Detecting Destroyed Communities in Remote Areas with Personal Electronic Device Data: A Case Study of the 2017 Puebla Earthquake


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
Personal Electronic Device (PED) Data
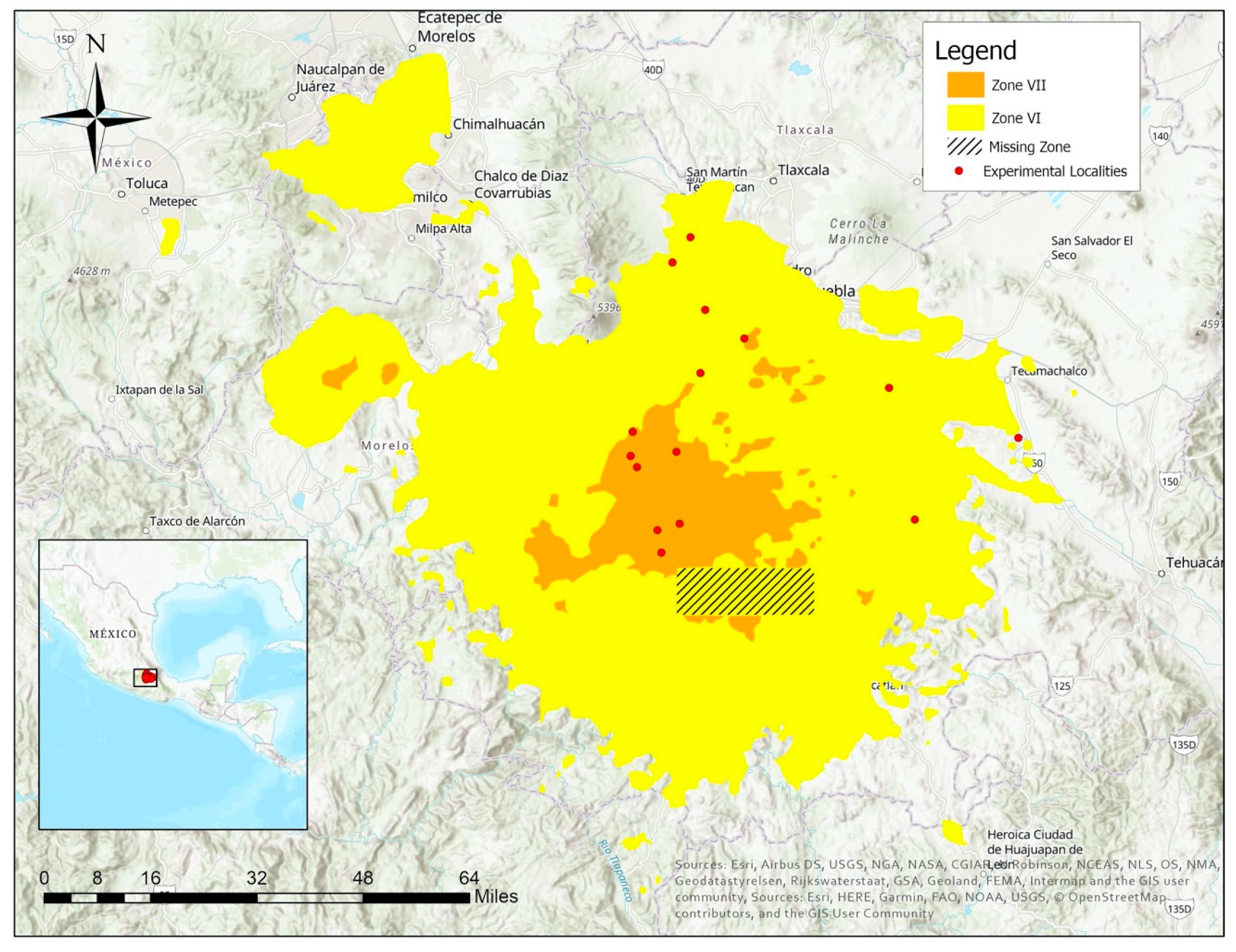
2.2. Earthquake Layer
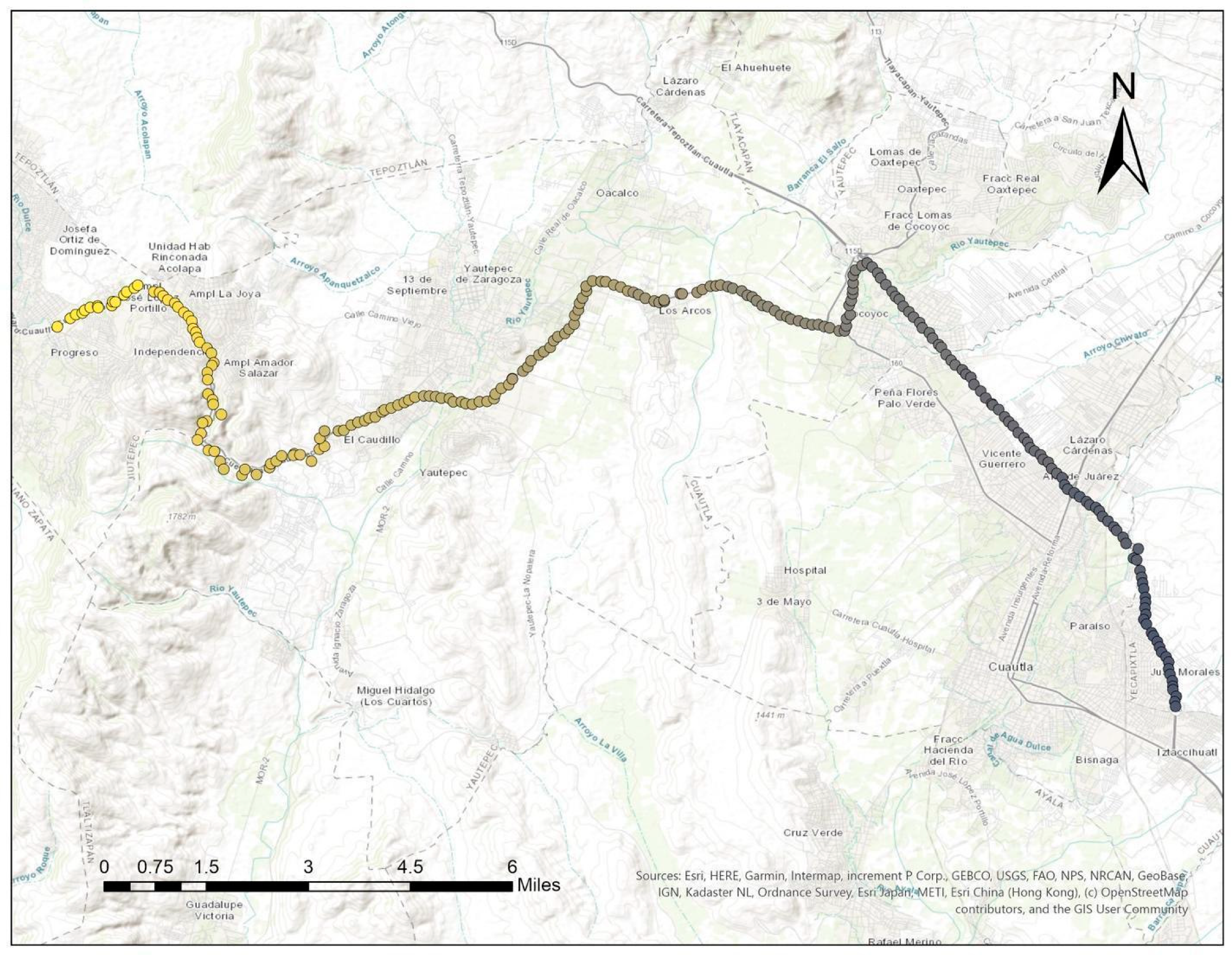
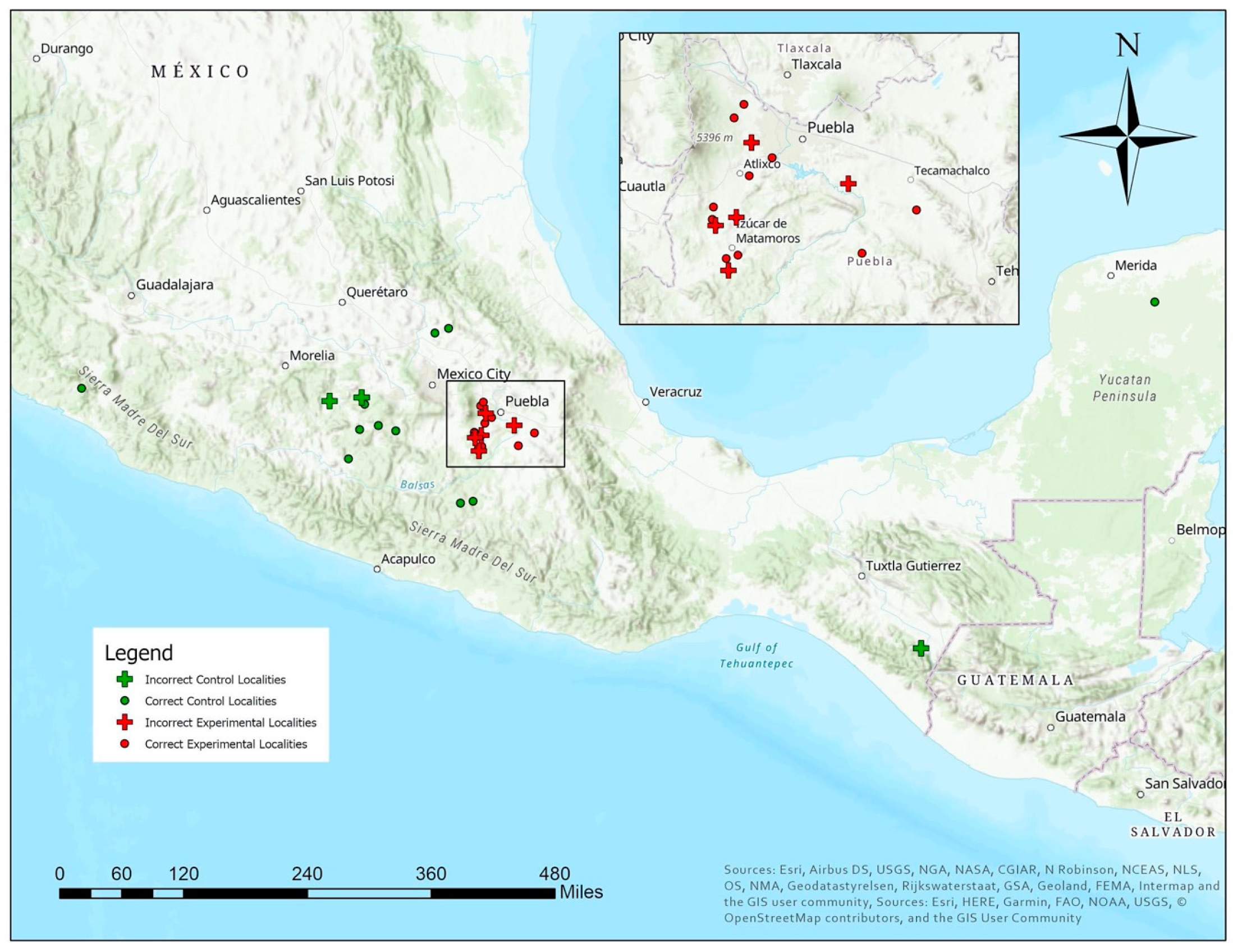
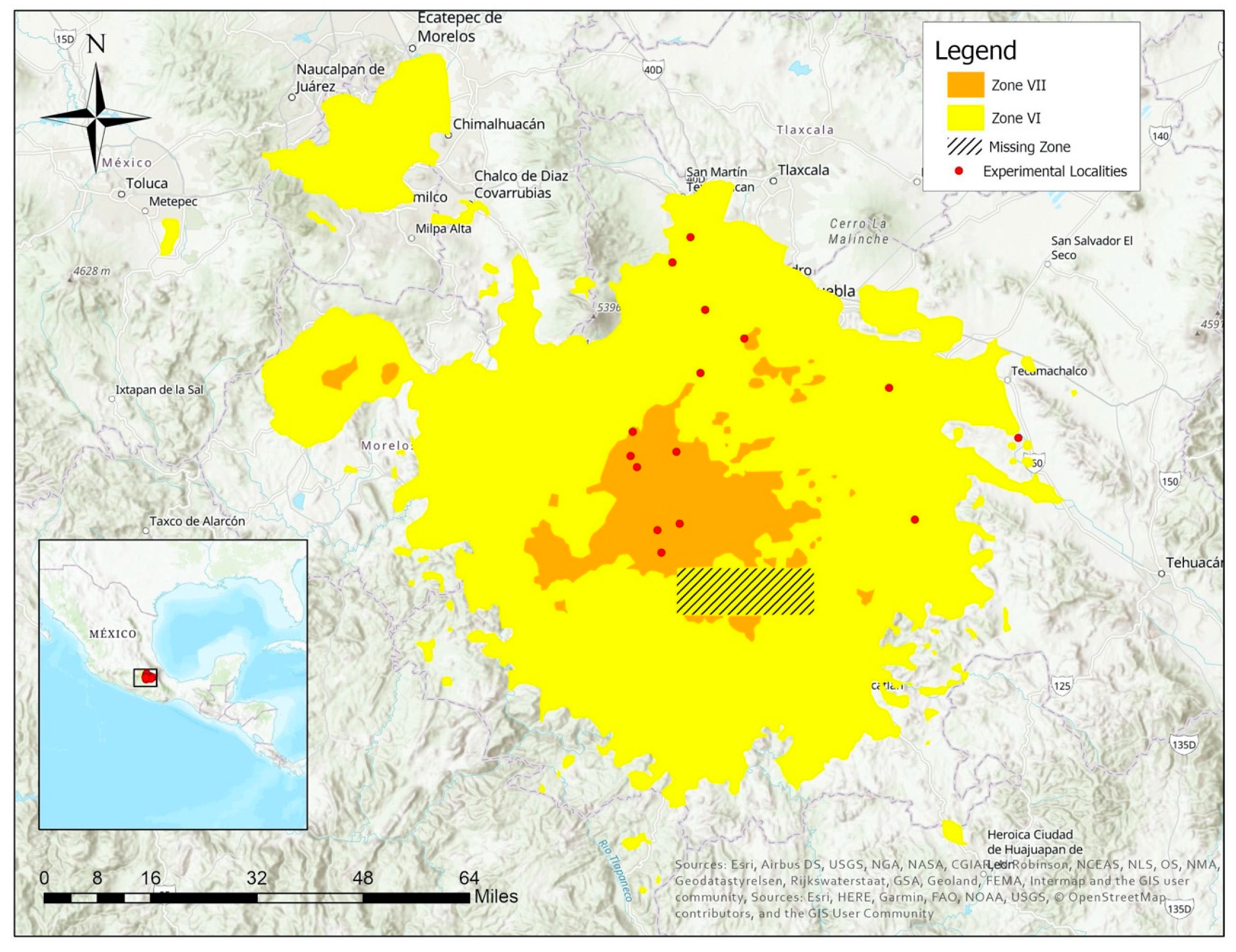
2.3. Study Area
2.4. Methodology
2.4.1. Database Preparation
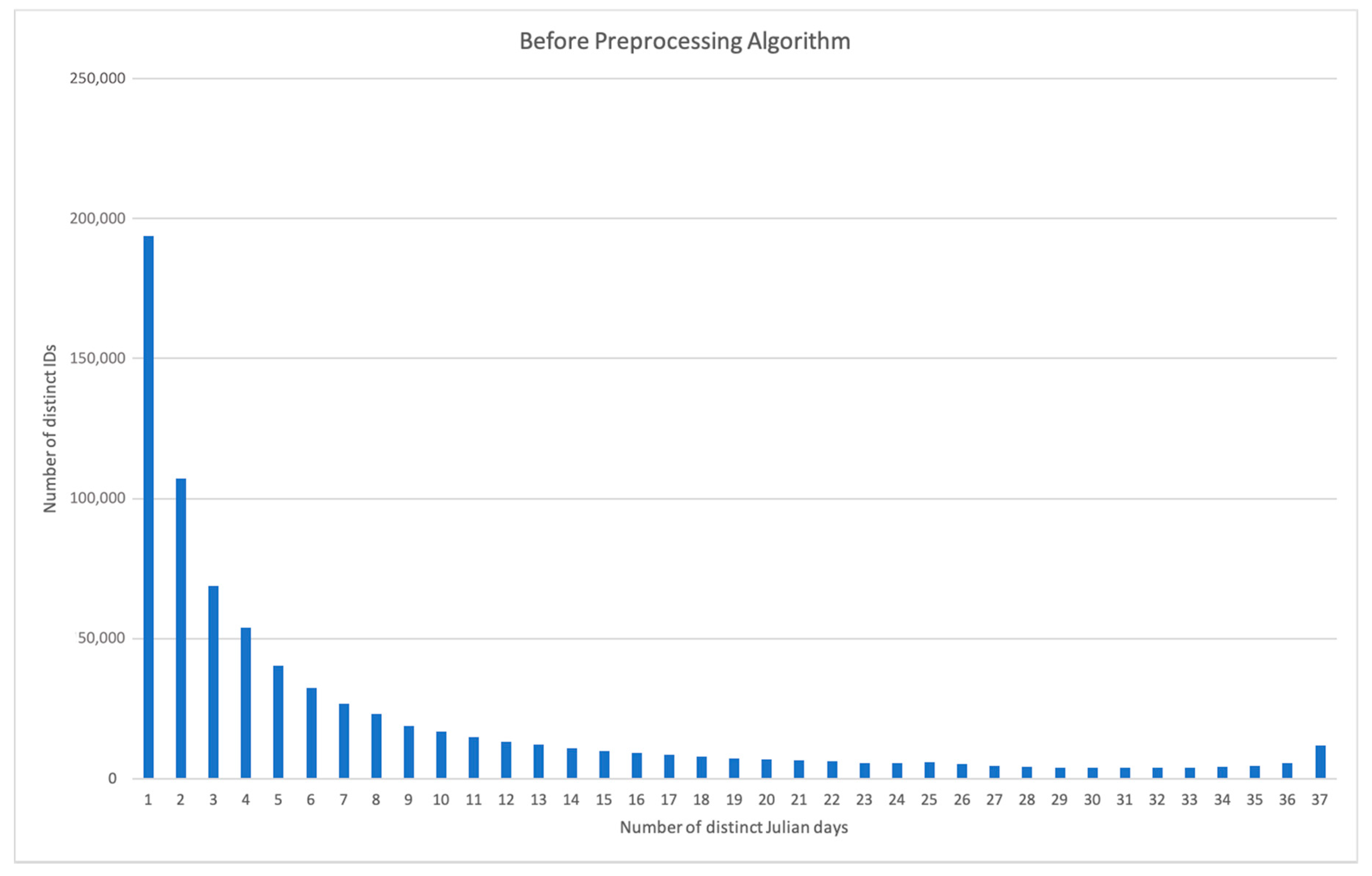
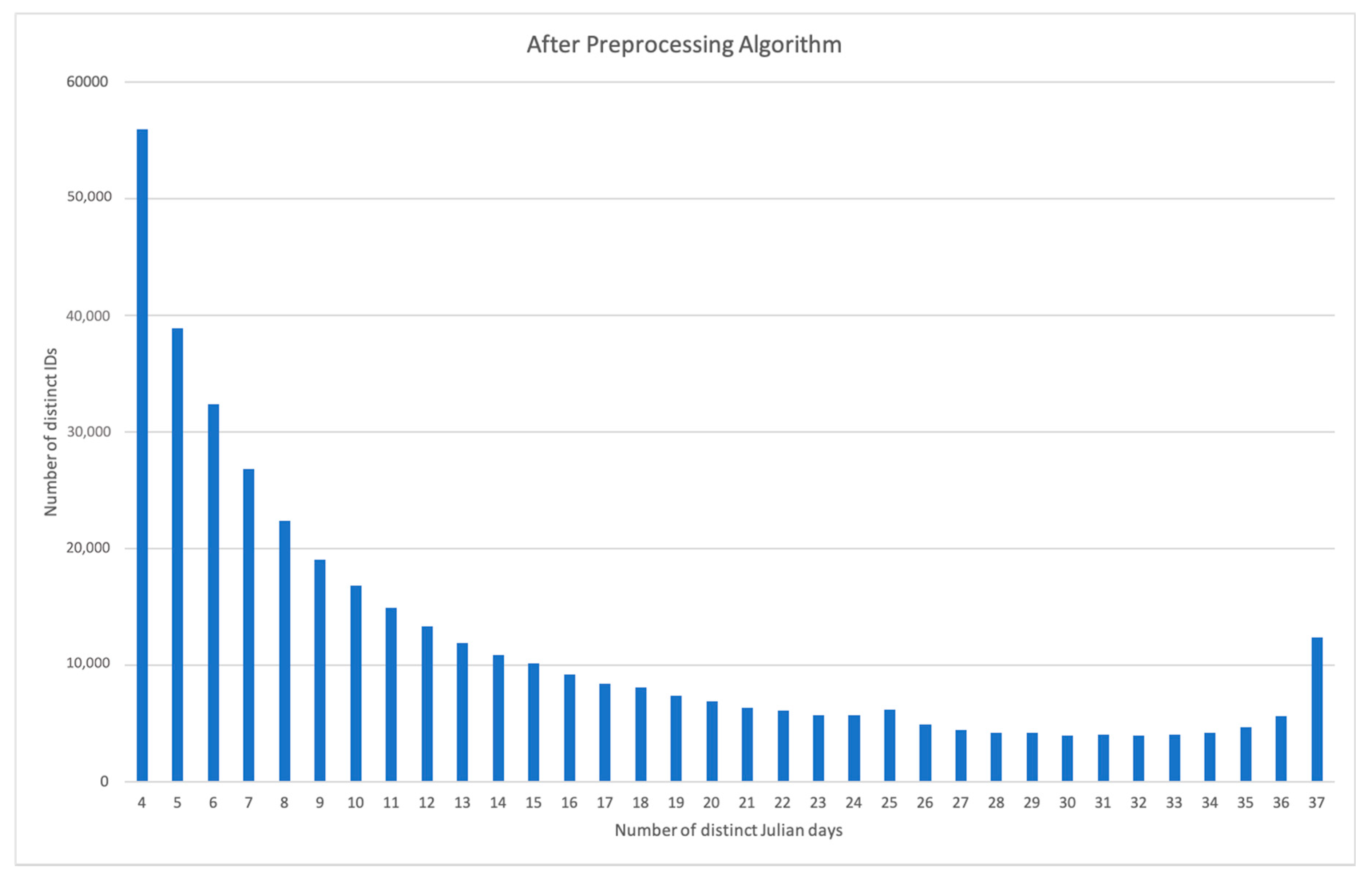
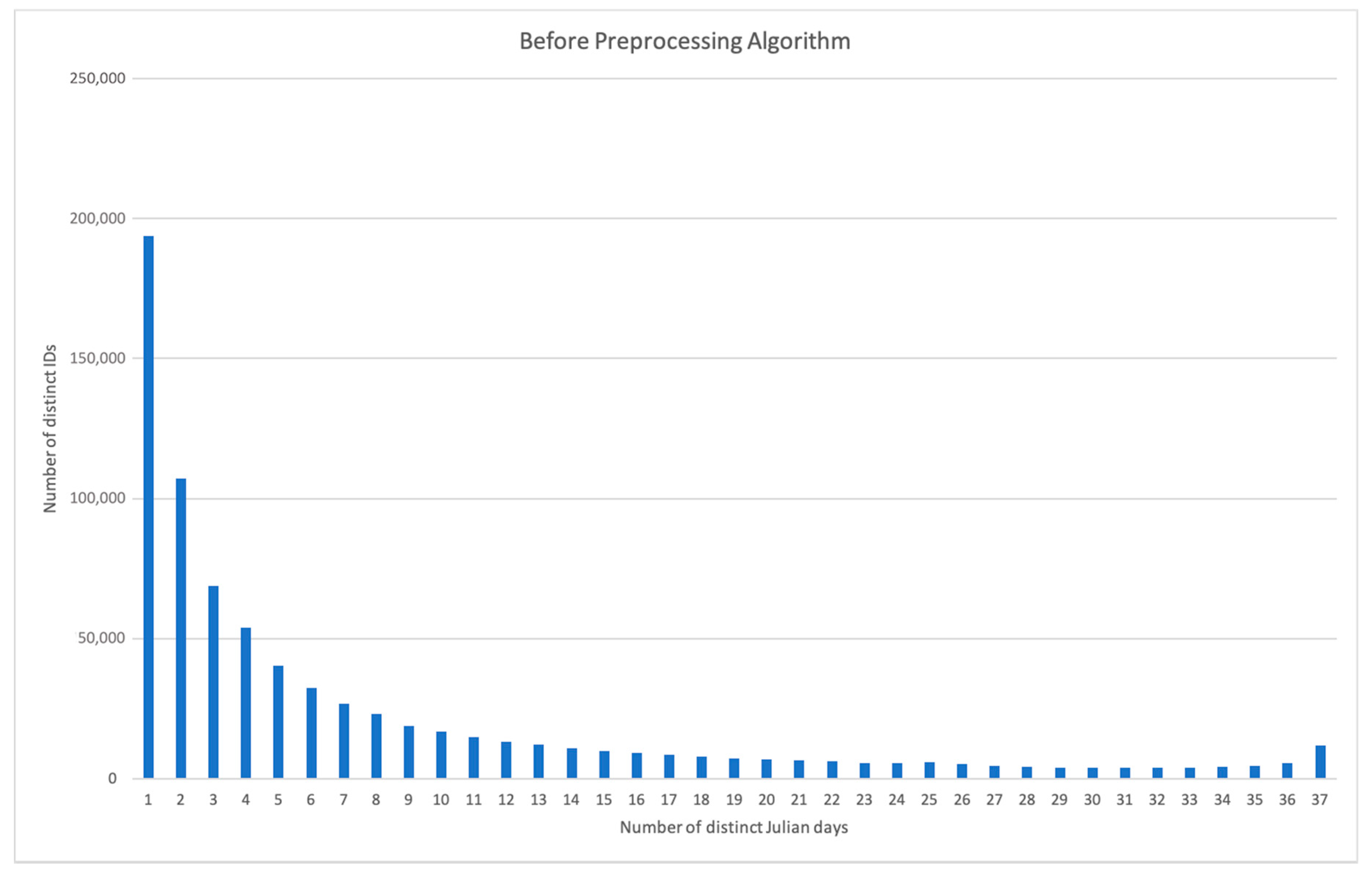
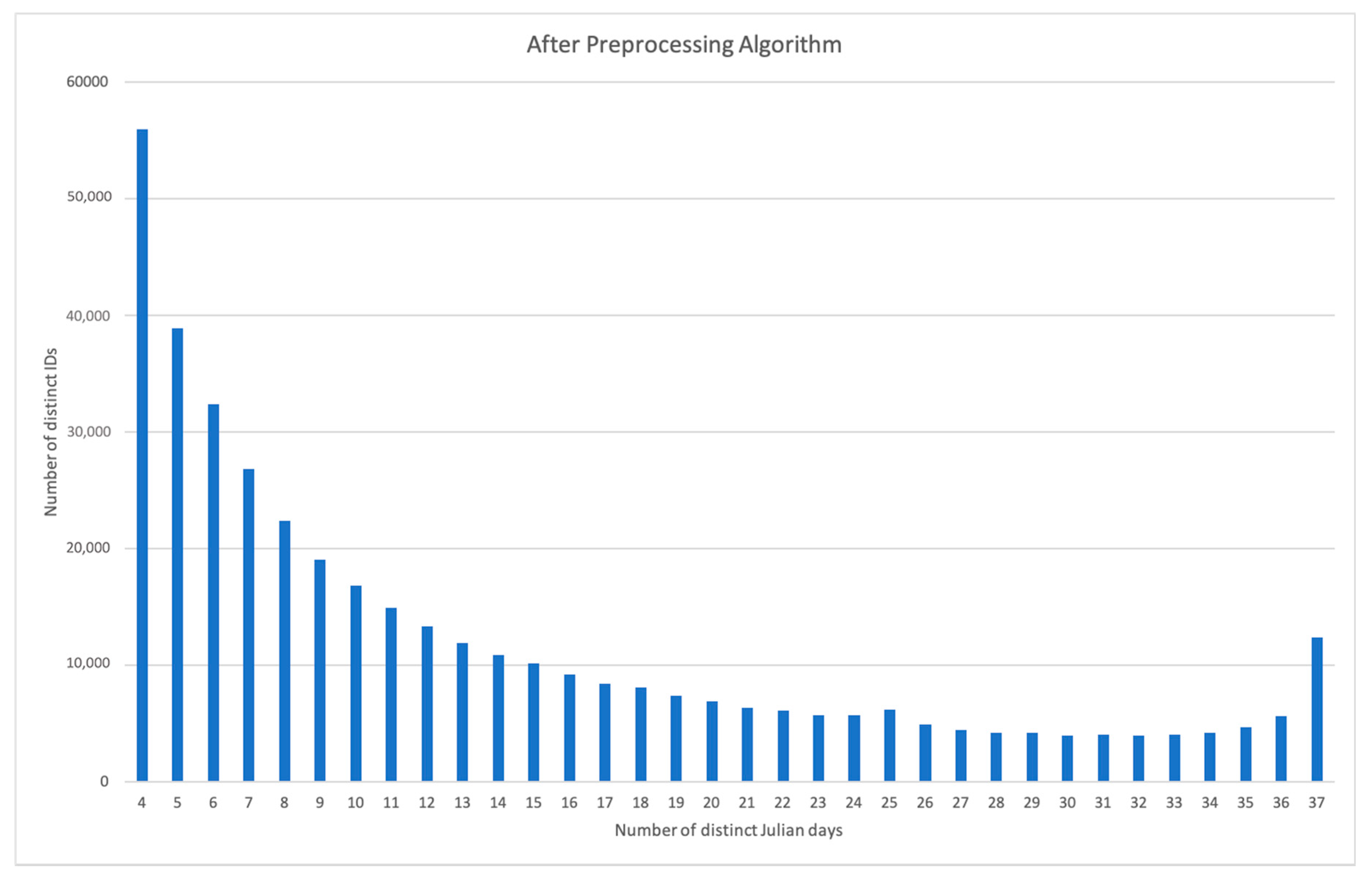
2.4.2. Preprocessing
2.4.3. Resident Determination Algorithm
2.4.4. Market Penetration Criteria
2.4.5. Resident Slope Analysis
2.5. Validation
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Unique Days that an ID had a record | Before Preprocessing | After Preprocessing |
|---|---|---|
| Mean | 7.86 | 13.48 |
| Median | 4 | 10 |
| Mode | 1 | 4 |
| Maximum | 37 | 37 |
| Minimum | 1 | 4 |
| 25th percentile | 1 | 6 |
| 75th percentile | 10 | 19 |
| Locality Name | State | Latitude, Longitude | Population | Residents Detected | Buffer Size (m) | Earthquake Class |
|---|---|---|---|---|---|---|
| San Gabriel Ixtla | Mexico | 19.257527, 100.124099 | 1624 | 139 | 995 | None |
| Tuzantla | Michoacán | 19.207914, 100.573904 | 2798 | 10 | 731 | None |
| El Arenal | Hidalgo | 20.226695, 98.905937 | 2933 | 9 | 794 | None |
| San Antonio del Rosario | Mexico | 18.398290, 100.309325 | 1356 | 9 | 965 | None |
| La Compania | Mexico | 19.163415, 100.082659 | 1094 | 10 | 530 | None |
| Almoloya de Alquisiras | Mexico | 18.864324, 99.889982 | 3153 | 13 | 1175 | None |
| Olinalá | Guerrero | 17.777701, 98.739085 | 5792 | 32 | 803 | None |
| Santiago Tezontlale | Hidalgo | 20.161152, 99.097445 | 4226 | 19 | 928 | None |
| El Terrero | Mexico | 18.790601, 99.646588 | 1273 | 7 | 752 | None |
