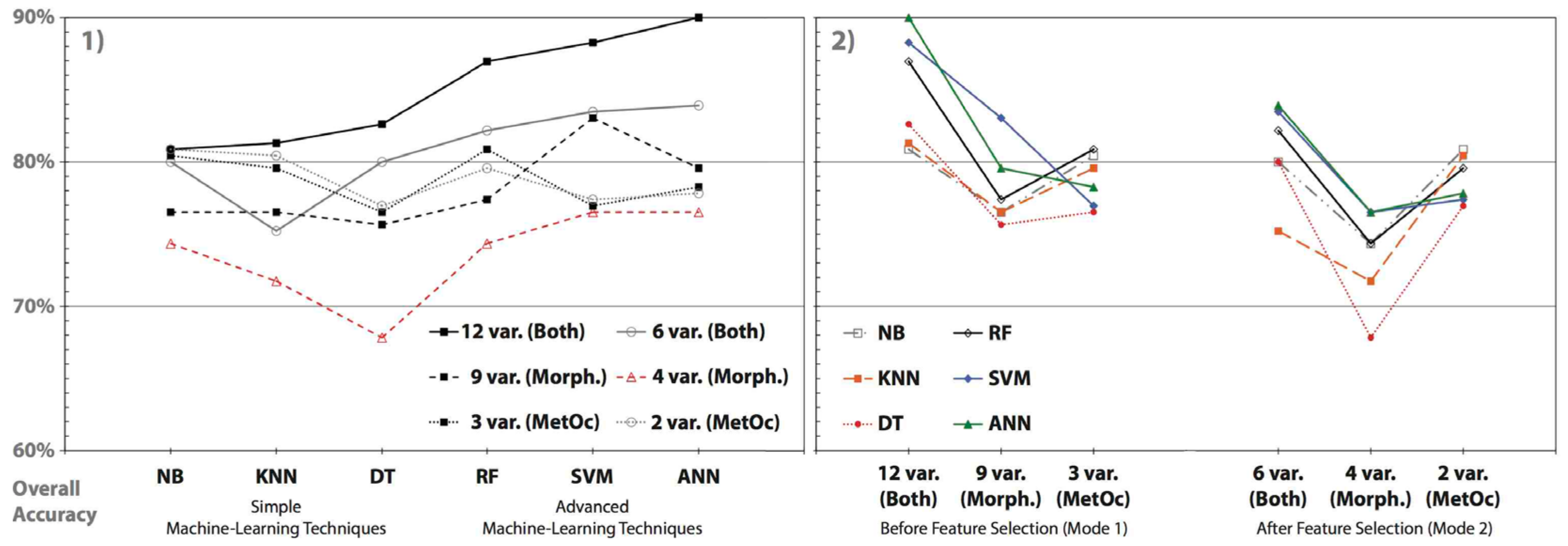
- Mode 1 (Before Feature Selection): Most techniques (NB, KNN, DT, and RF) were more accurate when all variables of both attribute types were used (Combination 1) and performed worse with morphological information (Combination 2); Figure 7. However, two advanced techniques (SVM and ANN) were best when using all variables of both attribute types (Combination 1), but were less accurate with MetOc parameters (Combination 3).
- -
- Mode 2 (After Feature Selection): The pattern observed above was also frequent in most techniques (DT, RF, SVM, and ANN); Figure 7. These were also more accurate when exploiting variables from both types (Combination 1) and were also less accurate when accounting for morphological information (Combination 2). Here, two simple techniques (NB and KNN) deviated from this pattern and were more accurate with MetOc parameters (Combination 3) and less accurate with morphological information (Combination 2).
3.3.3. Tertiary Comparison Level
- -
- Combination 1 (Both Attribute Types): the six techniques were more accurate before (A) than after (D) feature selection. The variable set A provided the best of all 36 algorithms: ANN (90%)—indicated in Figure 6A by ++. The overall-accuracy difference between the best and worst algorithms within A, and well as D, was about ~9%.
- -
- Combination 2 (Morphological Information): without exception all six algorithms performed better before (B) than after (E) feature selection. The variable set E provided the worst performance of all 36 algorithms: DT (~68%) indicated by −− in Figure 6E. As in Combination 1, the overall-accuracy difference between the best and worst algorithms within B, and well as E, were also about ~9%.