| San Miguel Ixtapan | Mexico | 18.808699, 100.151928 | 1251 | 9 | 900 | None |
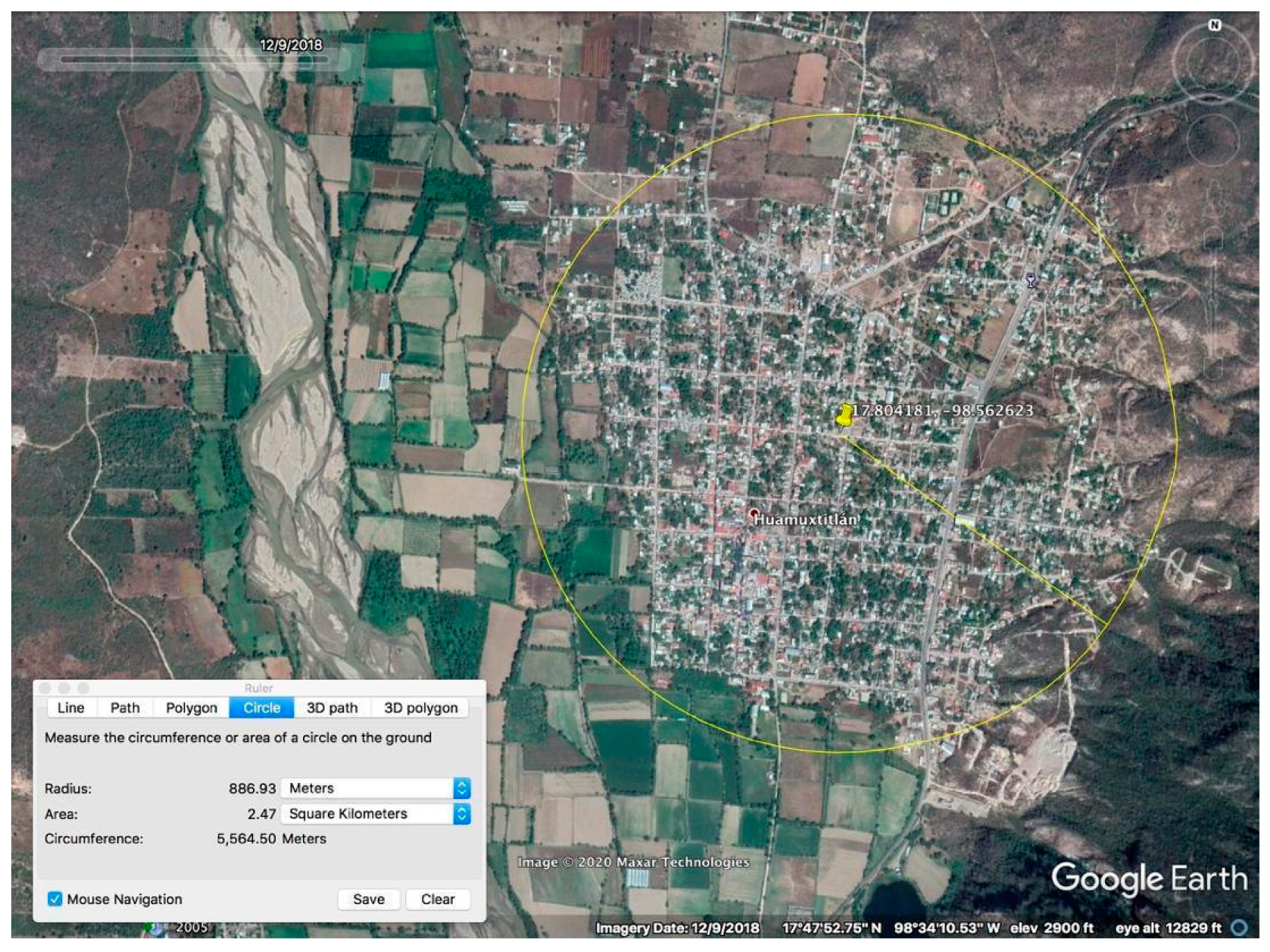
| Huamuxtitlán | Guerrero | 17.804181, 98.562623 | 6063 | 9 | 887 | None |
| Chicomuselo | Chiapas | 15.743312, 92.28328 | 5938 | 8 | 1420 | None |
| Minatitlán | Colima | 19.387388, 104.049396 | 4588 | 14 | 851 | None |
| Sotuta | Yucatan | 20.596148, 89.008522 | 5548 | 31 | 1371 | None |
| Tetiz | Yucatan | 20.961913, 89.93324 | 3939 | 42 | 1206 | None |
| Locality Name | State | Latitude, Longitude | Population | Residents Detected | Buffer Size (m) | Earthquake Class |
|---|---|---|---|---|---|---|
| San Felix Hidalgo | Puebla | 18.899207, 98.396168 | 1628 | 34 | 590 | VII |
| Tepeojuma | Puebla | 18.727938, 98.448294 | 4788 | 35 | 1200 | VII |
| Tepexi de Rodriguez | Puebla | 18.580354, 97.929589 | 4933 | 22 | 990 | VI/VII |
| San Felix Rijo | Puebla | 18.718743, 98.548084 | 1118 | 17 | 818 | VII |
| Huaquechula | Puebla | 18.771417, 98.543500 | 3005 | 20 | 916 | VII |
| San Juan Raboso | Puebla | 18.571540, 98.441297 | 3637 | 17 | 546 | VII |
| Tlapanala | Puebla | 18.694467, 98.534198 | 2727 | 13 | 957 | VII |
| San Lucas Colucán | Puebla | 18.508552, 98.481103 | 2577 | 11 | 739 | VII |
| Matzaco | Puebla | 18.557439, 98.489604 | 2580 | 34 | 784 | VII |
| Domingo Arenas | Puebla | 19.139648, 98.457057 | 5864 | 26 | 1004 | VI/VII |
| Santa Clara Ocoyucan | Puebla | 18.974270, 98.300668 | 4871 | 849 | 1107 | VII |
| Santa Maria Acuexcomac | Puebla | 19.036634, 98.385763 | 4432 | 19 | 978 | VII |
| San Gabriel Tetzoyocan | Puebla | 18.758063, 97.704389 | 6060 | 183 | 776 | VI/VII |
| Santiago Coltzingo | Puebla | 19.382436, 98.534143 | 3155 | 12 | 947 | VI/VII |
| San Mateo Capultitán | Puebla | 19.194610, 98.417855 | 2328 | 10 | 720 | VI/VII |