- -
- Combination 3 (MetOc Parameters): Only RF and ANN better performed before feature selection (C) than after (F), as this pattern was inverted for the other ML methods that reached improved outcomes with fewer variables (after feature selection: F) than with more variables (before feature selection: C). In both variable sets (C and F), the algorithms produced the smallest overall-accuracy differences between the best and worst algorithms of all (~4%); about half of those from the other four variable sets, i.e., A, B, D, and E.
3.4. LDA Benchmark Comparison
- -
- LDA 1 (83.1%): This is analogous to those using variable set A (Mode 1 and Combination 1), and was outperformed by all advanced techniques (RF (87.0%), SVM (88.3%), and ANN (90.0%)) but was more effective than all simple ones (NB (80.9%), KNN (81.3%), and DT (82.6%)).
- -
- LDA 2 (79.1%): This used variable set B (Mode 1 and Combination 2) and was only inferior to SVM (83.0%) and ANN (79.6%); but other algorithms were less accurate.
- -
- LDA 3 (76.9%): This algorithm matched variable set C (Mode 1 and Combination 3) but performed worse than all algorithms except DT (76.5%).
- -
- LDA 4 (83.7%): This was the best of all 39 combinations reported by Carvalho et al. [31], also using variables from both attribute types, and performed better than 34 of our algorithms, besides the ones that were better than LDA 1 and ANN with both attribute types after feature selection (83.9%).
- -
- LDA 5 (84.6%): Carvalho et al. [32] were able to improve the LDA accuracy by combining the two attribute types with a Geo-Loc attribute (bathymetry). They explored 114 different combinations of variables.
4. Discussion
5. Summary and Conclusions
- -
- Primary: techniques compared among themselves;
- -
- Secondary: techniques compared using different types of attributes: before (Mode 1) and after (Mode 2) feature selection; and
- -
- Tertiary: techniques compared using different types of attributes: both types together (Combination 1), morphological information (Combination 2), and MetOc parameters (Combination 3).
5.1. Primary Comparison Level
- -
- Mode 1 and Combination 1 (all twelve attributes): 90% (ANN) and ~81% (NB);
- -
- Mode 1 and Combination 2 (all nine pieces of morphological information): 89% (SVM) and ~76% (DT);
- -
- Mode 1 and Combination 3 (all three MetOc parameters): ~81% (RF) and 76.5% (DT);
- -
- Mode 2 and Combination 1 (only the the six feature-selected attributes): ~84% (ANN) an ~75% (KNN);
- -
- Mode 2 and Combination 2 (only the four pieces of feature-selected morphological information): 76.5% (SVM and ANN) and ~68% (DT); and
- -
- Mode 2 and Combination 3 (only the two feature-selected MetOc parameters): ~81% (NB) and 77% (DT).
5.2. Secondary Comparison Level
5.3. Tertiary Comparison Level
5.4. LDA Benchmark Comparison
5.5. Concluding Remarks
5.6. Suggestions for Future Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- MacDonald, I.R.; Garcia-Pineda, O.; Beet, A.; Daneshgar Asl, S.; Feng, L.; Graettinger, G.; French-McCay, D.; Holmes, J.; Hu, C.; Huffer, F.; et al. Natural and Unnatural Oil Slicks in the Gulf of Mexico. J. Geophys. Res. Ocean. 2015, 120, 8364–8380. [Google Scholar] [CrossRef] [PubMed]
- Leifer, I.; Lehr, W.J.; Simecek-Beatty, D.; Bradley, E.; Clark, R.; Dennison, P.; Hu, Y.; Matheson, S.; Jones, C.E.; Holt, B.; et al. Review—State of the Art Satellite and Airborne Marine Oil Spill Remote Sensing: Application to the BP Deepwater Horizon Oil Spill. Remote Sens. Environ. 2012, 124, 185–209. [Google Scholar] [CrossRef] [Green Version]
- Kennicutt, M.C. Oil and Gas Seeps in the Gulf of Mexico. In Habitats and Biota of the Gulf of Mexico: Before the Deepwater Horizon Oil Spill; Ward, C., Ed.; Springer: New York, NY, USA, 2017; Chapter 5; p. 868. [Google Scholar] [CrossRef] [Green Version]
- Alpers, W.; Huhnerfuss, H. The Damping of Ocean Waves by Surface Films: A New Look at an Old Problem. J. Geophys. Res. Ocean. 1989, 94, 6251–6265. [Google Scholar] [CrossRef]
- API (American Petroleum Institute). Remote Sensing in Support of Oil Spill Response: Planning Guidance; Technical Report No. 1144; American Petroleum Institute: Washington, DC, USA, 2013; 80p, Available online: https://www.oilspillprevention.org/-/media/Oil-Spill-Prevention/spillprevention/r-and-d/oil-sensing-and-tracking/1144-e1-final.pdf (accessed on 16 April 2022).
- Smith, L.C., Jr.; Smith, M.; Ashcroft, P. Analysis of Environmental and Economic Damages from British Petroleum’s Deepwater Horizon Oil Spill. Albany Law Rev. 2011, 74, 563–585. [Google Scholar] [CrossRef] [Green Version]
- Jernelov, A. The Threats from Oil Spills: Now, Then, and in the Future. AMBIO 2010, 39, 353–366. [Google Scholar] [CrossRef] [Green Version]
- Brown, C.E.; Fingas, M. New Space-Borne Sensors for Oil Spill Response. In Proceedings of the International Oil Spill Conference; American Petroleum Institute: Washington, DC, USA, 2001; pp. 911–916. [Google Scholar]
- Brown, C.E.; Fingas, M. The Latest Developments in Remote Sensing Technology for Oil Spill Detection. In Proceedings of the Interspill Conference and Exhibition, Marseille, France, 12–14 May 2009; p. 13. [Google Scholar]
- Jackson, C.R.; Apel, J.R. Synthetic Aperture Radar Marine User’s Manual, NOAA/NESDIS; Office of Research and Applications: Washington, DC, USA, 2004; Available online: https://www.sarusersmanual (accessed on 16 April 2022).
- Espedal, H.A. Detection of Oil Spill and Natural Film in the Marine Environment by Spaceborne Synthetic Aperture Radar. Ph.D. Thesis, Department of Physics, University of Bergen and Nansen Environmental and Remote Sensing Center (NERSC), Bergen, Norway, 1998; p. 200. [Google Scholar]
- Kubat, M.; Holte, R.C.; Matwin, S. Machine Learning for the Detection of Oil Spills in Satellite Radar Images. Mach. Learn. 1998, 30, 195–215. [Google Scholar] [CrossRef] [Green Version]
- Alpers, W.; Holt, B.; Zeng, K. Oil Spill Detection by Imaging Rradars: Challenges and Pitfalls. Remote Sens. Environ. 2017, 201, 133–147. [Google Scholar] [CrossRef]
- Genovez, P.C. Segmentação e Classificação de Imagens SAR Aplicadas à Detecção de Alvos Escuros em Áreas Oceânicas de Exploração e Produção de Petróleo. Ph.D. Dissertation, Universidade Federal do Rio de Janeiro (UFRJ), COPPE, Rio de Janeiro, Brazil, 2010; p. 235. Available online: http://www.coc.ufrj.br/index.php/teses-de-doutorado/154-2010/1239-patricia-carneiro-genovez (accessed on 16 April 2022).
- Bentz, C.M. Reconhecimento Automático de Eventos Ambientais Costeiros e Oceânicos em Imagens de Radares Orbitais. Ph.D. Thesis, Universidade Federal do Rio de Janeiro (UFRJ), COPPE, Rio de Janeiro, Brazil, 2006; p. 115. Available online: http://www.coc.ufrj.br/index.php?option=com_content&view=article&id=1048:cristina-maria-bentz (accessed on 16 April 2022).
- Fingas, M.F.; Brown, C.E. Review of Oil Spill Remote Sensing. Spill Sci. Technol. Bull. 1997, 4, 199–208. [Google Scholar] [CrossRef] [Green Version]
- Fingas, M.; Brown, C. Review of Oil Spill Remote Sensing. Mar. Pollut. Bull. 2014, 15, 9–23. [Google Scholar] [CrossRef] [Green Version]
- Fingas, M.; Brown, C.E. A Review of Oil Spill Remote Sensing. Sensors 2018, 18, 91. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, G.A. Multivariate Data Analysis of Satellite-Derived Measurements to Distinguish Natural from Man-Made Oil Slicks on the Sea Surface of Campeche Bay (Mexico). Ph.D. Thesis, Universidade Federal do Rio de Janeiro (UFRJ), COPPE, Rio de Janeiro, Brazil, 2015; p. 285. Available online: http://www.coc.ufrj.br/index.php?option=com_content&view=article&id=4618:gustavo-de-araujo-carvalho (accessed on 16 April 2022).