| Village Name | 9/4 | 9/5 | 9/6 | 9/7 | 9/8 | 9/9 | 9/10 | 9/11 | 9/12 | 9/13 | 9/14 | 9/15 | 9/16 | 9/17 | 9/18 | 9/19 | 9/20 | 9/21 | 9/22 | 9/23 | 9/24 | 9/25 | 9/26 | 9/27 | 9/28 | 9/29 | 9/30 | 10/1 | 10/2 | 10/3 | 10/4 | 10/5 | 10/6 | 10/7 | 10/8 | 10/9 | 10/10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| San Gabriel Ixtla | 41 | 51 | 66 | 58 | 57 | 62 | 62 | 56 | 50 | 50 | 53 | 73 | 66 | 71 | 48 | 39 | 36 | 36 | 37 | 34 | 31 | 29 | 23 | 23 | 26 | 29 | 33 | 35 | 25 | 21 | 20 | 21 | 26 | 28 | 19 | 27 | 18 |
| Tuzantla | 4 | 4 | 5 | 7 | 5 | 4 | 8 | 6 | 8 | 7 | 6 | 7 | 8 | 6 | 7 | 6 | 7 | 7 | 6 | 4 | 4 | 5 | 3 | 4 | 5 | 3 | 2 | 3 | 4 | 4 | 4 | 3 | 3 | 2 | 3 | 2 | 2 |
| Olinalá | 3 | 5 | 5 | 3 | 4 | 5 | 5 | 4 | 6 | 7 | 6 | 6 | 7 | 4 | 4 | 3 | 3 | 4 | 4 | 5 | 5 | 5 | 4 | 3 | 3 | 2 | 2 | 2 | 3 | 3 | 3 | 3 | 2 | 2 | 2 | 3 | 2 |
| Almoloya de Alquisiras | 1 | 3 | 4 | 5 | 4 | 4 | 5 | 5 | 3 | 3 | 4 | 3 | 2 | 5 | 4 | 5 | 4 | 3 | 6 | 5 | 5 | 5 | 4 | 3 | 4 | 3 | 2 | 3 | 4 | 3 | 3 | 2 | 2 | 2 | 4 | 3 | 1 |
| La Compania | 2 | 3 | 4 | 4 | 6 | 4 | 5 | 5 | 5 | 4 | 4 | 6 | 7 | 5 | 2 | 2 | 2 | 2 | 3 | 4 | 1 | 2 | 3 | 2 | 1 | 1 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 0 |
| San Antonio del Rosario | 4 | 6 | 6 | 8 | 3 | 7 | 6 | 7 | 4 | 7 | 6 | 6 | 6 | 6 | 5 | 7 | 4 | 5 | 3 | 4 | 5 | 3 | 2 | 5 | 4 | 4 | 3 | 3 | 3 | 5 | 4 | 4 | 3 | 3 | 3 | 3 | 2 |
| El Arenal | 9 | 8 | 10 | 12 | 11 | 8 | 18 | 17 | 12 | 10 | 8 | 12 | 6 | 10 | 10 | 9 | 7 | 9 | 8 | 7 | 5 | 9 | 7 | 8 | 10 | 7 | 7 | 7 | 7 | 7 | 6 | 8 | 5 | 5 | 7 | 5 | 5 |
| Santiago Tezontlale | 7 | 6 | 6 | 7 | 10 | 8 | 11 | 6 | 8 | 9 | 6 | 6 | 9 | 8 | 7 | 6 | 5 | 4 | 6 | 7 | 6 | 5 | 5 | 4 | 5 | 7 | 4 | 8 | 4 | 4 | 3 | 3 | 7 | 8 | 6 | 3 | 4 |
| El Terrero | 2 | 4 | 4 | 3 | 2 | 3 | 3 | 4 | 4 | 5 | 4 | 3 | 4 | 2 | 2 | 4 | 4 | 2 | 4 | 2 | 3 | 3 | 4 | 5 | 5 | 2 | 3 | 2 | 3 | 2 | 3 | 3 | 4 | 3 | 2 | 3 | 1 |
| San Miguel Ixtapan | 6 | 7 | 5 | 5 | 4 | 4 | 7 | 6 | 6 | 4 | 5 | 4 | 2 | 6 | 5 | 3 | 3 | 4 | 2 | 1 | 1 | 4 | 5 | 5 | 4 | 3 | 2 | 3 | 3 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 0 |
| Huamuxtitlán | 4 | 6 | 6 | 4 | 3 | 5 | 3 | 4 | 4 | 6 | 6 | 6 | 4 | 3 | 3 | 4 | 3 | 5 | 3 | 3 | 2 | 3 | 4 | 2 | 2 | 1 | 2 | 3 | 4 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 |
| Chicomuselo | 2 | 3 | 2 | 2 | 2 | 1 | 3 | 3 | 4 | 4 | 4 | 3 | 6 | 4 | 3 | 2 | 3 | 3 | 2 | 3 | 2 | 2 | 1 | 6 | 4 | 3 | 3 | 4 | 4 | 5 | 5 | 3 | 5 | 6 | 5 | 6 | 5 |
| Minatitlán | 6 | 8 | 7 | 4 | 3 | 6 | 6 | 7 | 7 | 5 | 6 | 7 | 7 | 8 | 7 | 6 | 7 | 7 | 6 | 6 | 6 | 7 | 6 | 8 | 8 | 6 | 7 | 4 | 4 | 5 | 4 | 5 | 6 | 5 | 4 | 4 | 2 |
| Sotuta | 10 | 12 | 14 | 17 | 13 | 13 | 15 | 10 | 8 | 9 | 11 | 14 | 10 | 11 | 8 | 8 | 6 | 5 | 9 | 6 | 7 | 8 | 8 | 13 | 18 | 14 | 10 | 13 | 11 | 11 | 10 | 11 | 12 | 12 | 12 | 10 | 7 |
| Tetiz | 19 | 18 | 24 | 16 | 18 | 23 | 22 | 16 | 18 | 21 | 20 | 17 | 17 | 21 | 16 | 19 | 17 | 18 | 16 | 15 | 14 | 12 | 12 | 10 | 10 | 9 | 8 | 10 | 8 | 12 | 6 | 7 | 7 | 4 | 5 | 4 | 2 |
| San Felix Hidalgo | 9 | 14 | 16 | 15 | 11 | 6 | 11 | 13 | 12 | 17 | 17 | 10 | 11 | 13 | 14 | 9 | 12 | 13 | 14 | 10 | 10 | 10 | 11 | 10 | 10 | 9 | 8 | 10 | 8 | 12 | 6 | 7 | 7 | 4 | 5 | 4 | 2 |
| Tepeojuma | 12 | 16 | 17 | 13 | 11 | 12 | 15 | 16 | 11 | 10 | 16 | 10 | 9 | 14 | 13 | 14 | 8 | 9 | 7 | 8 | 9 | 10 | 10 | 11 | 7 | 6 | 8 | 8 | 9 | 5 | 7 | 5 | 4 | 4 | 2 | 5 | 1 |
| Tepexi de Rodriguez | 8 | 8 | 9 | 8 | 5 | 5 | 7 | 10 | 8 | 5 | 6 | 11 | 6 | 11 | 9 | 10 | 5 | 6 | 4 | 4 | 7 | 8 | 7 | 6 | 5 | 4 | 4 | 4 | 5 | 4 | 3 | 3 | 1 | 3 | 4 | 3 | 0 |
| San Felix Rijo | 6 | 7 | 6 | 7 | 8 | 10 | 13 | 10 | 7 | 7 | 4 | 8 | 10 | 9 | 8 | 7 | 8 | 8 | 7 | 8 | 6 | 7 | 6 | 7 | 4 | 7 | 3 | 5 | 6 | 5 | 6 | 6 | 5 | 3 | 4 | 5 | 2 |
| Huaquechula | 6 | 8 | 7 | 8 | 10 | 11 | 14 | 9 | 7 | 8 | 5 | 9 | 11 | 9 | 8 | 6 | 7 | 7 | 6 | 7 | 6 | 7 | 4 | 7 | 5 | 4 | 3 | 4 | 6 | 3 | 7 | 5 | 5 | 3 | 4 | 4 | 1 |
| San Juan Raboso | 5 | 5 | 8 | 9 | 11 | 8 | 8 | 8 | 7 | 8 | 7 | 11 | 9 | 7 | 8 | 8 | 9 | 8 | 10 | 10 | 7 | 5 | 4 | 5 | 5 | 5 | 8 | 8 | 6 | 6 | 5 | 4 | 5 | 6 | 3 | 5 | 5 |