- Langley, P.; Simon, H.A. Applications of Machine Learning and Rule Induction. Commun. ACM 1995, 38, 55–64. [Google Scholar] [CrossRef]
- Lary, D.; Alavi, A.H.; Gandomi, A.; Walker, A.L. Machine Learning in Geosciences and Remote Sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of Machine-Learning Classification in Remote Sensing: An Applied Review. Int. J. Remote Sens. 2018, 39, 27842817. [Google Scholar] [CrossRef] [Green Version]
- Al-Ruzouq, R.; Gibril, M.B.A.; Shanableh, A.; Kais, A.; Hamed, O.; Al-Mansoori, S.; Khalil, M.A. Sensors, Features, and Machine Learning for Oil Spill Detection and Monitoring: A Review. Remote Sens. 2020, 12, 42. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A Survey of Image Classification Methods and Techniques for Improving Classification Performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S., Sr. Comprehensive Survey of Deep Learning in Remote Sensing: Theories, Tools, and Challenges for the Community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- McLachlan, G. Discriminant Analysis and Statistical Pattern Recognition; A Whiley-Interescience Publication, John Wiley & Sons, Inc.: Queensland, Australia, 1992; 534p, ISBN 0-471-61531-5. [Google Scholar]
- Carvalho, G.A.; Minnett, P.J.; Miranda, F.P.; Landau, L.; Paes, E.T. Exploratory Data Analysis of Synthetic Aperture Radar (SAR) Measurements to Distinguish the Sea Surface Expressions of Naturally-Occurring Oil Seeps from Human-Related Oil Spills in Campeche Bay (Gulf of Mexico). ISPRS Int. J. Geo-Inf. 2017, 6, 379. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, G.A.; Minnett, P.J.; Paes, E.T.; Miranda, F.P.; Landau, L. Refined Analysis of RADARSAT-2 Measurements to Discriminate Two Petrogenic Oil-Slick Categories: Seeps versus Spills. J. Mar. Sci. Eng. 2018, 6, 153. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, G.A.; Minnett, P.J.; Paes, E.T.; Miranda, F.P.; Landau, L. Oil-Slick Category Discrimination (Seeps vs. Spills): A Linear Discriminant Analysis Using RADARSAT-2 Backscatter Coefficients in Campeche Bay (Gulf of Mexico). Remote Sens. 2019, 11, 1652. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, G.A.; Minnett, P.J.; Miranda, F.P.; Landau, L.; Moreira, F. The Use of a RADARSAT-Derived Long-Term Dataset to Investigate the Sea Surface Expressions of Human-Related Oil Spills and Naturally-Occurring Oil Seeps in Campeche Bay, Gulf of Mexico. Can. J. Remote Sens. Spec. Issue Long-Term Satell. Data Appl. 2016, 42, 307–321. [Google Scholar] [CrossRef]
- Carvalho, G.A.; Minnett, P.J.; Ebecken, N.F.F.; Landau, L. Classification of Oil Slicks and Look-Alike Slicks: A Linear Discriminant Analysis of Microwave, Infrared, and Optical Satellite Measurements. Remote Sens. 2020, 12, 2078. [Google Scholar] [CrossRef]
- Carvalho, G.A.; Minnett, P.J.; Ebecken, N.F.F.; Landau, L. Oil Spills or Look-Alikes? Classification Rank of Surface Ocean Slick Signatures in Satellite Data. Remote Sens. 2021, 13, 3466. [Google Scholar] [CrossRef]
- Kevin, P.M. Machine Learning: A Probabilistic Perspective. MIT Press: London, UK, 2012; ISBN 978-0-262-01802-9. [Google Scholar]
- Lampropoulos, A.S.; Tsihrintzis, G.A. The Learning Problem. In Graduate Texts in Mathematics; Humana Press: Totowa, NJ, USA, 2015; pp. 31–61. [Google Scholar]
- Stephen, M. Machine Learning an Algorithmic Perspective, 2nd ed.; Chapman and Hall CRC Machine Learning and Pattern Recognition Series; CRC Press: Boca Raton, FL, USA, 2009; ISBN 978-1-4665-8333-7. [Google Scholar]
- Xu, L.; Li, J.; Brenning, A. A Comparative Study of Different Classification Techniques for Marine Oil Spill Identification Using RADARSAT-1 Imagery. Remote Sens. Environ. 2014, 141, 14–23. [Google Scholar] [CrossRef]
- Garcia-Pineda, O.; Holmes, J.; Rissing, M.; Jones, R.; Wobus, C.; Svejkovsky, J.; Hess, M. Detection of Oil near Shorelines During the Deepwater Horizon Oil Spill Using Synthetic Aperture Radar (SAR). Remote Sens. 2017, 9, 567. [Google Scholar] [CrossRef] [Green Version]