| Tlapanala | 7 | 7 | 6 | 6 | 8 | 8 | 10 | 8 | 6 | 5 | 2 | 5 | 7 | 6 | 6 | 6 | 6 | 6 | 7 | 7 | 4 | 6 | 4 | 5 | 4 | 3 | 3 | 3 | 5 | 5 | 5 | 5 | 4 | 2 | 3 | 4 | 1 |
| San Lucas Colucán | 2 | 4 | 7 | 3 | 6 | 6 | 4 | 5 | 5 | 3 | 5 | 5 | 4 | 2 | 3 | 2 | 2 | 2 | 1 | 1 | 1 | 3 | 2 | 1 | 2 | 1 | 2 | 3 | 3 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Matzaco | 11 | 14 | 17 | 12 | 14 | 15 | 17 | 18 | 17 | 13 | 19 | 15 | 17 | 12 | 14 | 13 | 11 | 12 | 11 | 10 | 9 | 9 | 7 | 5 | 5 | 9 | 8 | 8 | 9 | 4 | 6 | 6 | 7 | 9 | 7 | 6 | 4 |
| Domingo Arenas | 7 | 9 | 12 | 11 | 9 | 10 | 10 | 9 | 10 | 11 | 10 | 14 | 12 | 14 | 12 | 9 | 9 | 8 | 9 | 11 | 10 | 7 | 8 | 10 | 7 | 6 | 9 | 6 | 7 | 6 | 7 | 8 | 7 | 8 | 7 | 5 | 4 |
| Santa Clara Ocoyucan | 282 | 373 | 374 | 400 | 406 | 366 | 368 | 386 | 393 | 410 | 403 | 375 | 341 | 395 | 360 | 316 | 310 | 318 | 305 | 246 | 264 | 302 | 298 | 289 | 297 | 274 | 257 | 258 | 259 | 262 | 249 | 257 | 257 | 205 | 216 | 220 | 139 |
| Santa Maria Acuexcomac | 4 | 11 | 6 | 5 | 6 | 4 | 7 | 7 | 8 | 11 | 8 | 4 | 7 | 5 | 6 | 6 | 7 | 6 | 6 | 3 | 5 | 2 | 4 | 5 | 4 | 4 | 2 | 3 | 6 | 5 | 5 | 3 | 4 | 4 | 3 | 3 | 3 |
| San Mateo Capultitlán | 67 | 85 | 80 | 85 | 100 | 86 | 92 | 83 | 78 | 87 | 81 | 78 | 85 | 78 | 78 | 79 | 77 | 76 | 69 | 72 | 78 | 64 | 61 | 61 | 57 | 56 | 54 | 63 | 63 | 60 | 60 | 63 | 56 | 46 | 51 | 45 | 22 |
| San Gabriel Tetzoyocan | 4 | 5 | 3 | 4 | 5 | 8 | 7 | 6 | 7 | 5 | 9 | 8 | 5 | 8 | 6 | 5 | 7 | 6 | 7 | 8 | 6 | 5 | 6 | 6 | 5 | 3 | 4 | 6 | 5 | 5 | 5 | 5 | 5 | 3 | 4 | 4 | 3 |
| Concepción Cuautla | 5 | 5 | 6 | 3 | 5 | 3 | 6 | 5 | 4 | 6 | 6 | 4 | 5 | 5 | 3 | 3 | 3 | 5 | 5 | 4 | 5 | 3 | 4 | 3 | 4 | 3 | 4 | 2 | 2 | 1 | 3 | 2 | 2 | 2 | 1 | 2 | 1 |
| Village Name | Pre-Quake Slope | Post-Quake Slope | (Post-Slope) − (Pre-Slope) |
|---|---|---|---|
| San Gabriel Ixtla | 64% | −69% | −133% |
| Tuzantla | 20% | −19% | −39% |
| Olinalá | 12% | −11% | −24% |
| Almoloya de Alquisiras | 4% | −14% | −17% |
| La Compania | 10% | −9% | −20% |
| San Antonio del Rosario | 2% | −6% | −8% |
| El Arenal | −4% | −12% | −8% |
| Santiago Tezontlale | 4% | −3% | −7% |
| El Terrero | 0% | −5% | −5% |
| San Miguel Ixtapan | −11% | −12% | −1% |
| Huamuxtitlán | −5% | −2% | 3% |
| Chicomuselo | 18% | −10% | −28% |
| Minatitlán | 10% | −9% | −19% |
| Sotuta | −26% | −20% | 6% |
| Tetiz | −13% | −35% | −22% |
| San Felix Hidalgo | 9% | −45% | −54% |
| Tepeojuma | −18% | −33% | −15% |
| Tepexi de Rodriguez | 9% | −22% | −31% |
| San Felix Rijo | 9% | −21% | −30% |
| Huaquechula | 6% | −19% | −25% |
| San Juan Raboso | 12% | −20% | −32% |
| Tlapanala | −14% | −17% | −3% |
| San Lucas Colucán | −7% | −10% | −3% |
| Matzaco | 11% | −25% | −36% |
| Domingo Arenas | 29% | −19% | −48% |
| Santa Clara Ocoyucan | 185% | −549% | −734% |
| Santa Maria Acuexcomac | 0% | −10% | −10% |
| San Mateo Capultitlán | −13% | −166% | −153% |
| San Gabriel Tetzoyocan | 23% | −16% | −39% |
References
- Alberto, Y.; Otsubo, M.; Kyokawa, H.; Kiyota, T.; Towhata, I. Reconnaissance of the 2017 Puebla, Mexico earthquake. Soils Found 2018, 58, 1073–1092. [Google Scholar] [CrossRef]
- Powerful Quake Devastates Central Mexico, Leaving More Than 200 Dead. Available online: https://www.npr.org/sections/thetwo-way/2017/09/19/552141609/at-least-42-people-killed-as-powerful-earthquake-convulses-central-mexico (accessed on 5 December 2019).
- Bengtsson, L.; Lu, X.; Thorson, A.; Garfield, R.; Von Schreeb, J. Improved response to disasters and outbreaks by tracking population movements with mobile phone network data: A post-earthquake geospatial study in Haiti. PLoS Med. 2011, 8, e1001083. [Google Scholar] [CrossRef] [PubMed]
- Sahar, L.; Muthukumar, S.; French, S.P. Using Aerial Imagery and GIS in Automated Building Footprint Extraction and Shape Recognition for Earthquake Risk Assessment of Urban Inventories. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3511–3520. [Google Scholar] [CrossRef]