- Soares, M.O.; Teixeira, C.E.P.; Bezerra, L.E.A.; Paiva, S.V.; Tavares, T.C.L.; Garcia, T.M.; De Araújo, J.T.; Campos, C.C.; Ferreira, S.M.C.; Matthews-Cascon, H.; et al. Oil Spill in South Atlantic (Brazil): Environmental and Governmental Disaster. Mar. Policy 2020, 115, 7. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; The Morgan Kaufmann Series in Data Management Systems Morgan Kaufmann Publishers: Burlington, MA, USA, 2011; 703p, ISBN 978-0123814791. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: New York, NY, USA, 2000; ISBN 978-1-4614-7137-0. [Google Scholar]
- Carvalho, G.A.; Minnett, P.J.; Ebecken, N.F.F.; Landau, L. Machine-Learning Classification of SAR Remotely-Sensed Sea-Surface Petroleum Signatures—Part 2: Validation Phase Using New, Unseen Data from Different Regions. 2022; in preparation. [Google Scholar]
- Demsar, J.; Curk, T.; Erjavec, A.; Gorup, C.; Hocevar, T.; Milutinovic, M.; Mozina, M.; Polajnar, M.; Toplak, M.; Staric, A.; et al. Orange: Data Mining Toolbox in Python. J. Mach. Learn. Res. 2013, 14, 2349–2353. [Google Scholar]
- Demsar, J.; Zupan, B. Orange: Data Mining Fruitful and Fun—A Historical Perspective. Informatica 2013, 37, 55–60. [Google Scholar]
- Jovic, A.; Brkic, K.; Bogunovic, N. A Review of Feature Selection Methods with Applications. In Proceedings of the 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; p. 6. [Google Scholar] [CrossRef]
- Yu, L.; Liu, H.; Guyon, I. Efficient Feature Selection via Analysis of Relevance and Redundancy. J. Mach. Learn. Res. 2004, 5, 1205–1224. [Google Scholar]
- Alelyani, S.; Tang, J.; Liu, H. Feature Selection for Clustering: A Review. In Data Clustering: Algorithms and Applications; Aggarwal, C., Reddy, C., Eds.; CRC Press: Boca Raton, FL, USA, 2013; pp. 29–60. [Google Scholar] [CrossRef]
- Shah, F.P.; Patel, V. A Review on Feature Selection and Feature Extraction for Text Classification. In Proceedings of the International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), IEEE, Chennai, India, 23–25 March 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Lee, C.; Lee, G.G. Information Gain and Divergence-Based Feature Selection for Machine Learning-Based Text Categorization. Inf. Processing Manag. 2006, 42, 155–165. [Google Scholar] [CrossRef]
- Azhagusundari, B.; Thanamani, A.S. Feature Selection Based on Information Gain. Int. J. Innov. Technol. Explor. Eng. 2013, 2, 18–21. [Google Scholar]
- Harris, E. Information Gain Versus Gain Ratio: A Study of Split Method Biases. In Annals of Mathematics and Artificial Intelligence (ISAIM); Computer Science Department William & Mary: Williamsburg, VA, USA, 2002; p. 20. [Google Scholar]
- Priyadarsini, R.P.; Valarmathi, M.L.; Sivakumari, S. Gain Ratio Based Feature Selection Method for Privacy Preservation. ICTACT J. Soft Comput. 2011, 1, 201–205. [Google Scholar] [CrossRef]
- Shang, W.; Huang, H.; Zhu, H.; Lin, Y.; Qu, Y.; Wang, Z. A Novel Feature Selection Algorithm for Text Categorization. Expert Syst. Appl. 2007, 33, 1–5. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model Selection and Estimation in Regression with Grouped Variables. J. R. Stat. Soc. Ser. B Stat. Methodol. 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Chen, Y.T.; Chen, M.C. Using Chi-Square Statistics to Measure Similarities for Text Categorization. Expert Syst. Appl. 2011, 38, 3085–3090. [Google Scholar] [CrossRef]
- Urbanowicz, R.J.; Meeker, M.; La Cava, W.; Olson, R.S.; Moore, J.H. Relief-Based Feature Selection: Introduction and Review. J. Biomed. Inform. 2018, 85, 189–203. [Google Scholar] [CrossRef]
- Senliol, B.; Gulgezen, G.; Yu, L.; Cataltepe, Z. Fast Correlation Based Filter (FCBF) with a Different Search Strategy. In Proceedings of the 23rd International Symposium on Computer and Information Sciences, IEEE, Istanbul, Turkey, 27–29 October 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Burman, P. A Comparative Study of Ordinary Cross-Validation, v-Fold Cross-Validation and the Repeated Learning-Testing Methods. Biometrika 1989, 76, 503–514. [Google Scholar] [CrossRef] [Green Version]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation Between Training and Testing Sets: A Pedagogical Explanation; Departmental Technical Reports (CS): El Paso, TX, USA, 2018; pp. 1–7. [Google Scholar]
- EMSA (European Maritime Safety Agency). Near Real Time European Satellite Based Oil Spill Monitoring and Vessel Detection Service, 2nd Generation. 2022. Available online: https://portal.emsa.europa.eu/web/csn (accessed on 19 May 2022).
- Moutinho, A.M. Otimização de Sistemas de Detecção de Padrões em Imagens. Ph.D. Thesis, Universidade Federal do Rio de Janeiro (UFRJ), COPPE, Rio de Janeiro, Brazil, 2011; p. 133. Available online: http://www.coc.ufrj.br/index.php/teses-de-doutorado/155-2011/1258-adriano-martins-moutinho (accessed on 16 April 2022).
- Fox, P.A.; Luscombe, A.P.; Thompson, A.A. RADARSAT-2 SAR Modes Development and Utilization. Can. J. Remote Sens. 2004, 30, 258–264. [Google Scholar] [CrossRef]
- Tang, W.; Liu, W.T.; Stiles, B.W. Evaluation of High-Resolution Ocean Surface Vector Winds Measured by QuikSCAT Scatterometer in Coastal Regions. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1762–1769. [Google Scholar] [CrossRef]
- Kilpatrick, K.A.; Podestá, G.P.; Evans, R.H. Overview of the NOAA/NASA Pathfinder Algorithm for Sea-Surface Temperature and Associated Matchup Database. J. Geophys. Res. 2001, 106, 9179–9198. [Google Scholar] [CrossRef]
- Kilpatrick, K.A.; Podestá, G.; Walsh, S.; Williams, E.; Halliwell, V.; Szczodrak, M.; Brown, O.B.; Minnett, P.J.; Evans, R. A Decade of Sea-Surface Temperature from MODIS. Remote Sens. Environ. 2015, 165, 27–41. [Google Scholar] [CrossRef]
- O’Reilly, J.E.; Maritorena, S.; O’Brien, M.C.; Siegel, D.A.; Toogle, D.; Menzies, D.; Smith, R.C.; Mueller, J.L.; Mitchell, B.G.; Kahru, M.; et al. SeaWiFS Postlaunch Calibration and Validation Analyses. In NASA Tech. Memo, 2000-2206892; Hooker, S.B., Firestone, E.R., Eds.; NASA Goddard Space Flight Center: Greenbelt, MD, USA, 2002; Part 3; Volume 11. [Google Scholar]
- Esaias, W.; Abbott, M.; Barton, I.; Brown, O.B.; Campbell, J.W.; Carder, K.L.; Clark, D.K.; Evans, R.H.; Hoge, F.E.; Gordon, H.R.; et al. An Overview of MODIS Capabilities for Ocean Science Observations. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1250–1265. [Google Scholar] [CrossRef] [Green Version]
- Campos, E.J.D.; Gonçalves, J.E.; Ikeda, Y. Water Mass Characteristics and Geostrophic Circulation in the South Brazil Bight: Summer of 91. J. Geophys. Res. 1995, 100, 18550–18573. [Google Scholar]
- Carvalho, G.A. Wind Influence on the Sea-Surface Temperature of the Cabo Frio Upwelling (23°S/42°W—RJ/Brazil) During 2001, Through the Analysis of Satellite Measurements (Seawinds-QuikScat/AVHRR-NOAA). Bachelor’s Thesis, UERJ, Rio de Janeiro, Brazil, 2002; p. 210. [Google Scholar]
- Silveira, I.C.A.; Schmidt, A.C.K.; Campos, E.J.D.; Godoi, S.S.; Ikeda, Y. The Brazil Current off the Eastern Brazilian Coast. Rev. Bras. De Oceanogr. 2000, 48, 171–183. [Google Scholar] [CrossRef]
- Izadi, M.; Sultan, M.; Kadiri, R.E.; Ghannadi, A.; Abdelmohsen, K. A Remote Sensing and Machine Learning-Based Approach to Forecast the Onset of Harmful Algal Bloom. Remote Sens. 2021, 13, 3863. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Zar, H.J. Biostatistical Analysis, 5th ed.; Pearson New International Edition; Pearson: Upper Saddle River, NJ, USA, 2014; ISBN 1-292-02404-6. [Google Scholar]
- Domingos, P.; Pazzani, M. On the Optimality of the Simple Bayesian Classifier under Zero-One Loss. Mach. Learn. 1997, 29, 103–137. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest Neighbour Classifiers—A Tutorial. ACM Comput. Surv. 2021, 54, 25. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Kulkarni, V.Y.; Sinha, P.K. Random Forest Classifiers: A Survey and Future Research Directions. Int. J. Adv. Comput. 2013, 36, 1144–1156. [Google Scholar]