- Feng, T.; Hong, Z.; Wu, H.; Fu, Q.; Wang, C.; Jiang, C.; Tong, X. Estimation of earthquake casualties using high-resolution remote sensing: A case study of Dujiangyan city in the May 2008 Wenchuan earthquake. Nat. Hazards 2013, 69, 1577–1595. [Google Scholar] [CrossRef]
- Ródenas, J.L.; García-Ayllón, S.; Tomás, A. Estimation of the Buildings Seismic Vulnerability: A Methodological Proposal for Planning Ante-Earthquake Scenarios in Urban Areas. Appl. Sci. 2018, 8, 1208. [Google Scholar] [CrossRef] [Green Version]
- Hossain, M.S.; Gadagamma, C.K.; Bhattacharya, Y.; Numada, M.; Morimura, N.; Meguro, K. Integration of smart watch and Geographic Information System (GIS) to identify post-earthquake critical rescue area part. I. Development of the System. Prog. Disaster Sci. 2020, 7, 100116. [Google Scholar] [CrossRef]
- Jena, R.; Pradhan, B.; Al-Amri, A.; Lee, C.W.; Park, H. Earthquake Probability Assessment for the Indian Subcontinent Using Deep Learning. Multidiscip. Digit. Publ. Inst. Sens. 2020, 20, 4369. [Google Scholar] [CrossRef]
- Mulder, F.; Ferguson, J.; Groenewegen, P.; Boersma, K.; Wolbers, J. Questioning Big Data: Crowdsourcing crisis data towards an inclusive humanitarian response. Big Data Soc. 2016. [Google Scholar] [CrossRef]
- Palen, L.; Hughes, A.L. Social Media in Disaster Communication. In Handbook of Disaster Research Handbooks of Sociology and Social Research; Springer International Publishing AG: Cham, Switzerland, 2017; pp. 497–518. [Google Scholar] [CrossRef]
- Marx, A.; Windisch, R.; Kim, J.S. Detecting village burnings with high-cadence smallsats: A case-study in the Rakhine State of Myanmar. Remote Sens. Appl. Soc. Environ. 2019, 14, 119–125. [Google Scholar] [CrossRef]
- Automating Disaster Relief. Available online: https://trajectorymagazine.com/automating-disaster-relief/ (accessed on 2 December 2019).