- Belgiu, M.; Dragut, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Moguerza, J.M.; Muñoz, A. Support Vector Machines with Applications. Stat. Sci. 2006, 21, 322–336. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Bennett, K.P.; Campbell, C. Support Vector Machines: Hype or Hallelujah? SIGKDD Explor. 2000, 2, 1–13. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support Vector Machines for Classification. In Efficient Learning Machines; Apress: Berkeley, CA, USA, 2015; Chapter 3; pp. 39–66. [Google Scholar] [CrossRef] [Green Version]
- Burges, C.J.C. A Tutorial on Support Vector Machines for Pattern Recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Cherkassky, V.; Ma, Y. Practical Selection of SVM Parameters and Noise Estimation for SVM Regression. Neural Netw. 2004, 17, 113–126. [Google Scholar] [CrossRef] [Green Version]
- Mountrakis, G.; Im, J.; Ogole, C. Support Vector Machines in Remote Sensing: A Review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines, 3rd ed.; Prentice Hall: Hoboken, NJ, USA, 2008; ISBN 10:0131471392. [Google Scholar]
- Trevethan, R. Sensitivity, Specificity, and Predictive Values: Foundations, Pliabilities, and Pitfalls in Research and Practice. Front. Public Health 2017, 5, 7. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness & Correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Congalton, R.G. A Review of Assessing the Accuracy of Classification of Remote Sensed Data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Pazzani, M.; Merz, C.; Murphy, P.; Ali, K.; Hume, T.; Brunk, C. Reducing Misclassification Costs. In Proceedings of the 11th International Conference on Machine Learning, New Brunswick, NJ, USA, 10–13 July 1994; Morgan Kaufmann: Burlington, MA, USA, 1994; pp. 217–225. [Google Scholar] [CrossRef]
- Swets, J.A. Measuring the Accuracy of Diagnostic Systems. Science 1988, 240, 1285–1293. [Google Scholar] [CrossRef] [Green Version]
- Lewis, D.; Gale, W. A Sequential Algorithm for Training Text Classifiers. In Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 3–6 July 1994; Springer: Berlin/Heidelberg, Germany, 1994; pp. 3–12. [Google Scholar] [CrossRef]
- Brenning, A. Benchmarking Classifiers to Optimally Integrate Terrain Analysis and Multispectral Remote Sensing in Automatic Rock Glacier Detection. Remote Sens. Environ. 2009, 113, 239–247. [Google Scholar] [CrossRef]
- Mattson, J.S.; Mattson, C.S.; Spencer, M.J.; Spencer, F.W. Classification of Petroleum Pollutants by Linear Discriminant Function Analysis of Infrared Spectral Patterns. Anal. Chem. 1977, 49, 500–502. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, L.; Clausi, D. Exploring the Potential of Active Learning for Automatic Identification of Marine Oil Spills Using 10-Year (2004-2013) RADARSAT Data. Remote Sens. 2017, 9, 1041. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Oil Spills | Look-Alikes | Targets | Morphological | MetOc | Geo-Loc | Variables | Samples | Study | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LDA 1 | 305 | 87.1% 78.2% | 334 | 79.7% 88.1% | 639 | 83.1% | + | + | 9 | 769 | Carvalho et al. [31] | |
| LDA 2 | 284 | 81.1% 74.9% | 324 | 77.3% 83.1% | 608 | 79.1% | + | 6 | 769 | Carvalho et al. [31] | ||
| LDA 3 | 277 | 79.1% 72.5% | 314 | 74.9% 81.1% | 591 | 76.9% | + | 3 | 769 | Carvalho et al. [31] | ||
| Model | Oil Spills | Look-Alikes | Targets | Morphological | MetOc | Geo-Loc | Variables | Samples | Study | |||
| LDA 4 | 316 | 90.3% 77.6% | 328 | 78.3% 90.6% | 644 | 83.7% | + | + | 7 | 769 | Carvalho et al. [31] | |
| LDA 5 | 251 | 89.3% 81.8% | 223 | 79.9% 88.1% | 474 | 84.6% | + | + | + | 10 | 560 | Carvalho et al. [32] |
| Attributes | Info Gain | % | |||
|---|---|---|---|---|---|
| * | 1) | PtoA | Perimeter to Area Ratio | 0.224 | |
| * | 2) | Area | Area | 0.215 | 95.8 |
| * | 3) | WND | Wind Speed | 0.191 | 85.4 |
| * | 4) | Per | Perimeter | 0.145 | 64.8 |
| * | 5) | FRA | Fractal Index | 0.133 | 59.6 |
| * | 6) | CHL | Chlorophyll-a Concentration | 0.082 | 36.7 |
| Calculated Cutoff Threshold | 0.078 | 35.0 | |||
| 7) | NUM | Number of Target Parts | 0.077 | 34.3 | |
| 8) | DEN | Density | 0.067 | 30.0 | |
| 9) | SST | Sea-Surface Temperature | 0.067 | 29.7 | |
| 10) | CUR | Curvature | 0.063 | 27.9 | |
| 11) | LtoW | Length to Width Ratio | 0.046 | 20.3 | |
| 12) | CMP | Compact Index | 0.039 | 17.6 | |
| A | D | |||||
|---|---|---|---|---|---|---|
| ++ | ANN | 90.0% | Best | 83.9% | ANN | + |
| NB | 80.9% | Worst | 75.2% | KNN | ||
| B | E | |||||
| SVM | 83.0% | Best | 76.5% | SVM | ANN | |
| − | DT | 75.7% | Worst | 67.8% | DT | −− |
| C | F | |||||
| RF | 80.9% | Best | 80.9% | NB | ||
| DT | 76.5% | Worst | 77.0% | DT | ||
| Naive Bayes (NB) | |||||
|---|---|---|---|---|---|
| ++ | 80.9% | A | D | 80.0% | |
| − | 76.5% | B | E | 74.3% | −− |
| 80.4% | C | F | 80.9% | ++ | |
| K-Nearest Neighbor (KNN) | |||||
| ++ | 81.3% | A | D | 75.2% | |
| − | 76.5% | B | E | 71.7% | −− |
| 79.6% | C | F | 80.4% | ++ | |
| Decision Trees (DT) | |||||
| ++ | 82.6% | A | D | 80.0% | + |
| − | 75.7% | B | E | 67.8% | (−−) |
| 76.5% | C | F | 77.0% | ||
| Random Forest (RF) | |||||
| ++ | 87.0% | A | D | 82.2% | + |
| − | 77.4% | B | E | 74.3% | −− |
| 80.9% | C | F | 79.6% | ++ | |
| Support Vector Machine (SVM) | |||||
| ++ | 88.3% | A | D | 83.5% | |
| 83.0% | B | E | 76.5% | −− | |
| − | 77.0% | C | F | 77.4% | |
| Artificial Neural Network (ANN) | |||||
| (++) | 90.0% | A | D | 83.9% | + |
| 79.6% | B | E | 76.5% | −− | |
| − | 78.3% | C | F | 77.8% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carvalho, G.d.A.; Minnett, P.J.; Ebecken, N.F.F.; Landau, L. Machine-Learning Classification of SAR Remotely-Sensed Sea-Surface Petroleum Signatures—Part 1: Training and Testing Cross Validation. Remote Sens. 2022, 14, 3027. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14133027
Carvalho GdA, Minnett PJ, Ebecken NFF, Landau L. Machine-Learning Classification of SAR Remotely-Sensed Sea-Surface Petroleum Signatures—Part 1: Training and Testing Cross Validation. Remote Sensing. 2022; 14(13):3027. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14133027
Chicago/Turabian StyleCarvalho, Gustavo de Araújo, Peter J. Minnett, Nelson F. F. Ebecken, and Luiz Landau. 2022. "Machine-Learning Classification of SAR Remotely-Sensed Sea-Surface Petroleum Signatures—Part 1: Training and Testing Cross Validation" Remote Sensing 14, no. 13: 3027. https://0-doi-org.brum.beds.ac.uk/10.3390/rs14133027