- Yu, M.; Yang, C.; Li, Y. Big Data in Natural Disaster Management: A Review. Geosciences 2018, 8, 165. [Google Scholar] [CrossRef] [Green Version]
- Salat, H.; Smoreda, Z.; Schläpfer, M. A method to estimate population densities and electricity consumption from mobile and phone data in developing countries. PLoS ONE 2020, 15, e0235224. [Google Scholar] [CrossRef] [PubMed]
- Zufiria, P.J.; Pastor-Escuredo, D.; Úbeda-Medina, L.; Hernandez-Medina, M.; Barriales-Valbuena, I.; Morales, A.J.; Jacques, D.C.; Nkwambi, W.; Diop, M.B.; Quinn, J.; et al. Identifying seasonal mobility profiles from anonymized and aggregated mobile phone data. Application in food security. PLoS ONE 2018, 13, e0195714. [Google Scholar] [CrossRef] [Green Version]
- Lai, S.; zu Erbach-Schoenberg, E.; Pezzulo, C.; Ruktanonchai, N.; Sorichetta, A.; Steele, J.; Li, T.; Dooley, C.; Tatem, A. Exploring the use of mobile phone data for national migration statistics. Palgrave Commun. 2019, 5, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Wilson, R.; zu Erbach-Schoenberg, E.; Albert, M.; Power, D.; Tudge, S.; Gonzalez, M.; Guthrie, S.; Chamberlain, H.; Brooks, C.; Hughes, C.; et al. Rapid and near real-time assessments of population displacement using mobile phone data following disasters: The 2015 Nepal Earthquake. PLoS Curr. 2016, 8. [Google Scholar] [CrossRef] [PubMed]
- Pastor-Escuredo, D.; Morales-Guzman, A.; Torres-Fernandez, Y.; Bauer, J.-M.; Wadhwa, A.; Castro-Correa, C.; Romanoff, L.; Lee, J.G.; Rutherford, A.; Frias-Martinez, V.; et al. Flooding through the lens of mobile phone activity. In Proceedings of the IEEE Global Humanitarian Technology Conference (GHTC 2014), San Jose, CA, USA, 10–13 October 2014; pp. 279–286. [Google Scholar] [CrossRef] [Green Version]
- Andrade, X.; Layedra, F.; Vaca, C.; Cruz, E. RiSC: Quantifying change after natural disasters to estimate infrastructure damage with mobile phone data. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 3383–3391. [Google Scholar]
- Horanont, T.; Witayangkurn, A.; Sekimoto, Y.; Shibasaki, R. Large-Scale Auto-GPS Analysis for Discerning Behavior Change during Crisis. IEEE Intell. Syst. 2013, 28, 26–34. [Google Scholar] [CrossRef]
- Peak, C.M.; Wesolowski, A.; zu Erbach-Schoenberg, E.; Tatem, A.J.; Wetter, E.; Lu, X.; Power, D.; Weidman-Grunewald, E.; Ramos, S.; Moritz, S.; et al. Population mobility reductions associated with travel restrictions during the Ebola epidemic in Sierra Leone: Use of mobile phone data. Int. J. Epidemiol. 2018, 47, 1562–1570. [Google Scholar] [CrossRef] [PubMed]
- Human Rights Watch. Mobile Location Data and Covid-19: Q&A. Available online: https://www.hrw.org/news/2020/05/13/mobile-location-data-and-covid-19-qa# (accessed on 2 December 2019).
- Yabe, T.; Sekimoto, Y.; Tsubouchi, K.; Ikemoto, S. Cross-comparative analysis of evacuation behavior after earthquakes using mobile phone data. PLoS ONE 2019, 14, e0211375. [Google Scholar] [CrossRef]
- Chen, Z.; Gong, Z.; Yang, S.; Ma, Q.; Kan, C. Impact of extreme weather events on urban human flow: A perspective from location-based service data. Comput. Environ. Urban. Syst. 2020, 83, 101520. [Google Scholar] [CrossRef] [PubMed]
- Liautaud, P.; Huybers, P.; Santillana, M. Fever and mobility data indicate social distancing has reduced incidence of communicable disease in the United States. arXiv 2020, arXiv:2004.09911. Available online: https://arxiv.org/pdf/2004.09911.pdf (accessed on 25 May 2020).
- Thompson, S.A.; Warzel, C. Twelve Million Phones, One Dataset, Zero Privacy. 2019. Available online: https://www.nytimes.com/interactive/2019/12/19/opinion/location-tracking-cell-phone.html (accessed on 2 December 2019).
- Cuebiq’s Data for Good Program Provides UNICEF with High-Precision Human Mobility Data for Real-Time Response to Humanitarian. Available online: https://www.bloomberg.com/press-releases/2019-09-10/cuebiq-s-data-for-good-program-provides-unicef-with-high-precision-human-mobility-data-for-real-time-response-to-humanitarian (accessed on 2 December 2019).
- Earthquake Leaves Hundreds Dead, Crews Combing through Rubble in Mexico. Available online: https://www.citynews1130.com/2017/09/20/earthquake-leaves-hundreds-dead-crews-combing-rubble-mexico/ (accessed on 5 October 2020).
- Emergency Response Coordination Centre (ERCC)—DG ECHO Daily map. Available online: https://erccportal.jrc.ec.europa.eu/ercmaps/ECDM_20170920_Mexico_EQ.pdf (accessed on 25 May 2020).
- Newzoo Global Mobile Market Report Light Version. 2017. Available online: https://resources.newzoo.com/hubfs/Reports/Newzoo_2017_Global_Mobile_Market_Report_Free.pdf (accessed on 2 December 2019).
- Censos y Conteeos de Poblaación y Vivienda. Available online: https://www.inegi.org.mx/programas/ccpv/2010/default.html#Microdatos (accessed on 2 December 2019).
- Newzoo Global Mobile Market Report 2019: Light Version. Available online: https://resources.newzoo.com/hubfs/Reports/2019_Free_Global_Mobile_Market_Report.pdf?utm_campaign=Mobile%20Report%20Launch%202019&utm_medium=email&_hsmi=76926953&_hsenc=p2ANqtz-_O72fQKM2ds9C0e-CuL4yhUoFzrQCAirctfPQYeB6ab0u_Qx998l6SSv0rf4SlGCKGX3DCWTTE-lCCUesAC9RsQqXGJg&utm_content=76926953&utm_source=hs_automation (accessed on 25 May 2020).






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marx, A.; Poynor, M.; Kim, Y.-K.; Oberreiter, L. Detecting Destroyed Communities in Remote Areas with Personal Electronic Device Data: A Case Study of the 2017 Puebla Earthquake. ISPRS Int. J. Geo-Inf. 2020, 9, 643. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9110643
Marx A, Poynor M, Kim Y-K, Oberreiter L. Detecting Destroyed Communities in Remote Areas with Personal Electronic Device Data: A Case Study of the 2017 Puebla Earthquake. ISPRS International Journal of Geo-Information. 2020; 9(11):643. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9110643
Chicago/Turabian StyleMarx, Andrew, Mia Poynor, Young-Kyung Kim, and Lauren Oberreiter. 2020. "Detecting Destroyed Communities in Remote Areas with Personal Electronic Device Data: A Case Study of the 2017 Puebla Earthquake" ISPRS International Journal of Geo-Information 9, no. 11: 643. https://0-doi-org.brum.beds.ac.uk/10.3390/ijgi9110643